

はじめに
アプリケーションでデータを保存する方法はたくさんあります。例えば、Cloudflare Workersアプリケーションでは、キーバリューストレージとしてWorkers KVを、一貫性を損なわずにリアルタイムで連携したストレージとしてDurable Objectsを用意しています。Cloudflareのエコシステムの外側では、NoSQLやグラフデータベースなどの他のツールもプラグインできます。
それでも、SQLが欲しくなることがあります。インデックスを使えば、データを素早く取り出せるようになりますし、Joinにより、異なるテーブル間の複雑な関係を記述することができます。SQLは、アプリケーションのデータがどのように検証され、作成され、パフォーマンスよくクエリーが行われるかを宣言的に記述します。
D1は本日、オープンアルファ版がリリースされました。これを記念して、D1を使ってアプリを構築した体験を共有したいと思います。具体的には、構築の始め方と、D1がCloudflareでアプリを構築するためのツールの仲間入りを果たしたことに私がワクワクしている理由です。
D1は、新しいツールを必要とすることなく、Cloudflareのエコシステム内でアプリケーションに即座に付加価値を与えることができる点で注目に値します。Wranglerを使えばWorkersアプリケーションをローカルで開発できますし、WranglerにD1が追加されたことで、きちんとしたステートフルなアプリケーションもローカルで開発できるようになりました。そして、アプリケーションをデプロイするとき、WranglerによりD1データベースとAPI自体にアクセスしてコマンドを実行することができるようになるのです。
Cloudflareが構築しているもの
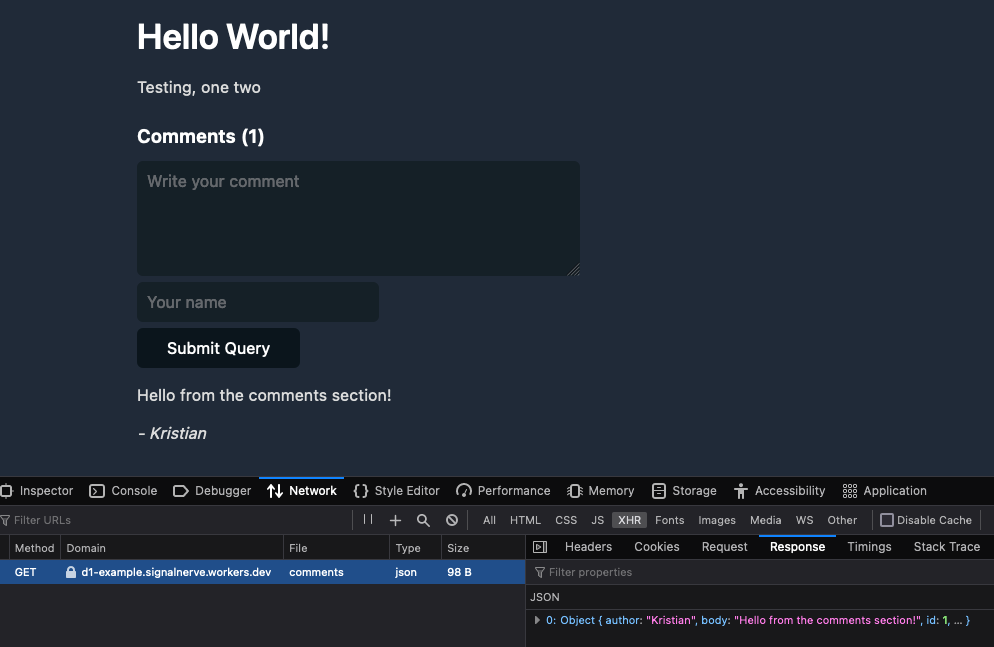
こののブログ記事では、D1を使って静的なブログサイトにコメントを追加する方法を紹介します。説明用に、新しいD1データベースを構築し、コメントの作成と取得を可能にする単純なJSON APIを構築します。
先ほど述べたように、D1をアプリ本体から分離することで、静的なサイトとは別にAPIとデータベースを残し、Webサイトの静的な部分と動的な部分を互いに抽象化することができるのです。また、アプリケーションのデプロイも簡単になります。フロントエンドはCloudflare Pagesに、D1のAPIはCloudflare Workersにデプロイされます。
新規アプリケーションの構築
まず、Workersで基本的なAPIを追加します。新しいディレクトリを作成し、その中に新しいWranglerプロジェクトを作成します。
$ mkdir d1-example && d1-example
$ wrangler init
この例では、APIを迅速に構築するために、Express.jsスタイルフレームワークのHonoを使用します。このプロジェクトでHonoを使用するには、NPMを使用してインストールします。
$ npm install hono
次に、src/index.tsで新しいHonoアプリを初期化し、GET /API/posts/:slug/commentsとPOST /get/api/:slug/commentsといういくつかのエンドポイントを定義します。
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
それでは、D1データベースを作成します。Wrangler 2では、wrangler d1サブコマンドがサポートされており、コマンドラインから直接D1データベースを作成し、クエリーを行うことができます。これにより、例えば、1つのコマンドで新しいデータベースを作成できます。
$ wrangler d1 create d1-example
作成したデータベースで、データベース名IDを取得し、wranglerの設定ファイルである wrangler.toml内でバインディングと関連付けることができます。バインディングを使うと、D1データベース、KVネームスペース、R2バケットなどのCloudflareリソースに、コード内の簡単な変数名でアクセスできるようになります。以下では、バインディングDBを作成し、新しいデータベースを表すために使用します。
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
このディレクティブ、[[d1_databases]]フィールドは、現在wranglerのベータ版を必要とすることに注意してください。これをプロジェクトにインストールするには、npm install -D wrangler/betaコマンドを実行します。
wrangler.tomlでデータベースが設定された状態になり、コマンドラインおよびWorkers関数の内部で対話できます。
まず、wrangler d1 executeを使って、直接SQLコマンドを発行できます。
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
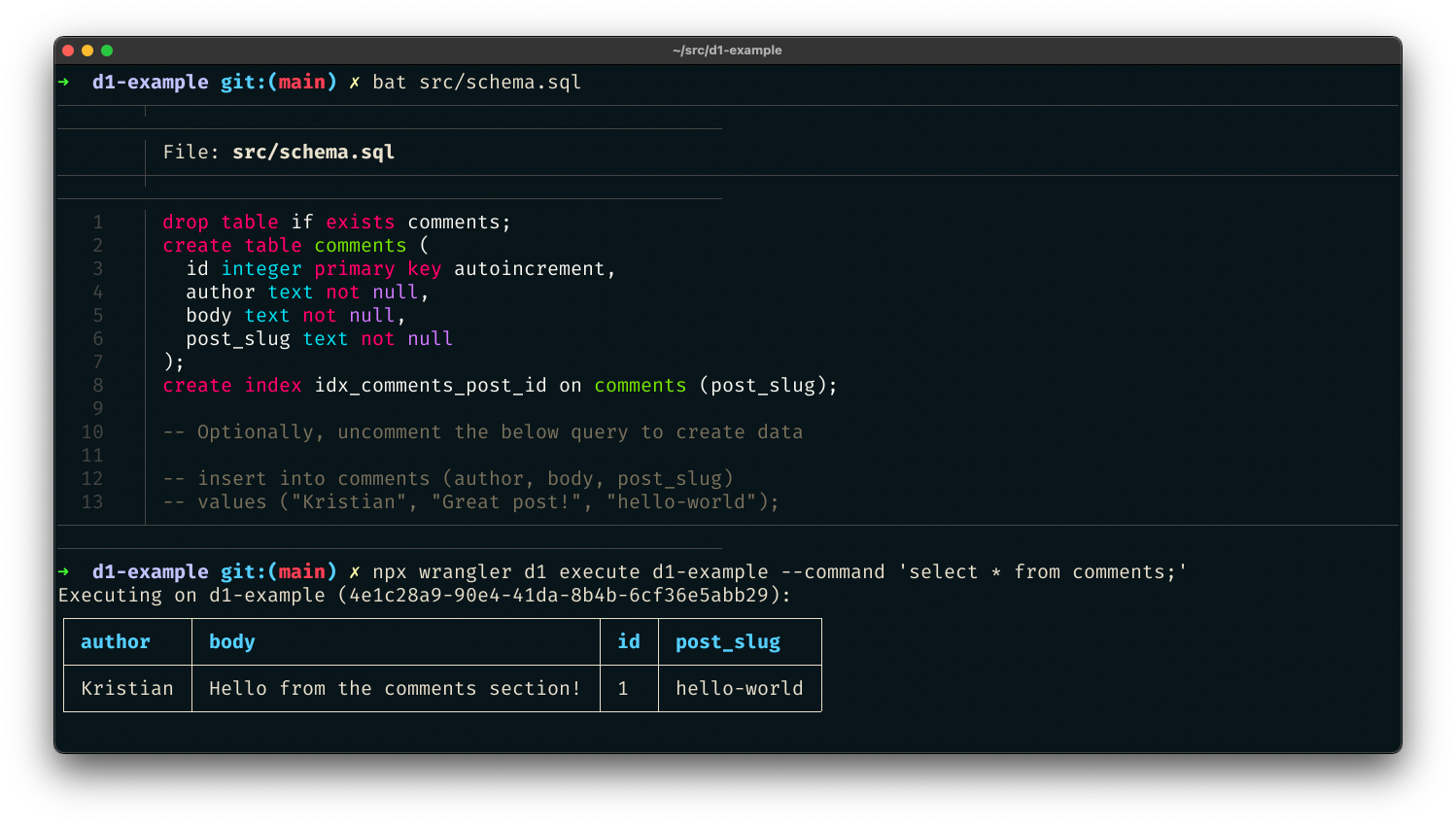
また、SQLファイルを渡すこともでき、1つのコマンドで最初のデータシードを作成するのに最適です。src/schema.sqlを作成すると、プロジェクト用に新しいcommentsテーブルが作成されます。
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
作成したファイルにフラグ--fileを付けて渡し、D1データベースに対してスキーマファイルを実行します。
$ wrangler d1 execute d1-example --file src/schema.sql
いくつかのコマンドを実行するだけで、SQLデータベースを作成し、初期データをシードできました。次に、Workers関数にルートを追加して、そのデータベースからデータを取得できます。wrangler.tomlの設定に基づき、D1データベースはDBのバインディングでアクセスできるようになっています。このコードでは、バインディングを使ってSQLステートメントを用意して実行することで、コメントの取得などを行実行できます。
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
この関数では、slug URLクエリーパラメータを受け取り、新しいSQLステートメントを設定して、クエリーパラメータにpost_slugの値が一致するコメントをすべて選択します。そして、それをシンプルなJSON応答として返します。
これまでは、データへの読み取り専用のアクセスを構築してきました。しかし、もちろん値をSQLに「挿入」することも可能です。そこで、エンドポイントにPOSTして新しいコメントを作成する別の関数を定義してみましょう。
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
この例では、ブログのためのコメントAPIを構築しています。このD1のコメントAPIのソースについては、cloudflare/templates/worker-d1-apiをご覧ください。
まとめ
D1で最もエキサイティングなことの1つは、既存のアプリケーションやWebサイトをダイナミックなリレーショナルデータで強化できることです。Ruby on Railsの元開発者として、JavaScriptやサーバーレス開発ツールの世界において、このフレームワークが最も恋しくなるのは、データベースインフラストラクチャの管理の専門家でなくても、データ駆動型アプリケーションを迅速にフル回転させることができる点です。D1とSQLベースのデータへの容易なアクセスにより、パフォーマンスや開発者の体験を犠牲にすることなく、真のデータ駆動型アプリケーションを構築できます。
この変化は、ここ数年のHugoやGatsbyといったツールを使った静的サイトの出現にうまく対応しています。Hugoのような静的サイトジェネレータで構築されたブログは非常にパフォーマンスが高く、アセットサイズを小さくしつつ、ほんの数秒で構築できます。
しかし、WordPressのようなツールを静的サイトジェネレータと組み合わせると、サイトに動的な情報を追加する機会を失ってしまうのです。多くの開発者は、この問題に対して、データをフェッチして取得し、そのデータをビルドの一部としてページを生成するという複雑なビルドプロセスで対応してきました。
このように複雑なビルドプロセスを経ることで、アプリケーションのダイナミズムの欠如を解決しようとしていますが、それでも純粋に動的とは言えません。新しいデータが作成されるたびに取得して表示するのではなく、データが変更されるたびにアプリケーションを再構築して再デプロイするため、ライブで動的にデータが表示されるようになります。アプリケーションは静的なままで、動的なデータがサイトのユーザーに地理的に近い場所に存在し、クエリーと表現が可能なAPIを介してアクセスできます。