

Today, v2 of Pwned Passwords was released as part of the Have I Been Pwned service offered by Troy Hunt. Containing over half a billion real world leaked passwords, this database provides a vital tool for correcting the course of how the industry combats modern threats against password security.
I have written about how we need to rethink password security and Pwned Passwords v2 in the following post: How Developers Got Password Security So Wrong. Instead, in this post I want to discuss one of the technical contributions Cloudflare has made towards protecting user information when using this tool.
Cloudflare continues to support Pwned Passwords by providing CDN and security functionality such that the data can easily be made available for download in raw form to organisations to protect their customers. Further, as part of the second iteration of this project, I have also worked with Troy on designing and implementing API endpoints that support anonymised range queries to function as an additional layer of security for those consuming the API, that is visible to the client.
This contribution allows for Pwned Passwords clients to use range queries to search for breached passwords, without having to disclose a complete unsalted password hash to the service.
Getting Password Security Right
Over time, the industry has realised that complex password composition rules (such as requiring a minimum number of special characters) have done little to improve user behaviour in making stronger passwords; they have done little to prevent users from putting personal information in passwords, avoiding common passwords or prevent the use of previously breached passwords[1]. Credential Stuffing has become a real threat recently; usernames and passwords are obtained from compromised websites and then injected into other websites until you find user accounts that are compromised.
This fundamentally works because users reuse passwords across different websites; when one set of credentials is breached on one site, this can be reused on other websites. Here are some examples of how credentials can be breached from insecure websites:
- Websites which don't use rate limiting or challenge login requests can have a user's log-in credentials breached using brute force attacks of common passwords for a given user,
- database dumps from hacked websites can be taken offline and the password hashes can be cracked; modern GPUs make this very efficient for dictionary passwords (even with algorithms like Argon2, PBKDF2 and BCrypt),
- many websites continue not to use any form of password hashing, once breached they can be captured in raw form,
- Proxy Attacks or hijacking a web server can allow for capturing passwords before they're hashed.
This becomes a problem with password reuse; having obtained real life username/password combinations, they can be injected into other websites (such as payment gateways, social networks, etc) until access is obtained to more accounts (often of a higher value than the original compromised site).
Under recent NIST guidance, it is a requirement, when storing or updating passwords, to ensure they do not contain values which are commonly used, expected or compromised[2]. Research has found that 88.41% of users who received a fear appeal later set unique passwords, whilst only 4.45% of users who did not receive a fear appeal would set a unique password[3].
Unfortunately, there are a lot of leaked passwords out there; the downloadable raw data from Pwned Passwords currently contains over 30 GB in password hashes.
Anonymising Password Hashes
The key problem in checking passwords against the old Pwned Passwords API (and all similar services) lies in how passwords are checked; with users being effectively required to submit unsalted hashes of passwords to identify if the password is breached. The hashes must be unsalted, as salting them makes them computationally difficult to search quickly.
Currently there are two choices that are available for validating whether a password is or is not leaked:
- Submit the password (in an unsalted hash) to a third-party service, where the hash can potentially be stored for later cracking or analysis. For example, if you make an API call for a leaked password to a third-party API service using a WordPress plugin, the IP of the request can be used to identify the WordPress installation and then breach it when the password is cracked (such as from a later disclosure); or,
- download the entire list of password hashes, uncompress the dataset and then run a search to see if your password hash is listed.
Needless to say, this conflict can seem like being placed between a security-conscious rock and an insecure hard place.
The Middle Way
The Private Set Intersection (PSI) Problem
Academic computer scientists have considered the problem of how two (or more) parties can validate the intersection of data (from two or more unequal sets of data either side already has) without either sharing information about what they have. Whilst this work is exciting, unfortunately these techniques are new and haven't been subject to long-term review by the cryptography community and cryptographic primitives have not been implemented in any major libraries. Additionally (but critically), PSI implementations have substantially higher overhead than our k-Anonymity approach (particularly for communication[4]). Even the current academic state-of-the-art is not with acceptable performance bounds for an API service, with the communication overhead being equivalent to downloading the entire set of data.
k-Anonymity
Instead, our approach adds an additional layer of security by utilising a mathematical property known as k-Anonymity and applying it to password hashes in the form of range queries. As such, the Pwned Passwords API service never gains enough information about a non-breached password hash to be able to breach it later.
k-Anonymity is used in multiple fields to release anonymised but workable datasets; for example, so that hospitals can release patient information for medical research whilst withholding information that discloses personal information. Formally, a data set can be said to hold the property of k-Anonymity, if for every record in a released table, there are k − 1 other records identical to it.
By using this property, we are able to seperate hashes into anonymised "buckets". A client is able to anonymise the user-supplied hash and then download all leaked hashes in the same anonymised "bucket" as that hash, then do an offline check to see if the user-supplied hash is in that breached bucket.
In more concrete terms:

In essence, we turn the table on password derivation functions; instead of seeking to salt hashes to the point at which they are unique (against identical inputs), we instead introduce ambiguity into what the client is requesting.
Given hashes are essentially fixed-length hexadecimal values, we are able to simply truncate them, instead of having to resort to a decision tree structure to filter down the data. This does mean buckets are of unequal sizes but allows clients to query in a single API request.
This approach can be implemented in a trivial way. Suppose a user enters the password test into a login form and the service they’re logging into is programmed to validate whether their password is in a database of leaked password hashes. Firstly the client will generate a hash (in our example using SHA-1) of a94a8fe5ccb19ba61c4c0873d391e987982fbbd3. The client will then truncate the hash to a predetermined number of characters (for example, 5) resulting in a Hash Prefix of a94a8. This Hash Prefix is then used to query the remote database for all hashes starting with that prefix (for example, by making a HTTP request to example.com/a94a8.txt). The entire hash list is then downloaded and each downloaded hash is then compared to see if any match the locally generated hash. If so, the password is known to have been leaked.
As this can easily be implemented over HTTP, client side caching can easily be used for performance purposes; the API is simple enough for developers to implement with little pain.
Below is a simple Bash implementation of how the Pwned Passwords API can be queried using range queries (Gist):
#!/bin/bash
echo -n Password:
read -s password
echo
hash="$(echo -n $password | openssl sha1)"
upperCase="$(echo $hash | tr '[a-z]' '[A-Z]')"
prefix="${upperCase:0:5}"
response=$(curl -s https://api.pwnedpasswords.com/range/$prefix)
while read -r line; do
lineOriginal="$prefix$line"
if [ "${lineOriginal:0:40}" == "$upperCase" ]; then
echo "Password breached."
exit 1
fi
done <<< "$response"
echo "Password not found in breached database."
exit 0
Implementation
Hashes (even in unsalted form) have two useful properties that are useful in anonymising data.
Firstly, the Avalanche Effect means that a small change in a hash results in a very different output; this means that you can't infer the contents of one hash from another hash. This is true even in truncated form.
For example; the Hash Prefix 21BD1 contains 475 seemingly unrelated passwords, including:
lauragpe
alexguo029
BDnd9102
melobie
quvekyny
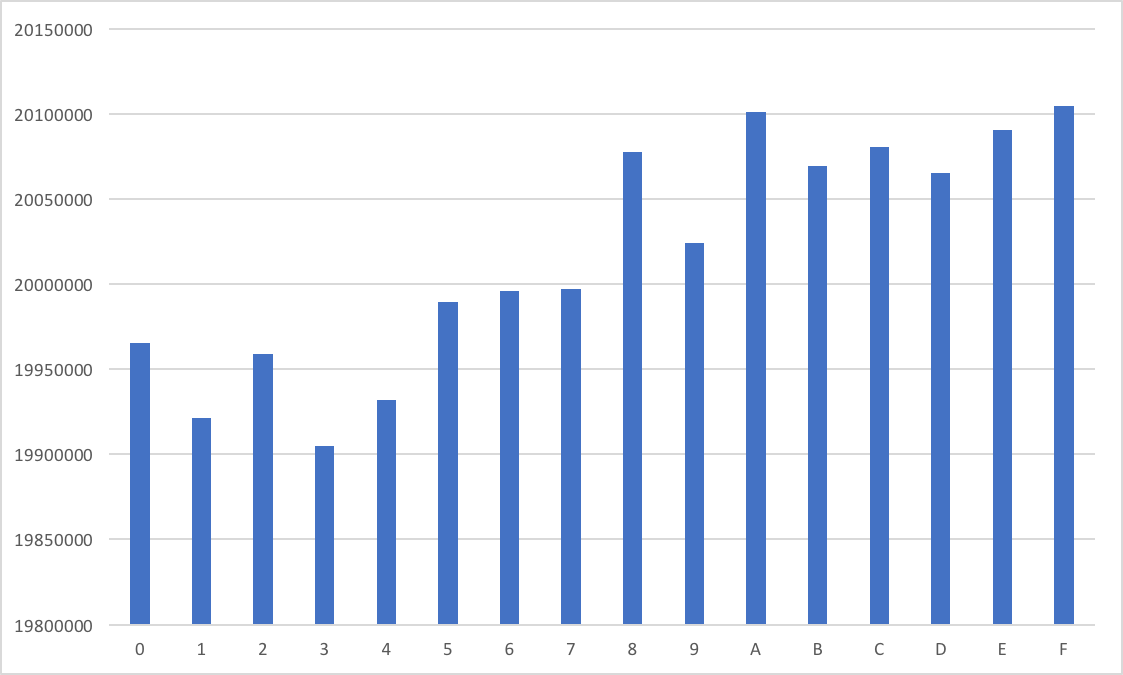
Further, hashes are fairly uniformally distributed. If we were to count the original 320 million leaked passwords (in Troy's dataset) by the first hexadecimal charectar of the hash, the difference between the hashes associated to the largest and the smallest Hash Prefix is ≈ 1%. The chart below shows hash count by their first hexadecimal digit:
Algorithm 1 provides us a simple check to discover how much we should truncate hashes by to ensure every "bucket" has more than one hash in it. This requires every hash to be sorted by hexadecimal value. This algorithm, including an initial merge sort, runs in roughly O(n log n + n) time (worst-case):

After identifying the Maximum Hash Prefix length, it is fairly easy to seperate the hashes into seperate buckets, as described in Algorithm 3:

This implementation was originally evaluated on a dataset of over 320 million breached passwords and we find the Maximum Prefix Length that all hashes can be truncated to, whilst maintaining the property k-anonymity, is 5 characters. When hashes are grouped together by a Hash Prefix of 5 characters, we find the median number of hashes associated with a Hash Prefix is 305. With the range of response sizes for a query varying from 8.6KB to 16.8KB (a median of 12.2KB), the dataset is usable in many practical scenarios and is certainly a good response size for an API client.
On the new Pwned Password dataset (with over half a billion) passwords and whilst keeping the Hash Prefix length 5; the average number of hashes returned is 478 - with the smallest being 381 (E0812 and E613D) and the largest Hash Prefix being 584 (00000 and 4A4E8).
Splitting the hashes into buckets by a Hash Prefix of 5 would mean a maximum of 16^5 = 1,048,576 buckets would be utilised (for SHA-1), assuming that every possible Hash Prefix would contain at least one hash. In the datasets we found this to be the case and the amount of distinct Hash Prefix values was equal to the highest possible quantity of buckets. Whilst for secure hashing algorithms it is computationally inefficient to invert the hash function, it is worth noting that as the length of a SHA-1 hash is a total of 40 hexadecimal characters long and 5 characters is utilised by the Hash Prefix, the total number of possible hashes associated with a Hash Prefix is 16^{35} ≈ 1.39E42.
Important Caveats
It is important to note that where a user's password is already breached, an API call for a specific range of breached passwords can reduce the search candidates used in a brute-force attack. Whilst users with existing breached passwords are already vulnerable to brute-force attacks, searching for a specific range can help reduce the amount of search candidates - although the API service would have no way of determining if the client was or was not searching for a password that was breached. Using a deterministic algorithm to run queries for other Hash Prefixes can help reduce this risk.
One reason this is important is that this implementation does not currently guarantee l-diversity, meaning a bucket may contain a hash which is of substantially higher use than others. In the future we hope to use percentile-based usage information from the original breached data to better guarantee this property.
For general users, Pwned Passwords is usually exposed via web interface, it uses a JavaScript client to run this process; if the origin web server was hijacked to change the JavaScript being returned, this computation could be removed (and the password could be sent to the hijacked origin server). Whilst JavaScript requests are somewhat transparent to the client (in the case of a developer), this may not be depended on and for technical users, non-web client based requests are preferable.
The original use-case for this service was to be deployed privately in a Cloudflare data centre where our services can use it to enhance user security, and use range queries to complement the existing transport security used. Depending on your risks, it's safer to deploy this service yourself (in your own data centre) and use the k-anonymity approach to validate passwords where services do not themselves have the resources to store an entire database of leaked password hashes.
I would strongly recommend against storing the range queries used by users of your service, but if you do for whatever reason, store them as aggregate analytics such that they cannot be linked back to any given user's password.
Final Thoughts
Going forward, as we test this technology more, Cloudflare is looking into how we can use a private deployment of this service to better offer security functionality, both for log-in requests to our dashboard and for customers who want to prevent against credential stuffing on their own websites using our edge network. We also seek to consider how we can incorporate recent work on the Private Set Interesection Problem alongside considering l-diversity for additional security guarantees. As always; we'll keep you updated right here, on our blog.
Campbell, J., Ma, W. and Kleeman, D., 2011. Impact of restrictive composition policy on user password choices. Behaviour & Information Technology, 30(3), pp.379-388. ↩︎
Grassi, P. A., Fenton, J. L., Newton, E. M., Perlner, R. A., Regenscheid, A. R., Burr, W. E., Richer, J. P., Lefkovitz, N. B., Danker, J. M., Choong, Y.-Y., Greene, K. K., and Theofanos, M. F. (2017). NIST Special Publication 800-63B Digital Identity Guidelines, chapter Authentication and Lifecycle Management. National Institute of Standards and Technology, U.S. Department of Commerce. ↩︎
Jenkins, Jeffrey L., Mark Grimes, Jeffrey Gainer Proudfoot, and Paul Benjamin Lowry. "Improving password cybersecurity through inexpensive and minimally invasive means: Detecting and deterring password reuse through keystroke-dynamics monitoring and just-in-time fear appeals." Information Technology for Development 20, no. 2 (2014): 196-213. ↩︎
De Cristofaro, E., Gasti, P. and Tsudik, G., 2012, December. Fast and private computation of cardinality of set intersection and union. In International Conference on Cryptology and Network Security (pp. 218-231). Springer, Berlin, Heidelberg. ↩︎