Vectorizeは、Cloudflareのグローバルネットワーク上で完全にフルスタックのAI搭載アプリケーションを構築できるように設計された、すぐにでも構築を始めることができる当社の全く新しいベクトルデータベース製品です。Vectorizeはオープンベータであり、Cloudflare Workersを利用されている開発者であれば、どなたでもご利用いただけます。
Vectorize with Workers AIをご利用いただくと、Workersを使用したセマンティック検索、分類、推奨、異常検出のユースケースの直接強化、LLM(大規模言語モデル)からの回答の精度やコンテキストの向上、OpenAIやCohereなどの一般的なプラットフォームからの独自の埋め込みを取り込むことができます。
ベクトルデータベースが何をするものか、Vectorizeは何が違うのかをより詳しく知りたい方は、Vectorizeの開発者向けドキュメントをご一読ください。
ベクトルデータベースが必要な理由
機械学習モデルは、学習したことしか記憶できません。
ベクトルデータベースは、構造化・非構造化テキスト、画像、音声などをMLモデルがどのようにデータを表現するかをキャプチャし、将来の入力と比較できるように保存することで、この問題を解決するように設計されています。これにより、それらがトレーニングされていないコンテンツに対して既存の機械学習モデルやLLM(大規模言語モデル)の力を活用することができます。このことは、モデルのトレーニングにかかる莫大なコストを考えると、非常に強力な機能であることをご理解いただけると思います。
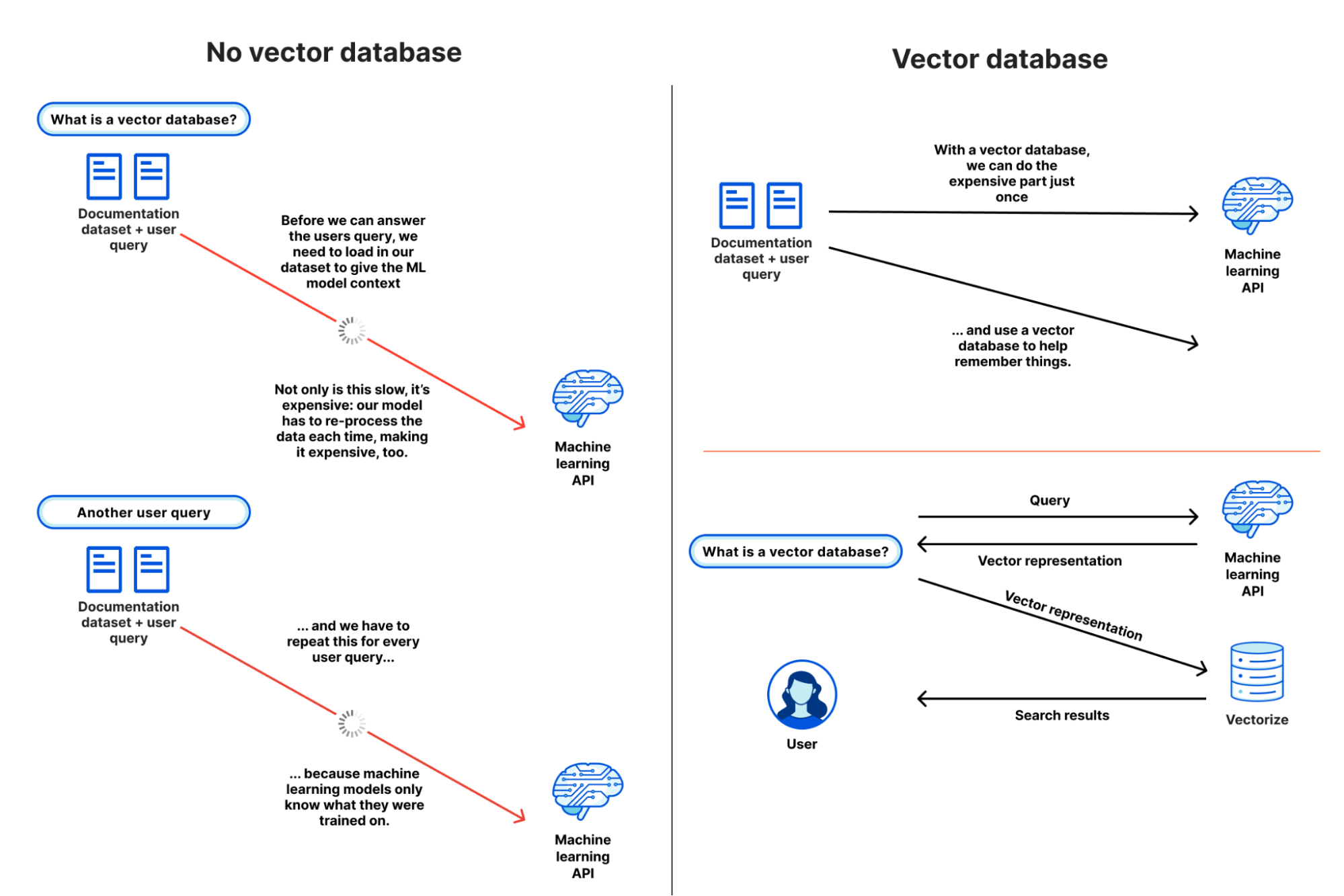
Vectorizeのようなベクトルデータベースがなぜ有用であるかをより分かりやすく説明するために、ベクトルデータベースが存在しない世界を仮定して、セマンティック検索や推薦タスクのためにMLモデルやLLMにコンテキストを与えることがいかに大変な作業であるかを見てみましょう。目標は、クエリーに対するコンテンツの一致度を理解して、データセットを基にそれを返すことです。
- 「Cloudflare WorkersからR2に書き込む方法」を検索するユーザーからのクエリーが入ります。
- 私たちは、(ありがたいことに「小さい」データセットである2.1GBの約65,000センテンスの)ドキュメントデータセット全体を読み込み、ユーザーからのクエリーと一緒に提供します。これによって、データを基に、モデルに必要なコンテキストを持たせることができます。
- しばらく待ちます。
- (長い間)
- ユーザーのクエリーに最も近いセンテンスの類似度スコアが返され、それらをURLにマッピングしてから検索結果を返します。
...そしてまた別のクエリーが入り、これをまた最初からやり直します。
現実的に、これを行うことは不可能です。多くの機械学習モデルはAPI呼び出し(プロンプト)でそれほど多くのコンテキストを渡すことはできません。たとえできたとしても、データセットを幾度となく処理するために膨大な量のメモリと時間を消費することになります。
ベクトルデータベースを使えば、上記手順2を繰り返す必要はありません。一度だけ、あるいはデータセットの更新時に実行し、ベクトルデータベースを機械学習モデルの長期記憶として利用します。ワークフローは以下により近いものになります:
- ドキュメントデータセット全体を読み込み、モデルを通して実行し、結果のベクトル埋め込みをベクトルデータベースに保存します(一度のみ)。
- 各ユーザークエリー(およびクエリーのみ)を同一のモデルに問い合わせてベクトル表現を取得します。
- そのクエリーベクトルを使用してベクトルデータベースに問い合わせることで、クエリーベクトルに最も近いベクトルが返されます。
この2つのフローを並べて見ることで、ベクトルデータベースを使用せずに既存のモデルで独自のデータセットを使用することが、いかに非効率的で非現実的であるかが一目でわかります:
この簡単な例から、多少なりとも理解に近付いたことと思います。ですが、なぜ普通のデータベースではなく、ベクトルデータベースが必要なのかという疑問は残るかもしれません。
ベクトルとは、入力に対するモデルの表現であり、その入力を内部構造、つまり「特徴」にどのようにマッピングするかを示すものです。大まかに言えば、類似したベクトルが多ければ多いほど、モデルは(入力から特徴を抽出する方法を基に)入力同士がより類似していると捉えます。
ほんの一握りの次元のベクトルを例にとれば、これは一見簡単なことのように見えます。しかし実世界の出力では、1万~25万のベクトルおよびそれぞれが潜在的に持つ1,536次元もの幅を検索することは簡単ではありません。そこでベクトルデータベースの出番となります。ベクトルデータベースは、大規模な検索を可能にするために、k近傍法(kNN)や他の近似最近傍探索(ANN)のような特定のクラスのアルゴリズムを使用してベクトルの類似性を判断します。
また、ベクトルデータベースはAIや機械学習を利用したアプリケーションを構築する際に非常に有用ですが、そのようなユースケースにのみ有用なわけではなく、多くの分類や異常検出タスクにも使用することができます。クエリー入力が他の入力と類似しているか否かを知ることで、コンテンツモデレーション(既知の不適切なコンテンツと一致するか)やセキュリティアラート(以前に検知したことがあるか)のタスクに活用することもできます。
ベクトル検索によるレコメンドエンジンの構築
私たちはVectorizeを、Workers AIの強力なパートナーとして構築しました。ベクトル検索タスクを可能な限りユーザーの近くで実行するため、本番環境でのスケールアップを考える必要はありません。
ここでは実際の例として、eコマースストア向けの(商品)レコメンドエンジンの構築を取り上げます。(一部単純化しています)。
ベクトル検索の完璧なユースケースである、各商品リストページに「関連商品」のリストを表示することをゴールとします。この例の入力ベクトルは事前に用意したものですが、実際のアプリケーションでは、商品説明やカートデータを文章の類似性モデル(Worker's AIのテキスト埋め込みモデルなど)に渡して生成します。
各ベクトルがストア全体の商品を表すため、それに商品のURLを関連付けます。各ベクトルのIDを商品IDに設定することもできます。どちらの方法も有効です。クエリー(ベクトル検索)は、ユーザーが現在閲覧している商品の商品説明とコンテンツを表しています。実際のコード例を見てみましょう。この例は開発者ドキュメントからそのまま引用したものです:
export interface Env {
// This makes our vector index methods available on env.MY_VECTOR_INDEX.*
// e.g. env.MY_VECTOR_INDEX.insert() or .query()
TUTORIAL_INDEX: VectorizeIndex;
}
// Sample vectors: 3 dimensions wide.
//
// Vectors from a machine-learning model are typically ~100 to 1536 dimensions
// wide (or wider still).
const sampleVectors: Array<VectorizeVector> = [
{ id: '1', values: [32.4, 74.1, 3.2], metadata: { url: '/products/sku/13913913' } },
{ id: '2', values: [15.1, 19.2, 15.8], metadata: { url: '/products/sku/10148191' } },
{ id: '3', values: [0.16, 1.2, 3.8], metadata: { url: '/products/sku/97913813' } },
{ id: '4', values: [75.1, 67.1, 29.9], metadata: { url: '/products/sku/418313' } },
{ id: '5', values: [58.8, 6.7, 3.4], metadata: { url: '/products/sku/55519183' } },
];
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
if (new URL(request.url).pathname !== '/') {
return new Response('', { status: 404 });
}
// Insert some sample vectors into our index
// In a real application, these vectors would be the output of a machine learning (ML) model,
// such as Workers AI, OpenAI, or Cohere.
let inserted = await env.TUTORIAL_INDEX.insert(sampleVectors);
// Log the number of IDs we successfully inserted
console.info(`inserted ${inserted.count} vectors into the index`);
// In a real application, we would take a user query - e.g. "durable
// objects" - and transform it into a vector emebedding first.
//
// In our example, we're going to construct a simple vector that should
// match vector id #5
let queryVector: Array<number> = [54.8, 5.5, 3.1];
// Query our index and return the three (topK = 3) most similar vector
// IDs with their similarity score.
//
// By default, vector values are not returned, as in many cases the
// vectorId and scores are sufficient to map the vector back to the
// original content it represents.
let matches = await env.TUTORIAL_INDEX.query(queryVector, { topK: 3, returnVectors: true });
// We map over our results to find the most similar vector result.
//
// Since our index uses the 'cosine' distance metric, scores will range
// from 1 to -1. A value of '1' means the vector is the same; the
// closer to 1, the more similar. Values of -1 (least similar) and 0 (no
// match).
// let closestScore = 0;
// let mostSimilarId = '';
// matches.matches.map((match) => {
// if (match.score > closestScore) {
// closestScore = match.score;
// mostSimilarId = match.vectorId;
// }
// });
return Response.json({
// This will return the closest vectors: we'll see that the vector
// with id = 5 has the highest score (closest to 1.0) as the
// distance between it and our query vector is the smallest.
// Return the full set of matches so we can see the possible scores.
matches: matches,
});
},
};
上記のコードは意図的に単純なものにしていますが、ベクトル検索の中核部分を示しています。データベースにベクトルを挿入し、クエリーのベクトルの距離が最も小さいベクトルを問い合わせます。
以下は値を含む視覚的な観測結果で、クエリーのベクトル[54.8, 5.5, 3.1]が、検索から返された最も高いスコアの一致[58.799,6.699,3.400]に類似しています。このインデックスはコサイン類似度でベクトル間の距離を計算し、スコアが1に近いほど、ベクトルの類似度が大きいことを意味します。
{
"matches": {
"count": 3,
"matches": [
{
"score": 0.999909,
"vectorId": "5",
"vector": {
"id": "5",
"values": [
58.79999923706055,
6.699999809265137,
3.4000000953674316
],
"metadata": {
"url": "/products/sku/55519183"
}
}
},
{
"score": 0.789848,
"vectorId": "4",
"vector": {
"id": "4",
"values": [
75.0999984741211,
67.0999984741211,
29.899999618530273
],
"metadata": {
"url": "/products/sku/418313"
}
}
},
{
"score": 0.611976,
"vectorId": "2",
"vector": {
"id": "2",
"values": [
15.100000381469727,
19.200000762939453,
15.800000190734863
],
"metadata": {
"url": "/products/sku/10148191"
}
}
}
]
}
}
実際のアプリケーションでは、最も類似度の高い商品を基に商品の推薦URLを素早く返し、スコア順にソート(最高値から最低値)し、表示を増やす場合はtopK値を増やすことができます。各ベクトルに付随して格納されるメタデータには、R2オブジェクトへのパス、D1データベースの行のUUID、またはWorkers KVからのキーと値のペアを埋め込むこともできます。
Workers AI + Vectorize:Cloudflare上でのフルスタックベクトル検索
実際のアプリケーションでは、(データベースのシード処理のために)オリジナルのデータセットからベクトル埋め込みを生成し、ユーザーからのクエリーを素早くベクトル埋め込みに変換できる機械学習モデルが必要です。モデルごとに表現する特徴が異なるため、これらは同じモデルである必要があります。
以下はCloudflareでエンドツーエンドのベクトル検索パイプライン全体を構築するコンパクトな例です:
import { Ai } from '@cloudflare/ai';
export interface Env {
TEXT_EMBEDDINGS: VectorizeIndex;
AI: any;
}
interface EmbeddingResponse {
shape: number[];
data: number[][];
}
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
const ai = new Ai(env.AI);
let path = new URL(request.url).pathname;
if (path.startsWith('/favicon')) {
return new Response('', { status: 404 });
}
// We only need to generate vector embeddings just the once (or as our
// data changes), not on every request
if (path === '/insert') {
// In a real-world application, we could read in content from R2 or
// a SQL database (like D1) and pass it to Workers AI
const stories = ['This is a story about an orange cloud', 'This is a story about a llama', 'This is a story about a hugging emoji'];
const modelResp: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: stories,
});
// We need to convert the vector embeddings into a format Vectorize can accept.
// Each vector needs an id, a value (the vector) and optional metadata.
// In a real app, our ID would typicaly be bound to the ID of the source
// document.
let vectors: VectorizeVector[] = [];
let id = 1;
modelResp.data.forEach((vector) => {
vectors.push({ id: `${id}`, values: vector });
id++;
});
await env.TEXT_EMBEDDINGS.upsert(vectors);
}
// Our query: we expect this to match vector id: 1 in this simple example
let userQuery = 'orange cloud';
const queryVector: EmbeddingResponse = await ai.run('@cf/baai/bge-base-en-v1.5', {
text: [userQuery],
});
let matches = await env.TEXT_EMBEDDINGS.query(queryVector.data[0], { topK: 1 });
return Response.json({
// We expect vector id: 1 to be our top match with a score of
// ~0.896888444
// We are using a cosine distance metric, where the closer to one,
// the more similar.
matches: matches,
});
},
};
上記のコードは次の4つの内容を実行しています:
- 3つの文をWorkers AIのテキスト埋め込みモデル(@cf/baai/bge-base-ja-v1.5)に渡し、そのベクトル埋め込みを取得します。
- これらのベクトルをVectorizeのインデックスに挿入します。
- ユーザーからのクエリーを受け取り、同一のWorkers AIモデルを通してベクトル埋め込みに変換します。
- 一致するVectorizeインデックスを問い合わせます。
この例は単純「すぎる」ように見えるかもしれませんが、本番アプリケーションでは、ベクトルを1回(またはCron Triggersを介して定期的に)挿入する、この3つの例文を、R2、D1データベース、または他のストレージプロバイダに保存された実際のデータに置き換えるといった2つの変更だけで完了します。
実際、これは私たちがCloudflare Workerに関する質問に答えるAIアシスタント「Cursor」の実行方法と非常によく似ています(私たちはCursorをWorkers AIとVectorize上で実行するように移行しました)。組み込みのテキスト埋め込みモデルを使用して開発者向けドキュメントからテキスト埋め込みを生成し、Vectorizeインデックスに挿入し、同じモデルを介してユーザーからのクエリーをその場で変換します。
お気に入りのAI APIから独自の埋め込みを持ち込む
VectorizeはWorkers AI専用ではなく、完全に独立したベクトルデータベースです。
すでにOpenAIのEmbedding APIや、Cohereの多言語モデル、その他の埋め込みAPIを使用している場合は、Vectorizeに簡単に独自のベクトルを持ち込む(BYO)ことができます。
これは、埋め込みを生成し、それをVectorizeに挿入し、インデックスにクエリーを実行する前にモデルにクエリーを渡すという全く同じ動作をします。Vectorizeには、最も一般的な埋め込みモデルのいくつかのショートカットが含まれています。
# Vectorize has ready-to-go presets that set the dimensions and distance metric for popular embeddings models
$ wrangler vectorize create openai-index-example --preset=openai-text-embedding-ada-002
これは、既存のEmbeddings APIを中心とした既存のワークフローが既にある場合や、ユースケースに対して特定のマルチモーダルまたは多言語の埋め込みモデルを検証している場合に特に有用です。
AIのコストを予測可能にする
AIとMLには非常に大きな期待が寄せられている一方で、実験にコストがかかりすぎる、大規模な予測が困難であると言う大きな懸念があります。
私たちはVectorizeのベクトルデータベースに、よりシンプルな価格モデルを採用したいと考えました。職場で概念実証のアイデアをお持ちですか?当社の設定する無料利用枠に収まります。パフォーマンスと精度を最適化するために埋め込みの次元をスケールアップしたいですか?予約枠を破綻させることはありません。
重要なのは、Vectorizeでは予測可能であることを目指していることです。使い始めでは困難で、まったく新しいユースケースで本番のピークとオフピークの時間帯を計画しようとするとさらに困難となるCPUやメモリの消費量を見積もる必要はありません。課金は、保存しているベクトル次元の総数と、毎月のそれらに対するクエリーの数に基づいて行われます。お客様のクエリーパターンに合わせたスケールアップは私たちの仕事です。
以下はVectorizeの価格表です。現在Workersの有料プランを利用されている場合、Vectorizeは2024年まで完全無料でご利用いただけます:
| Workers 無料版 (近日公開) | Workers 有料版 ($5/月) | |
|---|---|---|
| クエリーされたベクトル次元数を含む | 3千万 (総クエリ次元数) / 月 | 5千万 (総クエリ次元数) / 月 |
| 保存されたベクトル次元数を含む | 5百万 (保存次元数) / 月 | 1千万 (保存次元数) / 月 |
| 追加料金 | $0.04 / 100万 (クエリまたは保存ベクトル次元数) | $0.04 / 100万 (クエリまたは保存ベクトル次元数) |
価格は、保存する内容とクエリーの内容によって決まり、(問い合わせたベクトルの次元の合計 + 保存)* ベクトルあたりの大きさ * 価格となります。問い合わせ数を増やしますか?簡単に予測可能です。速度を向上させ、全体的な遅延を減らすために、ベクトルあたりの次元を小さくするように最適化しますか?コストは低減します。新しいユースケースを試作したり実験するためのインデックスを複数お持ちですか?インデックスごとの課金はありません。
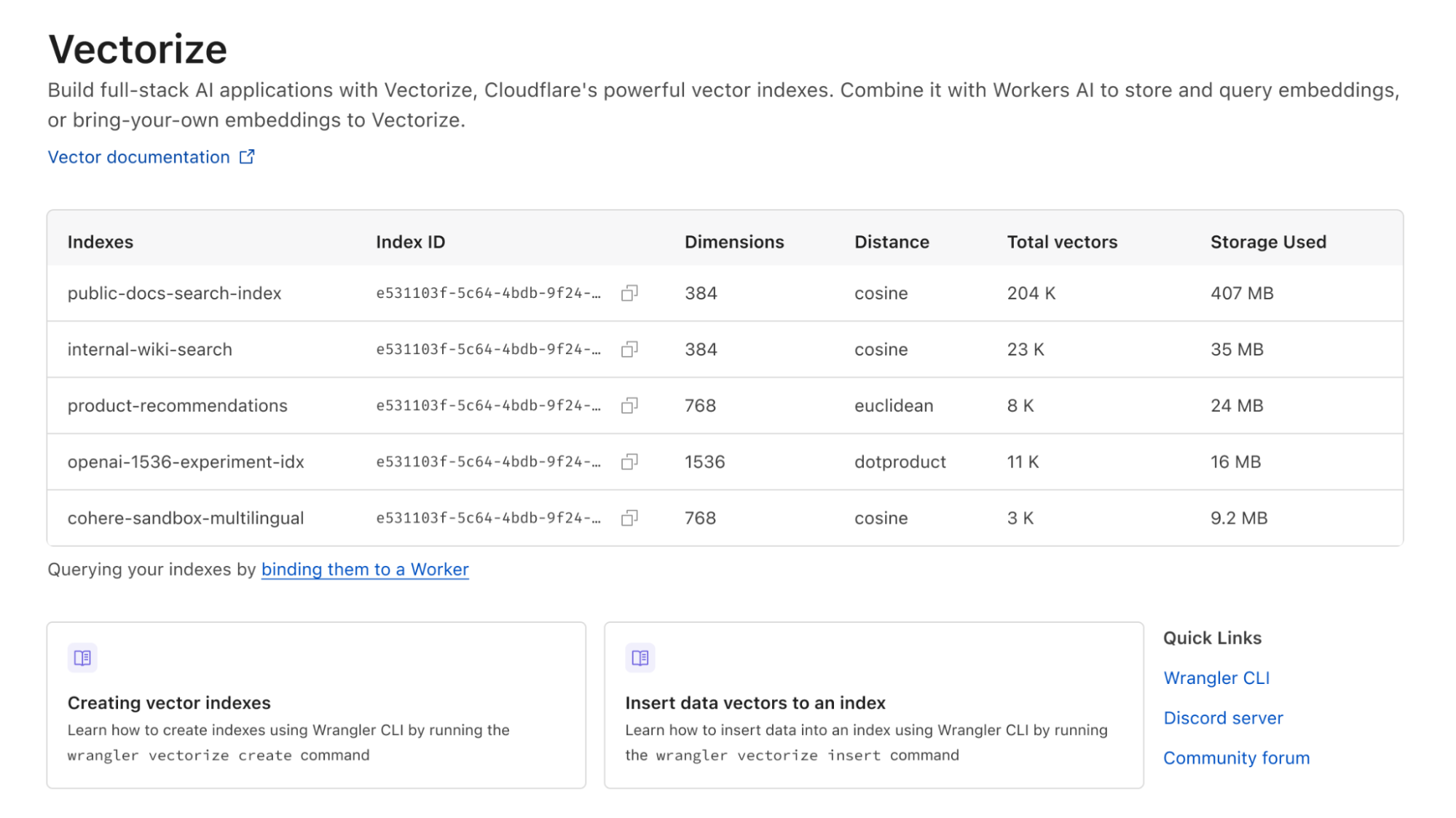
例として、10,000個のWorkers AIベクトル(各384次元)を読み込み、インデックスに対して毎日5,000回のクエリーを行った場合、クエリーされるベクトル次元の合計は4,900万となり、Workersの有料プラン(月額5ドル)にまだ収まります。さらに嬉しいことに、非アクティブな状態が原因でインデックスが削除されることはありません。
この価格設定は確定版ではありませんが、今後の変更はほぼないと考えています。プラットフォームでビルドを始め、コードの記入やテスト、技術のニュアンスを学んだ後で、その価格設定を維持できない状態に気づくほど最悪なことはなく、私たちはそのような驚愕の要素は避けたいと考えています。
Vectorize!
有料プランをご利用のWorkers開発者であれば、どなたでもすぐにVectorizeを使い始めることができます。現在利用できるのはオープンベータです。始めるには開発者向けドキュメントをご覧ください。
これもまた、私たちCloudflareにとってのベクトルデータベースの物語の始まりに過ぎません。今後数週間から数か月の間に、クエリーのパフォーマンスをさらに向上させ、さらに大きなインデックスをサポートし、サブインデックスのフィルタリング機能の導入、メタデータの制限の増加、インデックスごとの分析を行う新しいクエリーエンジンのリリースを予定しています。
何を作ればいいのかヒントをお探しの方は、Workers AIとVectorizeを組み合わせたドキュメント検索を行うセマンティック検索のチュートリアル(完全にCloudflareで実行)、またはOpenAIとVectorizeを組み合わせてLLMにより多くのコンテキストを与えて回答の精度を劇的に向上させる方法の例をご覧ください。また、当社の製品およびエンジニアリングチームでの Vectorizeの使用方法について質問がある方や、Workers AIを使用して構築している他の開発者とアイデアを交換したい方は、是非当社のDeveloper Discordの#vectorizeおよび#workers-aiチャンネルにご参加ください。