

Today, Cloudflare is announcing the development of Firewall for AI, a protection layer that can be deployed in front of Large Language Models (LLMs) to identify abuses before they reach the models.
While AI models, and specifically LLMs, are surging, customers tell us that they are concerned about the best strategies to secure their own LLMs. Using LLMs as part of Internet-connected applications introduces new vulnerabilities that can be exploited by bad actors.
Some of the vulnerabilities affecting traditional web and API applications apply to the LLM world as well, including injections or data exfiltration. However, there is a new set of threats that are now relevant because of the way LLMs work. For example, researchers have recently discovered a vulnerability in an AI collaboration platform that allows them to hijack models and perform unauthorized actions.
Firewall for AI is an advanced Web Application Firewall (WAF) specifically tailored for applications using LLMs. It will comprise a set of tools that can be deployed in front of applications to detect vulnerabilities and provide visibility to model owners. The tool kit will include products that are already part of WAF, such as Rate Limiting and Sensitive Data Detection, and a new protection layer which is currently under development. This new validation analyzes the prompt submitted by the end user to identify attempts to exploit the model to extract data and other abuse attempts. Leveraging the size of Cloudflare network, Firewall for AI runs as close to the user as possible, allowing us to identify attacks early and protect both end user and models from abuses and attacks.
Before we dig into how Firewall for AI works and its full feature set, let’s first examine what makes LLMs unique, and the attack surfaces they introduce. We’ll use the OWASP Top 10 for LLMs as a reference.
Why are LLMs different from traditional applications?
When considering LLMs as Internet-connected applications, there are two main differences compared with more traditional web apps.
First, the way users interact with the product. Traditional apps are deterministic in nature. Think about a bank application — it’s defined by a set of operations (check my balance, make a transfer, etc.). The security of the business operation (and data) can be obtained by controlling the fine set of operations accepted by these endpoints: “GET /balance” or “POST /transfer”.
LLM operations are non-deterministic by design. To start with, LLM interactions are based on natural language, which makes identifying problematic requests harder than matching attack signatures. Additionally, unless a response is cached, LLMs typically provide a different response every time — even if the same input prompt is repeated. This makes limiting the way a user interacts with the application much more difficult. This poses a threat to the user as well, in terms of being exposed to misinformation that weakens the trust in the model.
Second, a big difference is how the application control plane interacts with the data. In traditional applications, the control plane (code) is well separated from the data plane (database). The defined operations are the only way to interact with the underlying data (e.g. show me the history of my payment transactions). This allows security practitioners to focus on adding checks and guardrails to the control plane and thus protecting the database indirectly.
LLMs are different in that the training data becomes part of the model itself through the training process, making it extremely difficult to control how that data is shared as a result of a user prompt. Some architectural solutions are being explored, such as separating LLMs into different levels and segregating data. However, no silver bullet has yet been found.
From a security perspective, these differences allow attackers to craft new attack vectors that can target LLMs and fly under the radar of existing security tools designed for traditional web applications.
OWASP LLM Vulnerabilities
The OWASP foundation released a list of the top 10 classes of vulnerabilities for LLMs, providing a useful framework for thinking about how to secure language models. Some of the threats are reminiscent of the OWASP top 10 for web applications, while others are specific to language models.
Similar to web applications, some of these vulnerabilities can be best addressed when the LLM application is designed, developed, and trained. For example, Training Data Poisoning can be carried out by introducing vulnerabilities in the training data set used to train new models. Poisoned information is then presented to the user when the model is live. Supply Chain Vulnerabilities and Insecure Plugin Design are vulnerabilities introduced in components added to the model, like third-party software packages. Finally, managing authorization and permissions is crucial when dealing with Excessive Agency, where unconstrained models can perform unauthorized actions within the broader application or infrastructure.
Conversely, Prompt Injection, Model Denial of Service, and Sensitive Information Disclosure can be mitigated by adopting a proxy security solution like Cloudflare Firewall for AI. In the following sections, we will give more details about these vulnerabilities and discuss how Cloudflare is optimally positioned to mitigate them.
LLM deployments
Language model risks also depend on the deployment model. Currently, we see three main deployment approaches: internal, public, and product LLMs. In all three scenarios, you need to protect models from abuses, protect any proprietary data stored in the model, and protect the end user from misinformation or from exposure to inappropriate content.
Internal LLMs: Companies develop LLMs to support the workforce in their daily tasks. These are considered corporate assets and shouldn’t be accessed by non-employees. Examples include an AI co-pilot trained on sales data and customer interactions used to generate tailored proposals, or an LLM trained on an internal knowledge base that can be queried by engineers.
Public LLMs: These are LLMs that can be accessed outside the boundaries of a corporation. Often these solutions have free versions that anyone can use and they are often trained on general or public knowledge. Examples include GPT from OpenAI or Claude from Anthropic.
Product LLM: From a corporate perspective, LLMs can be part of a product or service offered to their customers. These are usually self-hosted, tailored solutions that can be made available as a tool to interact with the company resources. Examples include customer support chatbots or Cloudflare AI Assistant.
From a risk perspective, the difference between Product and Public LLMs is about who carries the impact of successful attacks. Public LLMs are considered a threat to data because data that ends up in the model can be accessed by virtually anyone. This is one of the reasons many corporations advise their employees not to use confidential information in prompts for publicly available services. Product LLMs can be considered a threat to companies and their intellectual property if models had access to proprietary information during training (by design or by accident).
Firewall for AI
Cloudflare Firewall for AI will be deployed like a traditional WAF, where every API request with an LLM prompt is scanned for patterns and signatures of possible attacks.
Firewall for AI can be deployed in front of models hosted on the Cloudflare Workers AI platform or models hosted on any other third party infrastructure. It can also be used alongside Cloudflare AI Gateway, and customers will be able to control and set up Firewall for AI using the WAF control plane.
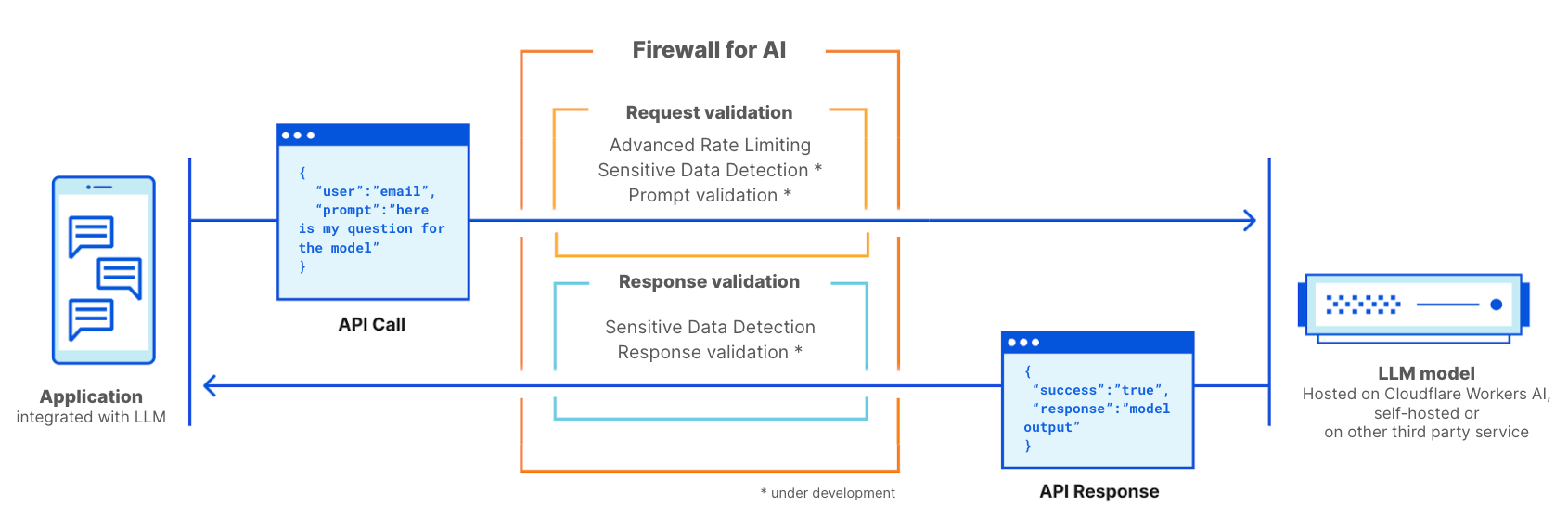
Firewall for AI works like a traditional web application firewall. It is deployed in front of an LLM application and scans every request to identify attack signatures
Prevent volumetric attacks
One of the threats listed by OWASP is Model Denial of Service. Similar to traditional applications, a DoS attack is carried out by consuming an exceptionally high amount of resources, resulting in reduced service quality or potentially increasing the costs of running the model. Given the amount of resources LLMs require to run, and the unpredictability of user input, this type of attack can be detrimental.
This risk can be mitigated by adopting rate limiting policies that control the rate of requests from individual sessions, therefore limiting the context window. By proxying your model through Cloudflare today, you get DDoS protection out of the box. You can also use Rate Limiting and Advanced Rate Limiting to manage the rate of requests allowed to reach your model by setting a maximum rate of request performed by an individual IP address or API key during a session.
Identify sensitive information with Sensitive Data Detection
There are two use cases for sensitive data, depending on whether you own the model and data, or you want to prevent users from sending data into public LLMs.
As defined by OWASP, Sensitive Information Disclosure happens when LLMs inadvertently reveal confidential data in the responses, leading to unauthorized data access, privacy violations, and security breaches. One way to prevent this is to add strict prompt validations. Another approach is to identify when personally identifiable information (PII) leaves the model. This is relevant, for example, when a model was trained with a company knowledge base that may include sensitive information, such asPII (like social security number), proprietary code, or algorithms.
Customers using LLM models behind Cloudflare WAF can employ the Sensitive Data Detection (SDD) WAF managed ruleset to identify certain PII being returned by the model in the response. Customers can review the SDD matches on WAF Security Events. Today, SDD is offered as a set of managed rules designed to scan for financial information (such as credit card numbers) as well as secrets (API keys). As part of the roadmap, we plan to allow customers to create their own custom fingerprints.
The other use case is intended to prevent users from sharing PII or other sensitive information with external LLM providers, such as OpenAI or Anthropic. To protect from this scenario, we plan to expand SDD to scan the request prompt and integrate its output with AI Gateway where, alongside the prompt's history, we detect if certain sensitive data has been included in the request. We will start by using the existing SDD rules, and we plan to allow customers to write their own custom signatures. Relatedly, obfuscation is another feature we hear a lot of customers talk about. Once available, the expanded SDD will allow customers to obfuscate certain sensitive data in a prompt before it reaches the model. SDD on the request phase is being developed.
Preventing model abuses
Model abuse is a broader category of abuse. It includes approaches like “prompt injection” or submitting requests that generate hallucinations or lead to responses that are inaccurate, offensive, inappropriate, or simply off-topic.
Prompt Injection is an attempt to manipulate a language model through specially crafted inputs, causing unintended responses by the LLM. The results of an injection can vary, from extracting sensitive information to influencing decision-making by mimicking normal interactions with the model. A classic example of prompt injection is manipulating a CV to affect the output of resume screening tools.
A common use case we hear from customers of our AI Gateway is that they want to avoid their application generating toxic, offensive, or problematic language. The risks of not controlling the outcome of the model include reputational damage and harming the end user by providing an unreliable response.
These types of abuse can be managed by adding an additional layer of protection that sits in front of the model. This layer can be trained to block injection attempts or block prompts that fall into categories that are inappropriate.
Prompt and response validation
Firewall for AI will run a series of detections designed to identify prompt injection attempts and other abuses, such as making sure the topic stays within the boundaries defined by the model owner. Like other existing WAF features, Firewall for AI will automatically look for prompts embedded in HTTP requests or allow customers to create rules based on where in the JSON body of the request the prompt can be found.
Once enabled, the Firewall will analyze every prompt and provide a score based on the likelihood that it’s malicious. It will also tag the prompt based on predefined categories. The score ranges from 1 to 99 which indicates the likelihood of a prompt injection, with 1 being the most likely.
Customers will be able to create WAF rules to block or handle requests with a particular score in one or both of these dimensions. You’ll be able to combine this score with other existing signals (like bot score or attack score) to determine whether the request should reach the model or should be blocked. For example, it could be combined with a bot score to identify if the request was malicious and generated by an automated source.
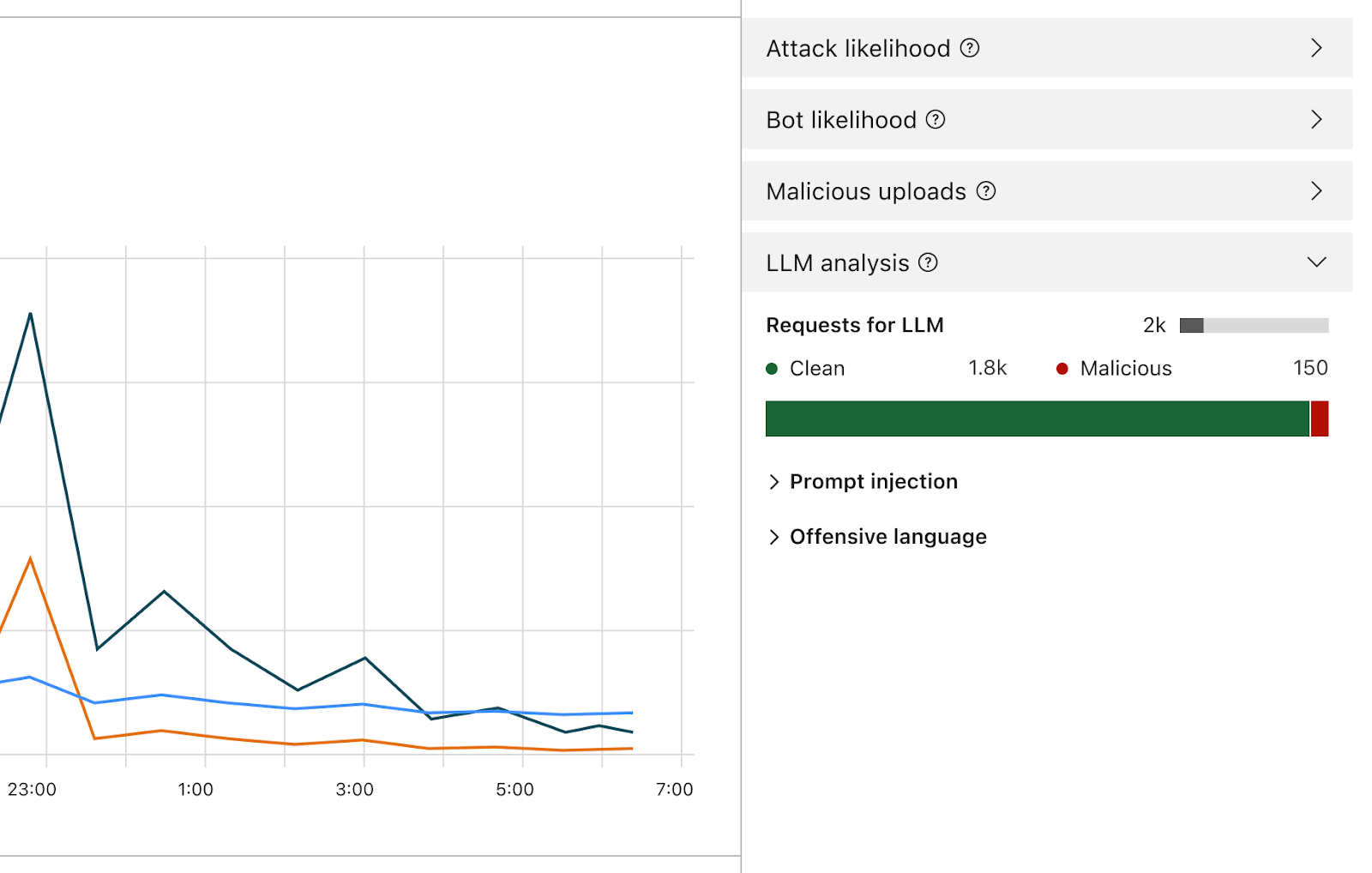
Detecting prompt injections and prompt abuse is part of the scope of Firewall for AI. Early iteration of the product design
Besides the score, we will assign tags to each prompt that can be used when creating rules to prevent prompts belonging to any of these categories from reaching their model. For example, customers will be able to create rules to block specific topics. This includes prompts using words categorized as offensive, or linked to religion, sexual content, or politics, for example.
How can I use Firewall for AI? Who gets this?
Enterprise customers on the Application Security Advanced offering can immediately start using Advanced Rate Limiting and Sensitive Data Detection (on the response phase). Both products can be found in the WAF section of the Cloudflare dashboard. Firewall for AI’s prompt validation feature is currently under development and a beta version will be released in the coming months to all Workers AI users. Sign up to join the waiting list and get notified when the feature becomes available.
Conclusion
Cloudflare is one of the first security providers launching a set of tools to secure AI applications. Using Firewall for AI, customers can control what prompts and requests reach their language models, reducing the risk of abuses and data exfiltration. Stay tuned to learn more about how AI application security is evolving.