

Cloudflare kündigt heute die Entwicklung von Firewall for AI an, einer Schutzschicht, die vor Large Language Models (LLMs) eingesetzt werden kann, um Missbrauchsversuche zu erkennen, bevor sie die Modelle erreichen.

Zwar sind KI-Modelle und insbesondere LLMs auf dem Vormarsch, aber Kunden berichten uns, dass sie intensiv darüber nachdenken, wie sie ihre eigenen LLMs am besten schützen können. Die Verwendung von LLMs als Teil von internetbasierten Anwendungen führt zu neuen Schwachstellen, die von bösartigen Akteuren ausgenutzt werden können.
Einige der Sicherheitslücken, die herkömmliche Web- und API-Anwendungen betreffen, gelten auch für die Welt der LLMs, einschließlich Injektionen oder Datenexfiltration. Es gibt jedoch eine Reihe neuer Bedrohungen, die jetzt aufgrund der Funktionsweise von LLMs relevant sind. So haben Forscher kürzlich eine Schwachstelle in einer KI-Kollaborationsplattform entdeckt, die es ihnen ermöglicht, Modelle zu kapern und unautorisierte Aktionen durchzuführen.
Firewall for AI ist eine fortschrittliche Web Application Firewall (WAF), die speziell auf Anwendungen zugeschnitten ist, die LLMs verwenden. Es wird eine Reihe von Tools umfassen, die vor den Anwendungen eingesetzt werden können, um Schwachstellen zu erkennen und den Anwendungsbetreibern Transparenz zu bieten. Das Toolkit wird Produkte beinhalten, die bereits Bestandteil der WAF sind, wie z. B. Rate Limiting und Sensitive Data Detection, sowie eine neue Schutzschicht, die derzeit entwickelt wird. Diese neue Validierung analysiert den vom Nutzenden übermittelten Prompt, um Versuche der Ausnutzung des Modells zur Datenextraktion und andere Missbrauchsversuche zu erkennen. Indem wir den Umfang des Cloudflare-Netzwerks nutzen, läuft die Firewall for AI so nah wie möglich am Nutzenden. So können wir Angriffe frühzeitig erkennen und sowohl Endnutzende als auch Modelle vor Missbrauch und Angriffen schützen.
Bevor wir uns mit der Funktionsweise und dem vollständigen Funktionsumfang von Firewall for AI befassen, sollten wir zunächst prüfen, was LLMs einzigartig macht und welche Angriffsflächen sie bieten. Wir werden die OWASP Top 10 für LLMs als Referenz verwenden.
Warum unterscheiden sich LLMs von herkömmlichen Anwendungen?
Wenn Sie LLMs als internetbasierte Anwendungen betrachten, gibt es zwei wesentliche Unterschiede im Vergleich zu herkömmlichen Webanwendungen.
Erstens die Art und Weise, wie die Nutzenden mit dem Produkt interagieren. Herkömmliche Anwendungen sind von Natur aus deterministisch. Denken Sie an eine Bankanwendung – sie ist durch eine Reihe von Vorgängen definiert (meinen Kontostand prüfen, eine Überweisung tätigen usw.). Die Sicherheit des Geschäftsvorgangs (und der Daten) kann durch die Kontrolle der von diesen Endpunkten akzeptierten Vorgänge erreicht werden: „GET /balance“ oder „POST /transfer“.
LLM-Vorgänge sind von Haus aus nicht-deterministisch. Zunächst einmal basieren LLM-Interaktionen auf natürlicher Sprache, was die Identifizierung problematischer Anfragen schwieriger macht als der Abgleich von Angriffssignaturen. Außerdem liefern LLMs, sofern eine Antwort nicht zwischengespeichert wird, in der Regel jedes Mal eine andere Antwort – selbst wenn derselbe Eingabeprompt wiederholt wird. Dadurch wird es viel schwieriger, die Art und Weise einzuschränken, wie ein Nutzender mit der Anwendung interagiert. Dies stellt auch für den Nutzenden eine Gefahr dar, da er Fehlinformationen ausgesetzt ist, die das Vertrauen in das Modell schwächen.
Zweitens besteht ein großer Unterschied darin, wie die Ebene der Anwendungssteuerung mit den Daten interagiert. In herkömmlichen Anwendungen ist die Steuerebene (Code) gut von der Datenebene (Datenbank) getrennt. Die definierten Vorgänge sind die einzige Möglichkeit, mit den zugrunde liegenden Daten zu interagieren (z. B. „zeigen Sie mir die Historie meiner Zahlungsvorgänge“). Dadurch können sich Sicherheitsexperten darauf konzentrieren, die Kontrollebene mit Kontrollen und Leitplanken zu versehen und so die Datenbank indirekt zu schützen.
LLMs sind insofern anders, als dass die Trainingsdaten durch den Trainingsprozess Teil des Modells selbst werden. Das macht es extrem schwierig, zu kontrollieren, wie diese Daten als Ergebnis des Prompts eines Nutzers weitergegeben werden. Es werden einige Lösungen auf Architekturebene erforscht, wie z. B. die Aufteilung von LLMs in verschiedene Ebenen und die Trennung von Daten. Es wurde jedoch noch kein Patentrezept gefunden.
Aus der Sicherheitsperspektive ermöglichen diese Unterschiede Angreifern, neue Angriffsvektoren zu entwickeln, die LLMs ins Visier nehmen und von bestehenden Sicherheitstools, die für herkömmliche Webanwendungen entwickelt wurden, womöglich nicht erkannt werden.
OWASP LLM-Schwachstellen
Die OWASP Foundation hat eine Liste der 10 wichtigsten Klassen von Schwachstellen für LLMs veröffentlicht, die einen nützlichen Rahmen für Überlegungen zur Absicherung von Sprachmodellen bietet. Einige der Bedrohungen erinnern an die OWASP Top 10 für Webanwendungen, während andere spezifisch für Sprachmodelle sind.
Ähnlich wie bei Webanwendungen lassen sich einige dieser Schwachstellen am besten beheben, wenn die LLM-Anwendung entworfen, entwickelt und trainiert wird. Zum Beispiel kann ein „Training Data Poisoning“ („Vergiften von Trainingsdaten“) durchgeführt werden, indem Schwachstellen in den Trainingsdatensatz eingeführt werden, der zum Trainieren neuer Modelle verwendet wird. Die vergifteten Informationen werden dann dem Nutzenden präsentiert, wenn das Modell im Einsatz ist. Schwachstellen in der Software-Lieferkette und Unsicheres Plugin-Design sind Schwachstellen in Komponenten, die dem Modell hinzugefügt werden, wie Softwarepakete von Drittanbietern. Und schließlich ist die Verwaltung von Autorisierung und Berechtigungen von entscheidender Bedeutung, wenn es um „Excessive Agency“ („Übermäßiges Vertrauen“), geht, d. h. um Modelle, die ohne Einschränkungen unerlaubte Aktionen innerhalb der gesamten Anwendung oder Infrastruktur durchführen können.
Umgekehrt können „Prompt Injection“ („Prompt-Injektion“), „Modell Denial of Service“, and „Sensitive Information Disclosure“ („Offenlegung sensibler Informationen“) durch den Einsatz einer Proxy-Sicherheitslösung wie Cloudflare Firewall for AI abgewehrt werden. In den folgenden Abschnitten gehen wir näher auf diese Schwachstellen ein und erläutern, wie Cloudflare bestens aufgestellt ist, um sie abzuwehren.
LLM-Bereitstellungen
Die Risiken des Sprachmodells hängen auch vom Bereitstellungsmodell ab. Derzeit gibt es drei wichtige Ansätze für die Bereitstellung: interne, öffentliche und Produkt-LLMs. In allen drei Szenarien müssen Sie die Modelle vor Missbrauch schützen, alle im Modell gespeicherten proprietären Daten schützen und den Nutzenden vor Fehlinformationen oder unangemessenen Inhalten bewahren.
Interne LLMs: Unternehmen entwickeln LLMs, um die Belegschaft bei ihren täglichen Aufgaben zu unterstützen. Diese werden als Assets des Unternehmens betrachtet und sollten für Nicht-Mitarbeitende nicht zugänglich sein. Beispiele hierfür sind ein KI-Kopilot, der auf Verkaufsdaten und Kundeninteraktionen trainiert wurde, um maßgeschneiderte Angebote zu erstellen, oder ein LLM, der auf eine interne Wissensdatenbank trainiert wurde, die von Ingenieuren abgefragt werden kann.
Öffentliche LLMs: Dabei handelt es sich um LLMs, die außerhalb der Grenzen eines Unternehmens genutzt werden können. Oft haben diese Lösungen kostenlose Versionen, die jeder nutzen kann, und sie sind oft auf allgemeines oder öffentliches Wissen trainiert. Beispiele hierfür sind GPT von OpenAI oder Claude von Anthropic.
Produkt-LLM: Aus Sicht eines Unternehmens können LLMs Teil eines Produkts oder einer Dienstleistung sein, die den Kunden angeboten wird. Dabei handelt es sich in der Regel um selbstgehostete, maßgeschneiderte Lösungen, die als Tool zur Interaktion mit den Unternehmensressourcen zur Verfügung gestellt werden können. Beispiele sind Chatbots für den Kundensupport oder Cloudflare AI Assistant.
Aus der Risikoperspektive betrachtet, besteht der Unterschied zwischen Produkt- und öffentlichen LLMs darin, wer von den Auswirkungen erfolgreicher Angriffe betroffen ist. Öffentliche LLMs werden als Bedrohung für den Datenschutz angesehen, da die Daten, die in dem Modell landen, von praktisch jedem eingesehen werden können. Dies ist einer der Gründe, warum viele Unternehmen ihren Mitarbeitenden raten, keine vertraulichen Informationen in Prompts für öffentlich zugängliche Dienste zu verwenden. Produkt-LLMs können als Bedrohung für Unternehmen und deren geistiges Eigentum angesehen werden, wenn die Modelle während der Ausbildung (absichtlich oder versehentlich) Zugang zu geschützten Informationen hatten.
Firewall for AI
Cloudflare Firewall for AI wird wie eine herkömmliche WAF eingesetzt, bei der jede API-Anfrage mit einem LLM-Prompt auf Muster und Signaturen möglicher Angriffe gescannt wird.
Firewall for AI kann vor Modellen eingesetzt werden, die auf der Cloudflare Workers AI-Plattform gehostet werden, oder vor Modellen, die auf einer anderen Infrastruktur von Drittanbietern gehostet werden. Sie kann auch zusammen mit Cloudflare AI Gateway verwendet werden. Kunden können Firewall for AI über die WAF-Kontrollebene steuern und einrichten.
Firewall for AI funktioniert wie eine herkömmliche Web Application Firewall. Sie wird vor einer LLM-Anwendung eingesetzt und scannt jede Anfrage, um Angriffssignaturen zu identifizieren.
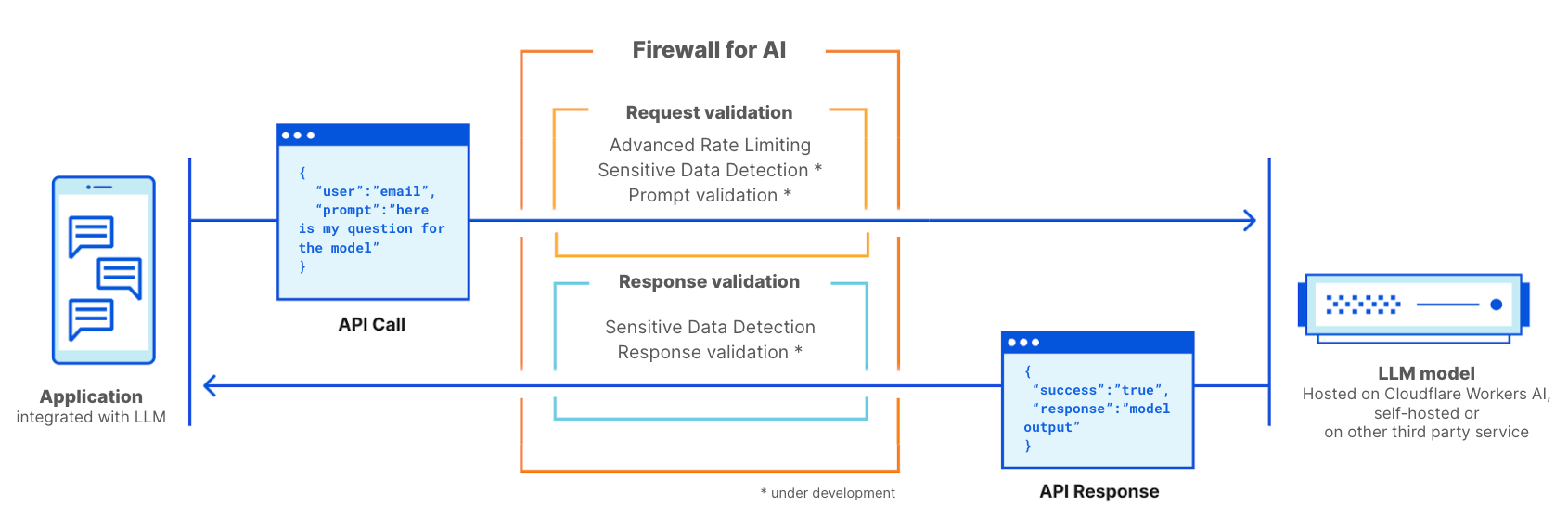
Volumetrische Angriffe verhindern
Eine der von OWASP aufgeführten Bedrohungen ist Model Denial of Service. Ähnlich wie bei herkömmlichen Anwendungen wird ein DoS-Angriff durchgeführt, indem eine außergewöhnlich hohe Menge an Ressourcen verbraucht wird, was zu einer verminderten Servicequalität führt oder möglicherweise die Kosten für den Betrieb des Modells erhöht. Angesichts der umfangreichen Ressourcen, die LLMs für ihre Ausführung benötigen, und der Unvorhersehbarkeit der Eingaben von Nutzern, kann diese Art von Angriff schädlich sein.
Dieses Risiko lässt sich abwehren, indem Sie Richtlinien für Rate Limiting einführen, die die Rate der Anfragen von einzelnen Sessions kontrollieren und somit das Kontextfenster begrenzen. Wenn Sie Ihr Modell heute über Cloudflare als Proxy nutzen, erhalten Sie sofort wirksamen DDoS-Schutz. Sie können auch Rate Limiting und Advanced Rate Limiting verwenden, um die Rate der Anfragen zu verwalten, die Ihr Modell erreichen dürfen, indem Sie eine maximale Rate der Anfragen festlegen, die von einer einzelnen IP-Adresse oder einem API-Schlüssel während einer Session ausgeführt werden kann.
Identifizieren Sie sensible Informationen mit Sensitive Data Detection
Es gibt zwei Anwendungsfälle für sensible Daten, je nachdem, ob Sie Eigentümer des Modells und der Daten sind oder ob Sie Nutzende daran hindern wollen, Daten in öffentliche LLMs zu senden.
Wie von OWASP definiert, kommt es zur Offenlegung sensibler Informationen, wenn LLMs versehentlich vertrauliche Daten in den Antworten preisgeben, was zu unbefugtem Datenzugriff, Verletzungen der Privatsphäre und Sicherheitsverstößen führt. Eine Möglichkeit, dies zu verhindern, besteht darin, strenge Abfragevalidierungen hinzuzufügen. Ein anderer Ansatz besteht darin, zu erkennen, wann personenbezogene Daten (PII) das Modell verlassen. Dies ist z. B. relevant, wenn ein Modell mit einer Wissensdatenbank eines Unternehmens trainiert wurde, die sensible Informationen wie PII (z. B. Sozialversicherungsnummer), geschützten Code oder Algorithmen enthalten kann.
Kunden, die LLM-Modelle hinter Cloudflare WAF verwenden, können den WAF-Regelsatz Sensitive Data Detection (SDD) einsetzen, um bestimmte PII zu identifizieren, die vom Modell in der Antwort zurückgegeben werden. Kunden können die SDD-Treffer auf WAF Security Events überprüfen. Heute wird SDD als eine Reihe von verwalteten Regeln angeboten, die für die Suche nach Finanzdaten (wie Kreditkartennummern) und Secrets (API-Schlüssel) entwickelt wurden. Als Teil der Roadmap planen wir, unseren Kunden die Möglichkeit zu geben, ihre eigenen Fingerprints zu erstellen.
Der andere Anwendungsfall soll verhindern, dass Nutzende PII oder andere sensible Informationen mit externen LLM-Anbietern wie OpenAI oder Anthropic teilen. Um uns vor diesem Szenario zu schützen, planen wir, SDD zu erweitern, um den Eingabeprompt zu scannen und ihr Output in AI Gateway zu integrieren, wo wir neben dem Verlauf des Prompts erkennen, ob bestimmte sensible Daten in der Anfrage enthalten sind. Wir werden zunächst die bestehenden SDD-Regeln verwenden und planen, unseren Kunden die Möglichkeit zu geben, ihre eigenen benutzerdefinierten Signaturen zu schreiben. In diesem Zusammenhang ist die Verschleierung eine weitere Funktion, über die viele Kunden sprechen. Sobald die erweiterte SDD verfügbar ist, können Kunden bestimmte sensible Daten in einem Prompt verschleiern, bevor sie das Modell erreichen. SDD für die Anfragephase wird derzeit entwickelt.
Missbrauch von Modellen verhindern
Der Missbrauch von Modellen ist eine breitere Kategorie von Missbrauch. Dazu gehören Ansätze wie die „Prompt-Injektion“ oder die Übermittlung von Anfragen, die Halluzinationen hervorrufen oder zu Antworten führen, die ungenau, beleidigend, unangemessen oder einfach nur themenfremd sind.
Prompt Injection ist ein Versuch, ein Sprachmodell durch speziell präparierte Eingaben zu manipulieren und so unbeabsichtigte Reaktionen des LLM hervorzurufen. Die Ergebnisse einer Injektion können unterschiedlich sein, von der Extraktion sensibler Informationen bis hin zur Beeinflussung der Entscheidungsfindung durch Nachahmung normaler Interaktionen mit dem Modell. Ein klassisches Beispiel für Prompt Injection ist die Manipulation eines Lebenslaufs, um die Ausgabe von Tools zur Überprüfung von Lebensläufen zu beeinflussen.
Ein häufiger Anwendungsfall, den wir von Kunden unseres AI Gateway hören, ist, dass sie vermeiden möchten, dass ihre Anwendung toxische, beleidigende oder verstörende Sprache erzeugt. Die Risiken, die entstehen, wenn Sie das Ergebnis des Modells nicht kontrollieren, sind u. a. Reputationsschäden und Nachteile für den Nutzenden durch unzuverlässige Antworten.
Diese Art von Missbrauch kann durch eine zusätzliche Schutzschicht vor dem Modell verhindert werden. Diese Schicht kann so trainiert werden, dass sie Injektionsversuche blockiert oder Prompts blockiert, die in Kategorien fallen, die unangemessen sind.
Prompt- und Antwort-Validierung
Firewall for AI führt eine Reihe von Erkennungen durch, die darauf abzielen, Prompt-Injektion-Versuche und andere Missbrauchsversuche zu identifizieren, z. B. um sicherzustellen, dass das Thema innerhalb der vom Modelleigentümer festgelegten Limitationen bleibt. Wie andere bestehende WAF-Funktionen wird Firewall for AI automatisch nach in HTTP-Anfragen eingebetteten Prompts suchen oder es Kunden ermöglichen, Regeln zu erstellen, die darauf basieren, wo im JSON-Body der Anfrage der Prompt zu finden ist.
Sobald diese Funktion aktiviert ist, analysiert die Firewall jeden Prompt und gibt eine Bewertung der Wahrscheinlichkeit ab, dass er bösartig ist. Außerdem wird der Prompt anhand von vordefinierten Kategorien gekennzeichnet. Der Score reicht von 1 bis 99 und gibt die Wahrscheinlichkeit einer Prompt-Injektion an, wobei 1 die höchste Wahrscheinlichkeit darstellt.
Kunden werden WAF-Regeln erstellen können, um Anfragen mit einer bestimmten Punktzahl in einer oder beiden dieser Dimensionen zu blockieren oder zu bearbeiten. Sie können diesen Score mit anderen vorhandenen Signalen (wie Bot Score oder Attack Score) kombinieren, um zu bestimmen, ob die Anfrage das Modell erreichen oder blockiert werden soll. Er könnte zum Beispiel mit einem Bot Score kombiniert werden, um zu erkennen, ob die Anfrage böswillig war und von einer automatisierten Quelle stammt.
Die Erkennung von Prompt-Injektionen und Prompt-Missbrauch ist Teil des Funktionsumfangs von Firewall for AI. Frühe Iteration des Produktdesigns.
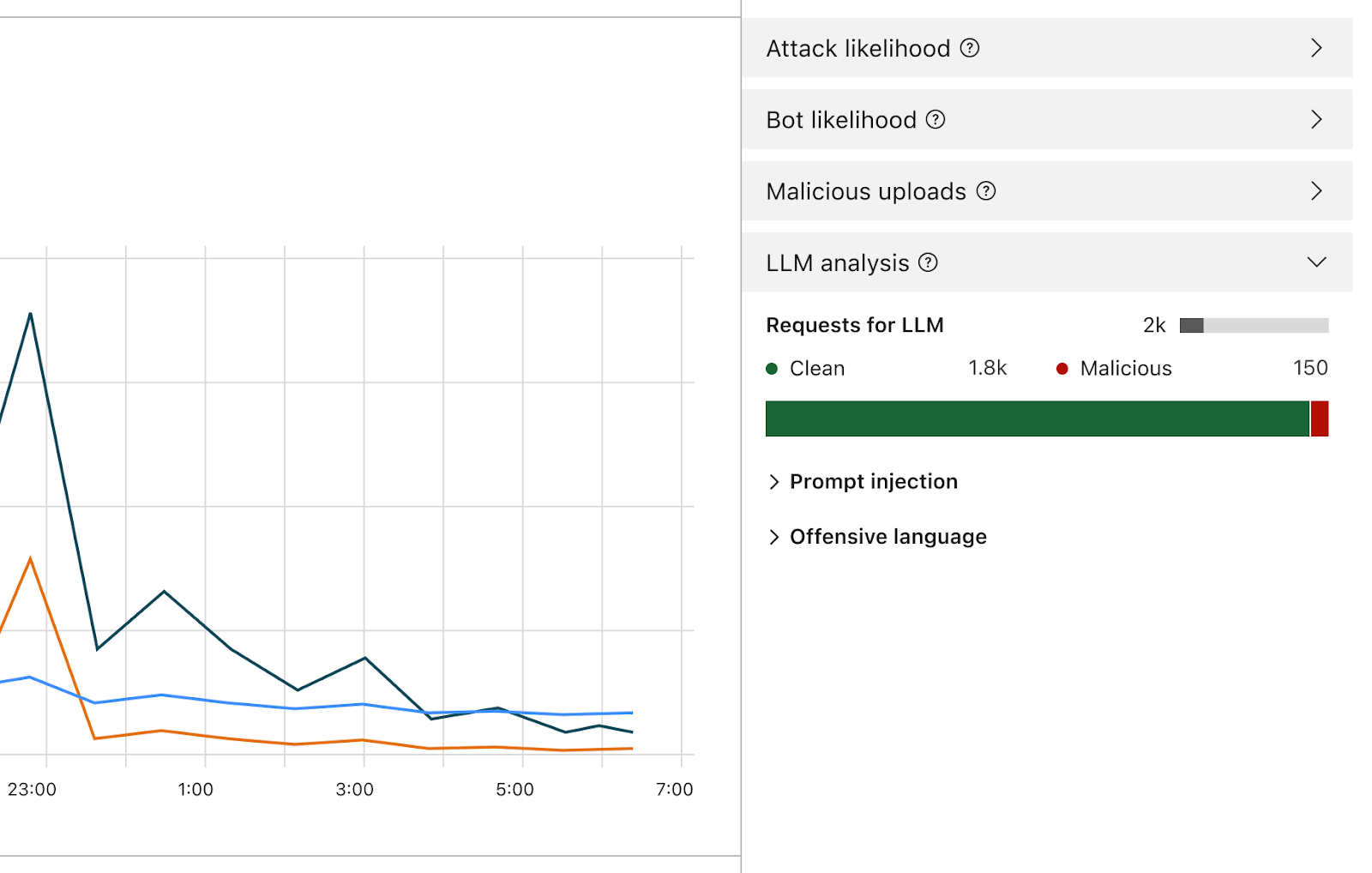
Neben der Bewertung werden wir jedem Prompt Tags zuweisen, die bei der Erstellung von Regeln verwendet werden können, um zu verhindern, dass Prompts, die zu einer dieser Kategorien gehören, ihr Modell erreichen. So können Kunden zum Beispiel Regeln erstellen, um bestimmte Themen zu blockieren. Dazu gehören Prompts mit Wörtern, die als beleidigend eingestuft werden oder beispielsweise mit Religion, sexuellen Inhalten oder Politik in Verbindung stehen.
Wie kann ich Firewall for AI nutzen? Wer erhält Zugang zu diesem Tool?
Enterprise-Kunden mit dem Application Security Advanced-Angebot können sofort mit Advanced Rate Limiting und Sensitive Data Detection (in der Antwortphase) beginnen. Beide Produkte finden Sie im WAF-Bereich des Cloudflare Dashboards. Die Prompt-Validierungsfunktion von Firewall for AI befindet sich derzeit in der Entwicklung und eine Beta-Version wird in den kommenden Monaten für alle Nutzenden von Workers AI freigegeben. Melden Sie sich für die Warteliste an und lassen Sie sich benachrichtigen, sobald die Funktion verfügbar ist.
Fazit
Cloudflare ist einer der ersten Sicherheitsanbieter, der eine Reihe von Tools zur Sicherung von KI-Anwendungen auf den Markt bringt. Mit Firewall for AI können Kunden kontrollieren, welche Prompts und Anfragen ihre Sprachmodelle erreichen, und so das Risiko des Missbrauchs und der Datenexfiltration verringern. Wir halten Sie auf dem Laufenden und berichten bald ausführlicher über die neuesten Entwicklungen im Bereich der Sicherheit für KI-Anwendungen.