
Efficient packet dropping is a key part of Cloudflare’s distributed denial of service (DDoS) attack mitigations. In this post, we introduce a new tool in our packet dropping arsenal: L4Drop.

We've written about our DDoS mitigation pipeline extensively in the past, covering:
- Gatebot: analyzes traffic hitting our edge and deploys DDoS mitigations matching suspect traffic.
- bpftools: generates Berkeley Packet Filter (BPF) bytecode that matches packets based on DNS queries, p0F signatures, or tcpdump filters.
- Iptables: matches traffic against the BPF generated by bpftools using the
xt_bpfmodule, and drops it. - Floodgate: offloads work from iptables during big attacks that could otherwise overwhelm the kernel networking stack. Incoming traffic bypasses the kernel to go directly to a BPF interpreter in userspace, which efficiently drops packets matching the BPF rules produced by bpftools.
Both iptables and Floodgate send samples of received traffic to Gatebot for analysis, and filter incoming packets using rules generated by bpftools. This ends up looking something like this:

This pipeline has served us well, but a lot has changed since we implemented Floodgate. Our new Gen9 and ARM servers use different network interface cards (NIC) than our earlier servers. These new NICs aren’t compatible with Floodgate as it relies on a proprietary Solarflare technology to redirect traffic directly to userspace. Floodgate’s time was finally up.
XDP to the rescue
A new alternative to the kernel bypass approach has been added to Linux: eXpress Data Path (XDP). XDP uses an extended version of the classic BPF instruction set, eBPF, to allow arbitrary code to run for each packet received by a network card driver. As Marek demonstrated, this enables high speed packet dropping! eBPF introduces a slew of new features, including:
- Maps, key-value data structures shared between the eBPF programs and userspace.
- A Clang eBPF backend, allowing a sizeable subset of C to be compiled to eBPF.
- A stringent kernel verifier that statically analyzes eBPF programs, ensuring run time performance and safety.
Compared to our partial kernel bypass, XDP does not require busy polling for packets. This enables us to leave an XDP based solution “always on” instead of enabling it only when attack traffic exceeds a set threshold. XDP programs can also run on multiple CPUs, potentially allowing a higher number of packets to be processed than Floodgate, which was pinned to a single CPU to limit the impact of busy polling.
Updating our pipeline diagram with XDP yields:

Introducing L4Drop
All that remains is to convert our existing rules to eBPF! At first glance, it seems we should be able to store our rules in an eBPF map and have a single program that checks incoming packets against them. Facebook’s firewall implements this strategy. This allows rules to be easily inserted or removed from userspace.
However, the filters created by bpftools rely heavily on matching arbitrary packet data, and performing arbitrary comparisons across headers. For example, a single p0f signature can check both IP & TCP options. On top of this, the thorough static analysis performed by the kernel’s eBPF verifier currently disallows loops. This restriction helps ensure that a given eBPF program will always terminate in a set number of instructions. Coupled together, the arbitrary matching and lack of loops prevent us from storing our rules in maps.
Instead, we wrote a tool to compile the rules generated by Gatebot and bpftools to eBPF. This allows the generated eBPF to match against any packet data it needs, at the cost of:
- Having to recompile the program to add or remove rules
- Possibly hitting eBPF code complexity limits enforced by the kernel with many rules
A C program is generated from the rules built by Gatebot, and compiled to eBPF using Clang. All that’s left is to reimplement the iptables features we use.
BPF support
We have many different tools for generating BPF filters, and we need to be able to include these filters in the eBPF generated by L4Drop. While the name eBPF might suggest a minor extension to BPF, the instruction sets are not compatible. In fact, BPF instructions don't even have a one-to-one mapping to eBPF! This can be seen in the kernel's internal BPF to eBPF converter, where a single BPF IP header length instruction maps to 6 eBPF instructions.
To simplify the conversion, we implemented a BPF to C compiler. This allows us to include any BPF program in the aforementioned C program generated by L4Drop. For example, if we generate a BPF program matching a DNS query to any subdomain of example.com using bpftools, we get:
$ ./bpfgen dns -- "*.example.com"
18,177 0 0 0,0 0 0 20,12 0 0 0,...
Converted to C, we end up with:
bool cbpf_0_0(uint8_t *data, uint8_t *data_end) {
__attribute__((unused))
uint32_t a, x, m[16];
if (data + 1 > data_end) return false;
x = 4*(*(data + 0) & 0xf);
...
}
The BPF instructions each expand to a single C statement, and the BPF registers (a, x and m) are emulated as variables. This has the added benefit of allowing Clang to optimize the full program. The generated C includes the minimum number of guards required to prevent out of bounds packet accesses, as required by the kernel.
Packet sampling
Gatebot requires all traffic received by a server to be sampled at a given rate, and sent off for analysis. This includes dropped packets. Consequently, we have to sample before we drop anything. Thankfully, eBPF can call into the kernel using a restricted set of helper functions, and one of these, bpf_xdp_event_output, allows us to copy packets to a perf event ring buffer. A userspace daemon then reads from the perf buffer, obtaining the packets. Coupled with another helper, bpf_get_prandom_u32(), to generate random numbers, the C code to sample packets ends up something like:
// Threshold may be > UINT32_MAX
uint64_t rnd = (uint64_t)get_prandom_u32();
if (rnd < threshold) {
// perf_event_output passes the number of bytes as a flags in the
// high 32 bits of the flags parameter.
uint64_t flags = len << 32;
// Use the current CPU number as index to sampled_packets.
flags |= BPF_F_CURRENT_CPU;
// Write the packet in ctx to the perf buffer
if (xdp_event_output(ctx, &sampled_packets, flags, &len, sizeof(len))) {
return XDP_ABORTED;
}
}
The newtools/ebpf library we use to load eBPF programs into the kernel has support for creating the required supporting eBPF map (sampled_packets in this example), and reading from the perf buffer in userspace.
Geo rules
With our large anycast network, a truly distributed denial of service attack will impact many of our data centers. But not all attacks have this property. We sometimes require location specific rules.
To avoid having to build separate eBPF programs for every location, we want the ability to enable or disable rules before loading a program, but after compiling it.
One approach would be to store whether a rule is enabled or not in an eBPF map. Unfortunately, such map lookups can increase the code size. Due to the kernel’s strict code complexity limits for XDP code, this reduces the number of rules that fit in a single program. Instead, we modify the generated eBPF ELF before loading it into the kernel.
If, in the original C program, every rule is guarded by a conditional like so:
int xdp_test(struct xdp_md *ctx) {
unsigned long long enabled;
asm("%0 = 0 ll" : "=r"(enabled));
if (enabled) {
// Check the packet against the rule
return XDP_DROP;
} else {
return XDP_PASS;
}
}
asm("%0 = 0 ll" : "=r"(enabled)) will emit a single 64bit eBPF load instruction, loading 0 into the register holding the variable enabled:
$ llvm-objdump-6.0 -S test.o
test.o: file format ELF64-BPF
Disassembly of section prog:
xdp_test:
0: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
2: b7 00 00 00 02 00 00 00 r0 = 2
3: 15 01 01 00 00 00 00 00 if r1 == 0 goto +1 <LBB0_2>
4: b7 00 00 00 01 00 00 00 r0 = 1
LBB0_2:
5: 95 00 00 00 00 00 00 00 exit
Modifying the ELF to change the load instruction to load 0 or 1 will change the value of enabled, enabling or disabling the rule. The kernel even trims conditionals against constants like these.
Modifying the instructions requires the ability to differentiate these special loads against ones normally emitted by Clang. Changing the asm to load a symbol (asm("%0 = RULE_0_ENABLED ll" : "=r"(enabled))) ensures it shows up in the ELF relocation info with that symbol name:
$ llvm-readelf-6.0 -r test.o
Relocation section '.relprog' at offset 0xf0 contains 1 entries:
Offset Info Type Symbol's Value Symbol's Name
0000000000000000 0000000200000001 R_BPF_64_64 0000000000000000 RULE_0_ENABLED
This enables the newtools/ebpf loader to parse the ELF relocation info, and always find the correct load instruction that guards enabling or disabling a rule.
Production
L4Drop is running in production across all of our servers, and protecting us against DDoS attacks. For example, this server dropped over 8 million packets per second:
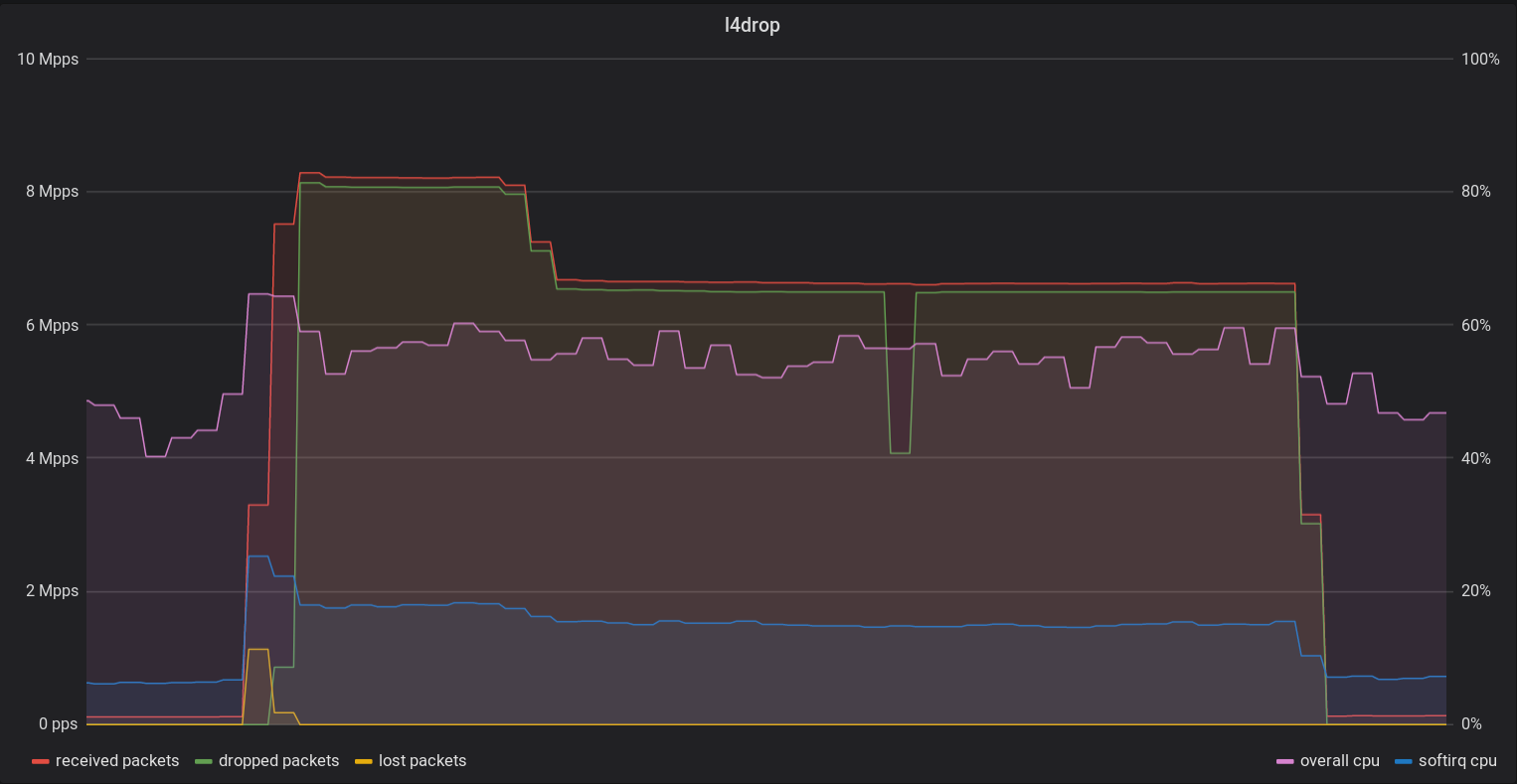
The graph shows a sudden increase in received packets (red). Initially, the attack overwhelmed the kernel network stack, causing some packets to be lost on the network card (yellow). The overall CPU usage (magenta) rose sharply.
Gatebot detected the attack shortly thereafter, deploying a rule matching the attack traffic. L4Drop began dropping the relevant packets (green), reaching over 8 million dropped packets per second.
The amount of traffic dropped (green) closely followed the received traffic (red), and the amount of traffic passed through remains unchanged before, during, and after the attack. This highlights the effectiveness of the deployed rule. At one point the attack traffic changed slightly, leading to a gap between the dropped and received traffic until Gatebot could respond with a new rule.
During the brunt of the attack, the overall CPU usage (magenta) only rose by about 10%, demonstrating the efficiency of XDP.
The softirq CPU usage (blue) shows the CPU usage under which XDP / L4drop runs, but also includes other network related processing. It increased by slightly over a factor of 2, while the number of incoming packets per second increased by over a factor of 40!
Conclusion
While we’re happy with the performance of L4Drop so far, our pipeline is in a constant state of improvement. We’re working on supporting a greater number of simultaneous rules in L4Drop through multiple, chained, eBPF programs. Another point of focus is increasing the efficiency of our generated programs, and supporting new eBPF features. Reducing our attack detection delay would also allow us to deploy rules quicker, leading to less lost packets at the onset of an attack.