
Cloudflareのダッシュボード は、現在新しく4言語(と複数のロケール)でご利用いただけます:スペイン語(国を特定するロケール:チリ、エクアドル、メキシコ、ペルー、スペイン)、ブラジルポルトガル語、中国語(繁体字)。当社のお客様はグローバルで多様性に富んでいます。誰にとってもより良いインターネットの構築に貢献する上で、どの言語でもお客様に製品とサービスをお届けするのは不可欠です。
昨年からCloudflareはダッシュボードを国際化しようと取り組んできました。2019年末、米国英語以外の言語を使った初めてのダッシュボードをドイツ語から開始しました。そして、2020年3月にはフランス語、日本語、中国語(簡体字)の3言語をリリースしました。いずれかの言語でダッシュボードの使用を始めたい場合は、Cloudflare ダッシュボードの右上部にある使用言語を変更するだけです。選んだ言語は、全セッションを通じて保存、使用されます。
このブログ記事を読んで、国際化とローカライゼーションに慣れていない方々にもその機能をご理解いただきたいと思います。当社がどのようにアプリケーションの国際化とローカライゼーションを標準かつ再現可能なプロセスにしたかという話をご紹介すると同時に、同じ作業をする場合に役立つヒントを少し共有したいと思います。
旅の始まり
国際化の最初のステップは、自分のアプリケーションの文字列を外部化することです。具体的には、ユーザーが読むことができるテキストをすべて取り出し、別のスタンドアロンファイルにアプリケーションコードを抽出するということです。これを行う理由がいくつかあります。
- これを行うと、翻訳チームがアプリケーションコードを表示したり変更することなく、文字列の翻訳に取り組むことができます。
- ほとんどの翻訳者がワークフロー面を自動化し、役に立つユーティリティ(翻訳メモリ、変更のトラッキング、複数の便利な解析ツールや書式設定ツール)を提供する翻訳管理アプリケーションを使います。このようなアプリケーションは(json、xml、md、csvファイルなど)標準化されたテキスト形式が必要です。
エンジニアの観点からは、翻訳からアプリケーションコードを分離することで、コードの再コンパイルしたり再デプロイしたりしなくても文字列の変更ができます。当社のReactベースのアプリケーションでは、文字列のほとんどを外部化して、次のようなコードブロックの変更にまとめました。
<Button>Cancel</Button>
<Button>Next</Button>
これを次のようにします。
<Button><Trans id="signup.cancel" /></Button>
<Button><Trans id="signup.next" /></Button>
// And in a separate catalog.json file for en_US:
{
"signup.cancel": "Cancel",
"signup.next": "Next",
// ...many more keys
}
上記の<Trans>コンポーネントは、当社アプリケーションで基本的なi18nビルディングブロックです。このスキームで、翻訳された文字列は翻訳IDによってキー設定された大きな辞書に保存されます。これを「翻訳カタログ」と呼び、当社がサポートする各言語の翻訳カタログのセットに入れます。
実行時、この<Trans>コンポーネントは提示されるキーの正しいカタログで翻訳を検索し、ページ(DOM経由で)この翻訳を挿入します。アプリケーションの静的テキストは全てこのように簡単な変換で外部化できます。
ただし、動的データを静的テキストと混在させる必要がある場合は、ソリューションが多少複雑になります。i18nの地雷でいっぱいの一見簡単な例を考えていきましょう。
<span>You've selected { totalSelected } Page Rules.</span>
次のように、この文をいくつかに切り刻んで外部化したくなるかもしれません。
<span>
<Trans id="selected.prefix" /> {totalSelected } <Trans id="pageRules" />
</span>
// English catalog.json
{
"selected.prefix": "You've selected",
"pageRules": "Page Rules",
// ...
}
// Japanese catalog.json
{
"selected.prefix": "選択しました",
"pageRules": "ページ ルール",
// ...
}
// German catalog.json
{
"selected.prefix": "Sie haben ausgewählt",
"pageRules": "Page Rules",
// ...
}
// Portuguese (Brazil) catalog.json
{
"selected.prefix": "Você selecionou",
"pageRules": "Page Rules",
// ...
}
これで作業は完了し、エレガントなソリューションに見えるかもしれません。結局のところ、selected.prefixとpageRules.suffix文字列はリユースするようになっているようです。しかし、このように文を切り刻んでから翻訳されたビットを連結させると、国際化のための文字列の外部化する際に一つの大きな落とし穴となってしまいます。
この問題は、翻訳されると文を構成する様々な語がコンテクスト(単数形コンテクスト vs 複数形コンテクスト、女性形と男性形に起因、主語/述語の一致など)に基づいて、さまざまな方法でモーフィングされることです。これは、語順のように言語間で大きく異なります。英語を例にすると、We like themという文は、主語-動詞-目的語の順ですが、他の言語の語順に従うと、主語-目的語-述語(We them like)だったり、述語-主語-目的語(Like we them)だったり、他の語順に従うこともあります。言語間にはこうした微妙な違いがあるため、翻訳された句を連結させて1つの文にするのは、ほとんどの場合、ローカライゼーションエラーとなるのです。
上記のコード例は、「選択しました」と「ページルール」を別の文字列として提供した際に、当社の翻訳チームから戻された実際の翻訳です。この文は、さまざまな言語でレンダリングされたときにどのように見えるかの一例です。
| 言語 | 翻訳 |
|---|---|
| 日本語 | 選択しました { totalSelected } ページ ルール。 |
| ドイツ語 | Sie haben ausgewählt { totalSelected } Page Rules |
| ポルトガル語(ブラジル) | Você selecionou { totalSelected } Page Rules. |
比較するために、変数のプレースホルダーを使って、単一の文字列として文を示しました。そして結果がこちらです。
| 言語 | 翻訳 |
|---|---|
| 日本語 | %{ totalSelected } 件のページルールを選択しました。 |
| ドイツ語 | Sie haben %{ totalSelected } Page Rules ausgewählt. |
| ポルトガル語(ブラジル) | Você selecionou { totalSelected } Page Rules. |
ご覧の通り、日本語とドイツ語の翻訳は同じではありません。ローカライザーションにはバグがありました。
翻訳者が忠実にテキストの意味を正しく伝えることができるように、各文を単一の外部化された文字列としてそのままにしておくことが重要です。当社の<Trans>コンポーネントによって、テンプレート文字列に値を簡単に注入することができるため、そっくりこちらのようになります。
<span>
<Trans id="pageRules.selectedForDeletion" values={{ count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ count } Page Rules.",
// ...
}
// Japanese catalog.json
{
"pageRules.selected": "%{ count } 件のページ ルールを選択しました。",
// ...
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ count } Page Rules ausgewählt.",
// ...
}
// Portuguese(Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ count } Page Rules.",
// ...
}
これによって、翻訳者は文の完全なコンテクストで作業することができるようになり、すべての語が正しい語形変化で翻訳されます。
別の潜在的な問題にお気づきになりましたか。この例で、totalSelectedが1だけの場合、どうなるのでしょうか。上記のコードの場合、ユーザーは「削除のために1 Page Rulesを選択しました」というメッセージが表示されます。動的データの値に基づいて、条件付きで文を複数形にする必要があります。これはかなり一般的なユースケースとなり、当社の<Trans>コンポーネントがsmart_count機能を経由して自動的に処理します。
<span>
<Trans id="pageRules.selectedForDeletion" values={{ smart_count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ smart_count } Page Rule. |||| You've selected %{ smart_count } Page Rules.",
}
// Japanese catalog.json
{
"pageRules.selected": "%{ smart_count } 件のページ ルールを選択しました。 |||| %{ smart_count } 件のページ ルールを選択しました。",
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ smart_count } Page Rule ausgewählt. |||| Sie haben %{ smart_count } Page Rules ausgewählt.",
}
// Portuguese (Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ smart_count } Page Rule. |||| Você selecionou %{ smart_count } Page Rules.",
}
ここでは、単数形バージョンと複数形バージョンは||||で区切られます。<Trans>はtotalSelected値渡し変数に応じて、正しい翻訳を自動的に選択します。
単一の文字列として外部化したいテキストのブロックとしてマークアップが混ざると、別の障害として発生します。たとえば、文中にあるいくつかの句に他のページへのリンクが必要な場合はどうなりますか。
<VerificationReminder>
Don't forget to <Link>verify your email address.</Link>
</VerificationReminder>
このユースケースを解決するために、<Trans>コンポーネントは、任意のエレメントを次のような翻訳文字列でプレースホルダーに注入できます。
<VerificationReminder>
<Trans id="notification.email_verification" Components={[Link]} componentProps={[{ to: '/profile' }]} />
</VerificationReminder>
// catalog.json
{
"notification.email_verification": "Don't forget to <0>verify your email address.</0>",
// ...
}
この例では、<Trans>コンポーネントはプレースホルダーエレメント(<0>、<1>など)をComponents配列のインデックスに位置するコンポーネントタイプのインスタンスに置き換えます。componentPropsで指定されたデータもそのインスタンスに転送します。上記の例は、Reactで次にまとめられます。
// en-US
<VerificationReminder>
Don't forget to <Link to="/profile">verify your email address.</Link>
</VerificationReminder>
// es-ES
<VerificationReminder>
No olvide <Link to="/profile">verificar la dirección de correo electrónico.</Link>
</VerificationReminder>
安全第一ではなく第三
上で説明した機能性は、文字列を外部化するのに十分です。しかし、時には、大量で繰り返しの多いコードになってしまうこともありました。2つの落とし穴があることがすぐに分かりました。
1つ目は、小さくハンドコードされた文字列は隠れるのがさらに簡単になり、ページの残りが翻訳されるまで開発者には明らかでなかったため、それらを見つけるためのフィードバックループが数日または数週間かかることもありました。これらの問題を表面化する場合の一般的な解決策は、開発中に擬似ローカライゼーションモードをご利用のアプリケーションに導入する方法です。擬似ローカライゼーションは、各文字を類似するUnicode文字に置き換えることで、全て適切に国際化された文字列を変換します。
たとえば、3 Page Rulesを選択しました。はÝôú'Ʋè ƨèℓèçƭèδ 3 Þáϱè Rúℓèƨに変換されるかもしれません。
もう一つ便利な機能は、コンテンツ幅の違いを計画するために、一定の量だけ全ての文字列を短くしたり長くしたりでき、擬似ローカライゼーションモードで自由に使えます。ここでは同じ擬似ローカライズされた文「Ýôú'Ʋè ƨèℓèçƭèδ 3 Þáϱè Rúℓèƨ. ℓôřè₥ ïƥƨú₥ δô」を50%長くします。これは、エンジニアとデザイナーがコンテンツの長さが問題になる可能性がある場所を特定するのに役立ちます。この問題に最初に気づいたのは、英語よりも単語が長い傾向があるドイツ語のサポートを開始しようとしたときでした。
つまり、こちらの「追加」ボタンのようにページエレメントでテキストがオーバーフロー(文字あふれ)する箇所が多いということを意味しました。
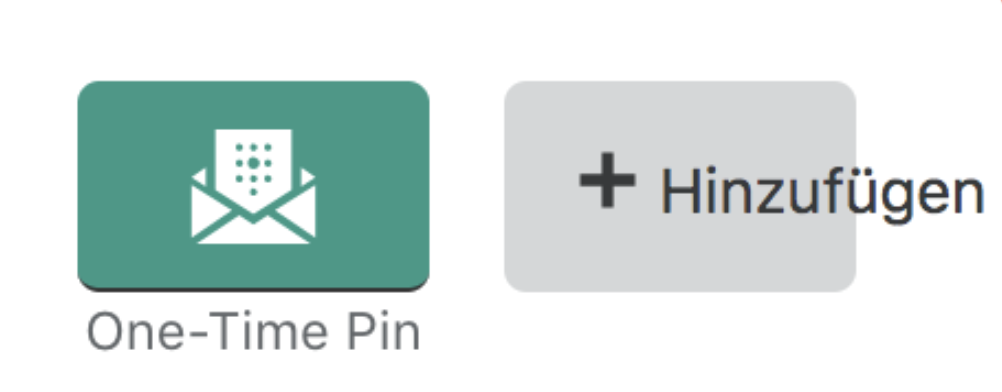
こういう種類の問題をユーザー体験を損なわずに、簡単に修正する方法は多くありません。
一番いい結果を得るには、可変コンテンツの幅はデザインそのものに含める必要があります。こうしたバグの修正は、新しい設計をリクエストするためにアップストリームに送り返すことを意味することがあるので、処理には時間がかかる傾向があります。コンテンツデザイン全般をそれほど考えていないなら、その時が国際化の取り組みを開始するのにいい時期かもしれません。ご自分のアプリで様々なエレメントに使用されるコピーでの標準と一貫性を持つことで、翻訳が必要な語数を減らすことができるだけでなく、新しい語句を使う際のコンテンツの長さに落とし穴がないか考え込む必要がなくなります。
我々が遭遇した落とし穴が、もう1つあります。特に、長くて繰り返しが多い翻訳IDが、タイプミスの影響を非常に受けやすいということです。
簡単なクイズを出しましょう。どちらの翻訳キーがアプリを壊すでしょうか。traffic.load_balancing.analytics.filters.origin_health_titleですか。それともtraffic.load_balancing.analytics.filters.origin_heath_titleでしょうか。
これは何百もの変更行の中にあって、コードレビューでは見つけるのが難しいです。ほとんどのアプリにはフォールバック機能があるので、翻訳が抜けていてもページの区切りエラーにはなりません。結果として、こうしたバグは非常に上手く隠れていると(ヘルプテキストのフライアウトなど)、完全に気付くことがないかもしれません。
ラッキーなことに、TypeScriptのコードベースの割合が増加し、コードを書くときに開発者にフィードバックを出すタイプチェッカーを活用することができました。こちらは、当社のコードエディターがIDプロパティが無効になっている(アルファベットの「l」が抜けているため)ことを示すために赤い下線を示している例です。

問題が明らかになっただけでなく、違反によってビルドが失敗し、コードベースに不正コードが入力されるのを防ぐことも示しました。
ロケールファイルの拡張
おそらくサポートするロケールごとに1つの翻訳ファイルから始めることが多いでしょう。さらに、キーに使用する命名規制がややシンプルなままかもしれません。アプリが大きくなると、翻訳ファイルも大きくなりすぎて別のファイルに分ける必要が出てきます。ファイルが大きすぎると、Translation Management(翻訳管理)アプリケーションが圧倒され、チェックを外せば、コードエディターに負担がかかることになります。すべての翻訳文字列(キーを含まない)は、1つのファイルにまとめた場合、約50,000語です。ちなみに、これは『The Hitchhiker's Guide to the Galaxy(銀河ヒッチハイク·ガイド)』や『Slaughterhouse Five(スローターハウス5)』とほぼ同じサイズです。
翻訳は(ファイアウォールやCloudflare Workersのように)特化機能にほぼ対応する、多数の「カタログ」ファイルに分割されます。文字列を見つける場所が予測可能で、翻訳カタログの行数を管理できる長さに維持することができるため、開発者にとっては都合がいいです。そして、翻訳者1人(または小さなチーム)にとって特化機能は適切な作業単位でもあるため、外部の翻訳チームにとっても都合が良いものです。
機能ごとのカタログに加えて、当社はアプリケーション全体でリユースする文字列を維持する共通のカタログファイルがあります。これのおかげで、IDを短くすることができ(common.deletevssome_page.some_tab.some_feature.thing.delete)、新しい文字列を追加する前に開発者は共通カタログを確認する習慣があるため、重複する可能性も低くできます。
ライブラリ
これまでのところ、当社の<Trans>コンポーネントとそれで何ができるかについて話してきましたが、ここでどのように構築されているのかという話に移りましょう。
驚くことではないと思いますが、当社はわざわざ一からやり直そうとしたのではなく、基本のi18nライブラリを最初から提案したかったわけでもありません。Backboneで書かれたアプリケーションのレガシー部分を国際化しようと以前から続けていた努力のため、当社はすでにAirbnbのPolyglot library、「tiny I18n helper library written in JavaScript(JavaScriptで記述された小さなI18nヘルパーライブラリ)」を使ってきました。これは、とりわけ「Backbone.jsとNode アプリにI18n機能を追加するAirbnbの経験に基づいて補間と複数形化のための簡単なソリューションを提供します」。
Reactアプリケーションの国際化を目的に設計された最も人気のあるライブラリをいくつか調べましたが、最終的にPolyglotに決めました。Reactとのギャップを埋めるために<Trans>コンポーネントを作成しました。この方向性には、いくつか理由があります。
- 新しいi18nサポートライブラリに移行するため、当社のアプリケーションでレガシーコードを再度国際化したくありませんでした。
- 新規vsレガシーコードの2つの異なるi18nスキームをサポートするオーバーヘッドの組み合わせが必要ではありませんでした。
- Transコンポーネントを書くことで、必要なインターフェースが書けるという柔軟性が得られました。Transは、どこででも使われているので、開発者にとってできる限りエルゴノミック(使いやすい)であるようにしたかったのです。
新規のReactベースウェブアプリでi18nを使い始めている場合、react-intlとi18n-nextの2つは人気ライブラリで、すでに述べたように<Trans>と類似したコンポーネントを提供します。
大まかに説明したように、<Trans>コンポーネントの最大の問題点は、文字列をソースコードとは別のファイルに入れなければならないことです。新規コードを作成したり、既存の機能を修正したりする際に複数のファイルを切り替えるのは面倒です。もし翻訳ファイルがディレクトリ構造から遠く離れたところにある場合、ディレクトリ内に存在する必要がある場合も多く、さらに面倒です。
新規のi18nライブラリにはjslinguiといったものもあり、翻訳カタログを取り扱うための抽出ベースのアプローチをとることで、この問題を回避します。このスキームで、<Trans>コンポーネントをまだ使いますが、別のカタログではなく、コンポーネント自体に文字列を保持します。
<span>
<Trans>Hmm... We couldn't find any matching websites.</Trans>
</span>
ビルド時に実行するツールは、こうした文字列をすべて見つけ、カタログに抽出する作業を行います。たとえば、上記の結果では、次のようなカタログが生成されます。
// locales/en_US.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... We couldn't find any matching websites.",
}
// locales/de_DE.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... Wir konnten keine übereinstimmenden Websites finden."
}
このアプローチの明らかな利点は、別々のファイルがないことです!他の利点は、タイプミスはもう起こらないので、タイプチェックの必要性がなくなることです。
ただし、当社のユースケースでは、いくつかの欠点がありました。
最初に、人間の翻訳者は翻訳キーのコンテキストを理解します。組織にとって役に立ち、文字列の目的が手がかりとなります。
翻訳IDではタイプミスの心配がなくなったとは言うものの、わずかなコピーの違いに影響を受けます(例:「eメールを確認します」vs「e-メールを確認します」)。この場合は検出するのが非常に難しく、ほぼ重複されるため、検出がさらに困難になります。これには対価が生じます。
作業しているテックスタックがどちらであっても、助けてくれるi18nライブラリはいくつかあります。どちらを選択するかは、ご利用のアプリケーションの技術的制約やチームの目標や文化の状況によっても大きく変わってきます。
数値、日付、時間
以前、データ翻訳された文字列の注入について話した時には触れなかった大きな問題があります。注入するデータもユーザーの現地の慣習に準拠するようにフォーマットする必要があるかもしれないということです。日付、時間、数値、通貨、その他の種類のデータに当てはまることです。
前回の内容からシンプルな例を見てみましょう。
<span>You've selected { totalSelected } Page Rules.</span>
適切に書式が設定されていなければ、小さな数値が正しく表示されても、何千という数になるとすぐにローカライゼーションの問題が発生します。桁をグループに分けて、シンボルで区切る方法は文化によって異なります。ここで30万と300分の1が異なるロケールでどのようなフォーマットになるか示されています。
| 言語(国名) | コード | フォーマットされた日付 |
|---|---|---|
| ドイツ語(ドイツ) | de-DE | 300.000,03 |
| 英語(米国) | en-US | 300,000.03 |
| 英語(英国) | en-GB | 300,000.03 |
| スペイン語(スペイン) | es-ES | 300.000,03 |
| スペイン語(チリ) | es-CL | 300.000,03 |
| フランス語(フランス) | fr-FR | 300 000,03 |
| ヒンズー語(インド) | hi-IN | 3,00,000.03 |
| インドネシア語(インドネシア) | in-ID | 300.000,03 |
| 日本語(日本) | ja-JP | 300,000.03 |
| 韓国語(韓国) | ko-KR | 300,000.03 |
| ポルトガル語(ブラジル) | pt-BR | 300.000,03 |
| ポルトガル語(ポルトガル) | pt-PT | 300 000,03 |
| ロシア語(ロシア) | ru-RU | 300 000,03 |
日付をフォーマットする方法は国ごとに大きく異なります。米国のオーディエンスを念頭に置いてUIを開発した場合、他の国にいるユーザーにとって使い慣れていない日付の表示方法を使うことになります。とりわけ、日付のフォーマットはセパレーターの選択、一桁の場合にゼロが追加されている、日付は日/月/年という順番かという点において異なります。今年の3月4日が異なるロケールでどのようにフォーマットされるか紹介します。
| 言語(国名) | コード | フォーマットされた日付 |
|---|---|---|
| ドイツ語(ドイツ) | de-DE | 4.3.2020 |
| 英語(米国) | en-US | 3/4/2020 |
| 英語(英国) | en-GB | 04/03/2020 |
| スペイン語(スペイン) | es-ES | 4/3/2020 |
| スペイン語(チリ) | es-CL | 04-03-2020 |
| フランス語(フランス) | fr-FR | 04/03/2020 |
| ヒンズー語(インド) | hi-IN | 4/3/2020 |
| インドネシア語(インドネシア) | in-ID | 4/3/2020 |
| 日本語(日本) | ja-JP | 2020/3/4 |
| 韓国語(韓国) | ko-KR | 2020.3.4 |
| ポルトガル語(ブラジル) | pt-BR | 04/03/2020 |
| ポルトガル語(ポルトガル) | pt-PT | 04/03/2020 |
| ロシア語(ロシア) | ru-RU | 04.03.2020 |
時間のフォーマットも大きく異なります。こちらは時間のフォーマットの違いをいくつかのロケールで示しました。
| 言語(国名) | コード | フォーマットされた日付 |
|---|---|---|
| ドイツ語(ドイツ) | de-DE | 14:02:37 |
| 英語(米国) | en-US | 2:02:37 PM |
| 英語(英国) | en-GB | 14:02:37 |
| スペイン語(スペイン) | es-ES | 14:02:37 |
| スペイン語(チリ) | es-CL | 14:02:37 |
| フランス語(フランス) | fr-FR | 14:02:37 |
| ヒンズー語(インド) | hi-IN | 2:02:37 pm |
| インドネシア語(インドネシア) | in-ID | 14.02.37 |
| 日本語(日本) | ja-JP | 14:02:37 |
| 韓国語(韓国) | ko-KR | 오후 2:02:37 |
| ポルトガル語(ブラジル) | pt-BR | 14:02:37 |
| ポルトガル語(ポルトガル) | pt-PT | 14:02:37 |
| ロシア語(ロシア) | ru-RU | 14:02:37 |
数値、日付、時間を処理するライブラリ
サポートするロケール全てで、こうしたデータを正確なフォーマットにすることは簡単な作業ではありません。幸いにも、役に立つライブラリが数多くあります。このライブラリは、成熟しており、実地経験も豊富です。
プロジェクトを開始した時、当社はmoment.jsライブラリをデータおよび時間のフォーマットに広く使用していました。この便利なライブラリは、長さが異なる日付のフォーマット(「20年7月9日」、「2020年7月9日」、vs 「木曜日」)を無視して、多数ある中から相対的な日(「2日前」)を表示します。ほぼすべての日付は、可読性を考慮してMoment.js経由ですでにフォーマットされており、Moment.jsは大多数のロケールでi18nがあります。つまり、スイッチを二つ切ることができ、影響をほとんど与えずに、適切に日付をローカライズできたということです。
Mement.jsに関しては強い(大抵は誇張した)批判がありますが、すべての日付と時間をやり直す場合にかかるコストと比較すると、最終的にフットプリントが少ない代替品に切り替える方がメリットが得られます。
数値に関しては、話が違ってきます。すでにご想像されたかもしれませんが、ダッシュボード全体には何千もの未加工でフォーマットされていない数値がありました。そのすべてを追跡するのは骨が折れますし、手動による作業になることもありました。
実際の数値をフォーマット化するために、当社はIntl API(the Internationalization library defined by the ECMAScript standard:ECMAScript標準で定義された国際化ライブラリ)を使用しました。
var number = 300000.03;
var formatted = number.toLocaleString('hi-IN'); // 3,00,000.03
// This probably works in the browser you're using right now!
ラッキーにも、Intlのブラウザサポートは、完全サポート付きの最新ブラウザになり、大きな発展を遂げています。
V8のような最新のJavaScriptエンジンの中には、C++ベースの組み込み関数を選び、こうしたライブラリのセルフホストJavaScriptを実装しなくなるものもあり、その結果として大幅なスピードアップにつながりました。
古いブラウザのサポートは、やや欠けているものがありますが、ここでCloudflare Workershttps://intl-formatting.jculvey.workers.dev/で構築されたシンプルなデモサイト(ソースコード)を使って、いくつかのロケールで日付、時間、数値がどのようにレンダリングされているかをご紹介しましょう。
古いブラウザとOSの組み合わせによっては、理想的とは言えない結果になるでしょう。こちらは、上記と同じ日付と時間がIE10を使うWindows 8でレンダリングされている例です。
 |
 |
古いブラウザをサポートする必要がある場合は、Polyfillで解決できます。
翻訳する
すべての文字列が外部化され、ロケール特有の基準で慎重にフォーマット化されたデータがすべて挿入されると、エンジニアの作業はだいたい終了です。この時点で、当社は簡単にローカライズする方法を採用したために、アプリケーションを国際化できたということが言えると思います。
次に、ユーザーの言語と文化的な規範に基づいて、さまざまなコンテンツを実際に作成するローカライゼーションの手順に移りましょう。
これは、小さな仕事ではありません。前述のとおり、アプリケーション内の文字列は一緒に追加され、小さな小説レベルのサイズです。これには、忠実に情報を捉え、ユーザーにとって慣れ親しんだ方法で伝えられる翻訳コピーが作成できる人の専門知識とかなりの調整が必要となります。
翻訳作業の処理にはさまざまな方法があります。他言語スタッフを活用したり、個人翻訳者や翻訳会社、またはその両方と契約したり、社内翻訳者チームを雇用することもあります。いかなる場合でも、翻訳チームと開発チームの間でワークフローの送信とアセットを移動するための円滑な処理が必要となります。
健全なi18nプログラムでは、その過程で、開発者にブラックボックスインターフェイスを提供します。開発者は新しい文字列を翻訳カタログファイルに入れて変更します。それ以上の作業は必要なく、開発者が書いた機能コードは数日後にサポートするすべてのロケールにおける作業で利用可能となります。同様に、安定したプロセスのおかげで、翻訳者は開発プロセスとアプリケーションアーキテクチャの詳細を気にさえしないままでいられます。翻訳者が受け取るのは、自分のツールに簡単に読み込め、どのような翻訳が必要なのかを明確に示すファイルです。
これが実際にどう機能するのでしょうか。
ローカライゼーションチームがオンデマンドで実行できるようにした自動のスクリプトセットがあり、すべてのサポート言語でローカライゼーションカタログのスナップショットをパッケージ化することができます。この処理では、いくつかの事が起こります。
- JSONファイルが、TypeScriptで作成されたカタログファイルから生成される
- 英語で新しいカタログが追加された場合はいつでも、プレースホルダーコピーが他のサポート言語でも作成される
- 新しい文字列が当社のベースカタログに追加されると、全言語のプレースホルダー文字列が追加される
そこからUIを経由する、またはAPIへの自動呼び出しを介して翻訳管理システムへと翻訳カタログがアップロードされます。ファイルは、翻訳者に手渡される前に、事前処理として新しい各文字列と翻訳メモリ(以前に翻訳された文字列と部分文字列のキャッシュ)が比較されます。一致する翻訳があれば、既存のものが使われます。これは文字列を翻訳し直す手間を省くことでコストカットできるだけでなく、すでにレビューして承認されている翻訳ができる限り使われるようにして、品質を向上させます。
ロケールファイルは最後、以下のようになるとしましょう。
{
"verify.button": "Verify Email",
"other.verify.button": "Verify Email",
"verify.proceed.link": "Verify Email to proceed",
// ...
}
ここに逐語的に複製された文字列とコピーされた部分文字列があります。翻訳サービスは単語数で請求されます。二回分の料金を払って、一貫性に関する問題が発生するリスクを負いたくはないものです。このため、翻訳メモリがきちんと機能するようにして、翻訳者がファイルを見る前にこうした文字列の事前翻訳のステップが確実に行われるようにしておきます。
翻訳作業の準備が完了したとマークされると、翻訳チームは作業の大きさ、翻訳者のスケジュール、契約条件など様々な要因によって、翻訳済みコピーの提出まで数時間ほどから数週間かけます。この部分における懸念は、適切な翻訳チームの調達、コスト管理、品質と一貫性の確保、そして企業ブランドが適切に伝えられているかというものです。これについては、同じ長さの別のブログを書くことができるほどです。この記事は主にテクニカルな面を取り上げているので、詳細には触れませんが、間違いなく、この部分で間違いを犯すと、たとえ技術的な目標を達成できたとしても、全体の努力を無駄にしてしまうことになります。
翻訳チームが新しいファイルの受け取り準備ができたことを通知した後、アセットはサーバーからプルされ、アプリケーションコードで正しいロケーションにアンパックされます。一連の自動チェックを事項し、すべてのファイルが有効で、書式設定問題がないことを確認します。
オプションの(ですが、強く推奨される)ステップはこの段階で行われます。それが文脈内レビューです。翻訳レビュー担当者のチームが文脈の中で翻訳された文章を確認し、仕上げ段階で翻訳を完璧にします。この作業では、製品に精通し、翻訳先の言語が堪能なサポートスタッフがいることが有益です。この作業に時間と労力を費やした会社のチームメンバー全員に感謝の意を表しましょう。外部の業務委託者にも同じことができるように、当社は開発モードをロケールでも有効にしてテストが受けられるプレビュー版のアプリを準備しました。
さあ、これで世界中のユーザーにローカライズされたバージョンのアプリケーションを配信するためのすべてが揃いました。
継続的なローカライゼーション
ここで話を止めてもいいのですが、これまで話し合ってきたのは、一度に終わらせるために必要となる作業です。ご存知の通り、コードは代わります。新機能が始まり、マイナーチェンジが加えられる間に、新しい文字列は徐々に追加され、修正され、削除されます。
翻訳とは、世界中あらゆるところにいる人の作業がともなうことが多いため、ターンオーバーが可能な時間枠には限りがあります。当社のリリース頻度(毎日)はこのターンオーバー率(2~5日)よりも早い場合があります。そのため、機能に変更を加える開発者はそれに合わせてこの頻度に合わせてスローダウンするか、完全に適用させないでローカライゼーションスケジュールよりもわずかに先にリリースするか、選択しなければなりません。
翻訳の前にリリースする機能がアプリケーションの破損エラーを出さないようにするために、文字列が設定言語に存在しない場合、当社のベースロケール(en_US)にフォールバックします。
アプリケーションによっては、フォールバック動作がわずかに異なります。それは未加工の翻訳キー表示です(お使いのアプリでsome.funny.dot.delimited.strinを見たことがあるかもしれません)。ここには速度と正確性にトレードオフがあり、速度と最小限のオーバーヘッドを最適化することを選択しました。アプリの中には、正確性が i18nの頻度を落とす十分な理由になるものもあります。この場合は、そうではありませんでした。
最後の仕上げをする
新しくローカライズされたアプリケーションには、ユーザー体験を最適化するためにできることがいくつかあります。
まず、パフォーマンスの低下がないことを確認します。当社のアプリケーションに、ユーザーがページをレンダリングする前に翻訳済み文字列のすべてを取得させると、これが確実にできます。したがって、アプリケーションがページのコンテンツをレンダリングする必要がある場合に限り、翻訳カタログを非同期で取得すると、すべてが円滑に実行できます。ParcelやWebpackのような動的インポートステートメントをサポートするモジュールバンドラーで利用できるコード分割機能で簡単にできるようになっています。
また、ユーザーがいろいろなCloudflareのプロパティにアクセスする際にいつも使用言語を選択しなければならないという問題を取り除きたいと考えました。それを実現させるために、ユーザーがマーケティングサイトまたはサポートサイトでユーザーが選ぶ言語設定がダッシュボードを使うときに持続するようにしました(例示したすべてのリンクはフランス語です)。
次は何を?
ここまで様々なことを経験し、たくさんのことを学びました。i18nプロジェクトをすべて完了することは難しい(おそらく不可能)です。新しい言語での展開によって、隠れていたエラーが表面化し、新しい課題が明らかになるでしょう。コスト削減と効率性アップをして、予算面でのプレッシャーにも立ち向かわなければなりません。さらに、ユーザーのためにローカライズされた体験を向上する方法を見つけることも必要になります。
要改善のリストは長いですが、注目すべき点がいくつかあります。
- コレーション(照合順序)。文字列の比較は、言語によって大きく変わります。アプリでデータリストやデータ表を辞書学的に分類するために書いたコードが、ユーザーによっては誤ったものになるでしょう。これはアルファベット(英語やスペイン語など)のような言語と対照的に、表語文字体系を用いる言語(中国や日本語など)で特に顕著です。
- アラビア語やヘブライ語のように右から左に記述する言語をサポートします。
- API応答のローカライゼーションは、チーム間で取り組みを調整しなければならないため、ユーザーインターフェースで静的コピーをローカライズするよりも難しくなります。マイクロサービスの時代に、各サービスを回す無数のテックスタック全体で機能するソリューションを見つけることは、非常に困難なこともあります。
- マップをローカライズします。マップベースの視覚化ですべてのコンテンツが翻訳されていることを確認する作業を行います。
- 機械翻訳は近年、大きく発展してきましたが、人の監視なしで当社の翻訳を行うところまでには至っていません。しかし、翻訳レビュー担当者が正確さと論調を確認する前の最初の通過地点として、機械翻訳をさらに試していきたいと考えています。
Cloudflareがどのようにダッシュボードを国際化、ローカライズ化したのかに関する概要をお楽しみいだだけましたでしょうか。当社のキャリアページでは、全世界の正規雇用やインターンシップの機会に関する詳細を掲載しています。ぜひご覧ください。