


生成AIを支える大規模言語モデル(LLM)と拡散モデルの構築には、大規模なインフラスストラクチャが必要です。最も明白なコンポーネントは数百から数千のGPUによるコンピューティングですが、同様に重要な(そしてしばしば見落とされる)コンポーネントは、 データストレージインフラストラクチャです。 トレーニングデータセットのサイズはテラバイトからペタバイトになる可能性があり、このデータは数千のプロセスで並行して読み取る必要があります。さらに、モデルのチェックポイントはトレーニングの実行中に頻繁に保存する必要があり、LLMの場合、これらのチェックポイントはそれぞれ数百ギガバイトになることがあります!
ストレージコストとスケーラビリティを管理するために、多くの機械学習チームがデータセットとチェックポイントをホストするためにオブジェクトストレージに移行してきました。残念ながら、ほとんどのオブジェクトストアプロバイダーは、ユーザーを自社のプラットフォームに「ロックイン」するために、エグレス料金を使用しています。このことより、データやモデルのチェックポイントを移動させるにはコストがかかりすぎるため、複数のクラウドプロバイダーでGPUの能力を活用したり、他の場所で低価格や動的な価格設定を利用することは非常に困難です。クラウドGPUが不足し、新しいハードウェアオプションが市場に参入している今、柔軟性を保つことはこれまで以上に重要です。
高いエグレス料金に加え、オブジェクトストア中心の機械学習トレーニングには技術的な障壁があります。オブジェクトストレージとコンピューティングクラスター間のデータの読み込み/書き込みには、高いスループット、ネットワーク帯域幅の効率的な使用、決定性、弾力性(異なる数のGPUでトレーニングする能力)などが求められます。これらを正しく、確実に処理するためのトレーニングソフトを作るのは大変です!
本日は、MosaicMLのツールとCloudflare R2を併用することで、これらの課題にどのように対処できるかをご紹介します。第一に、MosaicMLのオープンソースであるStreamingDatasetとComposerライブラリを使えば、トレーニングデータのストリームインやモデルのチェックポイントをR2に読み込み/書き込みを簡単に戻すことができます。必要なのは、インターネット接続だけです。第二に、R2のゼロエグレス料金により、データ転送料を支払うことなく、コンピューティングプロバイダー間のGPUの利用可能性と価格に応じてジョブを開始/停止/移動/リサイズすることができます。MosaicMLのトレーニングプラットフォームは、複数のクラウドにまたがるトレーニングジョブのオーケストレーションを非常に簡単に行うことができます。
CloudflareとMosaicMLが一丸となり、切り替えコストゼロで世界中どこでもあらゆるコンピューティングパワーでLLMを訓練する自由が実現します。これにより、よりスピーディに、低い訓練実施コストで、ベンダーロックイン根絶が実現します。
「MosaicMLトレーニングプラットフォームを使用することで、お客様はR2を耐久性のあるストレージバックエンドとして効率的に使用し、あらゆるコンピューティングプロバイダー上でLLMをトレーニングすることができ、さらにエグレス料金はゼロです。AI企業は法外なクラウドコストに直面しており、最高のモデルを最高の価格でトレーニングするためのスピードと柔軟性を提供できるツールを求めています。」
– Naveen Rao(MosaicML社CEO兼共同創業者
StreamingDatasetを使ったR2からのデータ読み込み
R2から効率的かつ決定論的にデータを読み込むには、MosaicML StreamingDatasetライブラリを使用することができます。まず、トレーニングデータ(画像、テキスト、動画、何でもOKです!)を、提供されているPython APIを使って `.mds` シャードファイルに書き込みます。
import numpy as np
from PIL import Image
from streaming import MDSWriter
# Local or remote directory in which to store the compressed output files
data_dir = 'path-to-dataset'
# A dictionary mapping input fields to their data types
columns = {
'image': 'jpeg',
'class': 'int'
}
# Shard compression, if any
compression = 'zstd'
# Save the samples as shards using MDSWriter
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
データセットが変換されたら、R2にアップロードできます。以下では、`awscli`コマンドラインツールを使って説明しますが、`wrangler`やお好みのS3互換ツールを使うこともできます。StreamingDatasetは、近日中にR2へのクラウド直接書き込みにも対応する予定です!
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/folder --endpoint-url $S3_ENDPOINT_URL
最後に、R2バケットへの読み込みアクセス権を持つデバイスにデータを読み込むことができます。個々のサンプルをフェッチし、データセット上でループし、標準的なPyTorchのデータローダーにフィードできます。
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/folder'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
StreamingDatasetは、高いパフォーマンス、弾力的な決定性、高速な再開、マルチワーカーサポート機能を備えており、すぐに利用できます。また、ダウンロードの帯域幅を最小限に抑えるために、スマートシャッフリングと分散を使用しています。LLMや拡散モデルなどのさまざまなワークロードにおいて、R2のようなオブジェクトストアからトレーニングする場合、トレーニングスループットに影響がない(dataloaderのボトルネックがない)ことが分かっています。詳細は、StreamingDatasetの発表をお知らせするブログをご確認ください!
Composerを使ったR2へのモデルチェックポイントの読み込み/書き込みについて
トレーニングループにデータをストリーミングすることで問題の半分は解決しますが、モデルのチェックポイントをどのようにロード/保存するのでしょうか?幸い、 Composerのようなトレーニングライブラリを使用すれば、R2パスを指定するのと同じくらい簡単です!
from composer import Trainer
...
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
trainer = Trainer(
run_name='mpt-7b',
model=model,
train_dataloader=train_loader,
...
save_folder=s3://my-bucket/mpt-7b/checkpoints,
save_interval='1000ba',
# load_path=s3://my-bucket/mpt-7b-prev/checkpoints/ep0-ba100-rank0.pt,
)
Composerは非同期アップロードを使用して、トレーニング中にチェックポイントが保存される際の待ち時間を最小限に抑えます。また、マルチGPUやマルチノードのトレーニングでもすぐに動作し、 共有ファイルシステムを必要としません。つまり、コンピューティングクラスターに高価なEFS/NFSシステムを設定する必要がなく、パブリッククラウドで毎月数千ドル以上を節約できることを意味します。インターネット接続と適切な認証情報さえあれば、チェックポイントはR2バケットに安全に到達し、プライベートモデル用のスケーラブルで安全なストレージを提供します。
MosaicMLとR2を使って、どこでも効率よくトレーニングができる
上記のツールとCloudflare R2を併用することで、ユーザーはトレーニング用ワークロードをあらゆるコンピューティングプロバイダー上で自由に実行でき、切り替えコストもゼロになります。
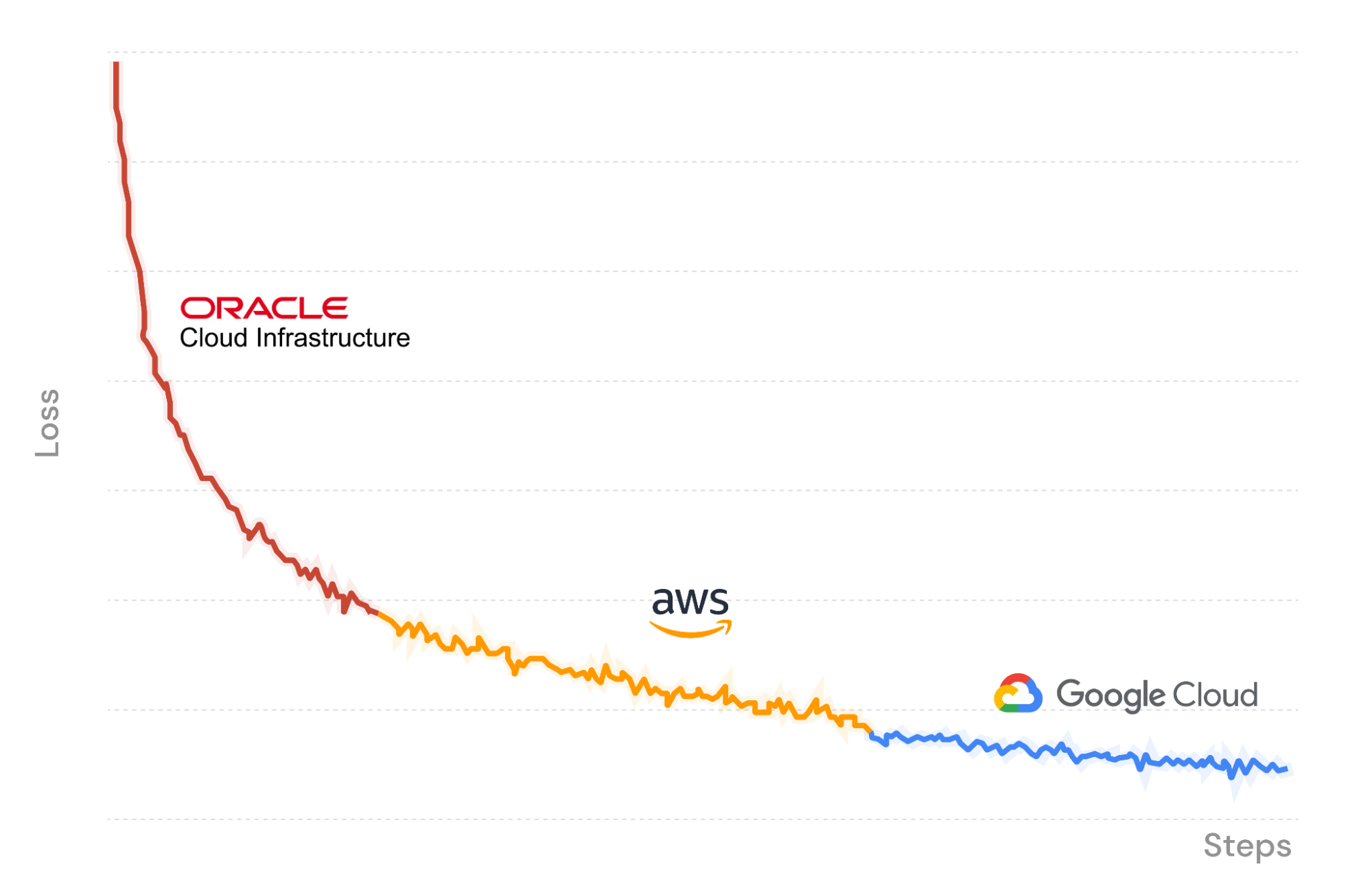
図Xでは、MosaicMLトレーニングプラットフォームを使って、Oracle Cloud Infrastructure上でLLMトレーニングジョブを起動し、データをストリームインし、チェックポイントをR2にアップロードしています。途中でジョブを一時停止し、Amazon Web Services上の別のGPUセットでシームレスに再開します。Composerは、R2で最後に保存したチェックポイントからモデルの重みをロードし、ストリーミングデータローダーは瞬時に正しいバッチに再開されます。トレーニングは決定的に続きます。最後に、再びGoogle Cloudに移動して実行を終了します。
3つのクラウドプロバイダーでLLMをトレーニングするため、私たちが支払うコストはGPUコンピューティングとデータストレージのみです。Cloudflare R2により、エグレス料金は発生せず、ロックインを避けることができます!
$ mcli get clusters
NAME PROVIDER GPU_TYPE GPUS INSTANCE NODES
mml-1 MosaicML │ a100_80gb 8 │ mosaic.a100-80sxm.1 1
│ none 0 │ cpu 1
gcp-1 GCP │ t4 - │ n1-standard-48-t4-4 -
│ a100_40gb - │ a2-highgpu-8g -
│ none 0 │ cpu 1
aws-1 AWS │ a100_40gb ≤8,16,...,32 │ p4d.24xlarge ≤4
│ none 0 │ cpu 1
oci-1 OCI │ a100_40gb 8,16,...,64 │ oci.bm.gpu.b4.8 ≤8
│ none 0 │ cpu 1
$ mcli create secret s3 --name r2-creds --config-file path/to/config --credentials-file path/to/credentials
✔ Created s3 secret: r2-creds
$ mcli create secret env S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
✔ Created environment secret: s3-endpoint-url
$ mcli run -f mpt-125m-r2.yaml --follow
✔ Run mpt-125m-r2-X2k3Uq started
i Following run logs. Press Ctrl+C to quit.
Cloning into 'llm-foundry'...
MCLIコマンドラインツールを使用して、コンピュートクラスタ、シークレット、サブミットランを管理する。
### mpt-125m-r2.yaml ###
# set up secrets once with `mcli create secret ...`
# and they will be present in the environment in any subsequent run
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: main
pip_install: -e .[gpu]
image: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
cd llm-foundry/scripts
composer train/train.py train/yamls/mpt/125m.yaml \
data_remote=s3://bucket/path-to-data \
max_duration=100ba \
save_folder=s3://checkpoints/mpt-125m \
save_interval=20ba
run_name: mpt-125m-r2
gpu_num: 8
gpu_type: a100_40gb
cluster: oci-1 # can be any compute cluster!
MCLIジョブテンプレート。実行名、Dockerイメージ、コマンドセット、実行するコンピューティングクラスターの指定。
今すぐ始めましょう
MosaicMLプラットフォームは、トレーニングを次のレベルに引き上げるための貴重なツールです。この記事では、Cloudflare R2が、あらゆるコンピューティングプロバイダー(あるいはそのすべて)を利用して、独自のデータでモデルをトレーニングできるようにする方法を探りました。R2のストレージはエグレス料金を排除することで、MosaicMLのトレーニングを補完し、最大限の自律性と制御を実現する非常に費用対効果の高い製品です。この組み合わせなら、時間の経過とともに組織のニーズに合わせてクラウドサービスプロバイダーを切り替えていくことが可能です。
MosaicMLを使用して、お客様のデータでカスタムの最先端AIをトレーニングする方法については、 こちらをご覧いただくか、当社までお問い合わせください。