

Workers Analytics Engine est un nouvel outil, annoncé plus tôt cette année, qui permet aux développeurs et aux équipes produit de générer des données analytiques issues de séries chronologiques pour toutes les données, avec une dimensionnalité et une cardinalité élevées, ainsi qu'une mise à l'échelle fluide. Nous avons développé Analytics Engine pour permettre aux équipes d'obtenir des informations sur le code qu'elles exécutent dans Workers, de fournir des données analytiques aux clients finaux ou même d'établir une facturation en fonction de la consommation.
Dans cet article de blog, nous allons vous expliquer comment nous utilisons Analytics Engine pour développer Analytics Engine. Nous avons instrumenté notre API SQL Analytics Engine avec la solution Analytics Engine elle-même, et nous utilisons ces données pour rechercher les bugs et hiérarchiser les nouvelles fonctionnalités du produit. Nous espérons que cette approche servira d'inspiration à d'autres équipes qui cherchent des solutions pour instrumenter leurs produits et recueillir des commentaires.
Pourquoi avons-nous besoin d'Analytics Engine ?
Analytics Engine vous permet de générer des événements (ou « points de données ») depuis Workers avec quelques lignes de code seulement. Avec l'API GraphQL ou l'API SQL, vous pouvez interroger ces événements et générer des informations utiles sur votre activité ou votre pile technologique. Pour découvrir comment faire vos premiers pas avec Analytics Engine, consultez notre documentation pour développeurs.
Depuis le lancement de la version bêta ouverte d'Analytics Engine en septembre, nous avons ajouté de nouvelles fonctionnalités à un rythme soutenu, en fonction des commentaires reçus des développeurs. Cependant, nous avons constaté deux grandes lacunes dans notre visibilité du produit.
Premièrement, notre équipe d'ingénieurs doit répondre à des questions traditionnelles concernant l'observabilité : combien de requêtes nous recevons, quelle part de ces requêtes génère des erreurs, quelle est la nature de ces erreurs, etc. Nos ingénieurs doivent à la fois pouvoir visualiser des données agrégées (par exemple, le taux d'erreurs moyen ou le temps de réponse du centile p99) et approfondir des événements individuels.
Deuxièmement, parce qu'il s'agit d'un produit récemment lancé, nous sommes à demandeurs d'informations concernant le produit. En instrumentant l'API SQL, nous pouvons comprendre les requêtes que nos clients écrivent et les erreurs qu'ils observent, ce qui nous aide à hiérarchiser les fonctionnalités manquantes.
Nous avons pris conscience qu'Analytics Engine serait un formidable outil pour répondre à nos questions concernant l'observabilité technique, mais également pour recueillir des informations sur le produit. En effet, nous pouvons journaliser un événement pour chaque requête transmise à notre API SQL, puis examiner les problèmes de performances dans leur ensemble, ainsi que les erreurs individuelles et les requêtes exécutées par nos clients.
Dans la section suivante, nous allons vous expliquer comment nous utilisons Analytics Engine pour surveiller cette API.
Ajouter l'instrumentation à notre API SQL
L'API SQL d'Analytics Engine vous permet d'interroger les données d'événements de la même manière que vous interrogeriez une base de données ordinaire. Depuis des décennies, SQL est le langage le plus courant pour l'interrogation des données. Nous souhaitions fournir une interface qui vous permette de commencer à interroger immédiatement vos données, sans devoir apprendre un nouveau langage de génération de requêtes.
Notre API SQL analyse les requêtes SQL des utilisateurs, les transforme et les valide, puis les exécute sur les serveurs de bases de données back-end. Nous retranscrivons ensuite les informations concernant la requête dans Analytics Engine, afin de pouvoir exécuter nos propres analyses de données.
L'écriture de données dans Analytics Engine depuis une instance Cloudflare Workers est une procédure très simple, expliquée dans notre documentation. Nous instrumentons notre API SQL de la même manière que nos utilisateurs, et cet extrait de code présente les données que nous écrivons dans Analytics Engine :
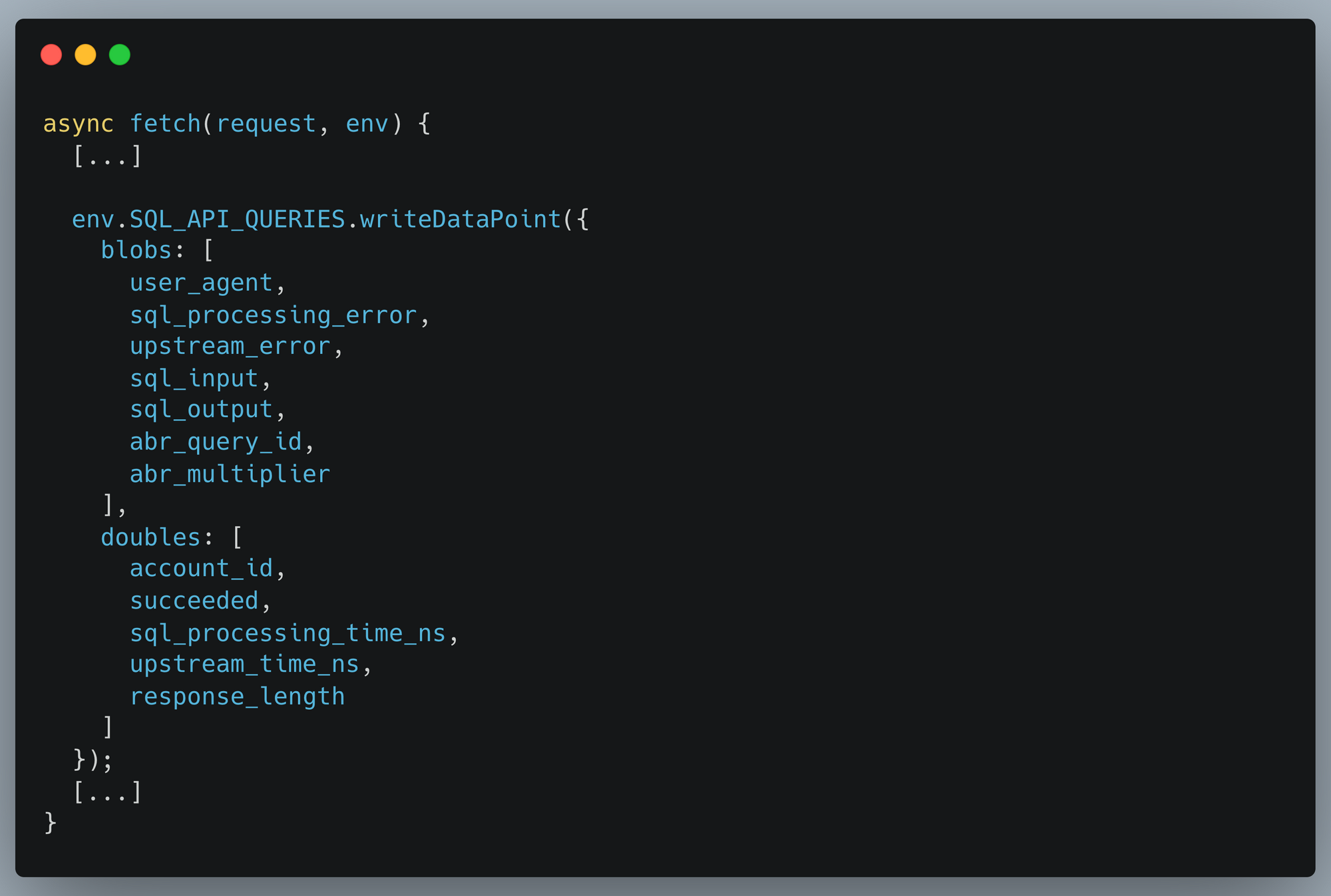
Ces données étant maintenant stockées dans Analytics Engine, nous pouvons en extraire des informations sur chacun des champs que nous examinons.
Créer des requêtes pour générer des informations
La conservation de nos données analytiques dans une base de données SQL vous offre la liberté d'écrire toutes les requêtes de votre choix. Par rapport à l'utilisation d'éléments tels que des indicateurs, qui sont souvent prédéfinis et spécifiques à un objectif, vous pouvez définir n'importe quel ensemble de données personnalisé et interroger vos données afin de poser facilement de nouvelles questions.
Nous devons assurer la prise en charge d'ensembles de données comprenant des trillions de points de données. Pour y parvenir, nous avons mis en œuvre une méthode d'échantillonnage appelée Adaptive Bit Rate (ABR). Avec ABR, si vous disposez de grands volumes de données, vos requêtes peuvent être renvoyées sous forme d'événements échantillonnés, afin d'offrir une réponse dans un délai raisonnable. Si vous disposez de volumes de données plus habituels, Analytics Engine interrogera toutes vos données. Cela vous permet d'exécuter toutes les requêtes de votre choix et d'obtenir rapidement des réponses. Actuellement, vous devez tenir compte de l'échantillonnage lors de la création de vos requêtes, mais nous examinons différentes approches pour automatiser ce processus.
Vous pouvez utiliser n'importe quel outil de visualisation de données pour visualiser vos données analytiques. Chez Cloudflare, nous utilisons fréquemment Grafana (et vous pouvez l'utiliser, vous aussi !). Cet outil est particulièrement utile dans le cadre de scénarios d'utilisation reposant sur l'observabilité.
Observer les temps de réponse de requêtes
Une requête à laquelle nous prêtons une attention particulière nous fournit des informations sur les performances de nos clusters de bases de données back-end :
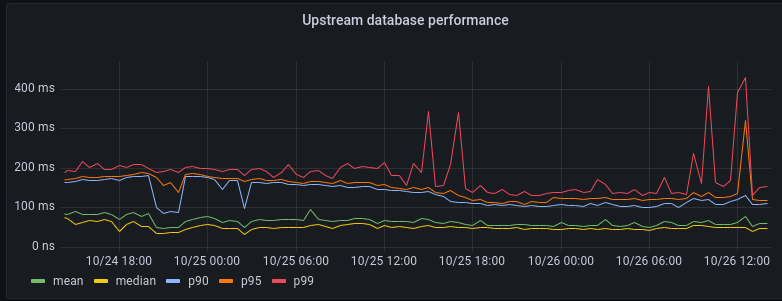
Comme vous pouvez le constater, le centile des 99 % (qui correspond au 1 % de requêtes dont l'exécution est la plus complexe) présente parfois des pics atteignant quelque 300 ms. En moyenne, notre back-end répond aux requêtes dans un délai de 100 ms.
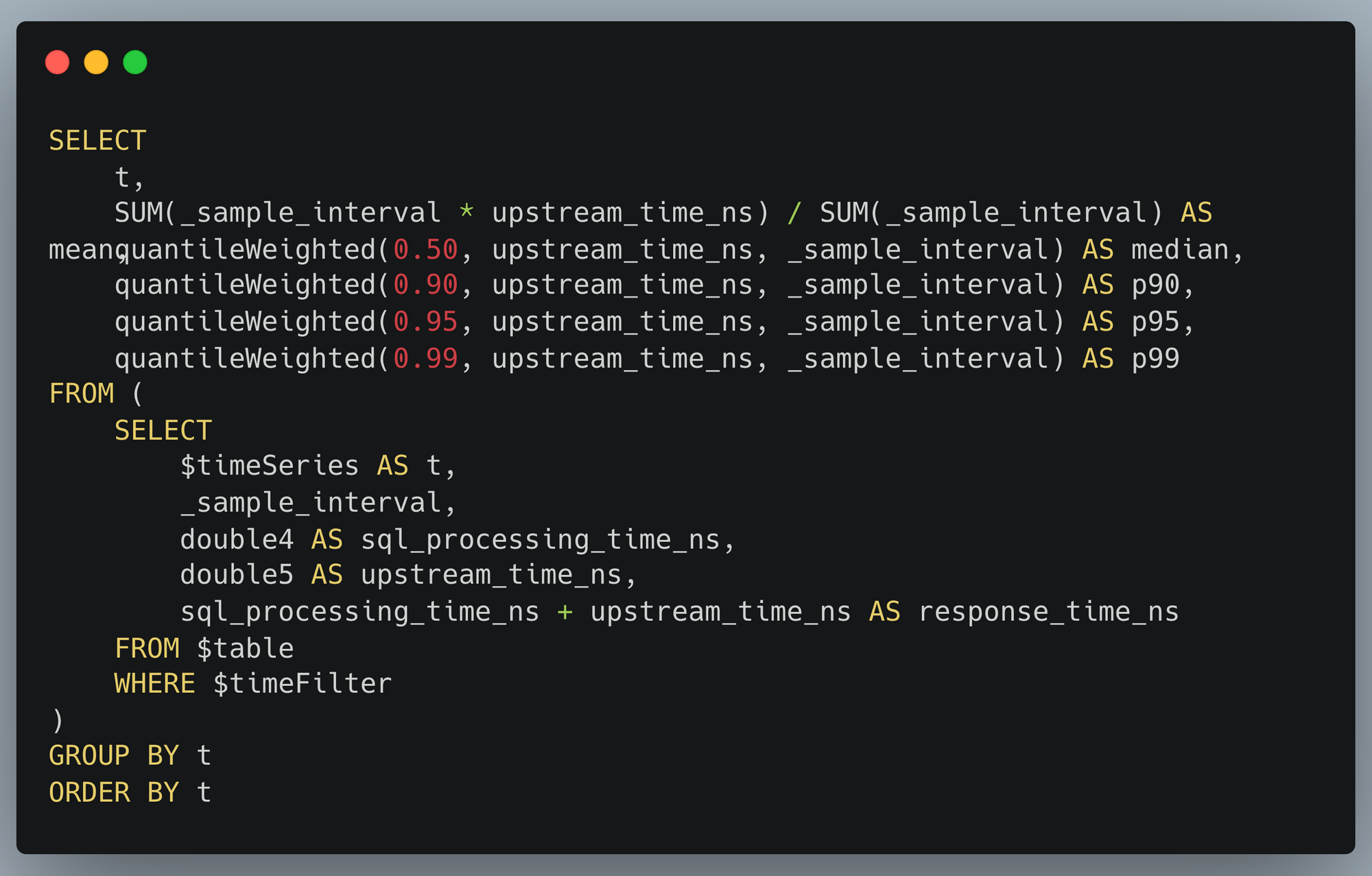
Cette visualisation est elle-même générée à partir d'une requête SQL :
Informations sur les clients issues de données à cardinalité élevée
Une autre utilisation d'Analytics Engine consiste à extraire des informations des données concernant le comportement des clients. Notre API SQL est particulièrement utile à cette fin, car elle vous permet de pleinement utiliser la puissance de SQL. Grâce à notre technologie ABR, même des requêtes très étendues peuvent être exécutées sur d'immenses volumes de données.
Nous utilisons cette capacité pour faciliter la hiérarchisation des améliorations à apporter à Analytics Engine. Notre API SQL prend en charge un dialecte assez classique de SQL, mais ses fonctionnalités sont encore incomplètes. Si un utilisateur tente d'effectuer une opération non prise en charge dans une requête SQL, il voit s'afficher un message d'erreur structuré. Ces messages d'erreur sont intégrés aux rapports dans Analytics Engine. Nous sommes en mesure d'agréger les types d'erreurs rencontrées par nos clients, ce qui nous aide à déterminer quelles fonctionnalités doivent être priorisées par la suite.
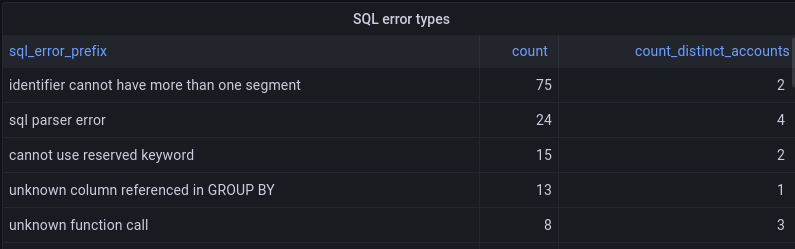
L'API SQL renvoie les erreurs au format type of error: more details. La première partie de l'erreur (avant les deux-points) indique donc le type d'erreur. Nous regroupons les erreurs en fonction de cette information pour obtenir un décompte du nombre d'occurrences de cette erreur et du nombre d'utilisateurs affectés.
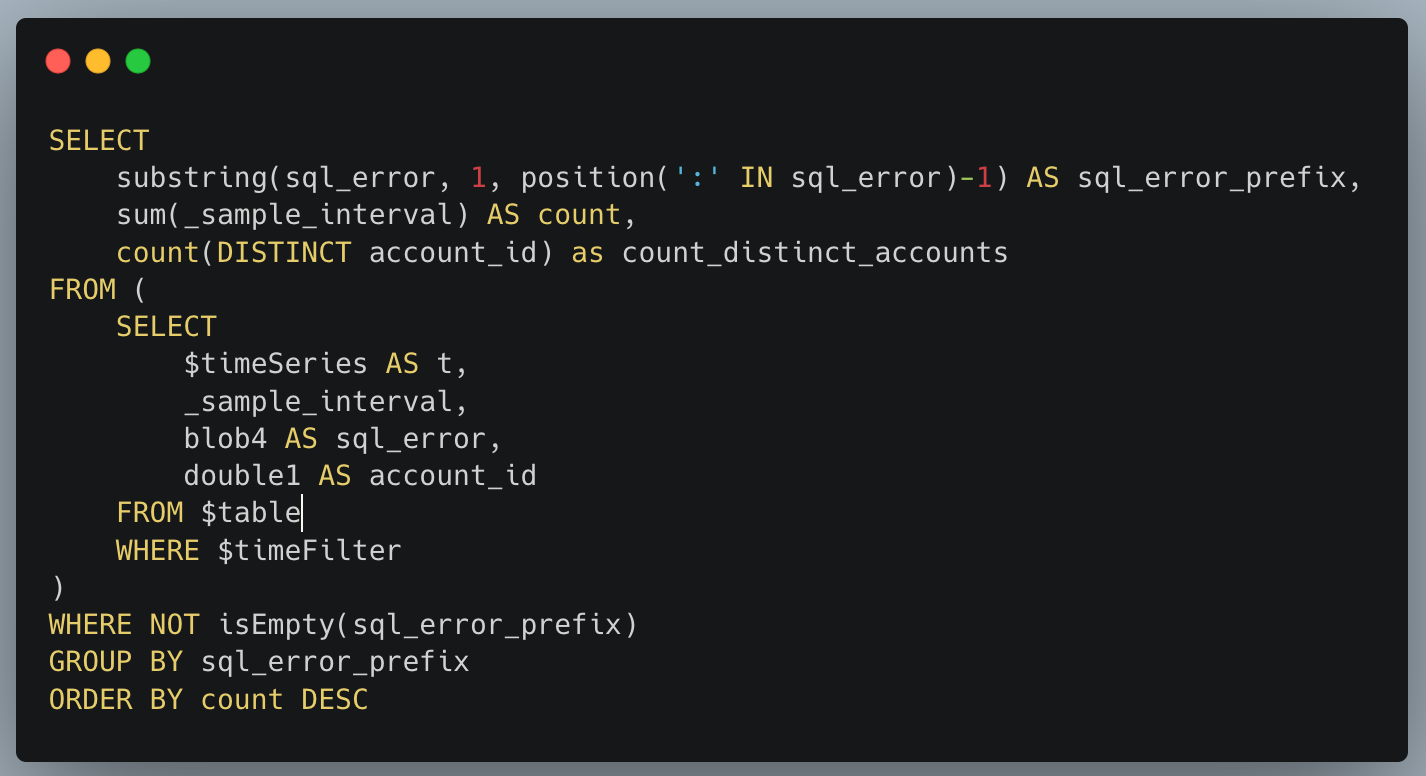
Pour exécuter la requête ci-dessus avec un système d'indicateurs ordinaire, il nous faudrait représenter chaque type d'erreur par un indicateur différent. Établir des rapports examinant autant d'indicateurs pour chaque microservice comporte des défis en termes d'évolutivité. Ce problème ne se présente pas avec Analytics Engine, puisque la solution est conçue pour traiter des données à cardinalité élevée.
Un autre avantage remarquable qu'offre un référentiel à cardinalité élevée tel qu'Analytics Engine est la capacité d'approfondir l'examen des détails. En cas de pic d'erreurs SQL, nous pouvons rechercher les clients affectés par un problème particulier afin de les aider ou d'identifier la fonction qu'ils essaient d'utiliser. C'est une tâche simple, avec une autre requête SQL :
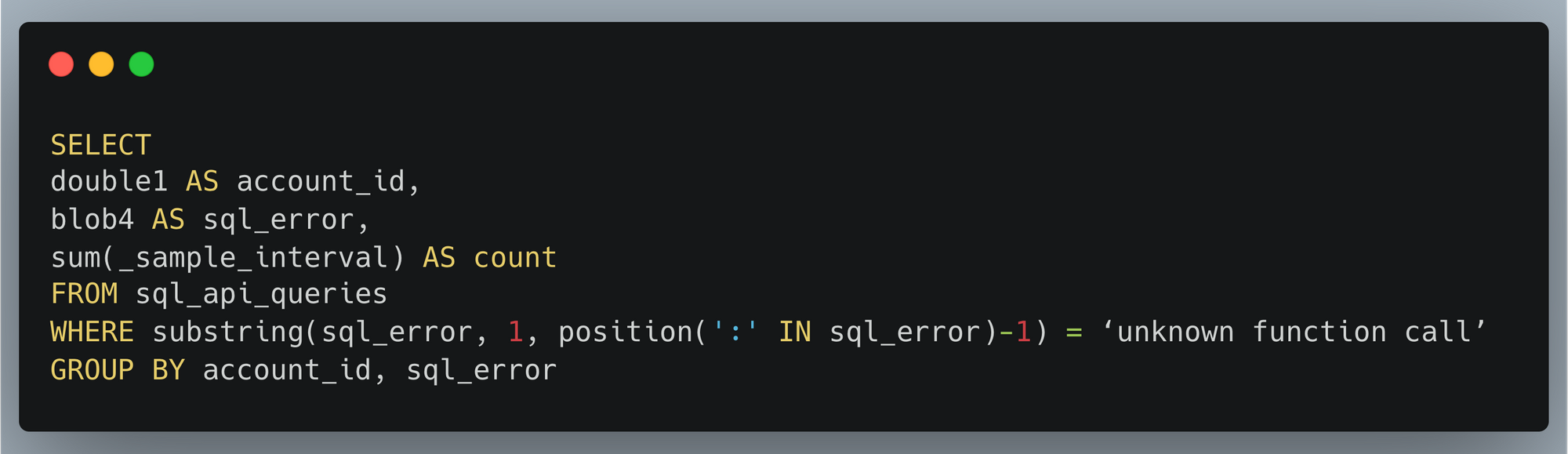
Dans les rouages de la solution Cloudflare, nous nous sommes toujours appuyés sur l'interrogation de nos serveurs de base de données back-end pour obtenir ce type d'informations. L'API SQL d'Analytics Engine nous permet désormais d'ouvrir notre technologie à nos clients, afin qu'ils puissent collecter facilement des informations sur leurs services à n'importe quelle échelle !
Conclusion et évolutions futures
Les informations que nous avons collectées sur l'utilisation de l'API SQL sont très utiles pour étayer nos décisions concernant la hiérarchisation des fonctionnalités du produit. Nous avons déjà ajouté la prise en charge des fonctions substring et position, utilisées dans les visualisations ci-dessus.
Si nous examinons les principales erreurs SQL, nous remarquons de nombreuses erreurs liées à la sélection de colonnes. Ces erreurs sont principalement imputables à des problèmes de convivialité du plugin Grafana. L'ajout de la prise en charge de la fonction DESCRIBE devrait atténuer ce problème, car sans cette fonction, le plugin Grafana ne comprend pas la structure de la table. Cette évolution figure sur notre feuille de route, à l'instar d'autres améliorations de notre plugin Grafana.
Nous constatons également que des utilisateurs essaient d'interroger des plages de temps correspondant à des données anciennes, qui n'existent plus. Cela suggère que nos clients aimeraient bénéficier d'une période de rétention prolongée des données. Nous avons récemment étendu notre période de rétention de 31 à 92 jours et nous allons continuer à surveiller cette demande, afin de déterminer si nous devons étendre davantage cette période.
Nous avons constaté de nombreuses erreurs liées à des erreurs courantes ou à une mauvaise compréhension de la syntaxe SQL correcte. Cela nous apprend que nous pourrions fournir de meilleurs exemples ou explications d'erreurs dans notre documentation, afin d'aider les utilisateurs à résoudre leurs requêtes.
Gardez un œil sur notre documentation pour développeurs afin d'être informé de l'évolution et de l'ajout de nouvelles fonctionnalités !
Vous pouvez commencer à utiliser Workers Analytics Engine maintenant ! Analytics Engine est actuellement en version bêta ouverte, avec une rétention gratuite des données pendant 90 jours. Commencez à l'utiliser aujourd'hui ou rejoignez notre communauté Discord pour échanger avec l'équipe.