


D1は現在オープンベータ中で、テーマは「スケール」です。データベースあたりのストレージ上限を引き上げるとともに、より多くのデータベースを作成できるようにすることで、開発者がD1で本番規模のアプリケーションを構築できるようにします。既存の有料Workersプランをお持ちの開発者の皆様は、この恩恵を受けるために指一本動かす必要はありません。既存のD1データベースにはすべてにこれを適用しました。
Developer Weekの際の最新のD1アップデート情報や、変更履歴にある多数のアップデート情報を見逃した方、D1全般が初めての方は、ぜひお読みください。
おさらい: D1とは?データベース?
昨年11月にアルファ版をリリースしたD1のネイティブサーバーレスデータベースは、Workers KV、Durable Objects、R2を補完するクエリ可能なデータベースです。
D1の構築に着手したとき、私たちは以下の必要性を認識していました。高速であること、驚くほど簡単にデータベースを作成できること、そしてSQLベースであることです。
最後の点はとても重要でした。(a) 開発者が別のカスタムクエリ言語を習得する必要がないため、また、(b) 既存のクエリビルディングやORM(オブジェクトリレーショナルマッパー)ライブラリ、その他のツールが最小限の労力でD1に接続できるようにするためです。これにより、Drizzle ORMやKyselyのD1サポートから、D1をデータベースとして使用するフルスタックツールキットであるT4アプリまで、たいへん多くのプロジェクトがD1をサポートするようになりました。
また、Workersからデータベースに問い合わせる唯一の方法がD1であるはずがありません。既存のデータベースや数千行ものSQL、既存のORMコードを持つチームにとって、D1への移行は一朝一夕の作業ではありません。そのようなチームのために、Hyperdriveを構築し、既存のデータベースに接続し、それらをグローバルに利用できるようにしました。グローバルに分散されたアプリのためにD1とWorkersを組み合わせ、レガシークラウドにあり、一晩では削除できないデータベースのクエリにはHyperdriveを使用する、といった柔軟性をチームに提供できると考えています。
より大きく、そしてより多くのデータベース
アルファ版を通じて何千人ものD1ユーザーから寄せられた最大の要望は、より多くのデータベースが必要なだけでなく、より大きなデータベースが必要だということでした。
Workers有料プランの開発者は、各データベースを最大2GBまで拡張し、50,000個のデータベースを作成できるようになります(500MBと10個から制限引き上げ)。はい、その通りです。1アカウントにつき50,000のデータベースです。これにより、従来のリレーショナル・データベースでは不可能であった、ユーザーごと、ユースケースごとの多くのデータベースを利用することが可能になり、顧客間の真の分離が実現します。
今後数週間から数ヶ月の間に、さらに大規模なデータベースの利用開放に取り組み続けます。D1ベータを使用している開発者は、D1の公開変更履歴でこれらの制限の自動的な増加を確認できます。
10GBを超えるデータベースの最大の障害の1つはパフォーマンスです。データベースは非常に速くロードされ、準備が整わなければなりません。数秒以上かかるコールドスタートは許されません。10GBや20GBのデータベースがクエリに答えるまでに15秒もかかるようでは、使うのにかなりイライラしてしまいます。
Workersの無料プランのユーザーは、10個の500MBデータベース(変更履歴)を永久に保持できます。より多くの開発者に、D1とWorkersに踏み切る前にテストする機会を持っていただくためです。
Time Travelはこちら
Time Travelを使用すると、データベースを特定の時点(具体的には、分単位で過去30日間の任意の時点)にロールバックすることができます。この機能はすべてのD1データベースでデフォルトで有効になっており、コストはかからず、ストレージの上限にもカウントされません。
記事をご覧になっている皆さんへ: Time Travelは今年の初めに発表され、7月にはすべてのD1ユーザーに提供されました。その核心は、驚くほどシンプルです。Time Travelは、D1に「ブックマーク」という概念を導入したものです。ブックマークとは、特定の時点におけるデータベースの状態を表すもので、事実上、追記のみのログです。Time Travelはタイムスタンプをブックマークに変換したり、直接ブックマークを取得したりできるので、その時点への復元が可能になります。さらに良いことに、復元してもそれ以上さかのぼることはできません。
Time Travelは例で説明するのが一番効果的だと思いますので、データベースを変更してみましょう。eコマースストアに対して行われたすべての注文を保存するOrderテーブルを持つデータベースです。
# 例として、当社の注文データベースには89,185件の個々の住所があります。
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 89185 │
└──────────┘
いいですね。では、住所変更や運送会社の変更など、特定の注文を変更したい場合はどうすればよいでしょうか?
# 何か忘れているような気がするのですが...
➜ wrangler d1 execute northwind --command "UPDATE [Order] SET ShipAddress = 'Av. Veracruz 38, Roma Nte., Cuauhtémoc, 06700 Ciudad de México, CDMX, Mexico'
これまで多くの人がしたのと同じ間違いをしてしまいました。UPDATEクエリのWHERE句を忘れていました。特定の注文IDを更新する代わりに、テーブル内のすべての注文のShipAddress(宛先住所)を更新してしまいました。
# すべての注文はメキシコシティのワインバーに送られます。
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 1 │
└──────────┘
パニック発生です。この変更を行う前にバックアップを取っていましたか。そうしたのはいつでしたか。ポイントインタイムリカバリーをオンにしていましたか。当時は高くつく可能性があるように思えたのですが。
大丈夫です。D1を使っています。Time Travelを使えます。デフォルトでオンになっています。修正するため、数分前に戻りましょう。
#過去の時点に戻りましょう。
➜ wrangler d1 time-travel restore northwind --timestamp="2023-09-23T14:20:00Z"
🚧 ブックマーク0000000b-00000002-00004ca7-9f3dba64bda132e1c1706a4b9d44c3c9からデータベースnorthwindをリストアします。
✔ 続行する場合はOK (y/N) ... yes
⚡️ Time Travel実行中...
✅ データベースdash-dbがブックマーク00000000-00000004-00004ca7-97a8857d35583887de16219c766c0785に復元されました。
↩️ この操作を元に戻すには、前のブックマーク00000013-ffffffff-00004ca7-90b029f26ab5bd88843c55c87b26f497に戻すことができます。
うまくいったかどうか確認してみましょう。
# ふぅ。もう大丈夫です。
➜ wrangler d1 execute northwind --command "SELECT count(distinct ShipAddress) FROM [Order]"
┌──────────┐
│ count(*) │
├──────────┤
│ 89185 │
└──────────┘
Time Travelは、小規模なデータベースが多数ある場合に、さらに効果を発揮すると考えられます。復元操作のデメリットがさらに軽減され、単一のユーザーまたはテナントに範囲が狭められます。
これはTime Travelの始まりにすぎません。データベースの復元だけでなく、既存のデータベースをフォークして上書きする機能もサポートするように取り組んでいます。単一のコマンドでデータベースをフォークしたり、移行やスキーマの変更を実際のデータに対してテストすることができれば、データベースを扱う際に今まで直面してきた従来からの課題の多くをリスク回避することができます。
行ベースの価格設定
5月にD1の価格を発表してから、無料と有料プランに含まれる使用量について多くの有益なフィードバックをいただきました。8月には、これまでのバイト単位に代わる新しい行ベースのモデルを発表し、より簡単に使用量を予測・定量化できるようになりました。行ベースに移行したのは、理屈が簡単なためであり、行を書き込む場合、それが1KBであろうと1MBであろうと関係ありません。読み取りクエリがインデックス付き列を使用してフィルタリングする場合、パフォーマンス上のメリットだけでなく、コスト削減も見込めます。
これはD1の価格設定ですが、ほとんどすべてが同じく、行数に応じて課金されるという利点もあります。
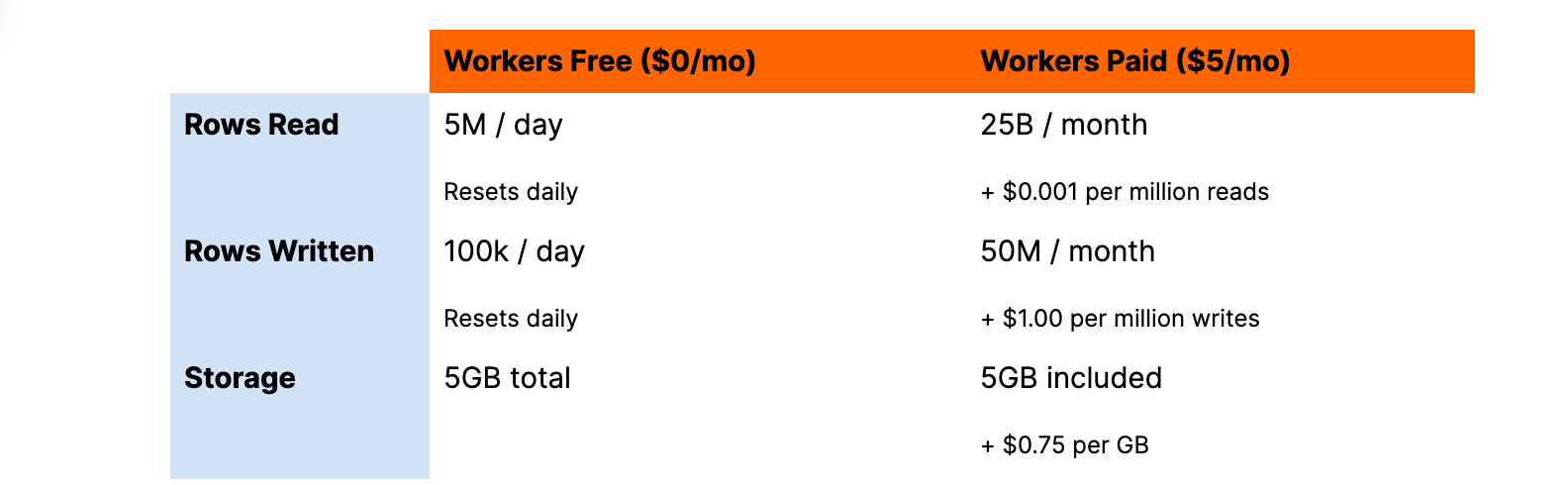
従来通り、D1では「データベース時間」、データベース数、ポイントインタイムリカバリー(Time Travel)に対して課金されることはありません。D1へのクエリ、読み取り、書き込み、ストレージの料金を支払うだけです。
これにより、D1のコスト効率が格段に向上するだけでなく、顧客データや本番用と開発用を分離するために複数のデータベースを管理することも容易になります。どのデータベースに対してクエリするかは問われません。好きなようにデータを管理し、顧客データを分離できます。たとえそれが直感的でなくても、あるいはあなたのチームにとって理にかなっていなくても、課金される方法だけを考えて構築する「課金ベースのアーキテクチャ」の罠にはまらないようにしましょう。
あるクエリにどれだけのコストがかかっているのか、またインデックスを使用してクエリを最適化するタイミングを簡単に確認できるように、D1はクエリが読み込んだ行数または書き込んだ行数(またはその両方)を返します。どれほどコストがかかっているかや、スピード面の影響がわかります。
例えば、以下のクエリは日付に基づいて注文をフィルタリングします。
SELECT * FROM [Order] WHERE ShippedDate > '2016-01-22'"
[
{
"results": [],
"success": true,
"meta": {
"duration": 5.032,
"size_after": 33067008,
"rows_read": 16818,
"rows_written": 0
}
}
]
上記のインデックスなしクエリは16,800行をスキャンします。最適化しないとしても、D1には月間250億回のクエリが無料で含まれています。つまり、余分なコストを気にすることなく、このクエリを月間140万回実行できることになります。
しかし、インデックスがあればもっとうまくやれます。
CREATE INDEX IF NOT EXISTS idx_orders_date ON [Order](ShippedDate)
インデックスが作成されたので、クエリが読み取る必要がある行数を確認してみましょう。
SELECT * FROM [Order] WHERE ShippedDate > '2016-01-22'"
[
{
"results": [],
"success": true,
"meta": {
"duration": 3.793,
"size_after": 33067008,
"rows_read": 417,
"rows_written": 0
}
}
]
「ShippedDate」列にインデックスを付けた同じクエリで読み取るのは、わずか417行です。このクエリの方が速いだけでなく(実行時間はミリ秒単位!)、コストも低く抑えられます。このクエリを月に5,900万回実行しても、Workersプランで提供される5ドル以上のコストはかかりません。
D1はまた、Cloudflareダッシュボードと当社のGraphQL分析APIの両方を介して行数を表示します。したがって、パフォーマンスをチューニングする際にクエリごとに確認できるだけでなく、すべてのデータベースにわたってクエリパターンを解析することもできます。
プラットフォーム用D1
D1のアルファ版期間中、私たちはD1の水平スケールアウト能力に注目するチームから話を聞いたり、一緒に働いたりしてきました。つまり、顧客(またはユーザー!)ごとにデータベースをデプロイできることで、チームがデータにアクセスする場所をより近くに保ち、さらにそのデータを他のユーザーからより明確に分離できるのです。
Workers for Platformsで次の大きなものを構築するチームは、「Functions as a Service, as a Service」と考えて、D1を使ってユーザーごとにデータベースをデプロイすることができ、顧客データをそれぞれより明確に分離しておくことができます。
例えば、RONINはD1をいち早く採用した企業の1社ですが、顧客ごとに専用のD1データベースに設けられた最先端のコンテンツ&データプラットフォームを構築しています。これにより、顧客はデータをユーザーの近くに置くことができ、各顧客は他の顧客のクエリから分離されます。
RONINは、従来のデータベースインスタンスを無数に立ち上げて管理する代わりに、D1 for Platformsを使用してエッジで自動的に無限のスケーラビリティを提供します。これにより、RONINはコンテンツを直感的に編集するエクスペリエンスを提供することに専念することができます。
「D1 for Platforms」を実現するために、当初よりいくつかの方法が検討されてきました。
- Workers for Platformsユーザーは、D1がすでに提供している1アカウントあたり50,000のデータベースに加え、100,000以上のデータベースをサポートします。制限はないのですが、「無制限」といっても信じがたいでしょう。
- D1の価格設定 - データベースごとの支払いや「アイドルデータベース」に対する支払いはありません。数千QPSのユーザーから10分に1~2人のユーザーまで、さまざまなユーザーがいる場合、トラフィックの少ないデータベースの「データベース時間」に対して高い料金を支払ったり、ユーザーベース全体で発生するスパイクのようなワークロードのために計画したりする必要はありません。
- D1のHTTP APIを介して、より多くのデータベースをプログラムで設定し、再デプロイすることなくWorkerにアタッチすることができます。「プロビジョニング」の遅延もありません。データベースを作成したら、すぐにお客様やお客様のユーザーがクエリできるようになります。
- データベースごとの詳細な分析により、D1のGraphQL分析APIを介して、どのデータベースが使用され、どのようにクエリされているかを把握できます。
Workers上に次の大きなプラットフォームを構築し、D1を大規模に使用したい場合、Workers Launchpadプログラムに参加しているかどうかに関わらず、ご連絡ください。
D1の次の目標は?
私たちが掲げている明確な目標は、来年初頭(2024年第1四半期)までに、D1を本番環境で利用できる「一般利用可能(GA)」にすることです。D1はすでにウェイティングリストや承認プロセスなしでご利用いただけますが、データベースに関して一般利用可能ということが多くの人にとって重要なことを理解しています(私たちも同様です)。
これから一般利用開始までの間、信頼性とパフォーマンスに焦点を当てながら、D1ビジョンの非常に重要な部分に取り組んでいきます。
このビジョンの残された最大のピースの1つが、今年の初めに記事にしたグローバルなリードレプリケーションです。重要なのは、レプリケーションは無料で、ストレージの消費量を増やさず、セッションの一貫性(read-your-writes)を実現することです。D1のミッションの1つは、データをユーザーのいる場所に近づけることですが、その実現も楽しみです。
また、D1に内蔵されているポイントインタイムのリカバリ機能であるTime Travelですが、特定の時点からデータベースをその場でブランチしたり、クローンしたりできるようにするための拡張にも取り組んでいます。
また、今年中にデータベースごとのストレージの制限を徐々に開放し、アカウントごとのストレージ数を増やし、作成できるデータベースの数を増やしていく予定です。D1の変更履歴(またはお使いの受信トレイ)に注意していてください。
まだD1を使ったことがない方は、今すぐ開始できます。D1の開発者向けドキュメントをご覧になるなら、アイデアがひらめくでしょう。または、開発者用Discordの#d1-betaチャンネルに参加して、他のD1開発者や製品エンジニアリングチームと話すこともできます。