

This week we’ve talked about how Workers provides a step function improvement in the TTFB (time to first byte) of applications, by running lightweight isolates in over 200 cities around the world, free of cold starts. Today I’m going to talk about another metric, one that’s arguably even more important: TTFD, or time to first dopamine, and announce a huge improvement to the Workers development experience — wrangler dev, our edge-based development environment with all the perks of a local environment.
There’s nothing quite like the rush of getting your first few lines of code to work — no matter how many times you’ve done it before, there's something so magical about the computer understanding exactly what you wanted it to do and doing it!
This is the kind of magic I expected of “serverless”, and while it’s true that most serverless offerings today get you to that feeling faster than setting up a virtual server ever would, I still can’t help but be disappointed with how lackluster developing with most serverless platforms is today.
Some of my disappointment can be attributed to the leaky nature of the abstraction: the journey to getting you to the point of writing code is drawn out by forced decision making about servers (regions, memory allocation, etc). Servers, however, are not the only thing holding developers back from getting to the delightful magical feeling in the serverless world today.
The “serverless” experience on AWS Lambda today looks like this: between configuring the right access policy to invoke my own test application, and deciding whether an HTTP or REST API was better suited for my needs, 30 minutes had easily passed, and I still didn’t have a URL I could call to invoke my application. I did, however, spin up five different services, and was already worrying about cleaning them up lest I be charged for them.
That doesn’t feel like magic!
In building what we believe to be the serverless platform of the future — a promise that feels very magical — we wanted to bring back that magical feeling to every step of the development journey. If serverless is about empowering developers, then they should be empowered every step of the way: from proof of concept to MVP and beyond.
We’re excited to share with you today our approach to making our developer experience delightful — we recognize we still have plenty of room to continue to grow and innovate (and we can’t wait to tell you about everything we have currently in the works as well!), but we’re proud of all the progress we’ve made in making Workers the easiest development platform for developers to use.
Defining “developer experience”
To get us started, let’s look at what the journey of a developer entails. Today, we’ll be defining the user experience as the following four stages:
- Getting started: All the steps we have to take before putting in some keystrokes
- Iteration: Does my code do what I expect it to do? What do I need to do to get it there?
- Release: I’ve tested what I can -- time to hit the big red button!
- Observe: Is anything broken? And how do I fix it?
When approaching each stage of development, we wanted to reimagine the experience, the way that we’ve always wanted our development flow to work, and fix places along the way where existing platforms have let us down.
Zero to Hello World
With Workers, we want to get you to that aforementioned delightful feeling as quickly as possible, and remove every obstacle in the way of writing and deploying your code. The first deployment experience is really important — if you’ve done it once and haven’t given up along the way, you can do it again.
We’re very proud to say our TTFD — even for a new user without a Cloudflare account -- is as low as three minutes. If you’re an existing customer, you can have your first Worker running in seconds. No regions to choose, no IAM rules to configure, and no API Gateways to set up or worry about paying for.
If you’re new to Workers and still trying to get a feel for it, you can instantly deploy your Worker to 200 cities around the world within seconds, with the simple click of a button.
If you’ve already decided on Workers as the choice for building your next application, we want to make you feel at home by allowing you to use all of your favorite IDEs, be it vim or emacs or VSCode (we don’t care!).
With the release of wrangler — the official command-line tool for Workers, getting started is just as easy as:
wrangler generate hello
cd hello
wrangler publishAgain, in seconds your code is up and running, and easily accessible all over the world.
“Hello, World!”, of course, doesn’t have to be quite so literal. We provide a range of tutorials to help get you started and get familiar with developing with Workers.
To save you that last bit of time in getting started, our template gallery provides starter templates so you can dive straight into building the products you’re excited about -- whether it’s a new GraphQL server or a brand new static site, we’ve got you covered.
Local(ish) development: code, test, repeat
We can’t promise to get the code right on your behalf, but we can promise to do everything we can to get you the feedback you need to help you get your code right.
The development journey requires lots of experimentation, trial and error, and debugging. If my Computer Science degree came with instructions on the back of the bottle, they would read: “code, print, repeat.”
Getting code right is an extremely iterative, feedback-driven process. We would all love to get code right the first time around and move on, but the reality is, computers are bad mind-readers, and you’ve ended up with an extraneous parenthesis or a stray comma in your JSON, so your code is not going to run. Found where the loose parenthesis was introduced? Great! Now your code is running, but the output is not right — time to go find that off-by-one error.
Local development has traditionally been the way for developers to get a tight feedback loop during the development process. The crucial components that make up an effective local development environment and make it a great testing ground are: fast feedback loop, its sandboxed nature (ability to develop without affecting production), and accuracy.
As we started thinking about accomplishing all three of those goals, we realized that being local actually wasn’t itself a requirement — speed is the real requirement, and running on the client is the only way acceptable speed for a good-enough feedback loop could be achieved.
One option was to provide a traditional local development environment, but one thing didn’t sit well with us: we wanted to provide a local development environment for the Workers runtime, however, we knew there was more to handling a request than just the runtime, which could compromise accuracy. We didn’t want to set our users up to fail with code that works on their machine but not ours.
Shipping the rest of our edge infrastructure to the user would pose its own challenges of keeping it up to date, and it would require the user to install hundreds of unnecessary dependencies, all potentially to end up with the most frustrating experience of all: running into some installation bug the explanation to which couldn’t be found on StackOverflow. This experience didn’t sit right with us.
As it turns out, this is a very similar problem to one we commonly solve for our customers: Running code on the client is fast, but it doesn’t give me the control I need; running code on the server gives me the control I need, but it requires a slow round-trip to the origin. All we had to do was take our own advice and run it on the edge! It’s the best of both worlds: your code runs so close to your end user that you get the same performance as running it on the client, without having to lose control.
To provide developers access to this tight feedback loop, we introduced wrangler dev earlier this year!

wrangler dev has the look and feel of a local development environment: it runs on localhost but tunnels to the edge, and provides output directly to your favorite IDE of choice. Since wrangler dev now runs on the edge, it works on your machine and ours exactly the same!
Our release candidate for wrangler dev is live and waiting for you to take it for a test drive, as easily as:
npm i @cloudflare/wrangler@beta -gLet us know what you think.
Release
After writing all the code, testing every edge case imaginable, and going through code review, at some point the code needs to be released for the rest of the world to reap the fruits of your hard labor and enjoy the features you’ve built.
For smaller, quick applications, it’s exciting to hit the “Save & deploy” button and let fate take the wheel.
For production level projects, however, the process of deploying to production may be a bit different. Different organizations adopt different processes for code release. For those using GitHub, last year we introduced our GitHub Action, to make it easy to configure an integrated release process.
With Wrangler, you can configure Workers to deploy using your existing CI, to automate deployments, and minimize human intervention.
When deploying to production, again, feedback becomes extremely important. Some platforms today still take as long as a few minutes to deploy your code. A few minutes may seem trivial, but a few minutes of nervously refreshing, wondering whether your code is live yet, and which version of your code your users are seeing is stressful. This is especially true in a rollback or a bug-fix situation where you want the new version to be live ASAP.
New Workers are deployed globally in less than five seconds, which means new changes are instantaneous. Better yet, since Workers runs on lightweight isolates, newly deployed Workers don’t experience dreaded cold starts, which means you can release code as frequently as you’re able to ship it, without having to invest additional time in auxiliary gadgets to pre-warm your Worker — more time for you to start working on your next feature!
Observe & Resolve
The big red button has been pushed. Dopamine has been replaced with adrenaline: the instant question on your mind is: “Did I break anything? And if so, what, and how do I fix it?” These questions are at the core of what the industry calls “observability”.
There are different ways things can break and incidents can manifest themselves: increases in errors, drops in traffic, even a drop in performance could be considered a regression.
To identify these kinds of issues, you need to be able to spot a trend. Raw data, however, is not a very useful medium for spotting trends — humans simply cannot parse raw lines of logs to identify a subtle increase in errors.
This is why we took a two-punch approach to helping developers identify and fix issues: exposing trend data through analytics, while also providing the ability to tail production logs for forensics and investigation.
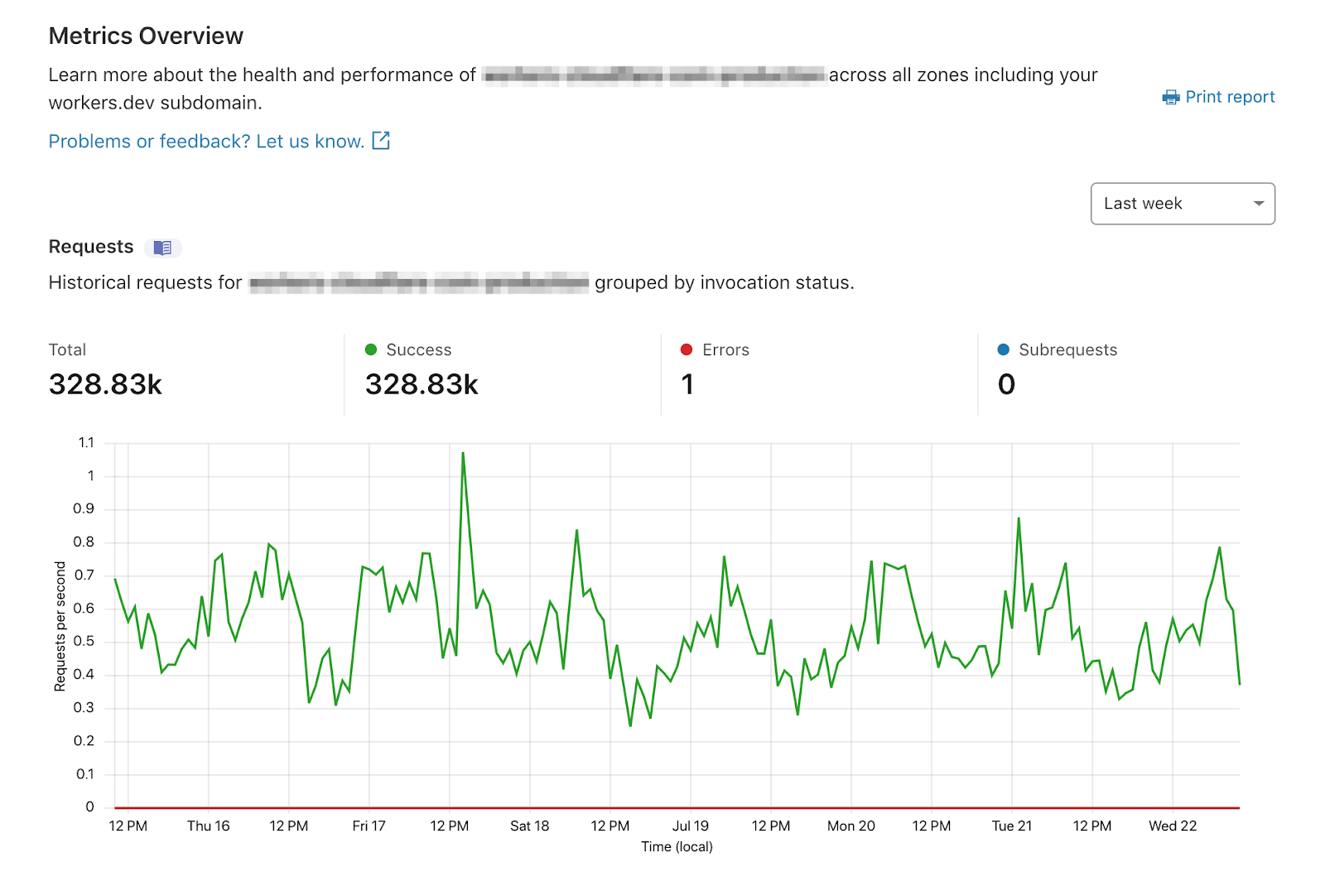
Earlier this year, we introduced Workers Metrics: an easy way for developers to identify trends in their production traffic.
With requests metrics, you can easily spot any increases in errors, or drastic changes in traffic patterns after a given release:
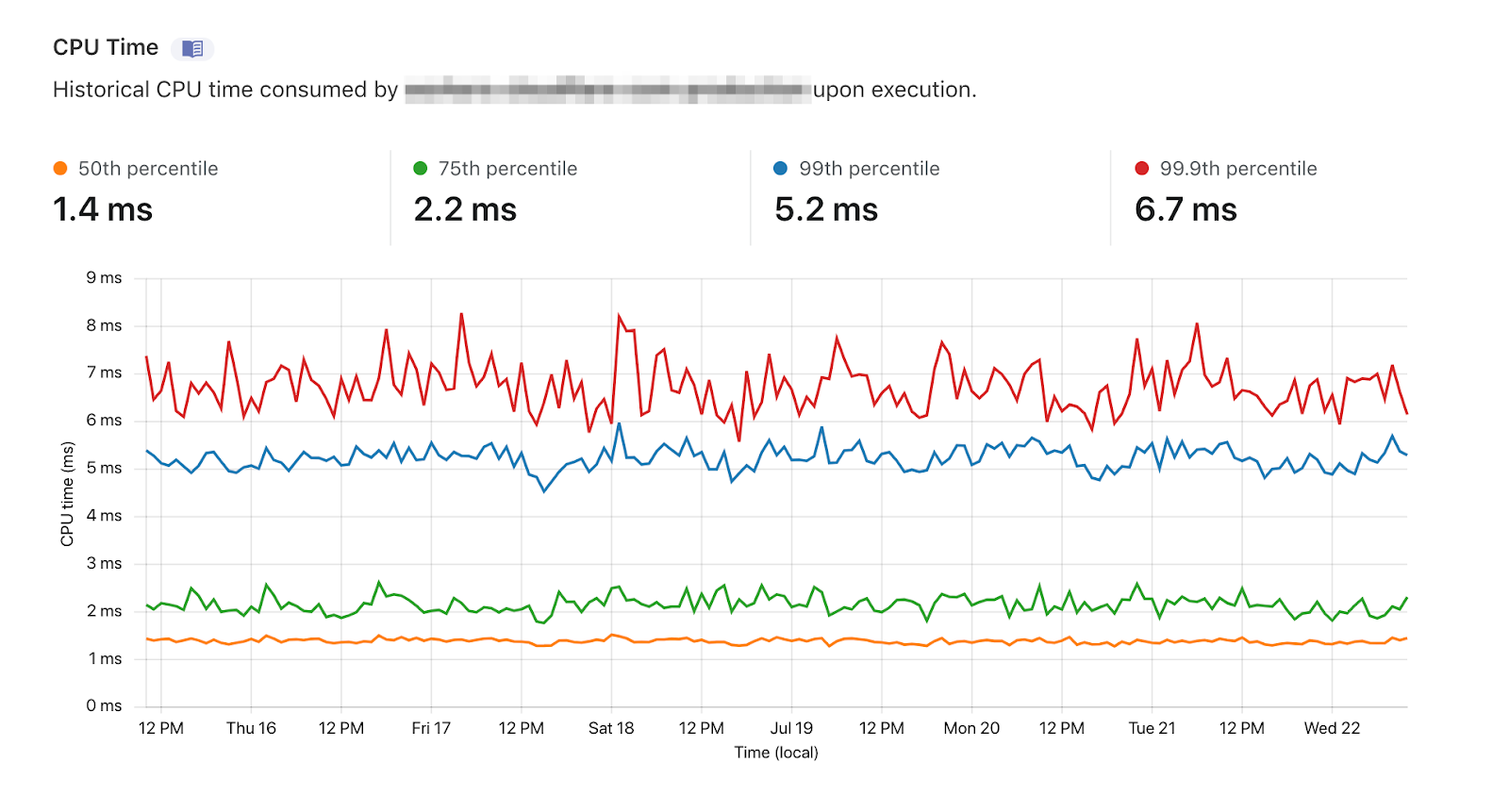
Additionally, sometimes new code can introduce unforeseen regressions in the overall performance of the application. With CPU time metrics, our developers are now able to spot changes in the performance of their Worker, as well as use that information to guide and optimize their code.
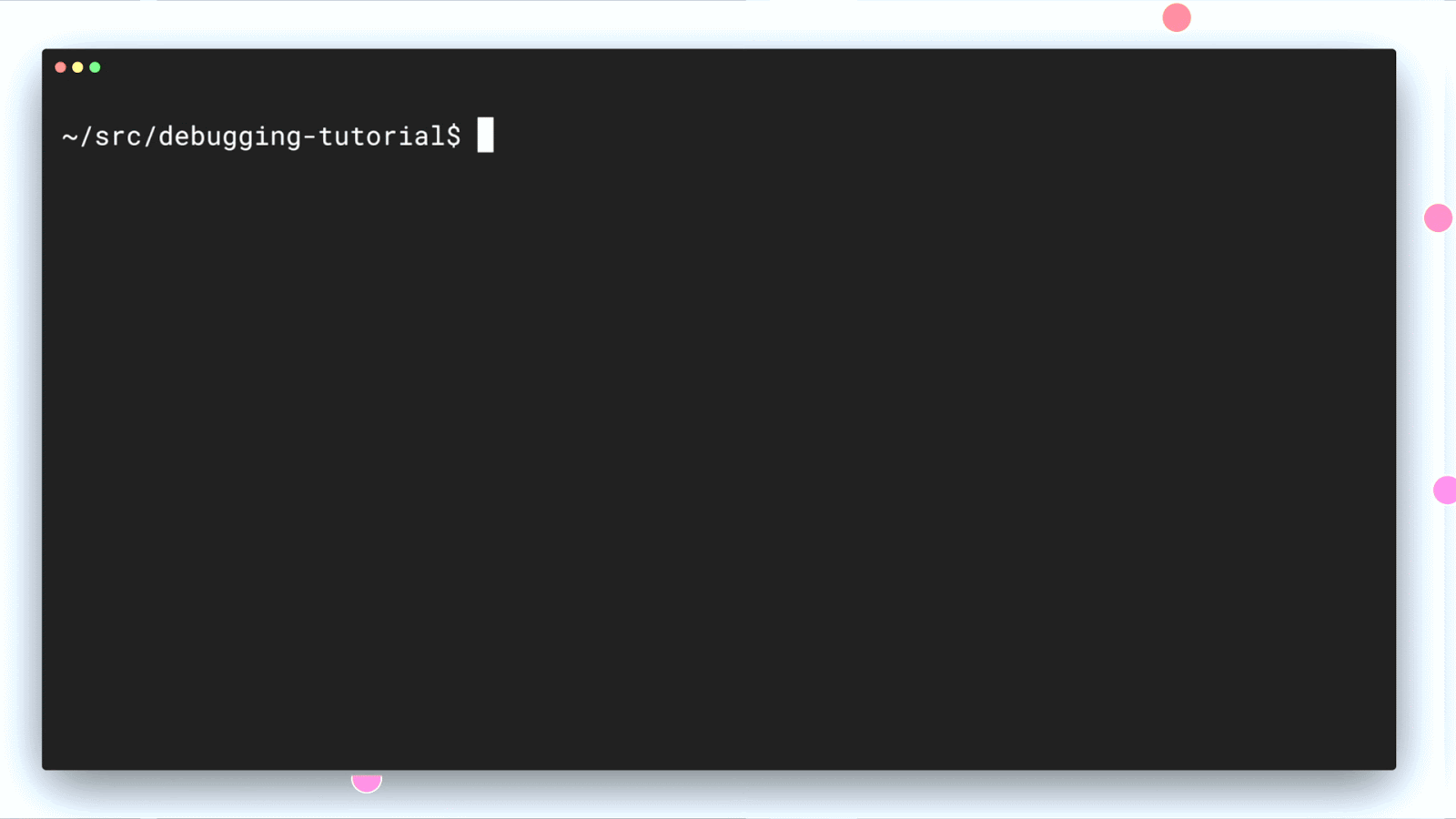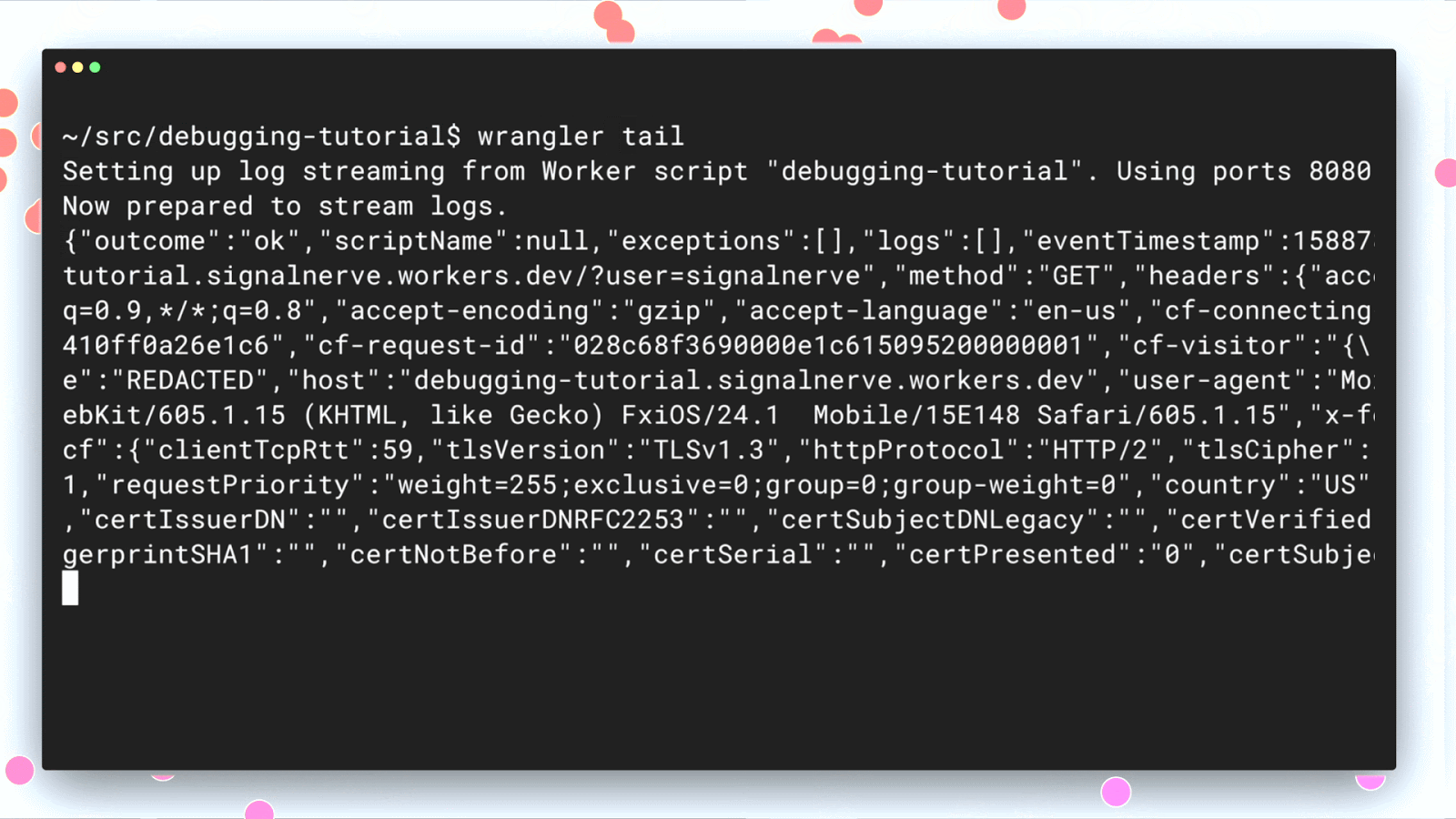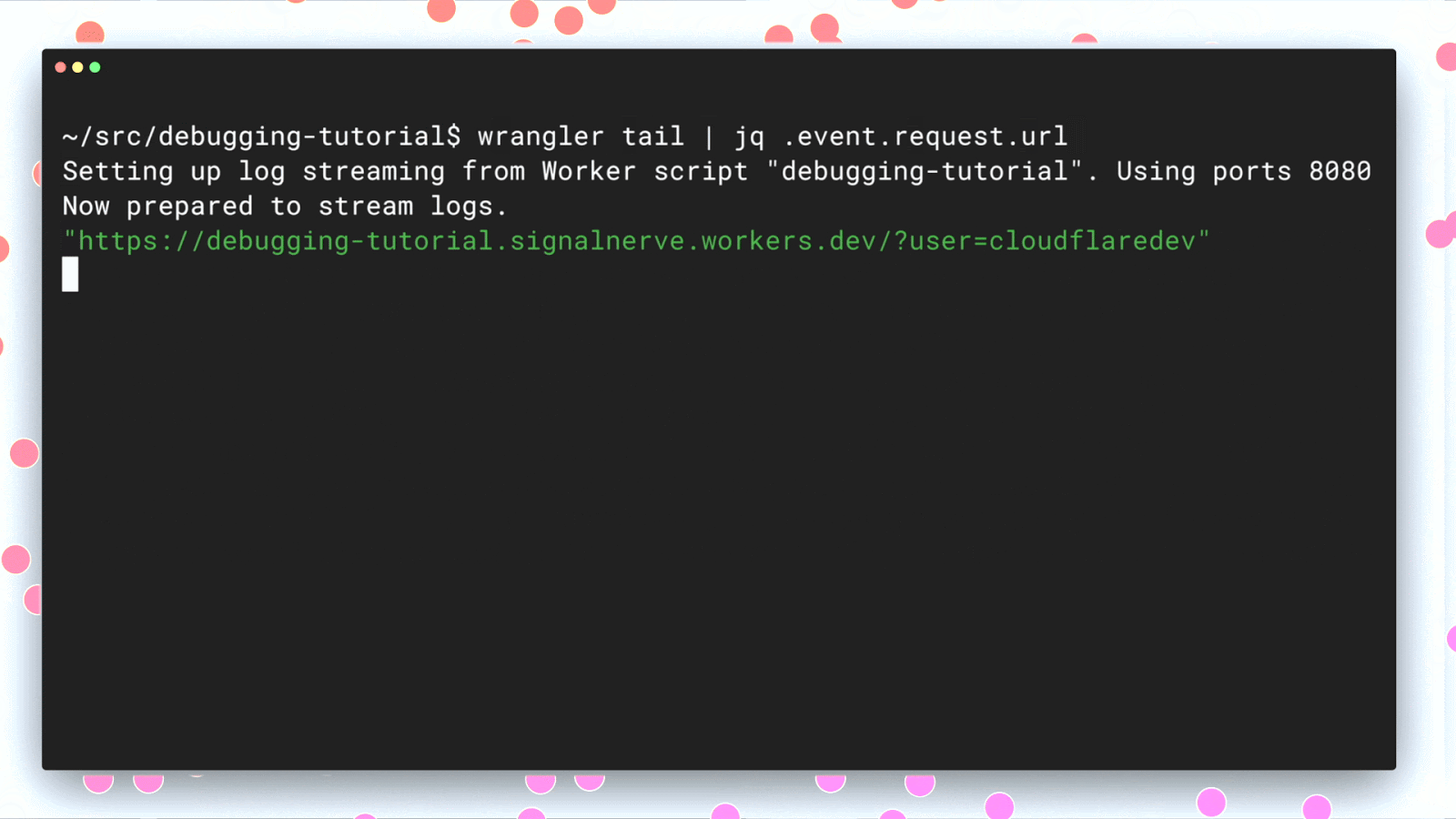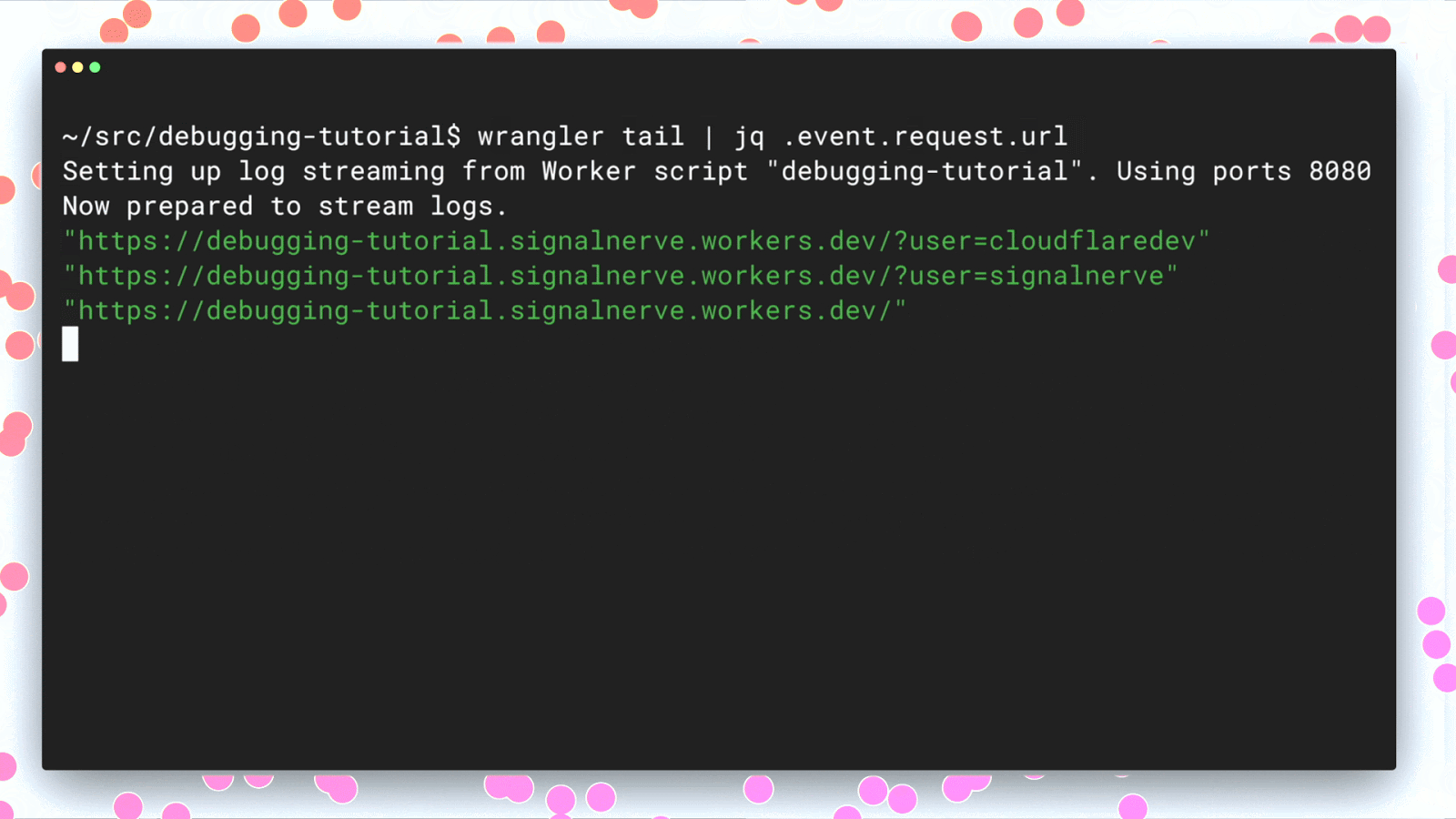
Once you’ve identified a regression, we wanted to provide the tools needed to find your bug and fix it, which is why we also recently launched `wrangler tail`: production logs in a single command.
wrangler tail can help diagnose where code is failing or why certain customers are getting unexpected outcomes because it exposes console.log() output and exceptions. By having access to this output, developers can immediately diagnose, fix, and resolve any issues occurring in production.
We know how precious every moment can be when a bad code deploy impacts customer traffic. Luckily, once you’ve found and fixed your bug, it’s only a matter of seconds for users to start benefiting from the fix — unlike other platforms which make you wait as long as 5 minutes, Workers get deployed globally within five seconds.
Repeat

As you’re thinking about your next feature, you checkout a new branch, and the cycle begins all over. We’re excited for you to check out all the improvements we’ve made to the development experience with Workers, all to reduce your time to first dopamine (TTFD).
We are always working on improving it further, looking where we can remove every additional bit of friction, and love to hear your feedback as we do so.