

Cloudflare annonce aujourd'hui le développement de Firewall for AI, une couche de protection qui peut être déployée devant les grands modèles de langage (LLM) afin d'identifier les tentatives d'utilisation abusive avant qu'elles n'atteignent les modèles.

À l'heure où les modèles d'IA, et plus particulièrement les LLM, connaissent un essor remarquable, nos clients nous informent qu'ils sont préoccupés par l'identification des meilleures stratégies permettant de sécuriser leurs LLM. L'utilisation de LLM dans le cadre d'applications connectées à Internet introduit de nouvelles vulnérabilités susceptibles d'être exploitées par des acteurs malveillants.
Certaines des vulnérabilités qui affectent les applications web et API traditionnelles s'appliquent également au monde des LLM, notamment les injections de code ou les exfiltrations de données. Cependant, il existe un nouvel ensemble de menaces qui sont désormais pertinentes en raison du mode de fonctionnement des LLM. Par exemple, des chercheurs ont récemment découvert une vulnérabilité sur une plateforme de collaboration d'IA, qui leur permet de détourner des modèles et d'effectuer des actions non autorisées.
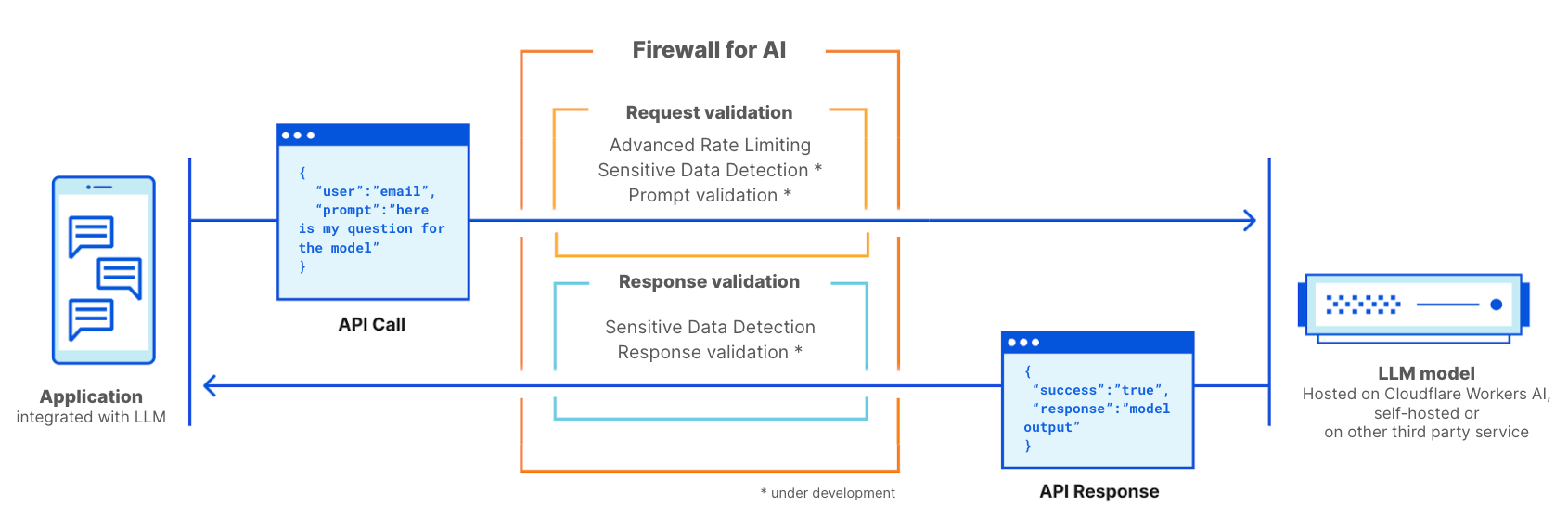
Firewall for AI est un pare-feu d'applications web (WAF) conçu spécifiquement pour les applications utilisant des LLM. Il inclura un ensemble d'outils pouvant être déployés en amont des applications afin de détecter les vulnérabilités et d'offrir une visibilité aux propriétaires de modèles. La suite d'outils comprendra des produits qui font déjà partie du pare-feu WAF, à l'image du contrôle du volume de requêtes et de la détection de données sensibles, ainsi qu'une nouvelle couche de protection, actuellement en cours de développement. Cette nouvelle validation analyse la demande transmise par l'utilisateur final afin d'identifier les tentatives d'exploitation du modèle visant à extraire des données, ainsi que d'autres tentatives d'utilisation abusive. Tirant parti de l'ampleur du réseau Cloudflare, Firewall for AI s'exécute au plus près de l'utilisateur, nous permettant d'identifier rapidement les attaques et de protéger à la fois l'utilisateur final et les modèles contre les tentatives d'utilisation abusive et les attaques.
Avant d'examiner le fonctionnement de Firewall for AI et l'ensemble complet de fonctionnalités qu'il propose, examinons d'abord ce qui rend les LLM uniques, ainsi que les surfaces d'attaque qu'ils introduisent. Nous utiliserons comme référence le classement OWASP Top 10 for LLMs.
En quoi les LLM sont-ils différents des applications traditionnelles ?
Si l'on considère les LLM selon la perspective d'applications connectées à Internet, ils présentent deux différences principales par rapport aux applications web plus traditionnelles.
Premièrement, la façon dont les utilisateurs interagissent avec le produit. Les applications traditionnelles sont déterministes par nature. Prenons l'exemple d'une application bancaire : elle est définie par un ensemble d'opérations (vérifier mon solde, effectuer un virement, etc.). La sécurité des opérations commerciales (et des données) peut être obtenue en contrôlant l'ensemble précisément défini d'opérations acceptées par ces points de terminaison : « GET /balance » ou « POST /transfer ».
Les opérations des LLM sont intrinsèquement non déterministes. Tout d'abord, les interactions avec les LLM sont basées sur le langage naturel, ce qui rend l'identification des requêtes problématiques plus difficile que l'établissement de correspondances avec des signatures d'attaques. En outre, à moins qu'une réponse ne soit mise en cache, les LLM fournissent généralement une réponse différente à chaque fois, même en cas de répétition de la même demande saisie en entrée. Il est, par conséquent, beaucoup plus difficile de limiter la manière dont un utilisateur interagit avec l'application. Ceci constitue également une menace pour l'utilisateur, puisqu'il risque d'être exposé à des informations erronées, susceptibles d'affaiblir sa confiance dans le modèle.
Deuxièmement, la façon dont le plan de contrôle de l'application interagit avec les données fait une grande différence. Dans les applications traditionnelles, le plan de contrôle (code) est distinct du plan de données (base de données). Les opérations définies constituent le seul moyen d'interagir avec les données sous-jacentes (par exemple, « afficher l'historique de mes transactions de paiement »). Cette approche permet aux professionnels de la sécurité de se concentrer sur l'ajout de contrôles et de garde-fous au niveau du plan de contrôle, et ainsi, de protéger indirectement la base de données.
Les LLM sont différents, dans la mesure où les données d'apprentissage deviennent une partie du modèle lui-même, par le biais du processus d'apprentissage ; il devient alors extrêmement difficile de contrôler la manière dont ces données sont partagées à la suite d'une demande transmise par l'utilisateur. Certaines solutions architecturales sont actuellement à l'étude, à l'image de la séparation des LLM en différents niveaux et de la séparation des données. Cependant, aucune « solution miracle » n'a encore été trouvée.
Du point de vue de la sécurité, ces différences permettent aux acteurs malveillants d'élaborer de nouveaux vecteurs d'attaque capables de cibler les LLM, tout en évitant d'être repérés par les outils de sécurité existants, conçus pour les applications web traditionnelles.
Les vulnérabilités des LLM selon OWASP
La fondation OWASP a publié une liste des 10 principales classes de vulnérabilités pour les LLM, fournissant un cadre de réflexion utile pour la sécurisation des modèles de langage. Certaines menaces rappellent celles du classement OWASP Top 10 dédié aux applications web, tandis que d'autres sont spécifiques aux modèles de langage.
À l'instar des applications web, l'approche idéale du traitement de certaines de ces vulnérabilités nécessite que l'application LLM soit conçue, développée et formée. Par exemple, les vulnérabilités de type empoisonnement des données d'apprentissage (« Training Data Poisoning ») peuvent être mises en œuvre par l'introduction de vulnérabilités dans l'ensemble de données d'apprentissage utilisé pour former de nouveaux modèles. Les informations empoisonnées sont ensuite présentées à l'utilisateur lorsque le modèle est opérationnel. Les vulnérabilités de la chaîne logistique (« Supply Chain Vulnerabilities ») et la conception non sécurisée de plugins (« Insecure Plugin Design ») sont des vulnérabilités introduites dans les composants ajoutés au modèle, à l'image des suites de logiciels tiers. Enfin, la gestion des autorisations et des permissions est cruciale dans le cas de la capacité d'action excessive (« Excessive Agency »), où des modèles exempts de restrictions peuvent effectuer des actions non autorisées dans l'application ou sur l'infrastructure plus large.
À l'inverse, les vulnérabilités de type infiltration de requêtes (« Prompt Injection »), déni de service de modèle (« Model Denial of Service ») et divulgation d'informations sensibles (« Sensitive Information Disclosure ») peuvent être atténuées en adoptant une solution de sécurité par proxy telle que Cloudflare Firewall for AI. Dans les sections suivantes, nous fournissons plus de détails sur ces vulnérabilités, et nous examinons pourquoi Cloudflare est idéalement positionnée pour les atténuer.
Déploiements de LLM
Les risques liés aux modèles de langage dépendent également du modèle de déploiement. Nous observons actuellement trois approches principales de déploiement de LLM : interne, public et produit. Dans ces trois scénarios, vous devez protéger les modèles contre les tentatives d'utilisation abusive, protéger les données propriétaires stockées dans le modèle et protéger l'utilisateur final contre les informations erronées ou l'exposition à des contenus inappropriés.
LLM internes : les entreprises développent des LLM afin d'aider leur personnel à accomplir ses tâches quotidiennes. Ces LLM sont considérés comme des actifs de l'entreprise, et ne doivent pas être accessibles à des personnes extérieures à l'entreprise. Il peut, par exemple, s'agir d'un copilote IA formé avec des données commerciales et des interactions avec les clients, utilisé pour générer des propositions personnalisées, ou encore d'un LLM formé avec une base de connaissances interne, pouvant être interrogé par les ingénieurs.
LLM publics : il s'agit de LLM accessibles au-delà des frontières d'une entreprise. Ces solutions proposent souvent des versions gratuites, utilisables par tous, et sont souvent formées à partir de connaissances générales ou publiques. Parmi les exemples figurent OpenAI GPT ou Anthropic Claude.
LLM produit : du point de vue d'une entreprise, les LLM peuvent faire partie d'un produit ou d'un service proposé aux clients de celle-ci. Il s'agit généralement de solutions personnalisées et auto-hébergées, qui peuvent être mises à disposition en tant qu'outil permettant d'interagir avec les ressources de l'entreprise. Parmi les exemples figurent les chatbots d'assistance ou l'assistant IA de Cloudflare.
Du point de vue du risque, la différence entre les LLM publics et les LLM produit est déterminée par la cible atteinte en cas d'attaque réussie. Les LLM publics sont considérés comme une menace pour les données, car les données transmises au modèle peuvent être consultées par pratiquement n'importe qui. C'est l'une des raisons pour lesquelles de nombreuses entreprises invitent leur personnel à ne pas saisir d'informations confidentielles dans les demandes adressées à des services accessibles au public. Les LLM produit peuvent être considérés comme une menace pour les entreprises et leur propriété intellectuelle si les modèles ont eu accès, à dessein ou par erreur, à des informations exclusives pendant leur apprentissage.
Firewall for AI
Cloudflare Firewall for AI sera déployé comme un pare-feu WAF traditionnel, où chaque requête d'API avec une demande adressée à un LLM est analysée à la recherche de modèles et de signatures d'attaques possibles.
Firewall for AI peut être déployé en amont des modèles hébergés sur la plateforme Workers AI de Cloudflare ou des modèles hébergés sur toute autre infrastructure tierce. La solution peut également être utilisée avec Cloudflare AI Gateway, et les clients pourront contrôler et configurer Firewall for AI depuis le plan de contrôle du pare-feu WAF.
Firewall for AI se comporte comme un pare-feu d'applications web traditionnel. Il est déployé en amont d'une application LLM et analyse chaque requête afin d'identifier les signatures d'attaques
Prévenez les attaques volumétriques
L'une des menaces répertoriées par OWASP est le déni de service de modèle (« Model Denial of Service »). De manière semblable aux applications traditionnelles, une attaque par déni de service consiste à provoquer la consommation d'une quantité exceptionnellement élevée de ressources, entraînant une diminution de la qualité du service ou une augmentation potentielle des coûts d'exécution du modèle. En raison de la quantité de ressources que nécessite le fonctionnement des LLM et de l'imprévisibilité des données saisies en entrée par les utilisateurs, ce type d'attaque peut être préjudiciable.
Ce risque peut être atténué par l'adoption de politiques de controle du volume de requêtes issues des sessions individuelles, limitant par conséquent la fenêtre contextuelle. En déployant dès aujourd'hui votre modèle en proxy par l'intermédiaire de Cloudflare, vous bénéficiez d'une protection contre les attaques DDoS dès la mise en service. Vous pouvez également utiliser les fonctionnalités de contrôle et de contrôle avancé du volume de requêtes pour gérer le volume de requêtes autorisées à atteindre votre modèle, en spécifiant le volume maximal de requêtes transmises depuis une adresse IP ou une clé d'API individuelle durant une session.
Identifiez les informations sensibles grâce à la détection de données sensibles
Il existe deux scénarios d'utilisation applicables aux données sensibles, selon que vous êtes propriétaire du modèle et des données ou que vous souhaitez empêcher les utilisateurs de transmettre des données à des LLM publics.
Selon la définition d'OWASP, la divulgation d'informations sensibles (« Sensitive Information Disclosure ») se produit lorsque des LLM dévoilent accidentellement des données confidentielles dans les réponses, entraînant ainsi un accès non autorisé aux données, des violations de la confidentialité et des failles de sécurité. Une façon d'éviter ces incidents consiste à ajouter des validations strictes des demandes ; une autre approche consiste à identifier le moment auquel les informations d'identification personnelles (IPI) quittent le modèle. Cela peut être le cas, par exemple, lorsqu'un modèle a été formé avec une base de connaissances de l'entreprise pouvant contenir des informations sensibles, telles que des IPI (des numéros de sécurité sociale, par exemple), du code propriétaire ou des algorithmes.
Les clients utilisant des modèles LLM derrière le pare-feu WAF de Cloudflare peuvent faire usage de l'ensemble de règles gérées « Sensitive Data Detection (SDD) » du pare-feu WAF pour identifier certaines IPI renvoyées par le modèle dans la réponse. Les clients peuvent consulter les correspondances avec l'ensemble de règles gérées SDD en accédant aux événements de sécurité du pare-feu WAF. Aujourd'hui, les règles gérées SDD sont proposées sous la forme d'un ensemble conçu pour rechercher des informations financières (des numéros de carte de paiement, par exemple) ainsi que des secrets (clés d'API). Dans le cadre de notre feuille de route, nous prévoyons de permettre aux clients de créer leurs propres empreintes numériques personnalisées.
L'autre scénario d'utilisation vise à empêcher les utilisateurs de communiquer des IPI ou d'autres informations sensibles à des fournisseurs externes de LLM, tels que OpenAI ou Anthropic. Pour offrir une protection contre ce scénario, nous avons l'intention d'étendre l'ensemble de règles gérées SDD afin d'analyser les demandes et d'intégrer leur résultat à AI Gateway où, en plus de l'historique des demandes, nous détectons si certaines données sensibles ont été incluses dans ces dernières. Nous commencerons par utiliser les règles SDD existantes, et nous prévoyons de permettre aux clients d'écrire leurs propres signatures personnalisées. Dans le même ordre d'idées, la dissimulation est une autre fonctionnalité dont nos clients nous parlent beaucoup. Une fois disponible, l'ensemble de règles gérées étendu SDD permettra aux clients de dissimuler certaines données sensibles dans une invite avant qu'elles n'atteignent le modèle. L'application de l'ensemble de règles gérées SDD durant la phase de requête est en cours de développement.
Prévenir les utilisations abusives de modèles
L'utilisation abusive de modèles est une catégorie plus large d'abus. Il s'agit notamment d'approches telles que l'infiltration de requêtes (« Prompt injection ») ou la transmission de requêtes générant des hallucinations ou entraînant des réponses inexactes, offensantes, inappropriées ou simplement hors sujet.
L'infiltration de requêtes est une tentative de manipulation d'un modèle de langage faisant appel à des requêtes spécialement conçues, qui entraîne des réponses indésirables de la part du LLM. Les résultats d'une attaque par infiltration de requêtes peuvent varier, de l'extraction d'informations sensibles jusqu'à l'influence d'une prise de décision reposant sur l'imitation d'interactions normales avec le modèle. Un exemple classique d'infiltration de requêtes est la manipulation d'un CV, avec l'objectif d'affecter le résultat d'outils de sélection de curriculum vitae.
Un scénario d'utilisation courant dont nous parlent les clients de notre solution AI Gateway est le souhait d'éviter que leur application ne génère un langage toxique, offensant ou problématique. Parmi les risques liés à l'absence de contrôle des résultats du modèle figurent notamment les atteintes à la réputation et un préjudice pour l'utilisateur final, suite à la présentation de réponses non fiables.
Ces types d'utilisations abusives peuvent être gérés par l'ajout d'une couche de protection supplémentaire devant le modèle. Cette couche peut être formée pour arrêter les tentatives d'infiltration de requêtes ou bloquer les requêtes correspondant à des catégories inappropriées.
Validation de demandes et de réponses
L'autre scénario d'utilisation vise à empêcher les utilisateurs de communiquer des IPI ou d'autres informations sensibles à des fournisseurs externes de LLM, tels que OpenAI ou Anthropic. Comme d'autres fonctionnalités existantes du pare-feu WAF, Firewall for AI recherchera automatiquement les demandes intégrées dans les requêtes HTTP ou permettra aux clients de créer des règles en fonction de l'emplacement, dans le corps de la requête JSON, où peut se trouver la demande.
Une fois activé, le pare-feu analyse chaque demande et attribue une note en fonction de la probabilité qu'elle soit malveillante. Il identifie également la demande en fonction de catégories prédéfinies. La plage de scores va de 1 à 99, indiquant ainsi la probabilité d'une attaque par infiltration de requête (1 étant le score le plus élevé).
Les clients pourront créer des règles de pare-feu WAF afin de bloquer ou de traiter les requêtes avec un score particulier dans l'une ou l'autre de ces dimensions, ou les deux. Vous pourrez associer ce score à d'autres signaux existants (par exemple, le score de bot ou l'indicateur Attack Score) afin de déterminer si la requête doit atteindre le modèle ou être bloquée. Par exemple, elle pourrait être associé à un score de bot afin d'identifier si la requête était malveillante et générée par une source automatisée.
La détection des attaques par injection de requêtes et des demandes abusives fait partie du champ d'application de Firewall for AI. Projet d'itération de la conception du produit
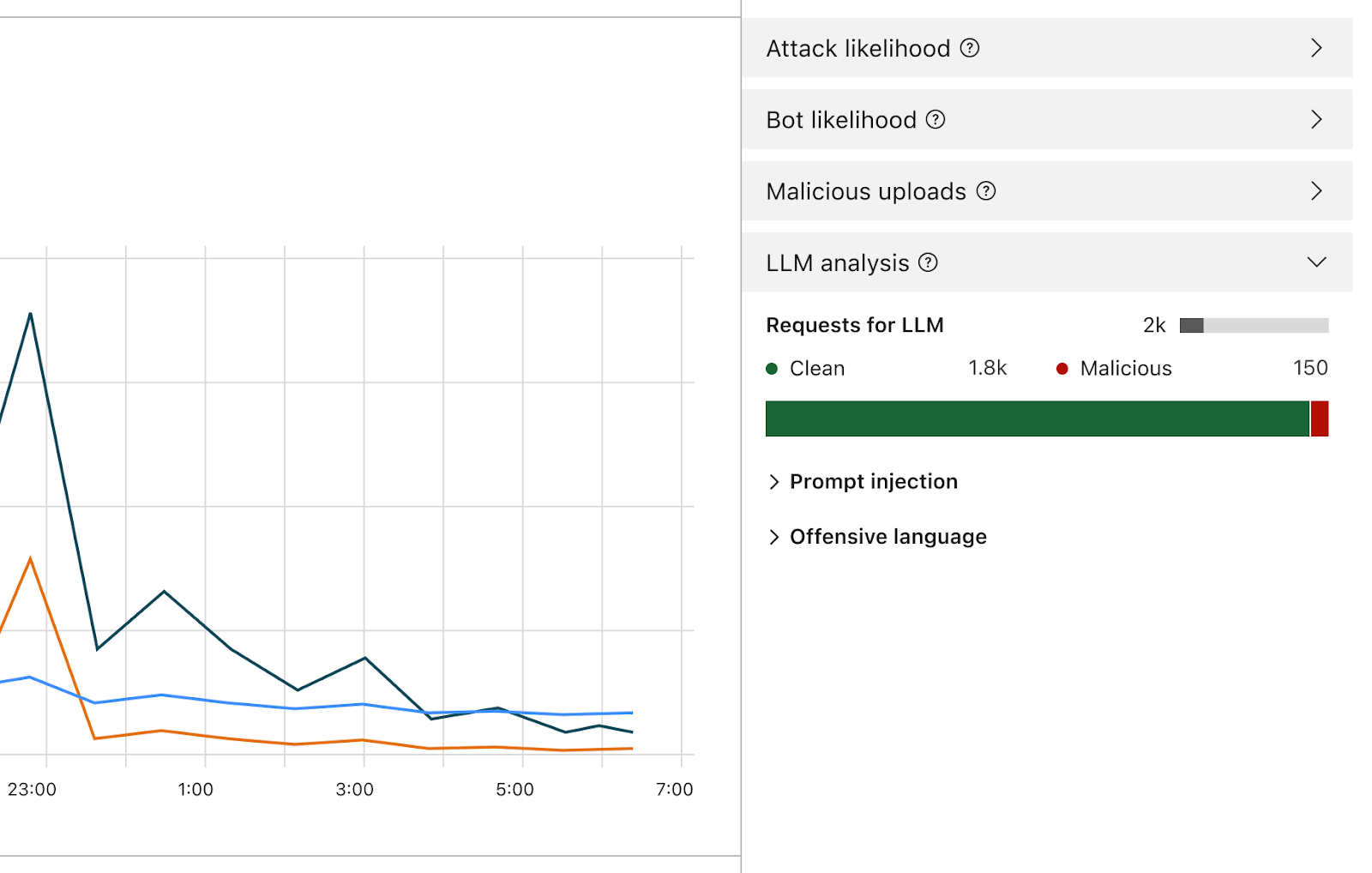
Outre le score, nous attribuerons à chaque demande des identifiants qui pourront être utilisés lors de la création de règles visant à empêcher les demandes associées à l'une ou l'autre de ces catégories d'atteindre le modèle correspondant. Par exemple, les clients pourront créer des règles afin d'interdire des sujets spécifiques, notamment les demandes utilisant des termes considérés comme offensants ou liés à la religion, à des contenus sexuels ou à la politique, par exemple.
Comment utiliser Firewall for AI ? Qui peut y accéder ?
Les entreprises clientes de l'offre Application Security Advanced peuvent immédiatement commencer à utiliser les fonctionnalités de contrôle avancé du volume de requêtes et de détection de données sensibles (sur la phase de réponse). Les deux produits sont accessibles depuis la section du pare-feu WAF du tableau de bord de Cloudflare. La fonctionnalité de validation de demandes de Firewall for AI est actuellement en cours de développement, et une version bêta sera lancée au cours des mois à venir pour tous les utilisateurs de Workers AI. Inscrivez-vous pour rejoindre la liste d'attente et recevoir une notification lorsque la fonctionnalité sera disponible.
Conclusion
Cloudflare est l'un des premiers fournisseurs de sécurité à inaugurer une suite d'outils dédiée à la sécurisation des applications d'IA. Grâce à Firewall for AI, les clients peuvent contrôler les demandes et les requêtes qui parviennent à leurs modèles de langage, réduisant ainsi le risque d'utilisations abusives et d'exfiltration de données. Restez à l'écoute pour en savoir plus sur l'évolution de la sécurité des applications d'IA.