



Imagina que estás en un aeropuerto y pasas por un control de seguridad. Hay un montón de agentes que escanean tu tarjeta de embarque y tu pasaporte y te mandan a tu puerta de embarque. De repente, algunos de los agentes se toman un descanso. Puede que haya una gotera en el techo del puesto de control, o puede que salgan varios vuelos a las 18:00 horas y lleguen varios pasajeros a la vez. En cualquier caso, este desequilibrio entre la oferta y la demanda localizadas puede provocar colas enormes y crear malestar entre los pasajeros, que solo quieren pasar la cola para coger su vuelo. ¿Cómo lo gestionan los aeropuertos?
Puede que algunos aeropuertos no hagan nada y se limiten a dejarte esperar en una cola más larga, puede que otros ofrezcan accesos rápidos a través de los puntos de control, previo pago de un importe, pero la mayoría de los aeropuertos te dirán que vayas a otro control de seguridad un poco más alejado para asegurarse de que puedes llegar a la puerta de embarque lo más rápido posible. Incluso pueden tener pantallas que te informen sobre el tiempo de espera en cada cola, para que decidas más fácilmente cuando intentes pasar.
En Cloudflare tenemos el mismo problema. Tenemos centros de datos en más de 300 ciudades de todo el mundo que reciben el tráfico de los usuarios finales que utilizan todos nuestros paquetes de productos. En un mundo ideal, siempre tenemos suficientes ordenadores y ancho de banda para atender a todo el mundo en su ubicación más próxima, pero no siempre es así. A veces desconectamos un centro de datos para llevar a cabo trabajos de mantenimiento, y otras se cae una conexión a un centro de datos, o falla algún equipo, entre otros incidentes posibles. Cuando ocurre, puede que no tengamos suficientes manos para atender a todas las personas que pasan por seguridad en cada lugar, y no es porque no tengamos suficientes puestos, sino porque ha ocurrido algo en nuestro centro de datos que nos impide atender a todo el mundo.
Por eso hemos desarrollado Traffic Manager, una herramienta que equilibra la oferta y la demanda en toda nuestra red global. En este blog analizaremos sus orígenes, cómo lo hemos desarrollado y qué hace ahora.
El mundo antes de Traffic Manager
El trabajo que ahora realiza Traffic Manager solía ser un proceso manual llevado a cabo por ingenieros de red. Nuestra red funcionaba con normalidad hasta que ocurría algo que hacía que el tráfico de usuarios se viera afectado en un centro de datos concreto.
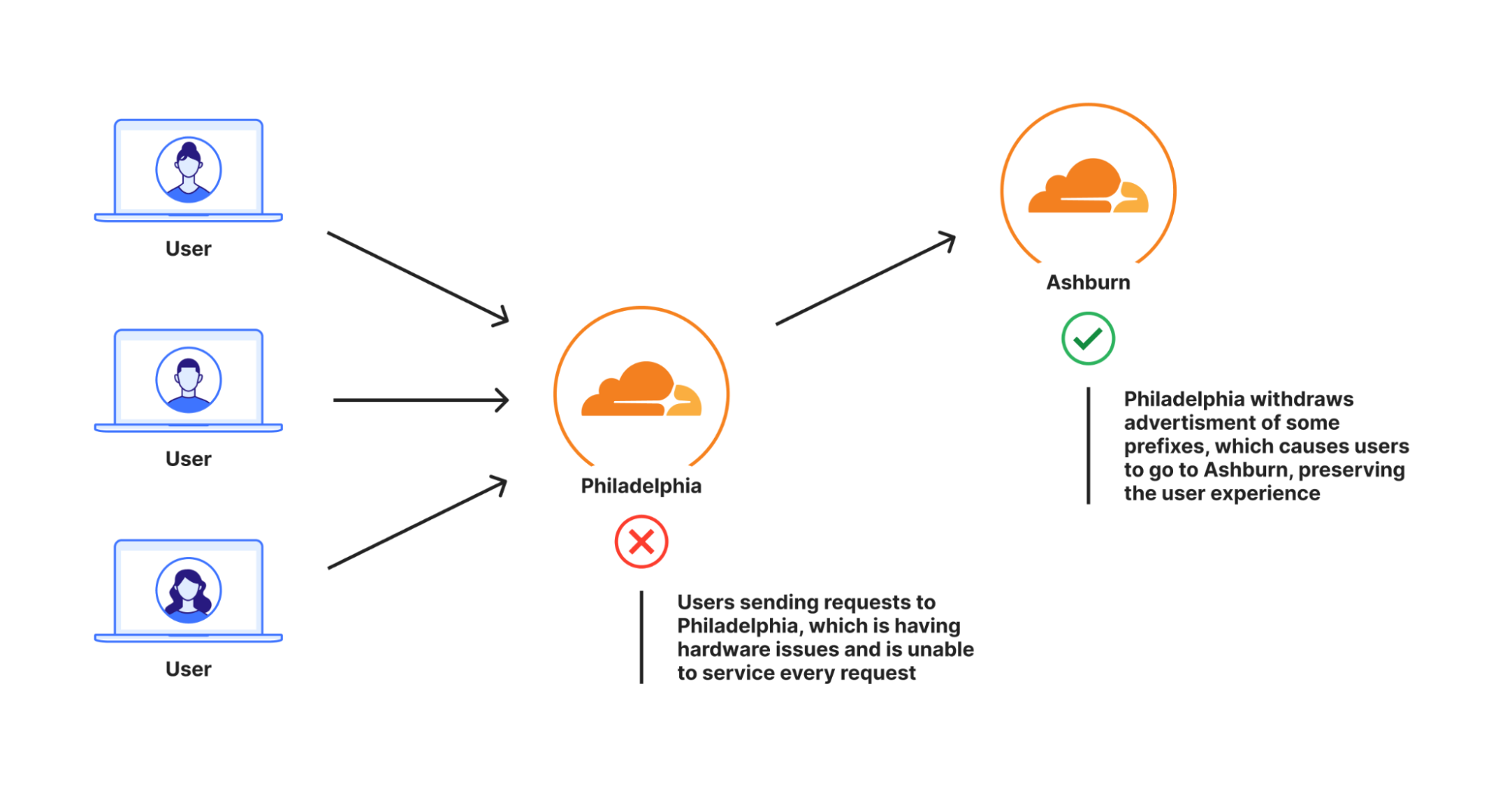
Cuando sucedían estos incidentes, las solicitudes de los usuarios empezaban a recibir errores HTTP 499 o 500 porque no había suficientes máquinas para gestionar la carga de solicitudes de nuestros usuarios. Estos errores mostraban una página a nuestros ingenieros de red, quienes se encargaban de eliminar algunas rutas Anycast para ese centro de datos. El resultado final era dejar de anunciar esos prefijos en el centro de datos afectado y desviar el tráfico de los usuarios a otro centro de datos. Así es como funciona fundamentalmente Anycast. El tráfico del usuario se dirige al centro de datos más cercano que anuncie el prefijo al que el usuario se intenta conectar, según determine el protocolo de puerta de enlace fronteriza (BGP). Para saber qué es Anycast, consulta este artículo de referencia.
Dependiendo de la gravedad del problema, los ingenieros eliminaban algunas o incluso todas las rutas de un centro de datos. Cuando el centro de datos recuperaba la capacidad de absorber todo el tráfico, los ingenieros volvían a colocar las rutas y el tráfico regresaba de forma natural al centro de datos.
Como puedes suponer, cada fallo del hardware de nuestra red era una complicación para nuestros ingenieros de red. No escalaba.
Nunca dejes que un humano haga el trabajo de una máquina
Sin embargo, el trabajo manual no solo era una carga para nuestro equipo de operaciones de red, también empobrecía la experiencia de nuestros clientes. Nuestros ingenieros tenían que dedicar tiempo a diagnosticar y redirigir el tráfico. Para resolver estos dos problemas, queríamos crear un servicio que detectara de forma inmediata y automática la incapacidad de los usuarios para llegar a un centro de datos de Cloudflare, y anulara las rutas del centro de datos hasta que los usuarios dejaran de tener problemas. Una vez que el servicio recibiera notificaciones de que el centro de datos afectado podía absorber el tráfico, se reactivarían las rutas y se reconectaría ese centro de datos. Este servicio se llama Traffic Manager porque su trabajo (como puedes suponer) es gestionar el tráfico que entra en la red de Cloudflare.
Respuesta de las consecuencias de segundo grado
Cuando un ingeniero de red elimina una ruta de un enrutador, puede hacer una estimación lo más aproximada posible de cuál será la ubicación donde se trasladarán las solicitudes de los usuarios, e intentar asegurarse de que el centro de datos de conmutación por error tiene recursos suficientes para gestionar las solicitudes. Si no es así, pueden configurar las rutas como corresponda antes de eliminar la ruta en el centro de datos inicial. Para poder automatizar este proceso, necesitábamos pasar de la intuición a los datos, es decir, predecir con precisión el lugar dónde iría el tráfico cuando se eliminara una ruta, y transmitir esta información a Traffic Manager, para que pudiera asegurarse de no empeorar la situación.
¡Bienvenido, Traffic Predictor!
Si bien podemos configurar qué centros de datos anuncian una ruta, no podemos influir en la proporción de tráfico que recibe cada centro de datos. Cada vez que añadimos un nuevo centro de datos, o una nueva sesión de emparejamiento, la distribución del tráfico cambia, y como estamos en más de 300 ciudades y 12 500 sesiones de emparejamiento, se ha vuelto bastante difícil para un humano controlar, o predecir, la forma en que el tráfico se moverá por nuestra red. Traffic Manager necesitaba un compañero, Traffic Predictor.
Para hacer su trabajo, Traffic Predictor lleva a cabo una serie de pruebas en el mundo real para ver por dónde se mueve realmente el tráfico. Se basa en un sistema de pruebas que simula la eliminación de un servicio de un centro de datos y mide dónde iría el tráfico si ese centro de datos no estuviera haciendo su trabajo. Para ayudar a comprender cómo funciona este sistema, vamos a simular la retirada de un subconjunto de un centro de datos en Christchurch, Nueva Zelanda:
En primer lugar, Traffic Predictor obtiene una lista de todas las direcciones IP que normalmente se conectan a Christchurch. Traffic Predictor enviará una solicitud de ping a cientos de miles de direcciones IP que hayan realizado recientemente una solicitud allí.
Registrará si la IP responde, y si la respuesta vuelve a Christchurch utilizando un rango especial de la dirección IP asociada a la red Anycast configurado específicamente para Traffic Predictor.
Una vez que Traffic Predictor tiene una lista de direcciones IP que responden a Christchurch, elimina de Christchurch la ruta que contiene ese rango especial, espera unos minutos a que se actualice la tabla de enrutamiento de Internet y vuelve a ejecutar la prueba.
Las respuestas, en lugar de ser enrutadas a Christchurch, se dirigen a centros de datos de los alrededores de Christchurch. A continuación, Traffic Predictor utilizará la información de las respuestas de cada centro de datos y registrará los resultados como la conmutación por error para Christchurch.
Este proceso nos permite simular la desconexión de Christchurch sin desconectarla realmente.
Sin embargo, Traffic Predictor no lo hace solo para un centro de datos concreto. Para añadir capas adicionales de resistencia, Traffic Predictor calcula incluso una segunda capa de enrutamiento indirecto. Para cada escenario de fallo del centro de datos, Traffic Predictor calcula también escenarios de fallo y crea políticas para cuando fallen los centros de datos circundantes.
Siguiendo con nuestro ejemplo anterior, cuando Traffic Predictor pruebe Christchurch, ejecutará una serie de pruebas que interrumpirán varios centros de datos circundantes, incluido Christchurch, para calcular diferentes escenarios de fallo. De esta forma garantizamos que, aunque ocurra algo catastrófico que afecte a varios centros de datos de una región, seguiremos teniendo capacidad para servir el tráfico de los usuarios. Si crees que este modelo de datos es complicado, estás en lo cierto. Se tardan varios días en calcular todas estas rutas de fallo y políticas.
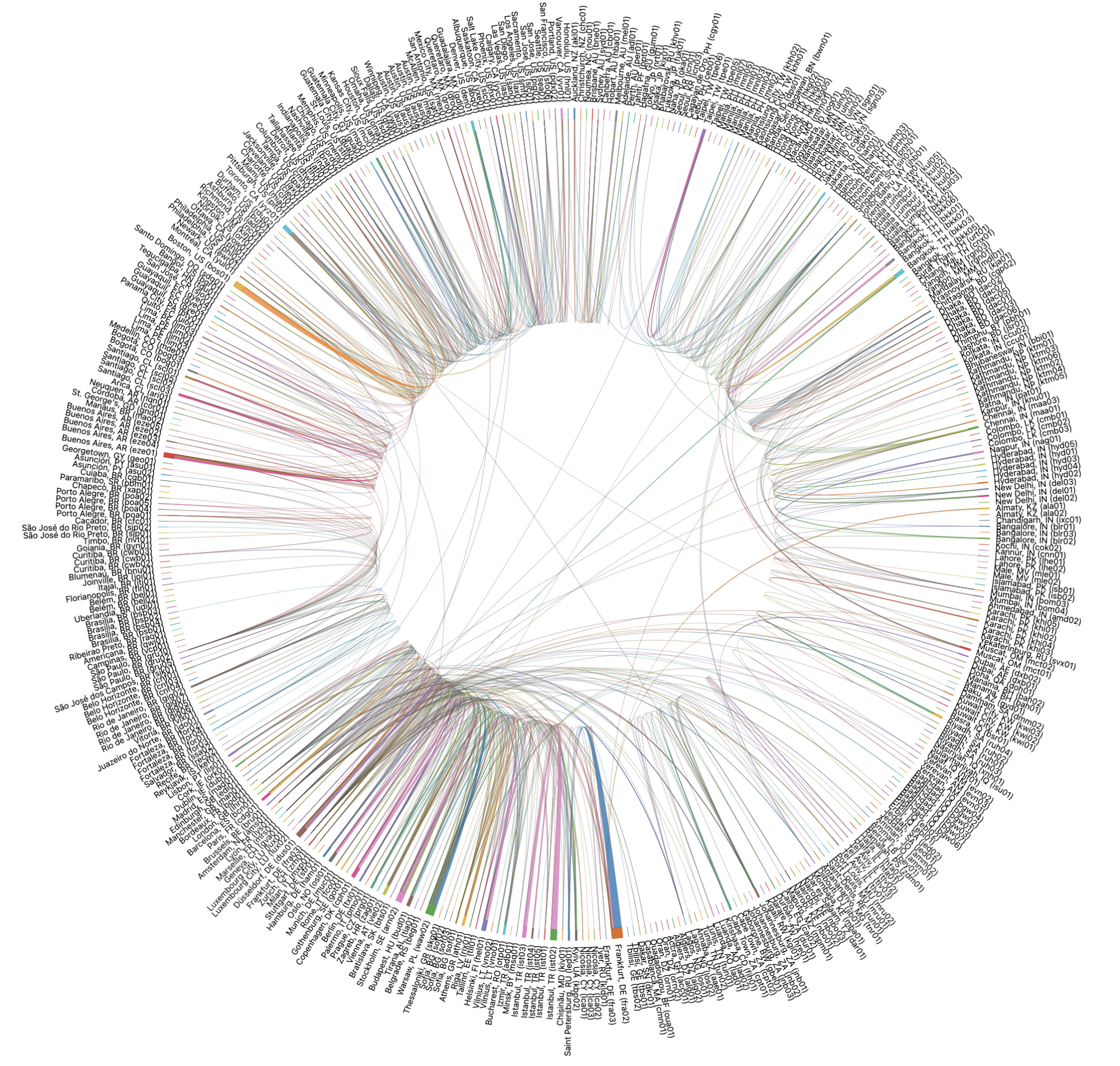
Así es como se ven esas rutas de fallo y escenarios de conmutación por error para todos nuestros centros de datos del mundo cuando se visualizan:
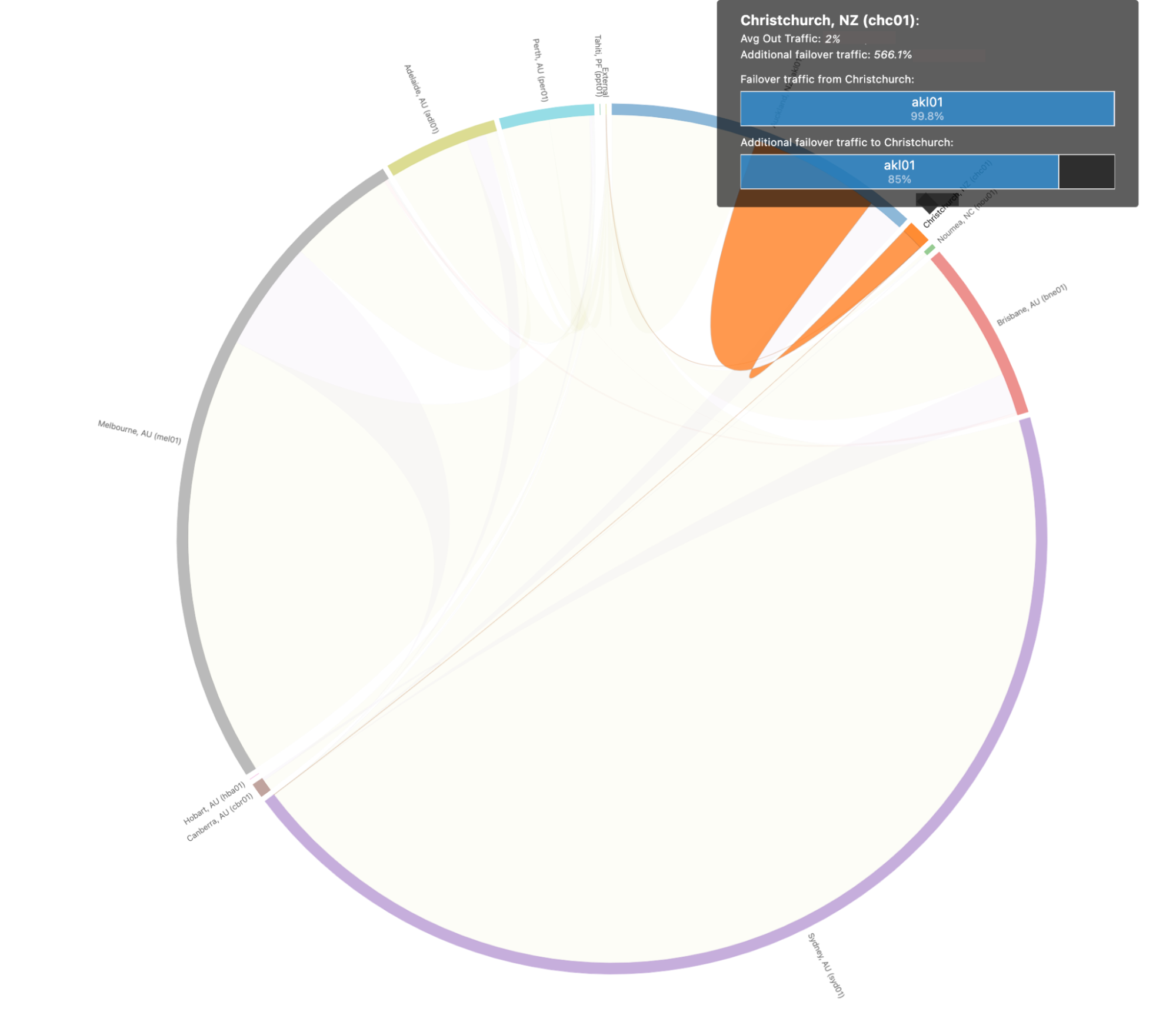
Puede ser un poco complicado de analizar para los humanos, así que vamos a profundizar en el escenario anterior de Christchurch (Nueva Zelanda) para que quede un poco más claro. Cuando echamos un vistazo a las rutas de conmutación por error específicamente para Christchurch, vemos que tienen este aspecto:
En este escenario prevemos que el 99,8 % del tráfico de Christchurch se trasladaría a Auckland, que es capaz de absorber todo el tráfico de Christchurch en caso de una interrupción catastrófica.
Traffic Predictor no solo nos permite ver dónde se desplazará el tráfico si ocurre algo, sino que también nos permite configurar previamente las políticas de Traffic Manager para trasladar las solicitudes fuera de los centros de datos de conmutación por error con el fin de evitar una estampida, en la que la afluencia repentina de solicitudes puede provocar fallos en un segundo centro de datos si el primero tiene problemas. Con Traffic Predictor, Traffic Manager no solo traslada el tráfico de un centro de datos cuando este falla, sino que también desplaza proactivamente el tráfico de otros centros de datos para garantizar la continuidad del servicio sin interrupciones.
De lo complejo a lo sencillo
Con Traffic Predictor, Traffic Manager puede anunciar y retirar prefijos de forma dinámica, garantizando que todos los centros de datos puedan gestionar todo el tráfico. Sin embargo, eliminar prefijos como medio de gestión del tráfico puede resultar a veces un poco brusco. Una de las razones es que la única forma que teníamos de añadir o retirar tráfico a un centro de datos era anunciando rutas desde nuestros enrutadores con conexión a Internet. Cada una de nuestras rutas tiene miles de direcciones IP, por lo que eliminar solo una sigue representando una gran parte del tráfico.
En concreto, las aplicaciones de Internet anunciarán prefijos a Internet desde una subred /24 como mínimo, pero muchas anunciarán prefijos con valores superiores. Esto se hace generalmente para evitar incidentes como fugas o secuestros de rutas. De hecho, muchos proveedores filtrarán las rutas que sean más específicas que una subred /24 (para más información al respecto, consulta nuestro blog aquí). Si suponemos que Cloudflare asigna propiedades protegidas a direcciones IP en una proporción de 1:1, entonces cada subred /24 podría dar servicio a 256 clientes, que es el número de direcciones IP de una subred /24. Si cada dirección IP enviara una solicitud por segundo, tendríamos que mover 4 subredes /24 fuera de un centro de datos si necesitáramos trasladar 1000 solicitudes por segundo.
Pero en realidad, Cloudflare asigna una única dirección IP a cientos de miles de propiedades protegidas. Así que, para Cloudflare, una subred /24 podría recibir 3000 solicitudes por segundo, pero si necesitáramos trasladar fuera 1000 solicitudes por segundo, no tendríamos más remedio que mover un única subred /24 fuera. Y eso solo suponiendo que anunciemos a un nivel /24. Si utilizáramos una subred /20, la cantidad que podemos eliminar sería menos granular. Con una asignación de sitio web a dirección IP de 1:1, serían 4096 solicitudes por segundo para cada prefijo, e incluso más si la asignación de sitio web a dirección IP es de muchos a uno.
Si bien la eliminación de los anuncios de prefijos mejoró la experiencia del cliente para los usuarios que habrían recibido un error HTTP 499 o 500, es posible que una parte significativa de usuarios no se hubiera visto afectada por un problema y, aun así, se habrían alejado del centro de datos al que deberían haber ido, debido a lo cual podrían haber experimentado una ralentización, aunque no de manera significativa. Este concepto de trasladar fuera más tráfico del necesario se denomina "capacidad de desviación": el centro de datos es teóricamente capaz de dar servicio a más usuarios en una región, pero no puede debido a cómo se ha desarrollado Traffic Manager.
Queríamos mejorar Traffic Manager para que solo trasladara la menor cantidad posible de usuarios fuera de un centro de datos que tuviera un problema, sin desviar más capacidad. Para ello, necesitábamos trasladar porcentajes de prefijos, de modo que pudiéramos ser más precisos y mover solo lo que fuera absolutamente necesario. Para solucionarlo, creamos una extensión de nuestro equilibrador de carga de capa 4 Unimog, que llamamos Plurimog.
Repasemos brevemente Unimog y el equilibrio de carga de capa 4. Cada una de nuestras máquinas contiene un servicio que determina si esa máquina puede aceptar una solicitud de un usuario. Si así fuera, envía la solicitud a nuestra pila HTTP, que la procesa antes de devolverla al usuario. Si la máquina no puede aceptar la solicitud, la envía a otra máquina del centro de datos que sí pueda hacerlo. Las máquinas pueden hacer esto porque están en comunicación permanente para saber si pueden atender las solicitudes de los usuarios.
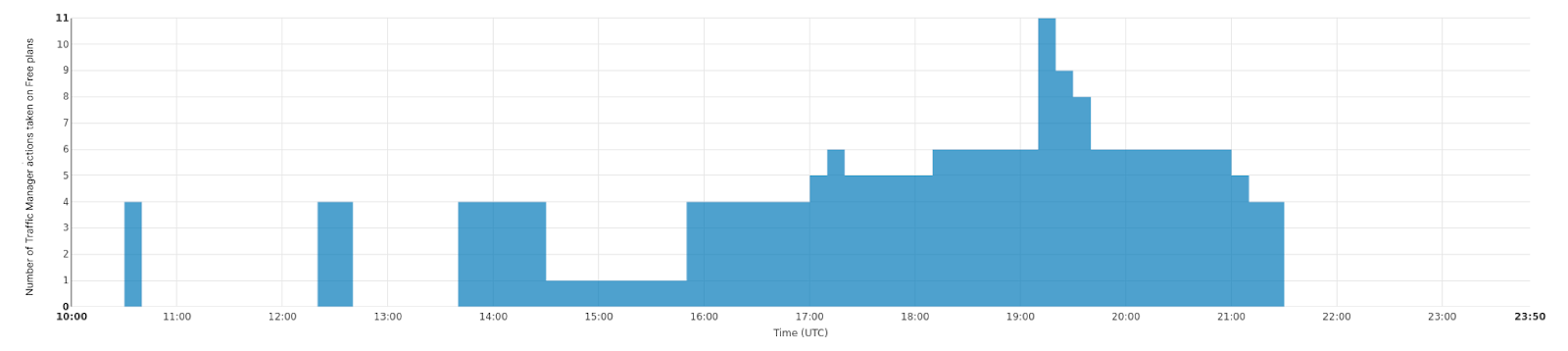
Plurimog hace lo mismo, pero en lugar de la comunicación entre máquinas, Plurimog se comunica con los centros de datos y puntos de presencia. Si una solicitud llega a Filadelfia y Filadelfia no puede aceptarla, Plurimog la reenvía a otro centro de datos que pueda aceptarla, como Ashburn, donde la solicitud se descifra y se procesa. Como Plurimog opera en la capa 4, puede enviar solicitudes TCP o UDP individuales a otros lugares, lo que mejora la precisión. Puede enviar porcentajes de tráfico a otros centros de datos muy fácilmente, lo que significa que solo tenemos que enviar el tráfico suficiente para garantizar que todo el mundo pueda ser atendido lo más rápidamente posible. Comprueba cómo funciona este proceso en nuestro centro de datos de Fráncfort, ya que podemos desviar progresivamente cada vez más tráfico para gestionar problemas en nuestros centros de datos. Este gráfico muestra el número de acciones realizadas sobre el tráfico libre que hacen que se envíe fuera de Fráncfort con el tiempo:
Pero incluso dentro de un centro de datos, podemos enrutar el tráfico para evitar que salga en absoluto del centro de datos. Nuestros grandes centros de datos, llamados puntos de presencia multicolocación (MCP), contienen secciones lógicas de computación dentro de un centro de datos que son distintas entre sí. Estos centros de datos MCP están habilitados con otra versión de Unimog llamada Duomog, que permite trasladar el tráfico entre secciones lógicas de computación de manera automática. De esta manera, los centros de datos MCP funcionan a prueba de fallos sin que el rendimiento se vea afectado, y permite que Traffic Manager funcione tanto dentro de un centro de datos como entre centros de datos.
Durante la evaluación de los porcentajes de solicitudes que hay que mover, Traffic Manager:
Identifica el porcentaje de solicitudes que se deben eliminar de un centro de datos o de una subsección de un centro de datos para que se puedan atender todas las solicitudes.
A continuación, calcula las métricas de espacio agregadas de cada objetivo para ver el número de solicitudes que puede admitir cada centro de datos de conmutación por error.
Después, determina la cantidad de tráfico que hay que desplazar de cada plan, ya sea una parte o la totalidad, con Plurimog/Duomog, hasta que hayamos movido suficiente tráfico. Primero movemos a los clientes suscritos al plan gratuito, y una vez comprobemos que no hay más clientes de este tipo en un centro de datos, trasladaremos a los clientes suscritos al plan Pro, y luego a los del plan Business si es necesario.
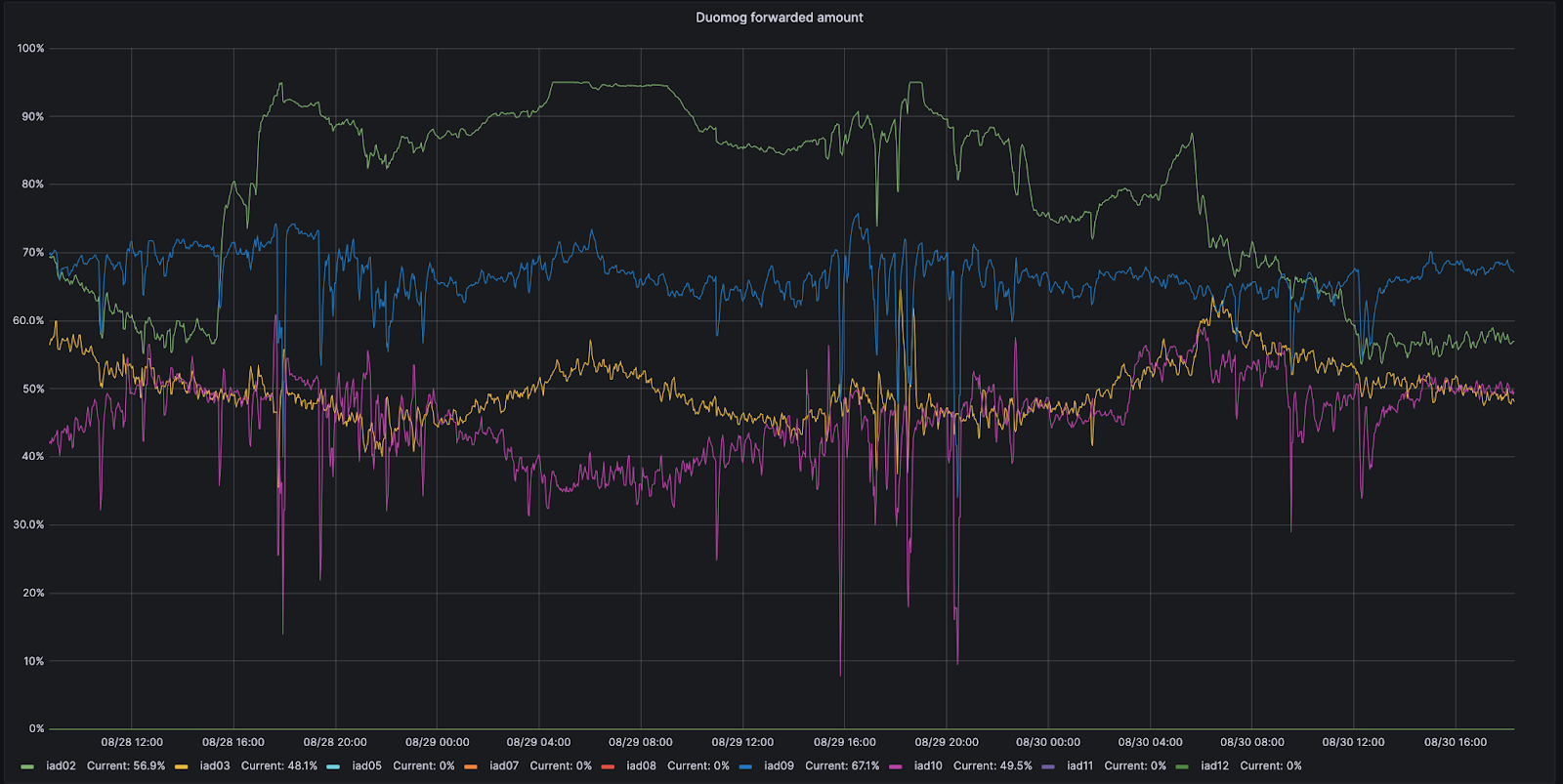
Por ejemplo, veamos Ashburn, Virginia, uno de nuestros MCP. Ashburn tiene nueve subsecciones diferentes de capacidad y cada una de ellas puede recibir tráfico. El 28 de agosto, una de esas subsecciones, IAD02, tuvo un problema que redujo la cantidad de tráfico que podía atender.
Durante este periodo, Duomog envió más tráfico de IAD02 a otras subsecciones de Ashburn, garantizando que Ashburn estuviera siempre en línea para que el rendimiento no se viera afectado durante este incidente. Una vez que IAD02 recuperó la capacidad para recibir tráfico, Duomog volvió a enviarlo de forma automática. Puedes ver estas acciones en el siguiente gráfico de series temporales, que rastrea el porcentaje de tráfico desplazado a lo largo del tiempo entre subsecciones de capacidad dentro de IAD02 (en verde):
¿Cómo sabe Traffic Manager la cantidad de tráfico que hay que desplazar?
Si bien hemos utilizado solicitudes por segundo en el ejemplo anterior, el uso de solicitudes por segundo como métrica no es lo bastante preciso cuando se trata de mover tráfico realmente. La razón es que los costes del servicio varían entre clientes. Un sitio web servido principalmente desde la caché con el WAF desactivado es mucho más barato desde el punto de vista de la CPU que un sitio con todas las reglas del WAF activadas y la caché desactivada. Así que registramos el tiempo que usa cada solicitud en la CPU. A continuación, podemos sumar el tiempo de CPU en cada plan para determinar el tiempo de CPU por tipo de plan. Registramos el tiempo de CPU en m/s, y tomamos un valor por segundo, lo que resulta en una unidad de milisegundos por segundo.
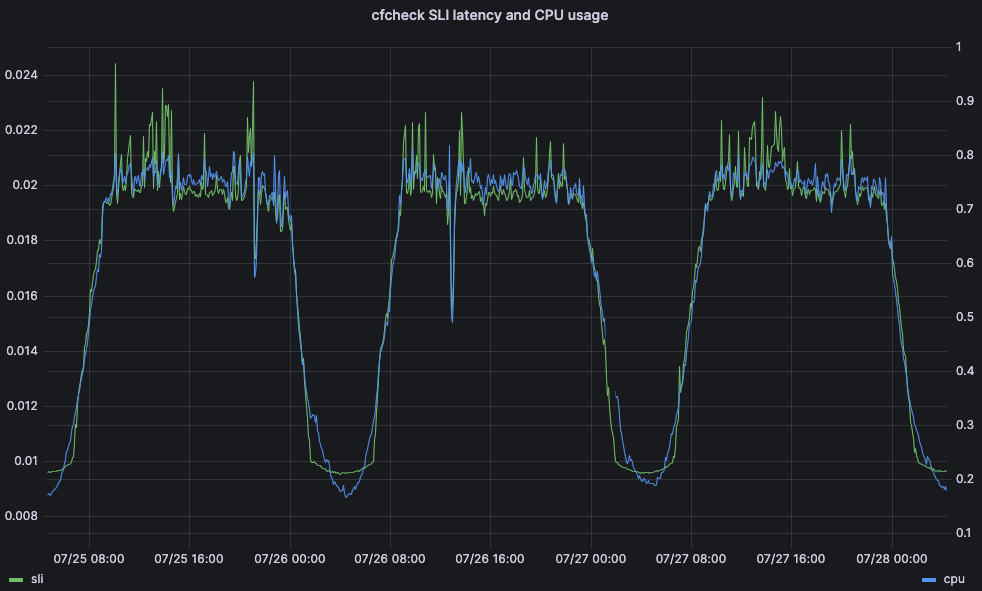
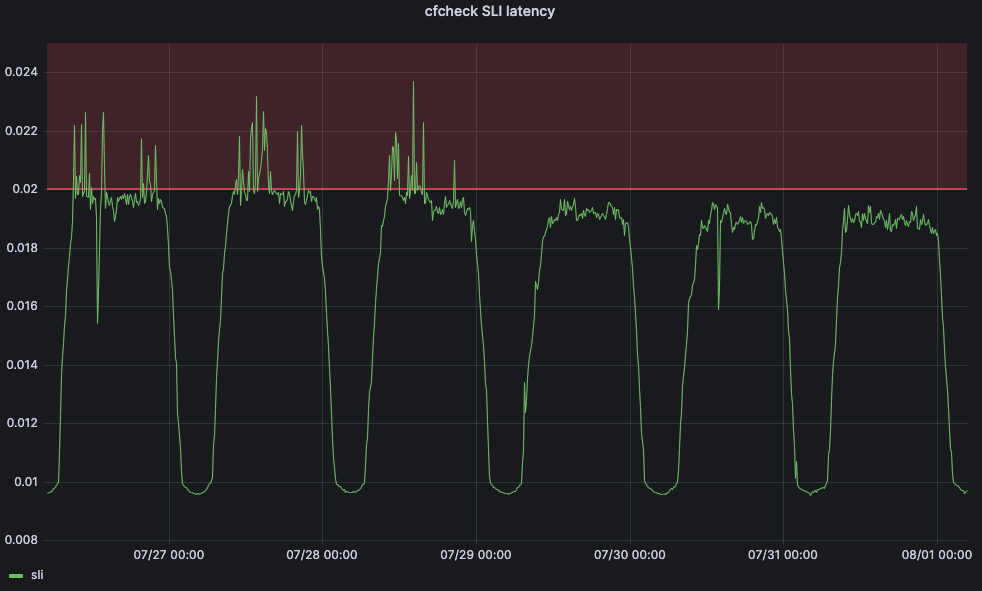
El tiempo de CPU es una métrica importante por el impacto que puede tener en la latencia y el rendimiento del cliente. A modo de ejemplo, analicemos el tiempo que tarda una solicitud de un visitante en atravesar por completo los servidores de primera línea de Cloudflare. A esto lo llamamos latencia cfcheck. Si este número sube demasiado, nuestros clientes empezarán a notarlo, y su experiencia se deteriorará. Cuando la latencia cfcheck es alta, suele deberse a una utilización de la CPU elevada. El gráfico siguiente muestra el percentil 95 de la latencia de cfcheck comparada con la utilización de la CPU en todas las máquinas del mismo centro de datos, y puedes ver la estrecha correlación:
Por tanto, conseguir que Traffic Manager revise el tiempo de CPU en un centro de datos es una forma muy buena de garantizar la mejor experiencia para los clientes sin causar problemas.
Después de obtener el tiempo de CPU por plan, tenemos que averiguar qué parte de ese tiempo de CPU debemos trasladar a otros centros de datos. Para ello, añadimos la utilización de la CPU en todos los servidores para obtener una única utilización de la CPU en el centro de datos. Si falla una parte de los servidores del centro de datos, debido a un fallo del dispositivo de red, un fallo de alimentación, etc., Duomog desvía automáticamente las solicitudes que estaban llegando a esos servidores a otro lugar del centro de datos. A medida que disminuye el número de servidores, aumenta la utilización general de la CPU del centro de datos. Traffic Manager tiene tres umbrales para cada centro de datos: máximo, objetivo y aceptable:
Máximo: el nivel de utilización de la CPU a partir del cual empieza a degradarse el rendimiento, cuando Traffic Manager tomará medidas.
Objetivo: el nivel al que Traffic Manager intentará reducir la utilización de la CPU para restablecer un servicio óptimo a los usuarios.
Aceptable: el nivel por debajo del cual un centro de datos puede recibir solicitudes reenviadas desde otro centro de datos, o revertir los movimientos activos.
Cuando un centro de datos supera el umbral máximo, Traffic Manager toma la relación entre el tiempo total de CPU de todos los planes y la utilización actual de la CPU, y la aplica a la utilización objetivo de la CPU para descubrir el tiempo objetivo de la CPU. Hacerlo así significa que podemos comparar un centro de datos con 100 servidores con un centro de datos con 10 servidores, sin tener que preocuparnos por el número de servidores de cada centro de datos. Esto supone que la carga aumenta linealmente, lo que se aproxima suficiente a la realidad como para que la suposición sea válida para nuestros objetivos.
La ratio objetivo es igual al ratio actual:
Por tanto:
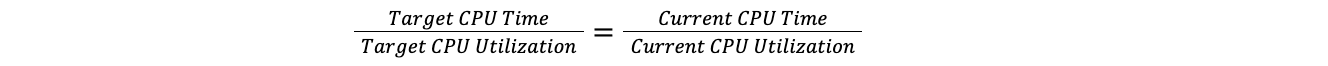
Restando el tiempo de CPU objetivo del tiempo de CPU actual obtenemos el tiempo de CPU que hay que trasladar:

Por ejemplo, si la utilización actual de la CPU fuera del 90 % en todo el centro de datos, el objetivo fuera del 85 % y el tiempo de CPU en todos los planes fuera de 18 000, tendríamos:

Esto significaría que Traffic Manager tendría que mover un tiempo de CPU de 1000:
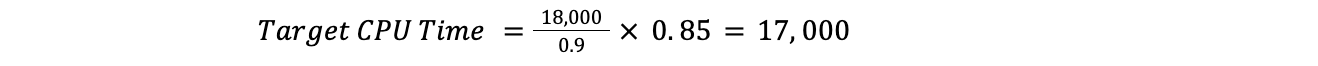
Ahora que sabemos el tiempo total de CPU que necesitamos mover, podemos ir revisando todos los planes, hasta alcanzar el tiempo que hay que trasladar.
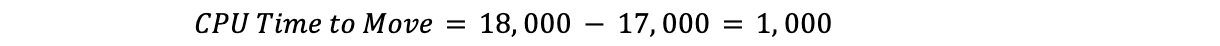
¿Cuál es el umbral máximo?
Un problema frecuente al que nos enfrentábamos era determinar en qué momento debe intervenir Traffic Manager en un centro de datos: ¿qué métrica debe observar y cuál es un nivel aceptable?Como ya hemos mencionado, cada servicio tiene requisitos diferentes en cuanto a la utilización de la CPU, y hay muchos casos de centros de datos que tienen patrones de utilización muy diferentes.
Para resolver este problema, recurrimos al aprendizaje automático. Creamos un servicio que configurara de manera automática los umbrales máximos de cada centro de datos en función de los indicadores utilizados por el cliente. En el caso de nuestro principal indicador de nivel de servicio (SLI), decidimos utilizar la métrica de latencia cfcheck que hemos descrito anteriormente.
Sin embargo, también necesitamos definir un objetivo de nivel de servicio (SLO) para que nuestra aplicación de aprendizaje automático pueda ajustar el umbral. Definimos el SLO en 20 m/s. Si comparamos nuestro SLO con nuestro SLI, nuestra latencia cfcheck del percentil 95 nunca debería superar los 20 m/s y, si lo hace, tenemos que intervenir. El siguiente gráfico muestra la latencia cfcheck del percentil 95 a lo largo del tiempo, y empieza el malestar entre los clientes cuando la latencia cfcheck entra en la zona roja:
Si los clientes tienen una mala experiencia cuando la utilización de la CPU es demasiada alta, el objetivo de los umbrales máximos de Traffic Manager es garantizar que el rendimiento del cliente no se vea afectado y empezar a redirigir el tráfico antes de que el rendimiento empiece a ralentizarse. En un intervalo programado, el servicio Traffic Manager obtendrá una serie de métricas para cada centro de datos y aplicará una serie de algoritmos de aprendizaje automático. Tras eliminar los valores atípicos, aplicamos un simple ajuste de curva cuadrática, y actualmente estamos probando un algoritmo de regresión lineal.
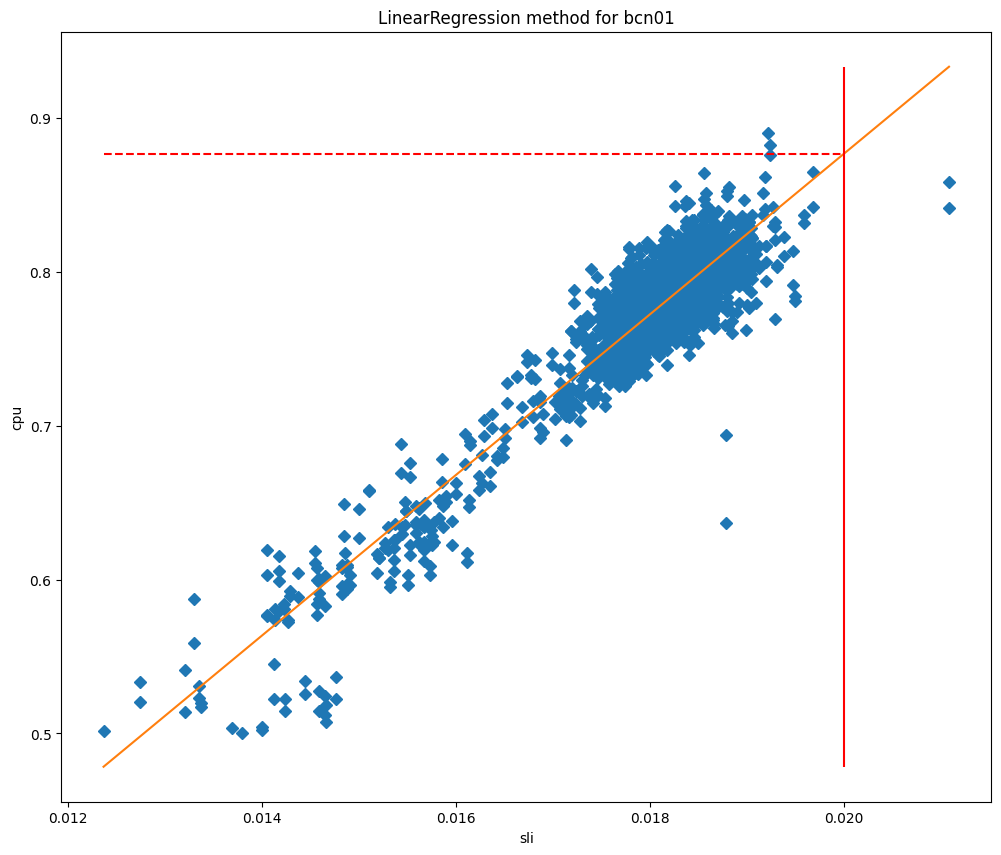
Tras ajustar los modelos, podemos utilizarlos para predecir el uso de la CPU cuando el SLI es igual a nuestro SLO, y utilizarlo como umbral máximo. Si comparamos los valores de la CPU con los del SLI, podemos ver claramente por qué estos métodos funcionan tan bien para nuestros centros de datos, como puedes ver en el caso de Barcelona en los gráficos siguientes, que se comparan con el ajuste de la curva y el ajuste de regresión lineal, respectivamente.
En estos gráficos, la línea vertical es el SLO, y la intersección de esta línea con el modelo ajustado representa el valor que se utilizará como umbral máximo. Este modelo ha demostrado ser muy preciso, y conseguimos reducir significativamente los incumplimientos del SLO. Echemos un vistazo a lo que ocurrió cuando empezamos a implementar este servidor en Lisboa:
Antes del cambio, la latencia cfcheck se disparaba constantemente, pero Traffic Manager no intervenía porque el umbral máximo era estático. Pero después del 29 de julio, hemos observado que la latencia cfcheck nunca ha alcanzado el SLO porque estamos midiendo constantemente para asegurarnos de que los clientes nunca se vean afectados por el aumento del tiempo de la CPU.
¿Dónde se envía el tráfico?
Así que ahora que tenemos un umbral máximo, tenemos que encontrar el tercer umbral de utilización de la CPU que no se utiliza cuando calculamos la cantidad de tráfico que hay que trasladar: el umbral aceptable. Cuando un centro de datos está por debajo de este umbral, dispone de capacidad no utilizada que, mientras no esté enviando tráfico por sí mismo, se pone a disposición de otros centros de datos que pueden utilizarla cuando la necesiten. Para saber la cantidad de tráfico que puede recibir cada centro de datos, utilizamos la metodología anterior y sustituiremos el umbral objetivo por el aceptable:
Por tanto:
Restando el tiempo de CPU actual del tiempo de CPU aceptable obtenemos la cantidad de tiempo de CPU que podría aceptar un centro de datos:
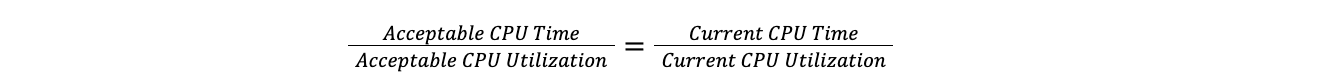
Para saber dónde enviar el tráfico, Traffic Manager encontrará el tiempo de CPU disponible en todos los centros de datos, y luego los ordenará por latencia desde el centro de datos que necesita trasladar el tráfico. Se mueve por cada uno de los centros de datos, utilizando toda la capacidad disponible en función de los umbrales máximos antes de pasar al siguiente. A la hora de localizar qué planes mover, iremos del plan menos prioritario al más prioritario, pero a la hora de decidir dónde enviarlos, lo haremos al contrario.

Para despejar cualquier duda, veamos un ejemplo:
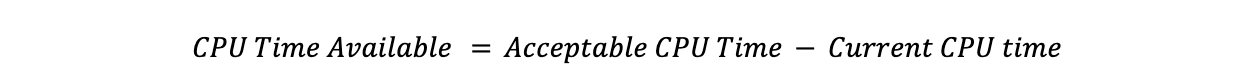
Necesitamos mover un tiempo de CPU de 1000 desde el centro de datos A, y tenemos el siguiente uso por plan: gratuito 500 ms/s, Pro: 400 ms/s, Business: 200 ms/s, Enterprise: 1000 ms/s.
Trasladaríamos el 100 % del uso del plan gratuito (500 ms/s), el 100 % del Pro (400 ms/s), el 50 % del Business (100 ms/s) y el 0 % del plan Enterprise.
Los centros de datos cercanos tienen el siguiente tiempo de CPU disponible: B: 300 ms/s, C: 300 ms/s, D: 1000 ms/s.
Con latencias: A-B: 100 m/s, A-C: 110 m/s, A-D: 120 m/s.
Empezando por el plan de menor latencia y mayor prioridad que necesita adopción de medidas, podríamos trasladar todo el tiempo de CPU del plan Business al centro de datos B y el 50 % al plan Pro. A continuación pasaríamos al centro de datos C, y podríamos trasladar el resto del tiempo de CPU del plan Pro, y el 20 % del plan gratuito. El resto del plan gratuito se podría trasladar al centro de datos D. El resultado sería: Business: 50 % → B, Pro: 50 % → B, 50 % → C, plan gratuito: 20 % → C, 80 % → D.
Revertir las acciones
De la misma forma que Traffic Manager intenta evitar constantemente que los centros de datos superen el umbral, también intenta devolver cualquier tráfico reenviado a un centro de datos que esté reenviando tráfico activamente.
Anteriormente hemos visto cómo Traffic Manager calcula la cantidad de tráfico que un centro de datos puede recibir de otro centro de datos, es lo que se denomina tiempo de CPU disponible. Cuando hay un movimiento activo, utilizamos este tiempo de CPU disponible para devolver tráfico al centro de datos. Siempre priorizamos el restablecimiento de un movimiento activo sobre la aceptación de tráfico de otro centro de datos.
Si lo juntamos todo, obtenemos un sistema que mide constantemente las métricas de estado del sistema y del cliente para cada centro de datos y reparte el tráfico para garantizar que cada solicitud es atendida en función del estado actual de nuestra red. Cuando situamos todos estos movimientos entre centros de datos en un mapa, obtenemos un mapa con todos los movimientos de Traffic Manager durante un periodo de una hora. Este mapa no muestra todo nuestra implementación de centros de datos, pero sí los centros de datos que están enviando o recibiendo tráfico que se ha trasladado durante este periodo:
Los centros de datos en rojo o amarillo están bajo carga y trasladan el tráfico a otros centros de datos hasta que pasan a estar en verde, lo que significa que todas las métricas se muestran como óptimas. El tamaño de los círculos representa el número de solicitudes que se desplazan desde o hacia esos centros de datos. El movimiento de las líneas representa hacia dónde se dirige el tráfico. No es fácil verlo a escala mundial, así que hagamos zoom en Estados Unidos para verlo en acción durante el mismo periodo de tiempo:
Aquí puedes ver que Toronto, Detroit, Nueva York y Kansas City no pueden atender algunas solicitudes debido a problemas de hardware, por lo que enviarán esas solicitudes a Dallas, Chicago y Ashburn hasta que se restablezca el equilibrio para los usuarios y los centros de datos. Una vez que los centros de datos como Detroit sean capaces de atender todas las solicitudes que reciben sin necesidad de desviar tráfico, Detroit dejará gradualmente de reenviar solicitudes a Chicago hasta que se resuelva por completo cualquier problema en el centro de datos, momento en el que ya no reenviará nada. Durante todo este proceso, los usuarios finales están en línea y no se ven afectados por ningún problema físico que pueda estar ocurriendo en Detroit o en cualquiera de las otras ubicaciones que envían tráfico.
Red óptima, productos óptimos
Traffic Manager forma parte de la experiencia del usuario, por lo que es un componente fundamental de la red de Cloudflare. Mantiene nuestros productos en línea y garantiza que sean lo más rápidos y fiables posible. Es nuestro equilibrador de carga en tiempo real, que nos ayuda a mantener la rapidez de nuestros productos desviando únicamente el tráfico necesario de los centros de datos que tienen problemas. Como se desplaza menos tráfico, garantizamos la rapidez de nuestros productos y servicios.
Sin embargo, Traffic Manager también puede ayudar a mantener nuestros productos en línea y seguros, permitiéndoles predecir dónde se pueden producir problemas de fiabilidad y trasladar preventivamente los productos a otro lugar. Por ejemplo, el servicio de aislamiento de navegador trabaja directamente con Traffic Manager para ayudar a garantizar el tiempo activo del producto. Cuando te conectas a un centro de datos de Cloudflare para crear una instancia de navegador alojada, el aislamiento de navegador pregunta primero a Traffic Manager si el centro de datos tiene capacidad suficiente para ejecutar la instancia localmente y, si es así, la instancia se crea en ese mismo momento. Si no hay suficiente capacidad disponible, Traffic Manager indica al servicio de aislamiento de navegador cuál es el centro de datos más cercano con suficiente capacidad disponible, ayudando así al servicio de aislamiento de navegador a proporcionar la mejor experiencia posible al usuario.
Funcionamiento óptimo de la red = usuarios felices
En Cloudflare, operamos esta vasta red para dar servicio a todos nuestros diferentes productos y escenarios de clientes. Hemos desarrollado esta red para que sea resistente. Además de nuestras ubicaciones MCP diseñadas para reducir el impacto de un único fallo, estamos trasladando constantemente el tráfico en nuestra red en respuesta a problemas internos y externos.
Pero ese es nuestro problema, no el tuyo.
Del mismo modo, cuando los seres humanos tenían que solucionar esos problemas, eran los clientes y los usuarios finales quienes se veían afectados. Para garantizar que siempre estás conectado, hemos desarrollado un sistema inteligente que detecta nuestros fallos de hardware y equilibra preventivamente el tráfico en nuestra red para garantizar que esté en línea y sea lo más rápido posible. Este sistema funciona más rápido que cualquier persona, lo que no solo permite a nuestros ingenieros de red descansar tranquilos, sino que también mejora y acelera las experiencias de todos nuestros clientes.
Por último, si este tipo de desafíos técnicos te parecen apasionantes, consulta los puestos vacantes del equipo de Ingeniería de Tráfico en nuestra página de empleo.