



Imaginez : vous êtes dans un aéroport, et vous passez le contrôle de sécurité. Un groupe d'agents scannent votre carte d'embarquement et votre passeport avant de vous envoyer vers votre porte d'embarquement. Tout à coup, certains agents partent en pause. Voilà qu'il se produit une fuite dans le plafond au-dessus du poste de contrôle. Ou tout simplement qu'un grand nombre de vols sont programmés pour 18 h, ce qui provoque l'arrivée de nombreux passagers en même temps. Dans les deux cas, le déséquilibre entre l'offre sur place et la demande peut donner lieu à d'énormes files d'attente et à des voyageurs mécontents qui ne demandent qu'à avancer rapidement dans la file pour accéder à leur vol. Comment l'aéroport gère-t-il la situation ?
Dans certains aéroports, rien ne sera fait et on vous laissera simplement prendre votre mal en patience. D'autres aéroports proposeront des files rapides aux postes de contrôle moyennant des frais supplémentaires. Cependant, dans la plupart des aéroports, vous serez invités à vous rendre vers un autre poste de contrôle de sécurité un peu plus éloigné afin que vous puissiez arriver à la porte d'embarquement le plus rapidement possible. Il arrive même qu'une signalétique vous indique le temps d'attente à chaque file pour faciliter une décision avisée au moment de passer les contrôles.
Chez Cloudflare, nous avons le même problème. Nous datacenters sont présents dans 300 villes dans le monde entier et ont été conçus pour recevoir le trafic des utilisateurs finaux de l'ensemble de nos suites de produits. Dans un monde idéal, nous disposons toujours des ordinateurs et de la bande passante en quantité suffisante pour servir tout le monde au plus près de son emplacement. Ce monde n'est toutefois pas toujours idéal ; il arrive qu'un de nos datacenters se trouve hors ligne ou soit en maintenance, ou encore qu'une connexion vers un datacenter soit en panne ou qu'un équipement soit défaillant, etc... Lorsque c'est le cas, nous n'avons pas toujours suffisamment de personnel pour servir chaque personne traversant la sécurité à chaque emplacement. Cela ne signifie pas que nous n'avons pas prévu assez de guichets, mais qu'un incident survenu dans notre datacenter nous empêche de répondre à tout le monde.
C'est pourquoi nous avons créé Traffic Manager : un outil qui équilibre l'offre et la demande dans tout notre réseau global. Cet article de blog concerne Traffic Manager : ce qui a motivé sa création, comment nous l'avons créé et ce qu'il permet aujourd'hui.
Le monde avant Traffic Manager
Les tâches réalisées aujourd'hui par Traffic Manager étaient auparavant effectuées manuellement par les ingénieurs réseau : notre réseau fonctionnait normalement jusqu'à ce qu'il se produise un événement dont les répercussions affectaient le trafic utilisateur au niveau d'un datacenter particulier.
Lorsqu'il se produisait de tels événements, les requêtes utilisateur commençaient à échouer avec des erreurs 499 ou 500 par manque de machines en nombre suffisant pour assumer la charge de requêtes de nos utilisateurs. Cela déclenchait une page pour nos ingénieurs réseau, qui allaient ensuite supprimer certains itinéraires Anycast pour ce datacenter. Résultat : ces préfixes n'étant plus annoncés dans le datacenter concerné, le trafic des utilisateurs était détourné vers un autre datacenter. C'est schématiquement ainsi que fonctionne Anycast : le trafic des utilisateurs est attiré vers le datacenter le plus proche affichant le préfixe auquel l'utilisateur tente de se connecter, conformément aux instructions du Border Gateway Protocol. Pour une présentation de ce qu'est Anycast, consultez cet article de référence.
Selon la gravité du problème, les ingénieurs supprimaient certains, voire tous les itinéraires à destination d'un datacenter. Une fois que le datacenter était à nouveau en mesure d'absorber tout le trafic, les ingénieurs rétablissaient les itinéraires et le trafic pouvait retourner naturellement vers le datacenter.
Vous l'aurez deviné, il s'agissait d'une tâche délicate pour nos ingénieurs réseau et à laquelle ils devaient procéder à chaque fois qu'une pièce matérielle de notre réseau présentait une défaillance. Cela n'a pas évolué.
N'envoyez jamais un humain faire le travail d'une machine
Mais notre équipe d'opérateurs réseau n'était pas la seule à supporter le fardeau de ces tâches manuelles. L'expérience était également peu satisfaisante pour nos clients ; nos ingénieurs devaient prendre le temps de procéder à un diagnostic et de réorienter le trafic. Pour résoudre ces deux problèmes, nous souhaitions mettre au point un service permettant de réagir immédiatement et automatiquement lorsque des utilisateurs ne parviennent pas à atteindre un datacenter Cloudflare et de réorienter les itinéraires à destination du datacenter jusqu'à ce que le problème soit réglé pour les utilisateurs. Une fois que le service aurait reçu les notifications indiquant que le datacenter en question pouvait absorber le trafic, il pourrait rétablir le trafic et reconnecter le datacenter. Ce service s'appelle Traffic Manager, car sa tâche, comme son nom l'indique, consiste à gérer le trafic entrant dans le réseau Cloudflare.
Tenir compte des conséquences secondaires
Lorsqu'un ingénieur réseau supprime un itinéraire vers un routeur, il devine avec le plus de précision possible la direction que vont prendre les requêtes utilisateur, et vérifie que le datacenter de basculement dispose des ressources suffisantes pour gérer la requête ; et si ce n'est pas le cas, il peut adapter les itinéraires avant de supprimer celui conduisant au datacenter initial. Pour être en mesure d'automatiser ce processus, nous avions besoin de passer du monde de l'intuition à celui des données afin de pouvoir prévoir avec précision l'orientation du trafic en cas de réorientation d'un itinéraire, et de transmettre ces informations à Traffic Manager, afin qu'il évite à la situation d'empirer.
Voici Traffic Predictor
Si nous pouvons décider des datacenters qui affichent un itinéraire donné, nous ne pouvons rien sur la proportion du trafic que chaque datacenter reçoit. Chaque fois que nous ajoutons un nouveau datacenter, ou une nouvelle session de peering, la distribution du trafic change, et dans la mesure où nous sommes présents dans plus de 300 villes et 12 500 sessions de peering, il est devenu plutôt difficile pour un humain de suivre ou de prédire l'orientation du trafic au sein de notre réseau. Traffic Manager avait besoin d'un compagnon : Traffic Predictor.
Pour accomplir sa tâche, Traffic Predictor effectue des séries continues de tests dans la réalité afin d'observer où va réellement le trafic. Traffic Predictor repose sur un système de test qui simule la suppression de l'exploitation d'un datacenter et contrôle l'endroit où irait le trafic si le datacenter ne pouvait pas le servir. Pour mieux comprendre la manière dont fonctionne ce système, simulons la suppression d'un sous-ensemble d'un datacenter à Christchurch en Nouvelle-Zélande :
Traffic Predictor commence par obtenir une liste de toutes les adresses IP qui se connectent normalement à Christchurch. Traffic Predictor envoie alors une requête ping à des centaines de milliers d'IP qui ont récemment envoyé une requête à cet emplacement.
Traffic Predictor note si l'adresse IP répond, et si la réponse revient à Christchurch en utilisant une plage d'adresses IP Anycast particulière, spécialement configurée pour Traffic Predictor.
Une fois que Traffic Predictor obtient une liste d'adresses IP qui répondent à Christchurch, il supprime l'itinéraire contenant cette plage particulière, patiente quelques minutes, le temps que la table de routage d'Internet soit mise à jour et recommence le test.
Au lieu d'être acheminées vers Christchurch, les réponses sont envoyées vers des datacenters autour de Christchurch. Traffic Predictor utilise ensuite la connaissance des réponses pour chaque datacenter et enregistre les résultats comme un basculement pour Christchurch.
Cela nous permet de simuler une mise hors ligne de Christchurch sans réellement placer Christchurch hors ligne !
Mais Traffic Predictor ne se limite pas à un seul datacenter. Pour ajouter des couches de résilience supplémentaires, Traffic Predictor calcule même une seconde couche d'indirection : pour chaque scénario de défaillance de datacenter, Traffic Predictor calcule également les scénarios de défaillance et crée des stratégies à adopter en cas de panne de datacenters voisins.
Pour reprendre l'exemple précédent, lorsque Traffic Predictor teste Christchurch, il effectue une série de tests qui mettent hors service plusieurs datacenters voisins, Christchurch compris, afin de calculer différents scénarios de défaillance. Cela permet de garantir que, même s'il se produit quelque chose de catastrophique avec des répercussions sur de multiples datacenters d'une même région, nous sommes toujours en mesure de service le trafic utilisateur. Si vous pensez que ce modèle de données est complexe, vous avez raison : il faut plusieurs jours pour calculer l'ensemble de ces chemins de défaillance et les stratégies associées.
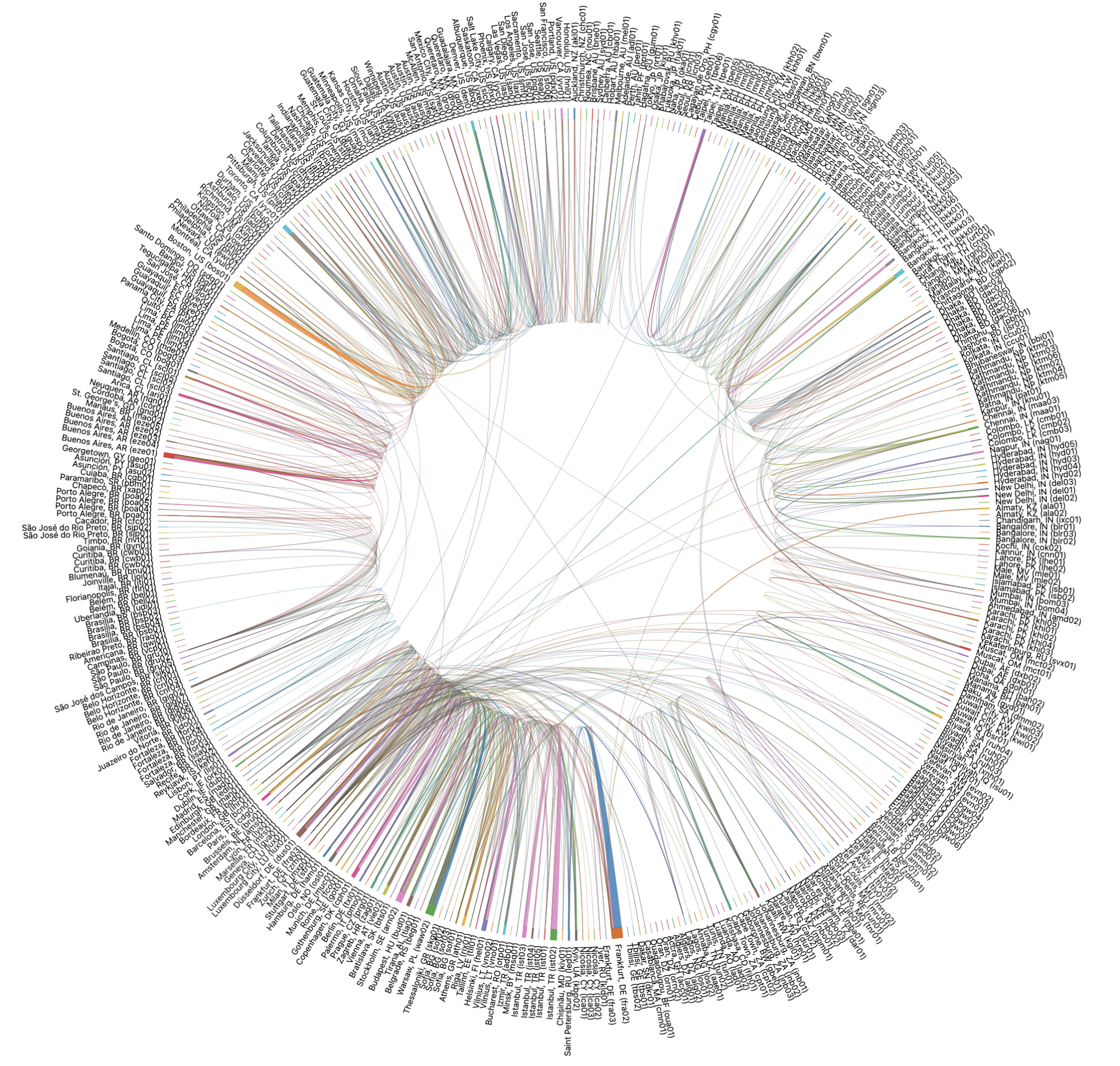
Voilà à quoi ressemblent ces chemins de défaillance et scénarios de basculement pour tous les datacenters du monde entier lorsqu'ils sont représentés visuellement :
Il peut être un peu compliqué pour un humain d'analyser un tel graphique, alors étudions en détail le scénario concernant Christchurch en Nouvelle-Zélande afin de le rendre plus limpide. Lorsque nous observons les chemins de basculement pour Christchurch précisément, voici à quoi ils ressemblent :
Dans ce scénario, nous prédisons que 99,98 % du trafic de Christchurch pourrait être détourné vers Auckland, qui est capable d'absorber l'intégralité du trafic de Christchurch en cas de panne catastrophique.
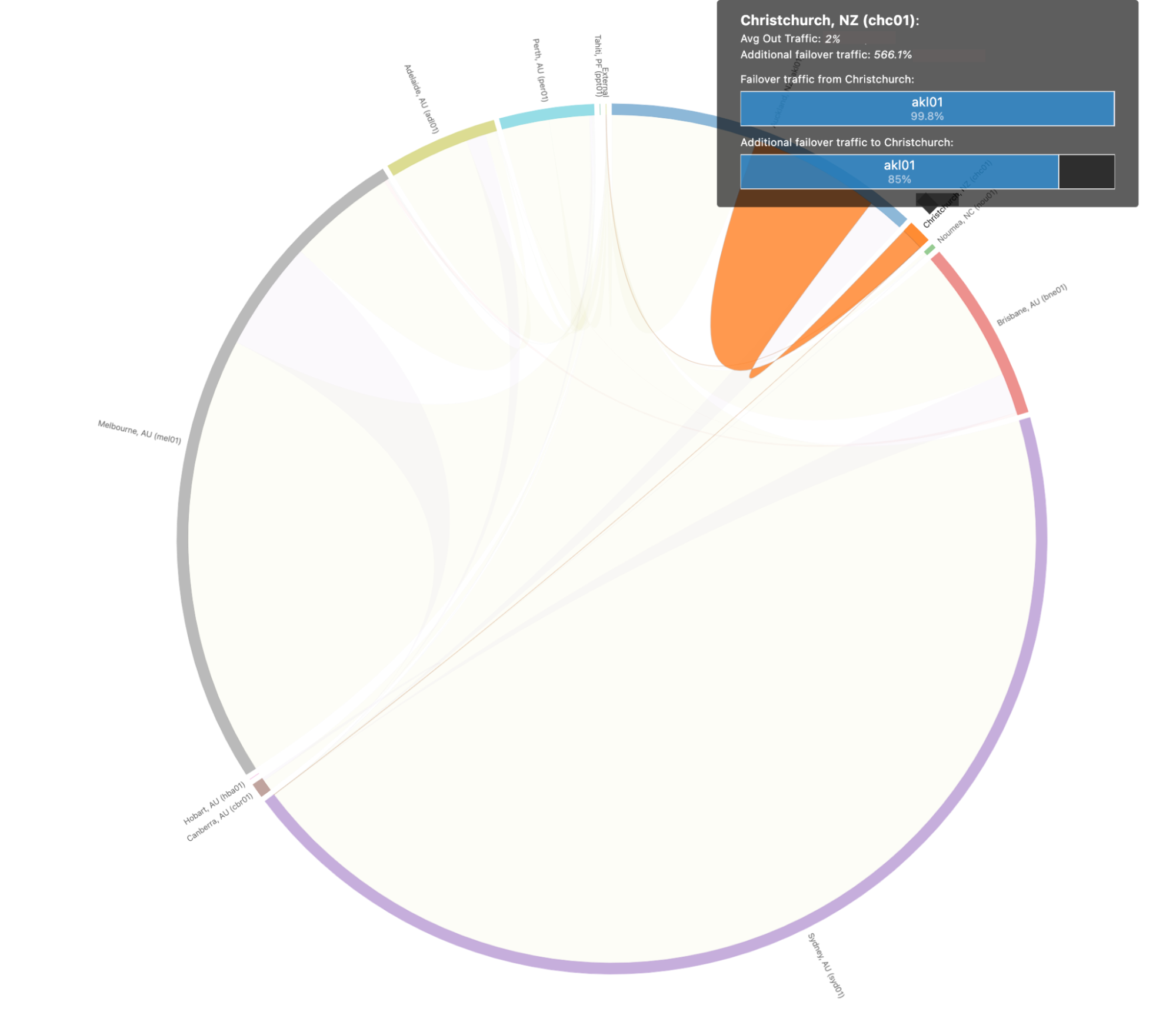
Traffic Predictor nous permet non seulement de voir où irait le trafic en cas de problème, mais il nous permet également de préconfigurer des stratégies Traffic Manager pour déplacer les requêtes hors des datacenters en panne afin de prévenir un scénario cataclysmique dans lequel l'afflux soudain de requêtes provoquerait des défaillances dans un second datacenter si le premier est en difficulté. Avec Traffic Predictor, Traffic Manager ne se contente pas d'éloigner le trafic hors d'un datacenter lorsqu'il est en panne, il réoriente également le trafic hors d'autres datacenters de manière proactive afin de garantir une poursuite du service sans interruption.
Du marteau-pilon au scalpel
Avec Traffic Predictor, Traffic Manager peut afficher et retirer dynamiquement les préfixes tout en garantissant que chaque datacenter est en mesure de gérer tout le trafic. Toutefois, la suppression des préfixes comme moyens de gérer le trafic peut donner lieu parfois à une lourde tâche. Une des raisons tient à ce que le seul moyen que nous avions d'ajouter ou de supprimer du trafic vers un datacenter était d'afficher les itinéraires depuis nos routeurs Internet. Chacun des itinéraires compte des milliers d'adresses IP, et quand bien même un seul est supprimé, cela représente une grande quantité de trafic.
Concrètement, les applications Internet annonceront des préfixes vers l'Internet issus d'un sous-réseau /24 au minimum, mais beaucoup annonceront des préfixes plus grands que cela. L'objectif est généralement d'éviter les fuites de routage ou les détournements d'itinéraire : de nombreux fournisseurs vont en réalité filtrer les itinéraires qui sont plus spécifiques que /24 (pour plus d'informations à ce sujet, consultez ce blog ici). En admettant que Cloudflare associe les propriétés protégées aux adresses IP selon un rapport de 1:1, chaque sous-réseau /24 pourra servir 256 clients, ce qui correspond au nombre d'adresses IP dans un sous-réseau /24. Si chaque adresse IP envoyait une requête par seconde, nous devrions retirer 4 sous-réseaux de /24 d'un datacenter pour transmettre 1 000 requêtes par seconde.
En réalité, Cloudflare met en correspondance une adresse IP unique avec des centaines de milliers de propriétés protégées. Ainsi pour Cloudflare, un /24 peut absorber 3 000 requêtes par seconde, mais si nous devions éloigner 1 000 requêtes par seconde, nous n'aurions pas d'autre choix que de déplacer un seul /24. Et il s'agit là de n'afficher qu'au niveau /24. Si nous affichons des /20, la quantité qu'il est possible de retirer devient moins granulaire : avec une correspondance d'un site web pour une adresse IP, cela représente 4 096 requêtes par seconde pour chaque préfixe, et encore plus si la correspondance site web/adresse IP est de plusieurs pour un.
Certes le retrait des annonces de préfixes a amélioré l'expérience des utilisateurs qui auraient vu une erreur 499 ou 500, toutefois une grande partie des utilisateurs qui ont été déplacés du datacenter initialement prévu n'auraient été en rien touchés par le problème, et ils ont probablement subi un ralentissement, aussi léger soit-il. Ce concept consistant à déplacer plus de trafic que nécessaire est appelé « capacité d'immobilisation » : le datacenter est théoriquement en mesure de servir davantage d'utilisateurs dans une région, mais dans les faits il ne le peut pas en raison de la manière dont Traffic Manager a été créé.
Nous souhaitions améliorer Traffic Manager de sorte qu'il n'éloigne que le minimum absolu d'utilisateurs d'un datacenter concerné par un problème, sans immobiliser davantage de capacité. Pour ce faire, nous devions déplacer des pourcentages de préfixes, ce qui nous a permis de gagner en granularité et de ne déplacer que ce qui devait absolument l'être. Pour y parvenir, nous avons créé une extension de notre équilibreur de charge de la couche 4 Unimog, que nous appelons Plurimog.
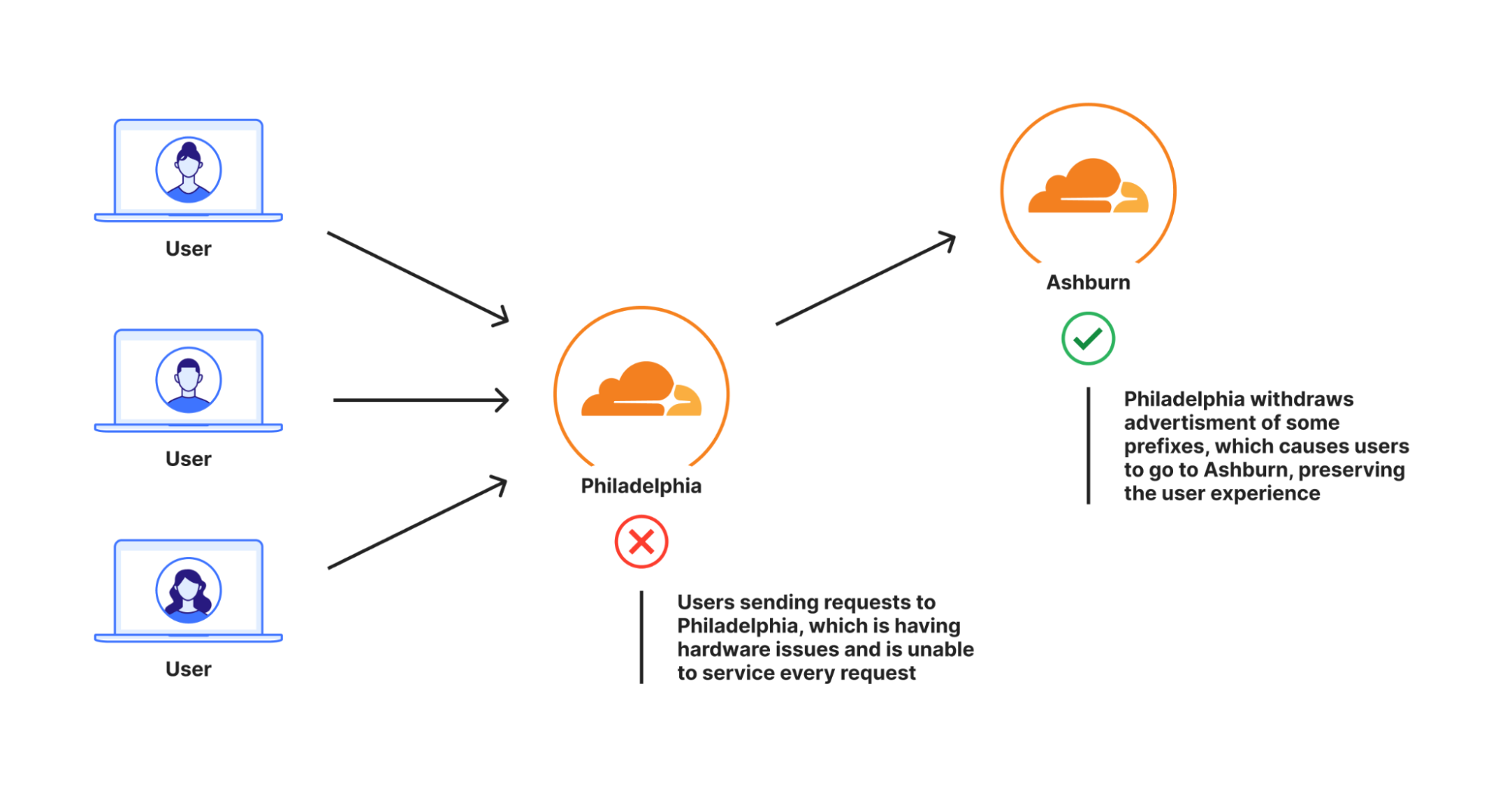
Petit rappel concernant Unimog et l'équilibrage de charge de la couche 4 : chacune de toutes nos machines contient un service qui détermine si une machine peut accepter une requête d'utilisateur. Si la machine le peut, elle envoie la requête à notre pile HTTP qui la traite avant de la renvoyer à l'utilisateur. Dans le cas contraire, la machine envoie la requête à une autre machine du datacenter capable de l'accepter. Ces machines peuvent agir ainsi car elles sont en constante communication pour savoir si elles sont en mesure de servir les requêtes des utilisateurs.
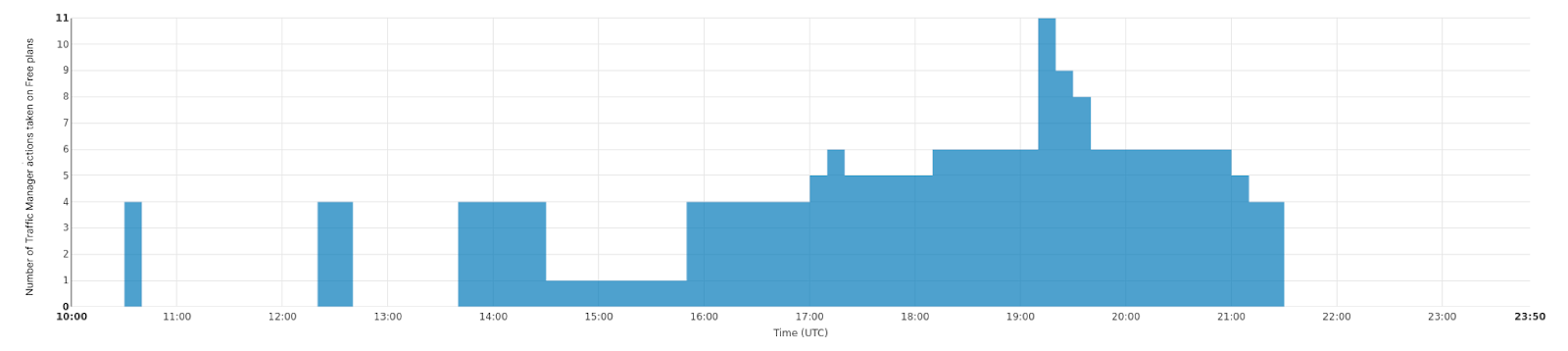
Plurimog procède de la même façon à la différence près qu'au lieu d'une communication entre machines, Plurimog établit un dialogue entre datacenters et points de présence. Si une requête est transmise à Philadelphie et que Philadelphie n'est pas en mesure de l'accepter, Plurimog la transmettra à un autre datacenter qui en est capable, par exemple Ashburn, où la requête est alors déchiffrée et traitée. Plurimog s'exécutant au niveau de la couche 4, il peut envoyer des requêtes TCP ou UDP individuelles vers d'autres emplacements qui permettent une granularité précise : il peut envoyer des pourcentages de trafic vers d'autres datacenters très facilement, ce qui signifie que nous pouvons nous contenter de n'éloigner que le trafic nécessaire pour garantir que chacun sera servi le plus rapidement possible. Observez le fonctionnement de notre datacenter de Francfort, nous y parvenons à déplacer progressivement de plus en plus de trafic afin de gérer les incidents survenus dans nos datacenters. Ce graphique illustre le nombre d'actions entreprises sur le trafic de l'offre gratuite pour l'éloigner de Francfort dans le temps :
Cela étant, même au sein d'un datacenter, nous pouvons acheminer le trafic de façon à éviter qu'il ne quitte le datacenter. Nos datacenters les plus grands, appelés les points de présence Multi-Colo (MCP) contiennent des sections logiques de calcul au sein d'un datacenter qui les distingue des autres. Ces datacenters MCP sont activés par une autre version d'Unimog appelée Duomog, qui permet de déplacer automatiquement le trafic entre les sections logiques de calcul. C'est ce qui rend les datacenters MCP tolérants aux erreurs sans sacrifier les performances pour nos clients, et qui permet à Traffic Manager de fonctionner aussi bien au sein d'un datacenter qu'entre les datacenters.
Lors de l'évaluation des portions de requêtes à déplacer, Traffic Manager procède ainsi :
Traffic Manager identifie la proportion de requêtes qui doivent être éloignées d'un datacenter ou d'une sous-section d'un datacenter afin que toutes les requêtes puissent être servies.
Il calcule ensuite les indicateurs d'espace global pour chaque cible afin de déterminer le nombre de requêtes que chaque datacenter de basculement peut accepter.
Puis il détermine la quantité de trafic à déplacer pour chaque offre, et déplace soit une partie du trafic correspondant à une offre, soit la totalité avec Plurimog/Duomog, jusqu'à ce que nous ayons déplacé suffisamment de trafic. Nous déplaçons d'abord les clients de l'offre gratuite, et quand il n'y en a plus dans le datacenter, nous déplaçons ceux de l'offre Pro, puis, a besoin, les clients de l'offre Business.
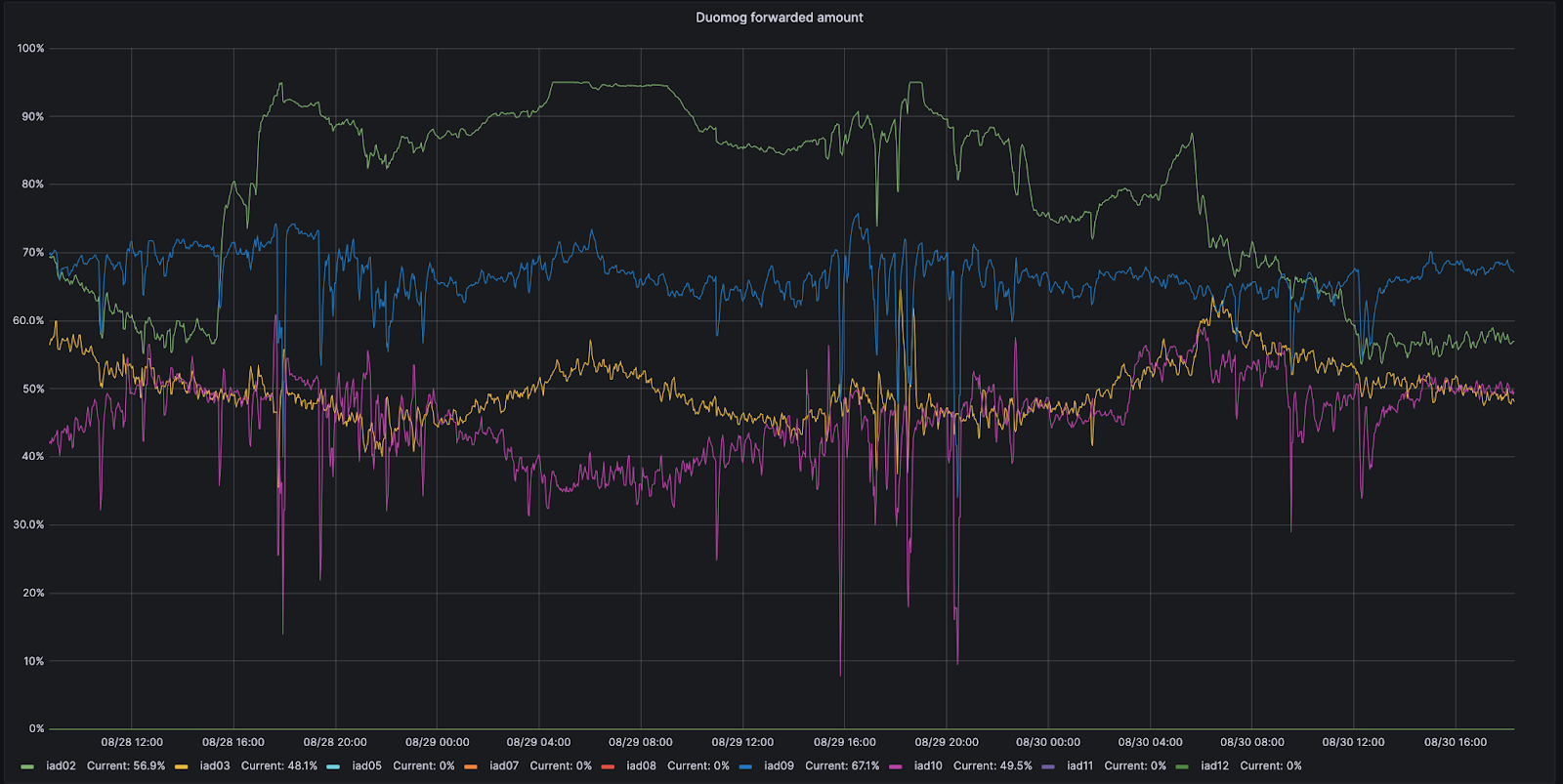
Par exemple, observons ce qui se passe à Ashburn en Virginie, dans l'un de nos MCP. Ashburn compte neuf sous-sections de capacité différentes qui peuvent chacune accepter du trafic. Le 28 août, une de ces sous-sections, l'IAD02, a subi une avarie qui a réduit la quantité de trafic acceptable.
Pendant cette période, Duomog a envoyé plus de trafic de l'IAD02 vers d'autres sous-sections au sein d'Ashburn, toujours en vérifiant qu'Ashburn était toujours en ligne et que les performances ne subissaient pas les répercussions de l'incident. Ensuite, une fois l'IAD02 capable d'accepter le trafic à nouveau, Duomog l'a réintégré automatiquement. Vous pouvez observer ces actions dans le graphique de séries chronologiques ci-dessous, qui présente un suivi du pourcentage de trafic déplacé dans le temps entre les sous-sections de capacité au sein de l'IAD02 (en vert) :
Comment Traffic Manager détermine-t-il la quantité à déplacer ?
Nous avons utilisé des requêtes par seconde dans l'exemple ci-dessus, cependant les requêtes par seconde ne constituent pas un indicateur suffisamment précis lorsqu'il s'agit de déplacer du trafic. En effet, le coût des ressources pour notre service varie d'un client à l'autre ; un site web servi principalement à partir du cache et dont le WAF est désactivé est beaucoup moins coûteux en temps processeur qu'un site dont toutes les règles du WAF sont activées et dont le cache est désactivé. Par conséquent, nous enregistrons le temps consommé pour chaque requête dans le temps processeur. Nous pouvons ensuite additionner le temps processeur dans chaque offre pour déterminer l'utilisation de temps processeur par offre. Nous enregistrons le temps processeur en ms et prenons une valeur par seconde, ce qui donne une unité de millisecondes par seconde.
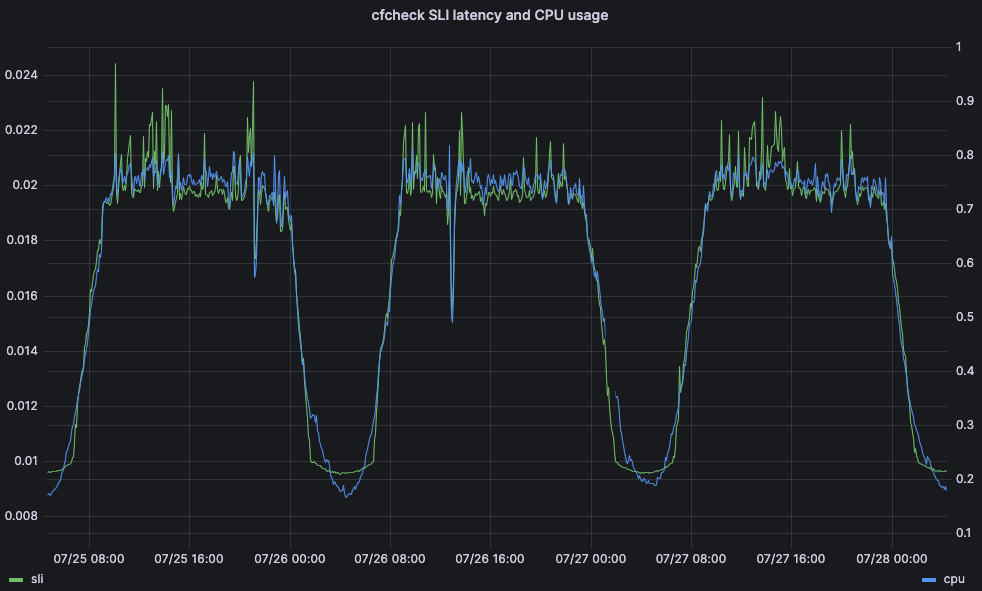
Le temps processeur est un indicateur important en raison de son incidence sur la latence et sur les performances pour le client. Prenons par exemple le temps qu'il faut à une requête eyeball pour traverser complètement les serveurs de première ligne de Cloudflare : c'est ce que nous appelons la latence cfcheck. Si ce chiffre est trop élevé, nos clients le remarqueront et cela nuira à leur expérience. Lorsque la latence cfcheck augmente, cela tient généralement à une utilisation trop importante du temps processeur. Le graphique ci-dessous affiche la latence cfcheck au 95e percentile défini par rapport à l'utilisation du temps processeur sur toutes les machines du même datacenter, et vous pouvez voir la forte corrélation :
Ainsi, le fait que Traffic Manager examine le temps processeur dans un datacenter est un très bon moyen de garantir à nos clients la meilleure expérience possible en étant certain de ne pas engendrer de problème.
Une fois que nous connaissons le temps processeur par offre, nous devons déterminer la part de ce temps processeur à déplacer vers d'autres datacenter. Pour ce faire, nous devons additionner le temps processeur utilisé parmi tous les serveurs afin d'obtenir le temps processeur utilisé dans l'ensemble du datacenter. Si une proportion de serveurs du datacenter tombe en panne, que ce soit en raison d'une défaillance d'un dispositif réseau, d'une coupure d'électricité ou de toute autre raison, les requêtes qui étaient dirigées vers ces serveurs sont automatiquement réorientées ailleurs au sein du datacenter par Duomog. L'utilisation globale de temps processeur du datacenter augmente à mesure que le nombre de serveurs diminue. Traffic Manager compte trois seuils pour chaque datacenter ; le seuil maximal, le seuil cible et le seuil acceptable :
Maximum : niveau de temps processeur à partir duquel les performances commencent à se dégrader et où Traffic Manager se met en action
Cible : niveau auquel Traffic Manager tente de réduire l'utilisation de temps processeur pour rétablir un service optimal pour les utilisateurs
Acceptable : niveau en dessous duquel un datacenter peut recevoir des requêtes transmises depuis un autre datacenter ou inverser des déplacements actifs
Lorsqu'un datacenter dépasse le seuil maximal, Traffic Manager calcule le rapport entre le temps processeur total de toutes les offres et l'utilisation actuelle de ce temps, puis l'applique à l'utilisation cible du temps processeur pour déterminer ce dernier. Ce faisant, nous pouvons comparer un datacenter de 100 serveurs à un datacenter de 10 serveurs, sans nous préoccuper du nombre de serveurs dans chaque datacenter. Cela suppose que la charge augmente de façon linéaire, ce qui est suffisamment proche de la réalité pour que l'hypothèse convienne à nos besoins.
Le rapport cible est équivalent au rapport actuel :
Ainsi :
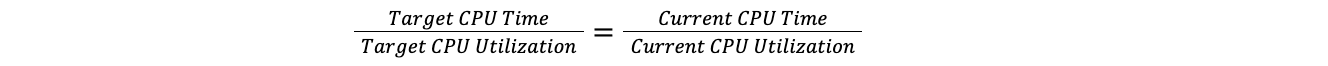
En soustrayant le temps processeur cible du temps processeur actuel, on obtient le temps processeur à déplacer :

Par exemple, si l'utilisation actuelle du temps processeur est de 90 % pour un datacenter, la cible est de 85 % et le temps processeur toutes offres confondues est de 18 000, cela donne :

Cela signifie que Traffic Manager doit déplacer 1 000 de temps processeur :
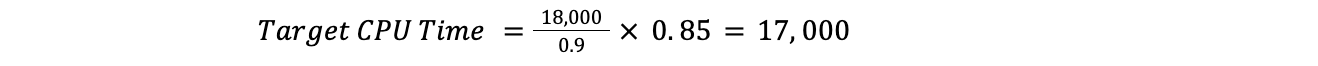
Maintenant que nous connaissons le temps processeur total à déplacer, nous pouvons parcourir les offres, jusqu'à ce que le temps à déplacer soit atteint.
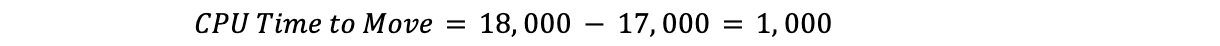
Qu'est-ce que le seuil maximal ?
Nous avons souvent été confrontés au problème de la détermination du moment à partir duquel Traffic Manager devait commencer à agir dans un datacenter ; quel indicateur devait-il surveiller, et quel était le niveau acceptable ?
Comme il a été mentionné précédemment, les exigences sont différentes pour les chaque service en ce qui concerne l'utilisation du temps processeur et dans de nombreux cas, les datacenters présentent un schéma d'utilisation très différent.
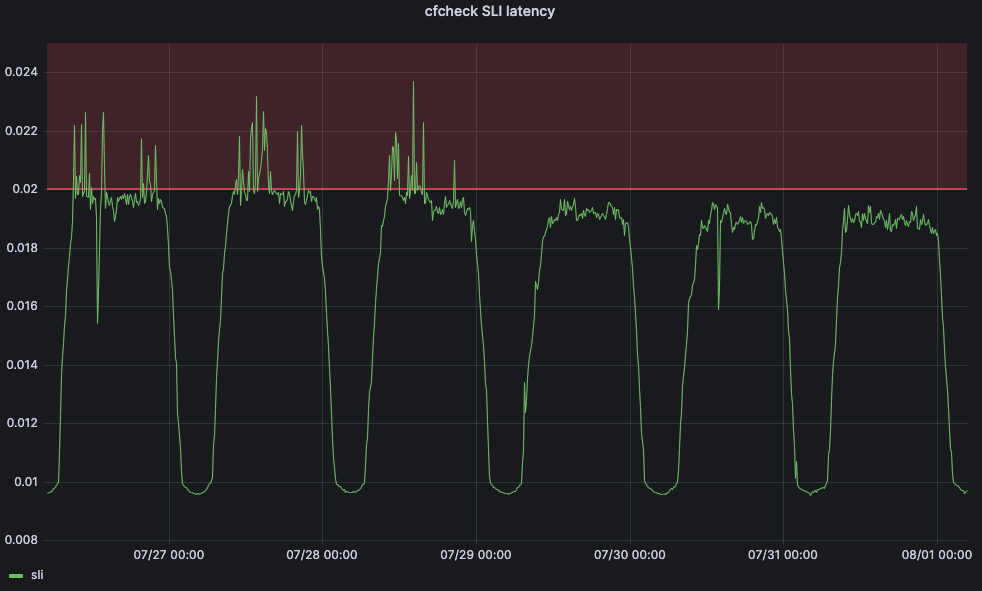
Pour résoudre ce problème, nous avons eu recours à l'apprentissage automatique. Nous avons créé un service qui adaptera automatiquement les seuils maximaux pour chaque datacenter en fonction d'indicateurs liés aux clients. Pour notre principal indicateur de niveau de service (SLI), nous avons décidé d'utiliser l'indicateur de latence cfcheck présenté dans un précédent paragraphe.
Il nous a toutefois également fallu définir un objectif de niveau de service (SLO) afin que notre application d'apprentissage automatique puisse adapter le seuil. Nous avons défini le SLO à 20 ms. Si l'on compare notre SLO à notre SLI, notre latence cfcheck au 95e percentile ne doit jamais dépasser 20 ms et si c'est le cas, nous devons faire quelque chose. Le graphique ci-dessous illustre la latence cfcheck au 95e percentile dans le temps, et les clients commencent à se plaindre lorsque la latence arrive dans la zone rouge :
Si l'expérience client est insatisfaisante lors d'une utilisation trop intensive du temps processeur, le seuil maximal de Traffic Manager a pour objectif de garantir des performances intactes pour le client en permettant de lancer la redirection du trafic avant que les performances ne commencent à se dégrader. À intervalles programmés, le service Traffic Manager récupère un certain nombre d'indicateurs pour chaque datacenter et applique une série d'algorithmes d'apprentissage automatique. Après avoir remédié aux anomalies, nous procédons à un simple ajustement de courbe quadratique et nous sommes actuellement en phase de test d'un algorithme de régression linéaire.
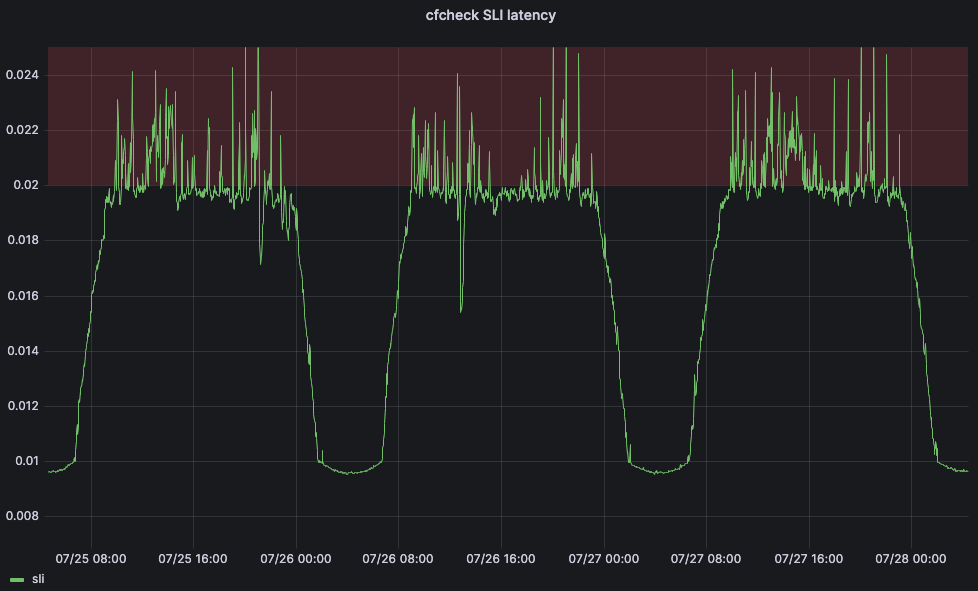
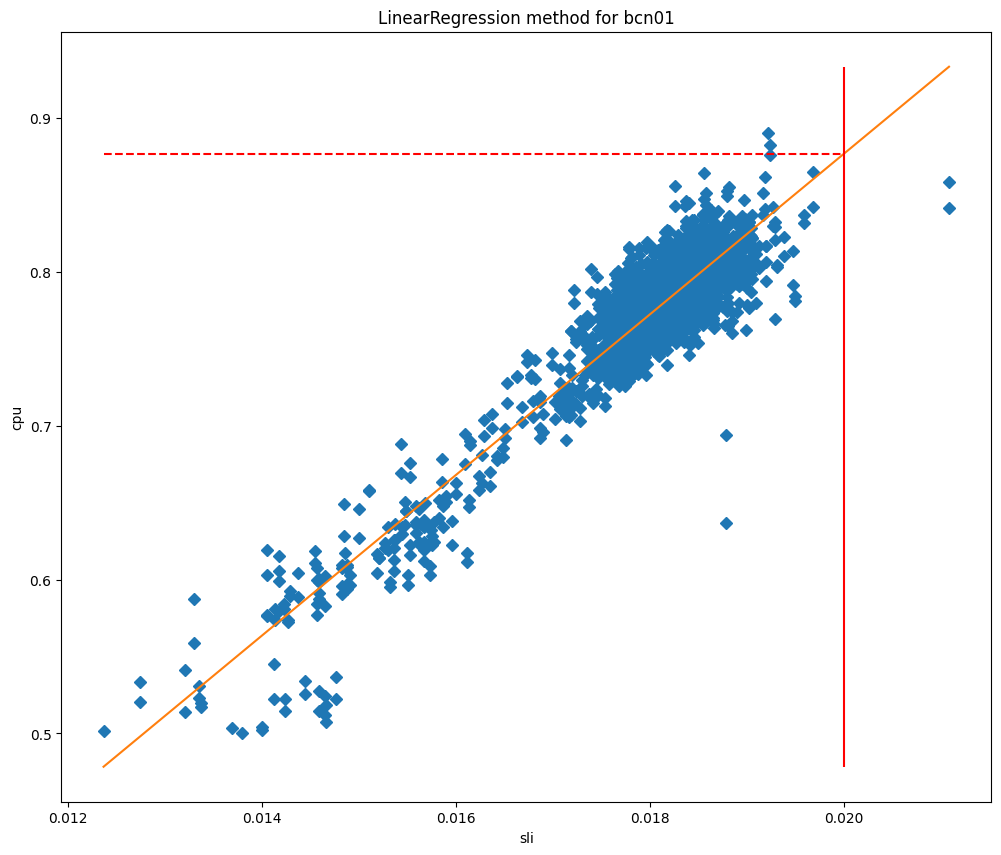
Une fois les modèles ajustés, nous pouvons les utiliser pour prédire l'utilisation du temps processeur lorsque le SLI est égal à notre SLO, puis nous en faisons notre seuil maximal. En comparant les valeurs du temps processeur à celles du SLI, il est facile de comprendre pourquoi ces méthodes fonctionnent si bien pour nos datacenters, comme vous pouvez le constater avec le cas de Barcelone dans les graphiques ci-dessous, qui sont comparés à l'ajustement de la courbe et à l'ajustement de la régression linéaire, respectivement.
Dans ces graphiques, la ligne verticale correspond au SLO et l'intersection de cette ligne avec le modèle ajusté représente la valeur qui sera celle du seuil maximal. Le modèle s'est avéré très précis, et nous sommes en mesure de réduire de manière significative les écarts de SLO. Observons ce qui s'est passé lorsque nous avons commencé à déployer ce serveur à Lisbonne :
Avant le changement, la latence chcheck affichait constamment des pics, mais Traffic Manager ne lançait aucune action car le seuil maximal était statique. Mais après le 29 juillet, nous constatons que la latence cfcheck n'a jamais atteint le SLO parce que nous mesurons constamment afin de garantir que les augmentations du temps processeur n'aient jamais d'incidence pour les clients.
Où envoyer le trafic ?
Maintenant que nous avons notre seuil maximal, nous devons établir le troisième seuil d'utilisation du temps processeur, celui qui n'est pas utilisé pour calculer la quantité de trafic à déplacer, à savoir le seuil acceptable. Lorsqu'un datacenter se trouve sous ce seuil, il dispose d'une capacité inutilisée qui, tant qu'elle ne transmet pas elle-même le trafic, est mise à disposition d'autres datacenters qui peuvent l'utiliser en cas de besoin. Pour déterminer la quantité que chaque datacenter est en mesure de recevoir, nous appliquons la même méthode que celle présentée ci-dessus, en remplaçant le qualificatif cible par acceptable :
Ainsi :
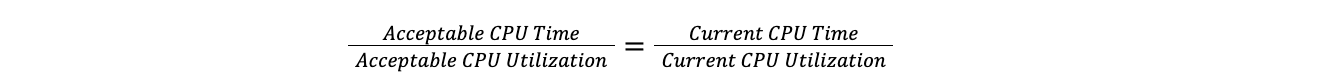
En soustrayant le temps processeur actuel du temps processeur acceptable, on obtient la quantité de temps processeur qu'un datacenter peut accepter :

Pour savoir où envoyer le trafic, Traffic Manager cherche le temps processeur disponible dans tous les datacenters, puis il les classe en fonction de la latence depuis le datacenter qui a besoin de déplacer du trafic. Il passe dans chaque datacenter, en utilisant toute la capacité disponible d'après les seuils maximaux avant de passer au suivant. Lorsqu'il s'agit de déterminer les offres à déplacer, nous allons de l'offre la moins prioritaire à la plus prioritaire, mais lorsqu'il s'agit de déterminer où les envoyer, nous allons dans la direction opposée.
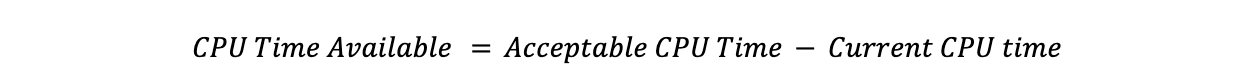
Pour mieux illustrer le processus, prenons un exemple :
Nous avons besoin de déplacer un temps processeur de 1 000 à partir du datacenter A, et l'utilisation se répartit comme suit entre les offres : Gratuit : 500 ms/s, Pro : 400 ms/s, Business : 200ms/s, Enterprise : 1000ms/s.
Nous devons déplacer 100 % du trafic de l'offre gratuite (500 ms/s), 100 % de l'offre Pro (400 ms/s), 50 % de l'offre Business (100 ms/s) et 0 % de l'offre Enterprise.
Le temps processeur disponible dans les datacenter voisins est le suivant : B : 300 ms/s, C : 300 ms/s, D : 1 000 ms/s.
Avec les latences suivantes : A-B : 100 ms, A-C: 110 ms, A-D: 120 ms.
En commençant par la latence la plus faible et l'offre à la priorité la plus élevée nécessitant une action, nous pourrions déplacer tout le temps processeur de l'offre Business vers le datacenter B et la moitié du trafic de l'offre Pro. Ensuite, nous passerions au datacenter C et pourrions déplacer le reste de l'offre Pro et 20 % de l'offre gratuite. Le reste de l'offre gratuite pourrait alors être transféré vers le datacenter D. Voici ce que cela donnerait : Business : 50 % → B, Pro : 50 % → B, 50 % → C, Gratuite : 20 % → C, 80 % → D.
Inverser les actions
De la même façon que Traffic Manager cherche toujours à empêcher les datacenters de dépasser le seuil, il cherche également à rétablir tout le trafic transféré dans un datacenter qui transfère activement le trafic.
Nous avons vu précédemment comment Traffic Manager détermine la quantité de trafic qu'un datacenter peut recevoir d'un autre datacenter ; c'est ce qu'il appelle le temps processeur disponible. Lorsqu'un déplacement est actif, nous utilisons ce temps processeur disponible pour rétablir le trafic vers le datacenter ; nous donnons toujours la priorité à l'annulation d'un déplacement actif plutôt qu'à l'acceptation de trafic en provenance d'un autre datacenter.
Lorsque vous réunissez tous ces éléments, vous obtenez un système qui mesure en permanence les indicateurs d'intégrité du système et du client pour chaque datacenter et qui répartit le trafic de façon à garantir un service pour chaque requête en fonction de l'état actuel de notre réseau. Si nous reportons tous ces déplacements entre datacenters sur une carte, nous obtenons quelque chose comme cette illustration de tous les déplacements organisés par Traffic Manager pour une période d'une heure. Cette carte ne montre pas l'ensemble de notre déploiement de datacenter, mais elle montre les datacenters qui envoient ou reçoivent du trafic pendant cette période :
Les datacenter affichés en rouge ou jaune ont une charge excessive et réorientent du trafic vers d'autres datacenters jusqu'à ce qu'ils deviennent verts, c'est-à-dire lorsque tous les indicateurs affichent des valeurs d'intégrité. La taille des cercles indique la quantité de requêtes réorientées depuis ou vers ces datacenters. L'orientation du trafic est indiquée par le déplacement des lignes. Ces opérations sont difficiles à visualiser à l'échelle mondiale ; zoomons sur les États-Unis pour les observer pour la même période :
Ici, vous observez que Toronto, Détroit, New York et Kansas City ne sont pas en mesure de servir certaines requêtes en raison d'avaries matérielles. Ces requêtes seront donc envoyées à Dallas, Chicago et Ashburn jusqu'à ce que l'équilibre soit rétabli pour les utilisateurs et les datacenters. Une fois que les datacenters tels que celui de Détroit sont en mesure de servir toutes les requêtes qu'ils reçoivent sans qu'il soit nécessaire d'éloigner du trafic, le transfert de requêtes vers Chicago va progressivement s'arrêter, jusqu'à ce que l'anomalie touchant le datacenter soit entièrement résolue et que plus rien ne soit transféré. Pendant tout ce temps, les utilisateurs finaux sont en ligne et ne subissent aucune répercussion en lien avec le problème matériel survenu à Détroit ou à tout autre endroit qui envoie du trafic.
Si le réseau est heureux, les produits le sont aussi
Traffic Manager étant partie prenante de l'expérience l'utilisateur, il est un composant fondamental du réseau Cloudflare : il maintient nos produits en ligne et en garantit une rapidité et une fiabilité optimale. Il s'agit de notre équilibreur de charge en temps réel, qui contribue à la rapidité de nos produits en ne transférant que le strict nécessaire du trafic associé à des datacenters qui connaissent des difficultés. Dans la mesure où une quantité moindre de trafic est déplacée, nos produits et services restent rapides.
Toutefois, Traffic Manager peut également contribuer au maintien en ligne de nos produits et à leur fiabilité dans la mesure où il leur permet de prédire où il risque de se produire des problèmes de fiabilité ainsi que de déplacer préventivement les produits ailleurs. Par exemple, l'isolement de navigateur fonctionne directement avec Traffic Manager afin de garantir la disponibilité du produit. Lorsque vous vous connectez à un datacenter Cloudflare pour créer une instance de navigateur hébergée, la fonction d'isolement de navigateur commence par demander à Traffic Manager si le datacenter dispose d'une capacité suffisante pour exécuter l'instance en local, auquel cas l'instance est créée sur-le-champ. Si la capacité disponible n'est pas suffisante, Traffic Manager indique à la fonction d'isolement de navigateur le centre de données le plus proche disposant d'une capacité disponible suffisante, ce qui permet à l'isolement de navigateur de fournir la meilleure expérience utilisateur possible.
Si le réseau est heureux, les utilisateurs le sont aussi
Chez Cloudflare, nous assurons le fonctionnement de cet énorme réseau pour mettre en service l'ensemble de nos différents produits et scénarios client. Nous avons créé ce réseau en ayant la résilience à l'esprit : en plus de prévoir des emplacements MCP conçus pour amoindrir les conséquences d'une défaillance unique, nous réorientons constamment le trafic sur notre réseau en réponse à des problèmes internes et externes.
Mais c'est notre problème, pas le vôtre.
De la même manière, lorsque ces problèmes devaient être résolus par des humains, ce sont les clients et les utilisateurs finaux qui en subissaient les répercussions. Pour vous permettre d'être toujours en ligne, nous avons mis au point un système intelligent qui détecte nos avaries matérielles et équilibre de manière préventive le trafic sur notre réseau afin de garantir son maintien en ligne et sa rapidité maximale. Ce système fonctionne plus rapidement que n'importe quelle personne ; non seulement il permet à nos ingénieurs réseau d'avoir le temps de dormir la nuit, mais il offre également une expérience de meilleure qualité et plus rapide à l'ensemble de nos clients.
Enfin : si vous êtes attiré par ce type de défis à relever dans le domaine de l'ingénierie, n'hésitez pas à consultez les postes à pouvoir de l'équipe Traffic Engineering dans la section Carrières du site de Cloudflare !