

Introduction
Mon équipe : l'équipe Cloudflare PROTOCOLS est responsable de la terminaison du trafic HTTP à la périphérie du réseau Cloudflare. Nous traitons avec des fonctionnalités liées à : Gestion des protocoles TCP, QUIC, TLS et des certificats sécurisés, HTTP/1 et HTTP/2. Au cours du premier trimestre, nous étions en charge de l’implémentation du produit de hiérarchisation HTTP/2 amélioré annoncé par Cloudflare lors de la Speed Week.
Il est très intéressant de faire partie de ce projet, et encore plus passionnant lorsque vous obtenez des résultats. Au cours du projet, nous avons cependant eu un certain nombre de réalisations intéressantes sur NGINX : le serveur orienté HTTP sur lequel Cloudflare déploie actuellement son infrastructure logicielle. Nous avons rapidement été certains que notre projet de hiérarchisation améliorée HTTP/2 ne pourrait pas obtenir un succès, même modéré, si le fonctionnement inhérent de NGINX n'était pas modifié.
En raison de ces réalisations, nous avons entrepris un certain nombre de modifications importantes dans la structure interne de NGINX, parallèlement aux travaux sur le produit principal de hiérarchisation. Cet article de blog décrit la motivation derrière les changements structurels, la façon dont nous les avons abordés et leur impact. Nous identifions également d'autres modifications que nous prévoyons d'ajouter à notre feuille de route, qui, nous l'espérons, amélioreront encore les performances.
Historique
La hiérarchisation HTTP/2 améliorée a un objectif dans le trafic Web entre un client et un serveur : c’est un moyen de structurer les nombreux flux HTTP/2 lorsqu’ils passent de l’amont (côté serveur ou source) à une seule connexion HTTP/2 qui s’achemine en aval (côté client).
La hiérarchisation HTTP/2 améliorée permet aux propriétaires de sites et aux systèmes périphériques Cloudflare d’imposer les règles relatives à la manière dont divers objets doivent être combinés dans une connexion HTTP/2 unique : si un objet particulier doit être prioritaire et dominer cette connexion pour atteindre le client dès que possible, ou si un groupe d’objets doit partager de manière égale la capacité de la connexion et mettre davantage l’accent sur le parallélisme.
Par conséquent, la hiérarchisation HTTP/2 améliorée permet aux propriétaires de sites de résoudre deux problèmes existant entre un client et un serveur : comment contrôler la priorité et le classement des objets et comment utiliser au mieux une ressource de connexion limitée, qui peut être contrainte par un certain nombre de facteurs tels que la bande passante, le volume de trafic et la charge de travail du processeur à différents niveaux du chemin de la connexion.
Qu'avons-nous observé ?
La clé de voûte de la hiérarchisation est de pouvoir comparer deux ou plusieurs flux HTTP/2, afin de déterminer la trame duquel doit être le prochain à emprunter le réseau. Le projet de hiérarchisation HTTP/2 améliorée nous a nécessairement entraîné dans la base de code principale de NGINX, notre intention étant de modifier fondamentalement la façon dont NGINX comparait et mettait en file d'attente les structures de données HTTP/2 lors de leur réécriture au client.
Très tôt dans la phase d’analyse, lorsque nous avons fouillé dans les composants internes de NGINX pour analyser le site de nos fonctionnalités proposées, nous avons constaté un certain nombre de lacunes dans la structure même de NGINX, notamment la manière dont il a déplacé les données de l’amont (côté serveur) vers l’aval (côté client) et la manière dont il stocke temporairement (en mémoire tampon) ces données dans ses différentes étapes internes. La principale conclusion de notre première analyse de NGINX était qu’il n’avait simplement pas réussi à offrir une « proximité » aux trames de données. Soit les flux ont été traités dans la couche NGINX HTTP/2 en succession isolée, soit des trames de flux différents ont passé très peu de temps au même endroit : une file d'attente partagée, par exemple. L’effet net a été une réduction des possibilités de comparaison utiles.
Nous avons inventé une nouvelle mesure peu scientifique mais utile : le potentiel, pour décrire l'efficacité avec laquelle les stratégies de hiérarchisation HTTP/2 améliorée (ou même la hiérarchisation par défaut de NGINX) peuvent être appliquées aux flux de données en file d'attente. Le potentiel n’est pas tant une mesure de l’efficacité de la hiérarchisation en soi. Cette métrique serait laissée pour plus tard dans le projet, c’est plutôt une mesure des niveaux de participation lors de l’application de l’algorithme. En termes simples, il considère le nombre de flux et de leurs trames compris dans une itération de hiérarchisation, avec davantage de flux et plus de trames conduisant à un potentiel plus élevé.
Ce que nous avons pu constater dès le début, c’est que, par défaut, NGINX affichait un potentiel faible, rendant les instructions de hiérarchisation du navigateur identiques à celles du modèle traditionnel de hiérarchisation HTTP/2, ou de notre produit de hiérarchisation HTTP/2 améliorée, presque inutiles.
Qu'avons-nous fait ?
Dans le but de résoudre les problèmes spécifiques liés au potentiel, ainsi que d’améliorer le débit général du système, nous avons identifié quelques points faibles de NGINX. Ces points (qui seront décrits ci-dessous) ont soit été travaillés et améliorés dans le cadre de notre publication initiale de la hiérarchisation améliorée HTTP/2, soit se sont maintenant ramifiés dans des projets importants auxquels nous consacrerons des efforts d'ingénierie au cours des prochains mois.
Récupération de la file d'attente d'écriture de trame HTTP/2
La récupération de la file d'attente d'écriture a été livrée avec succès dans notre version de la hiérarchisation HTTP/2 améliorée. Paradoxalement, il s’agissait en fait d’un changement par rapport à notre implémentation de la hiérarchisation HTTP/2 améliorée lorsque nous étions au beau milieu du projet. Et c’est un bon exemple de ce que l’on pourrait appeler « conservation des données », qui est un bon moyen d’accroître le potentiel.
Semblable au NGINX d'origine, notre algorithme de hiérarchisation HTTP/2 améliorée placera un ensemble de trames de données HTTP/2 dans une file d'attente d'écriture à la suite d'une itération des stratégies de hiérarchisation qui leur sont appliquées. Le contenu de la file d'attente d'écriture serait destiné à être écrit dans la couche TLS en aval. Également similaire au NGINX d'origine, la file d'attente d'écriture ne peut être que partiellement écrite dans la couche TLS en raison de la contre-pression exercée par la connexion réseau qui a temporairement atteint sa capacité d'écriture.
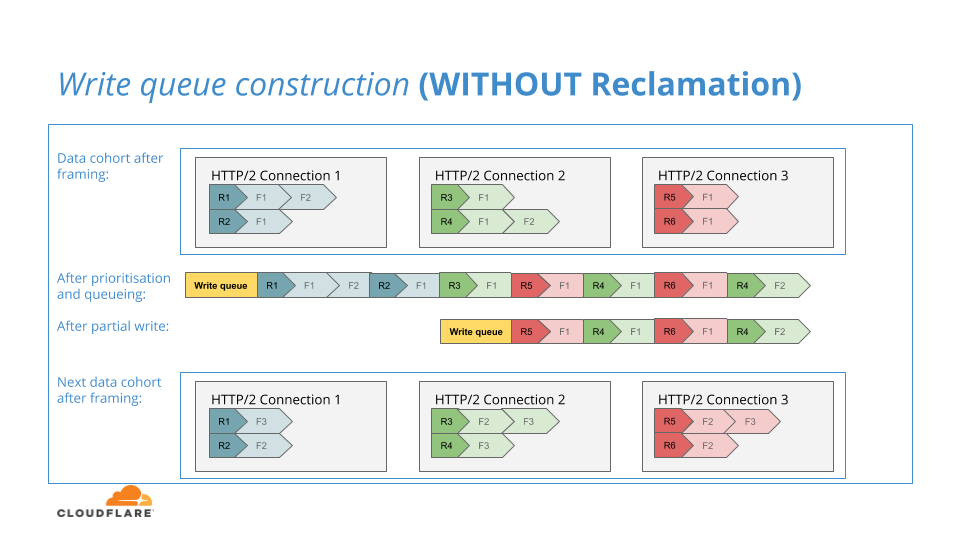
Au début de notre projet, si la file d'attente d'écriture n'était que partiellement écrite dans la couche TLS, nous laisserions simplement les trames dans la file d'attente d'écriture jusqu'à ce que l’accumulation soit supprimée, puis nous essaierions alors de ré-écrire ces données sur le réseau lors d'une prochaine itération d'écriture, tout comme le NGINX d'origine.
Le NGINX d'origine adopte cette approche car la file d'attente d'écriture est le seul endroit où les trames de données en attente sont stockées. Toutefois, dans notre NGINX modifié pour la hiérarchisation HTTP/2 améliorée, nous avons une structure unique qui manque au NGINX d'origine : les files d'attente de trames de données par flux où nous stockons temporairement les trames de données avant que nos algorithmes de hiérarchisation ne leur soient appliqués.
Nous nous sommes rendu compte qu'en cas d'écriture partielle, nous pouvions restaurer les trames non écrites dans leurs files d'attente par flux. Au cas où un nouveau groupe de données arrive après un autre non écrit en partie, les trames précédemment non écrites pourraient participer à une série supplémentaire de comparaisons de priorités, augmentant ainsi le potentiel de nos algorithmes.
Le diagramme suivant illustre ce processus :
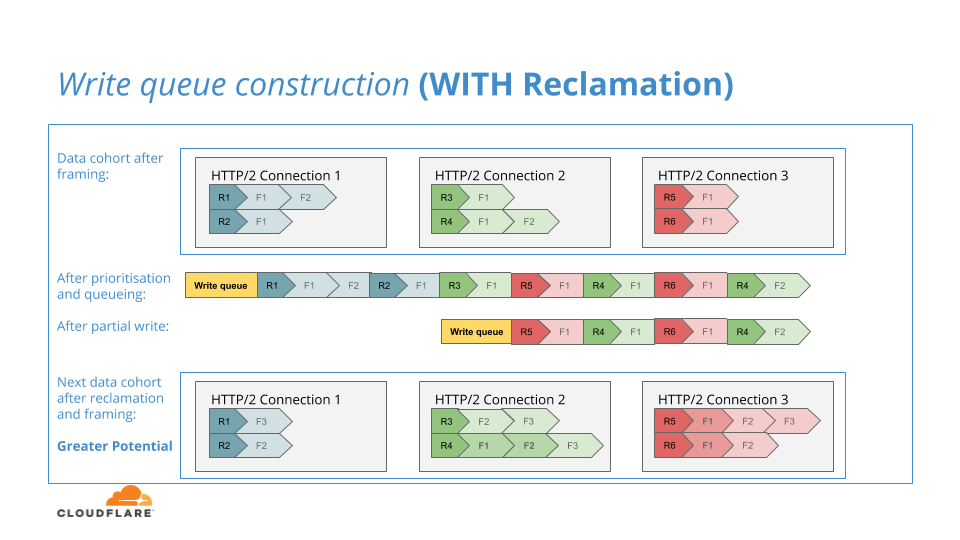
Nous avons été très heureux de fournir la hiérarchisation HTTP/2 améliorée avec la fonctionnalité de récupération incluse. En effet, cette amélioration unique augmentait considérablement le potentiel et compensait le fait que nous devions retenir la prochaine amélioration de la Speed Week en raison de sa finesse.
Réorganisation de l'événement d'écriture de trame HTTP/2
Dans l'infrastructure Cloudflare, nous faisons cadrer les nombreux flux d'une connexion HTTP/2 unique du globe oculaire avec plusieurs connexions HTTP/1.1 vers le plan de contrôle Cloudflare en amont.
Remarque : il peut sembler paradoxal de rétrograder des protocoles comme celui-ci, et cela peut sembler encore plus paradoxal lorsque je révèle que nous désactivons également HTTP Keepalive sur ces connexions en amont, ce qui entraîne une seule transaction par connexion. Toutefois, cet agencement offre de nombreux avantages, notamment sous la forme d’une distribution améliorée de la charge de travail du processeur.
Lorsque NGINX surveille l'activité de lecture de ses connexions HTTP/1.1 en amont, il peut détecter la lisibilité de plusieurs de ces connexions et les traiter toutes dans un lot. Toutefois, au sein de ce lot, les connexions en amont sont traitées une par une de manière séquentielle, du début à la fin : de la lecture de la connexion HTTP/1.1, au cadrage du flux HTTP/2, jusqu’à l’écriture de la connexion HTTP/2 sur la couche T LS.
Le flux de travail NGINX existant est illustré dans ce diagramme :
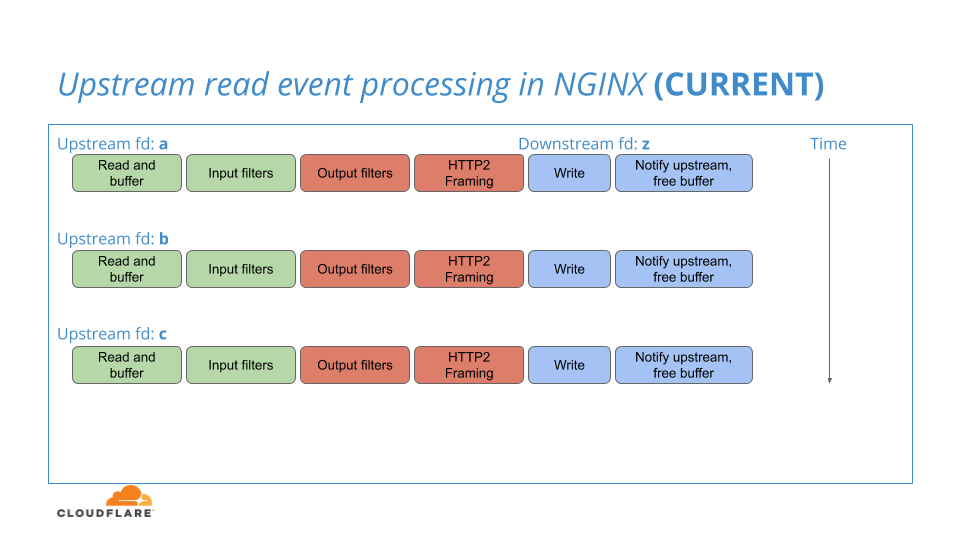
En validant les trames de chaque flux à la couche TLS, un flux à la fois, de nombreuses trames peuvent entièrement passer par le système NGINX avant que la contre-pression sur la connexion en aval ne permette à la file d'attente des trames de se constituer, permettant ainsi à ces trames d’être à proximité et facilitant l’application de la logique de priorisation. Cela a un impact négatif sur le potentiel et réduit l'efficacité de la hiérarchisation.
Le NGINX modifié de la hiérarchisation HTTP/2 améliorée de Cloudflare vise à réorganiser le flux de travail interne décrit ci-dessus dans le modèle suivant :
Bien que nous continuions à encadrer les données en amont des trames de données HTTP/2 dans des itérations différentes pour chaque connexion en amont, nous ne validons plus ces trames dans une seule file d'attente d'écriture au sein de chaque itération, mais nous les organisons en files d'attente par flux décrites précédemment. Nous publions ensuite un seul événement à la fin des itérations par connexion et effectuons la hiérarchisation, la mise en file d'attente et l'écriture des trames de données HTTP/2 de tous les flux de cet événement.
Cet événement unique trouve la cohorte de données stockée de manière pratique dans leurs files d'attente par flux respectives, toutes à proximité, ce qui augmente considérablement le potentiel des algorithmes de hiérarchisation des périphéries.
Dans une forme plus proche du code réel, le cœur de cette modification ressemble un peu à ceci :
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
ngx_http_v2_write_queue(h2_conn->queue);
}
À cela :
ngx_http_v2_process_data(ngx_http_v2_connection *h2_conn,
ngx_http_v2_stream *h2_stream,
ngx_buffer *buffer)
{
while ( ! ngx_buffer_empty(buffer) {
ngx_http_v2_frame_data(h2_conn,
h2_stream->frames,
buffer);
}
ngx_list_add(h2_conn->active_streams, h2_stream);
ngx_call_once_async(ngx_http_v2_write_streams, h2_conn);
}
ngx_http_v2_write_streams(ngx_http_v2_connection *h2_conn)
{
ngx_http_v2_stream *h2_stream;
while ( ! ngx_list_empty(h2_conn->active_streams)) {
h2_stream = ngx_list_pop(h2_conn->active_streams);
ngx_http_v2_prioritise(h2_conn->queue,
h2_stream->frames);
}
ngx_http_v2_write_queue(h2_conn->queue);
}
Cette modification comporte un niveau de risque élevé car, même si elle est remarquablement petite, nous prenons le flux d’événements bien établi et débogué dans NGINX et le changeons de manière significative. Tout comme prendre un certain nombre de pièces Jenga de la tour et les placer à un autre endroit, nous risquons des conditions de course, des ratés d’événements et des pertes d’évènements menant à des blocages lors du traitement des transactions.
En raison de ce niveau de risque, nous n’avons pas publié ce changement dans son intégralité au cours de la Speed Week mais nous continuerons à le tester et à le peaufiner en vue d’une publication ultérieure.
Réutilisation partielle du tampon en amont
Nginx a une zone tampon interne pour stocker les données de connexion qu’il lit en amont. Pour commencer, l'intégralité de ce tampon est prêt à l'emploi. Lorsque les données sont lues depuis l’amont dans le tampon Prêt, la partie du tampon qui contient les données est transmise à la couche HTTP/2 en aval. Étant donné que HTTP/2 est responsable de ces données, cette partie de la mémoire tampon est marquée comme suit : occupé, il restera occupé aussi longtemps qu'il faudra à la couche HTTP/2 pour écrire les données dans la couche TLS, ce qui peut prendre un certain temps (en termes informatiques !).
Pendant ce temps, la couche en amont peut continuer à lire plus de données dans les sections Prêt restantes de la mémoire tampon et continuer à transmettre ces données incrémentielles à la couche HTTP/2 jusqu'à ce qu'il n'y ait plus de sections Prêt disponible.
Lorsque les données en gestion sont enfin terminées dans la couche HTTP/2, l’espace tampon contenant ces données est alors marqué comme suit : Libre
Le processus est illustré dans ce diagramme :
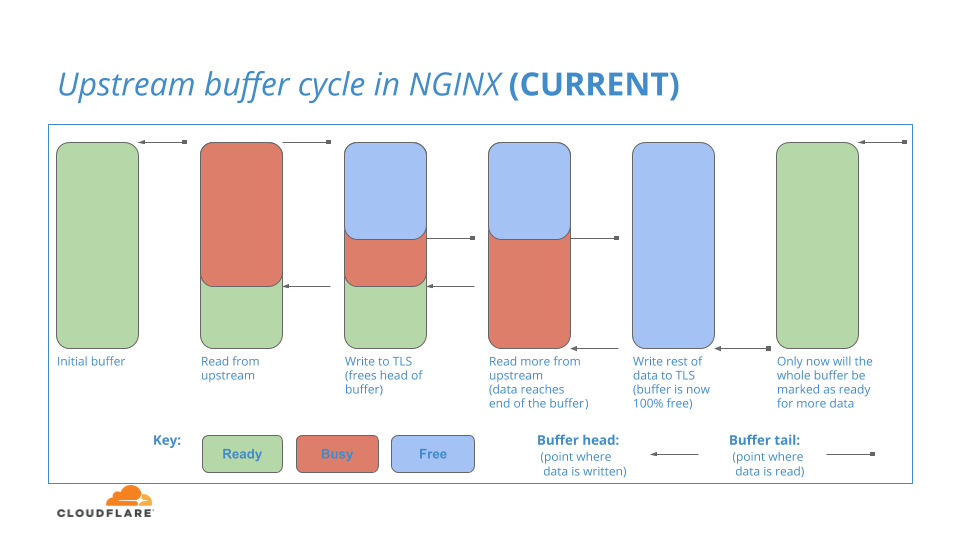
Vous pouvez poser la question de savoir si : lorsque la partie avant du tampon amont est marquée comme étant libre (en bleu, dans le diagramme), même si la partie finale du tampon amont est toujours en gestion, la partie libre peut-elle être réutilisée pour lire davantage de données depuis l'amont ?
La réponse à cette question est la suivante : NON
Comme seule une petite partie de la mémoire tampon est toujours en gestion, NGINX n’autorisera pas la réutilisation de tout l'espace de la mémoire tampon pour les lectures. Ce n'est que lorsque l'intégralité du tampon est libre que le tampon peut être ramené à l'état Prêt et utilisé pour une autre itération des lectures en amont. Donc, en résumé, les données peuvent être lues d’amont dans l’espace Prêt à la fin du tampon, mais pas dans l’espace libre à la tête du tampon.
Ceci est une lacune de NGINX, ce qui est manifestement indésirable car interrompant le flux de données dans le système. Nous avons demandé : qu’en est-il si nous pouvions parcourir cette région tampon et réutiliser des parties en tête une fois devenues libres ? Nous cherchons à répondre à cette interrogation dans un avenir proche en testant le modèle de mise en mémoire tampon suivant dans NGINX :
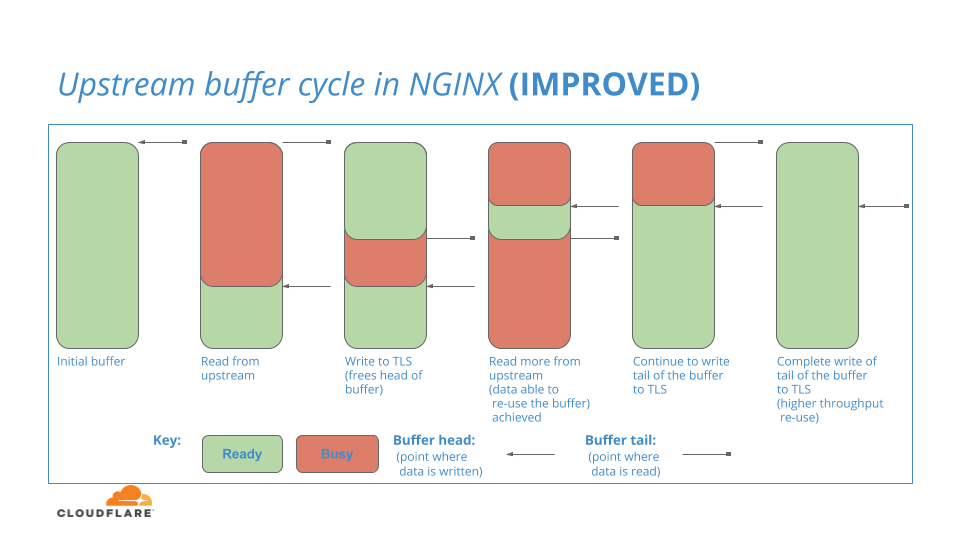
Mise en mémoire tampon de la couche TLS
À plusieurs reprises dans le texte ci-dessus, j'ai mentionné la couche TLS et la manière dont la couche HTTP/2 y écrit des données. Dans le modèle de réseau OSI, TLS se situe juste en dessous de la couche de protocole (HTTP/2) et, dans de nombreux systèmes logiciels de réseau conçus consciemment, tels que NGINX, les interfaces logicielles sont séparées de manière à imiter cette couche.
La couche HTTP/2 de NGINX collecte la cohorte actuelle de trames de données et les place par ordre de priorité dans une file d'attente de sortie, puis soumet cette file d'attente à la couche TLS. La couche TLS utilise un tampon par connexion pour collecter les données de la couche HTTP/2 avant d'effectuer sur celles-ci les transformations cryptographiques réelles.
Le but de la mémoire tampon est de donner à la couche TLS une quantité plus importante de données à chiffrer, car, si la mémoire tampon était trop petite ou si la couche TLS reposait simplement sur les unités de données de la couche HTTP/2, la surcharge d'information due au chiffrement et à la transmission de la multitude de petits blocs pourrait alors avoir un impact négatif sur le débit du système.
Le diagramme suivant illustre cette situation de tampon trop petit :
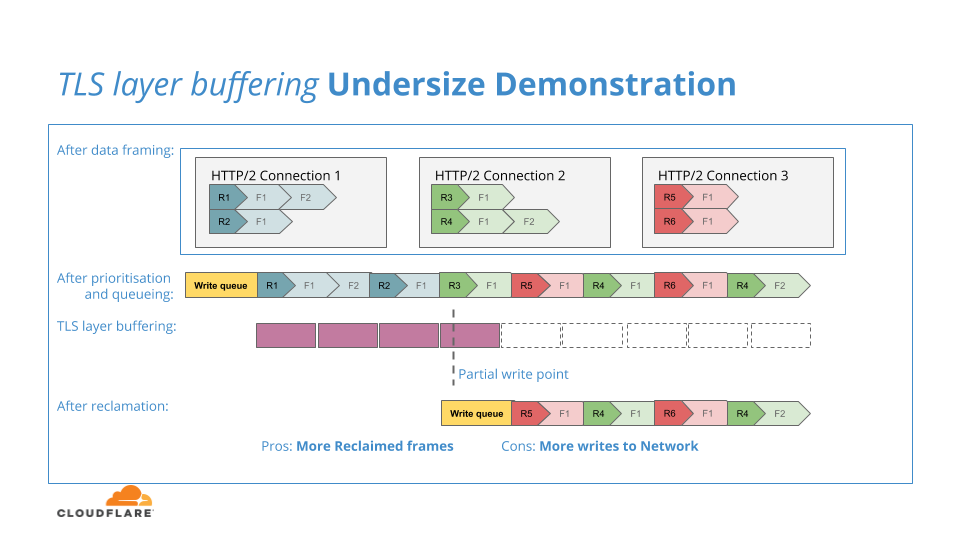
Si la mémoire tampon TLS est trop volumineuse, une quantité excessive de données HTTP/2 sera validée pour le chiffrement et, si elle échoue dans l’écriture sur le réseau en raison d'une contre-pression, elle sera verrouillé dans la couche TLS et ne pourra plus revenir à la couche HTTP/2 pour le processus de récupération, ce qui réduirait l'efficacité de la récupération. Le diagramme suivant illustre cette situation tampon trop volumineux :
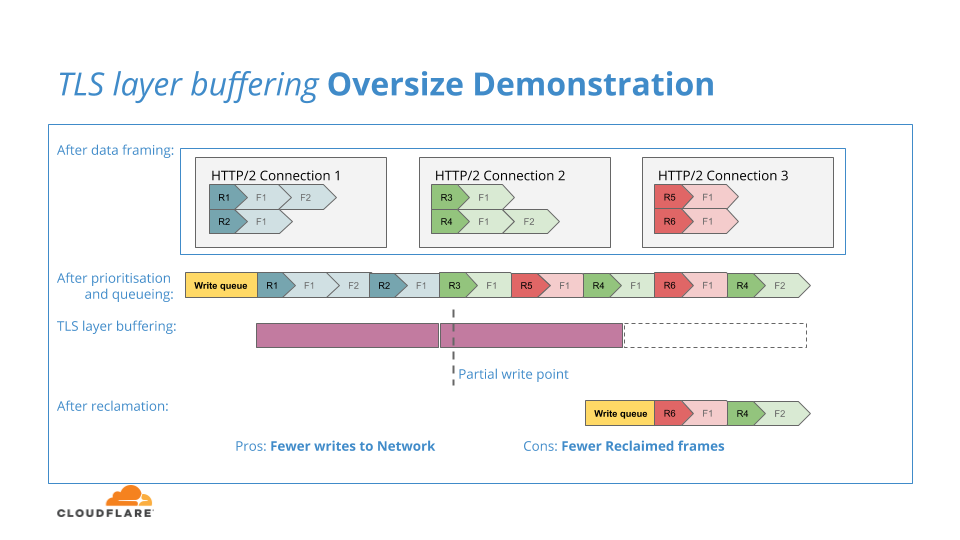
Dans les mois à venir, nous entamerons un processus visant à trouver l’emplacement « idéal » pour la mise en mémoire tampon TLS : pour dimensionner la mémoire tampon TLS, afin qu'elle soit suffisamment importante pour maintenir l'efficacité du cryptage et des écritures sur le réseau, sans toutefois réduire la réactivité face aux écritures réseau incomplètes et l'efficacité de la récupération.
Merci - La suite !
Le projet de hiérarchisation HTTP/2 améliorée a pour objectif ambitieux de repenser fondamentalement la façon dont nous acheminons le trafic de la périphérie Cloudflare aux clients. Comme le montrent les résultats de nos tests et les commentaires de certains de nos clients, nous y sommes certainement parvenus ! Toutefois, l’un des aspects les plus importants que nous ayons tiré du projet est le rôle essentiel que joue le flux de données interne au sein de notre infrastructure logicielle NGINX en prévision du trafic observé par nos utilisateurs finaux. Nous avons constaté que la modification de quelques lignes de code (bien que critique) pouvait avoir des conséquences importantes sur l'efficacité et les performances de nos algorithmes de hiérarchisation. Un autre résultat positif est qu'en plus d'améliorer HTTP/2, nous sommes impatients de mettre en œuvre nos nouvelles compétences et les leçons apprises et, les appliquer à HTTP/3 sur QUIC.
Nous sommes impatients de partager nos modifications à NGINX avec la communauté. Nous avons donc ouvert ce ticket par lequel nous discuterons en amont de réorganisations d’événements et du changement de réutilisation partielle de la mémoire tampon avec l’équipe de NGINX.
Alors que Cloudflare continue de croître, nos exigences en matière d'infrastructure logicielle changent également. Cloudflare a déjà dépassé le proxy de HTTP/1 sur TCP pour prendre en charge la terminaison et la protection des couches 3 et 4 pour tous les trafics UDP et TCP. Nous passons maintenant à d’autres technologies et protocoles, tels que QUIC et HTTP/3 et à la procuration complète d’un large éventail d’autres protocoles, tels que la messagerie et la diffusion en continu.
Aux fins de ces efforts, nous examinons de nouvelles manières de répondre aux questions sur des sujets tels que : l’évolutivité, les performances localisées, les performances à grande échelle, l’introspection et le débogage, l’agilité de publication et la maintenabilité.
Vous souhaitez nous aider à répondre à ces questions et en savoir un peu plus sur l'évolutivité matérielle et logicielle, la programmation réseau, les événements asynchrones et la conception futuriste de logicielles, les protocoles TCP, TLS, QUIC, HTTP, RPC, Rust ou peut-être autre chose ? Rendez-vous ici.