


Am 25. August 2023 begannen wir, ungewöhnlich große HTTP-Angriffe auf viele unserer Kunden zu bemerken. Diese Angriffe wurden von unserem automatischen DDoS-System erkannt und abgewehrt. Es dauerte jedoch nicht lange, bis sie rekordverdächtige Ausmaße annahmen und schließlich einen Spitzenwert von knapp über 201 Millionen Anfragen pro Sekunde erreichten. Damit waren sie fast dreimal so groß wie der bis zu diesem Zeitpunkt größte Angriff, den wir jemals verzeichnet hatten.
Besorgniserregend ist die Tatsache, dass der Angreifer in der Lage war, einen solchen Angriff mit einem Botnetz von lediglich 20.000 Rechnern durchzuführen. Es gibt heute Botnetze, die aus Hunderttausenden oder Millionen von Rechnern bestehen. Bedenkt man, dass das gesamte Web in der Regel nur zwischen 1 bis 3 Milliarden Anfragen pro Sekunde verzeichnet, ist es nicht unvorstellbar, dass sich mit dieser Methode quasi die Anzahl aller Anfragen im Internet auf eine kleine Reihe von Zielen konzentrieren ließe.
Erkennen und Abwehren
Dies war ein neuartiger Angriffsvektor in einem noch nie dagewesenen Ausmaß, aber die bestehenden Schutzmechanismen von Cloudflare konnten die Wucht der Angriffe weitgehend bewältigen. Zunächst sahen wir einige Auswirkungen auf den Traffic unserer Kunden – etwa 1 % der Anfragen waren während der ersten Angriffswelle betroffen –, doch heute konnten wir unsere Abwehrmethoden so verfeinern, dass der Angriff für jeden Cloudflare-Kunden gestoppt werden konnte, ohne dass er unsere Systeme beeinträchtigte.
Wir haben diese Angriffe zur gleichen Zeit bemerkt, als zwei andere große Branchenakteure – Google und AWS – dasselbe erlebten. Wir haben daran gearbeitet, die Systeme von Cloudflare zu verstärken, um sicherzustellen, dass alle unsere Kunden heute vor dieser neuen DDoS-Angriffsmethode geschützt sind, ohne dass es Auswirkungen auf die Kunden gibt. Außerdem haben wir gemeinsam mit Google und AWS an einer koordinierten Offenlegung des Angriffs gegenüber den betroffenen Anbietern und Betreibern kritischer Infrastrukturen mitgewirkt.
Dieser Angriff wurde durch den Missbrauch einiger Funktionen des HTTP/2-Protokolls und von Details der Server-Implementierung ermöglicht (siehe CVE-2023-44487 für Details). Da der Angriff eine zugrundeliegende Sicherheitslücke im HTTP/2-Protokoll ausnutzt, glauben wir, dass jeder Anbieter, der HTTP/2 implementiert hat, dem Angriff ausgesetzt ist. Dazu gehört jeder moderne Webserver. Gemeinsam mit Google und AWS haben wir die Angriffsmethode den Anbietern von Webservern offengelegt, von denen wir erwarten, dass sie Patches implementieren werden. Die beste Schutzmaßnahme ist einstweilen die Verwendung eines DDoS-Abwehrdienstes wie Cloudflare vor jedem Web- oder API-Server, der mit dem Internet verbunden ist.
Dieser Beitrag befasst sich mit allen Einzelheiten zum HTTP/2-Protokoll, der Funktion, die Angreifer ausnutzen, um diese massiven Angriffe zu generieren, und den Abwehrstrategien, die wir ergriffen haben, um sicherzustellen, dass alle unsere Kunden geschützt sind. Wir hoffen, dass durch die Bekanntgabe dieser Details andere betroffene Webserver und -dienste die Informationen erhalten, die sie benötigen, um Abwehrstrategien zum Schutz vor dieser Sicherheitslücke zu implementieren. Darüber hinaus können das Team für die HTTP/2-Protokollstandards sowie die Teams, die an künftigen Webstandards arbeiten, diese besser gestalten, um solche Angriffe zu verhindern.
Nähere Einzelheiten zum RST-Angriff
HTTP ist das Anwendungsprotokoll, auf dem das Web basiert. HTTP Semantics ist allen Versionen von HTTP gemeinsam - die Gesamtarchitektur, Terminologie und Protokollaspekte wie Anfrage- und Antwortnachrichten, Methoden, Statuscodes, Header- und Trailer-Felder, Nachrichteninhalte und vieles mehr. Jede einzelne HTTP-Version definiert, wie die Semantik in ein „Austauschformat“ („wire format“) für den Austausch über das Internet umgewandelt wird. So muss ein Client beispielsweise eine Anfragenachricht in binäre Daten serialisieren und senden, die dann vom Server wieder in eine verarbeitbare Nachricht umgewandelt werden.
HTTP/1.1 verwendet eine textuelle Form der Serialisierung. Anfrage- und Antwortnachrichten werden als Strom von ASCII-Zeichen ausgetauscht, die über eine zuverlässige Transportebene wie TCP unter Verwendung des folgenden Formats (wobei CRLF für Carriage-Return und Linefeed steht) gesendet werden:
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]Eine sehr einfache GET-Anfrage für https://blog.cloudflare.com/ würde beim Austausch zum Beispiel so aussehen:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Und die Antwort würde so aussehen:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Dieses Format rahmt (Frame)Nachrichten bei der Übertragung ein, was bedeutet, dass es möglich ist, eine einzige TCP-Verbindung für den Austausch mehrerer Anfragen und Antworten zu verwenden. Das Format erfordert jedoch, dass jede Nachricht als Ganzes gesendet wird. Außerdem ist für die korrekte Zuordnung von Anfragen und Antworten eine strikte Reihenfolge erforderlich, d. h. die Nachrichten werden seriell ausgetauscht und können nicht gemultiplext werden. Zwei GET-Anfragen für https://blog.cloudflare.com/ und https://blog.cloudflare.com/page/2/, wären:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Mit den Antworten:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Webseiten erfordern kompliziertere HTTP-Interaktionen als diese Beispiele. Wenn Sie den Cloudflare-Blog besuchen, lädt Ihr Browser mehrere Skripte, Stile und Medieninhalte. Wenn Sie den Cloudflare-Blog besuchen, lädt Ihr Browser mehrere Skripte, Stile und Medieninhalte. Entweder muss man alle in der Warteschlange befindlichen Antworten für die nicht mehr gewünschte Seite abwarten, bevor Seite 2 überhaupt starten kann, oder man bricht laufende Anfragen ab, indem man die TCP-Verbindung schließt und eine neue Verbindung öffnet. Beides ist nicht gerade zweckmäßig. Browser neigen dazu, diese Beschränkungen zu umgehen, indem sie einen Pool von TCP-Verbindungen (bis zu 6 pro Host) verwalten und eine komplexe Logik für den Versand von Anfragen über den Pool implementieren.
HTTP/2 behebt viele der Probleme mit HTTP/1.1. Jede HTTP-Nachricht wird in einen Satz von HTTP/2-Frames serialisiert, die Typ, Länge, Flags, Stream Identifier (ID) und Payload haben. Die Stream-ID macht deutlich, welche Bytes bei der Übertragung zu welcher Nachricht gehören, was sicheres Multiplexing und Gleichzeitigkeit ermöglicht. Streams sind bidirektional. Clients senden Frames und Server antworten mit Frames, die dieselbe ID verwenden.
In HTTP/2 würde unsere GET-Anfrage für https://blog.cloudflare.com über Stream-ID 1 ausgetauscht, wobei der Client einen HEADERS-Frame sendet und der Server mit einem HEADERS-Frame antwortet, gefolgt von einem oder mehreren DATA-Frames. Client-Anfragen verwenden immer ungerade Stream-IDs, sodass nachfolgende Anfragen die Stream-ID 3, 5 usw. verwenden würden. Die Antworten können in beliebiger Reihenfolge gesendet werden, und Frames aus verschiedenen Streams können ineinander verschachtelt werden.
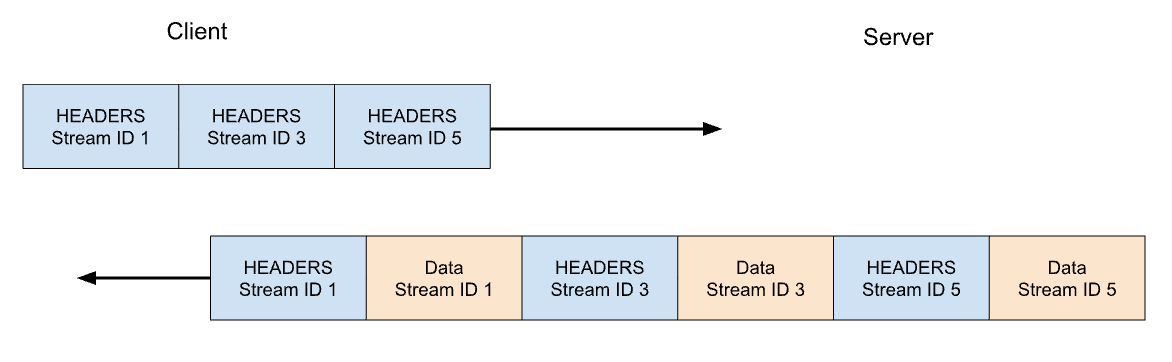
Stream-Multiplexing und Gleichzeitigkeit sind leistungsstarke Funktionen von HTTP/2. Sie ermöglichen eine effizientere Nutzung einer einzigen TCP-Verbindung. HTTP/2 optimiert den Abruf von Ressourcen, insbesondere in Verbindung mit der Priorisierung. Andererseits kann die Erleichterung für Clients, große Mengen an paralleler Arbeit zu starten, den Spitzenbedarf an Serverressourcen im Vergleich zu HTTP/1.1 erhöhen. Dies ist ein naheliegender Vektor für Denial-of-Service.
Um einige Leitlinien bereitzustellen, bietet HTTP/2 einen Begriff für maximal aktive gleichzeitige Streams. Der Parameter SETTINGS_MAX_CONCURRENT_STREAMS ermöglicht es einem Server, sein Limit für die Gleichzeitigkeit bekannt zu geben. Wenn der Server beispielsweise ein Limit von 100 angibt, können zu jedem Zeitpunkt nur 100 Anfragen aktiv sein. Versucht ein Client, einen Stream oberhalb dieser Grenze zu öffnen, muss er vom Server mit einem RST_STREAM-Frame abgelehnt werden. Die Ablehnung eines Streams hat keine Auswirkungen auf die anderen Streams, die sich in der Verbindung befinden.
In Wahrheit ist die Sache ein wenig komplizierter. Streams haben einen Lebenszyklus. Unten sehen Sie ein Diagramm des HTTP/2-Stream-Zustandsrechner. Client und Server verwalten ihre eigenen Ansichten über den Zustand bzw. Status eines Streams. HEADERS-, DATA- und RST_STREAM-Frames lösen Übergänge aus, wenn sie gesendet oder empfangen werden. Obwohl die Ansichten des Stream-Zustands unabhängig sind, werden sie synchronisiert.
HEADERS- und DATA-Frames enthalten ein END_STREAM-Flag, das, wenn es auf den Wert 1 (true) gesetzt ist, einen Übergang des Zustands auslösen kann.
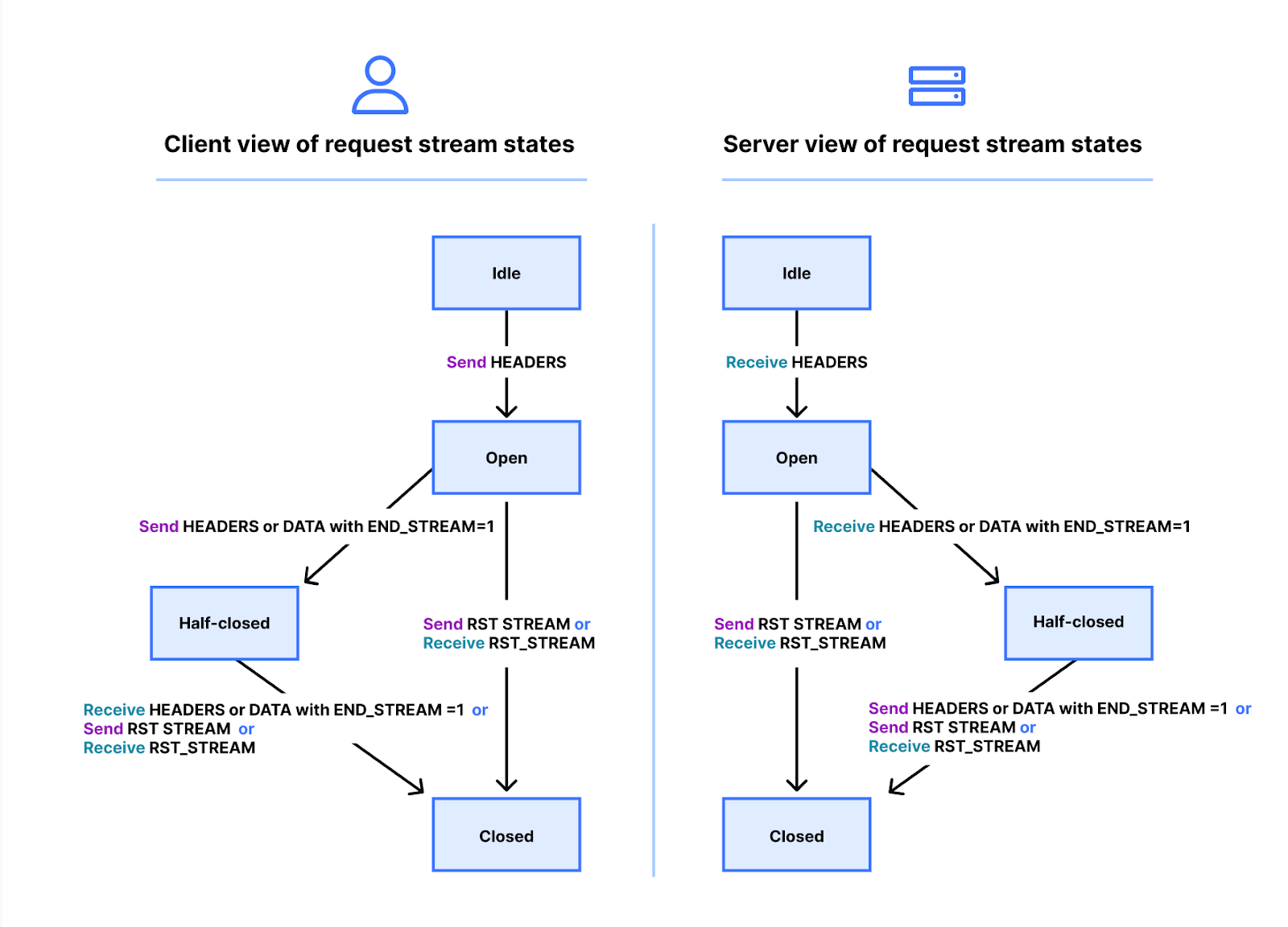
Lassen Sie uns dies anhand eines Beispiels für eine GET-Anfrage ohne Nachrichteninhalt durchgehen. Der Client sendet die Anfrage als HEADERS-Frame, wobei das END_STREAM-Flag auf 1 gesetzt ist. Der Client überführt den Stream zunächst vom Zustand „idle“ in den Zustand „open“ und geht dann sofort in den Zustand „half-closed“ über. Hat der Client den Zustand „half-closed“, bedeutet dies, dass er keine HEADERS oder DATA mehr senden kann, sondern nur noch WINDOW_UPDATE-, PRIORITY- oder RST_STREAM-Frames. Er kann jedoch jeden Frame empfangen.
Sobald der Server den HEADERS-Frame empfängt und analysiert, ändert er den Stream-Zustand von „idle“ zu „open“ und dann zu „half-closed“, damit er mit dem Client übereinstimmt. Der Zustand „half-closed“ bedeutet, dass der Server jeden Frame senden kann, aber nur WINDOW_UPDATE-, PRIORITY- oder RST_STREAM-Frames empfangen kann.
Die Antwort auf die GET-Anfrage enthält Nachrichteninhalte, daher sendet der Server HEADERS mit dem END_STREAM-Flag auf 0, dann DATA mit dem END_STREAM-Flag auf 1. Der DATA-Frame löst auf dem Server den Übergang des Streams von „half-closed“ auf „closed“ aus. Wenn der Client ihn empfängt, geht er ebenfalls in den Zustand „closed“ über. Sobald ein Stream geschlossen ist, können keine Frames mehr gesendet oder empfangen werden.
Wenn man diesen Lebenszyklus zurück in den Kontext der Gleichzeitigkeit überträgt, stellt HTTP/2 fest:
Streams, die sich im Zustand „open“ oder im Zustand „half-closed“ befinden, werden auf die maximale Anzahl von Streams angerechnet, die ein Endpunkt öffnen darf. Streams, die sich in einem dieser drei Zustände befinden, werden auf das in der Einstellung SETTINGS_MAX_CONCURRENT_STREAMS angegebene Limit angerechnet.
Theoretisch ist das Limit für die Gleichzeitigkeit nützlich. Es gibt jedoch praktische Faktoren, die seine Wirksamkeit beeinträchtigen, worauf wir später in diesem Blog eingehen werden.
Widerruf einer HTTP/2-Anfrage
Vorhin haben wir über den Widerruf von gerade in Bearbeitung befindlichen Client-Anfragen gesprochen. HTTP/2 unterstützt dies auf wesentlich effizientere Weise als HTTP/1.1. Anstatt die gesamte Verbindung zu unterbrechen, kann ein Client einen RST_STREAM-Frame für einen einzelnen Stream senden. Dadurch wird der Server angewiesen, die Bearbeitung der Anfrage zu beenden und die Antwort abzubrechen, wodurch Serverressourcen frei werden und keine Bandbreite verschwendet wird.
Betrachten wir unser vorheriges Beispiel mit 3 Anfragen. Dieses Mal widerruft der Client die Anfrage auf Stream 1, nachdem alle HEADERS gesendet wurden. Der Server analysiert diesen RST_STREAM-Frame, bevor er bereit ist, die Antwort zu übermitteln, und antwortet stattdessen nur auf Stream 3 und 5:
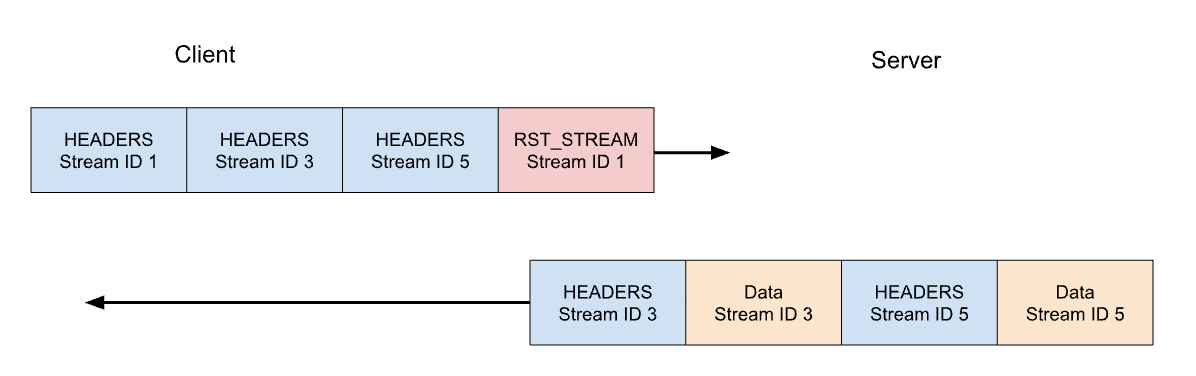
Der Widerruf von Anfragen ist eine nützliche Funktion. Beim Scrollen einer Webseite mit mehreren Bildern kann ein Webbrowser beispielsweise Bilder, die außerhalb des Sichtfensters liegen, löschen, sodass Bilder, die in das Sichtfenster gelangen, schneller geladen werden können. HTTP/2 macht dieses Verhalten im Vergleich zu HTTP/1.1 wesentlich effizienter.
Ein widerrufener Anfrage-Stream durchläuft den Lebenszyklus des Streams sehr schnell. Die HEADERS des Clients mit dem auf 1 gesetzten END_STREAM-Flag wechseln den Zustand von „idle“ zu „open“ zu „half-closed“, dann bewirkt RST_STREAM sofort einen Übergang von „half-closed“ zu „closed“.

Erinnern Sie sich, dass nur Streams, die sich im „open“ oder „half-closed“ Zustand befinden, auf das Limit für die Gleichzeitigkeit von Streams angerechnet werden. Wenn ein Client einen Stream abbricht, erhält er sofort die Möglichkeit, an dessen Stelle einen anderen Stream zu öffnen und kann sofort eine weitere Anfrage senden. Genau darum funktioniert CVE-2023-44487.
Schnelles Reset führt zu Denial of Service
Der Widerruf von HTTP/2-Anfragen kann dazu missbraucht werden, eine unbegrenzte Anzahl von Streams schnell zurückzusetzen. Wenn ein HTTP/2-Server in der Lage ist, vom Client gesendete RST_STREAM-Frames zu verarbeiten und den Zustand schnell genug abzubauen, stellen solche schnellen Resets kein Problem dar. Problematisch wird es dann, wenn es bei den Aufräumarbeiten zu Verzögerungen oder Resets kommt.Der Client kann so viele Anfragen stellen, dass sich ein Rückstau bildet, der zu einem übermäßigen Ressourcenverbrauch auf dem Server führt.
Eine gängige HTTP-Bereitstellungsarchitektur besteht darin, einen HTTP/2-Proxy oder Load-Balancer vor anderen Komponenten zu betreiben. Wenn eine Client-Anfrage eintrifft, wird sie schnell abgewickelt und die eigentliche Arbeit wird als asynchrone Aktivität an anderer Stelle erledigt. So kann der Proxy den Client-Traffic sehr effizient verarbeiten. Diese Trennung kann es dem Proxy jedoch erschweren, die in Bearbeitung befindlichen Aufträge aufzuräumen. Daher ist es bei diesen Bereitstellungen wahrscheinlicher, dass es zu Problemen durch schnelle Resets kommt.
Wenn die Reverse-Proxies von Cloudflare eingehenden HTTP/2-Client-Traffic verarbeiten, kopieren sie die Daten aus dem Socket der Verbindung in einen Puffer und verarbeiten diese gepufferten Daten der Reihe nach. Beim Lesen jeder Anfrage (HEADERS- und DATA-Frames) wird diese an einen Upstream-Service weitergeleitet. Wenn RST_STREAM-Frames gelesen werden, wird der lokale Zustand für die Anfrage abgebaut und der vorgelagerte Dienst wird benachrichtigt, dass die Anfrage abgebrochen wurde. Dieser Vorgang wird so lange wiederholt, bis der gesamte Puffer verbraucht ist. Diese Logik kann jedoch missbraucht werden: Wenn ein böswilliger Client eine enorme Kette von Anfragen und Resets zu Beginn einer Verbindung sendet, würden unsere Server sie alle eifrig lesen und die vorgelagerten Server so stark belasten, dass sie keine neuen eingehenden Anfragen mehr verarbeiten können.
Es ist wichtig hervorzuheben, dass die Gleichzeitigkeit von Streams allein das schnelle Reset nicht abwehren kann. Der Client kann Anfragen abwälzen, um hohe Anfrageraten zu erzeugen, unabhängig von dem vom Server gewählten Wert von SETTINGS_MAX_CONCURRENT_STREAMS.
Rapid Reset genau analysiert

Das ist ein bisschen schwierig zu sehen, weil es viele Bilder gibt. Mit dem Wireshark-Tool Statistik > HTTP2 erhalten wir einen schnellen Überblick:
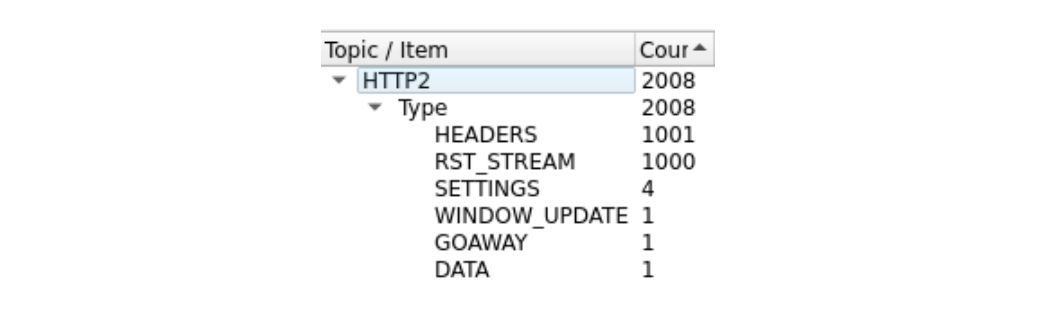
Der erste Frame in dieser Aufzeichnung, in Paket 14, ist der SETTINGS-Frame des Servers, der eine maximale Anzahl an gleichzeitigen Stream von 100 angibt. In Paket 15 sendet der Client einige Kontrollframes und beginnt dann mit Anfragen, die schnell zurückgesetzt werden. Der erste HEADERS-Frame ist 26 Byte lang, alle folgenden HEADERS sind nur 9 Byte lang. Dieser Größenunterschied ist auf eine Komprimierungstechnologie namens HPACK. zurückzuführen. Insgesamt enthält Paket 15 dabei 525 Anfragen, die bis zum Stream 1051 reichen.
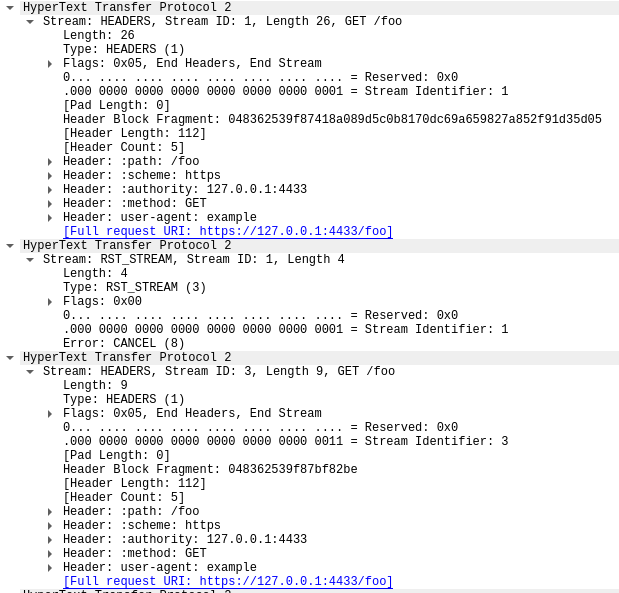
Interessanterweise passt der RST_STREAM für Stream 1051 nicht in Paket 15, so dass der Server in Paket 16 mit einer 404-Antwort antwortet. In Paket 17 sendet der Client dann das RST_STREAM, bevor er mit dem Senden der restlichen 475 Anfragen fortfährt.
Beachten Sie, dass der Server zwar 100 gleichzeitige Streams ankündigte, die beiden vom Client gesendeten Pakete jedoch viel mehr HEADERS-Frames als diese Zahl enthielten. Der Client musste nicht auf den Antwort-Traffic des Servers warten, er war lediglich durch die Größe der Pakete begrenzt, die er senden konnte. In dieser Aufzeichnung sind keine RST_STREAM-Frames des Servers zu sehen, was darauf hindeutet, dass der Server keinen Verstoß gegen das Limit der Gleichzeitigkeit von Streams festgestellt hat.
Auswirkungen auf Kunden
Wie bereits erwähnt, werden vorgelagerte Dienste benachrichtigt, wenn Anfragen abgebrochen werden, und können diese abbrechen, bevor sie zu viele Ressourcen dafür verschwenden. Dies war bei diesem Angriff der Fall, bei dem die meisten bösartigen Anfragen nie an die Ursprungsserver weitergeleitet wurden. Die schiere Größe dieser Angriffe hatte jedoch einige Auswirkungen.
Erstens erreichten die eingehenden Anfragen höhere Spitzenwerte als jemals zuvor, und die Clients meldeten vermehrt 502-Fehler. Dies geschah in unseren am stärksten betroffenen Rechenzentren, da sie Mühe hatten, alle Anfragen zu verarbeiten. Unser Netzwerk ist zwar für große Angriffe ausgelegt, aber diese spezielle Sicherheitslücke deckte eine Schwäche in unserer Infrastruktur auf. Werfen wir einen genaueren Blick auf die Details, wobei wir uns darauf konzentrieren, wie eingehende Anfragen verarbeitet werden, wenn sie eines unserer Rechenzentren erreichen:
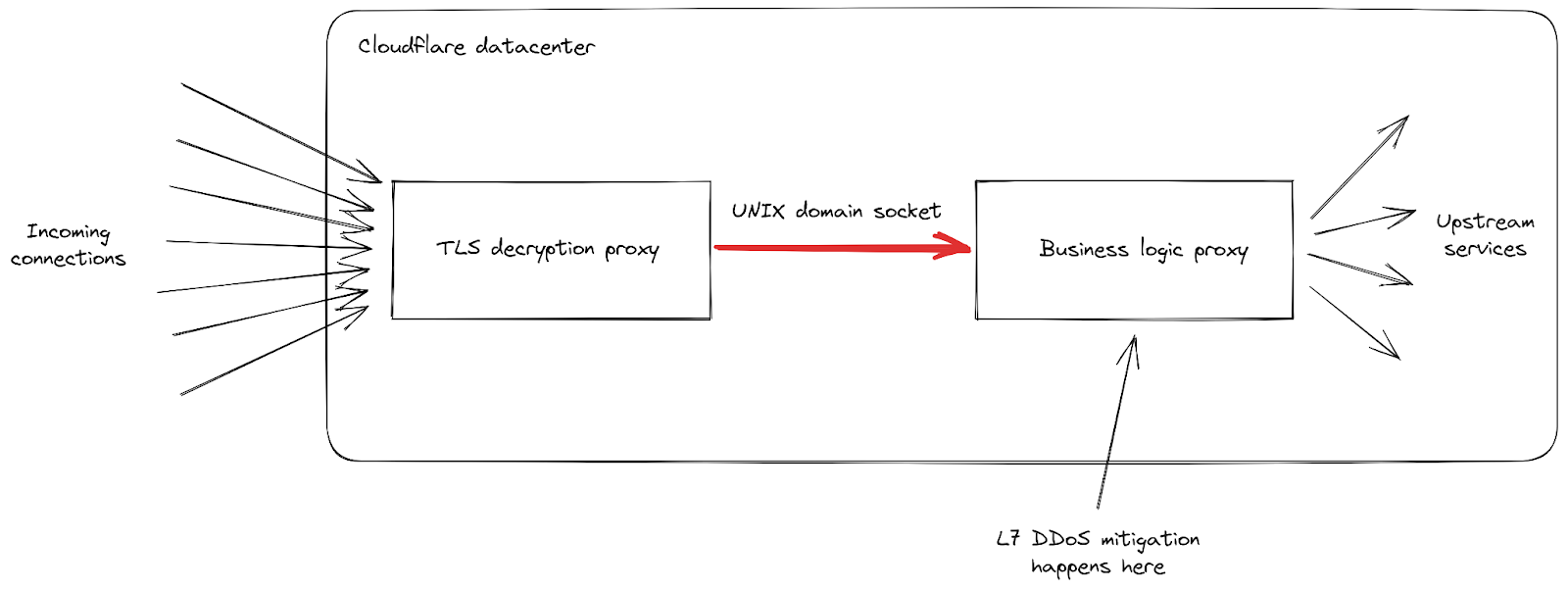
Wir sehen, dass unsere Infrastruktur aus einer Kette verschiedener Proxy-Server mit unterschiedlichen Zuständigkeiten besteht. Wenn sich ein Client mit Cloudflare verbindet, um HTTPS-Traffic zu senden, trifft er zunächst auf unseren TLS-Entschlüsselungs-Proxy: Er entschlüsselt den TLS-Traffic, verarbeitet den HTTP-1-, -2- oder -3-Traffic und leitet ihn dann an unseren Proxy für die „Geschäftslogik“ weiter. Dieser ist dafür zuständig, alle Einstellungen für jeden Kunden zu laden und dann die Anfragen korrekt an andere vorgelagerte Dienste weiterzuleiten – und, was in unserem Fall noch wichtiger ist, er ist auch für die Sicherheitsfunktionen zuständig. Hier wird die L7-Angriffsabwehr abgewickelt.
Das Problem bei diesem Angriffsvektor ist, dass er bei jeder einzelnen Verbindung sehr schnell sehr viele Anfragen senden kann. Jede dieser Anfragen musste an den Proxy für die Geschäftslogik weitergeleitet werden, bevor wir die Möglichkeit hatten, sie zu blockieren. Da der Anfragedurchsatz unsere Proxy-Kapazität überstieg, erreichte die Verbindungsleitung zwischen diesen beiden Diensten bei einigen unserer Server ihre Belastungsgrenze.
Wenn dies geschieht, kann der TLS-Proxy keine Verbindung mehr zu seinem vorgeschalteten Proxy herstellen, weshalb einige Clients bei den schwerwiegendsten Angriffen eine einfache „502 Bad Gateway“-Fehlermeldung erhielten. Es ist wichtig zu beachten, dass die Protokolle, die zur Erstellung von HTTP-Analysen verwendet werden, ab sofort auch von unserem Proxy für die Geschäftslogik ausgegeben werden. Dies hat zur Folge, dass diese Fehler im Cloudflare-Dashboard nicht sichtbar sind. Unsere internen Dashboards zeigen, dass etwa 1 % der Anfragen während der ersten Angriffswelle (bevor wir Abwehrmaßnahmen ergriffen) betroffen waren, mit Spitzenwerten von etwa 12 % für einige Sekunden während der schwerwiegendsten Angriffswelle am 29. August. Das folgende Diagramm zeigt das Verhältnis dieser Fehler über einen Zeitraum von zwei Stunden, in dem dies geschah:
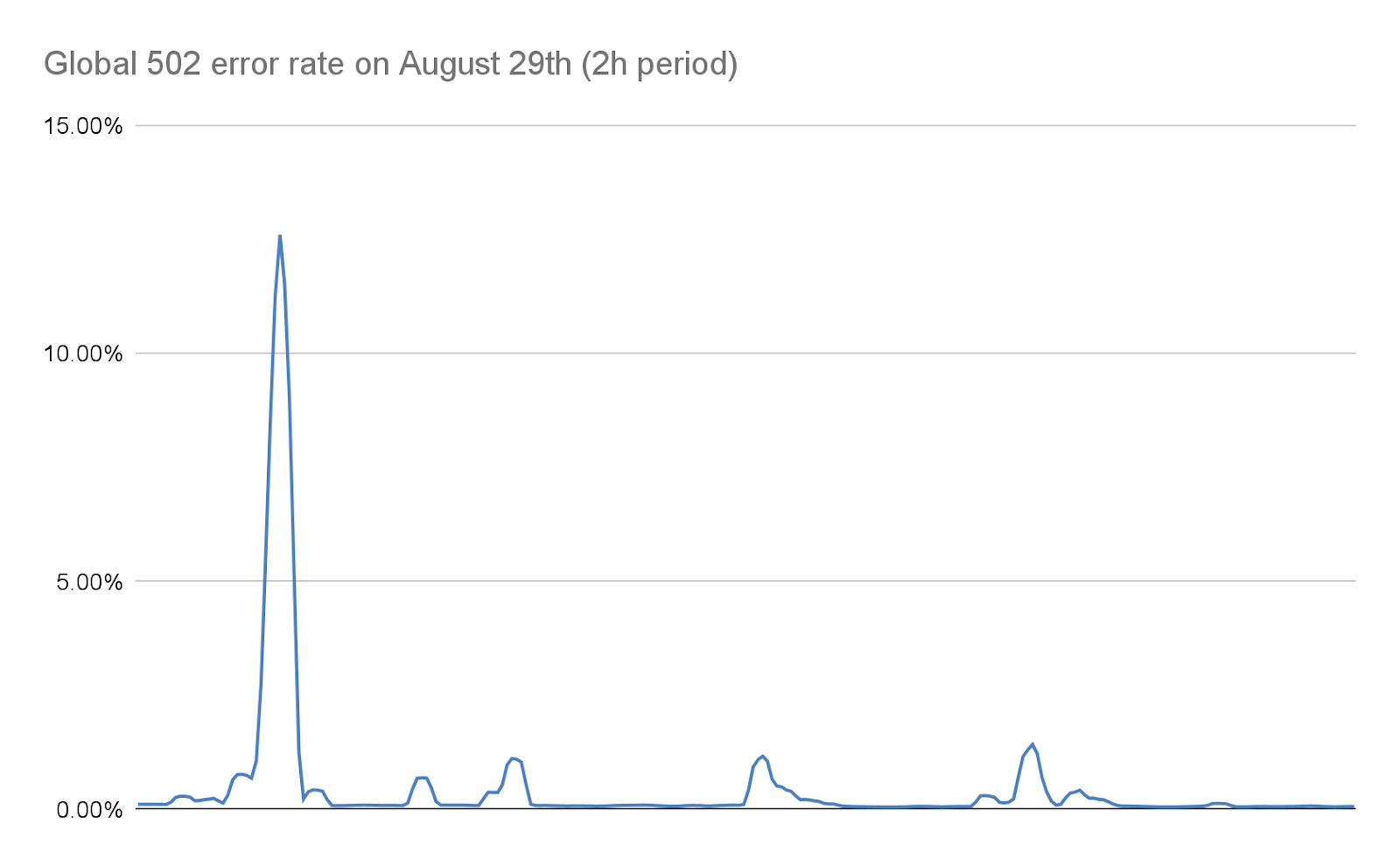
In den darauffolgenden Tagen haben wir hart daran gearbeitet, diese Zahl drastisch zu reduzieren, wie in diesem Beitrag näher erläutert wird. Dank der Änderungen in unserem Stack und unserer Abwehreinrichtungen, die die Größe dieser Angriffe erheblich reduzieren, liegt diese Zahl heute praktisch bei null:
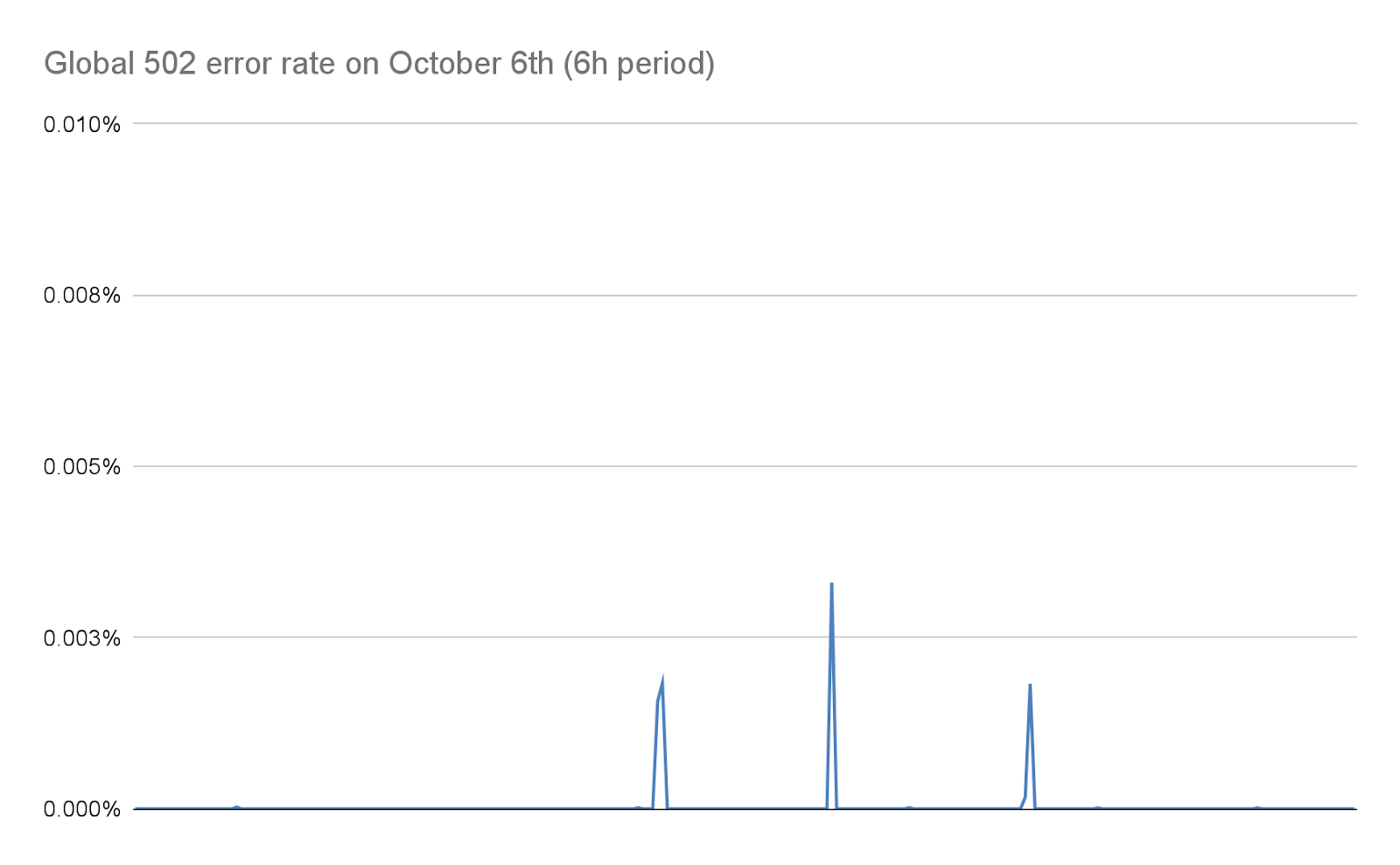
499-Fehler und die Herausforderungen für die Gleichzeitigkeit von HTTP/2-Streams
Ein weiteres Phänomen, von dem einige Kunden berichten, ist die Zunahme von 499.Fehlermeldungen. Die Ursache hierfür ist etwas anders und hängt mit der maximalen Anzahl gleichzeitiger Streams in einer HTTP/2-Verbindung zusammen, die weiter oben in diesem Beitrag beschrieben wurde.
HTTP/2-Einstellungen werden zu Beginn einer Verbindung über SETTINGS-Frames ausgetauscht. Wird kein expliziter Parameter angegeben, gelten die Standardwerte. Sobald ein Client eine HTTP/2-Verbindung aufgebaut hat, kann er auf die SETTINGS eines Servers warten (langsam) oder er kann die Standardwerte annehmen und mit den Anfragen beginnen (schnell). Für SETTINGS_MAX_CONCURRENT_STREAMS ist der Standardwert praktisch unbegrenzt (Stream-IDs verwenden einen 31-Bit-Zahlenraum, und Anfragen verwenden ungerade Zahlen, sodass das tatsächliche Limit bei 1073741824 liegt). In der Spezifikation wird empfohlen, dass ein Server nicht weniger als 100 Streams anbietet. Clients sind in der Regel auf Schnelligkeit bedacht und warten daher nicht auf Servereinstellungen, was zu einer Art Wettlauf führt. Clients wetten darauf, welchen Grenzwert der Server auswählt; wenn sie sich irren, wird die Anfrage abgelehnt und muss erneut gestellt werden. Auf 1073741824 zu wetten ist ein bisschen albern. Stattdessen beschließen viele Clients, sich auf die Ausgabe von 100 gleichzeitigen Streams zu beschränken, in der Hoffnung, dass die Server die empfohlene Spezifikation befolgen. Wenn die Server einen Wert unter 100 wählen, schlägt dieses Client-Ratespiel fehl und die Streams werden zurückgesetzt.
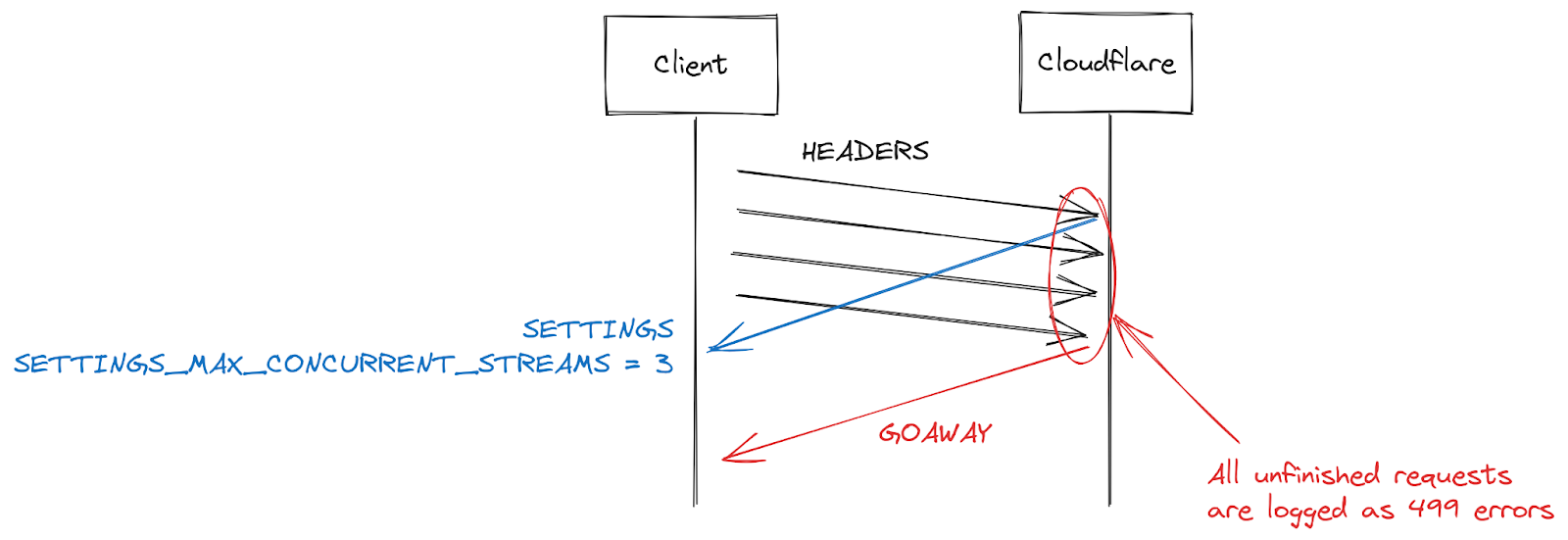
Es gibt viele Gründe, warum ein Server einen Stream bei Überschreitung des Limits für die Anzahl gleichzeitiger Streams zurücksetzen kann. HTTP/2 ist streng und verlangt, dass ein Stream geschlossen wird, wenn Parsing- oder Logikfehler auftreten. 2019 entwickelte Cloudflare mehrere Abwehrmaßnahmen als Reaktion auf HTTP/2 DoS-Schwachstellen. Mehrere dieser Schwachstellen wurden durch das Fehlverhalten eines Clients verursacht, was den Server dazu veranlasste, einen Stream zurückzusetzen. Eine sehr effektive Strategie, um solche Clients einzudämmen, besteht darin, die Anzahl der Server-Resets während einer Verbindung zu zählen und, wenn diese einen bestimmten Schwellenwert überschreitet, die Verbindung mit einem GOAWAY-Frame zu schließen. Legitime Clients machen vielleicht ein oder zwei Fehler während einer Verbindung, und das ist akzeptabel. Ein Client, der zu viele Fehler macht, ist wahrscheinlich entweder defekt oder böswillig; das Schließen der Verbindung ist in beiden Fällen zielführend.
Als Reaktion auf DoS-Angriffe, die durch CVE-2023-44487, ermöglicht wurden, hat Cloudflare die Anzahl der gleichzeitig zugelassenen Streams auf 64 reduziert. Vor dieser Änderung war uns nicht bewusst, dass Clients nicht auf SETTINGS warten und stattdessen für die maximale Anzahl gleichzeitiger Streams 100 annehmen. Einige Webseiten, wie z. B. eine Bildergalerie, veranlassen einen Browser in der Tat dazu, gleich zu Beginn einer Verbindung 100 Anfragen zu senden. Leider mussten die 36 Streams, die über unserem Limit lagen, alle zurückgesetzt werden, was unsere durch Zählung aktivierten Abwehrmaßnahmen auslöste. Das bedeutete, dass wir die Verbindungen von legitimen Clients beendeten, was zu einem kompletten Seitenladefehler führte. Als wir dieses Interoperabilitätsproblem erkannten, änderten wir die maximale Anzahl der gleichzeitig zugelassenen Streams auf 100.
Diese Schritte hat Cloudflare gesetzt
2019 wurden mehrere DoS-Schwachstellen im Zusammenhang mit Implementierungen von HTTP/2 aufgedeckt. Cloudflare hat daraufhin eine Reihe von Erkennungs- und Abwehrmaßnahmen entwickelt und implementiert. CVE-2023-44487 ist eine andere Ausprägung der HTTP/2-Schwachstelle. Um sie abzuwehren, konnten wir jedoch die bestehenden Schutzmaßnahmen erweitern, um vom Client gesendete RST_STREAM-Frames zu überwachen und Verbindungen zu schließen, wenn sie missbräuchlich verwendet werden. Legitime Client-Nutzungen für RST_STREAM sind davon nicht betroffen.
Neben einer direkten Korrektur haben wir mehrere Verbesserungen an der HTTP/2-Frame-Verarbeitung des Servers und am Code für die Anfragenabwicklung vorgenommen. Darüber hinaus wurden die Warteschlangen und die Scheduling-Funktion des Servers für die Geschäftslogik verbessert, um unnötige Arbeit zu vermeiden und die Reaktionsfähigkeit bei Widerrufen zu verbessern. Dadurch werden die Auswirkungen verschiedener potenzieller Missbrauchsmuster verringert und der Server erhält mehr Raum, um Anfragen zu bearbeiten, bevor er ausgelastet ist.
Angriffe einfacher abwehren
Cloudflare verfügte bereits über Systeme, um sehr große Angriffe mit weniger kostspieligen Methoden effizient abwehren zu können. Eines dieser Systeme heißt „IP Jail“ (weil IPs hier quasi „gefangen genommen“ werden). Bei hypervolumetrischen Angriffen sammelt dieses System die am Angriff beteiligten Client-IPs und verhindert, dass sie sich mit dem angegriffenen Objekt verbinden, entweder auf IP-Ebene oder in unserem TLS-Proxy. Dieses System benötigt jedoch einige Sekunden, um seine volle Wirkung zu entfalten; während dieser kostbaren Sekunden sind die Ursprünge bereits geschützt, aber unsere Infrastruktur muss immer noch alle HTTP-Anfragen aufnehmen. Da dieses neue Botnetz praktisch keine Anlaufzeit hat, müssen wir Angriffe neutralisieren können, bevor sie zu einem Problem werden können.
Zu diesem Zweck haben wir das IP-Jail-System erweitert, um unsere gesamte Infrastruktur zu schützen: Sobald eine IP darin „gefangen“ ist, kann sie sich nicht nur nicht mehr mit der angegriffenen Domain verbinden, sondern wir verbieten den entsprechenden IPs für einige Zeit auch die Nutzung von HTTP/2 für jede andere auf Cloudflare gehostete Domain. Da derartige Protokollmissbräuche mit HTTP/1.x nicht möglich sind, schränkt dies die Möglichkeiten des Angreifers ein, groß angelegte Angriffe auszuführen, während ein legitimer Client, der dieselbe IP-Adresse nutzt, in dieser Zeit nur einen sehr geringen Performance-Verlust erleiden würde. IP-basierte Abwehrmaßnahmen sind ein sehr hartes Mittel – deshalb müssen wir bei ihrem Einsatz in diesem Ausmaß äußerst vorsichtig sein und versuchen, Fehlalarme so weit wie möglich zu vermeiden. Außerdem ist die Lebensdauer einer bestimmten IP in einem Botnetz in der Regel kurz, so dass jede langfristige Abwehrmaßnahme wahrscheinlich mehr schadet als nützt. Die folgende Grafik zeigt den Wechsel der IPs bei den von uns beobachteten Angriffen:
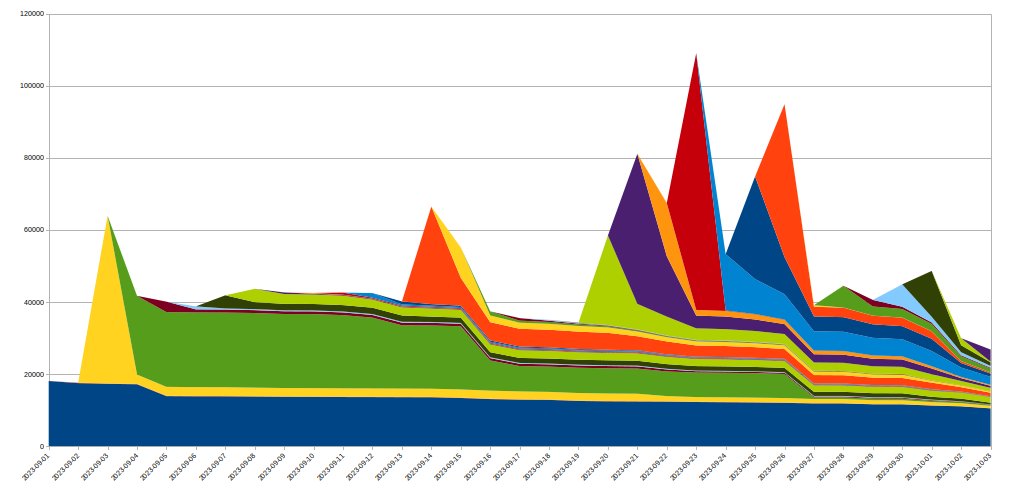
Wir sehen: Viele neue IPs, die an einem bestimmten Tag entdeckt werden, verschwinden sehr schnell wieder.
Da alle diese Aktionen in unserem TLS-Proxy am Anfang unserer HTTPS-Pipeline stattfinden, spart dies im Vergleich zu unserem regulären L7-Abwehrsystem erhebliche Ressourcen. Dadurch konnten wir diese Angriffe viel besser abwehren, und die Zahl der zufälligen 502-Fehler, die von diesen Botnetzen verursacht werden, ist jetzt auf null gesunken.
Verbesserungen der Beobachtbarkeit
Auch im Bereich der Beobachtbarkeit nehmen wir Veränderungen vor. Es ist nicht zufriedenstellend, wenn Clients Fehler erhalten, ohne dass diese in der Kundenanalyse sichtbar sind. Glücklicherweise wurde bereits lange vor den jüngsten Angriffen ein Projekt zur Überarbeitung dieser Systeme eingeleitet. Damit kann jeder Dienst innerhalb unserer Infrastruktur seine eigenen Daten protokollieren, anstatt sich auf unseren Proxy für die Geschäftslogik zu verlassen, der die Protokolldaten konsolidiert und ausgibt. Dieser Vorfall hat gezeigt, wie wichtig diese Arbeit ist, und wir intensivieren unsere Bemühungen.
Wir arbeiten auch an einer besseren Protokollierung auf Verbindungsebene, damit wir solche Protokollmissbräuche viel schneller erkennen und unsere Fähigkeiten zur DDoS-Abwehr verbessern können.
Fazit
Auch wenn dies der jüngste rekordverdächtige Angriff war, wissen wir, dass es nicht der letzte sein wird. Die Angriffe werden immer raffinierter. Darum arbeiten wir bei Cloudflare unermüdlich daran, neue Bedrohungen proaktiv zu identifizieren und Gegenmaßnahmen in unserem globalen Netzwerk zu implementieren, damit unsere Millionen von Kunden sofort und automatisch geschützt sind.
Seit 2017 bietet Cloudflare allen Kunden kostenlosen und zeitlich unbefristeten DDoS-Schutz ohne Volumensbegrenzung. Darüber hinaus bieten wir eine Reihe zusätzlicher Sicherheitsfunktionen, die den Bedürfnissen von Unternehmen jeder Größe entsprechen. Kontaktieren Sie uns, wenn Sie sich nicht sicher sind, ob Sie geschützt sind, oder wenn Sie wissen möchten, wie Sie sich schützen können.