
En interne, notre équipe d’atténuation des attaques DDoS est parfois appelée « les supprimeurs de paquets ». Tandis que d’autres équipes créent des produits passionnants permettant de gérer intelligemment le trafic transitant par notre réseau, nous prenons plaisir à découvrir de nouvelles façons de le supprimer.

Il est très important de pouvoir éliminer rapidement les paquets pour résister aux attaques DDoS.
Supprimer des paquets sur nos serveurs, aussi simple que cela puisse paraître, peut être fait sur plusieurs couches. Chaque technique a ses avantages et ses limites. Dans cet article de blog, nous examinerons toutes les techniques que nous avons essayées jusqu'à présent.
Banc d'essai
Pour illustrer la performance propre à chaque méthode, nous allons présenter quelques chiffres. Les benchmarks sont synthétiques, alors prenez les chiffres avec des pincettes. Nous utiliserons l'un de nos serveurs Intel, avec une carte réseau de 10 Gbps. Les détails du matériel ne sont pas trop importants, car les tests sont préparés pour montrer les limites du système d'exploitation, et non celles du matériel.
Notre configuration de test est préparée comme suit :
- Nous transmettons un grand nombre de minuscules paquets UDP, atteignant 14 Mpps (millions de paquets par seconde).
- Ce trafic est dirigé vers un seul processeur sur un serveur cible.
- Nous mesurons le nombre de paquets traités par le noyau de ce processeur.
Nous n'essayons pas de maximiser la vitesse des applications utilisateur, ou le débit des paquets. Nous essayons plutôt de montrer spécifiquement les goulots d'étranglement du noyau.
Le trafic synthétique est préparé pour exercer une contrainte maximale sur conntrack. Il utilise des champs d'adresse IP et de port sources aléatoires. Tcpdump va le présenter comme ceci :
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16Du côté cible, tous les paquets vont être transférés dans une seule file d'attente RX, donc un processeur. Nous réalisons cela avec une direction de flux de matériel :
ethtool -N type de flux ext0 udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
L'analyse comparative est toujours difficile. Lors de la préparation des tests, nous avons appris qu’avoir des sockets raw actives réduisait les performances. C'est évident avec le recul, mais facile à rater. Avant d'exécuter des tests, assurez-vous de ne pas avoir de processus tcpdump obsolète en cours d'exécution. Voici comment le vérifier, en montrant un mauvais processus actif :
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))Enfin, nous allons désactiver la fonctionnalité Intel Turbo Boost sur la machine :
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Bien que Turbo Boost soit agréable et augmente le débit d'au moins 20 %, il aggrave également l'écart-type de nos tests de manière considérable. Avec le turbo activé, nous avions un écart de ± 1,5 % dans nos chiffres. Avec la désactivation de Turbo, ce pourcentage tombe à 0,25 %.
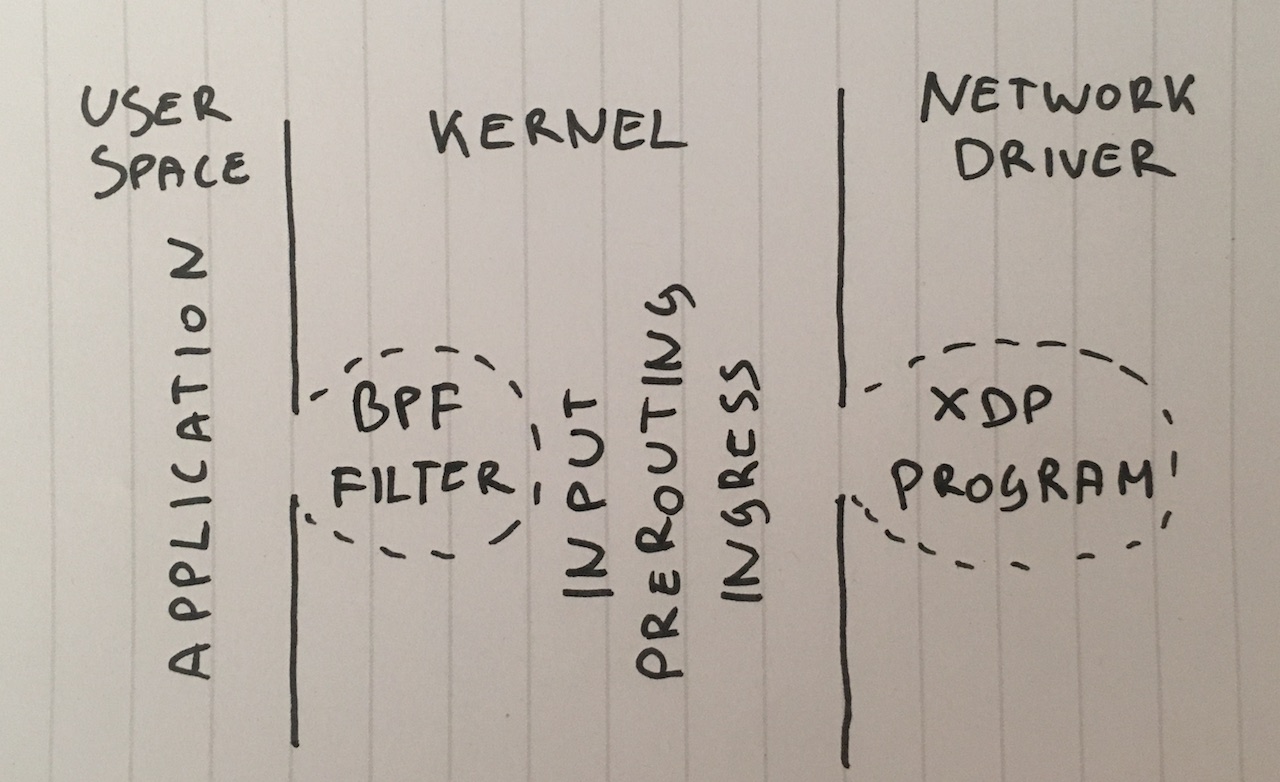
Étape 1. Supprimer les paquets dans l’application
Commençons par l’idée de livrer des paquets à une application et de les ignorer dans le code de l’espace utilisateur. Pour la configuration du test, assurons-nous que nos iptables n’affectent pas les performances :
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
Le code de l'application est une boucle simple, recevant des données et les renvoyant immédiatement dans l'espace utilisateur :
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])Nous avons préparé le code, pour l'exécuter :
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176Cette configuration permet au noyau de recevoir un maigre 175kpps de la file d'attente de réception matérielle, mesuré par ethtool et à l'aide de notre simple outil mmwatch :
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/sTechniquement, le matériel reçoit 14 Mpps du câble, mais il est impossible de tout transférer à une seule file d'attente RX gérée par un seul cœur de processeur effectuant le travail du noyau. mpstat confirme ceci :
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Comme vous pouvez le constater, le code de l'application n'est pas un goulot d'étranglement, utilisant 27 % sys + 2 % d'espace utilisateur sur le processeur n° 1, tandis que le réseau SOFTIRQ sur le processeur n° 2 utilise 100 % des ressources.
À propos, recvmmsg (2) est important. En ces jours post-spectres, les appels système sont devenus plus chers. En effet, nous exécutons le noyau 4.14 avec KPTI et les « retpolines » :
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FWÉtape 2. Conntrack d'abattage
Nous avons spécialement conçu le test en choisissant une adresse IP et des ports sources aléatoires pour appliquer des contraintes à la couche conntrack. Ceci peut être vérifié en regardant le nombre d'entrées conntrack, qui pendant le test atteint le maximum :
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152Vous pouvez également observer conntrack crier dansdmesg :
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
Pour accélérer nos tests, désactivons-le :
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Et recommencez les tests :
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128Cela augmente instantanément les performances de réception de l’application à 333kpps. Youpi !
PS. Avec SO_BUSY_POLL, nous pouvons ramener les nombres à 470 kpps, mais réservons ce sujet pour une autre fois.
Étape 3. Suppression BPF sur une socket
De plus, quelle peut bien être l’utilité livrer des paquets à une application utilisateur ? Même si cette technique est rare, nous pouvons rattacher un filtre BPF classique à un socket SOCK_DGRAM avec setsockopt ( SO_ATTACH_FILTER ) et programmer le filtre pour éliminer les paquets dans l’espace noyau.
Voir le code, pour l'exécuter :
$ ./bpf-drop
packets=0 bytes=0Avec des suppressions BPF (l’eBPF classique et étendu ont des performances similaires), nous traitons environ 512 kpps. Tous sont supprimés dans le filtre BPF en mode d'interruption logicielle, ce qui nous évite le processeur nécessaire pour réactiver l'application utilisateur.
Étape 4. SUPPRESSION iptables après routage
Dans une prochaine étape, nous pouvons simplement supprimer des paquets dans la chaîne INPUT du pare-feu iptables en ajoutant une règle comme celle-ci :
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Rappelez-vous que nous avons déjà désactivé conntrack avec -j NOTRACK. Ces deux règles nous donnent 608 kpps.
Les chiffres dans les compteurs iptables :
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
600kpps n'est pas mal, mais nous pouvons faire mieux !
Étape 5. SUPPRESSION iptables dans PREROUTING
Une technique encore plus rapide consiste à supprimer les paquets avant qu'ils ne soient routés. Cette règle peut faire ceci :
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j SUPPRESSION
Cela produit 1,688 mpps (énorme).
Il s’agit d’un saut de performance assez important et je ne le comprends pas bien. Soit notre couche de routage est inhabituellement complexe, soit il y a un bogue dans la configuration de notre serveur.
Dans tous les cas, la table iptables « raw » est nettement plus rapide.
Étape 6. SUPPRESSION nftables avant CONNTRACK
Iptables est considéré comme dépassé de nos jours. Le nouveau gamin en ville est nftables. Regardez cette vidéo pour une explication technique de la supériorité de nftables. Nftables promet d’être plus rapide que iptables aux cheveux grisonnants pour de nombreuses raisons, notamment une rumeur selon laquelle les retpolines (c'est-à-dire pas de spéculation sur les sauts indirects) perturbent sérieusement iptables.
Comme cet article ne compare pas la vitesse de nftables à celle d'iptables, essayons uniquement la suppression la plus rapide que j'ai pu trouver :
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Les compteurs peuvent être vus avec cette commande :
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}rendements de crochet d’« entrée » Nftables autour de 1,53 mpps. Ceci est légèrement plus lent que iptables dans la couche PREROUTING. Ce constat a de quoi surprendre. En théorie, l’« entrée » se produit avant le PREROUTING, elle devrait donc être plus rapide.
Dans notre test, nftables était légèrement plus lent que iptables, mais pas beaucoup. Nftables est toujours mieux :P
Étape 7. SUPPRESSION du gestionnaire d’entrée tc
Un fait quelque peu surprenant est qu’un raccordement d’entrée tc (contrôle de trafic) se produit avant même le PREROUTING. Avec tc, il est possible de sélectionner des paquets en fonction des critères de base et les supprimer effectivement. La syntaxe est plutôt difficile. Il est donc recommandé d'utiliser ce script pour le configurer. Nous avons besoin d'une correspondance de tc un peu plus complexe. Voici la ligne de commande :
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Nous pouvons le vérifier :
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
Un crochet d’entrée tc avec correspondance de u32 nous permet de supprimer 1,8 ppm sur un seul processeur. C'est génial !
Mais nous pouvons aller encore plus vite...
Étape 8. XDP_DROP
Enfin, l'arme ultime est XDP - eXpress Data Path. Avec XDP, nous pouvons exécuter le code eBPF dans le contexte d’un pilote réseau. Plus important encore, ceci est avant l’attribution de la mémoire skbuff, ce qui permet de grandes vitesses.
Habituellement, les projets XDP ont deux parties :
- le code eBPF chargé dans le contexte du noyau
- le chargeur d'espace utilisateur, qui charge le code sur la bonne carte réseau et le gère
L'écriture du chargeur est assez difficile. Nous pouvons donc plutôt utiliser la nouvellefonctionnalitéiproute2 et charger le code avec cette commande triviale :
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Tadam !
Le code source du programme eBPF XDP chargé est disponible ici. Le programme analyse les paquets IP et recherche les caractéristiques souhaitées : Transport IP, protocole UDP, sous-réseau cible et port de destination souhaités :
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}Le programme XDP doit être compilé avec un « clang » moderne pouvant émettre le bytecode BPF. Après cela, nous pouvons charger et vérifier le programme XDP en cours d’exécution :
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
Et voyez les chiffres dans les statistiques de la carte réseau ethtool -S :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
Whooa ! Avec XDP, nous pouvons supprimer 10 millions de paquets par seconde sur un seul processeur.

Résumé
Nous les avons répété pour IPv4 et IPv6 et avons préparé ce tableau :
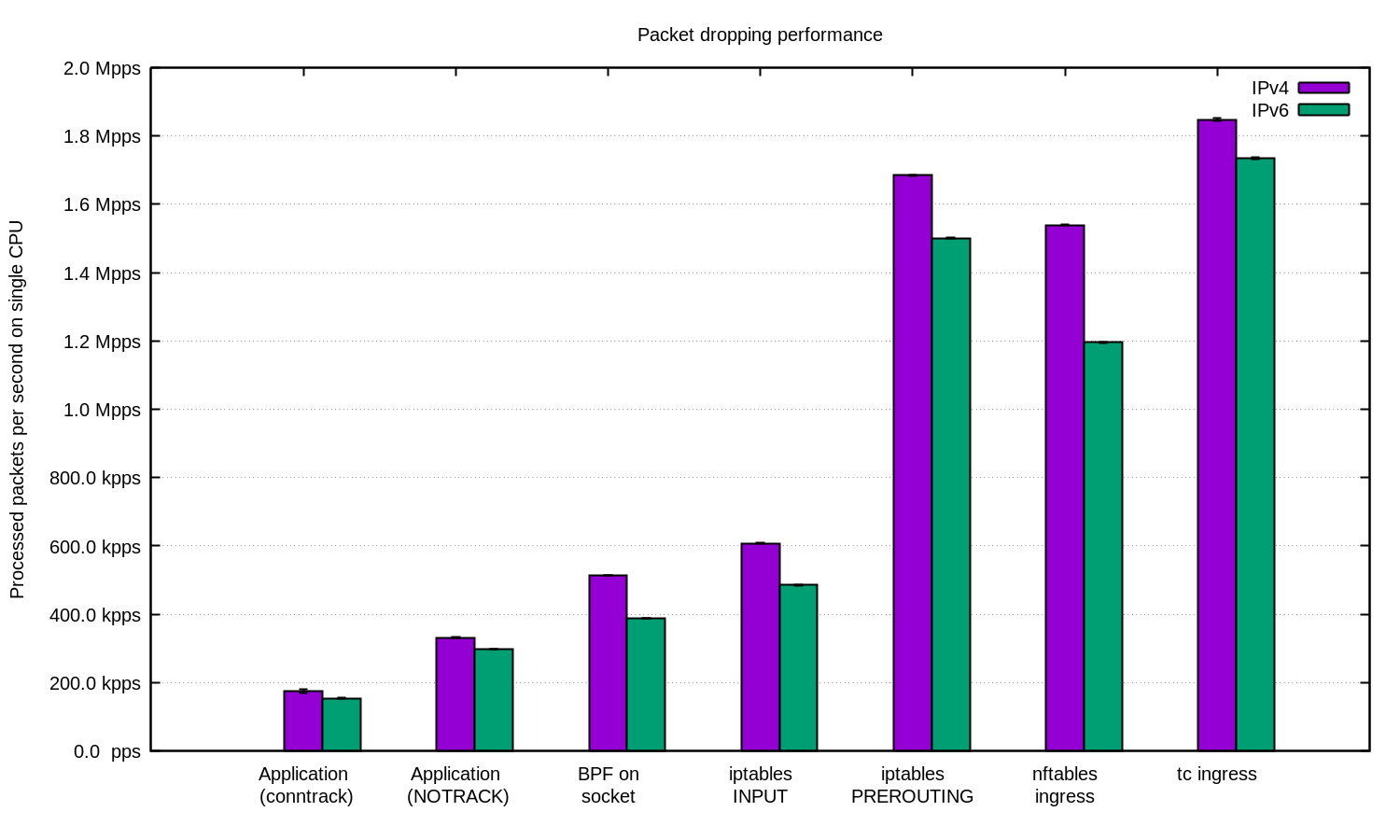
De manière générale, dans notre configuration, IPv6 présentait des performances légèrement inférieures. N'oubliez pas que les paquets IPv6 sont légèrement plus volumineux. Par conséquent, une certaine différence de performances est inévitable.
Linux possède de nombreux crochets qui peuvent être utilisés pour filtrer les paquets, chacun avec des performances et des caractéristiques de facilité d'utilisation différentes.
Pour ce qui est de DDoS, il peut être parfaitement raisonnable de simplement recevoir les paquets dans l'application et de les traiter dans l'espace utilisateur. Des applications correctement réglées peuvent obtenir des chiffres assez satisfaisants.
Pour les attaques DDoS avec des adresses IP source aléatoires/ usurpées, il peut être rentable de désactiver conntrack pour gagner un peu de vitesse. Attention toutefois : il existe des attaques pour lesquelles conntrack est très utile.
Dans d'autres circonstances, il peut être judicieux d'intégrer le pare-feu Linux à la chaîne d'atténuation des attaques DDoS. Dans ces cas-là, n'oubliez pas de placer les atténuations dans une couche « -t raw PREROUTING », car elle est nettement plus rapide que la table « filtre ».
Pour des charges de travail encore plus exigeantes, nous avons toujours XDP. Et dieu que c'est puissant ! Voici le même tableau que ci-dessus, mais avec XDP :
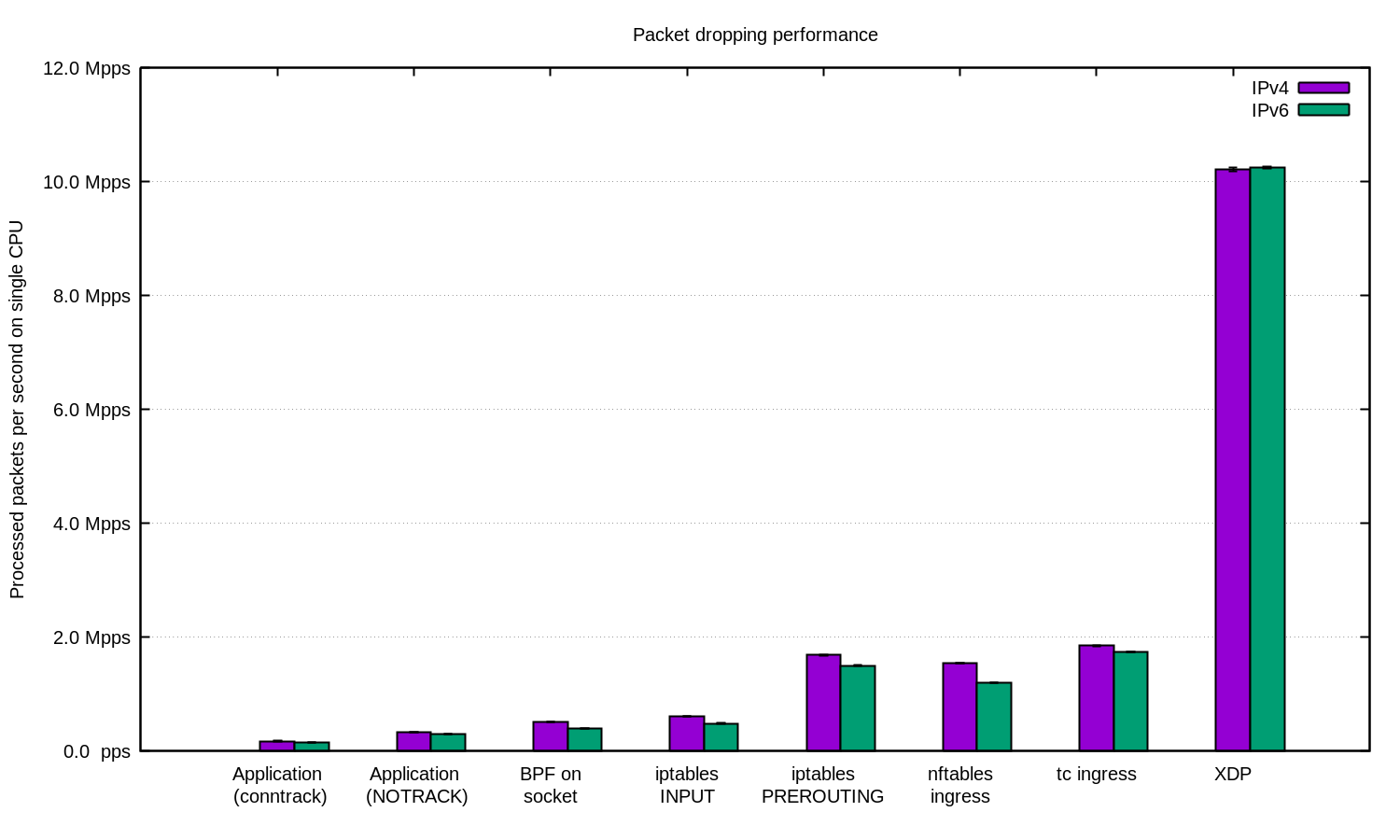
Si vous souhaitez reproduire ces chiffres, consultez le fichier README où nous avons tout documenté.
Ici, chez Cloudflare, nous utilisons... presque toutes ces techniques. Certaines astuces de l’espace utilisateur sont intégrées à nos applications. La couche iptables est gérée par notre pipeline Gatebot DDoS. Enfin, nous travaillons au remplacement de notre solution propriétaire de déchargement de noyau par XDP.
Vous voulez nous aider à supprimer plus de paquets ? Nous recrutons pour de nombreux postes, y compris des supprimeurs de paquets, des ingénieurs systèmes et plus encore !
J’aimerais adresser un remerciement spécial à Jesper Dangaard Brouer pour sa contribution à ce travail.