

Cloudflare 採取各種措施來確保自如地應對基礎結構所有層級的失敗。其中包括 Kafka,我們會將其用於傳送時效性電子郵件和警示等關鍵工作流程。
有關如何確保利用 Kafka 的應用程式狀況良好以便它們能夠始終運作,我們學了很多。眾所周知,實施應用程式健康情況檢查非常之難:哪些因素可以判定應用程式狀況良好?如何保持服務始終運作?
我們可以採取多種實施方式。我們將討論的一種方法,可幫助我們大大降低發生應用程式狀況不良事件的頻率,同時減少所需的人工干預。
Kafka 在 Cloudflare
Cloudflare 是 Kafka 的一個大型採用者。由於 Kafka 具有非同步性和可靠性,我們使用它來分離服務。藉助它,不同的團隊能夠有效地工作,而無需建立彼此依賴的關係。您還可以在這篇文章中,深入瞭解 Cloudflare 其他團隊如何使用 Kafka。
Kafka 用於傳送和接收訊息。訊息代表某種事件,例如信用卡付款或在您的平台中建立的新使用者的詳細資料。這些訊息有多種表示方式:JSON、Protobuf、Avro 等。
Kafka 依主題組織訊息。主題是已排序的事件記錄,其中每條訊息都以一個漸進式位移來標示。當事件由外部系統寫入時,則會將其附加到該主題的末尾。依預設,不會從主題中刪除這些事件(可套用保留)。
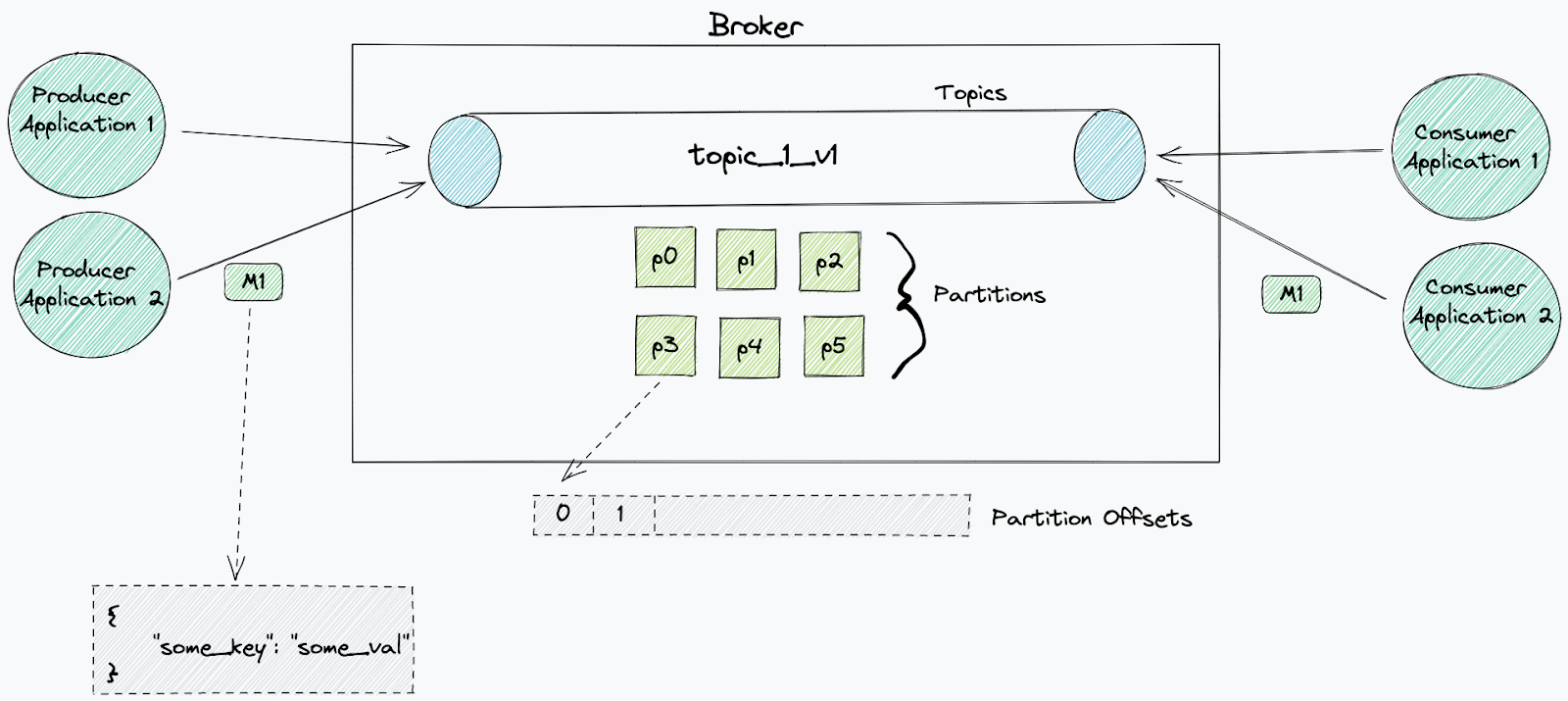
主題以記錄檔的形式儲存在磁碟上,大小是有限的。磁碟分割是一種系統性方法,可將一個主題記錄檔分為多個記錄檔,每個記錄檔可以託管在不同的伺服器上,以便支援擴展主題。
主題由 Kafka 叢集中的代理程式–節點來管理。它們負責將新事件寫入磁碟分割、提供讀取並在它們之間複寫磁碟分割。
訊息可由個別取用者或經過協調的取用者群組(稱為取用者群組)取用。
取用者使用的唯一 ID(取用者 ID)可讓代理程式將他們識別為從特定主題取用的應用程式。
每個主題都可以由無限數量的不同取用者讀取,但他們必須使用不同的 ID。每個取用者都可以根據自己需要的次數重新顯示相同的訊息。
當取用者開始從一個主題取用時,它將從選定的位移開始,處理每個磁碟分割中的所有訊息。透過取用者群組,磁碟分割會在群組中的每個取用者之間進行分割。此分割由取用者群組負責人來判定。該負責人將接收有關該群組中其他取用者的資訊,並決定哪些取用者將從哪些磁碟分割接收訊息(磁碟分割策略)。
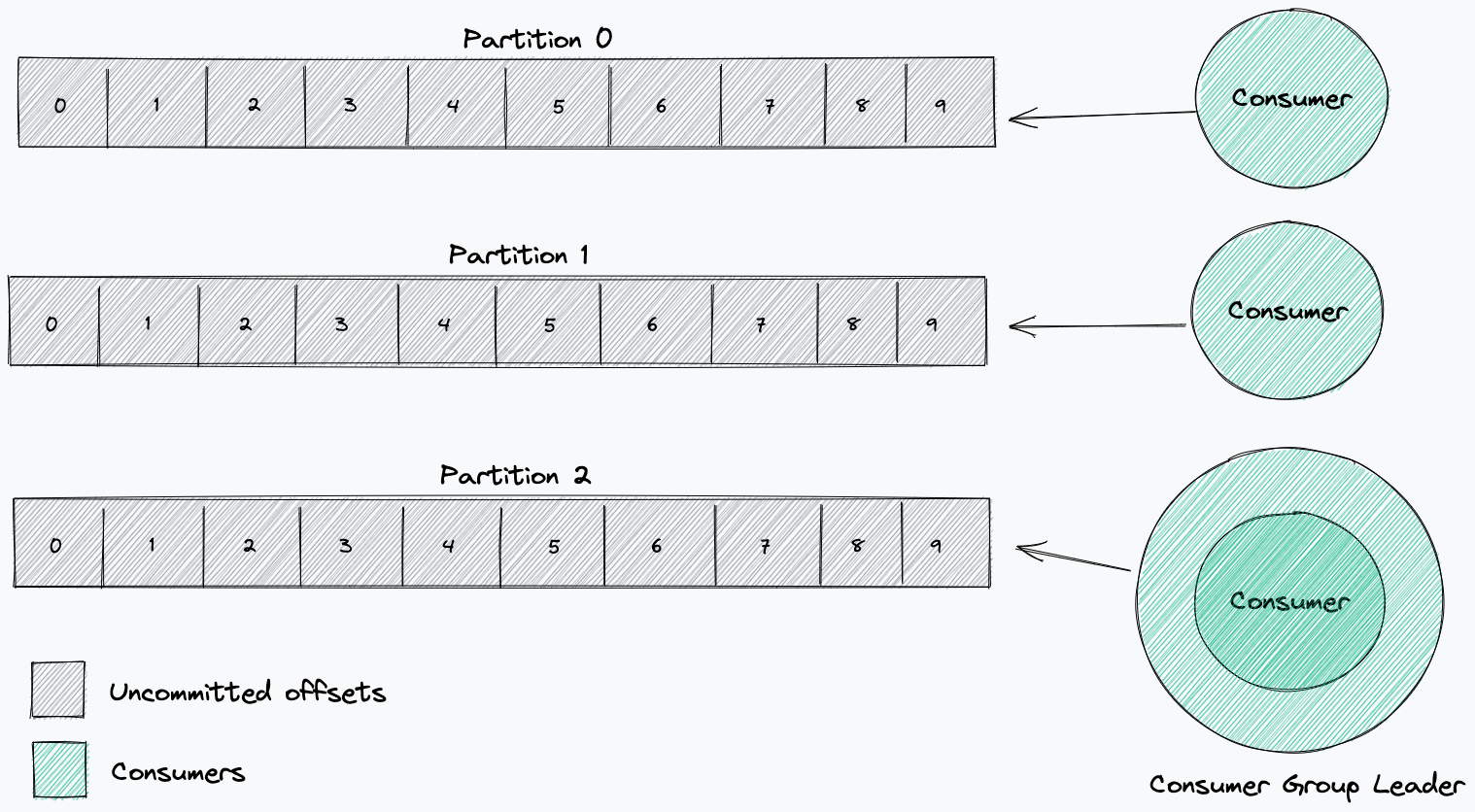
取用者認可的位移能夠表明取用者是否按預期工作。取用者及其取用者群組透過認可已處理的位移,向代理程式報告他們已處理特定訊息。
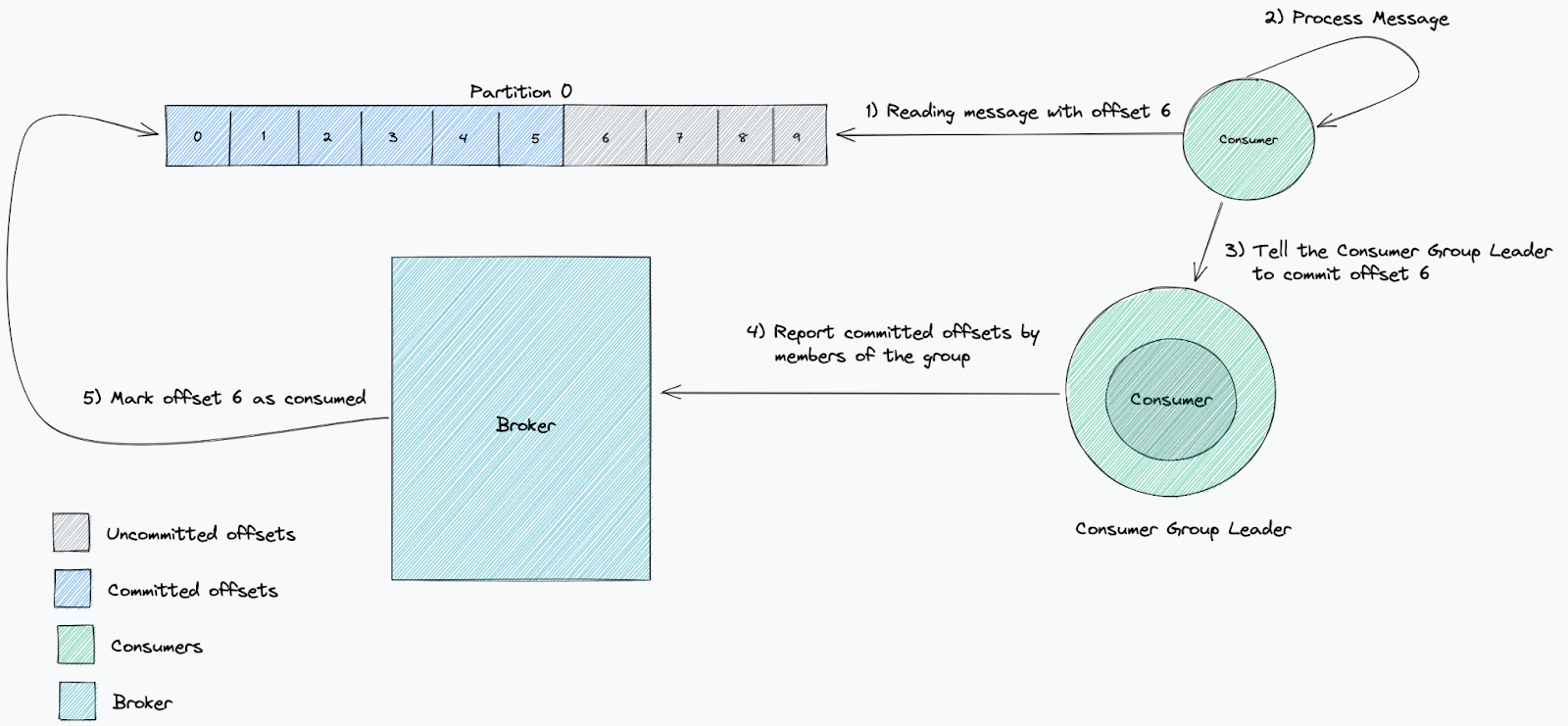
測量取用者處理速度是否足夠快的標準是延遲。我們使用它來測量我們落後於最新訊息的距離。這可追蹤將訊息寫入主題和從中讀取訊息之間經過的時間。當一項服務落後時,這意味著取用速度比新訊息的產生速度慢。
由於 Cloudflare 的規模較大,通常訊息費率最終會非常大,並且許多要求都有時效性,因此,監控這一點至關重要。
在 Cloudflare,使用 Kafka 的應用程式會以微服務的形式部署在 Kubernetes 上。
Kubernetes 應用程式的健康情況檢查
Kubernetes 使用探查來瞭解一項服務是否狀況良好,以及是否準備好接收流量或執行。當活躍度探查失敗且超出重試限制時,Kubernetes 會重新啟動服務。
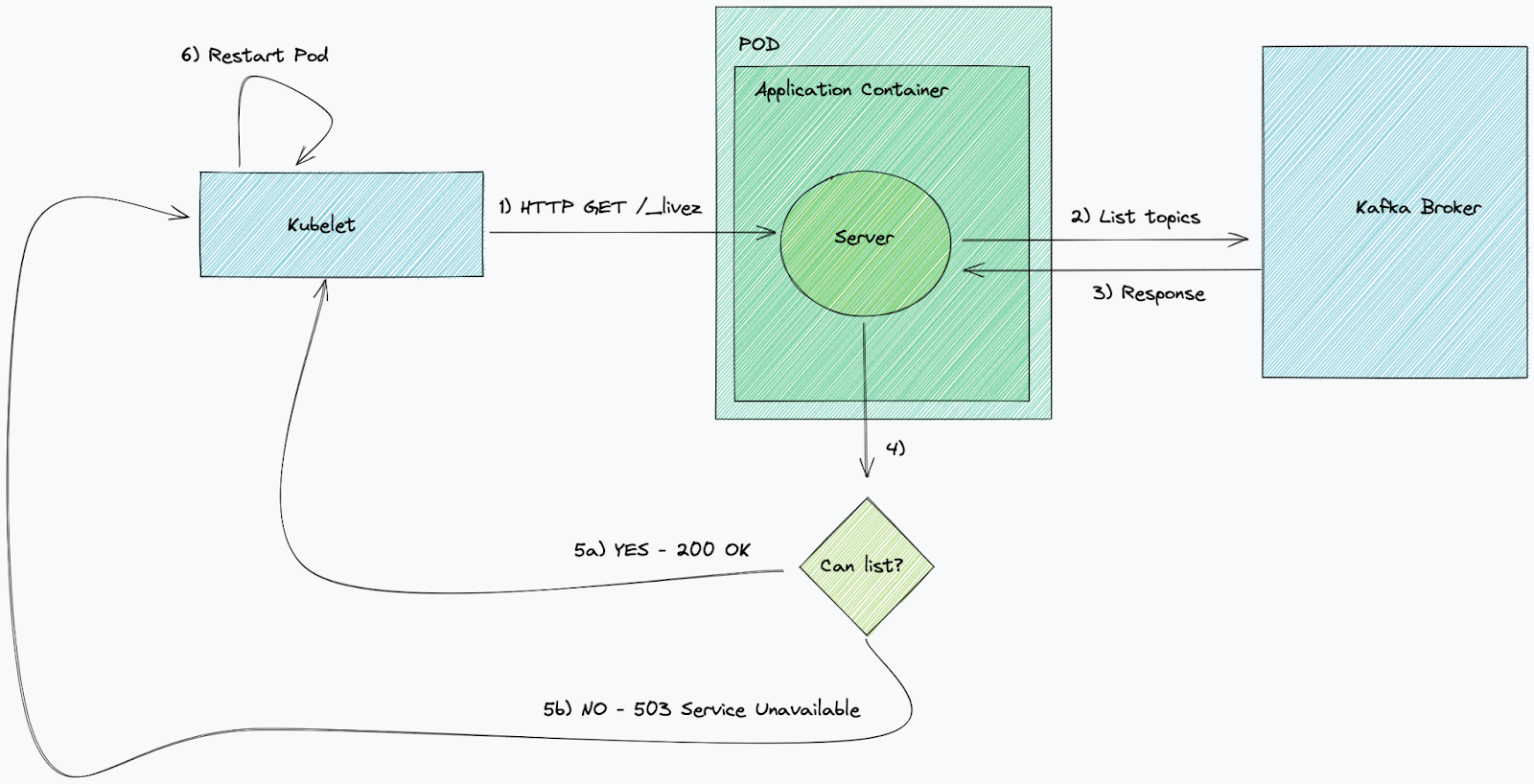
當整備度探查失敗且超出重試限制時,它會停止向目標 pod 傳送 HTTP 流量。就 Kafka 應用程式而言,這並不重要,因為它們不執行 http 伺服器。為此,我們僅執行活躍度檢查。
對取用者進行的傳統 Kafka 活躍度檢查會檢查與代理程式的連線狀態。通常最佳做法是執行簡單的檢查和一些基本操作——比如說,列出主題(在本案例中)。如果此檢查出於任何原因持續失敗,例如代理程式傳回 TLS 錯誤,則 Kubernetes 會終止服務並啟動一個相同服務的新 pod,進而強制建立新的連線。透過簡單的 Kafka 活躍度檢查,即可清楚地瞭解與代理程式的連線何時狀況不佳。
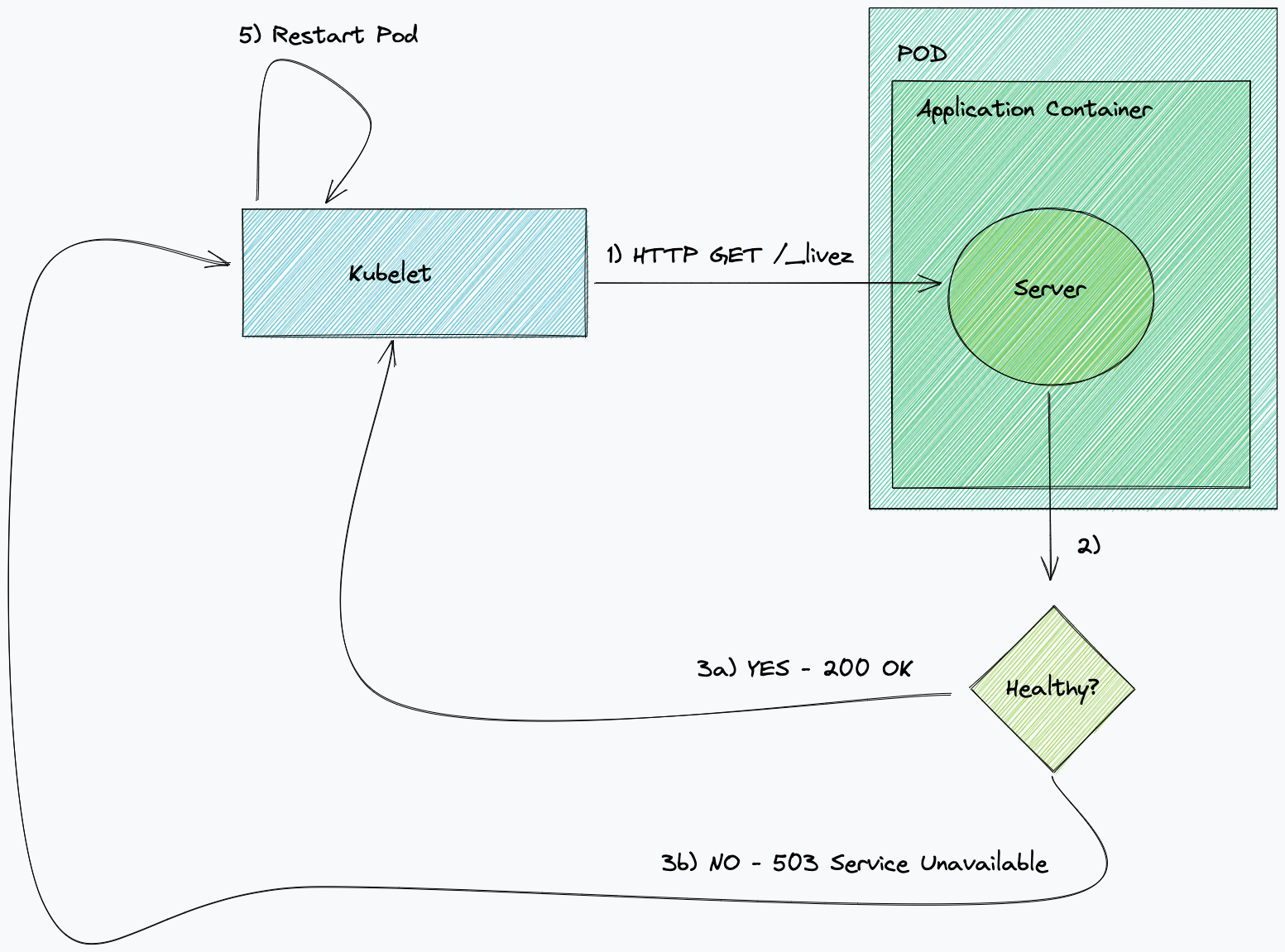
Kafka 健康情況檢查的問題
由於 Cloudflare 的規模較大,大量 Kafka 主題會被分成多個磁碟分割(在某些情況下,可能是數百個!),並且在許多情況下,我們的取用服務的複本計數不一定與 Kafka 主題上的磁碟分割數量相符。這可能意味著在很多情況下,這種簡單的健康情況檢查方法是遠遠不夠的!
如果從 Kafka 主題取用的微服務在訊息發佈到某個主題時,定期取用和認可位移,則表示它們狀況良好。當這些服務未按預期認可位移時,則表示取用者處於不良狀態,並且將開始累積延遲。我們通常採取的一種方法是在 Kubernetes 中手動終止並重新啟動該服務,這將導致重新連線和重新平衡。
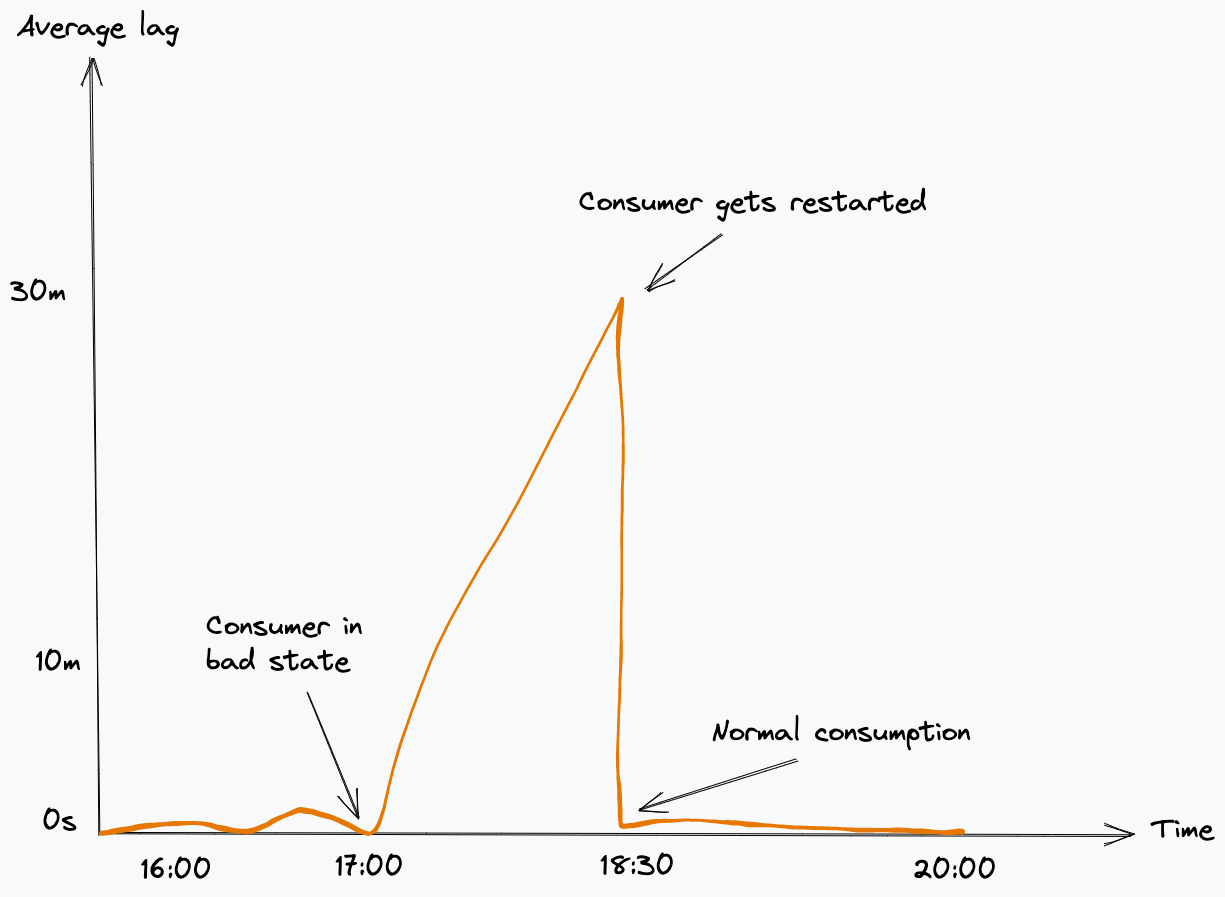
當取用者加入或離開取用者群組時,會觸發重新平衡,而取用者群組負責人必須重新指派哪些取用者將從哪些磁碟分割進行讀取。
當重新平衡發生時,會通知每個取用者停止取用。一些取用者的已指派的磁碟分割可能會被撤銷,並重新指派給另一個取用者。我們注意到在我們的程式庫實作中發生了這種情況;如果取用者不承認這個命令,它將無限期地等待從不再指派給它的磁碟分割中取用新訊息,最終導致鎖死。通常需要手動重新啟動故障用戶端應用程式,以便繼續處理。
智慧型健康情況檢查
當看到取用者報告為「狀況良好」但閒置時,我們開始想到我們在健康情況檢查中所關注的事情可能是錯的。僅僅因為服務連線到 Kafka 代理程式,並且可以從主題中讀取,這並不意味著取用者正在積極處理訊息。
因此,我們意識到我們應該專注於訊息擷取,使用位移值來確保正在取得進展。
PagerDuty 方法
PageDuty 曾針對這個主題撰寫了一篇很棒的部落格,而我們在提出自己的方法時,從中汲取了靈感。
他們的方法使用目前(最新)位移值和已認可位移值。目前位移表示傳送至主題的最後一條訊息,而已認可位移則是取用者處理的最後一條訊息。
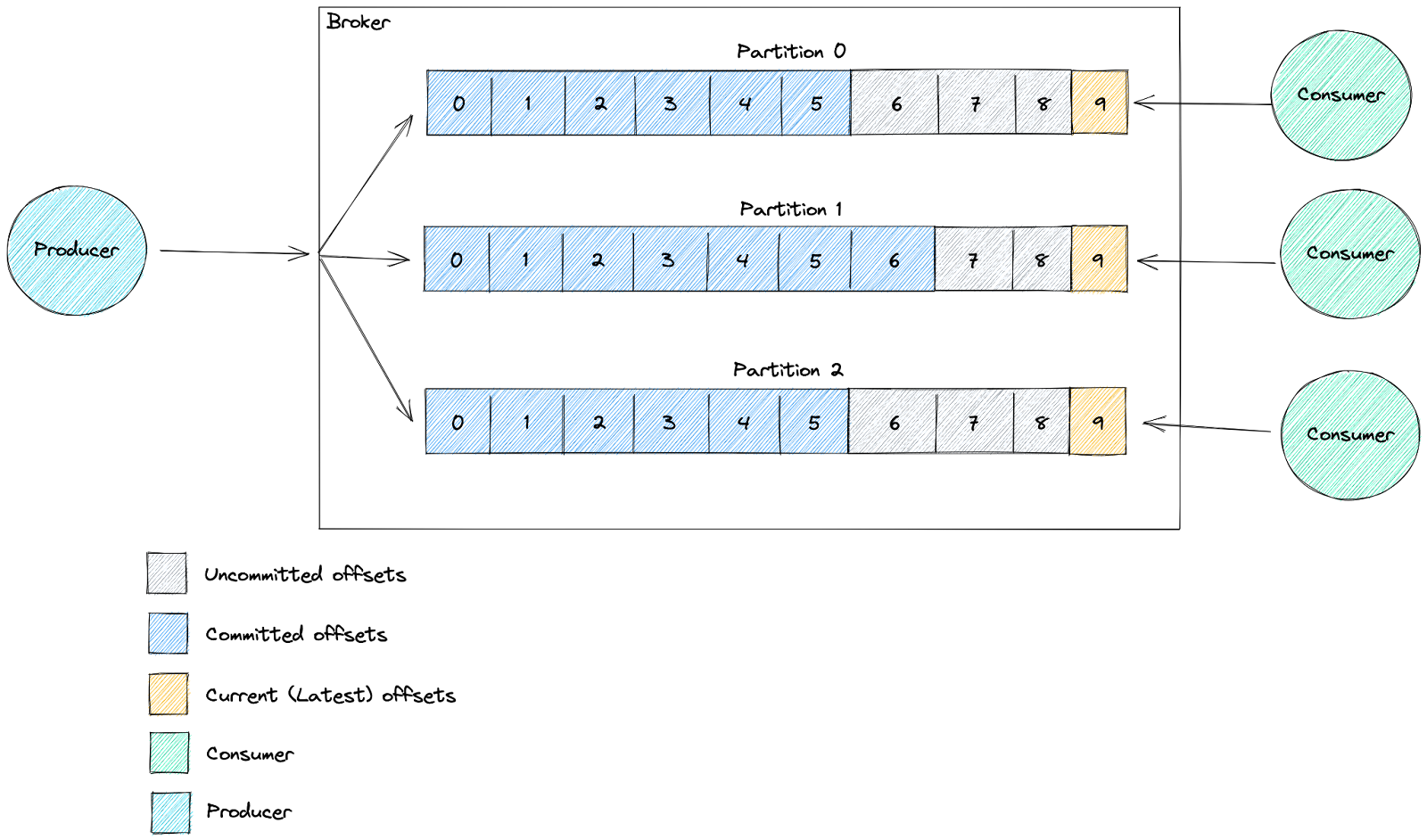
透過確保最新位移正在變化(接收新訊息),並且已認可位移也在變化(處理新訊息),來檢查取用者是否正在向前移動。
因此,我們提出了以下解決方案:
- 如果我們不能讀取目前位移,則活躍度探查失敗。
- 如果我們不能讀取已認可位移,則活躍度探查失敗。
- 如果已認可位移 == 目前位移,則活躍度探查通過。
- 如果自上次執行健康情況檢查以來,已認可位移的值並未變化,則活躍度探查失敗。
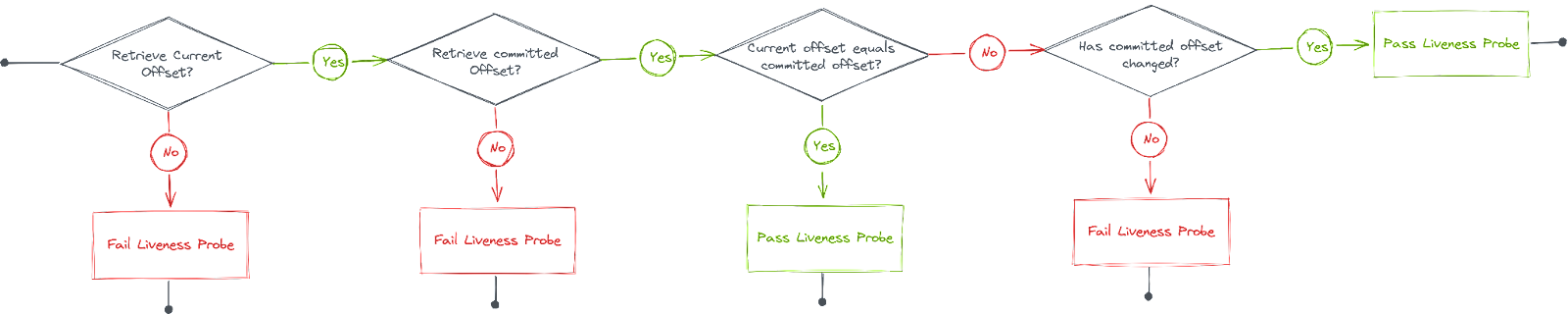
為了測量已認可位移是否發生變化,我們需要儲存上一次執行的值,我們使用磁碟分割編號為索引鍵的記憶體內對應來執行此操作。這表示我們服務的每個執行個體都只能檢視目前從中取用的分割區,並會針對每個磁碟分割執行健康情況檢查。
問題
當首次推出智慧型健康情況檢查時,我們在發佈一段時間後開始注意到一連串的失敗。經過初步調查,我們意識到這種情況是在重新平衡時發生的。它最初會影響一個複本,然後會迅速導致其他複本報告為狀況不良。
我們觀察到,由於我們在記憶體內儲存了先前的已認可位移值,發生重新平衡時,可能會為服務重新指派一個不同的磁碟分割。發生這種情況時,這意味著我們的服務不正確地假設該磁碟分割的已認可位移沒有變化(因為此特定複本不再更新最新值),因此它會開始將服務報告為狀況不良。然後,活躍度探查失敗會導致它重新啟動,而這會反過來觸發 Kafka 中的另一個重新平衡,導致其他複本面臨同樣的問題。
解決方案
為了解決這個問題,我們需要確保每個複本只追蹤它當時正在從中取用的磁碟分割的位移。幸運的是,我們內部使用的 Shopify Sarama 程式庫能夠觀察到重新平衡何時發生。這意味著我們可以使用它來重建記憶體內位移對應,以便它僅包含相關的磁碟分割值。
這是透過從工作階段內容通道接收訊號來處理的:
for {
select {
case message, ok := <-claim.Messages(): // <-- Message received
// Store latest received offset in-memory
offsetMap[message.Partition] = message.Offset
// Handle message
handleMessage(ctx, message)
// Commit message offset
session.MarkMessage(message, "")
case <-session.Context().Done(): // <-- Rebalance happened
// Remove rebalanced partition from in-memory map
delete(offsetMap, claim.Partition())
}
}
驗證這個解決方案非常簡單,我們只需觸發一個重新平衡。為了測試此解決方案適用於所有可能的情況,我們啟動了從多個磁碟分割取用之服務的單一複本,然後繼續擴大複本數量,直到它符合磁碟分割計數,然後再重新縮小到單一複本。透過這樣做,我們驗證了健康情況檢查可以安全地處理正在指派的新磁碟分割以及正在撤銷的磁碟分割。
重點
Kubernetes 中的探查非常容易設定,而且可以作為一款強大的工具來確保應用程式按預期執行。是召喚工程師來解決瑣碎問題(有時在工作時間之外)還是服務自我修復,這其中的差別往往取決於實作良好的探查。
然而,如果考慮不當,「愚蠢」的健康情況檢查也可能導致錯誤的安全感,即誤以為服務按預期執行,即使並非如此。我們從中學到的一件事是,要更多地考慮服務的具體行為,並決定狀況不良在每個執行個體中意味著什麼,而不僅僅是確保依存服務連接起來。