


API มีความสำคัญอย่างไม่น่าเชื่อ ตลอดช่วงทศวรรษ 2000 โดย API ถือเป็นแกนหลักของบริการเว็บยอดนิยม ซึ่งช่วยให้อินเทอร์เน็ตมีประโยชน์และเข้าถึงได้มากขึ้น ในช่วงทศวรรษ 2010 API มีบทบาทมากขึ้นในชีวิตของเรา ทำให้อุปกรณ์ส่วนบุคคลสามารถสื่อสารกับโลกดิจิทัลได้ กิจกรรมประจำวันหลาย ๆ กิจกรรมของเรา เช่น การใช้บริการเครือข่ายคมนาคมและซื้อกาแฟล้วนขึ้นอยู่กับรูปแบบการสื่อสารสมัยใหม่นี้ และในทุกวันนี้ เรากำลังเข้าสู่โลกหลังการระบาดใหญ่ที่ API จะมีความสำคัญมากกว่าที่เคย
น่าเสียดายที่เทคโนโลยีต่าง ๆ เติบโตขึ้น ดังนั้น พื้นที่ที่เปิดให้เกิดการละเมิดก็เติบโตขึ้นด้วย และ API ก็เป็นหนึ่งในนั้นเช่นกัน บริการเครือข่ายคมนาคมที่แข่งขันกันอาจมีการตรวจสอบค่าบริการของกันและกันผ่าน API ทำให้เกิดสงครามราคาและสิ้นเปลืองทรัพยากรดิจิทัล หรือนักดื่มกาแฟอาจใช้ API เพื่อรับส่วนลดกาแฟลาเต้ของตน บางบริษัทมี API นับพันรายการ ซึ่งรวมไปถึง API ที่ตนเองไม่เคยรู้จักเสียด้วยซ้ำ ซึ่ง Cloudflare สามารถช่วยแก้ปัญหาเหล่านี้ได้
ในวันนี้ เรากำลังเปิดตัวการเข้าใช้งาน API Discovery และ API Abuse Detection ล่วงหน้า
ภูมิหลัง
ก่อนที่จะดำเนินการต่อไป สิ่งที่สำคัญคือเราควรอธิบายเหตุผลที่เราต้องการโซลูชันสำหรับ API นั่นก็ด้วยเครื่องมือรักษาความปลอดภัยแบบดั้งเดิม ซึ่งประกอบด้วยการจำกัดอัตราและการป้องกัน DDoS นั้นมีประโยชน์อย่างยิ่ง แต่วิธีการเหล่านี้ไม่ได้สร้างขึ้นเพื่อให้ทำงานได้ด้วยตัวเอง เราอาจให้กำหนดจำกัดของ API endpoint เฉพาะได้ แต่เราจะเลือกขีดจำกัดที่เหมาะสมได้อย่างไร งานนี้ทำได้ยากยิ่งหากต้องทำในสเกลขนาดใหญ่โดยไม่ก่อให้เกิดปัญหา เนื่องจาก API อาจได้รับผลกระทบจากการโจมตีแบบกระจาย (ต่ำกว่าขีดจำกัด) หรืออาจมีปัญหาเมื่อต้องการรับส่งข้อมูลที่ถูกต้องเพิ่มมากขึ้น (เกินขีดจำกัด)
มีผู้แนะนำให้ทำการใช้งานตัว Bot Management บน API endpoint ซึ่งในหลาย ๆ กรณี วิธีนี้ได้ผลและเพิ่มระดับการป้องกันได้ โดยเฉพาะอย่างยิ่งหาก API นั้นมีไว้สำหรับเบราว์เซอร์ (เป็นส่วนหนึ่งของเว็บแอปพลิเคชัน) แต่ Bot Management ได้รับการออกแบบมาเพื่อค้นหาตัวตีเนียนที่แฝงในหมู่ผู้ใช้งานที่เป็นมนุษย์ ซึ่งตัวตีเนียนนี้มักใช้ระบบอัตโนมัติ ในขณะที่มนุษย์มักใช้เบราว์เซอร์ ความแตกต่างจึงค่อนข้างชัดเจน แต่ API มีปัญหาที่แตกต่างออกไป เพราะ API เป็นแบบอัตโนมัติ ดังนั้น โซลูชันใดก็ตามจะต้องสามารถค้นหาบอทที่ไม่ดีท่ามกลางบอทอื่น ๆ เราจึงต้องแยกความแตกต่างระหว่างการรับส่งข้อมูลอัตโนมัติที่ดีและไม่ดีให้ชัดเจน
เพื่อแก้ปัญหาของ API เราต้องสร้างมาตรวัดเจตนา — ที่แทบจะเหมือนกับการสัมภาษณ์แต่ละการร้องขอเพื่อกำหนดเป้าหมาย โดยเราต้องตอบคำถามต่อไปนี้ตามข้อมูลสถานการณ์แต่เพียงอย่างเดียว:
- การร้องขอนี้ใช้ API ตามจุดประสงค์หรือไม่
- การร้องขอนี้แสดงพฤติกรรมที่น่าสงสัยหรือไม่ ดัวยเหตุผลใด
ก็เช่นเดิม ในขณะที่เครื่องมืออย่างเช่นการจำกัดอัตราสามารถจัดการกับปัญหาไบนารี (เช่น "IP นี้มีการร้องขอเกิน 200 รายการหรือไม่") แต่ปัญหา API ต้องการผู้ตัดสินที่อิงตามอัตวิสัยมากกว่า ทำให้เราต้องตรวจสอบจุดประสงค์ของ API และกำหนดข้อจำกัดที่สมเหตุสมผลตามสิ่งที่เราพบ อีกทั้งเรายังต้องค้นหาแหล่งความจริงพื้นฐานใหม่ ดังนั้น เมื่อเราสร้าง Bot Management เราจะสามารถยืนยันได้ว่าการร้องขอเป็นการร้องขอของมนุษย์หรือเป็นแบบอัตโนมัติด้วยการยื่นคำถามไปให้ ซึ่ง API ที่เกี่ยวข้องกับระบบอัตโนมัติย่อมไม่สามารถพิสูจน์ความถูกต้องด้วยการแก้ปัญหานั้นได้
หลังจากการแก้ไขปัญหานี้มานานหลายเดือน เรารู้สึกตื่นเต้นมากที่จะให้ทุกท่านได้เห็นโซลูชันของเราเป็นครั้งแรก ซึ่งเป็นเพียงแค่ส่วนหนึ่งเท่านั้น…
API Discovery
ผู้ใช้บางคนบอกเราว่าพวกเขาไม่สามารถติดตาม API ของตนเองได้ ก่อนที่เราจะพยายามปกป้อง endpoint เหล่านี้ เราต้องกำหนดรายละเอียดและทำความเข้าใจพื้นที่การโจมตี โดยเราเรียกสิ่งนี้ว่า "API Discovery"

กระบวนการค้นหาเริ่มต้นด้วยการสรุปให้ง่าย เว็บไซต์ขนาดใหญ่อาจมี API นับพัน แต่การเรียกใช้หลาย ๆ ครั้งก็ดูคล้ายคลึงกัน ลองดูเส้นทางสองเส้นทางต่อไปนี้:
- api.example.com/login/237
- api.example.com/login/415
ในตัวอย่างนี้ “237” และ “415” คือตัวระบุลูกค้า ทั้งสองเส้นทางมีจุดประสงค์เดียวกัน คือการอนุญาตให้ผู้ใช้ลงชื่อเข้าใช้บัญชี แต่ก็มีความแตกต่างกัน ดังนั้น เราจึงกำหนดเส้นทางใหม่และรวมให้เป็นเส้นทางนี้ทันที:
- api.example.com/login/*
- api.example.com/login/*
ให้สังเกตวิธีที่เราใช้ลบตัวระบุลูกค้า ระบบของเราสามารถตรวจจับส่วนที่ API เปลี่ยนแปลงไปได้ ทำให้เรารู้ว่าเส้นทางทั้งสองเป็นเส้นทางเดียวกัน ซึ่งเราสามารถทำสิ่งนี้ได้โดยการบันทึกจำนวนสมาชิกในเซ็ตของแต่ละจุดปลายทาง เช่น ในตอนแรกเราอาจพบว่ามีสตริงที่แตกต่างกันอยู่ 700 สตริงในตำแหน่งที่มีเครื่องหมายดอกจัน ซึ่ง “237” และ “415” เป็นเพียงสองความเป็นไปได้เหล่านั้น จากนั้นเราจึงใช้ unsupervised learning จัดการเพื่อเลือกขีดจำกัด (ในกรณีนี้ สมมุติว่า 30) เนื่องจากเราสังเกตเห็นรูปแบบเส้นทางนี้มากกว่า 30 รูปแบบ เราจึงทราบว่าตัวระบุลูกค้านั้นเป็นตัวแปรแล้วจึงทำการยุบเส้นทาง กระบวนการนี้เรียกว่า "path normalization"
API Discovery เป็นส่วนประกอบสำคัญสำหรับผลิตภัณฑ์ความปลอดภัยมากมายที่จะมีต่อมาในภายหลัง แต่โดยแก่นแท้แล้ว เทคโนโลยีนี้เกี่ยวกับการสร้างแผนที่ API ที่เรียบง่ายและไว้วางใจได้ นี่คือตัวอย่างเล็ก ๆ น้อย ๆ ที่คุณอาจพบเจอ:
login/<customer_identifier>
auth
account/<customer_identifier>
password_reset
logout
ลองนึกภาพรายการนี้ขยายไปเป็นร้อย หรืออีกพันกว่า endpoint คุณจะเห็นภาพบางอย่างชัดเจน (หวังว่าจะมี endpoint สำหรับให้เข้าสู่ระบบ!) แต่คนอื่นอาจจะแปลกใจ การกำหนดรายละเอียดสุดท้ายจะช่วยระบุตัวแปรหรือโทเค็นที่แต่ละ endpoint ใช้อ้างอิง
การตรวจจับการละเมิดตามปริมาณ
ในตอนนี้ เราทราบ API แล้ว เราจึงสามารถเริ่มค้นหาการละเมิดได้ วิธีแรกของเราจะจัดการกับความผิดปกติเชิงปริมาตร กล่าวอีกนัยหนึ่งคือ เราจะทำการคาดเดาแบบมีการศึกษาในเรื่องความถี่ที่แต่ละเส้นทางเข้าถึง และกำหนดขีดจำกัดบางอย่างเพื่อจัดการการละเมิด ซึ่งนี่เป็นรูปแบบหนึ่งของการจำกัดอัตราการที่ปรับเปลี่ยนได้
ลองพิจารณาเส้นทาง API /update-score สำหรับเว็บไซต์กีฬา คุณอาจเดาได้ว่าสิ่งนี้ใช้ทำอะไร สิ่งนี้มักจะเรียกข้อมูลคะแนนล่าสุดของการแข่งขัน ซึ่งอาจเกิดขึ้นหลายครั้งต่อวินาที เราอาจปรับใช้ unsupervised learning จัดการแล้วตั้งค่าขีดจำกัดให้สูงสำหรับการใช้งานปกติ บางทีอาจจะถึง 150 การร้องขอต่อนาทีสำหรับ IP เฉพาะ ตัวแทนผู้ใช้ หรือตัวระบุ session อื่น ๆ
แต่เว็บไซต์กีฬาเดียวกันนั้นอาจกำหนดให้ผู้ใช้ต้องมีบัญชี ในกรณีนี้ อาจมี /reset-password API แยกต่างหากอยู่ในโดเมนเดียวกัน คงไม่มีแฟนกีฬาคนใดที่จะรีเซ็ตรหัสผ่านหลายครั้งเท่ากับการดูคะแนน ดังนั้นเส้นทางนี้จึงน่าจะใช้ขีดจำกัดที่ต่ำกว่า ความดีงามของ unsupervised learning (และรูปแบบการตรวจจับการละเมิดของเรา) คือ การที่เราศึกษารายละเอียดเว็บไซต์ของคุณ พัฒนาแนวฐานที่แยกจากกันสำหรับแต่ละ API และพยายามคาดการณ์เจตนาของการร้องขอที่เกิดขึ้น หากเราพบว่ามีการพยายามรีเซ็ตรหัสผ่านอย่างกะทันหัน 150 ครั้ง ระบบของเราจะสงสัยว่ามีการเข้ายึดบัญชีทันที
สิ่งสำคัญคือ เราต้องเข้าใจเหตุผลที่การรับส่งข้อมูลเปลี่ยนไปเมื่อเกิดการเปลี่ยนแปลง เช่น เราไม่ควรบล็อกการรับส่งข้อมูลด้านกีฬาเมื่อมีการรับส่งข้อมูลสูงขึ้นเนื่องจากรอบชิงชนะเลิศ NBA แม้ว่าปลายทาง /update-score อาจพบการใช้งานสูงมากกว่าเดิมชั่วคราว แต่ Cloudflare จะรับรู้บริบทที่กว้างกว่านั้นแล้วเปลี่ยนขีดจำกัดที่เกี่ยวข้อง เพราะเราเพียงแค่ต้องการลดทอนกรณีที่มีผู้ใช้งานปลายทางในทางที่ผิดเท่านั้น
การตรวจจับการละเมิดโดยดูจากความต่อเนื่อง
ทีมงานของเรามักใช้แบบจำลอง Swiss Cheese เพื่อการรักษาความปลอดภัย แนวทางนี้ถูกใช้ในการดูแลสุขภาพ การรักษาความปลอดภัยทางกายภาพ และอุตสาหกรรมอื่น ๆ มากมาย ซึ่งแนวคิดนี้เรียบง่ายมาก การป้องกันเลเยอร์ใด ๆ จะมีช่องโหว่อยู่บ้างสองสามช่อง แต่การวางแนวป้องกันที่ไม่ซ้ำกัน (หรือแผ่นชีสหลาย ๆ แผ่น) ไว้ซ้อนกันจะช่วยเพิ่มความปลอดภัยโดยรวมได้
ในโลกของการรักษาความปลอดภัยทางอินเทอร์เน็ต เราเรียกสิ่งนี้ว่า "การป้องกันในเชิงลึก" โดยเราจะใช้ชุดความปลอดภัยของ Cloudflare (เช่น DDoS) เพื่อป้องกัน API เป็นเลเยอร์แรก ในเลเยอร์ที่สองจะใช้การตรวจจับเชิงปริมาตร (ตามที่อธิบายไว้ด้านบน) ส่วนเลเยอร์ที่สามนั้นจะแตกต่างจากสิ่งที่เราเคยทำมาก่อนอย่างสิ้นเชิง นั่นคือการตรวจจับความผิดปกติตามลำดับ ซึ่งเราคาดหวังว่าสิ่งนี้จะเปลี่ยนภาพรวมของ API ได้อย่างมาก
และนี่คือวิธีการทำงาน ตามปกติแล้ว เราจะเริ่มต้นด้วยการทำให้เส้นทางเป็นมาตรฐาน เพื่อค้นหาชุดของสถานะที่มีจำกัด ในการทดสอบหนึ่งครั้ง กระบวนการนี้จะลดสถานะจากราว 10,000 สถานะลงเหลือเพียง 60 สถานะ ซึ่งทำให้ปัญหาของ API นั้นง่ายขึ้นอย่างมาก จากนั้น เราจะใช้ Markov Chains เพื่อสร้างเมทริกซ์การเปลี่ยนแปลง ซึ่งเป็นรายละเอียดของทุกสถานะและตำแหน่งที่มักจะไป จากนั้นเราจะปิดท้ายด้วยการกำหนดความน่าจะเป็นให้กับการเปลี่ยนแปลงแต่ละครั้ง
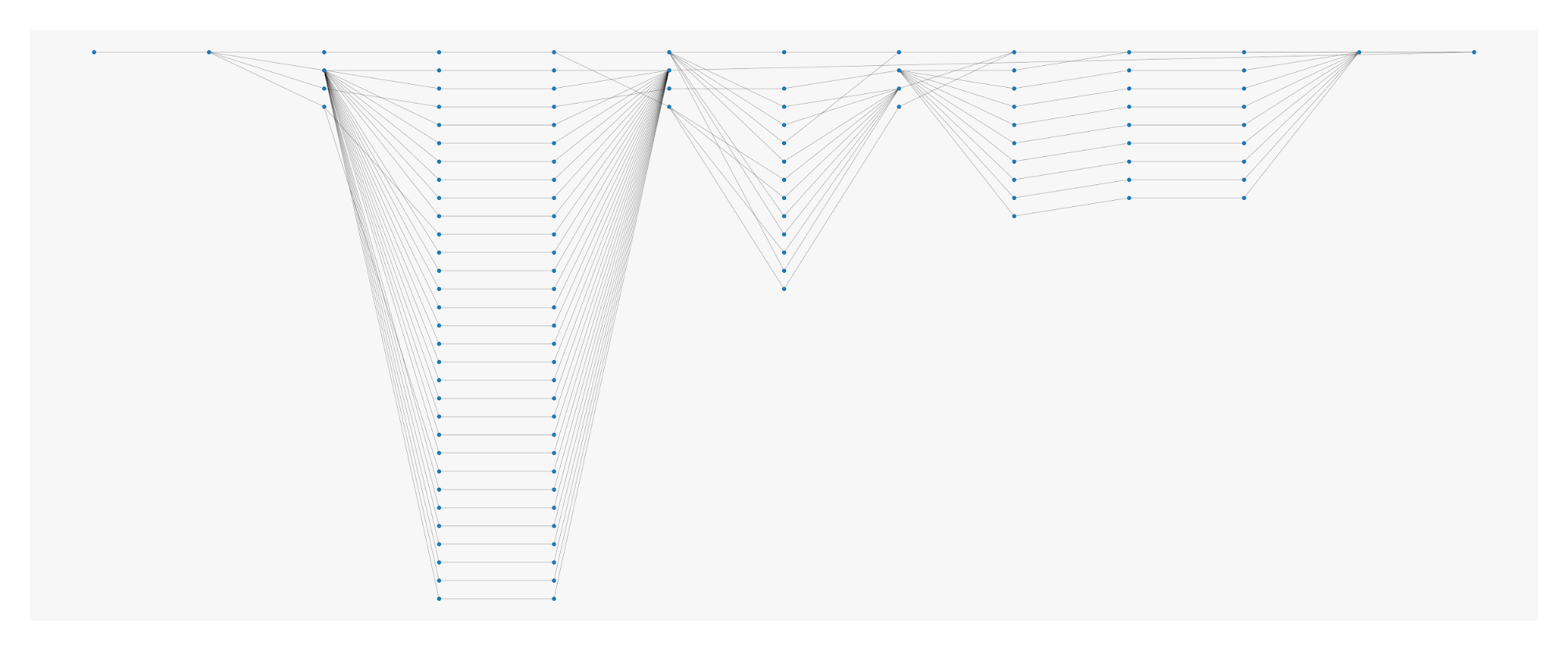
แล้วผลลัพธ์สุดท้ายจะเป็นอย่างไร เราสามารถวาดภาพรวมการเคลื่อนไหวบนเว็บไซต์ได้ ซึ่งอาจประกอบด้วยขั้นตอนต่อไปนี้:
- การส่งการร้องขอไปที่ /login/*/enter
- การเปลี่ยนเส้นทางไปที่ /login/*/verify
- ปลายทางเปลี่ยนเส้นทางไปที่ /login-successful
ดูเหมือนว่าผู้ใช้ที่ถูกต้องพยายามเข้าสู่ระบบ เป็นอีกครั้งที่เราใช้ unsupervised learning เพื่อตรวจจับขั้นตอนเช่นนี้ แต่วิธีการของเราจะตรวจจับค่าที่ผิดปกติด้วยเช่นกัน ในกรณีนี้ เราพบว่า 1 → 2 → 3 เป็นขั้นตอนเชิงตรรกะ แต่ถ้ามีใครที่ข้ามไปที่ขั้นตอนที่ 3 โดยตรงล่ะ เราอาจตั้งค่าสถานการณ์ร้องขอนี้ว่าผิดปกติ
แนวทางที่อาศัย Markov Chains เป็นอย่างมากนี้ค่อนข้างมีประสิทธิภาพ ลองพิจารณาเพิ่มโหนดเดี่ยวลงในห่วงโซ่: แน่นอนว่าห่วงโซ่จะขยายเป็นเส้นตรง แต่ในเมทริกซ์มีการเปลี่ยนแปลง ซึ่งกำหนดความสัมพันธ์ของโหนดที่เป็นไปได้ทั้งหมดนั้น จะเป็นการขยายแบบทวีคูณ แต่เราพบว่าความสัมพันธ์เหล่านี้ส่วนใหญ่นั้นไม่มีอยู่ในการใช้งานจริง เพราะในทางปฏิบัติ ไม่มีใครดำเนินเส้นทางที่ซับซ้อน เช่น ออกจากระบบ → อัปโหลด → รับรองความถูกต้อง การเปลี่ยนแปลงทั่วไปที่อาจดูเหมือนการเข้าสู่ระบบ → อัปเดตผลคะแนน → ออกจากระบบนั้น คิดเป็นเพียง 2% ของการเปลี่ยนแปลงทั้งหมดในการทดสอบของเรา เราสามารถจัดเก็บเมทริกซ์ได้อย่างมีประสิทธิภาพโดยละเว้นการเปลี่ยนแปลงที่ไม่ได้ใช้งานจริง
ซึ่งนั่นเป็นการสรุปภาพรวมของการตรวจจับความผิดปกติแบบต่อเนื่องของเรา เลเยอร์นี้คือเลเยอร์สุดท้ายในแบบจำลอง Swiss Cheese ของเรา ซึ่งเป็นเช่นเดียวกับวิธีการเชิงปริมาตร นั่นคือการใช้แนวฐานที่เราจะอัปเดตเมื่อเวลาผ่านไป
การใช้งานอื่น ๆ
การตรวจจับการละเมิด API นั้นใช้งานได้หลากหลายอย่างน่าทึ่ง แม้ว่าเราจะสร้างเทคโนโลยีนี้ไว้สำหรับการใช้ API ทั่วไปก็ตาม แต่ก็มีบางกรณีการใช้งานที่ควรค่าแก่การเน้นย้ำให้ท่านทราบ
อย่างแรกคือ Bot Management สำหรับแอปบนโทรศัพท์มือถือ แม้ว่าโซลูชัน Bot Management ของเราจะทำงานได้ดีกับแอปจำนวนมาก แต่ API Abuse Detection ก็มีประสิทธิภาพมากกว่าอย่างเห็นได้ชัด นั่นเป็นเพราะว่าอุปกรณ์โทรศัพท์มือถือที่มักจะพึ่งพาการใช้งาน API แม้ว่าการร้องขอของ API จะเป็นไปตามเจตนาและการค่อย ๆ ใช้งานของผู้ใช้ที่เป็นมนุษย์ แต่แอปบนโทรศัพท์มือถือจะใช้ API endpoint ซึ่งอาจปรากฏให้เห็นเป็นระบบอัตโนมัติได้ แอปเหล่านี้ไม่ได้ให้อิสระในการนำทางแบบเดียวกับเว็บไซต์ แต่เราสามารถใช้สิ่งนี้เพื่อประโยชน์ของเราได้: ผู้ใช้ที่ถูกต้องจะปฏิบัติตามลำดับที่คาดเดาได้ โดยอิงจากสถานะก่อนหน้า ซึ่งในขณะนี้เราสามารถตรวจสอบด้วย API Abuse Detection ได้แล้ว

บริษัทอื่น ๆ ได้พัฒนา SDK สำหรับอุปกรณ์เคลื่อนที่เพื่อรับทราบการละเมิด API แต่ SDK นั้นมีขนาดใหญ่ ผสานรวมได้ยาก และบางครั้งก็ไม่ได้ผล และวิธีการฝั่งไคลเอ็นต์เช่นนี้ยังเสี่ยงต่อการปลอมแปลงอีกด้วย เพราะจะเป็น Authentication ของซอฟต์แวร์ไคลเอนต์ แต่ไม่สามารถตรวจจับพฤติกรรมที่ไม่เหมาะสมที่เกิดขึ้นจริงได้ บุคคลใดก็ตามที่สามารถแยก Certificate ฝั่งไคลเอ็นต์ได้จะสามารถข้ามการป้องกัน Bot ได้ทันที เราเชื่อว่าเราสามารถรักษาความปลอดภัยแอปบนโทรศัพท์มือถือได้โดยไม่ต้องใช้ SDK ใด ๆ เพียงแค่ปรับใช้ API Abuse Detection บนอุปกรณ์เคลื่อนที่เท่านั้น
นอกจากนี้ API endpoint หลาย ๆ จุดมีการใช้งานหนาแน่น ไม่ใช่ทุกคนที่จะสามารถระบุปริมาณการรับส่งข้อมูลของ API/บอทที่ "ดี" ได้ ซึ่งหมายความว่าแบบจำลองความปลอดภัยเชิงบวกอาจไม่ทำงาน โดยเฉพาะอย่างยิ่งในบริษัทที่ทำงานร่วมกับพันธมิตรที่มีการหมุนเวียนตัวแทนผู้ใช้หรือไม่สามารถจับสัญญาณของตนเองได้ วิธีการของเราจะช่วยหลีกเลี่ยงเรื่องที่น่าปวดหัวนี้ได้อย่างสิ้นเชิง เราจะสร้างแผนที่ของ API endpoint โดยอัตโนมัติ สร้างแนวฐาน แล้วตรวจจับการละเมิด
การเข้าใช้งานก่อนวางจำหน่าย
คุณมีเว็บไซต์ที่ต้องการการตรวจจับการละเมิด API หรือไม่ คุณต้องการลองใช้ Bot Management รุ่นต่อไปสำหรับแอปบนโทรศัพท์มือถือของคุณหรือไม่ โปรดแจ้งให้เราทราบโดยติดต่อทีมบัญชีของคุณ เรารู้สึกตื่นเต้นที่จะนำแบบจำลองเหล่านี้มาใช้งานจริงในอีกไม่กี่เดือนข้างหน้า