
Recientemente, en Netdev 0x13, la conferencia sobre Redes en Linux en Praga, di una breve charla titulada “Linux en Cloudflare”. La charla terminó siendo casi en su totalidad sobre el BPF. Parece que independientemente de la pregunta, el BPF es la respuesta.
Aquí presentamos una transcripción de una versión ligeramente adaptada de esa charla.
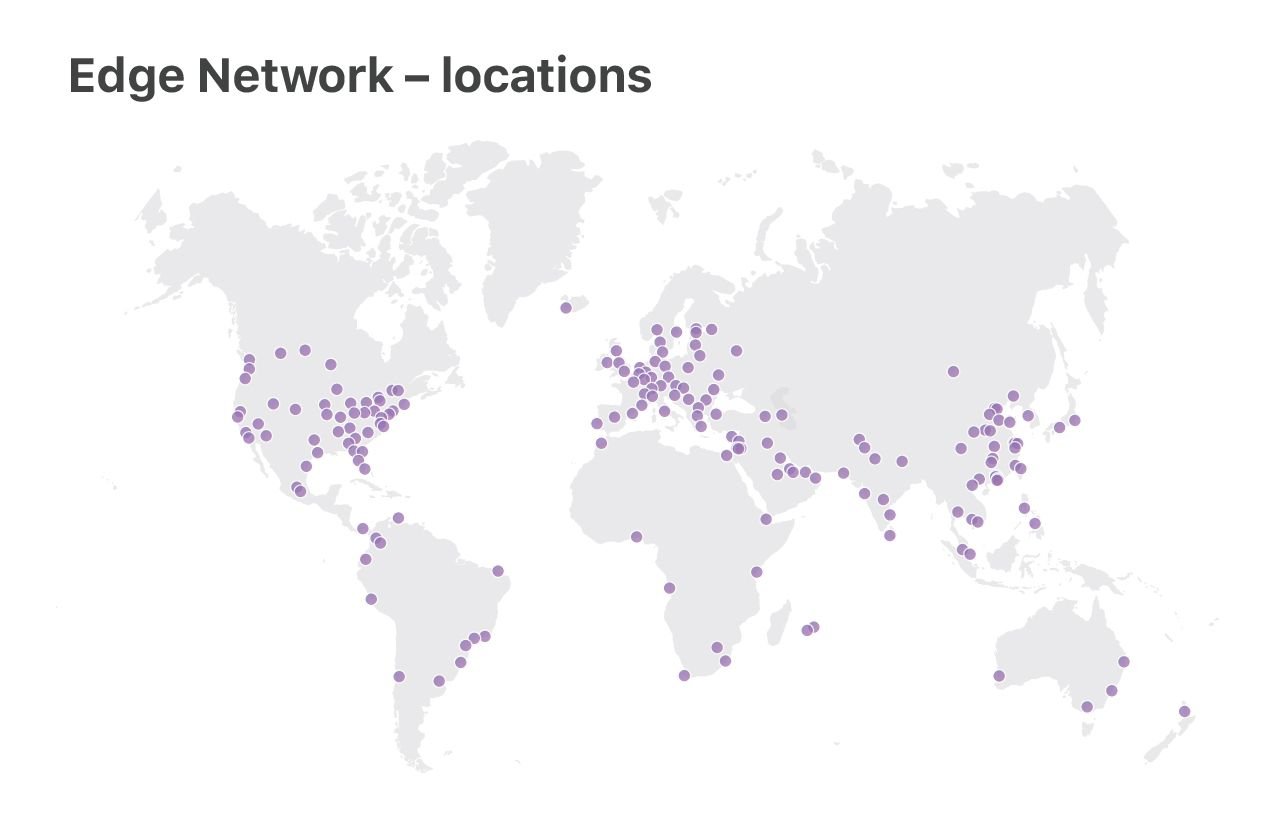
En Cloudflare, ejecutamos Linux en nuestros servidores. Operamos dos categorías de centros de datos: los centros de datos “básicos” grandes, donde procesamos registros, analizamos ataques y hacemos cálculos analíticos, y la flota de servidores “perimetrales”, que envían contenido de clientes desde 180 ubicaciones en todo el mundo.
En esta charla, nos concentraremos en los servidores “perimetrales”. Es aquí donde utilizamos las características más recientes de Linux, optimizamos el rendimiento y nos ocupamos en gran medida de la resiliencia del DoS.
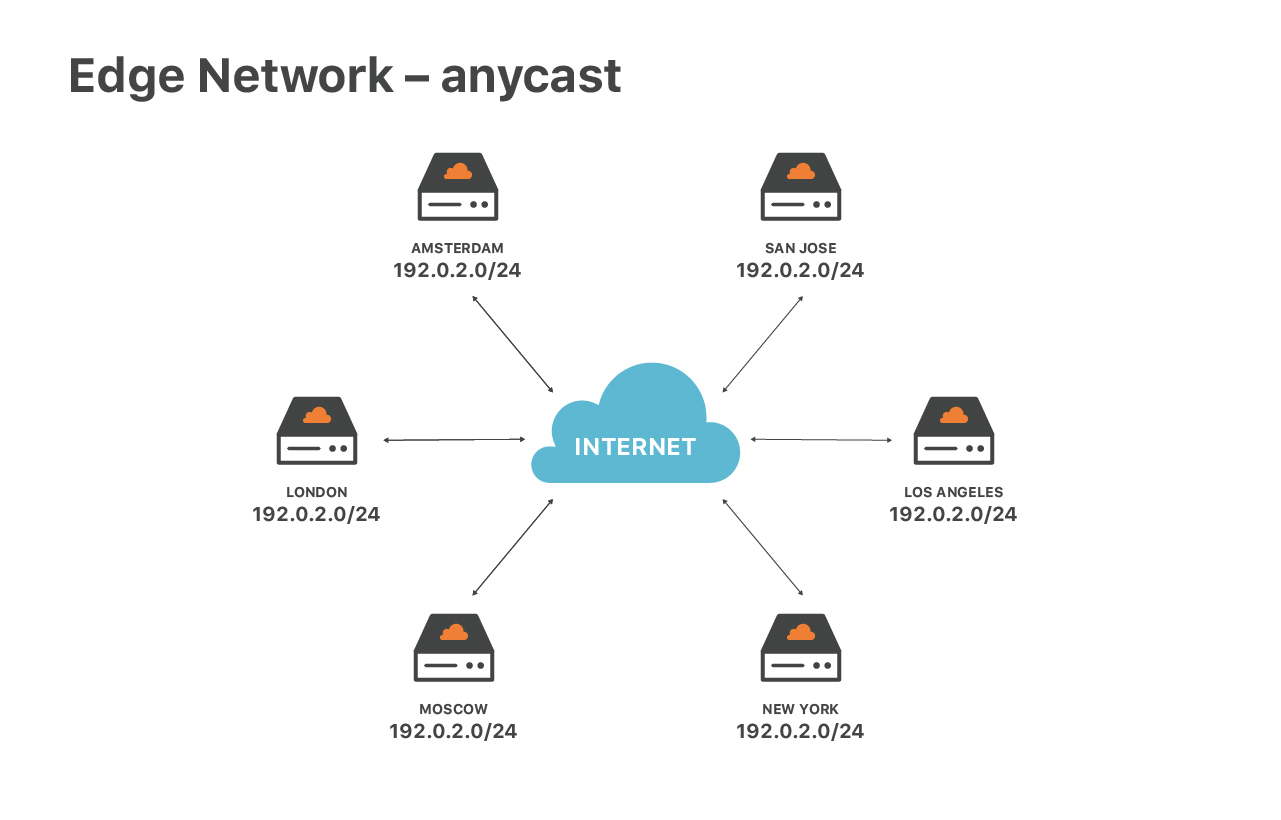
Nuestro servicio perimetral es especial debido a nuestra configuración de red, estamos utilizando ampliamente el enrutamiento anycast. Anycast significa que todos nuestros centros de datos anuncian la misma serie de direcciones IP.
Este diseño tiene enormes ventajas. En primer lugar, garantiza la velocidad óptima para los usuarios finales. Independientemente del lugar en que usted se encuentre, siempre llegará al centro de datos más cercano. Luego, anycast nos ayuda a extender el tráfico de DoS. Durante los ataques, cada una de las ubicaciones recibe una pequeña fracción del tráfico total, lo que facilita la asimilación y el filtrado del tráfico no deseado.
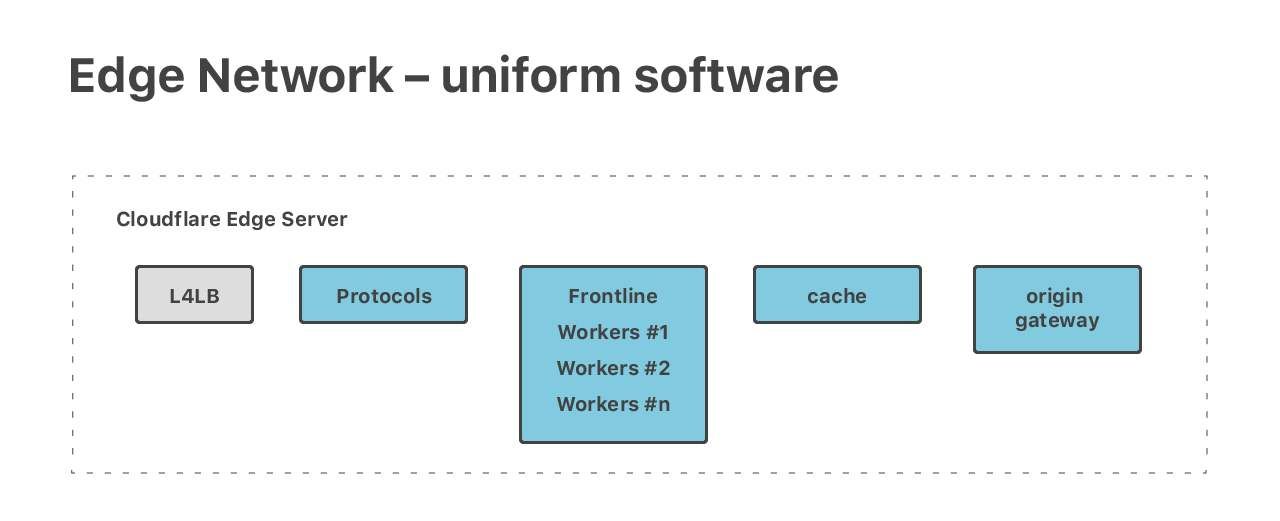
Anycast nos permite mantener la uniformidad de la configuración de red en todos los centros de datos perimetrales. Aplicamos el mismo diseño en nuestros centros de datos: nuestra pila de software es uniforme en todos los servidores perimetrales. Todas las piezas de software se ejecutan en todos los servidores.
En principio, cada equipo puede gestionar cada tarea, y nosotros ejecutamos una cantidad de tareas diversas y exigentes. Tenemos una pila HTTP completa, el mágico Cloudflare Workers, dos series de servidores DNS - autorización y resolución, y muchas otras aplicaciones públicas como Spectrum y Warp.
Si bien en cada servidor se está ejecutando todo el software, las solicitudes suelen pasar por muchas máquinas en su trayecto hacia la pila. Por ejemplo, una máquina diferente puede gestionar una solicitud HTTP durante cada una de las 5 etapas del procesamiento.
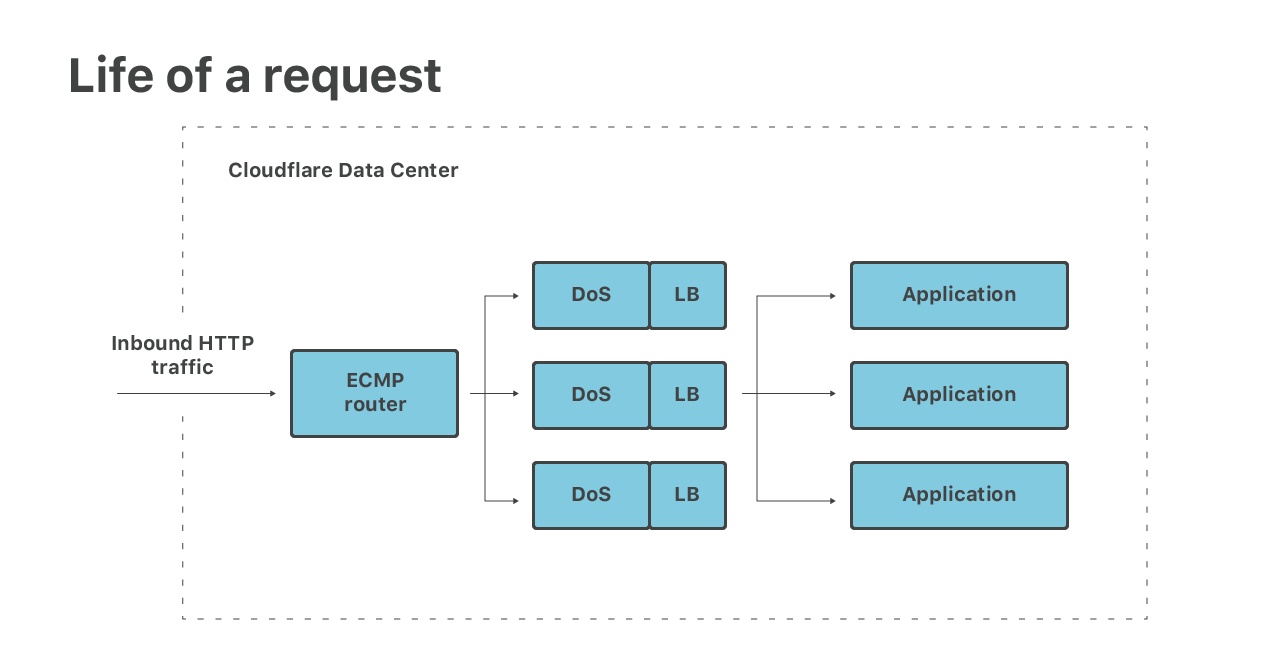
Permítanme guiarlos en las primeras etapas del procesamiento de paquetes entrantes:
(1) En primer lugar, los paquetes llegan a nuestro enrutador. El enrutador genera una multirruta de igual costo (ECMP) y reenvía los paquetes a nuestros servidores Linux. Utilizamos ECMP para distribuir cada IP de destino entre muchas máquinas, al menos 16. Esto se utiliza como una técnica rudimentaria de equilibrio de carga.
(2) En los servidores tomamos paquetes con eBPF de XDP. En XDP ejecutamos dos etapas. En primer lugar, ejecutamos mitigaciones de DoS volumétricas y eliminamos los paquetes que pertenecen a ataques muy grandes de la capa 3.
(3) Luego, aún en XDP, llevamos a cabo el equilibrio de carga de la capa 4. Todos los paquetes que no son de ataque se redirigen a través de los equipos. Esto se utiliza para solucionar los problemas de ECMP, nos da un equilibrio de carga de granularidad fina y nos permite sacar correctamente de servicio a los servidores.
(4) Después de la redirección, los paquetes llegan a un equipo designado. En este punto, la pila de redes de Linux normal los toma, pasan por el firewall de iptables habitual y se envían a un socket de red adecuado.
(5) Por último, una aplicación recibe los paquetes. Por ejemplo, las conexiones HTTP son manejadas por un servidor de “protocolo” encargado del cifrado TLS y el procesamiento de los protocolos HTTP, HTTP/2 y QUIC.
Es en estas primeras fases de procesamiento de solicitudes donde utilizamos las características nuevas más interesantes de Linux. Podemos agrupar las funciones modernas útiles en tres categorías:
- Control de DoS
- Equilibrio de carga
- Envío de sockets
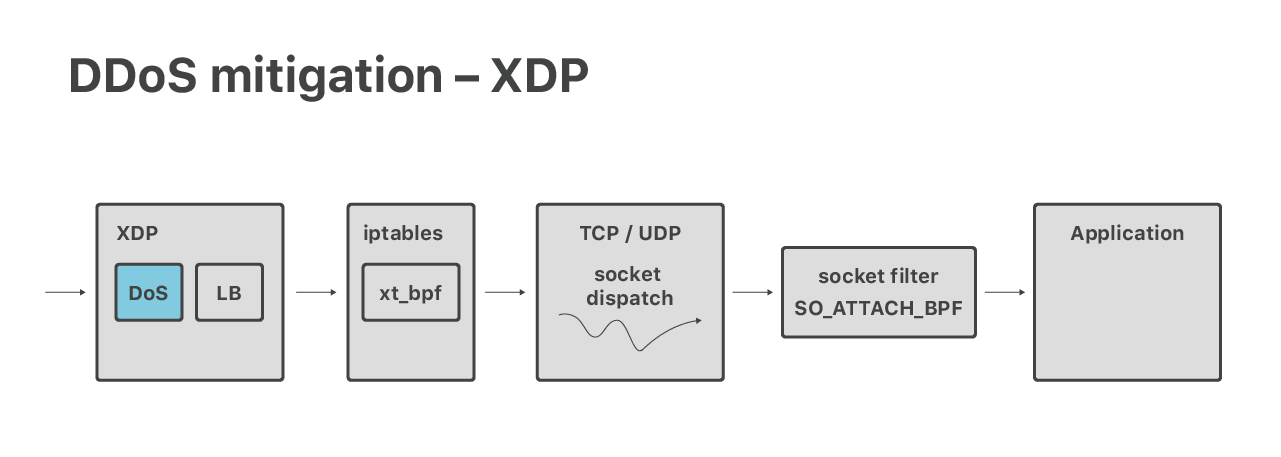
Analicemos el control de DoS en más detalle. Como se mencionó anteriormente, el primer paso después del enrutamiento ECMP es la pila XDP de Linux donde, entre otras cosas, ejecutamos mitigaciones de DoS.
Históricamente, nuestras mitigaciones de ataques volumétricos se expresaban en la gramática clásica de estilo de iptables y BPF. Recientemente, hicimos una adaptación para ejecutar en el contexto de eBPF de XDP, lo que resultó ser increíblemente difícil. Siga leyendo sobre nuestras experiencias:
- L4Drop: Mitigaciones de DDoS XDP
- xdpcap: Captura de paquetes XDP
- Charla de mitigación de DoS en función de XDP de Arthur Fabre
- XDP en la práctica: integración de XDP en nuestra canalización de mitigación de DDoS(PDF)
Durante este proyecto nos encontramos con una serie de limitaciones de eBPF/XDP. Una de ellas fue la falta de primitivas de concurrencia. Resultó muy difícil implementar cosas como algoritmos token buckets sin competencia. Más tarde, descubrimos que la ingeniera de Facebook Julia Kartseva tenía los mismos problemas. En febrero, este problema se solucionó con la introducción de la aplicación auxiliar bpf_spin_lock.
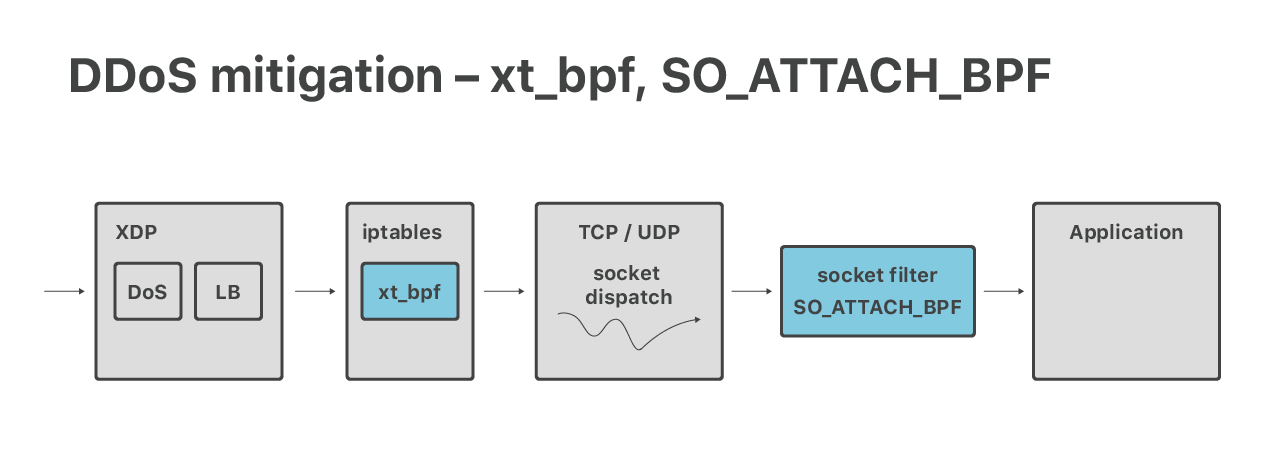
Si bien nuestros modernos sistemas de defensa de ataques DoS volumétricos se hacen en la capa XDP, aún contamos con iptables para aplicar las mitigaciones de la capa 7. Aquí, resultan útiles las características de un firewall de nivel superior: connlimit, hashlimits e ipsets. También utilizamos el módulo de iptables xt_bpf para ejecutar cBPF en iptables que coincidan con las cargas útiles del paquete. Ya hablamos de esto antes:
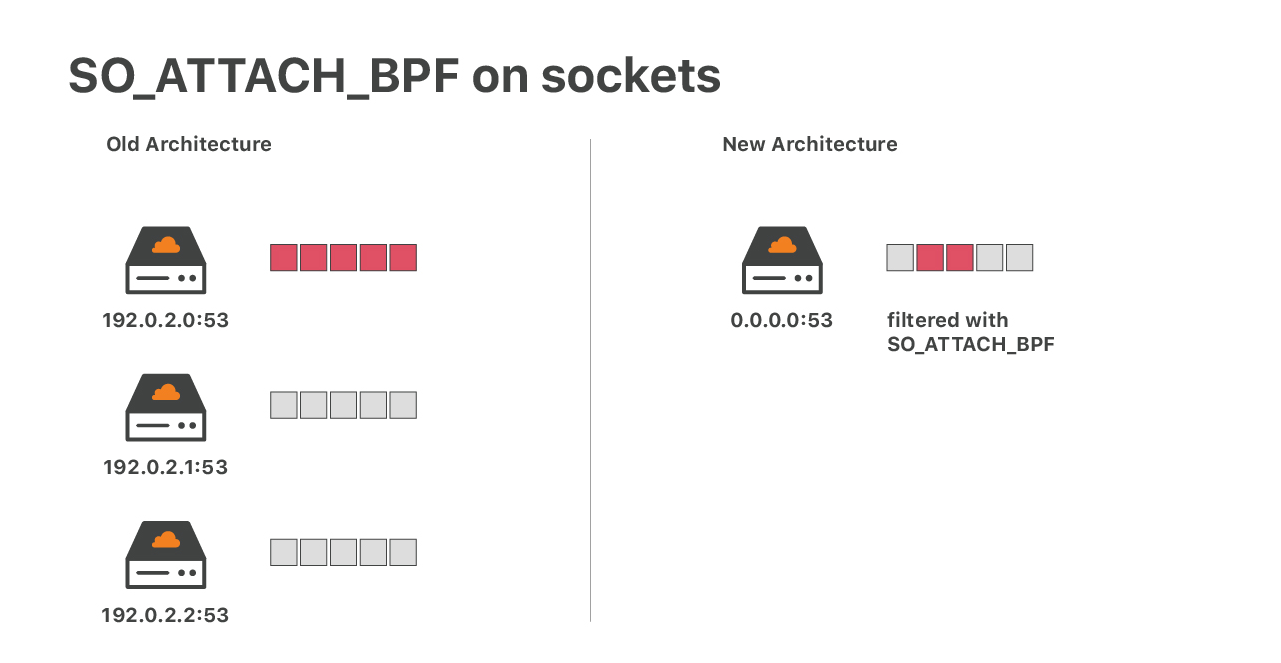
Después de XDP e iptables, tenemos una última capa de defensa DoS del lado del núcleo.
Considere una situación en la que fallan nuestras mitigaciones del protocolo de datagramas de usuarios (UDP). En tal caso, podríamos recibir una avalancha de paquetes que llegan a al socket de UDP de nuestra aplicación. Esto podría desbordar el socket y generar la pérdida de paquetes. Esto es un problema, ya que se eliminarán indiscriminadamente tanto los paquetes buenos como los malos. Para aplicaciones como DNS esto resulta catastrófico. En el pasado, para reducir el daño ejecutamos un socket de UDP por dirección IP. Una inundación sin mitigar era algo malo, pero al menos no afectaba el tráfico a otras direcciones IP del servidor.
En la actualidad, esa estructura ya no resulta adecuada. Estamos ejecutando más de 30 000 IP DNS, y la ejecución de esa cantidad de sockets UDP no es una situación óptima. Nuestra solución actual es la ejecución de un único socket UDP con un filtro de socket eBPF complejo - utilizando la opción de socket SO_ATTACH_BPF. En publicaciones anteriores, hablamos sobre la ejecución de eBPF en sockets de red:
- eBPF, sockets, distancia de salto y escritura manual de ensamblado de eBPF
- SOCKMAP - Empalme de TCP del futuro
El tipo de eBPF mencionado limita los paquetes. Mantiene el estado - recuento de paquetes - en un mapa de eBPF. Estamos seguros de que una sola IP inundada no afectará al resto del tráfico. Esto funciona bien, sin embargo, mientras trabajábamos en este proyecto encontramos un error bastante preocupante en el verificador de eBPF:
Supongo que ejecutar eBPF en un socket UDP no es una tarea común.
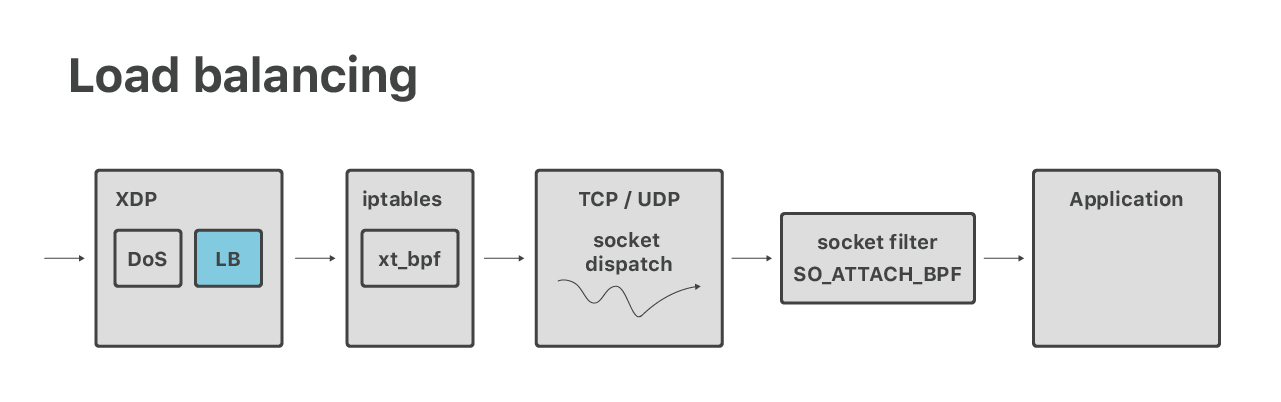
Aparte del DoS, en XDP también ejecutamos un equilibrador de carga de capa 4. Este es un proyecto nuevo, y aún no hemos hablado mucho de este. Sin entrar en tantos detalles: en ciertas ocasiones, necesitamos hacer una búsqueda de socket desde XDP.
El problema es relativamente simple - nuestro código necesita buscar la estructura del núcleo del “socket” para una tupla-5 extraída de un paquete. Por lo general, esto es fácil - hay una asistencia bpf_sk_lookup disponible para esto. Como era de esperar, hubo algunas complicaciones. Un problema fue la incapacidad de verificar si un paquete ACK recibido era una parte válida del protocolo de enlace de tres vías cuando se activan las cookies SYN. Mi colega Lorenz Bauer está trabajando para lograr más apoyo para este caso fuera de lo habitual.
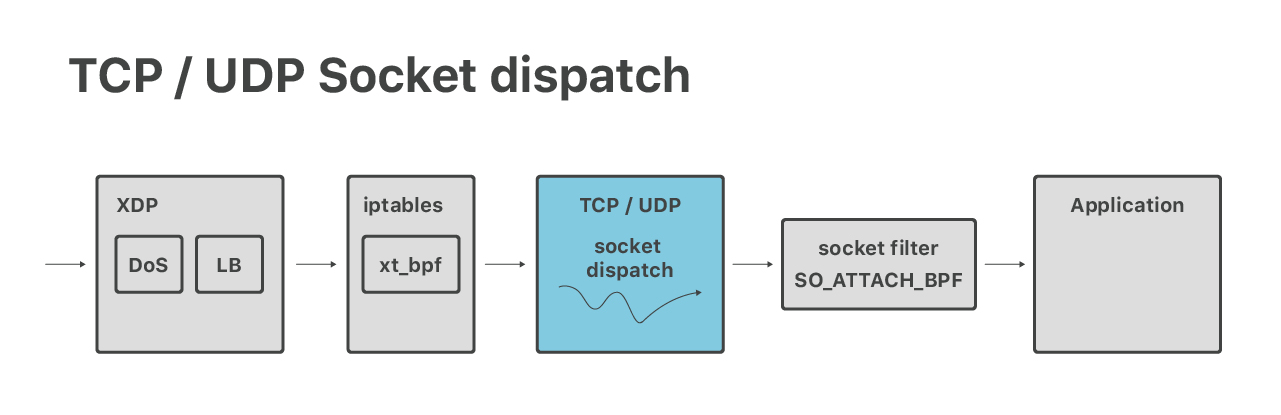
Después de la denegación de servicio (DoS) y las capas de equilibrio de carga, los paquetes pasan a la pila de TCP / UDP de Linux habitual. Aquí hacemos un envío de socket - por ejemplo, los paquetes que van al puerto 53 pasan a un socket que pertenece a nuestro servidor DNS.
Hacemos todo lo posible por utilizar características estándar de Linux, pero las cosas se vuelven complejas cuando se usan miles de direcciones IP en los servidores.
Convencer a Linux para enrutar paquetes correctamente es bastante fácil con el truco “AnyIP. Verificar que los paquetes se envían a la aplicación correcta es otra cuestión. Lamentablemente, la lógica de envío de sockets Linux estándar no es lo suficientemente flexible para nuestras necesidades. Para puertos populares como TCP/80 queremos compartir el puerto entre varias aplicaciones, cada una de las cuales lo maneja en un rango de IP diferente. Linux no es compatible de manera directa. Usted puede llamar enlazar() a una dirección IP específica o a todas las IP (con 0.0.0.0).
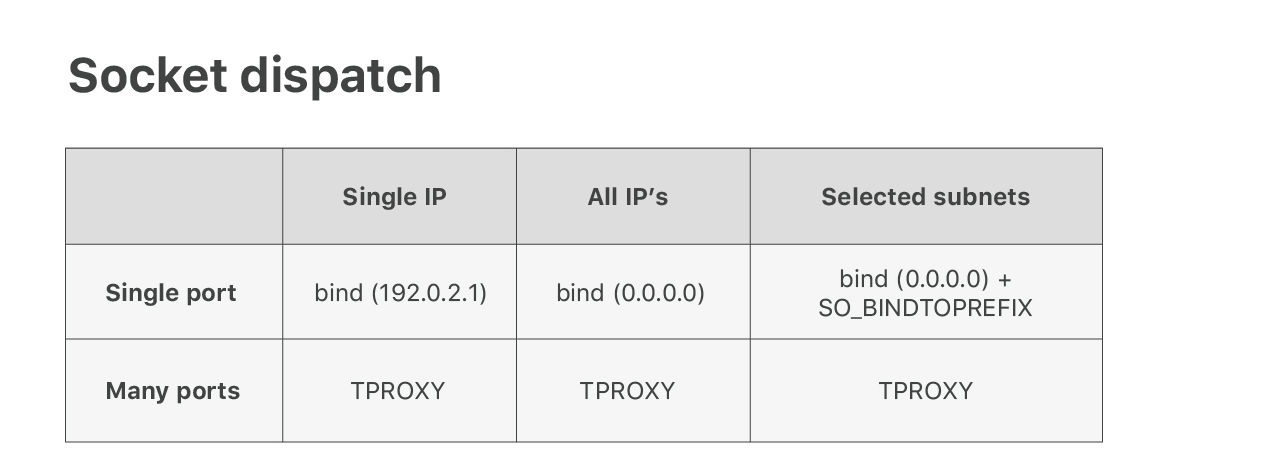
Para solucionar este inconveniente, desarrollamos un parche de núcleo personalizado que agrega una opción de socket SO_BINDTOPREFIX. Como su nombre lo indica, nos permite llamar enlazar() un prefijo de IP seleccionado. Esto resuelve el problema de aplicaciones múltiples que comparten puertos populares como 53 u 80.
Luego nos encontramos con otro problema. Para nuestro producto Spectrum, necesitamos escuchar en los 65535 puertos. Ejecutar tantos sockets de escucha no es una buena idea (ver nuestro viejo blog con historias de guerras), por lo tanto, tuvimos que encontrar otra manera. Después de algunos experimentos, aprendimos a utilizar un módulo de iptables no muy conocido - TPROXY - para este propósito. Leer sobre este aquí:
Esta configuración está funcionando, pero no nos gustan las reglas de firewall adicionales. Estamos trabajando para resolver correctamente este problema, en realidad estamos ampliando la lógica de envío de socket. Adivinó, queremos extender la lógica de envío de socket mediante la utilización de eBPF. Estamos desarrollando algunos parches.
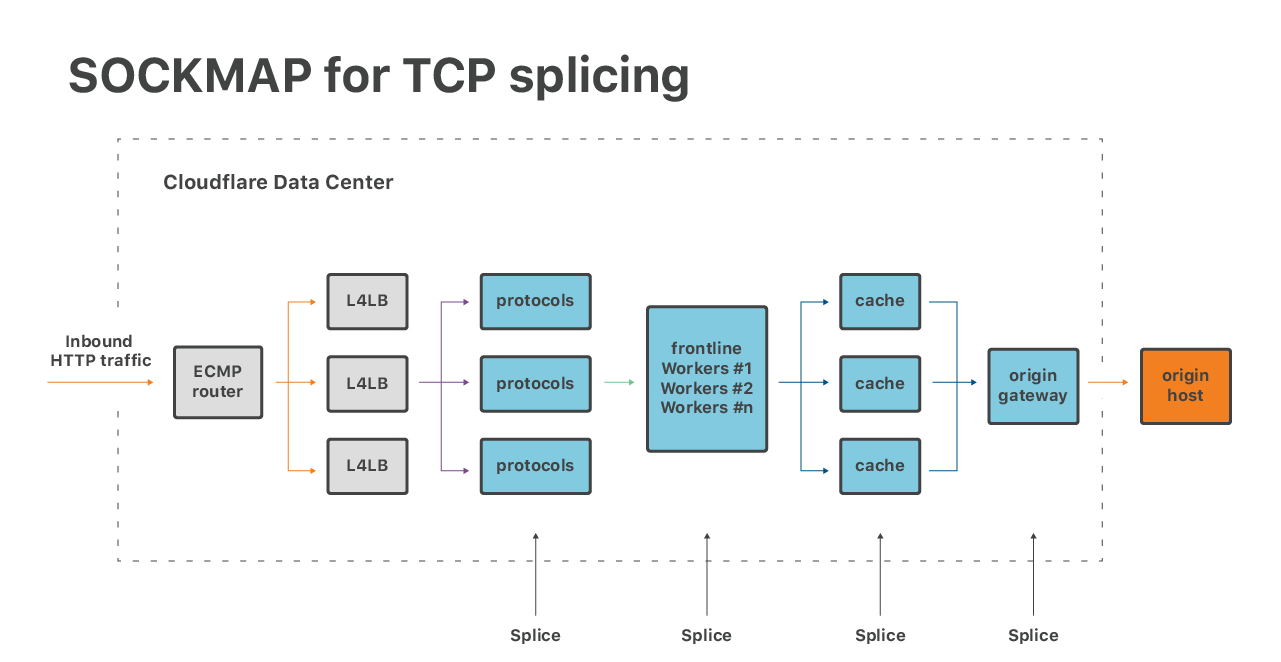
Luego, hay una manera de utilizar eBPF para optimizar las aplicaciones. Recientemente, nos interesamos en el empalme de TCP con SOCKMAP:
Esta técnica ofrece un gran potencial para mejorar la latencia de cola en muchas piezas de nuestra pila de software. La implementación de SOCKMAP actual aún no está lista para el horario de mayor tráfico, pero el potencial es enorme.
Del mismo modo, los nuevos enlaces TCP-BPF también conocidos como BPF_SOCK_OPS ofrecen una excelente manera de inspeccionar los parámetros de rendimiento de los flujos de TCP. Esta funcionalidad resulta muy útil para nuestro equipo de rendimiento.
Algunas características de Linux no soportaron bien el paso del tiempo y tenemos que trabajar en esto. Por ejemplo, estamos llegando a los límites de las métricas de red. No quiero que me malinterprete: las métricas de red son increíbles, pero lamentablemente no tienen la granularidad suficiente. Cosas como TcpExtListenDrops y TcpExtListenOverflows se informan como contadores globales, y nosotros necesitamos la información de cada aplicación.
Nuestra solución es utilizar un sondeo de eBPF para extraer los números directamente del núcleo. Mi colega Ivan Babrou desarrolló un exportador de métricas Prometheus que se llama “ebpf_exporter” para facilitar esto. Seguir leyendo:
Con “ebpf_exporter”, podemos generar todo tipo de métricas detalladas. Es muy potente y nos salvó en muchas ocasiones.
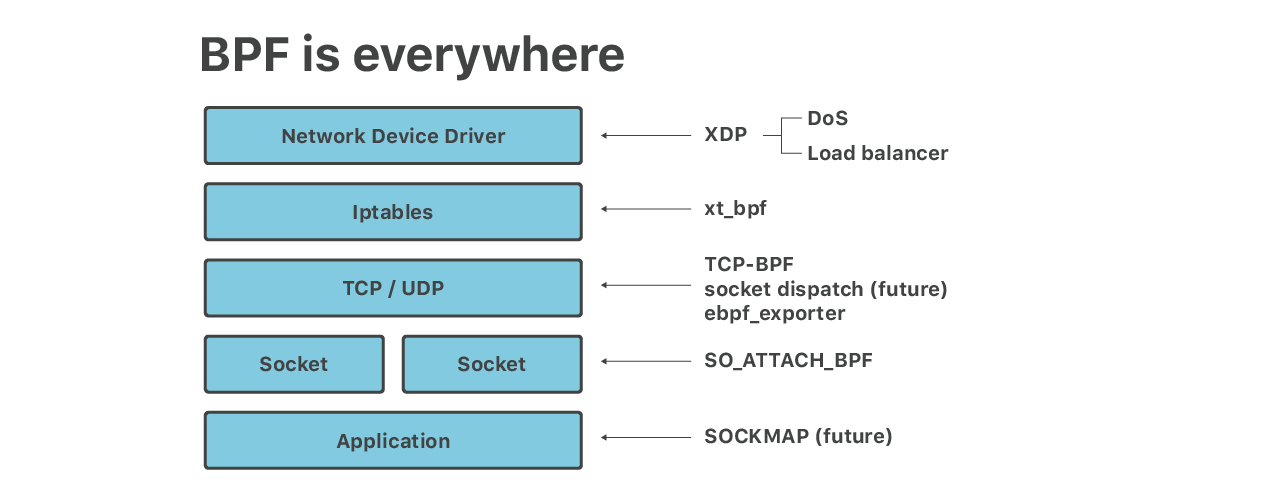
En esta charla analizamos las 6 capas del BPF que se ejecutan en nuestros servidores perimetrales:
- Las mitigaciones de DoS volumétricas se ejecutan en eBPF de XDP
- Iptables xt_bpf cBPF para ataques de capas de aplicaciones
- SO_ATTACH_BPF para límites de velocidad en sockets UDP
- Equilibrador de carga, que se ejecuta en XDP
- Auxiliares de aplicaciones que se ejecutan en eBPF como SOCKMAP para el empalme de socket TCP y TCP-BPF para mediciones de TCP
- “ebpf_exporter” para métricas granulares
¡Y eso es solo el comienzo! Pronto haremos más con el envío de socket basado en eBPF, eBPF que se ejecuta en la capa Linux TC (Control de tráfico) y más integración con enlaces eBPF para cgroup. Además, nuestro equipo de ingeniería de confiabilidad del sitio (SRE) lleva una lista cada vez más extensa de scripts BCCqué resulta útil para la depuración.
Parece que Linux dejó de desarrollar nuevas API y todas las características nuevas se implementan como auxiliares y enlaces eBPF. Esto está bien y presenta muchas ventajas. Es más fácil y seguro actualizar el programa de eBPF que tener que volver a compilar un módulo del núcleo. Algunas cosas como TCP-BPF, que exponen un gran volumen de datos de seguimiento del rendimiento, probablemente serían imposibles sin eBPF.
Algunos afirman que “el software se está comiendo el mundo”, yo diría que: “el BPF se está comiendo el software”.