
Wenn Sie unseren anderen Beitrag gelesen haben, wissen Sie, dass wir WARP heute auch für die letzten Mitglieder unserer Warteliste freigegeben haben. Mit WARP wollten wir die Verbindung zwischen Ihren mobilen Geräten und dem Internet sicherer und besser machen. Dabei sind wir auf Probleme mit Telefon- und Betriebssystemversionen, der Vielfalt der Netzwerke und unserer eigenen Infrastruktur gestoßen. Und das, während wir eine Warteliste von fast zwei Millionen Leuten abarbeiten mussten.
Damit Sie verstehen können, welche Probleme es gab und wie wir sie gelöst haben, brauchen Sie zunächst etwas Hintergrundwissen über die Funktionsweise des Cloudflare-Netzwerks:
So funktioniert unser Netzwerk
Das Netzwerk von Cloudflare besteht aus Rechenzentren in 194 Städten und mehr als 90 Ländern. In jedem Cloudflare-Rechenzentrum stehen viele Server, die kontinuierlich eine Flut von Anfragen empfangen. Diese Anforderungen müssen zur Verarbeitung auf die Server verteilt werden. Für diesen Vorgang verwenden wir eine Reihe von Routern:
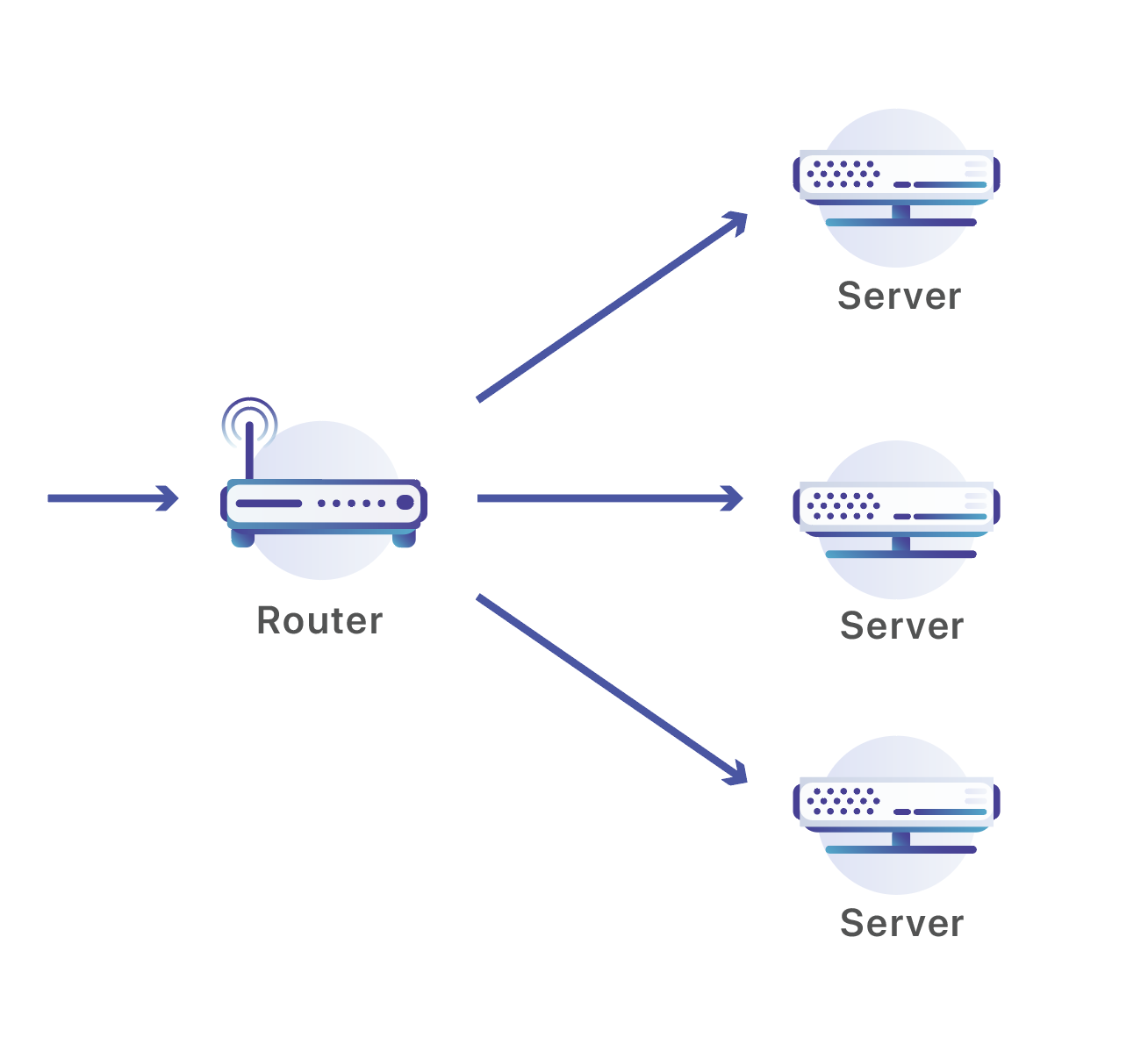
Unsere Router erwarten Traffic über Anycast-IP-Adressen, die über das öffentliche Internet bekanntgegeben werden. Wenn Ihre Website auf Cloudflare gehostet wird, ist sie über zwei dieser Adressen verfügbar. In diesem Fall mache ich eine DNS-Abfrage für „workers.dev“, eine Website, die von Cloudflare betrieben wird:
➜ dig workers.dev
;; QUESTION SECTION:
;workers.dev. IN A
;; ANSWER SECTION:
workers.dev. 161 IN A 198.41.215.162
workers.dev. 161 IN A 198.41.214.162
;; SERVER: 1.1.1.1#53(1.1.1.1)
workers.dev ist unter den beiden Adressen 198.41.215.162 und 198.41.214.162 verfügbar (außerdem gibt es zwei IPv6-Adressen, die über die AAAA-DNS-Abfrage verfügbar sind). Diese beiden Adressen werden von jedem unserer Rechenzentren auf der ganzen Welt bekanntgegeben. Wenn jemand eine Verbindung zu einer Website auf Cloudflare herstellt, wählt jedes Netzwerkgerät, durch das seine Paketen laufen, den kürzesten Pfad von seinem Computer oder Telefon zum nächstgelegenen Cloudflare-Rechenzentrum.
Sobald die Pakete in unserem Rechenzentrum eintreffen, senden wir sie an einen der vielen dort arbeitenden Server. Traditionell kann man für diese Art der Traffic-Verteilung auf mehrere Rechner einen Load Balancer einsetzen. Eine Batterie von Load Balancern, die das Traffic-Volumen in einem unserer Rechenzentren bewältigen kann, wäre allerdings irrsinnig teuer und nicht so einfach skalierbar wie unsere Server. Deshalb verwenden wir Netzwerkrouter. Diese Geräte sind für gewaltiges Traffic-Volumen ausgelegt.
Sobald ein Paket in unserem Rechenzentrum ankommt, wird es von einem Router verarbeitet. Dieser Router sendet den Traffic an einen der Server, die für die Verarbeitung dieser Adresse zuständig sind. Dabei wird eine Routingstrategie namens ECMP (Equal-Cost Multi-Path) eingesetzt. Mit ECMP ist eine Situation gemeint, in der der Router unter mehreren Routen keinen klaren „Gewinner“ feststellen kann und es mehrere geeignete Etappen gibt, die alle zu demselben Endziel führen. Wir haben dieses Konzept ein wenig „gehackt“. Wir gleichen mit ECMP nicht mehrere Zwischenverbindungen aus, sondern wir erklären die Zwischenverbindungsadressen zum Endziel des Traffics: unsere Server.
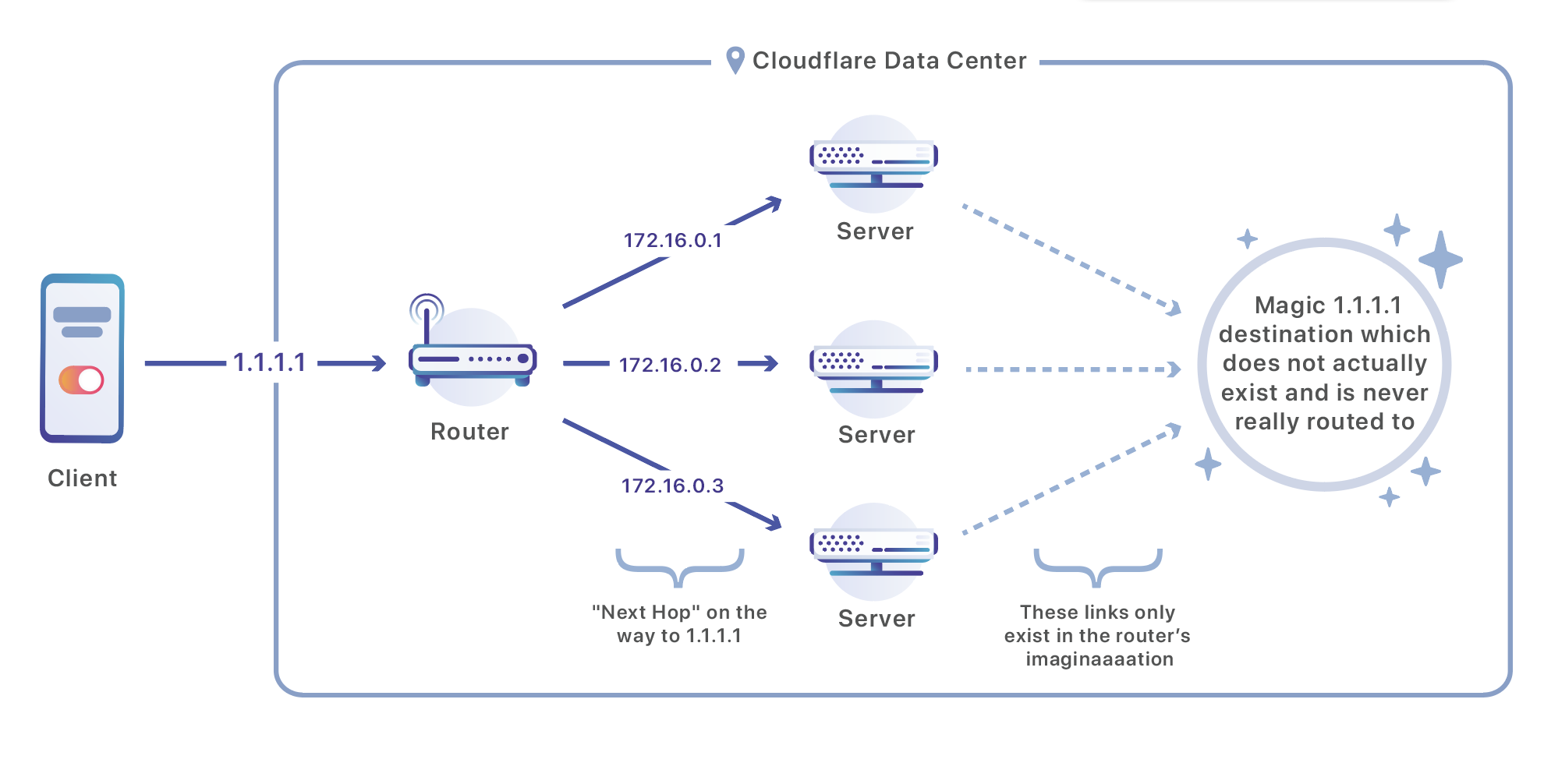
Hier die Konfiguration eines Juniper-Routers, der sich in einem unserer Rechenzentren befinden könnte und so konfiguriert ist, dass der Traffic zwischen drei Zielen ausgeglichen wird:
user@host# show routing-options
static {
route 172.16.1.0/24 next-hop [ 172.16.2.1 172.16.2.2 172.16.2.3 ];
}
forwarding-table {
export load-balancing-policy;
}
Da die „nächste Etappe“ („next-hop“) unser Server ist, wird der Traffic sehr effizient auf mehrere Rechner aufgeteilt.
TCP, IP und ECMP
IP ist dafür verantwortlich, Datenpakete von Adressen wie 93.184.216.34 über das Internet nach 208.80.153.224 (oder bei IPV6 von [2606:2800:220:1:248:1893:25c8:1946] nach [2620:0:860:ed1a::1]) zu senden. Es ist das „Internet-Protokoll“.
TCP (Transmission Control Protocol) setzt auf einem Protokoll wie IP, das ein Paket von einem Ort an einen anderen senden kann, auf und sorgt dafür, dass die Datenübertragung für mehrere Prozesse gleichzeitig verlässlich und sinnvoll funktioniert. Es ist dafür zuständig, unzuverlässige und falsch sortierte Pakete, die über ein Protokoll wie IP ankommen können, zu übernehmen und sie zuverlässig und in der richtigen Reihenfolge abzuliefern. Außerdem wird durch TCP das Konzept eines „Ports“ eingeführt. Ein Port ist eine Nummer von 1 bis 65535, mit deren Hilfe der Traffic auf einem Computer oder Telefon an einen bestimmten Dienst (z. B. Web oder E-Mail) weitergeleitet wird. Jede TCP-Verbindung hat einen Quell- und einen Ziel-Port. TCP fügt am Anfang jedes Pakets einen Header ein, in dem diese Ports angegeben sind. Ohne die Idee der Ports wäre es schwierig, festzustellen, welche Nachrichten für welches Programm bestimmt sind. So könnten beispielsweise Google Chrome und Mail gleichzeitig Nachrichten über Ihre WLAN-Verbindung senden wollen. Dazu verwenden sie jeweils ihren eigenen Port.
Hier ein Beispiel für eine Anfrage für https://cloudflare.com/ unter 198.41.215.162 auf dem Standardport für HTTPS: 443. Mein Computer hat mir zufällig den Port 51602 zugewiesen. Auf diesem Port erwartet er die Antwort, die (hoffentlich) den Inhalt der Website enthält:
Internet Protocol Version 4, Src: 19.5.7.21, Dst: 198.41.215.162
Protocol: TCP (6)
Source: 19.5.7.21
Destination: 198.41.215.162
Transmission Control Protocol, Src Port: 51602, Dst Port: 443, Seq: 0, Len: 0
Source Port: 51602
Destination Port: 443
Von der Cloudflare-Seite aus betrachtet sehen wir dieselbe Anfrage als Spiegelbild – eine Anfrage von meiner öffentlichen IP-Adresse, die von meinem Quell-Port stammt und für Port 443 bestimmt ist (ich ignoriere NAT für den Moment, mehr dazu später):
Internet Protocol Version 4, Src: 198.41.215.16, Dst: 19.5.7.21
Protocol: TCP (6)
Source: 198.41.215.162
Destination: 19.5.7.21
Transmission Control Protocol, Src Port: 443, Dst Port: 51602, Seq: 0, Len: 0
Source Port: 443
Destination Port: 51602
Nun können wir auf ECMP zurückkommen! Theoretisch könnte man mit ECMP Pakete zufällig zwischen Servern verteilen, aber das sollte man eigentlich nie so machen. Eine über das Internet gesendete Nachricht besteht in der Regel aus mehreren TCP-Paketen. Wenn jedes Paket an einen anderen Server gesendet würde, wäre es unmöglich, an einem einzelnen Ort die Ausgangsnachricht zu rekonstruieren und darauf zu reagieren. Auch sonst würde es sich furchtbar auf die Leistung auswirken: Wir verlassen uns auf langlebige TCP- und TLS-Sitzungen, und dafür brauchen wir eine dauerhafte Verbindung zu einem einzelnen Server. Um diese Persistenz zu gewährleisten, führen unsere Router die Lastverteilung nicht zufällig durch, sondern arbeiten mit einer Kombination aus vier Werten: der Quell-Adresse, dem Quell-Port, der Ziel-Adresse und dem Ziel-Port. Traffic mit derselben Kombination aus diesen vier Werten wird immer auf denselben Server geleitet. Im obigen Beispiel werden Nachrichten, die für cloudflare.com bestimmt sind, zu einem ganz bestimmten Server weitergeleitet, der die TCP-Pakete in meiner Anfrage rekonstruieren und Pakete in einer Antwort zurückgeben kann.
Da kommt WARP ins Spiel
Bei einer herkömmlichen Anfrage ist es sehr wichtig, dass unser ECMP-Routing für die Dauer Ihrer Anfrage alle Ihre Pakete an denselben Server sendet. Über das Web dauert eine Anfrage in der Regel weniger als zehn Sekunden, sodass das System gut funktioniert. Leider bekamen wir schnell Probleme mit WARP.
Bei WARP werden Pakete mit einem Sitzungsschlüssel gesichert, der mit Public-Key-Verschlüsselung gebildet wurde. Damit die Verbindung erfolgreich sein kann, müssen beide Seiten eine Verbindung vereinbaren, die dann nur für den jeweiligen Client und den bestimmten Server gültig ist, mit dem sie kommunizieren. Diese Abstimmung erfordert Zeit und muss jedes Mal durchgeführt werden, wenn ein Client mit einem neuen Server kommuniziert. Schlimmer noch: Wenn Pakete, die für einen bestimmten Server vorgesehen sind, auf einem anderen landen, können sie nicht entschlüsselt werden und die Verbindung wird beendet. Diese fehlgeschlagenen Pakete zu erkennen und die Verbindung ganz neu aufzubauen, kostet so viel Zeit, dass unsere Alpha-Tester das Gefühl hatten, ihre Internetverbindung sei vollkommen zusammengebrochen. Kein Wunder also, dass unsere Tester WARP schon bald abgeschaltet haben, weil es sie daran gehindert hat, das Internet zu nutzen.
Bei WARP erlebten wir so viele Ausfälle, weil die Geräte ihre Server viel häufiger wechselten, als wir erwartet hatten. Wie Sie sich erinnern werden, ermittelt unsere ECMP-Routerkonfiguration über eine Kombination aus (Quell-IP, Quell-Port, Ziel-IP, Ziel-Port) den richtigen Server für ein Paket. Die Ziel-IP ändert sich im Allgemeinen nicht, denn WARP-Clients stellen immer eine Verbindung zu denselben Anycast-Adressen her. Ebenso ändert sich der Ziel-Port nicht, wir erwarten den WARP-Traffic immer auf demselben Port. Die anderen beiden Werte, Quell-IP und Quell-Port, änderten sich jedoch viel häufiger, als wir geplant hatten.
Eine Ursache dieser Änderungen war zu erwarten gewesen. WARP wird auf Mobiltelefonen ausgeführt, und Mobiltelefone wechseln häufig zwischen Mobilfunk- und WLAN-Verbindungen. Bei diesem Wechsel geht man plötzlich von der Kommunikation über den IP-Adressraum des Mobilfunkanbieters (z. B. AT&T oder Verizon) zur Kommunikation über den Adressraum des Internetanbieters der WLAN-Verbindung (z. B. Comcast oder Google Fiber) über. Es ist praktisch unmöglich, dass die IP-Adresse bei so einem Verbindungswechsel gleich bleibt.
Aber die Portänderungen traten noch häufiger auf, als durch Netzwerkwechsel allein erklärt werden konnte. Um den Grund dafür zu verstehen, müssen wir noch ein weiteres Kapitel der „Internetkunde“ aufschlagen: Netzwerkadressübersetzung (Network Address Translation).
NAT
Eine IPv4-Adresse besteht aus 32 Bit (oft als vier Acht-Bit-Zahlen geschrieben). Wenn man die nicht verwendbaren, reservierten Adressen ausschließt, bleiben 3.706.452.992 mögliche Adressen übrig. Diese Zahl ist konstant geblieben, seit IPv4 1983 auf dem ARPANET eingeführt wurde, obwohl die Anzahl der Geräte inzwischen explodiert ist (allerdings könnte sie bald etwas ansteigen, wenn 0.0.0.0/8 verfügbar wird). Diese Daten beruhen auf Prognosen und Schätzungen von Gartner Research:
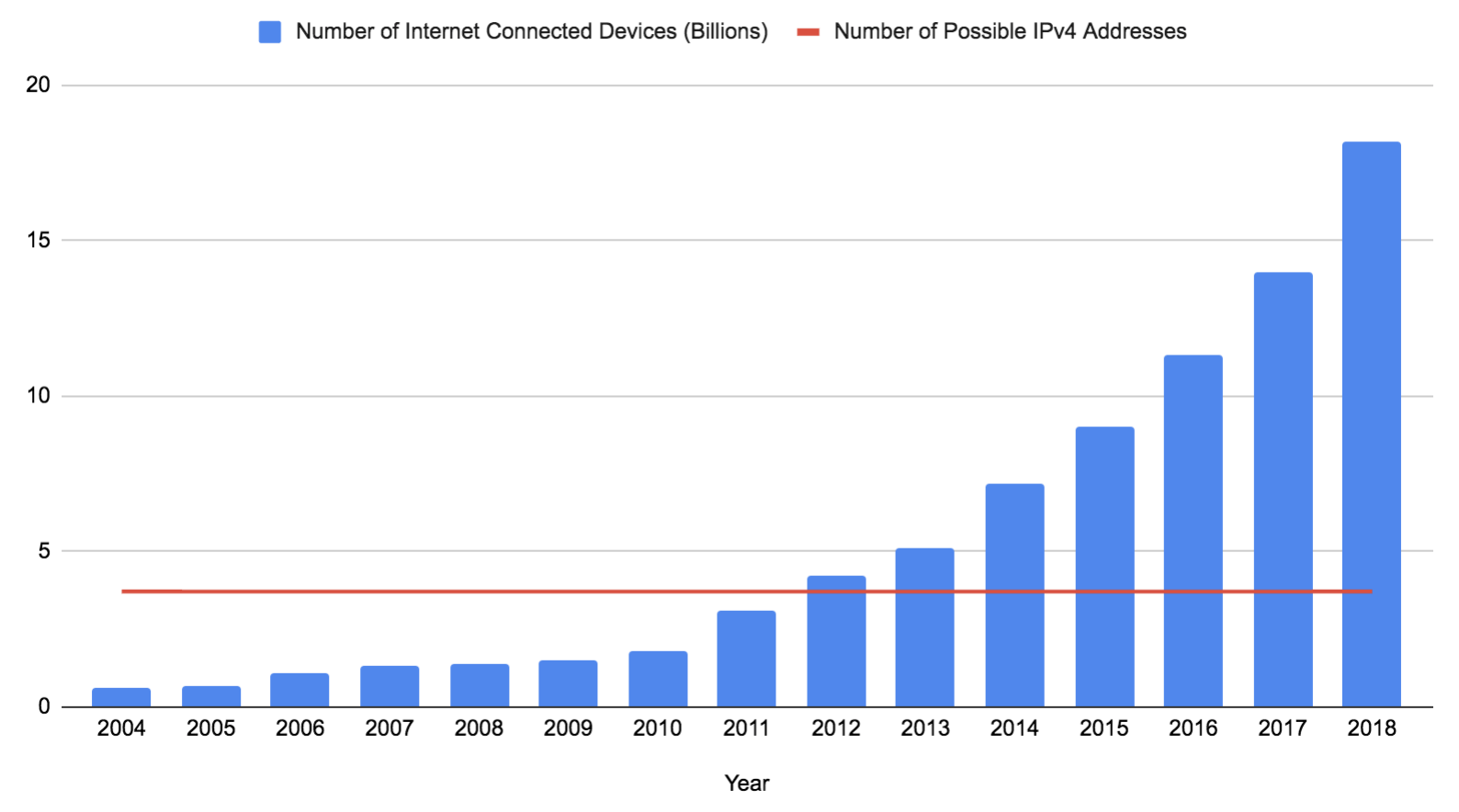
Mit IPv6 wird dieses Problem definitiv gelöst. IPv6 erweitert die Länge einer Adresse von 32 auf 128 Bit. Davon sind momentan 125 Bit in einer gültigen Internetadresse verfügbar (bei allen öffentlichen IPv6-Adressen sind die ersten drei Bit auf 001 festgelegt; die verbliebenen 87,5 % des IPv6-Adressraums werden noch nicht benötigt). 2^125 ist eine gewaltige Zahl und würde mehr als ausreichen, jedem Gerät auf der Erde seine eigene Adresse zu geben. Leider wird IPv6 auch 21 Jahre nach seiner Veröffentlichung von vielen Netzwerken immer noch nicht unterstützt. Ein Großteil des Internets stützt sich immer noch auf IPv4, und die IPv4-Adressen reichen, wie oben gesehen, nicht für alle Geräte aus.
Um dieses Problem zu lösen, stellt man viele Geräte häufig hinter eine einzige internetfähige IP-Adresse. Für die Netzwerkadressübersetzung wird ein Router eingesetzt. Er nimmt Nachrichten entgegen, die auf dieser einzigen öffentlichen IP-Adresse ankommen, und leitet sie an das entsprechende Gerät im lokalen Netzwerk weiter. Das ist ungefähr so wie in einem Mehrfamilienhaus, in dem jeder exakt die gleiche Postadresse hat und der Postbote die Briefe in die Briefkästen der einzelnen Personen einsortieren muss.
Wenn Ihre Geräte ein Paket an das Internet senden, fängt Ihr Router es ab. Der Router überschreibt dann die Quell-Adresse mit der einzelnen öffentliche Internetadresse, die Ihnen zugewiesen wurde, und den Quell-Port mit einem eindeutigen Port für alle Nachrichten, die von allen mit dem Internet verbundenen Geräte in Ihrem Netzwerk gesendet werden. Genauso wie Ihr Computer für Ihre Nachrichten einen zufälligen Quell-Port wählt, der unter all den verschiedenen Prozessen auf Ihrem Computer einzigartig ist, wählt Ihr Router einen zufälligen Quell-Port, der für alle Internetverbindungen in Ihrem Netzwerk einzigartig ist. Er merkt sich den Port, den er für Ihre Verbindung auswählt, und lässt die Nachricht nun weiter über das Internet verbreiten.
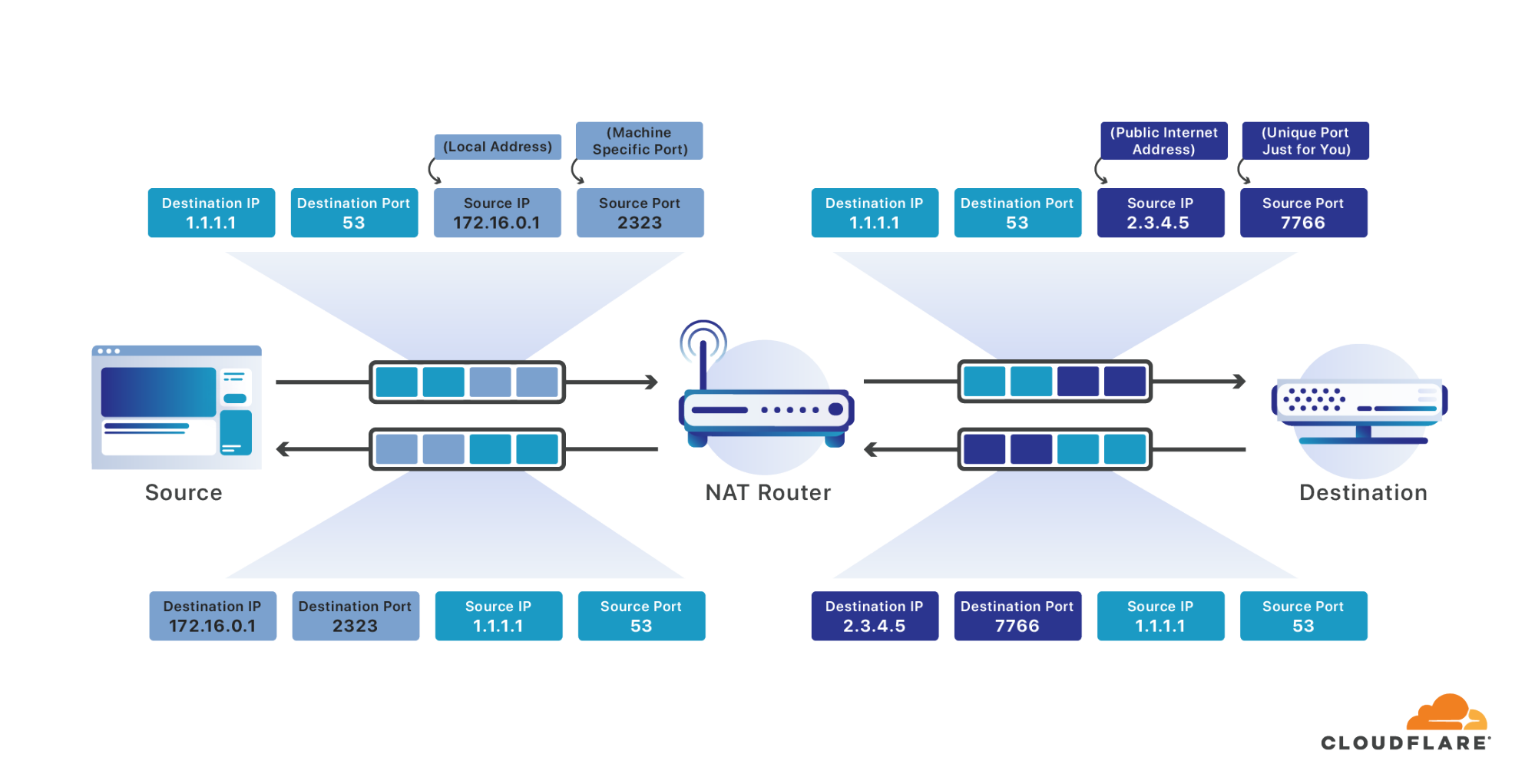
Wenn eine Antwort eintrifft, die für den Port bestimmt ist, den er Ihnen zugewiesen hat, wird der Port mit Ihrer Verbindung abgeglichen und erneut überschrieben. Dabei wird diesmal die Ziel-Adresse durch Ihre Adresse im lokalen Netzwerk und der Ziel-Port durch Ihren ursprünglichen Quell-Port ersetzt. So können offensichtlich alle Geräte in Ihrem Netzwerk so tun, als wären sie ein einziger großer Computer mit einer einzigen mit dem Internet verbundenen IP-Adresse.
Dieser Prozess funktioniert für die Dauer einer gewöhnlichen Internet-Anfrage sehr gut. Ihr Router hat jedoch nur begrenzt viel Speicherplatz, sodass er Portzuordnungen löschen und Platz für neue schaffen muss. In der Regel wartet er dabei, bis es bei der Verbindung mindestens dreißig Sekunden keine Nachrichten gab, und löscht dann die Zuordnung. Dadurch ist es unwahrscheinlich, dass eine Antwort eintrifft, die nicht mehr an die entsprechende Quelle gesendet werden kann. Leider benötigen WARP-Sitzungen viel länger als dreißig Sekunden.
Wenn Sie nach Ablauf der NAT-Sitzung eine weitere Nachricht senden, erhalten Sie einen neuen Quell-Port. Durch diesen neuen Port ändert sich die ECMP-Zuordnung (basierend auf Quell-IP, Quell-Port, Ziel-IP, Ziel-Port). Was wiederum dazu führt, dass Ihre Anfragen in dem Cloudflare-Rechenzentrum, in dem Ihre Nachrichten ankommen, an einen anderen Computer weitergeleitet werden. Ihre WARP-Sitzung wird dadurch unterbrochen, ebenso Ihre Internetverbindung.
Wir haben ausgiebig mit Methoden experimentiert, die NAT-Sitzung aufrechtzuerhalten, indem wir regelmäßig Keep-Alive-Nachrichten sendeten, die Router und Mobilfunkanbieter davon abhalten, die Zuordnungen zu entfernen. Die Auffrischung der Funkverbindung zu Ihrem Gerät alle dreißig Sekunden wirkt sich allerdings schlecht auf die Akkulaufzeit aus. Außerdem konnten wir die Port- und Adressänderungen auch so nicht hundertprozentig verhindern. Wir brauchten eine Möglichkeit, Sitzungen immer demselben Computer zuzuordnen, auch wenn sich der Quell-Port (und sogar die Quell-Adresse) geändert hat.
Glücklicherweise konnten wir an anderer Stelle bei Cloudflare eine Lösung dafür finden. Wir setzen keine dedizierten Load Balancer ein, aber wir haben viele der gleichen Probleme, die durch Load Balancer gelöst werden. Wir hatten schon lange den Bedarf, bei der Zuordnung von Traffic zu Cloudflare-Servern mehr Kontrolle zu erreichen, als ECMP allein zulässt. Anstatt eine ganze Batterie von Load Balancern einzusetzen, nutzen wir einfach jeden Server in unserem Netzwerk als Load Balancer. Dazu leiten wir Pakete zuerst an einen beliebigen Rechner weiter und verlassen uns dann darauf, dass dieser Rechner das Paket an den richtigen Host weiterleitet. So ist der Ressourcenverbrauch minimal und unsere Lastverteilungs-Infrastruktur skaliert mit jedem Rechner, der dazukommt. Wir werden noch mehr darüber erzählen, wie diese Infrastruktur funktioniert und was sie so einzigartig macht. Abonnieren Sie doch diesen Blog, damit Sie benachrichtigt werden, wenn der entsprechende Beitrag veröffentlicht wird.
Aber damit unsere Lastverteilungs-Technik funktioniert, mussten wir irgendwie herausfinden, welchem Client ein WARP-Paket zugeordnet war, bevor es entschlüsselt werden konnte. Um zu verstehen, wie wir das gemacht haben, sollte man wissen, wie WARP die Nachrichten verschlüsselt. Die Standardmethode, ein Gerät mit einem entfernten Netzwerk zu verbinden, ist ein VPN. VPNs nutzen Protokolle wie IPsec, damit Ihr Gerät Nachrichten sicher an ein entferntes Netzwerk senden kann. Leider sind VPNs im Allgemeinen eher unbeliebt. Sie machen Verbindungen langsamer, kosten Akkulaufzeit und durch ihre Komplexität entstehen häufig Sicherheitslücken. Wer in einem Unternehmensnetzwerk arbeitet, in dem VPNs vorgeschrieben sind, ist oft sehr unzufrieden damit. Die Vorstellung, Millionen von Verbrauchern davon zu überzeugen, so etwas freiwillig zu installieren, schien lächerlich.
Wir haben einige modernere Möglichkeiten in Betracht gezogen und getestet und sind schließlich bei WireGuard® gelandet. WireGuard ist ein modernes, leistungsstarkes und vor allem einfaches Protokoll, das von Jason Donenfeld entwickelt wurde, um genau das gleiche Problem zu lösen. Die Größe seiner ursprünglichen Codebasis beträgt weniger als 1 % der einer beliebten IPSec-Implementierung. Deshalb konnten wir es mühelos verstehen und absichern. Wir haben uns für Rust als Sprache entschieden, da Rust uns am ehesten die Leistung und Sicherheit verschafft, die wir brauchen. Bei der Implementierung von WireGuard haben wir den Code für unsere Zielplattformen stark optimiert. Dann haben wir das Projekt zu Open Source gemacht.

Durch WireGuard ändern sich beim Internet-Traffic zwei sehr wichtige Dinge. Erstens wird UDP statt TCP verwendet. Zweitens wird der Inhalt dieses UDP-Pakets mit einem Sitzungsschlüssel gesichert, der mit Public-Key-Verschlüsselung gebildet wurde.
TCP ist das herkömmliche Protokoll zum Laden einer Website über das Internet. Es kombiniert die Fähigkeit, Ports zu adressieren (wie bereits erwähnt), mit zuverlässiger Übermittlung und Ablaufsteuerung. Zuverlässige Übermittlung bedeutet, dass TCP beim Verwerfen einer Nachricht die fehlenden Daten erneut sendet. Durch die Ablaufsteuerung kann TCP viele Clients bewältigen, die dieselbe Verbindung gemeinsam nutzen und ihre Kapazität eigentlich überschreiten. UDP ist ein viel einfacheres Protokoll, das zugunsten der Einfachheit auf diese Leistungsmerkmale verzichtet. Es unternimmt einen Versuch, eine Nachricht zu senden, und wenn die Nachricht ausfällt oder es zu viele Daten für die Verbindungen gibt, gehen die Nachrichten eben verloren.
Normalerweise wäre die Unzuverlässigkeit von UDP beim Surfen im Internet ein Problem. Aber wir senden nicht einfach UDP, wir senden ein komplettes TCP-Paket _innerhalb_ unserer UDP-Pakete.
Innerhalb der von WireGuard verschlüsselten Nutzdaten befindet sich ein kompletter TCP-Header mit allen Informationen, die für eine zuverlässige Übermittlung erforderlich sind. Dieses Paket wird in die WireGuard-Verschlüsselung verpackt und per UDP (also unzuverlässig) über das Internet versendet. Falls es verloren geht, macht TCP genau so weiter, als ob eine Netzwerkverbindung die Nachricht verloren hätte, und sendet es erneut. Wenn wir unsere innere, verschlüsselte TCP-Sitzung stattdessen in ein weiteres TCP-Paket verpacken würden, wie es einige andere Protokolle tun, würde die Anzahl erforderlicher Netzwerknachrichten drastisch zunehmen und die Performance zunichte machen.
Die zweite interessante, für unser Thema relevante WireGuard-Komponente ist die Public-Key-Verschlüsselung. Mit WireGuard kann man jede gesendete Nachricht so absichern, dass nur das Ziel, für das sie bestimmt ist, sie entschlüsseln kann. Auf diese Weise kann man die Sicherheit beim Surfen im Internet gut gewährleisten, es bedeutet aber auch, dass man die verschlüsselten Nutzdaten erst lesen kann, wenn die Nachricht den für die Sitzung zuständigen Server erreicht hat.
Zurück zu unserem Lastverteilungs-Problem. Wie Sie sehen, sind vor dem Entschlüsseln der Nachricht nur drei Dinge für uns zugänglich: der IP-Header, der UDP-Header und der WireGuard-Header. Weder der IP-Header noch der UDP-Header enthalten die Informationen, die wir brauchen, denn wir scheitern schon an den vier darin enthaltenen Informationen (Quell-IP, Quell-Port, Ziel-IP, Ziel-Port). Damit ist der WireGuard-Header der einzige Speicherort für eine Kennung, mit der man vor dem Entschlüsseln der Nachricht ermitteln kann, wer der Client war. Leider gibt es diese Kennung nicht. Hier das Format der Nachricht, mit der eine Verbindung eingeleitet wird:

sender sieht verlockend nach einer Client-ID aus, wird aber bei jedem Handshake zufällig zugewiesen. Handshakes müssen alle zwei Minuten durchgeführt werden, damit die Schlüssel rotieren. Dadurch sind sie nicht ausreichend persistent. Wir hätten das Protokoll abwandeln und jede Menge zusätzlicher Felder aufnehmen können, aber wir wollten mit anderen WireGuard-Clients kompatibel bleiben. Glücklicherweise gibt es bei WireGuard einen Drei-Byte-Block im Header, der derzeit nicht von anderen Clients verwendet wird. Wir haben uns entschieden, unsere Kennung in diesem Bereich abzulegen und trotzdem weiterhin Nachrichten anderer WireGuard-Clients zu unterstützen (wenn auch mit weniger zuverlässigem Routing als unserem). Sollte dieser reservierte Bereich einmal für andere Zwecke verwendet werden, können wir diese Bit ignorieren oder das Protokoll mit dem WireGuard-Team auf andere geeignete Weise erweitern.
Zu Beginn einer WireGuard-Sitzung tragen wir unser Feld clientid ein. Es wird von unserem Authentifizierungsserver bereitgestellt, mit dem kommuniziert werden muss, um eine WARP-Sitzung zu beginnen:

Auch Datennachrichten enthalten dasselbe Feld:

Es ist wichtig zu beachten, dass die clientid nur 24 Bit lang ist. Es gibt also weniger mögliche Werte für die clientid als Benutzer, die gerade auf WARP warten. Das ist uns ganz recht, denn wir wollen gar nicht die Möglichkeit schaffen, einzelne WARP-Benutzer zu verfolgen. Die clientid wird nur für die Lastverteilung gebraucht. Wenn sie ihren Zweck erfüllt hat, löschen wir sie schnellstmöglich aus unseren Systemen.
Das Lastverteilungs-System ermittelt nun anhand eines Hashwerts der clientid, an welchen Rechner ein Paket weitergeleitet werden soll. Das bedeutet, dass WARP-Nachrichten immer auf demselben Rechner ankommen, selbst beim Wechsel der Netzwerke oder von WLAN zu Mobilfunk. Problem gelöst.
Client-Software
Cloudflare hat noch nie zuvor Client-Software entwickelt. Wir sind stolz darauf, einen Service zu verkaufen, den jeder nutzen kann, ohne Hardware kaufen oder Infrastruktur bereitstellen zu müssen. Damit WARP funktioniert, muss unser Code jedoch auf der verbreitetsten Hardwareplattform überhaupt laufen, nämlich Smartphones.
Die Entwicklung von Software für mobile Geräte ist in den letzten zehn Jahren ständig einfacher geworden. Bei maschinennaher Netzwerksoftware bleibt es jedoch ziemlich schwierig. Um ein Beispiel zu nennen: Wir begannen das Projekt mit der neuesten iOS-Netzwerk-API namens Network, die in iOS 12 eingeführt wurde. Apple empfiehlt dringend den Einsatz von Network. Wir zitieren: „Ihre Kunden werden die besseren Verbindungen, den zuverlässigeren Verbindungsaufbau und die längere Akkulaufzeit durch die bessere Leistung zu schätzen wissen.“
Das Network-Framework bietet eine API auf angenehm hohem Niveau, die nach Apples Worten gut mit den nativen Performance-Funktionen in iOS zusammenarbeitet. Der Aufbau einer UDP-Verbindung (wobei „Verbindung“ nicht ganz der richtige Begriff ist, es gibt keine Verbindungen in UDP, nur Pakete) geht so einfach vonstatten:
self.connection = NWConnection(host: hostUDP, port: portUDP, using: .udp)
Und das Senden einer Nachricht ist ebenso einfach:
self.connection?.send(content: content)
Leider wird an einem bestimmten Punkt tatsächlich Code bereitgestellt, und dann kommen die Fehlerberichte. Das erste Problem bestand darin, dass aufgrund der Einfachheit der API unmöglich mehr als ein einzelnes UDP-Paket gleichzeitig verarbeitet werden kann. Wir verwenden häufig Pakete von bis zu 1.500 Byte. Bei einem Geschwindigkeitstest auf meiner Google-Fiber-Verbindung bekomme ich derzeit eine Geschwindigkeit von 370 Mbit/s oder fast 31.000 Paketen pro Sekunde. Der Versuch, jedes Paket einzeln zu verarbeiten, machte die Verbindungen um bis zu 40 % langsamer. Nach Angaben von Apple war es für die erforderliche Leistung das Beste, auf die ältere NWUDPSession-API zurückzugreifen, die in iOS 9 eingeführt wurde.
IPv6
Wenn wir den Code zum Erstellen einer NWUDPSession mit dem obigen Beispiel vergleichen, stellen wir fest, dass es plötzlich eine Rolle spielt, welches Protokoll wir verwenden, IPv4 oder IPv6:
let v4Session = NWUDPSession(upgradeFor: self.ipv4Session)
v4Session.setReadHandler(self.filteringReadHandler, maxDatagrams: 32)
Tatsächlich kann NWUDPSession mit vielen der schwierigeren Elemente beim Aufbau von Internetverbindungen nicht umgehen. Beispielsweise bestimmt das Network-Framework automatisch, ob eine Verbindung über IPv4 oder 6 hergestellt werden soll:
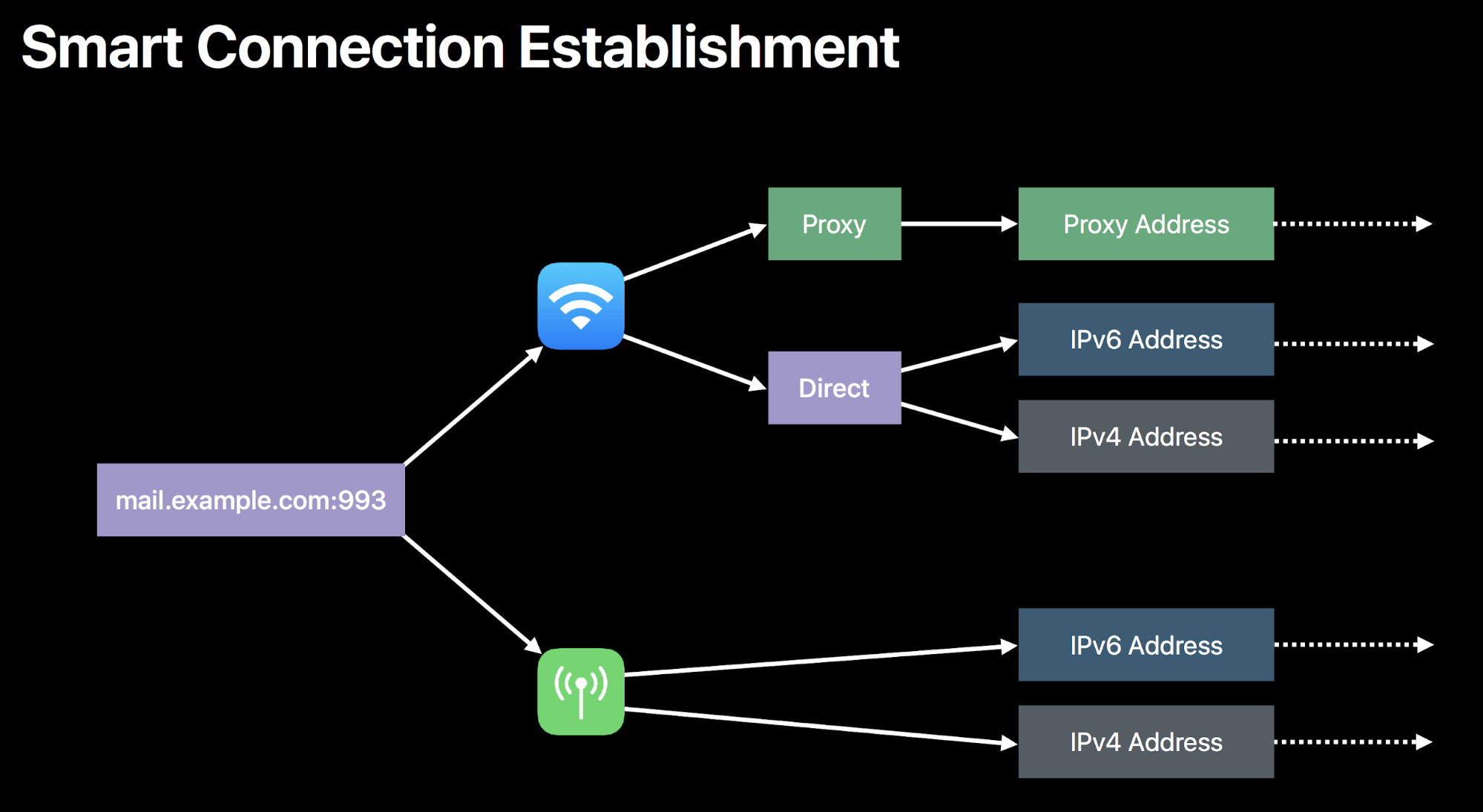
NWUDPSession tut dies nicht selbst, daher fingen wir an, eine eigene Logik zu entwickeln, um den Verbindungstyp zu bestimmen. Als wir mit unseren Versuchen begannen, wurde schnell klar, dass die Protokolle nicht gleichwertig sind. Es kommt ziemlich häufig vor, dass eine Route zum gleichen Ziel abhängig davon, ob man ihre IPv4- oder ihre IPv6-Adresse benutzt, eine sehr unterschiedliche Leistung aufweist. Das hat oft damit zu tun, dass es weniger IPv4-Adressen gibt, diese aber schon länger. Dadurch können diese Routen durch die Infrastruktur des Internets besser optimiert werden.
Jedes Cloudflare-Produkt muss grundsätzlich IPv6 unterstützen. Im Jahr 2016 haben wir über 98 % unseres Netzwerks IPv6-fähig gemacht, das sind über vier Millionen Websites. Damit haben wir die Akzeptanz von IPv6 im Web ein ordentliches Stück vorangebracht:
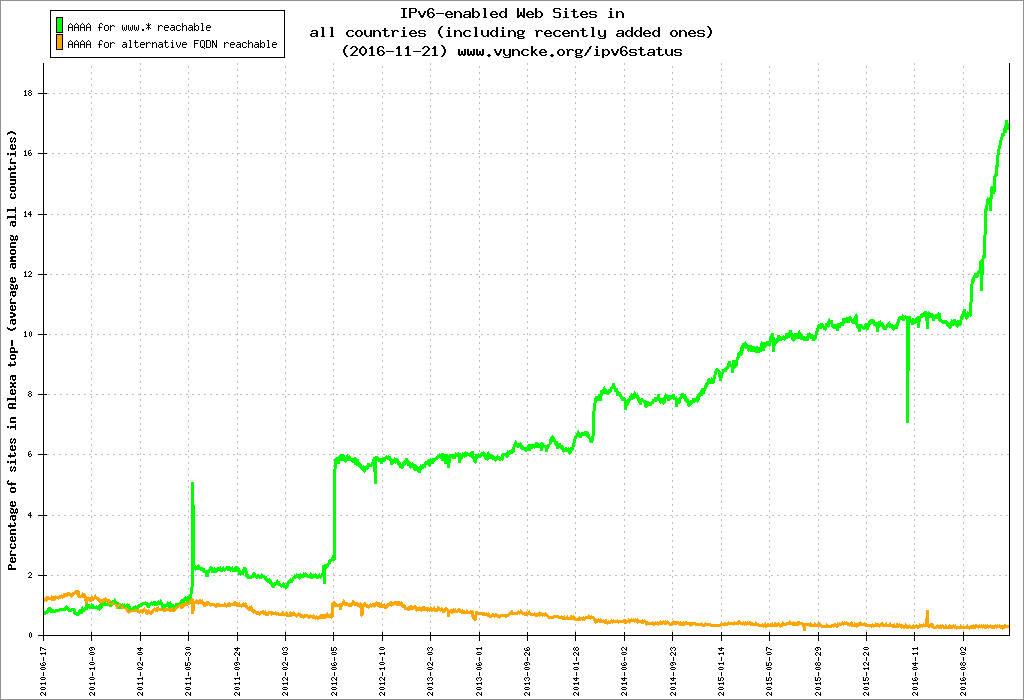
Wir konnten WARP nicht ohne IPv6-Unterstützung veröffentlichen. Wir mussten gewährleisten, dass immer die schnellstmögliche Verbindung benutzt wird, und gleichzeitig beide Protokolle in gleichem Maß unterstützen. Um das zu lösen, haben wir uns einer Technologie zugewandt, die wir bei DNS schon jahrelang nutzen: Happy Eyeballs. Wie in RFC 6555 festgelegt, besteht der Grundgedanke bei Happy Eyeballs darin, bei einem DNS-Lookup sowohl nach einer IPv4- als auch nach einer IPv6-Adresse zu suchen. Was man zuerst findet, hat gewonnen. So können IPv6-Websites selbst in einer Welt, die IPv6 nicht vollständig unterstützt, schnell geladen werden.
Als Beispiel lade ich jetzt die Website http://zack.is/. Mein Webbrowser macht gleichzeitig eine DNS-Anfrage nach der IPv4-Adresse („A“-Eintrag) und nach der IPv6-Adresse („AAAA“-Eintrag):
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 1.1.1.1
User Datagram Protocol, Src Port: 47447, Dst Port: 53
Domain Name System (query)
Queries
zack.is: type A, class IN
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 1.1.1.1
User Datagram Protocol, Src Port: 49946, Dst Port: 53
Domain Name System (query)
Queries
zack.is: type AAAA, class INIn diesem Fall wurde die Antwort auf die A-Abfrage schneller zurückgegeben und die Verbindung mit diesem Protokoll gestartet:
Internet Protocol Version 4, Src: 1.1.1.1, Dst: 192.168.7.21
User Datagram Protocol, Src Port: 53, Dst Port: 47447
Domain Name System (response)
Queries
zack.is: type A, class IN
Answers
zack.is: type A, class IN, addr 104.24.101.191
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.24.101.191
Transmission Control Protocol, Src Port: 55244, Dst Port: 80, Seq: 0, Len: 0
Source Port: 55244
Destination Port: 80
Flags: 0x002 (SYN)
Wir brauchen keine DNS-Abfragen, um WARP-Verbindungen herzustellen, denn wir kennen die IP-Adressen unserer Rechenzentren schon. Aber wir möchten wissen, ob die IPv4- oder die IPv6-Adresse zu einer schnelleren Route über das Internet führt. Dazu setzen wir die gleiche Technik auf Netzwerkebene ein: Wir senden ein Paket über jedes Protokoll. Für weitere Nachrichten verwenden wir das Protokoll, das zuerst geantwortet hat. Das sieht dann so aus (wir haben aus Gründen der Übersichtlichkeit etwas Fehlerbehandlung und Protokollierung weggelassen):
let raceFinished = Atomic<Bool>(false)
let happyEyeballsRacer: (NWUDPSession, NWUDPSession, String) -> Void = {
(session, otherSession, name) in
// Session is the session the racer runs for, otherSession is a session we race against
let handleMessage: ([Data]) -> Void = { datagrams in
// This handler will be executed twice, once for the winner, again for the loser.
// It does not matter what reply we received. Any reply means this connection is working.
if raceFinished.swap(true) {
// This racer lost
return self.filteringReadHandler(data: datagrams, error: nil)
}
// The winner becomes the current session
self.wireguardServerUDPSession = session
session.setReadHandler(self.readHandler, maxDatagrams: 32)
otherSession.setReadHandler(self.filteringReadHandler, maxDatagrams: 32)
}
session.setReadHandler({ (datagrams) in
handleMessage(datagrams)
}, maxDatagrams: 1)
if !raceFinished.value {
// Send a handshake message
session.writeDatagram(onViable())
}
}
Mit dieser Technik können wir IPv6-Adressierung erfolgreich unterstützen. Tatsächlich unterstützt jedes Gerät, das WARP verwendet, sofort die IPv6-Adressierung. Das gilt auch in Netzwerken, die sie selbst nicht unterstützen. Durch WARP können Benutzer der 34 % des Comcast-Netzwerks, die IPv6 nicht unterstützen, oder der 69 % des Charter-Netzwerks, für die dies ebenfalls gilt (Stand 2018), erfolgreich mit IPv6-Servern kommunizieren.
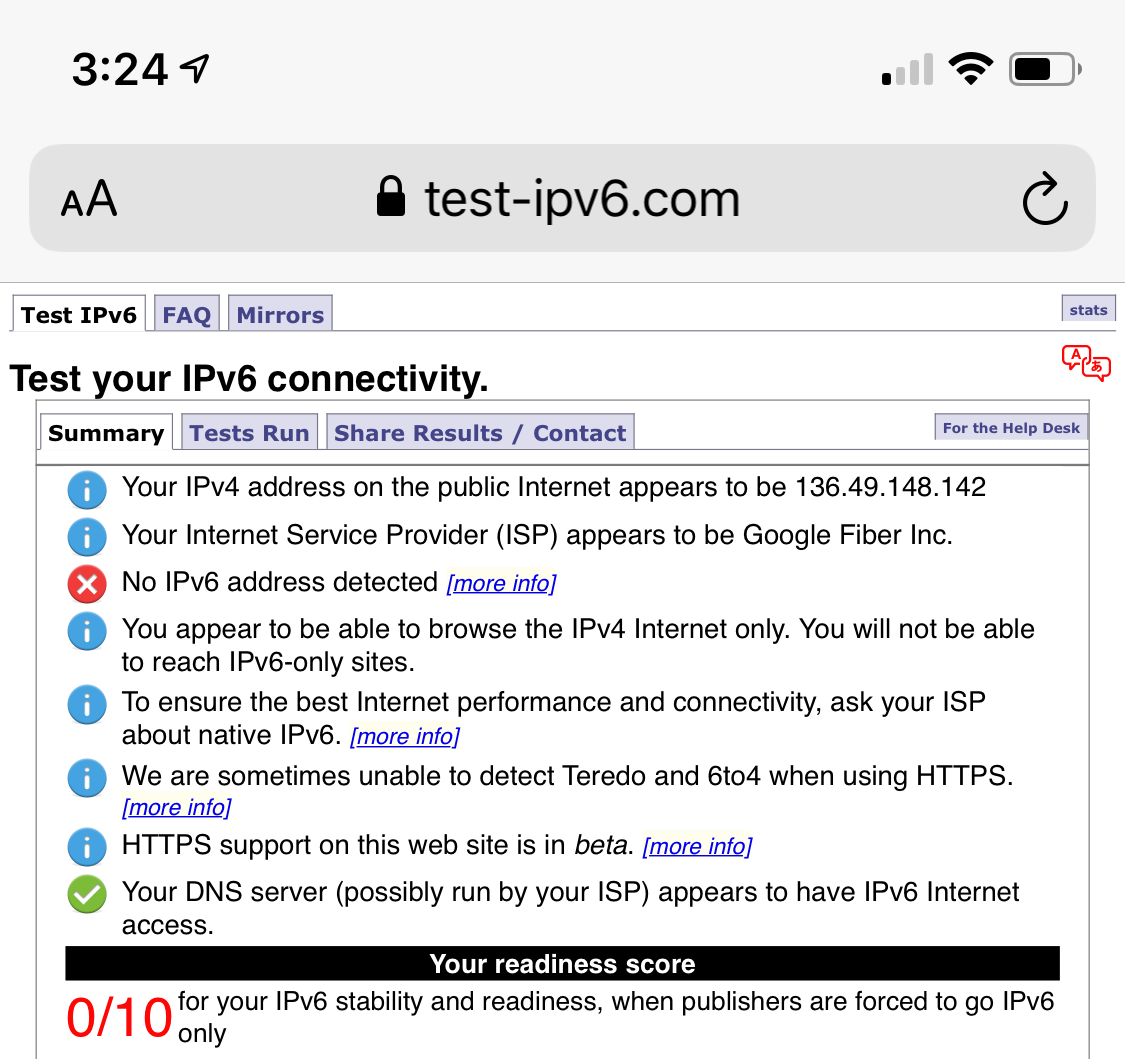
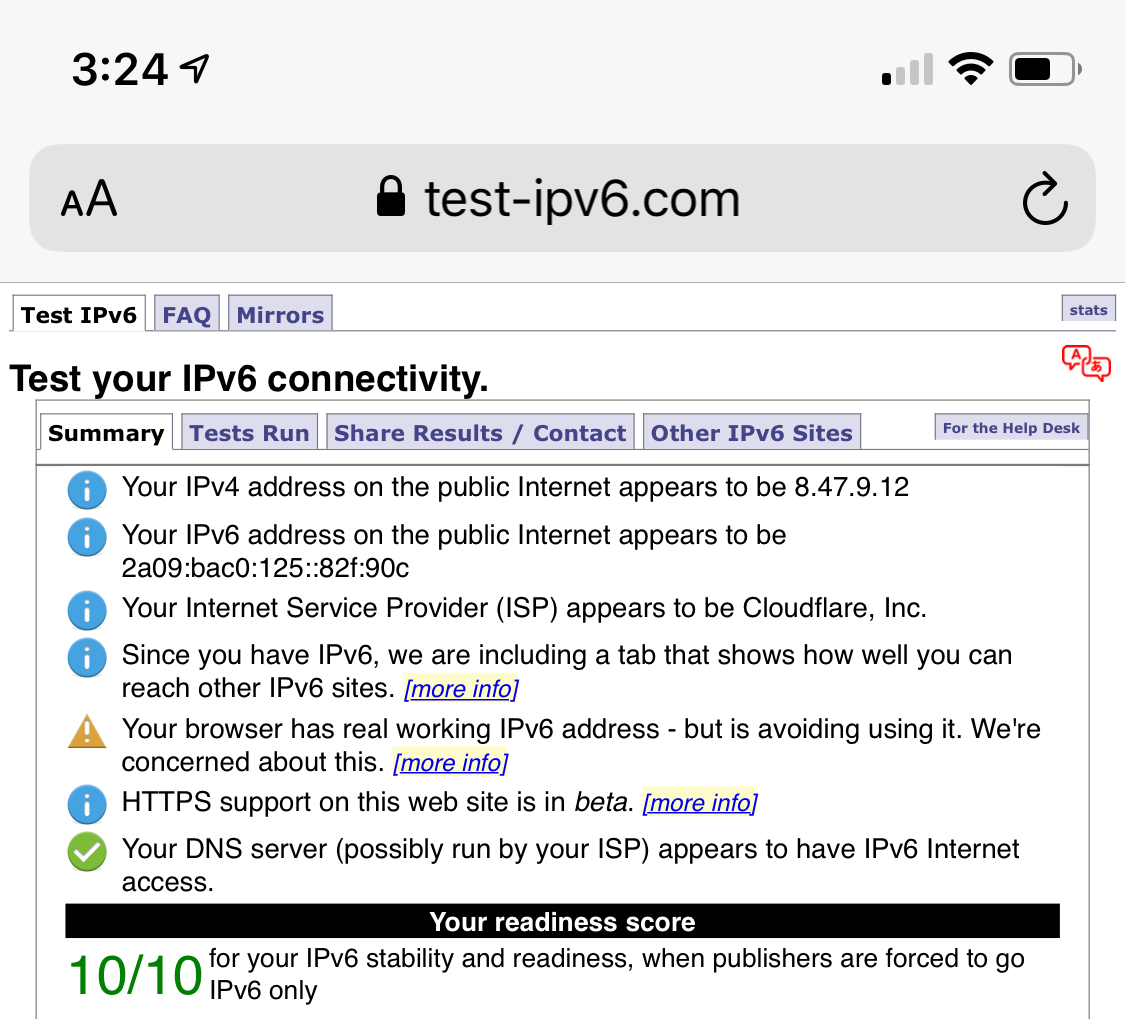
Dieser Test zeigt, wie mein Smartphone vor und nach der WARP-Aktivierung IPv6 unterstützt:
Verbindungsabbrüche
Aber nichts ist so einfach, wie es auf den ersten Blick scheint. Bei iOS 12.2 führte NWUDPSession plötzlich zu Fehlern und in der Folge zu Verbindungsabbrüchen. Diese Fehler waren nur mit dem Code „55“ gekennzeichnet. Recherchen zufolge scheint 55 schon seit den ersten Anfängen des Betriebssystems FreeBSD, das die ursprüngliche Basis von OS X war, auf den gleichen Fehler zu verweisen. Dieser wird in FreeBSD gemeinhin als ENOBUFS bezeichnet und zurückgegeben, wenn das Betriebssystem für den durchgeführten Vorgang nicht genügend Puffer-Speicherplatz hat. Wenn Sie sich beispielsweise einen heutigen FreeBSD-Quellcode ansehen, finden Sie diesen Code in seiner IPv6-Implementierung:

Wenn in diesem Beispiel nicht genügend Arbeitsspeicher für die Größe eines IPv6- und ICMP6-Headers reserviert werden kann, wird der Fehler ENOBUFS (dem die Zahl 55 zugeordnet ist) zurückgegeben. Leider setzt Apple bei seiner Variante von FreeBSD jedoch nicht auf Open Source: Wie, wann und warum der Fehler bei Apple zurückgegeben wird, ist ein Geheimnis. Dieser Fehler ist auch bei anderen UDP-basierten Projekten aufgetreten, aber eine Lösung ist nicht in Sicht.
Eins ist allerdings klar: Wenn ein Fehler 55 auftritt, ist die Verbindung unbrauchbar geworden. In diesem Fall müssen wir die Verbindung neu aufbauen. Dazu müssen wir aber nicht wieder den gleichen Happy-Eyeballs-Mechanismus durchlaufen wie beim ersten Verbindungsaufbau. Das ist unnötig – wir kommunizieren ja bereits über die schnellste Verbindung – und wäre zeitraubend. Stattdessen setzen wir eine zweite Verbindungsmethode ein, die nur zum Neuaufbau einer bereits funktionierenden Sitzung verwendet wird:
/**
Create a new UDP connection to the server using a Happy Eyeballs like heuristic.
This function should be called when first establishing a connection to the edge server.
It will initiate a new connection over IPv4 and IPv6 in parallel, keeping the connection that receives the first response.
*/
func connect(onViable: @escaping () -> Data, onReply: @escaping () -> Void, onFailure: @escaping () -> Void, onDisconnect: @escaping () -> Void)
/**
Recreate the current connections.
This function should be called as a response to error code 55, when a quick connection is required.
Unlike `happyEyeballs`, this function will use viability as its only success criteria.
*/
func reconnect(onViable: @escaping () -> Void, onFailure: @escaping () -> Void, onDisconnect: @escaping () -> Void)
Mit reconnect können wir Sitzungen neu aufbauen, die durch Code-55-Fehler unterbrochen wurden, aber hierdurch entsteht zusätzliche Latenz, die natürlich eher unerwünscht ist. Wie bei allen Entwicklungsprojekten von Clientsoftware auf einer Closed-Source-Plattform sind wir jedoch darauf angewiesen, dass Fehler auf Plattformebene identifiziert und behoben werden.
Und dies ist tatsächlich nur einer aus einer langen Liste von plattformspezifischen Fehlern, auf die wir bei der Entwicklung von WARP gestoßen sind. Wir hoffen, dass wir weiterhin mit Geräteanbietern zusammenarbeiten können, um diese Fehler zu beheben. Die Anzahl der Kombinationen von Geräten und Verbindungen ist unvorstellbar hoch und jede Verbindung existiert nicht nur zu einem einzigen Zeitpunkt. Sie verändert sich ständig, Fehlerzustände treten ein und werden aufgehoben, und das fast schneller, als wir nachverfolgen können. Das Problem, WARP auf jedem Gerät und jeder Verbindung der Welt zum Laufen zu bringen, ist bis heute noch nicht gelöst. Wir erhalten weiterhin täglich Fehlerberichte, die wir untersuchen, testen und lösen.
WARP+
WARP soll ein Ort für Optimierungen sein, die das Internet besser machen. Wir haben eine Menge Erfahrung darin, die Leistung von Websites zu steigern. Durch WARP können wir ausprobieren, wie wir das gleiche für den gesamten Internetverkehr erreichen.
Bei Cloudflare haben wir ein Produkt namens Argo. Argo verkürzt bei Websites die „Zeit bis zum ersten Byte“ im Durchschnitt um über 30 %. Dazu werden Tausende von Internetrouten zwischen unseren Rechenzentren kontinuierlich beobachtet. Diese Daten ergeben eine Datenbank, in der für jeden IP-Adressbereich die schnellstmögliche Route zu jedem Ziel aufgeführt ist. Wenn ein Paket eintrifft, erreicht es zuerst das Rechenzentrum, das dem Client am nächsten liegt. Dieses Rechenzentrum ermittelt dann mithilfe der Daten aus unseren Tests die Route, über die das Paket mit der geringstmöglichen Latenz ans Ziel gelangt. Man kann sich das wie ein Navi für das Internet vorstellen, das auch Verkehrsmeldungen einbezieht.
Argo hat bisher nur mit HTTP-Paketen funktioniert. HTTP ist das Protokoll des Webs. Über dieses Protokoll werden auf Grundlage von TCP und IP die Nachrichten versendet, mit denen Websites geladen werden. Wenn ich beispielsweise http://zack.is lade, wird innerhalb eines TCP-Pakets eine HTTP-Nachricht gesendet:
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.24.101.191
Transmission Control Protocol, Src Port: 55244, Dst Port: 80
Source Port: 55244
Destination Port: 80
TCP payload (414 bytes)
Hypertext Transfer Protocol
GET / HTTP/1.1\r\n
Host: zack.is\r\n
Connection: keep-alive\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: en-US,en;q=0.9\r\n
\r\n
Durch das moderne und sichere Web stehen wir jedoch vor einem Problem: Wenn ich dieselbe Anfrage über HTTPS (https://zack.is) statt nur über HTTP (http://zack.is) mache, wird etwas ganz anders übertragen:
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.25.151.102
Transmission Control Protocol, Src Port: 55983, Dst Port: 443
Source Port: 55983
Destination Port: 443
Transport Layer Security
TCP payload (54 bytes)
Transport Layer Security
TLSv1.2 Record Layer: Application Data Protocol: http-over-tls
Encrypted Application Data: 82b6dd7be8c5758ad012649fae4f469c2d9e68fe15c17297…
Meine Anfrage wurde verschlüsselt! Weder WARP noch irgendjemand sonst außer dem Ziel kann jetzt noch erkennen, was sich in den Nutzdaten befindet. Es könnte HTTP, aber auch jedes andere Protokoll sein. Wenn meine Website schon eine der zwanzig Millionen Websites ist, die Cloudflare nutzen, können wir den Traffic entschlüsseln und beschleunigen (und eine lange Liste anderer Optimierungen durchführen). Aber für verschlüsselten Traffic, der für eine Nur-HTTP-Quelle bestimmt war, funktionierte die Argo-Technologie nicht.
Zum Glück haben wir durch unsere Produkte Spectrum und Magic Transit inzwischen viel Erfahrung mit Nicht-HTTP-Traffic sammeln können. Um unser Problem zu lösen, wandte sich das Argo-Team dem CONNECT-Protokoll zu.
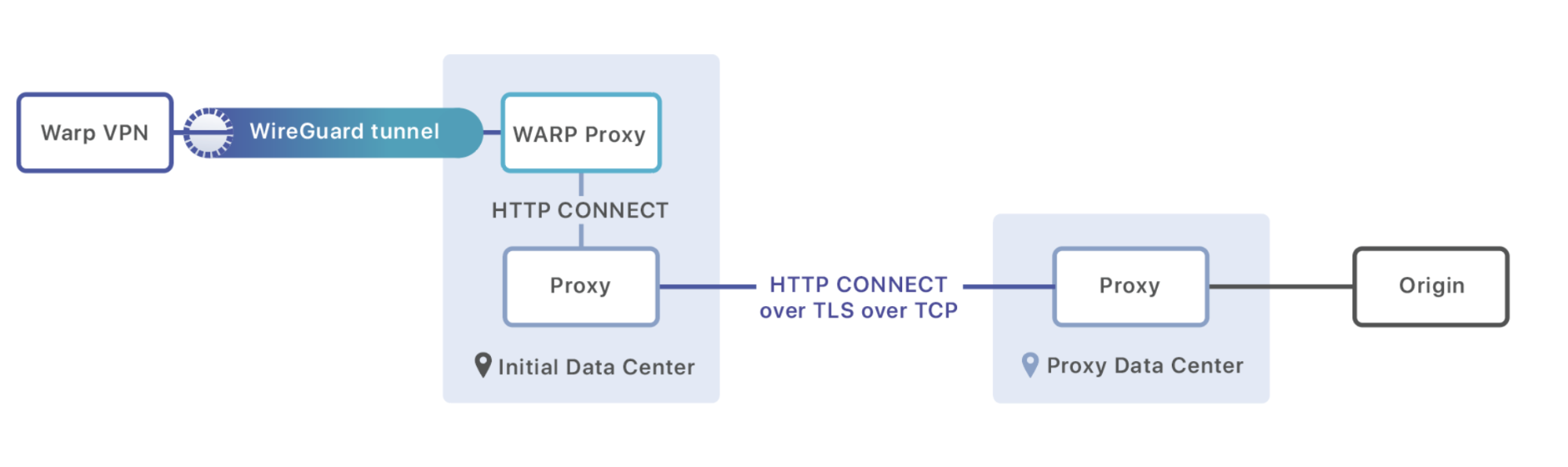
Wie wir jetzt wissen, kommuniziert eine WARP-Anfrage zuerst über das WireGuard-Protokoll mit einem Server in einem unserer 194 Rechenzentren auf der ganzen Welt. Nach der Entschlüsselung der WireGuard-Nachricht untersuchen wir die Ziel-IP-Adresse und stellen fest, ob es sich um eine HTTP-Anfrage an eine Cloudflare-basierte Website oder eine Anfrage für ein anderes Ziel handelt. Wenn sie für uns bestimmt ist, geht es mit unserem Standard-HTTP-Verfahren weiter. Oft können wir die Anfrage direkt aus dem Cache im selben Rechenzentrum beantworten.
Wenn die Anforderung nicht für eine Cloudflare-basierte Website bestimmt ist, leiten wir das Paket stattdessen an einen Proxy-Prozess weiter, der auf jedem Rechner ausgeführt wird. Dieser Proxy ist dafür zuständig, den schnellsten Pfad aus unserer Argo-Datenbank zu laden und eine HTTP-Sitzung auf einem Rechner im Rechenzentrum aufzubauen, an den dieser Traffic weitergeleitet werden soll. Mithilfe des Befehls CONNECT werden Metadaten (als Header) übertragen und die HTTP-Sitzung in eine Verbindung umgewandelt, über die die Rohbyte der Nutzdaten übertragen werden:
CONNECT 8.54.232.11:5564 HTTP/1.1\r\n
Exit-Tcp-Keepalive-Duration: 15\r\n
Application: warp\r\n
\r\n
<data to send to origin>
Sobald die Nachricht im Ziel-Rechenzentrum eintrifft, wird sie entweder an ein anderes Rechenzentrum (wenn hierdurch die beste Performance gewährleistet ist) oder direkt an den Ursprungsserver weitergeleitet, der auf den Traffic wartet.
Intelligentes Routing ist nur der erste Schritt bei WARP+. Wir haben noch viele Projekte und Pläne auf unserer Liste. Bei allen geht es darum, das Internet für Sie schneller zu machen. Wir sind restlos begeistert darüber, endlich eine Plattform zu haben, mit der wir sie testen können.
Unsere Mission
Heute, nach weit über einem Jahr Entwicklungszeit, steht WARP für Sie und Ihre Freunde und Angehörigen bereit. Für uns ist das aber erst der Anfang. Die Möglichkeit, die Netzwerkverbindungen für den gesamten Traffic zu verbessern, eröffnet uns eine ganz neue Welt von Optimierungen und Sicherheitsverbesserungen, die vorher einfach unmöglich waren. Wir finden es ungeheuer spannend zu experimentieren, herumzuprobieren und schließlich alle möglichen neuen WARP- und WARP+-Funktionen zu veröffentlichen.
Die Mission von Cloudflare besteht darin, das Internet besser zu machen. Wenn wir bereit sind, gemeinsam zu experimentieren und schwierige technische Probleme zu lösen, dann können wir das Internet von morgen besser gestalten als das Internet von heute. Und wir freuen uns über die Chance, dazu beizutragen. Vielen Dank dafür, dass Sie uns Ihre Internetverbindung anvertraut haben.
WARP wurde entwickelt von Oli Yu, Vlad Krasnov, Chris Branch, Dane Knecht, Naga Tripirineni, Andrew Plunk, Adam Schwartz, Irtefa und Praktikantin Michelle Chen, unterstützt von Mitarbeitern unserer Büros in Austin, San Francisco, Champaign, London, Warschau und Lissabon.