


思い浮かべてみてください。空港にいて、空港の保安検査場を通過しようとしています。大勢の係員が搭乗券とパスポートをスキャンし、ゲートへと通してくれます。そこで突然、何人かの係員が持ち場を離れます。チェックポイントの上の天井に雨漏りがあるのかもしれません。あるいは、午後6時に出発する便が集中し、一度に何人もの乗客が現れようとしているのかもしれません。いずれにせよ、このような局地的な需要と供給のアンバランスは、大行列を引き起こし、とにかく列を抜けてフライトに乗らせてほしいと旅行者の不満を募らせる可能性があります。空港では、これにどのように対処しているのでしょうか。
特に何もせず、ただ長い列に並ばされ続けることになる空港もあります。チェックポイント通過の際のファストトラックを有料で提供する空港もあります。しかし、たいていの空港では、できるだけ早くゲートにたどり着けるよう少し離れた別の保安検査場に行くように指示するでしょう。それぞれの列の長さを示す看板が設置されている場合もあり、通過する際の判断がしやすくなっています。
Cloudflareでも、同じ問題に直面します。当社は世界300都市に拠点を持ち、すべての製品スイートのエンドユーザーのトラフィックを受けられるように構築されています。理想としては、可能な限り近い場所にいる全員に対応できるだけのコンピューターと帯域幅が常に存在していることが望ましいと言えます。しかし、世の中は常に理想的というわけではありません。メンテナンスのためにデータセンターをオフラインにすることもあれば、データセンターへの接続がダウンしたり、機器が故障したりすることもあります。そうなれば、すべての場所で保安検査を受けるすべての人に対応できるだけの係員を確保できないかもしれません。ブースの数が足りないからではなく、データセンターで何かが起き、すべての人にサービスを提供できなくなるのです。
そこで当社では、グローバル・ネットワーク全体で需要と供給のバランスをとるツールとして、Traffic Managerを開発しました。このブログは、Traffic Managerについて、その起源、構築のされ方、現在の役割を徹底解説します。
Traffic Manager登場以前の世界
現在Traffic Manager(トラフィック・マネージャー)が行っている作業は、以前はネットワークエンジニアが手作業で行っていたものです。当社のネットワークは、特定のデータセンターでユーザートラフィックに影響を与えることが起こるまでは、通常通り運用されていました。
このようなイベントが発生すると、ユーザーのリクエスト負荷を処理するのに十分なマシンがないため、ユーザーリクエストは499または500エラーにより失敗するようになりました。そのため、ネットワークエンジニアはそのデータセンターのAnycastルートを削除しました。その結果、影響を受けたデータセンターでそれらのプレフィックスをもはやアドバタイズしないことで、ユーザートラフィックは別のデータセンターに迂回させられます。これがAnycastの基本的な仕組みです。ユーザトラフィックは、ボーダー・ゲートウェイ・プロトコルによって決定されるように、ユーザーが接続しようとしているプレフィックスをアドバタイズしている最も近いデータセンターに引き寄せられます。エニーキャストについては、この参考記事をご覧ください。
問題の程度にもよるものの、エンジニアはデータセンター内の経路の一部、あるいは全部を削除します。データセンターが再びすべてのトラフィックを吸収できるようになると、エンジニアはルートを元に戻し、トラフィックは自然にデータセンターに戻ります。
ご想像のとおり、ネットワークエンジニアにとって、ネットワーク上のハードウェアに問題が発生するたびにこの作業を行うのは、とても骨の折れることでした。スケール化できなかったのです。
機械の仕事は決して人間にやらせない
しかし、手作業はネットワーク・オペレーション・チームの負担になるだけではありませんでした。また、エンジニアがトラフィックを診断した上でルートを変更するのに時間がかかるなど、顧客にとって満足のいくものではありませんでした。この2つの問題を解決するために、Cloudflareのデータセンターにユーザーが到達できないことを即座に自動的に検出し、ユーザーが問題を感じなくなるまでデータセンターからルートを撤回するサービスを構築したいと考えました。影響を受けたデータセンターがトラフィックを吸収できるようになったとの通知を受けた時点で、そのデータセンターにルートを戻して再接続できるようにするものです。このサービスは、(ご想像の通り)Cloudflareネットワークに入ってくるトラフィックを管理することを仕事とするため、Traffic Managerと呼ぶようになりました。

二次的結果への準備
ネットワークエンジニアがルーターからルートを削除する場合、ユーザーリクエストの移動先を最善の方法で推測し、フェイルオーバー・データセンターにリクエストを処理するのに十分なリソースがあることの確認を取ろうとします。このプロセスを自動化するには、直感の世界からデータの世界へと移行する必要がありました。ルートが削除されたときにトラフィックがどこへ向かうかを正確に予測し、その情報をトラフィック・マネージャーに送り込むことで、状況を悪化させないようにするのです。
Traffic Predictorとの出会い
ルートをアドバタイズするデータセンターの調整は可能ですが、各データセンターが受け取るトラフィックの割合には影響を与えられません。新しいデータセンターや新しいピアリングセッションを追加するたびに、トラフィックの分布は変化し、300以上の都市で12,500以上のピアリングセッションを展開しているため、人間がトラフィックのネットワーク内での動きを把握したり予測したりすることは非常に困難です。Traffic Managerには相棒が必要であり、それがTraffic Predictorなのです。
Traffic Predictor(トラフィック・プレディクター)は、その機能を果たすために、トラフィックが実際に移動する場所を確認するための一連の実世界でのテストを継続的に実施しています。Traffic Predictorは、データセンターをサービスから外し、そのデータセンターがトラフィックを提供していない場合にトラフィックが向かう場所をシミュレートするテストシステムを基に稼働します。このシステムの仕組みを理解するために、ニュージーランドのクライストチャーチにあるデータセンターの一部を撤去するシミュレーションで説明します。
- まず、Traffic Predictorはクライストチャーチに通常接続するすべてのIPアドレスのリストを取得します。Traffic Predictorは、最近リクエストを行ってきた何十万ものIPにpingリクエストを送ります。
- Traffic Predictorは、IPが応答するかどうか、また、Traffic Predictor用に特別に設定されたAnycast IPレンジを使用し、応答がクライストチャーチに戻るかどうかを記録します。
- Traffic Predictorが、クライストチャーチに応答するIPのリストを得ると、クライストチャーチからその特別な範囲を含むルートを削除し、インターネットのルーティングテーブルが更新されるまで数分待ち、再度テストを実行します。
- 回答はクライストチャーチではなく、クライストチャーチ周辺のデータセンターにルーティングされます。Traffic Predictorはその後、各データセンターの応答に関する知識を利用し、クライストチャーチのフェイルオーバーとして結果を記録します。
これにより、クライストチャーチを実際にオフラインにすることなく、クライストチャーチがオフラインになるよう、シミュレーションができるのです。
しかし、Traffic Predictorは1つのデータセンターだけを対象にしているわけではありません。回復能力に付加的なレイヤーを設けるため、Traffic Predictorはさらに2つ目の迂回路のレイヤーも計算します。データセンターの障害シナリオごとに、Traffic Predictorは障害のシナリオも考慮し、周囲のデータセンターが障害に陥った場合のポリシーも作成します。
先ほどの例で言えば、トラフィック予測がクライストチャーチをテストする際、クライストチャーチを含む周辺のデータセンターをいくつかサービスから外し、さまざまな障害シナリオを計算する一連のテストを実行します。これにより、ある地域の複数のデータセンターに影響を与えるような大惨事が起こったとしても、ユーザートラフィックに対応する能力が確保されます。このデータモデルは複雑であるとするなら、否定はできません。これらの障害経路とポリシーをすべて計算するのに、数日かかります。
世界中のデータセンターの障害パスとフェイルオーバーシナリオを可視化すると、次のようになります:

人間の支店では若干複雑になるため、ニュージーランドのクライストチャーチにおける上記のシナリオをもう少し掘り下げてみます。クライストチャーチでのフェイルオーバー・パスを見ると、以下のようになります:

このシナリオでは、クライストチャーチのトラフィックの99.8%がオークランドに移行すると予測されます。オークランドは、壊滅的な障害が発生したとしても、クライストチャーチのトラフィックをすべて吸収することができます。
Traffic Predictorは、万が一の場合のトラフィックの移動先を確認できるだけでなく、フェイルオーバー・データセンターからリクエストを移動させるTraffic Predictorポリシーを事前に設定することで、1つ目のデータセンターに問題が発生した場合に2つ目のデータセンターで突発的なリクエストの流入が障害を引き起こすことになる連鎖障害発生シナリオを防げます。Traffic Predictorにより、Traffic Managerは、あるデータセンターに障害が発生したときに、そのデータセンターからトラフィックを移動させるだけでなく、他のデータセンターからもトラフィックを積極的に移動させ、シームレスなサービス継続を保証します。
ハンマーからメスへ
Traffic Predictorを使えば、Traffic Managerは、すべてのデータセンターがすべてのトラフィックを処理できるようにしながら、プレフィックスを動的にアドバタイズしたり取り下げたりすることができます。しかし、トラフィック管理の手段としてのプレフィックスの撤回は、時として少々強引になりかねません。その理由のひとつは、データセンターへのトラフィックの追加および削除の方法が、インターネットに面したルーターからの広告ルートしかなかったことにあります。各ルートには何千ものIPアドレスがあるため、1つだけを削除してもトラフィックの大部分を占めることになります。
具体的には、インターネット・アプリケーションは、絶対最小値で/24サブネットからインターネットへのプレフィックスをアドバタイズしますが、多くはそれよりも大きなプレフィックスをアドバタイズします。これは一般に、ルーティングリークやルーティングハイジャックなどを防ぐために行われます。多くのプロバイダは、/24よりも特定的なルーティングを実際にフィルタリングします(詳細は、こちらのブログをご覧ください)。Cloudflareが保護されたプロパティをIPアドレスに1:1の比率でマッピングすると仮定すると、各/24サブネットは256の顧客にサービスを提供できることになり、この数字は/24サブネットのIPアドレスの数となります。すべてのIPアドレスが毎秒1つのリクエストを送信するとすると、毎秒1,000リクエスト(RPS)を移動する必要がある場合、データセンターから4つの/24サブネットを移動する必要があります。
しかし実際には、Cloudflareは1つのIPアドレスを何十万もの保護されたプロパティにマッピングしています。つまり、Cloudflareの場合、/24は1秒間に3,000リクエストを受けるものの、1,000 RPSを移動させる必要があれば1つの/24を移動させるほかありません。また、これは/24レベルでアドバタイズすると仮定した場合の話になります。アドバタイズに/20を用いた場合、撤回できる数の粒度は下がります。WebサイトとIPアドレスのマッピングが1対1の場合、各プレフィックスに対して1秒間に4,096リクエスト、WebサイトとIPアドレスのマッピングが多対1の場合はさらに多くなります。
プレフィックスアドバタイズを撤回したことで、499エラーや500エラーが表示されていたユーザーのカスタマーエクスペリエンスは改善されるものの、問題の影響を受けなかったはずのユーザーのかなりの部分が、本来行くべきデータセンターから離れた場所に移動させられたままとなり、若干であるとは言えおそらく遅延が発生することになります。必要以上のトラフィックを外部に移動させるこの概念は、「ストランディング・キャパシティ」と呼ばれます。データセンターは理論上、ある地域でより多くのユーザーにサービスを提供できますが、Traffic Managerの構築のされ方上、でそれができないのです。
私たちはTraffic Managerを改善し、問題が発生しているデータセンターから必要最小限のユーザーだけを移動させ、これ以上容量を増やさないようにしたいと考えました。そのためには、プレフィックスのパーセンテージをシフトさせ、よりきめ細かく、移動せざるを得ない必要なものだけを移動させる必要がありました。これを解決するために、私たちはレイヤー4ロードバランサーである「Unimog」を拡張し、これをPlurimogと名付けました。
Unimogとレイヤー4負荷分散について簡単にまとめます。私たちのマシンのひとつひとつに、そのマシンがユーザーのリクエストを受けられるかどうかを決定するサービスが含まれています。もしマシンがユーザーのリクエストを受け付けることができれば、HTTPスタックにリクエストを送り、HTTPスタックはユーザーに返す前にリクエストを処理します。マシンがリクエストを受けられない場合、そのマシンはリクエストを受けられるデータセンター内の別のマシンに送ります。このようなことができるのは、マシン同士が常に会話し、ユーザーのリクエストに応えられるかどうかを把握しているからなのです。
Plurimogも同じことをするものの、マシン間で会話するのではなく、データセンターと接続拠点間で会話します。リクエストがフィラデルフィアに入り、フィラデルフィアがリクエストに応じられない場合、Plurimogはアッシュバーンなどクエストに応じられる別のデータセンターに転送し、そこでリクエストは復号化され処理されることになります。Plurimogはレイヤー4で動作するため、個々のTCPまたはUDPリクエストを他の場所に送信することができ、非常にきめ細かく対応できます。つまり、トラフィックのパーセンテージを非常に簡単に他のデータセンターに送信でき、あらゆるユーザーに可能な限り早くサービスがいきわたるよう十分なトラフィックを他に送信することのみが必要となります。当社のフランクフルトのデータセンターでは、トラフィックを徐々にシフトさせ、データセンターの問題を処理しています。その様子をご覧ください。このグラフは、フランクフルトからの送出につながるフリートラフィックに対しとられたアクションの数を時系列で示したものです:

しかし、データセンター内であっても、トラフィックをルーティングしてデータセンターからトラフィックがまったく出ないようにすることができます。Multi-Colo Points of Presence(MCP)と呼ぶ当社の大規模データセンターには、データセンター内で別のものとは異なるコンピュートの論理セクションがあります。これらのMCPデータセンターは、Duomogと呼ぶUnimogの別バージョンで実現され、トラフィックをコンピュート内の論理セクション間で自動的にシフトさせることができます。これにより、MCPデータセンターは、顧客のパフォーマンスを犠牲にすることなくフォールトトラレントになり、Traffic Managerはデータセンター内だけでなく、データセンター間でも機能するようになります。
移動リクエストの評価時、Traffic Managerは以下のことを行います:
- Traffic Managerは、すべてのリクエストに対応できるように、データセンターまたはデータセンターのサブセクションから削除する必要があるリクエストの割合を特定します。
- Traffic Managerは次に、各ターゲットのスペースメトリクスを集計し、各フェイルオーバー・データセンターが受けられるリクエスト数を確認します。
- 続いてTraffic Managerは、それぞれのプランのトラフィックをどれだけ移動させる必要があるかを特定し、十分なトラフィックを移動しきるまで、プランの一部、またはプランのすべてをPlurimog/Duomog経由で移動させます。まずFree(サブスクリプションタイプ)のユーザーを移動し、データセンターにFreeのお客様がいなくなれば、Proのユーザーを移動し、続いて必要に応じBusinessのユーザーを移動します。
例えば、バージニア州アッシュバーンの例を見てみましょう。アッシュバーンには9つの異なるサブセクションがあり、それぞれトラフィックを受け入れることができます。8月28日、そのサブセクションのひとつであるIAD02で、処理できるトラフィック量が減少する問題が発生しました。
この期間中、DuomogはIAD02からAshburn内の他のサブセクションにより多くのトラフィックを送信し、Ashburnが常にオンラインであるようにし、この問題の間パフォーマンスに影響がないことを確認しました。その後、IAD02が再びトラフィックを受けられるようになると、Duomogは自動的にトラフィックを戻します。下の時系列グラフでは、IAD02内のキャパシティのサブセクション(緑で表示)間で、トラフィックが移動した割合を時系列で追跡したものです:
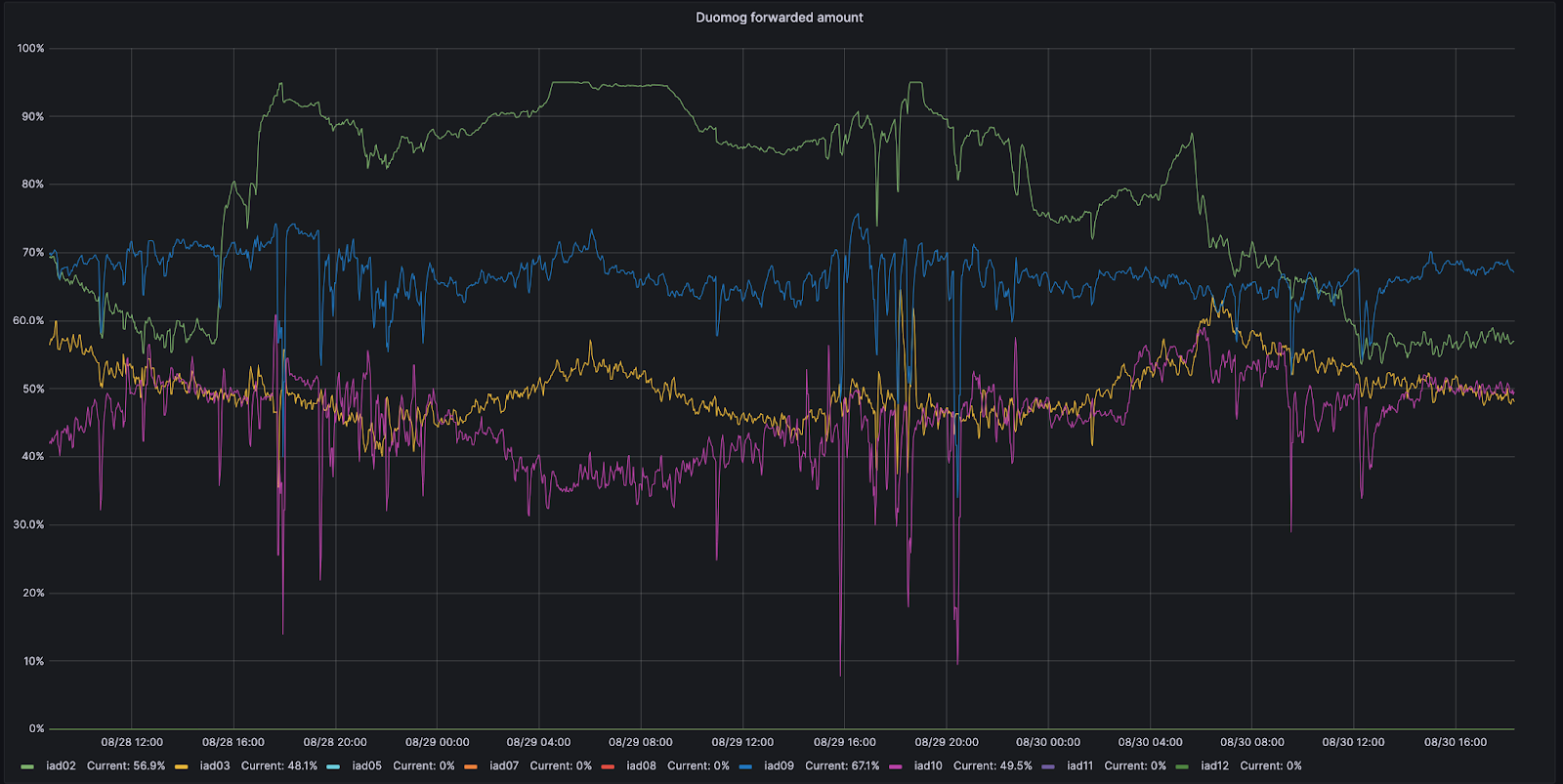
Traffic Managerが移動すべき量を把握する仕組み
上記の例では1秒あたりのリクエスト数を使っていますが、実際にトラフィックを動かす場合、1秒あたりのリクエスト数を指標にするのは正確性が十分ではありません。その理由は、ユーザーごとに当社サービスへのリソースコストが異なるためです。WAFを無効にして主にキャッシュから提供されるWebサイトは、すべてのWAFルールを有効にしてキャッシングを無効にしたサイトよりも、CPU的にははるかに安くなっています。そこで、各リクエストがCPUで消費する時間を記録します。これにより、各プランのCPU時間を集計し、プランごとのCPU時間使用量を求めることができる。CPU時間をミリ秒単位で記録し、1秒あたりの値を取り、これが秒あたりにミリ秒単位となります。
CPU時間は、遅延や顧客のパフォーマンスに影響を与える可能性があり、重要な指標となります。例として、Web閲覧リクエストがCloudflareのフロントラインサーバーを完全に通過するのにかかる時間を考えてみましょう。これを、cfチェック遅延と呼びます。この数値が高すぎると、ユーザーは異常に気づき始め、体験が劣り始めます。cfチェック遅延が高くなる理由はたいてい、CPU使用率が高いためです。下のグラフは、同じデータセンター内のすべてのマシンのCPU使用率に対して95パーセンタイルのcfチェック遅延をプロットしたもので、強い相関関係があることがわかります:

そのため、Traffic ManagerがデータセンターのCPU時間を調べることは、ユーザーに最高水準の体験を提供し、問題を引き起こしていないことを確認する点で優れた方法と言えます。
プランごとのCPU時間を求めたら、そのCPU時間のうちどれだけを他のデータセンターに移動させるかを考える必要があります。そのためには、全サーバーのCPU使用率を集計し、データセンター全体のCPU使用率を1つにまとめます。ネットワーク機器の故障や停電などにより、データセンター内のサーバーの一部が故障した場合、それらのサーバーに当たっていたリクエストは、Duomogによってデータセンター内の別の場所に自動的にルーティングされます。サーバーの台数が減ると、データセンター全体のCPU使用率は増加します。Traffic Managerには、データセンターごとに最大閾値、目標閾値、許容閾値の3つの閾値があます:
- 最大:パフォーマンスが低下し始めるCPUレベルで、Traffic Managerがアクションを実行します
- 目標:ユーザーへの最適なサービスを回復するために、Traffic ManagerがCPU使用率の削減を試みるレベルとなります
- 許容可能:データセンターが他のデータセンターから転送されたリクエストを処理できるレベル、またはアクティブな移動を戻すことができるレベルです
データセンターが最大閾値を超えると、Traffic Managerはその時点のCPU使用率に対する全プランの総CPU時間の比率を取り、それを目標CPU使用率に適用して目標CPU時間を求めます。このようにすることで、それぞれのデータセンターのサーバー数を気にすることなく、100台のサーバーを持つデータセンターと10台のサーバーを持つデータセンターを比較できることになります。これは負荷が直線的に増加すると仮定したものですが、この仮定はここでの目的には十分に有効となります。
目標比率がその時点の比率に等しい場合:

したがって:

その時点のCPU時間から目標のCPU時間を引くと、移動すべきCPU時間がわり出せます:

たとえば、現在のCPU使用率がデータセンター全体で90%、目標が85%、全プランのCPU時間が18,000だった場合、次のようになります:

これは、Traffic Managerが1,000CPUの時間を動かす必要があることを意味しています:
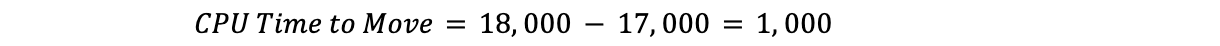
これで、移動に必要なCPUの総時間がわかったので、移動に必要な時間が満たされるまでプランを進めることができます。
閾値の上限
しばしば直面した問題に、Traffic Managerがデータセンターで対応を始めるべきポイントの決定があります。どういった指標を検討し、許容可能なレベルはどの程度か、という点になります。
前述したように、サービスによってCPU使用率に関する要件は異なる上に、利用パターンが大きく異なるデータセンターのケースも多くなっています。
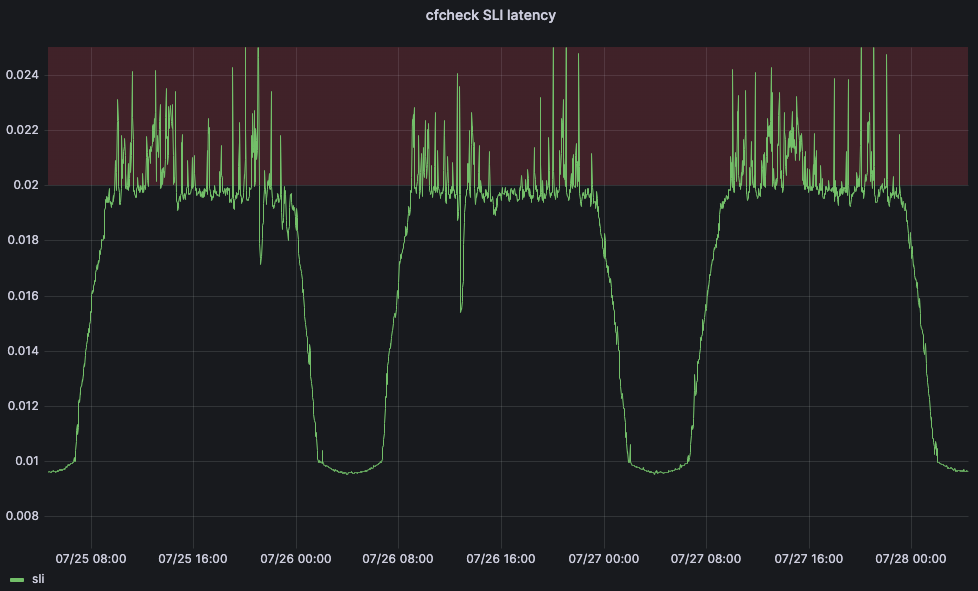
この問題を解決するために、当社は機械学習に目を向けました。当社は顧客向けの指標に応じ、各データセンターの最大しきい値を自動的に調整するサービスを作ったのです。主なサービスレベル指標(SLI)には、先に説明したcfチェック遅延指標を使うことにしました。
しかし、機械学習アプリケーションが閾値を調整できるようにするためには、サービスレベル目標(SLO)も定義する必要があります。SLOは20ミリ秒に設定しました。SLOとSLIを比較すると、95パーセンタイルのcfチェック遅延が20ミリ秒を超えることはないはずです。下のグラフは、95パーセンタイルのcfチェック遅延を経時的に示したもので、cfチェック遅延がレッドゾーンに入ると、ユーザーは不満を持ち始めます:
CPUが高くなり過ぎるとユーザー側でのエクスペリエンスが悪化する場合、Traffic Managerの最大閾値の目標は、顧客のパフォーマンスに影響が出ないようにし、パフォーマンスが低下し始める前にトラフィックのリダイレクトを開始することになります。スケジュールされた間隔で、Traffic Managerサービスは各データセンターの多くのメトリクスを取得し、一連の機械学習アルゴリズムを適用します。外れ値のためにデータをクリーニングした後、単純な2次関数曲線を適用し、現在では線形回帰アルゴリズムをテストしているところです。
モデルをフィッティングした後、SLIがSLOに等しいときのCPU使用率を予測し、それを最大閾値として使用することができます。CPUの値をSLIに対してプロットしてみると、なぜこれらの方法がデータセンターにとって非常に有効なのかがよくわかるでしょう。

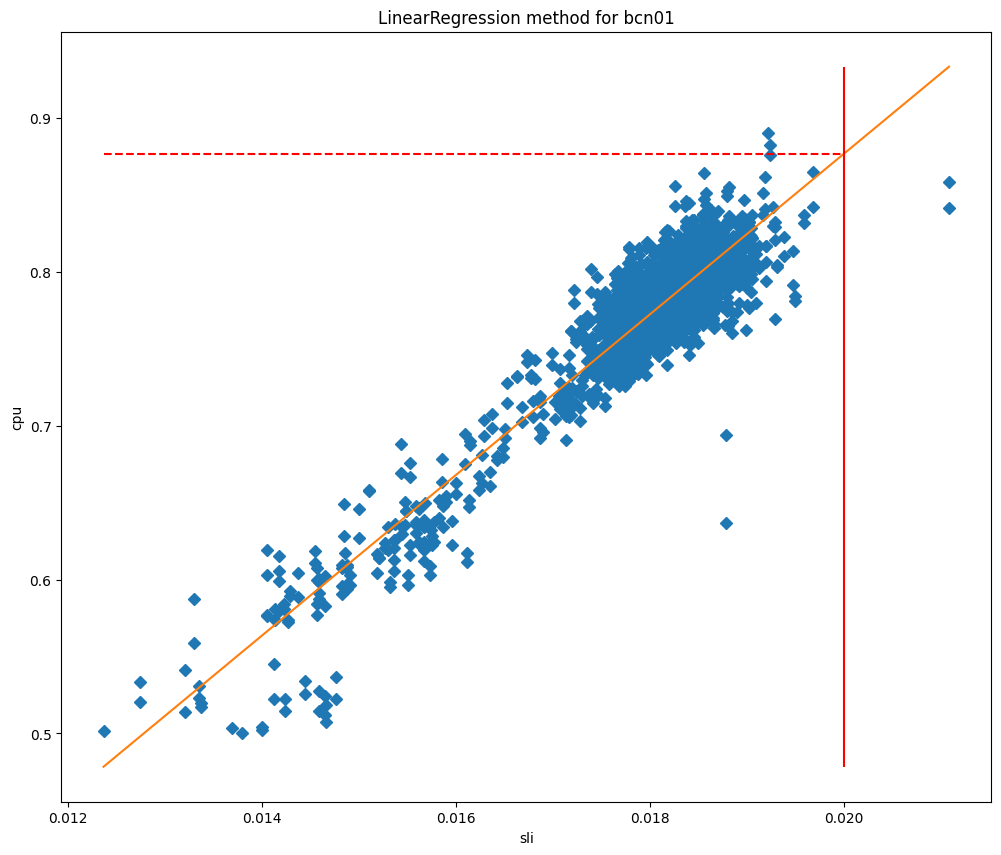
これらのグラフでは、縦線がSLOであり、この線と適合モデルとの交点が最大閾値として使用される値を表しています。このモデルは非常に正確であることが証明され、当社ではSLO違反を大幅に減らすことができました。リスボンでこのサービスを展開し始めた時期の様子を振り返ってみます:

変更前は、cfcheck 遅延は常にスパイクしていたが、最大しきい値が固定されていたため、Traffic Managerはアクションを起こさなかった。しかし、7月29日以降、cfcheck 遅延がSLOにヒットすることはありませんでした。
トラフィックの送り先
最大閾値が割り出せたので、次に移動させるトラフィック量を計算するときに使用されない3番目のCPU使用率閾値、つまり許容閾値を見つける必要が出てきます。データセンターがこの閾値を下回ると未使用のキャパシティができることになり、データセンター自身がトラフィックを転送していない限り、必要なときに他のデータセンターが使用できるようになります。各データセンターがどれだけ受け入れることができるかを計算するために、上記と同じ方法を使用して目標を許容可能な量に置き換えます:

したがって:

許容CPU時間から現在のCPU時間を引くと、データセンターが許容できるCPU時間がわかります:

トラフィックの送信先を見つけるために、Traffic Managerはすべてのデータセンターで利用可能なCPU時間を見つけ、トラフィックの移動が必要なデータセンターから遅延時間順に並べます。各データセンターを移動し、最大閾値に基づいて利用可能な容量をすべて使用した後、次のデータセンターに移動します。移動させるプランを決めるとき、優先順位の低いプランから高いプランへと移動させますが、移動先を決めるときは逆方向に移動させます。
より分かりやすく、例を使って説明します:
データセンターAから1,000CPU時間を移動させる必要があり、1プランあたりの使用量はFree:500ms/s、Pro:400ms/s、Business:200ms/s、Enterprise:1000ms/sとなります。
Free(500ms/s)の100%、Pro(400ms/s)の100%、Business(100ms/s)の50%、Enterpriseの0%を移動させます。
近隣のデータセンターのCPU使用可能時間は、:B:300ms/s、C:300ms/s、D:1,000ms/sとなっています。
発生する遅延は、A-B:100ms、A-C:110ms、A-D:120msです。
最も遅延が少なくアクションを必要とする優先順位の高いプランから始めると、Business CPU時間をすべてデータセンターBとProの半分に移動させます。次に、データセンターCに移動し、Proの残りとFreeの20%を移動させます。フリーの残りはデータセンターDに移動させます。その結果、Business:50%→B、プロ:50%→B、50%→C、フリー:20%→C、80%→Dとなります。
アクションの取り消し
Traffic Managerは、データセンターが閾値を超えないように常に監視しているのと同様に、アクティブにトラフィックを転送しているデータセンターに転送されたトラフィックを戻すことも監視しています。
上記では、Traffic Managerが、データセンターが他のデータセンターから受信できるトラフィック量の計算方法を提示しました。アクティブな移動がある場合、この利用可能なCPU時間を使ってデータセンターにトラフィックを戻します。当社では常に、他のデータセンターからのトラフィックを受け入れるよりもアクティブな移動を戻すことを優先します。
これらをすべて組み合わせれば、各データセンターのシステムと顧客の健全性指標を常に測定し、トラフィックを分散させネットワークのその時点の状態から各リクエストへの対応を実現するシステムができあがります。データセンター間の移動をすべて地図上に並べると、このようになります。1時間におけるトラフィック・マネージャーのすべての移動を地図で表したものです。このマップはデータセンターのすべての展開を示しているわけではないものの、この期間に移動したトラフィックを送信または受信しているデータセンターを示しています:
赤や黄色のデータセンターには負荷がかかっており、すべての指標が健全であることを意味する緑になるまで他のデータセンターにトラフィックを移動させています。円の大きさは、該当のデータセンターから、あるいは該当のデータセンターへ、どれだけのリクエストがシフトされたかを表しています。トラフィックの行き先は、線が動いている場所で示されます。これは世界規模で見るのは難しいので、米国にズームインして同じ時期の動きを見てみましょう:
ここでは、トロント、デトロイト、ニューヨーク、カンザスシティがハードウェアの問題で一部のリクエストに対応できないため、ユーザーとデータセンターの均衡が回復するまで、ダラス、シカゴ、アッシュバーンにリクエストを送信していることがわかります。デトロイトのようなデータセンターが、トラフィックを転送する必要なく受信しているすべてのリクエストに対応できるようになれば、デトロイトはデータセンター内の問題が完全に解決するまでにシカゴへのリクエスト転送を徐々に停止していきます。この間、エンドユーザーはオンラインであり、デトロイトやトラフィックを送信している他の場所で起こっている物理的な問題の影響を受けることはありません。
満足いくネットワーク、満足いく製品
Traffic Managerは、Cloudflareネットワークの基本コンポーネントとしてユーザーエクスペリエンスに組み込まれています。当社製品をオンラインに接続し続け、可能な限りのスピードと信頼性を実現するものです。当社のリアルタイム・ロードバランサーであり、問題が発生しているデータセンターから必要なトラフィックだけをシフトすることによって、当社製品のスピードを高く保つ役目を果たしています。トラフィックの移動がより少なくなるため、当社製品とサービスが迅速に提供されるのです。
一方、トラフィック・マネージャーは信頼性の問題が発生しそうな場所を予測し、先手を打って製品を別の場所に移動させることができるため、製品のオンライン性と信頼性を維持するのにも役立ちます。例えば、ブラウザ分離はトラフィック・マネージャーと直接連携し、製品のアップタイムを保証しています。ホストされたブラウザインスタンスを作成するためにCloudflareデータセンターに接続すると、ブラウザ分離はまず、データセンターにローカルでインスタンスを実行するのに十分な容量があるかどうかをTraffic Managerに尋ねます。利用可能な容量が十分でない場合、Traffic Managerは、利用可能な容量が十分ある最も近いデータセンターをブラウザ分離に知らせ、ブラウザ分離がユーザーに可能な限り最高の体験を提供できるよう支援します。
満足いくネットワーク、満足するユーザー
Cloudflareでは、この巨大なネットワークを運用し、さまざまな製品やお客様のシナリオに対応しています。このネットワークは、耐障害性を考慮して構築されています。単一障害による影響を軽減するように設計されたMCPロケーションに加え、社内外の問題に対応するため、ネットワーク上のトラフィックを常に移動させています。
しかし、これは当社の問題であって、ユーザーの問題ではありません。
同様に、人間がそれらの問題を解決しなければならないとき、影響を受けるのは当社のお客様やエンドユーザーとなります。常にオンラインであることを確かなものにするため、ハードウェアの故障を検出し、ネットワーク全体のトラフィックを先取りしてバランスを取り、オンラインかつ可能な限り高速であることを保証するためのスマートシステムを構築しました。このシステムはあらゆる人間による操作よりも速く機能するため、当社のネットワークエンジニアが夜眠れるようになるだけでなく、当社のすべてのお客様により優れより速い体験を提供することができるのです。
最後に:ここまで説明したエンジニアリングの挑戦にご関心がおありなら、ぜひCloudflareの採用ページにあるトラフィックエンジニアリングチームの求人をご検討ください。