

Lors de ma récente visite au musée de l'histoire de l'ordinateur de Mountain View, je me suis retrouvé devant une section d'une mémoire à tores magnétiques.

Je me suis vite rendu compte que je n'avais absolument aucune idée de la manière dont ces objets pouvaient bien fonctionner. Je me suis demandé si les anneaux tournaient (ce n’est pas le cas), et pourquoi chacun d'entre eux était traversé par trois fils tressés (et je n'ai toujours pas compris exactement comment ceux-ci fonctionnent). De plus, je me suis rendu compte que je comprenais très mal comment fonctionne la mémoire vive dynamique qui équipe les ordinateurs modernes !
J'ai été particulièrement intéressé par l'une des conséquences du fonctionnement de la mémoire vive dynamique. En fait, chaque bit de données est stocké par la charge (ou l'absence de charge) sur un minuscule condensateur dans la puce RAM. Mais ces condensateurs perdent progressivement leur charge au fil du temps. Pour éviter de perdre les données stockées, elles doivent être régulièrement rafraîchies pour rétablir la charge ( si elle est présente) à son niveau initial. Ce procédé de rafraîchissement nécessite la lecture de la valeur de chaque bit et sa réécriture . Lors de cette opération de « rafraîchissement », la mémoire est occupée et ne peut effectuer des opérations normales comme le chargement ou le stockage de bits.
J'y pense depuis un bon moment et je me suis demandé... est-il possible de ressentir ce délai de rafraîchissement dans les logiciels ?
Principe de rafraîchissement de la mémoire vive dynamique
Chaque unité de DIMM est composée de « cellules » et de « lignes», de « colonnes », de « côtés » et/ou de « rangées ». Cette présentation de l’Université de l’Utah, explique la nomenclature. Vous pouvez vérifier la configuration de la mémoire dans votre ordinateur avec la commande decode-dimms. Voici un exemple :
$ decode-dimms
Size 4096 MB
Banks x Rows x Columns x Bits 8 x 15 x 10 x 64
Ranks 2
Pour le moment, nous n'avons pas besoin de comprendre toute la structure de la mémoire DDR DIMM, nous avons juste besoin de comprendre le fonctionnement d'une seule cellule mémoire qui stocke un bit de données. Concrètement, seul le processus de rafraîchissement nous intéresse.
Nous allons examiner deux articles :
- Tutoriel sur le rafraîchissement de la DRAM, de l'Université de l'Utah
- Et un excellent document sur la cellule de 1 gigabit par micron : TN-46-09 Conception pour une mémoire SDRAM DDR de 1 Go
En général, chaque bit stocké dans la mémoire dynamique doit être rafraîchi, toutes les 64 ms (rafraîchissement statique). Il s’agit d’une opération assez coûteuse. Pour éviter une interruption importante toutes les 64 ms, ce processus est divisé en 8192 petites opérations de rafraîchissement. A chaque opération, le contrôleur de mémoire de l'ordinateur envoie des commandes de rafraîchissement aux puces DRAM. Après avoir reçu l'instruction, une puce rafraîchit 1/8192 de ses cellules. Calcul : 64 ms / 8192 = 7812,5 ns ou 7.81 μs. Cela signifie :
- qu'une instruction de rafraîchissement est envoyée toutes les 7812,5 ns. C’est ce qu’on appelle tREFI.
- Il faut un certain temps pour que la puce effectue le rafraîchissement et récupère pour qu'elle puisse effectuer à nouveau des opérations normales de lecture et d'écriture. Cette période, appelée RFCt, est de 75 ns ou 120 ns (selon la fiche technique de Micron).
Lorsque la mémoire atteint une certaine température (> 85° C), la durée de rétention de la mémoire diminue et la durée de rafraîchissement statique tombe à 32 ms, et le tREFI à 3906,25 ns.
Une puce de mémoire standard est occupée par des rafraîchissements pendant une fraction significative de son temps de fonctionnement (entre 0,4 % et 5 %). De plus, les puces de mémoire représentent une part non négligeable de la consommation d'énergie d'un ordinateur, et une grande partie de cette énergie sert à effectuer les rafraîchissements.
Pendant la durée du rafraîchissement, toute la puce de mémoire est bloquée. Cela signifie que toutes les 7812 ns, chaque bit en mémoire est bloqué pendant plus de 75 ns. Effectuons cette mesure.
Préparons notre expérience
Pour mesurer les opérations avec une granularité de l'ordre de la nanoseconde, nous devons écrire une boucle serrée, par exemple en C. Elle se présente comme suit :
for (i = 0; i < ...; i++) {
// Perform memory load. Any load instruction will do
*(volatile int *) one_global_var;
// Flush CPU cache. This is relatively slow
_mm_clflush(one_global_var);
// mfence is needed, otherwise sometimes the loop
// takes very short time (25ns instead of like 160). I
// blame reordering.
asm volatile("mfence");
// Measure and record time
clock_gettime(CLOCK_MONOTONIC, &ts);
}
Le code complet est disponible sur Github.
Le code est vraiment simple. Effectuer une lecture de mémoire. Vider les données des caches CPU. Mesurer la durée.
(Remarque : Lors d’une deuxième expérience, j'ai essayé d'utiliser MOVNTDQA pour effectuer la charge de données, mais cela nécessite une page spéciale de mémoire qui ne peut être mise en cache, qui nécessite un accès root.)
Sur mon ordinateur, les données sont générées comme suit :
# timestamp, loop duration
3101895733, 134
3101895865, 132
3101896002, 137
3101896134, 132
3101896268, 134
3101896403, 135
3101896762, 359
3101896901, 139
3101897038, 137
J'obtiens en général ~ 140 ns par boucle, et la durée de la boucle saute de temps en temps à ~ 360 ns. Parfois, j'obtiens des mesures étranges supérieurs à 3200 ns.
Malheureusement, les données se révèlent très excessives. Il est très difficile de voir s'il y a un retard notable lié aux cycles de rafraîchissement.
Transformation rapide de Fourier
J'ai fini par avoir un déclic. Étant donné que l'on recherche un événement à intervalle fixe, il est possible d'introduire les données dans l'algorithme FFT (transformation rapide de Fourier), qui déchiffre les fréquences sous-jacentes.
Je ne suis pas le premier à avoir cette idée : Mark Seaborn de Rowhammer a appliqué cette technique en 2015. Même après avoir jeté un coup d'œil au code de Mark, il m'a été plus difficile que prévu d'utiliser la FFT. Mais finalement, j'ai rassemblé toutes les pièces du puzzle.
Il faut d'abord préparer les données. La FFT nécessite que les données d'entrée soient échantillonnées à un intervalle constant. De plus, il faut aussi recadrer les données pour réduire le bruit. Par tâtonnements, j'ai constaté que les meilleurs résultats sont obtenus lorsque les données sont traitées en amont :
- Les petites valeurs (inférieures à la moyenne * 1,8) des boucles sont supprimées, ignorées et remplacées par des valeurs égales à « 0 ». Il ne faut surtout pas introduire de bruit dans l'algorithme.
- Toutes les mesures restantes sont remplacées par « 1 », car on ne se soucie pas vraiment de l'amplitude du retard causé par certains bruits.
- J'ai choisi un intervalle d'échantillonnage de 100 ns, mais n'importe quel nombre jusqu'à une valeur de Nyquist (double de la fréquence prévue) fonctionne également bien.
- Les données doivent être échantillonnées à des intervalles fixes avant d'être introduites dans la FFT. Toutes les méthodes d'échantillonnage raisonnables fonctionnent bien, j'ai fini par effectuer une interpolation linéaire de base.
L’algorithme est d’environ :
UNIT=100ns
A = [(timestamp, loop_duration),...]
p = 1
for curr_ts in frange(fist_ts, last_ts, UNIT):
while not(A[p-1].timestamp <= curr_ts < A[p].timestamp):
p += 1
v1 = 1 if avg*1.8 <= A[p-1].duration <= avg*4 else 0
v2 = 1 if avg*1.8 <= A[p].duration <= avg*4 else 0
v = estimate_linear(v1, v2, A[p-1].timestamp, curr_ts, A[p].timestamp)
B.append( v )
Ce qui, d'après mes données, produit un vecteur de ce type :
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
Cependant, le vecteur est assez long, environ 200 000 points de données. Les données ainsi préparées sont prêtes à être introduites dans la FFT !
C = numpy.fft.fft(B)
C = numpy.abs(C)
F = numpy.fft.fftfreq(len(B)) * (1000000000/UNIT)
Plutôt simple, n'est-ce pas ? Nous obtenons deux vecteurs :
- C contient les nombres complexes des composantes de fréquence. Nous ne sommes pas intéressés par les nombres complexes et nous pouvons les homogénéiser avec abs().
- F contient des balises indiquant la fréquence à laquelle la corbeille est située à un emplacement dans le vecteur C. Nous devons le normaliser en Hz en le multipliant par la fréquence d'échantillonnage du vecteur d'entrée.
Le résultat peut être représenté graphiquement :
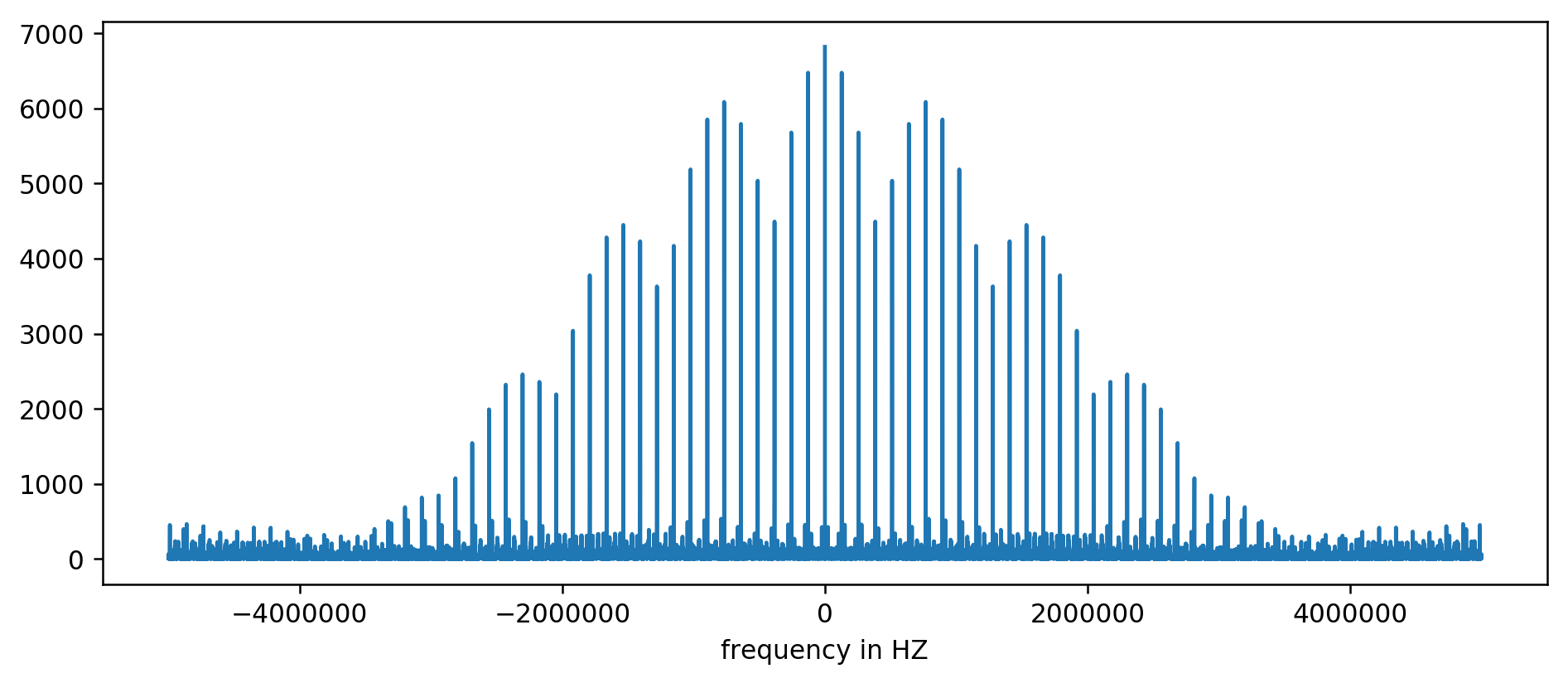
L'axe Y ne comporte pas d'unité puisque nous avons normalisé les temps de retard. Toutefois, il indique clairement des pics à certains intervalles de fréquence fixes. Effectuons un zoom avant :
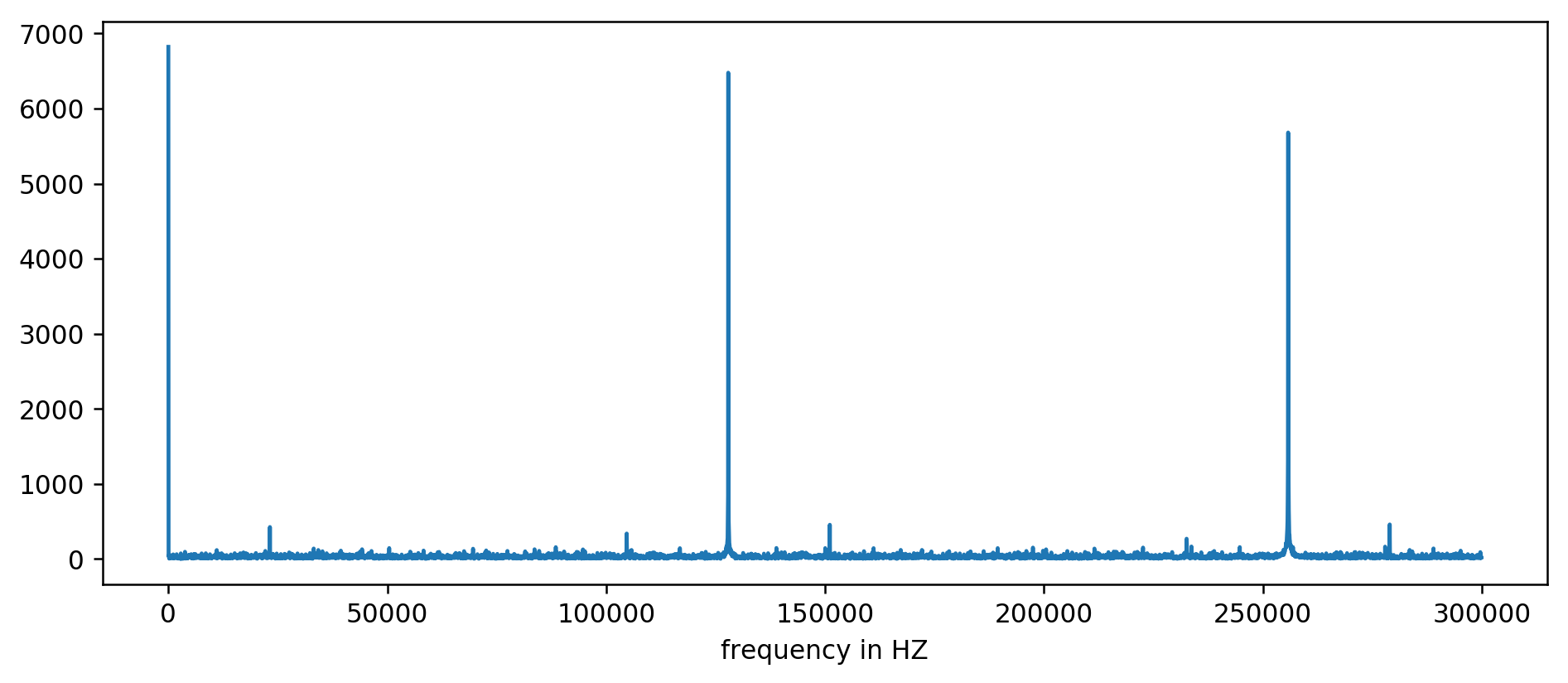
Nous pouvons clairement voir les trois premiers pics. Après un peu de calculs arithmétiques approximatifs qui impliquent de filtrer la valeur au moins 10 fois plus que la moyenne, nous pouvons extraire les fréquences sous-jacentes :
127850.0
127900.0
127950.0
255700.0
255750.0
255800.0
255850.0
255900.0
255950.0
383600.0
383650.0
Soit : 1000000000 (ns/s) / 127900 (Hz) = 7818,6 ns
Youpi ! Le premier pic de fréquence correspond bien à ce que nous recherchions, et il correspond bien aux durées de rafraîchissement.
Les autres pics à 256 kHz, 384 kHz, 512 kHz et ainsi de suite sont des multiples de notre fréquence de base de 128 kHz appelés harmoniques. Il s'agit d'un effet secondaire obtenu en effectuant une FFT sur une sorte d'onde carrée et il est tout à fait normal.
Pour faciliter l'expérimentation, nous avons préparé une version en ligne de commande de cet outil . Vous pouvez exécuter le code vous-même. Voici un exemple d’exécution sur mon serveur :
~/2018-11-memory-refresh$ make
gcc -msse4.1 -ggdb -O3 -Wall -Wextra measure-dram.c -o measure-dram
./measure-dram | python3 ./analyze-dram.py
[*] Verifying ASLR: main=0x555555554890 stack=0x7fffffefe2ec
[ ] Fun fact. I did 40663553 clock_gettime()'s per second
[*] Measuring MOVQ + CLFLUSH time. Running 131072 iterations.
[*] Writing out data
[*] Input data: min=117 avg=176 med=167 max=8172 items=131072
[*] Cutoff range 212-inf
[ ] 127849 items below cutoff, 0 items above cutoff, 3223 items non-zero
[*] Running FFT
[*] Top frequency above 2kHz below 250kHz has magnitude of 7716
[+] Top frequency spikes above 2kHZ are at:
127906Hz 7716
255813Hz 7947
383720Hz 7460
511626Hz 7141
Je dois admettre que le code n'est pas parfaitement stable. En cas de problème, pensez à désactiver le Turbo Boost, le réglage de la fréquence du processeur et le paramétrage des performances.
Conclusion
IOn peut tirer deux conclusions principales de cette analyse.
Nous avons constaté que les données de bas niveau sont assez difficiles à analyser et semblent être assez imprécises. Au lieu d'obtenir un résultat approximatif, nous pouvons recourir à la bonne vieille transformation rapide de Fourier. La préparation des données nécessite une certaine dose d'optimisme.
Plus important encore, nous avons montré qu'il est souvent possible de mesurer des comportements matériels complexes à partir d'un simple processus d'espace utilisateur. C’est ce genre de raisonnement qui a mené à la découverte de la vulnérabilitédu martèlement de mémoirequi a été utilisée lors des attaques Meltdown/Spectre et qui a de nouveau été mis en évidence lors de la récente réincarnation du martèlement de mémoire ayant mis à mal la mémoire à code correcteur d'erreur.
Il y a davantage à dire. Nous avons à peine abordé en surface le fonctionnement du sous-système mémoire. Je recommande ces lectures complémentaires :
- L3 cache mapping on Sandy Bridge CPUs
- How physical address maps to rows and banks in DRAM
- Hannu Hartikainen hacking DDR3 SO-DIMM to work... slower
Pour finir, voici un document de référence sur l'ancienne mémoire à tores magnétiques :