


本日、Workers AIにMistral-7B-v0.1-instructを追加したことをお知らせします。Mistral 7Bは、73億のパラメーターを持つ言語モデルで、多くのユニークな利点を備えています。Mistral AIの創設者の協力のもと、Mistral 7Bモデルのハイライトをいくつか紹介します。この機会に「Attention」とそのバリエーションであるMulti-Query AttentionやGrouped-Query Attentionについても深く掘り下げてみましょう。
Mistral 7B tl;dr:
Mistral 7Bは、ベンチマークで素晴らしい数字を叩き出す73億パラメーターのモデルです。以下は本モデルの特長です。
- 13Bモデルと比較してすべてのベンチマークで性能を上回る。
- 34Bモデルと比較して多くのベンチマークで性能を上回る。
- CodeLlama 7Bに匹敵するコード性能を持ちつつ、英語タスクの優秀さも維持。
- 導入されたチャットの微調整バージョンは、Mistralが提供したベンチマークで、2 13Bチャットを上回る。
以下は、REST APIを使用してストリーミングを行う例です:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
以下は、Workerスクリプトを使用した例です。
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistralは推論を高速化するためにグループ化されたクエリ注意を利用します。この最近開発されたテクニックは、出力の質を落とすことなく推論の速度を向上させます。グループ化されたクエリ注意のおかげで、70億のパラメーターモデルに対して、MistralはLlamaの4倍近いトークンを1秒間に生成することができます。
Mistral-7Bを使い始めるのに、これ以上の情報は必要ありません。ai.Cloudflare.comで今すぐテストできます。AttentionとGrouped-Query Attentionについてもっと知りたい方は、こちらをお読みください!
そもそも「Attention」とは何でしょうか?
Attentionの基本的なメカニズム、具体的には画期的な論文「Attention Is All You Need」で紹介された「Scaled Dot-Product Attention」は以下のように非常にシンプルです。
私たちはこの特定のAttentionを「Scale Dot-Product Attention」(スケール化ドット積注意)と呼んでいます。入力はクエリ、次元のキー「d_k」、次元の値「d_v」から構成されます。クエリとすべてのキーのドット積を計算し、それぞれを平方根(d_k)で割り、softmax関数を適用して値の重みを求めます。
具体的には次のようになります。
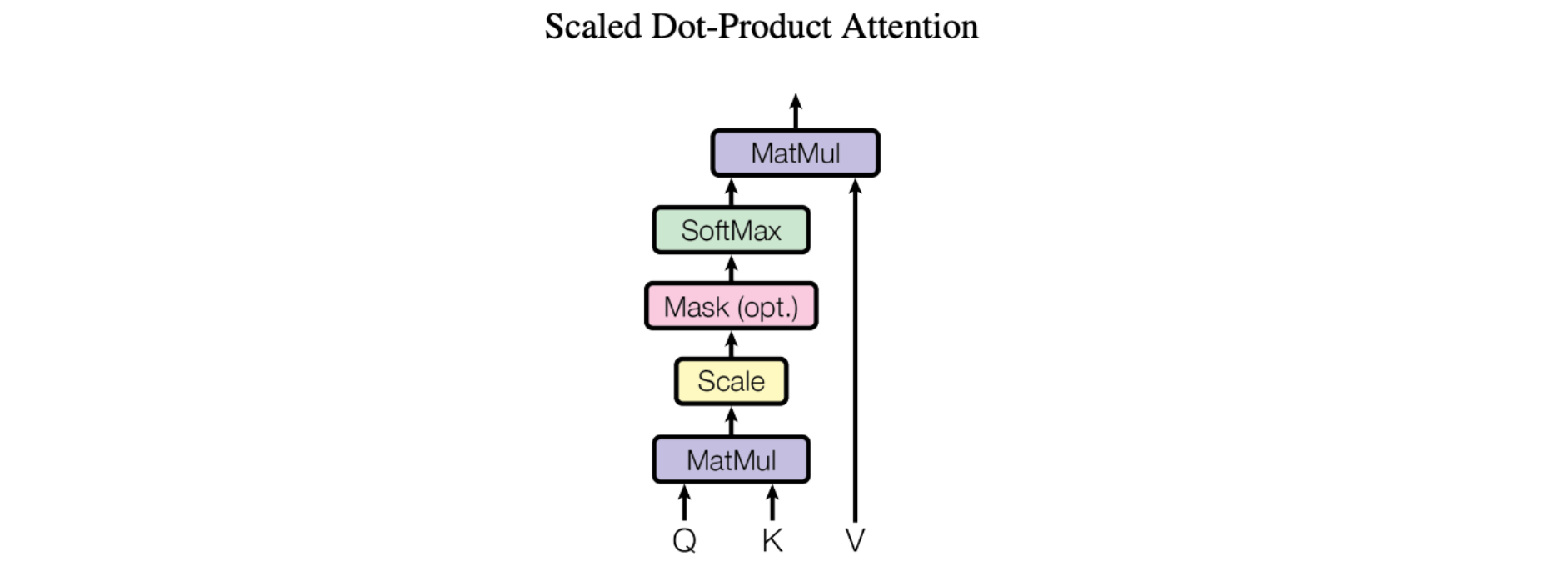
もっと簡単に言えば、これによってモデルは入力の重要な部分に集中することができます。ある文章を読んでいて、それを理解しようとしているところを想像してみてください。Scaled dot product attentionでは、関連性に基づいて特定の単語により多くの注意を払うことができます。これは、文中の各単語(K)とクエリ(Q)の類似度を計算することによって行なわれます。次に、類似度スコアをクエリの次元の平方根で割ってスケーリングします。このスケーリングは、極端に小さい値や極端に大きい値を避けるのに役立ちます。最後に、これらの類似度スコアを使用して、各単語がどの程度注目されるか、または重要視されるかを決定します。このAttentionメカニズムは、モデルが重要な情報(V)を識別し、理解と翻訳能力を向上させるのに役立ちます。
簡単でしょう?この単純なメカニズムから、「ジェリーがバブルソート・アルゴリズムを学習する『となりのサインフェルド』エピソード」を書けるAIになるには、もっと複雑にする必要があります。実際、今取り上げたものには、学習されたパラメーター(モデルのトレーニング中に学習され、Attentionブロックの出力をカスタマイズする定数値)すらありません!
「Attention is All You Need」スタイルのAttentionブロックは、主に以下の3種類の複雑さを加えます。
学習されたパラメーター
学習されたパラメーターとは、モデルのパフォーマンスを向上させるために学習過程で調整される値や重みのことです。これらのパラメーターは、モデル内の情報の流れやAttentionを制御するために使用され、入力データの最も関連性の高い部分に焦点を当てることができます。もっと簡単に言えば、学習されたパラメーターは、機械の調節可能なつまみのようなもので、それを回すことで動作を最適化することができます。
垂直スタッキング - Attentionブロックを重ねる
垂直レイヤースタッキングとは、複数のAttention機構を積み重ねる方法で、各レイヤーは前のレイヤーのアウトプットの上に構築されます。これにより、モデルは抽象度の異なる入力データの異なる部分に焦点を当てることができ、特定のタスクでより優れたパフォーマンスを発揮することができます。
水平スタッキング - 別名Multi-Head Attention
論文に掲載された図は、Multi-Head Attentionモジュールの全容を示したものです。複数のAttention操作は並行して行われ、それぞれのQ-K-V入力は、同じ入力データ(学習されたパラメーターのユニークなセットによって定義される)のユニークな線形射影によって生成されます。これらの並列Attentionブロックは「Attentionヘッド」と呼ばれます。すべてのAttentionヘッドの加重和出力は1つのベクトルに連結され、最終出力を得るために別のパラメーター化された線形変換に渡されます。
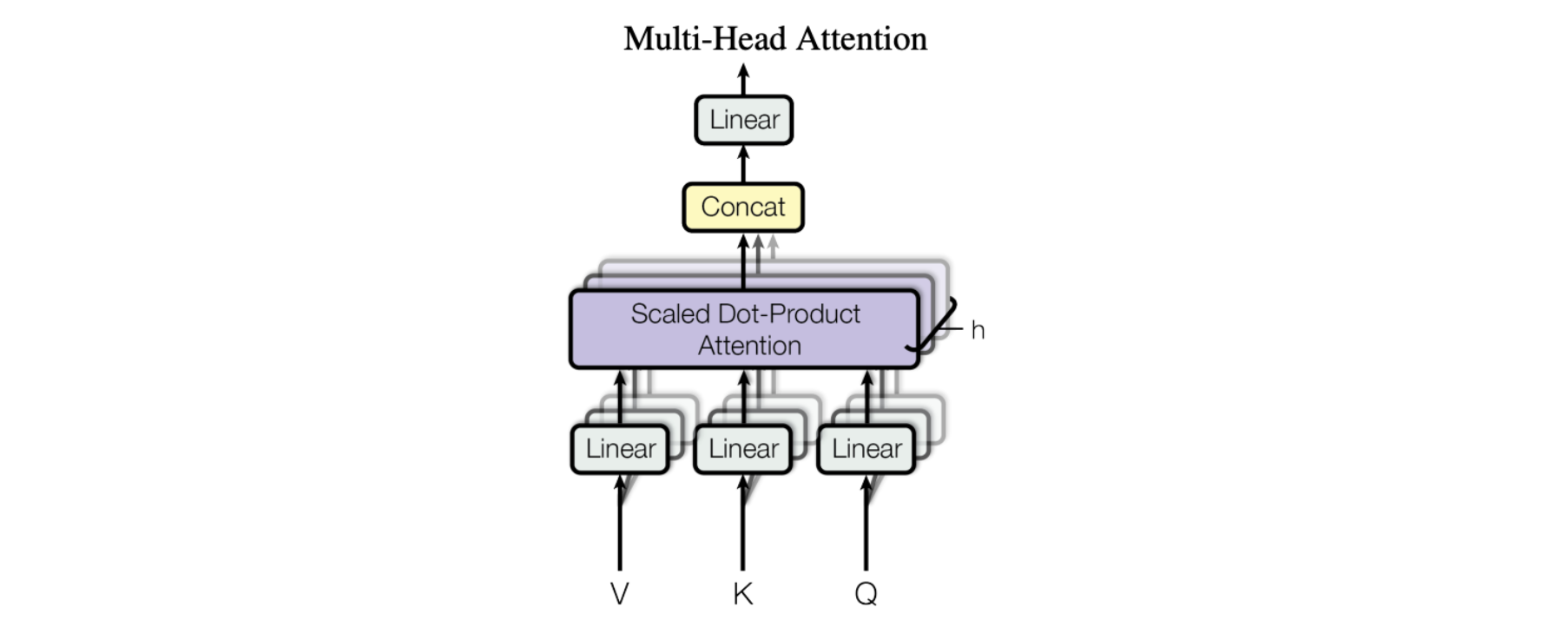
このメカニズムにより、モデルは入力データの異なる部分に同時に焦点を当てることができます。文章や段落のような複雑な情報を理解しようとしているところを想像してみてください。それを理解するためには、同時にさまざまな部分に注意を払う必要があります。例えば、文の意味を理解するためには、文の主語、動詞、目的語に同時に注意を払う必要があるかもしれません。Multi-Head Attentionも同様です。これは、複数のAttentionの「ヘッド」を使用することによって、モデルが入力データの異なる部分に同時に注意を払うことを可能にします。Attentionの各ヘッドは入力データの異なる側面に焦点を当て、すべてのヘッドの出力は、モデルの最終的な出力を生成するために結合されます。
Attentionのスタイル
近年開発された大規模言語モデルで使用されるAttentionブロックには、Multi-Head Attention、Grouped-Query Attention、Multi-Query Attentionの3つの一般的な配置があります。これらは、クエリーベクトルの数に対するKとVのベクトルの数が異なります。Multi-Head AttentionはQベクトルと同じ数のKベクトルとVベクトルを使用します。下表では「N」で示されています。Multi-Query Attentionは、単一のKとVベクトルだけを使用します。Grouped-Query Attentionは、Mistral 7Bモデルで使用されているタイプで、Qベクトルをそれぞれ「G」ベクトルを含むグループに均等に分割し、各グループに単一のKおよびVベクトルを使用して、合計NをKおよびVベクトルのGセットで分割します。この違いを要約し、以下にその意味を説明します。
|
キー/値ブロックの数 |
品質 |
メモリ使用量 |
|
|
Multi-head attention (MHA) |
N |
ベスト |
最も多い |
|
Grouped-query attention (GQA) |
N / G |
良い |
少ない |
|
Multi-query attention (MQA) |
1 |
良い |
最も少ない |
Attentionスタイルのまとめ
そしてこの図は、3つのスタイルの違いを説明するのに役立ちます。
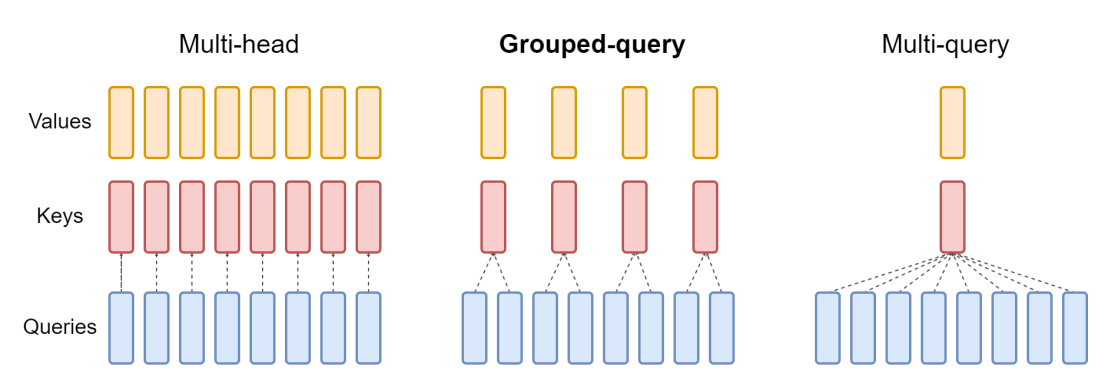
Multi-Query Attention
Multi-Query Attentionは、2019年にGoogleからの論文「Fast Transformer Decoding: One Write-Head is All You Need」(トランスフォーマーの高速デコード: 必要なのは1つのライトヘッドのみ)で説明されました。このアイデアは、上記のMulti-Head Attentionのように、Attention機構内のすべてのQベクトルに対して別々のKとVエントリを作成する代わりに、Qベクトルのセット全体に対して単一のKとVベクトルだけを使用するというものです。このように、複数のクエリを1つのAttention機構にまとめたものがこの名前です。論文では、これを翻訳タスクでベンチマークし、ベンチマークタスクでMulti-Head Attentionと同等の性能を示しました。
もともとは、モデルの推論を実行する際にアクセスされるメモリの総サイズを小さくすることでした。それ以来、一般化されたモデルが出現し、パラメーターの数が増えるにつれて、必要なGPUメモリがボトルネックになることが多く、3つのAttentionタイプの中でアクセラレーターメモリの必要が最小となるMulti-Query Attentionの強みとなっています。しかし、モデルのサイズが大きくなり、一般性が増すにつれて、Multi-Query AttentionのパフォーマンスはMulti-Head Attentionに比べて低下しました。
Grouped-Query Attention
最も新しいスタイルで、Mistralでも使われているものは、Grouped-Query Attentionです。2023年5月にarxiv.orgで発表された論文「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」(GQA: マルチヘッドチェックポイントからの一般化マルチクエリー変換モデルの学習)で説明されています。Grouped-Query Attentionは、Multi-Head Attentionの品質、およびMulti-Query Attentionの速度と低いメモリ使用量という両方の長所を兼ね備えています。KとVのベクトル1セット、またはQベクトルごとに1セットの代わりに、QベクトルごとにKとVのベクトル1セットの固定比率が使用され、メモリ使用量を削減しながら、多くのタスクで高いパフォーマンスを維持します。
多くの場合、生産作業のためにモデルを選択する場合、単に入手可能な最良のモデルを選ぶわけではありません。パフォーマンス、メモリ使用量、バッチサイズ、利用可能なハードウェア(またはクラウドコスト)の間のトレードオフを考慮しなければならないからです。この3つのAttentionスタイルを理解することは、そうした決断の指針になり、状況に応じて特定のモデルを選択する場合を理解するのに役立ちます。
Mistralをどうぞ今すぐお試しください
Grouped-Query Attentionを活用し、それをSliding Window Attentionと組み合わせた最初の大規模言語モデルの1つであるMistralは、「生命維持可能領域」に到達したようです。低遅延、高スループットであり、大型モデル(13B)と比べてもベンチマークで非常に良い結果を出しています。そのサイズにしてはパンチがあるということです。そして、Workers AIを通じて、すべての開発者が今日利用できるようになったことは、何よりの喜びです。
まずは開発者用ドキュメントをご覧になって、開始してください。ヘルプが必要な場合、フィードバックが必要な場合、作っているものを共有なさりたい場合は、開発者用Discordにおいでください!
Workers AIチームも雇用を拡大しています。AIエンジニアリングに情熱を持ち、グローバルなサーバーレスGPU推論プラットフォームの構築と発展に貢献したい方は、求人ページで募集職種をご覧ください。