

This post is also available in 简体中文, 繁體中文, 日本語, Deutsch, Français, Español, and 한국어.

Workers AI is our serverless GPU-powered inference platform running on top of Cloudflare’s global network. It provides a growing catalog of off-the-shelf models that run seamlessly with Workers and enable developers to build powerful and scalable AI applications in minutes. We’ve already seen developers doing amazing things with Workers AI, and we can’t wait to see what they do as we continue to expand the platform. To that end, today we’re excited to announce some of our most-requested new features: streaming responses for all Large Language Models (LLMs) on Workers AI, larger context and sequence windows, and a full-precision Llama-2 model variant.
If you’ve used ChatGPT before, then you’re familiar with the benefits of response streaming, where responses flow in token by token. LLMs work internally by generating responses sequentially using a process of repeated inference — the full output of a LLM model is essentially a sequence of hundreds or thousands of individual prediction tasks. For this reason, while it only takes a few milliseconds to generate a single token, generating the full response takes longer, on the order of seconds. The good news is we can start displaying the response as soon as the first tokens are generated, and append each additional token until the response is complete. This yields a much better experience for the end user — displaying text incrementally as it's generated not only provides instant responsiveness, but also gives the end-user time to read and interpret the text.
As of today, you can now use response streaming for any LLM model in our catalog, including the very popular Llama-2 model. Here’s how it works.
Server-sent events: a little gem in the browser API
Server-sent events are easy to use, simple to implement on the server side, standardized, and broadly available across many platforms natively or as a polyfill. Server-sent events fill a niche of handling a stream of updates from the server, removing the need for the boilerplate code that would otherwise be necessary to handle the event stream.
| Easy-to-use | Streaming | Bidirectional | |
|---|---|---|---|
| fetch | ✅ | ||
| Server-sent events | ✅ | ✅ | |
| Websockets | ✅ | ✅ |
To get started using streaming on Workers AI’s text generation models with server-sent events, set the “stream” parameter to true in the input of request. This will change the response format and mime-type to text/event-stream.
Here’s an example of using streaming with the REST API:
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]And here’s an example using a Worker script:
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}If you want to consume the output event-stream from this Worker in a browser page, the client-side JavaScript is something like:
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}You can use this simple code with any simple HTML page, complex SPAs using React or other Web frameworks.
This creates a much more interactive experience for the user, who now sees the page update as the response is incrementally created, instead of waiting with a spinner until the entire response sequence has been generated. Try it out streaming on ai.cloudflare.com.
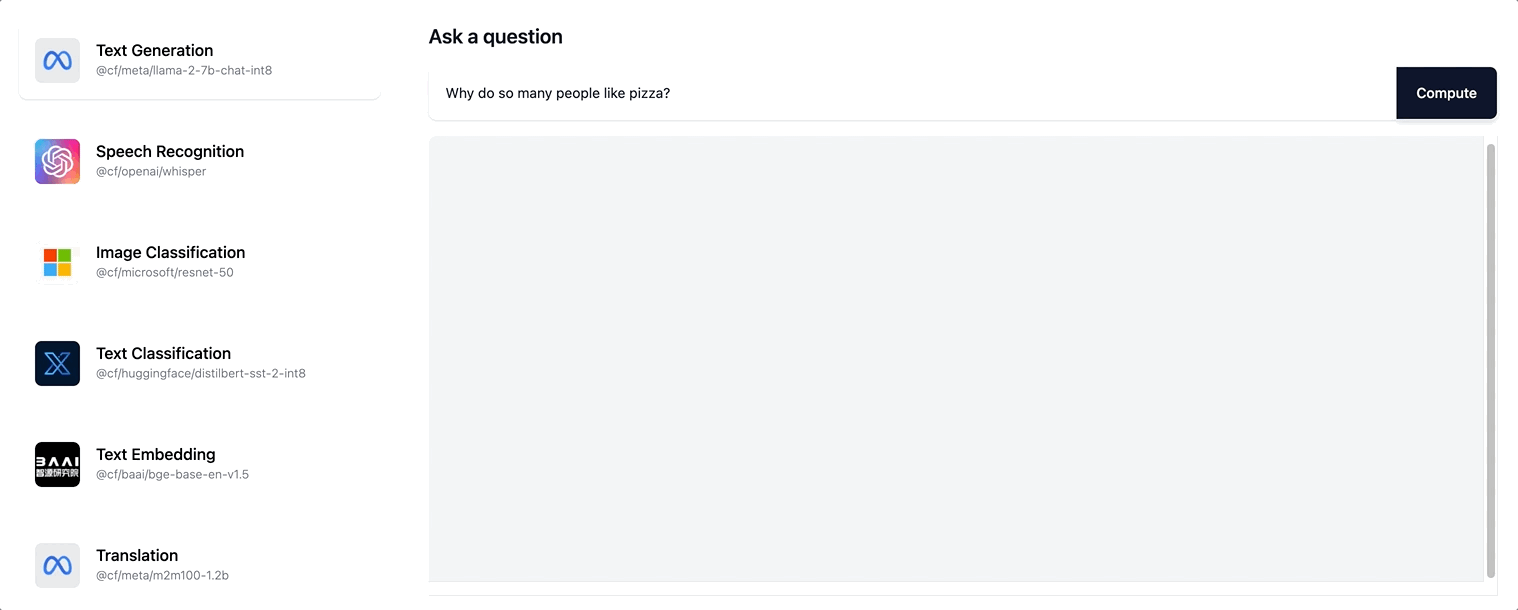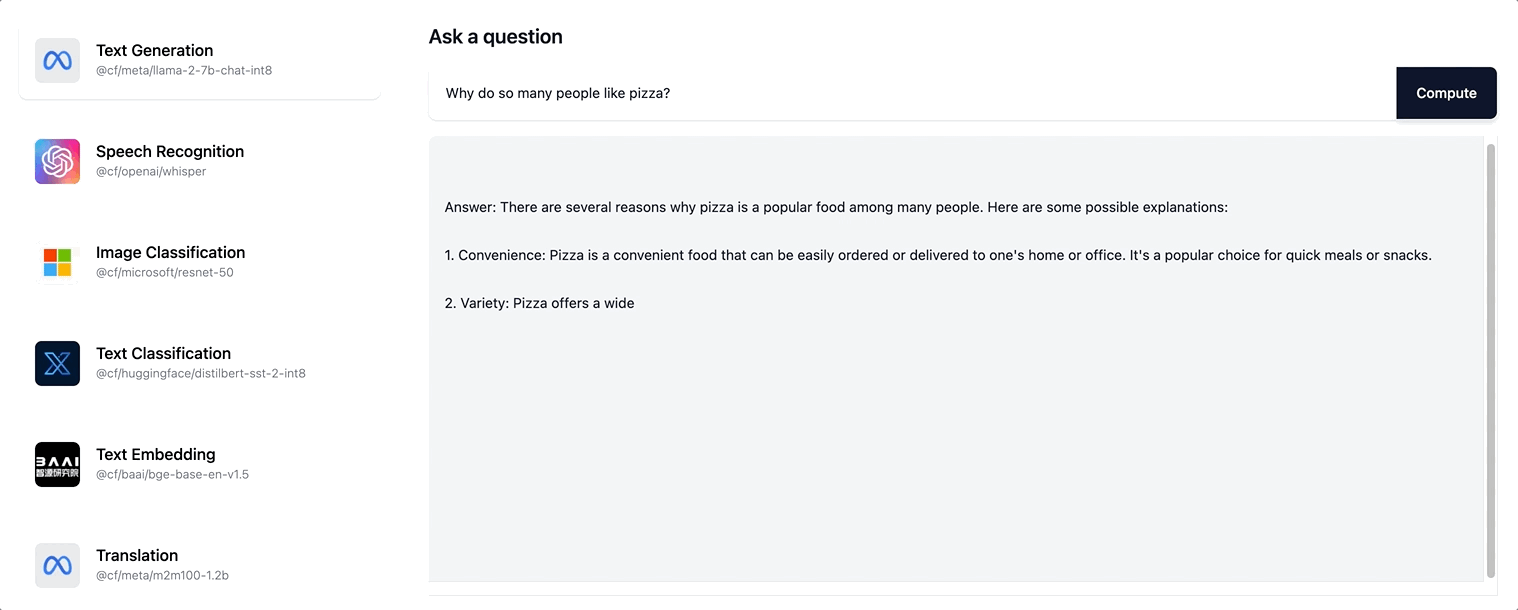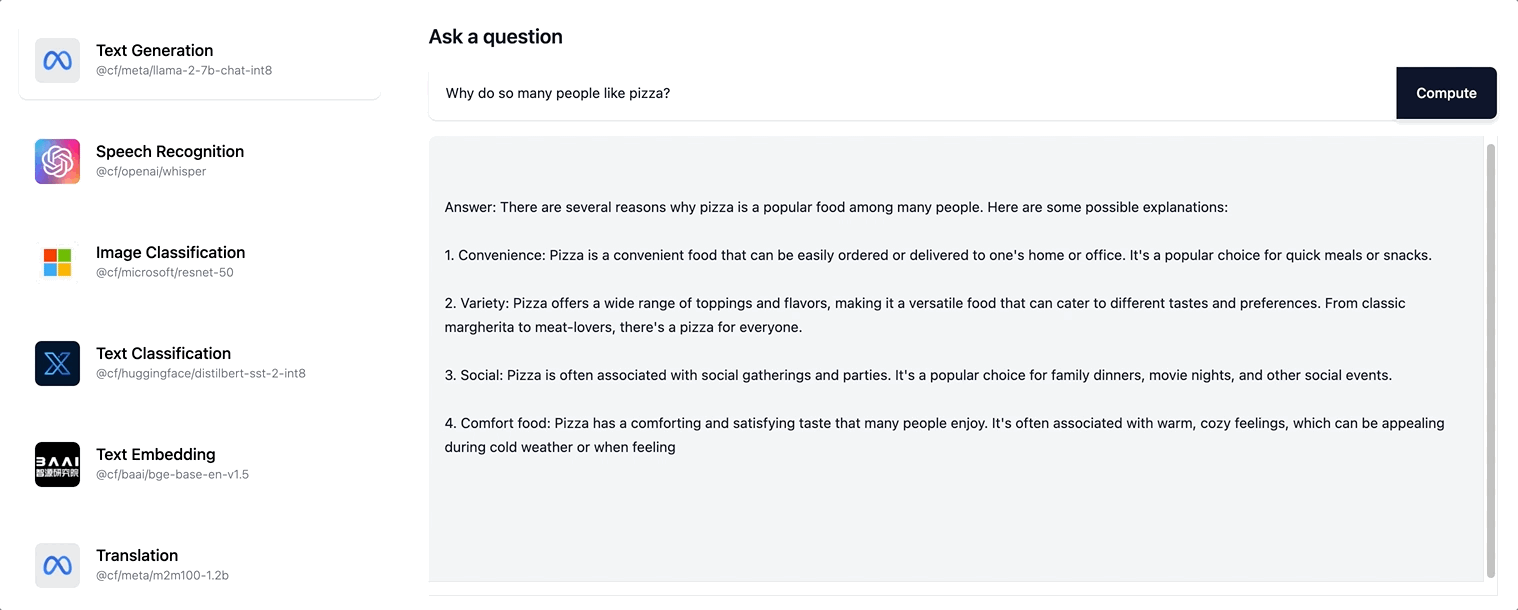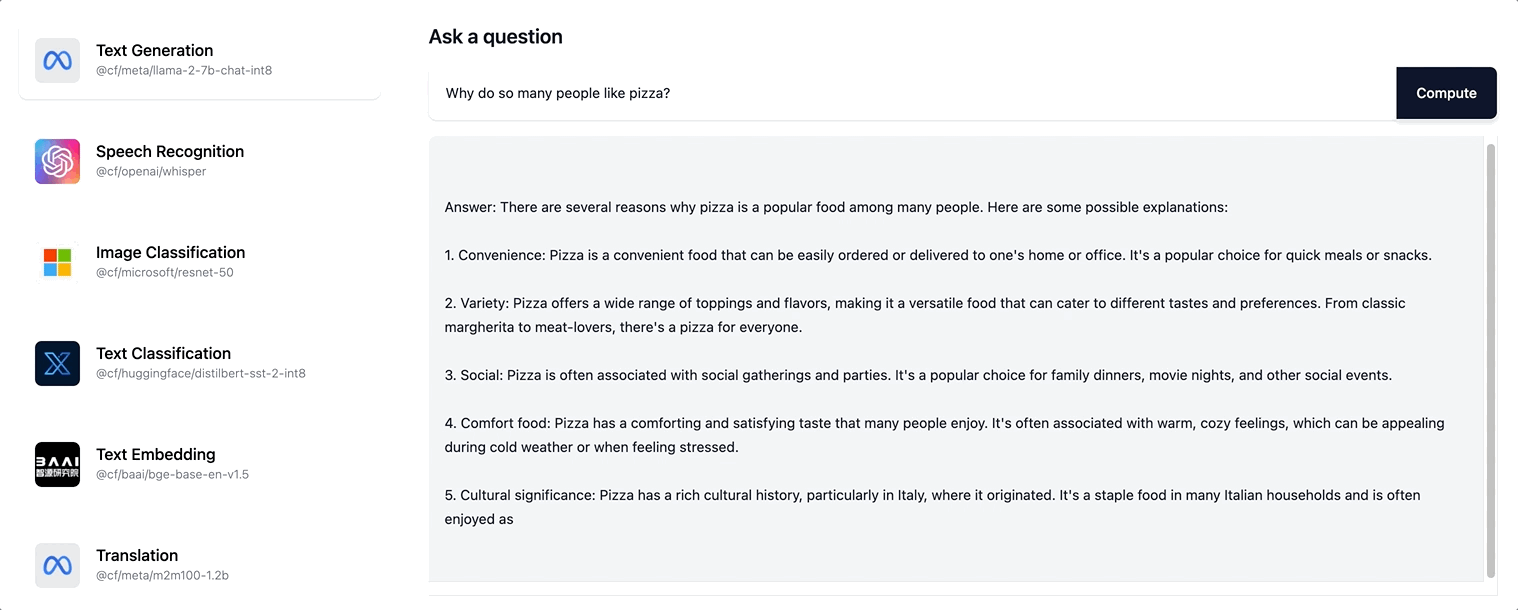
Workers AI supports streaming text responses for the Llama-2 model and any future LLM models we are adding to our catalog.
But this is not all.
Higher precision, longer context and sequence lengths
Another top request we heard from our community after the launch of Workers AI was for longer questions and answers in our Llama-2 model. In LLM terminology, this translates to higher context length (the number of tokens the model takes as input before making the prediction) and higher sequence length (the number of tokens the model generates in the response.)
We’re listening, and in conjunction with streaming, today we are adding a higher 16-bit full-precision Llama-2 variant to the catalog, and increasing the context and sequence lengths for the existing 8-bit version.
| Model | Context length (in) | Sequence length (out) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048 (768 before) | 1800 (256 before) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
Streaming, higher precision, and longer context and sequence lengths provide a better user experience and enable new, richer applications using large language models in Workers AI.
Check the Workers AI developer documentation for more information and options. If you have any questions or feedback about Workers AI, please come see us in the Cloudflare Community and the Cloudflare Discord.
If you are interested in machine learning and serverless AI, the Cloudflare Workers AI team is building a global-scale platform and tools that enable our customers to run fast, low-latency inference tasks on top of our network. Check our jobs page for opportunities.