


最近,Fediverse 一直是一个热门话题,成千上万甚至上十万新用户在 Mastodon 等平台上创建帐户,或完全转移到“另一端”,或试用和了解这一全新的社交网络。

今天我们要介绍的是 Wildebeest。这是一个易于部署的开源服务器,与 ActivityPub 和 Mastodon 兼容,完全构建在 Cloudflare 的 Supercloud 之上。若想在 Fediverse 中运行自己的服务器,现在您可以完全通过 Cloudflare 实现。
构建在 Cloudflare 上的 Fediverse。
若想加入 Mastodon 联盟网络,现在您有两个选择:或加入现有的服务器(服务器也称社区,每个社区都有自己的基础设施和规则),或运行自己的自托管服务器。
想运行自己的服务器有以下几种原因:
您想创建一个新的社区,并通过共同的主题和使用规来吸引其他用户。
您不希望必须信任第三方服务器并遵守他们的策略,您希望您的服务器在您自己的域中为您的个人帐户服务。
您希望完全控制自己的数据、个人信息和内容,并了解实例的运行情况。
非营利组织 Mastodon gGmbH 使用 Ruby、Node.js、PostgreSQL 和 Redis 来帮助实现服务器。不过,运行官方服务器可能存在挑战。您需要在某个地方拥有或租赁一台服务器或虚拟专用服务器 (VPS);您必须安装和配置软件,设置数据库和面向公众的 web 服务器,配置和保护您的网络免遭攻击或滥用。然后,您必须维护所有这些设备,并不断更新。您需要处理大量的脚本和技术工作才能启动和运行;非技术爱好者绝对不想这么麻烦。
Wildebeest 的宗旨:让您可以在 Cloudflare 上快速部署与 Mastodon 兼容的自有服务器,并在几分钟内连接到 Fediverse;无需担心维护、滥用或攻击问题;Cloudflare 会自动为您处理这些工作。
Wildebeest 不是一项托管服务。它是您的实例、数据和代码,以您的 Cloudflare 帐户在我们的云中运行。而且它是一项开源服务,这意味着它会不断发展,将拥有更多功能,任何人都可以扩展并改进。
目前我们支持:
与 ActivityPub、WebFinger、NodeInfo、WebPush 和 Mastodon 兼容的 API。Wildebeest 可以连接其他 Fediverse 服务器或接收来自其他 Fediverse 服务器的连接。
与最常用的 Mastodon web(例如 Pinafore)、桌面和移动客户端兼容。我们还提供一个简单的只读 web 界面来浏览时间线和用户档案。
可以发布、编辑、推广或删除帖子、sorry 帖、嘟文。我们支持文本、图像,马上还将支持视频。
任何人都可以关注您;您也可以关注任何人。
可以搜索内容。
可以在您的实例下注册一个或多个帐户。可使用电子邮件,或与 Cloudflare Access 兼容的任何 IdP(例如 GitHub 或 Google)进行身份验证。
可以编辑您的档案信息、头像和标头图像。
我们的网络是如何打造的
这些实现完全以我们的产品和 API 为基础。构建 Wildebeest 是另一个绝佳机会,可以展示我们功能强大、用途广泛的技术栈,证明任何人都可以使用 Cloudflare 来构建涉及多个系统和复杂要求的大型应用程序。
Wildebeest 架构的鸟瞰图如下:
现在我们来了解其细节和技术。
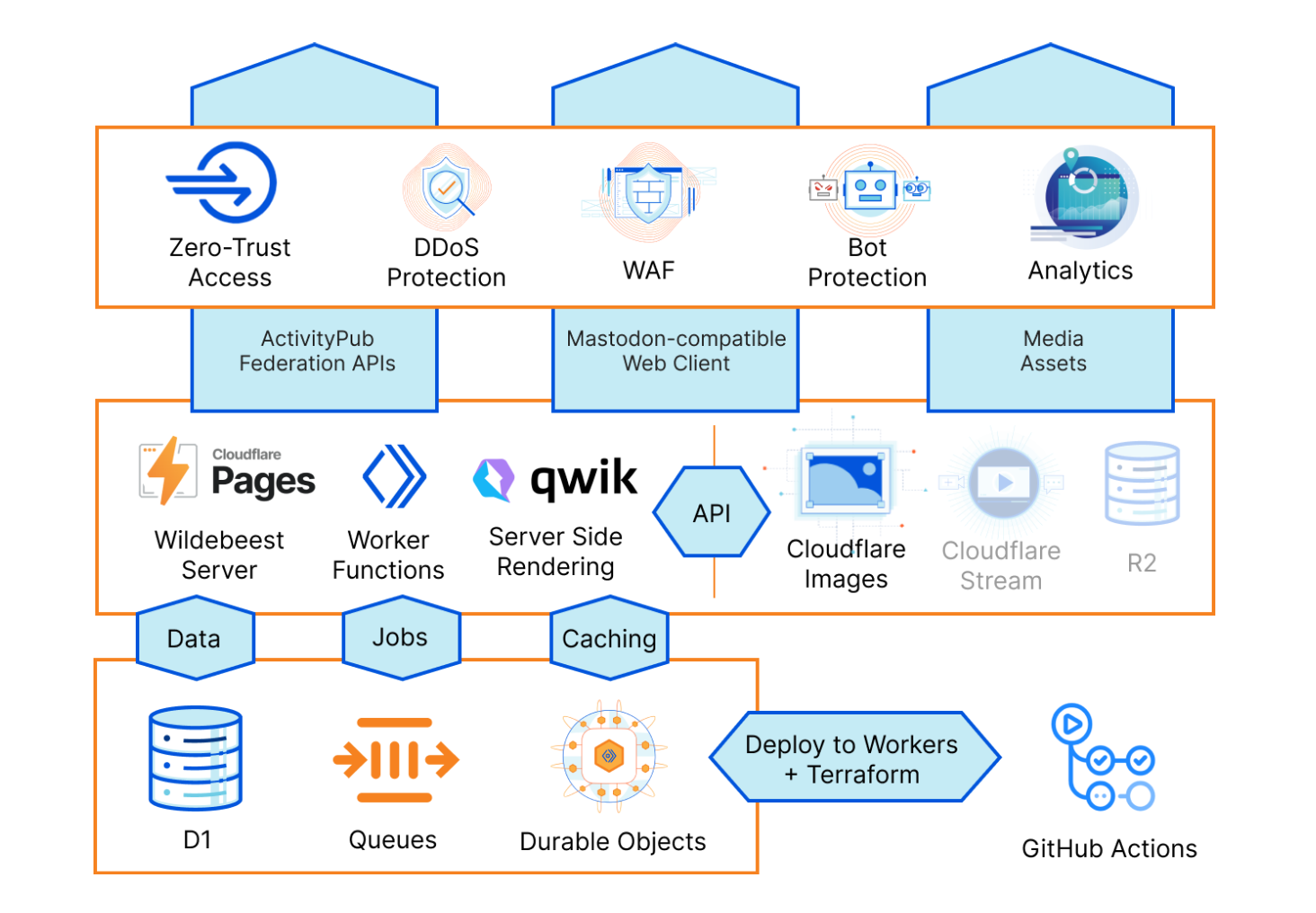
Cloudflare 页面
本质上而言,Wildebeest 是一个使用 Pages Functions 运行代码的 Cloudflare Pages 项目。Cloudflare Pages 为构建和部署应用程序、支持您的捆绑资产提供了很好的基础,Functions 则让您能够完全访问 Workers 生态系统,您可在其中运行任何代码。
Functions 有一个基于文件的内置路由器。/functions 目录结构,按 Wildebeest 的持续部署版本上传,它定义了您的应用程序路由以及哪些文件和代码负责处理每个 HTTP 端点请求。这种路由技术与 Next.js 等框架使用的技术相似。
例如,Mastodon 的 /api/v1/timelines/public API 端点由 /functions/api/v1/timelines/public.ts 使用 onRequest 方法处理。
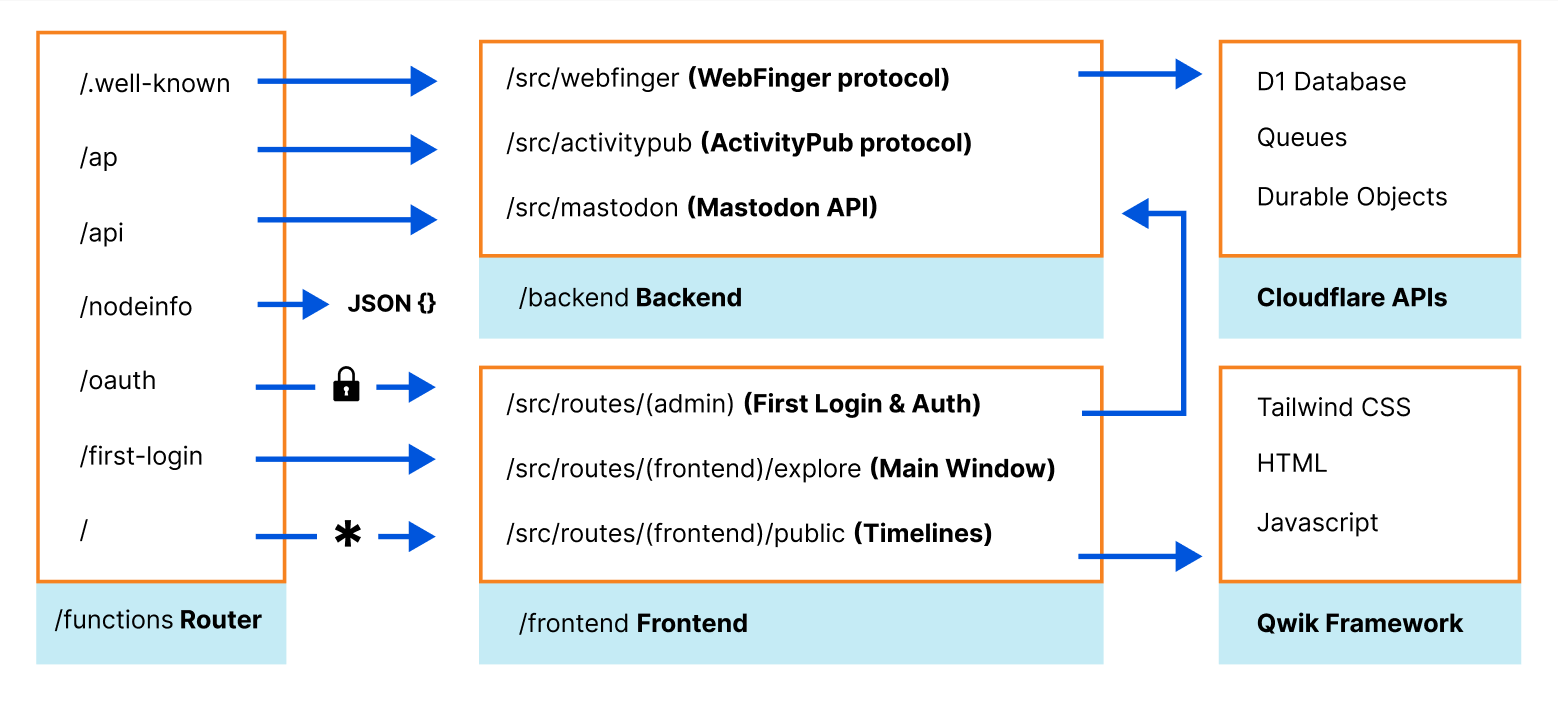
端点单元测试也变得更加简单,只需从测试框架中调用 handleRequest() 函数即可。请参阅我们的一个 Jest 测试——mastodon.spec.ts。
export onRequest = async ({ request, env }) => {
const { searchParams } = new URL(request.url)
const domain = new URL(request.url).hostname
...
return handleRequest(domain, env.DATABASE, {})
}
export async function handleRequest(
…
): Promise<Response> {
…
}
与其他普通 Worker 一样,Functions 也允许设置绑定,以便与其他 Cloudflare 产品和功能交互,例如 KV、R2、D1、Durable Objects,等等。可交互的产品和功能还在不断增加。
import * as v1_instance from 'wildebeest/functions/api/v1/instance'
describe('Mastodon APIs', () => {
describe('instance', () => {
test('return the instance infos v1', async () => {
const res = await v1_instance.handleRequest(domain, env)
assert.equal(res.status, 200)
assertCORS(res)
const data = await res.json<Data>()
assert.equal(data.rules.length, 0)
assert(data.version.includes('Wildebeest'))
})
})
})
我们使用 Functions 来实现官方 Mastodon API 规范的大部分内容,使 Wildebeest 与其他服务器和客户端应用程序的现有生态系统兼容,同时在同一项目代码库中运行我们自己的只读 web 前端。
Wildebeest 的 web 前端使用 Qwik。Qwik 是一个旨在加快速度的多用途 web 框架,使用 JSX JavaScript 语法扩展等现代概念,支持服务器端渲染 (SSR) 和静态网站生成 (SSG)。
Qwik 提供一个开箱即用的 Cloudflare Pages Adaptor,所以我们可以直接使用(查看我们的框架指南,进一步了解如何在 Cloudflare 页面上部署 Qwik 网站)。样式设计方面,我们使用 Qwik 原生支持的 Tailwind CSS 框架。
可通过 /frontend 目录查找我们的前端网站代码和静态资产。应用程序由 /functions/[[path]].js 动态路由处理,它基本上能捕捉所有非 API 请求,然后调用 Qwik 自己的内部路由器 Qwik City,由其负责后面的所有工作。
Pages 和 Functions 路由功能强大,用途广泛,使得在同一项目下同时运行后端 API 和服务器端渲染的动态客户端(实际上是一个全栈应用程序)成为可能。
现在我们来深入了解服务器如何与我们架构中的其他组件交互。
D1
Wildebeest 使用 D1。D1 是 Cloudflare 为 Workers 平台构建的第一个 SQL 数据库,以 SQLite 为基础,现在向所有人开放 α 测试,用于存储和查询数据。我们的模式如下:
随着功能不断增多,未来模式可能会发生改变。但没关系,D1 支持迁移,当您需要更新数据库模式时,不会丢失数据。使用每个新版 Wildebeest 时,如果需要改变数据库模式,我们可以创建一个新的迁移文件。
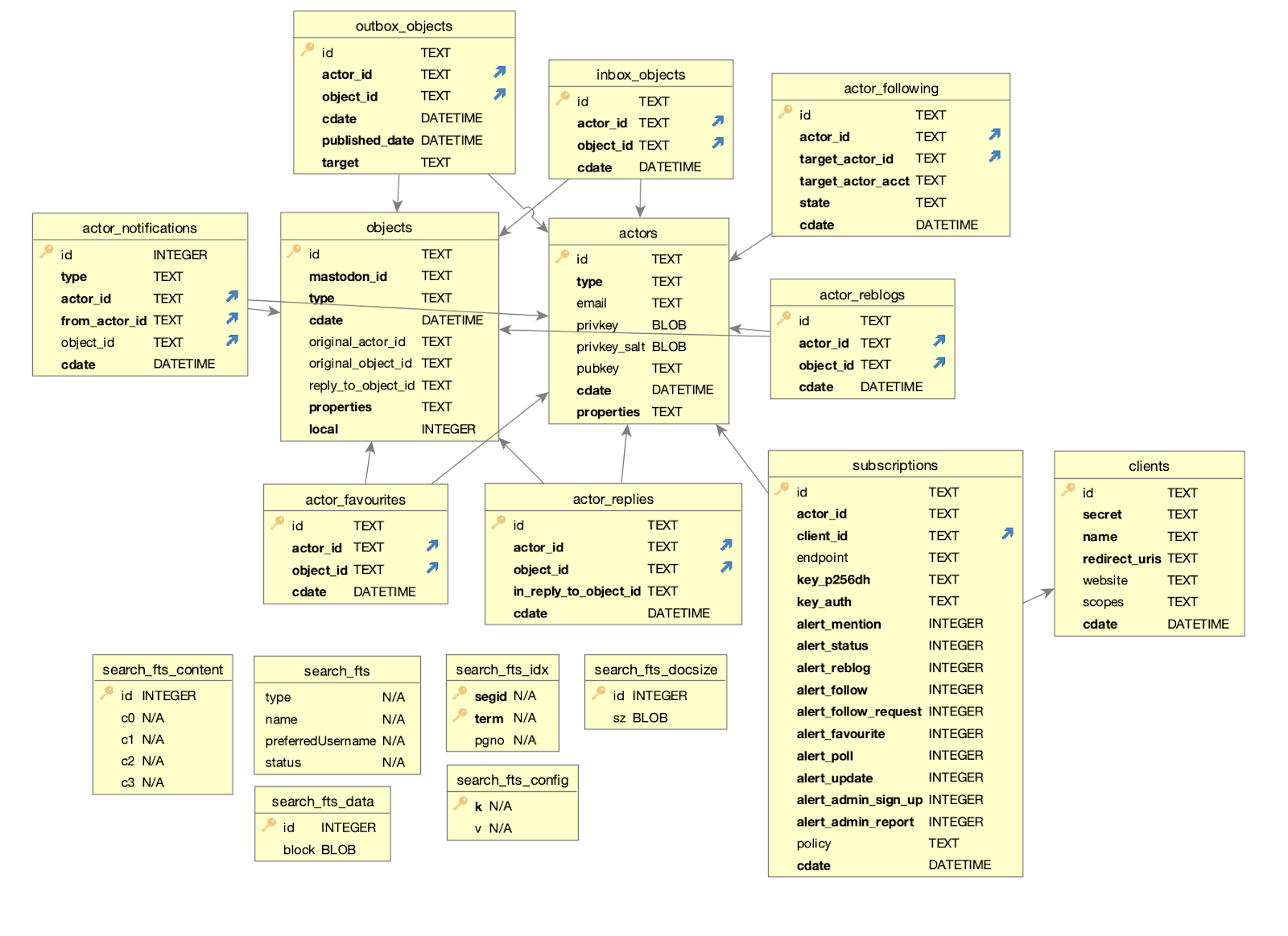
D1 支持构建强大的客户端 API,帮助开发者操作和查询 Worker 脚本的数据。在我们的例子中就是 Pages Functions。
-- Migration number: 0001 2023-01-16T13:09:04.033Z
CREATE UNIQUE INDEX unique_actor_following ON actor_following (actor_id, target_actor_id);
下面举一个简化的例子,说明当您在 Fediverse 上开始关注某人时,我们如何与 D1 交互。
Cloudflare 的文化倡导内部测试,在自己的产品基础上构建,这意味着我们有时会比用户先发现产品的不足。使用 D1 确实给我们带来了一些挑战,D1 以 SQLite 为基础,用于存储我们的数据。下面来看两个例子。
export async function addFollowing(db, actor, target, targetAcct): Promise<UUID> {
const query = `INSERT OR IGNORE INTO actor_following (id, actor_id, target_actor_id, state, target_actor_acct) VALUES (?, ?, ?, ?, ?)`
const out = await db
.prepare(query)
.bind(id, actor.id.toString(), target.id.toString(), STATE_PENDING, targetAcct)
.run()
return id
}
ActivityPub 使用 UUID 来识别对象,并在 URI 中广泛引用。这些对象需要存储在数据库中。PostgreSQL 等其他数据库则提供内置函数来产生唯一标识符。SQLite 和 D1 目前没有这个功能,但已列入我们的计划。
别担心,Workers 运行时支持 Web Crypto,所以我们使用 crypto.randomUUID() 来获取唯一标识符。请参阅 /backend/src/activitypub/actors/inbox.ts:
问题就解决了。
export async function addObjectInInbox(db, actor, obj) {
const id = crypto.randomUUID()
const out = await db
.prepare('INSERT INTO inbox_objects(id, actor_id, object_id) VALUES(?, ?, ?)')
.bind(id, actor.id.toString(), obj.id.toString())
.run()
}另一个例子是,我们需要存储具有亚秒级分辨率的日期。同样,PostgreSQL 等数据库也有该功能。
但 SQLite 的不足之处在于:
psql> select now();
2023-02-01 11:45:17.425563+00我们通过一个小型 hack 程序,使用 strftime() 解决了这个问题:
sqlite> select datetime();
2023-02-01 11:44:02请参阅我们的初始 SQL 模式,查找 cdate 默认值。
sqlite> select strftime('%Y-%m-%d %H:%M:%f', 'NOW');
2023-02-01 11:49:35.624Images
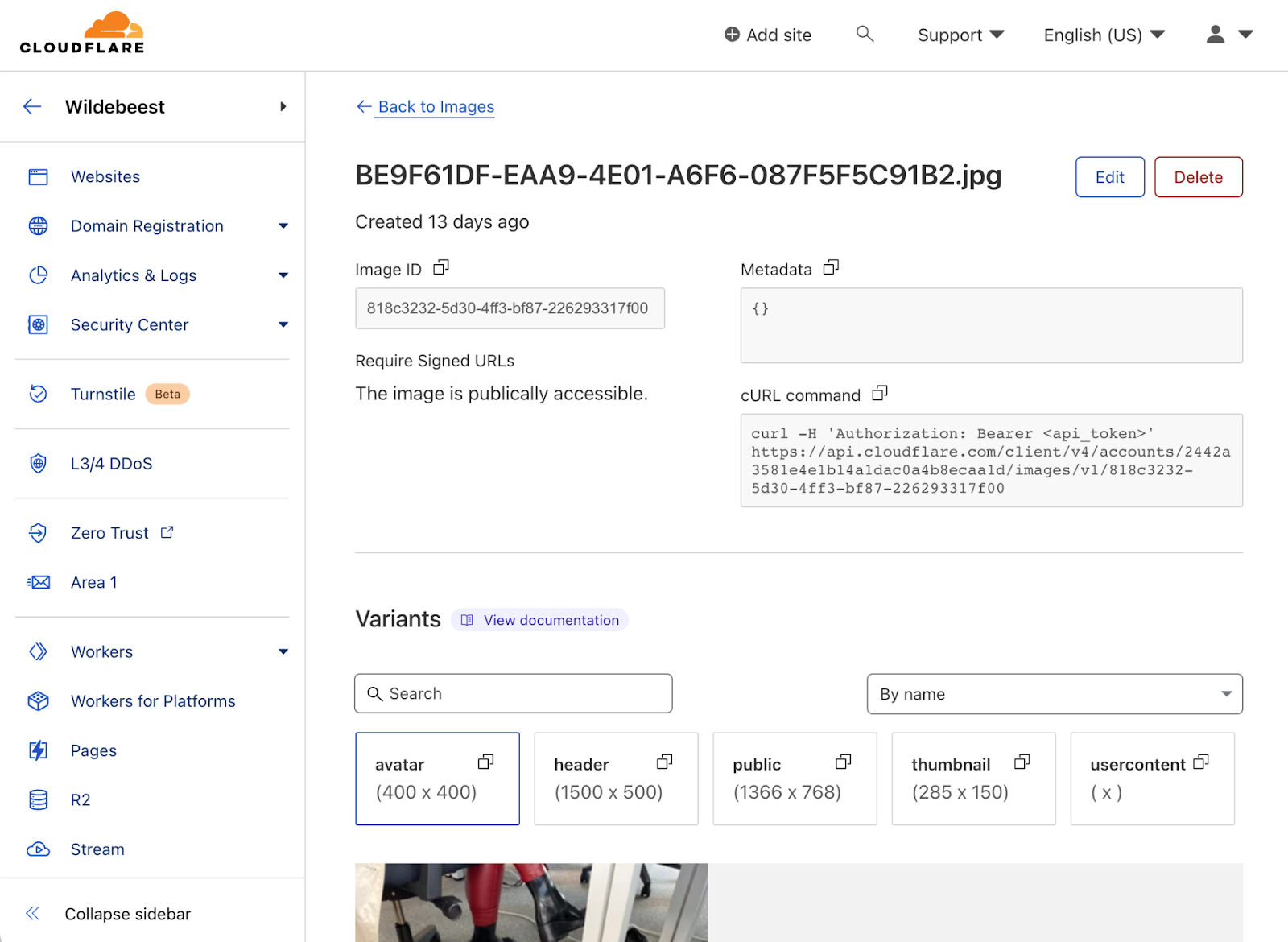
Mastodon 的内容有大量富媒体。我们不需要重造轮子,重建图像管道;Cloudflare Images 提供 API,从我们的全球 CDN 上传、转换和提供优化的图像,完全符合 Wildebeest 的要求。
发布内容图像、档案头像或标头等,都是使用图像 API。请参阅 /backend/src/media/image.ts,了解我们如何与 Images 配合使用。
如有兴趣在下一个项目中考虑使用 Images,请参阅此教程:如何在您的网站上集成 Cloudflare Images。
async function upload(file: File, config: Config): Promise<UploadResult> {
const formData = new FormData()
const url = `https://api.cloudflare.com/client/v4/accounts/${config.accountId}/images/v1`
formData.set('file', file)
const res = await fetch(url, {
method: 'POST',
body: formData,
headers: {
authorization: 'Bearer ' + config.apiToken,
},
})
const data = await res.json()
return data.result
}也可从仪表板访问 Cloudflare Images。可以用它来快速浏览或管理您的目录。
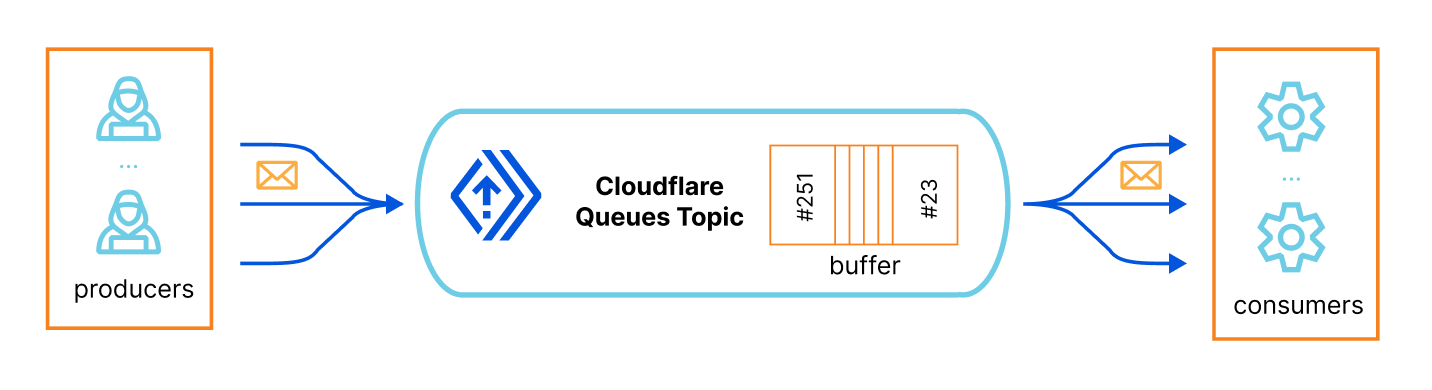
队列
ActivityPub 协议是为聊天设计的。根据社交图谱的大小,可能会有很多来回传递的 HTTP 流量。我们不能在每次有人发帖时,都让客户端等待数百条 Fediverse 消息的传送,造成拥堵。
我们需要寻找一种方法,既支持异步工作,又启动后台作业,将数据处理从主应用程序中分离出来,以保持客户端的敏捷性。官方的 Mastodon 服务器有一个类似策略,使用 Sidekiq 负责后台处理。
幸运的是,我们也不需要担心这些复杂的问题。Cloudflare Queues 让开发人员能够安心无虞地发送和接收消息,为 Workers 请求分担一些工作,从而有效提供异步批量作业的能力。
简而言之,您有一个队列主题标识符——本质上是一个自动扩展的缓冲列表;然后您有一个或多个生产者生产结构化的消息(在我们的例子中就是 JSON 对象),并把它们放入队列(模式由您定义);最后您有一个或多个消费者订阅该队列,接收消息并按自己的速度处理消息。
请参阅 Queues 工作原理页面,了解更多信息。
在我们的案例中,每当任何传入的 API 调用需要时间长、成本高的操作时,主应用程序就会产生队列作业。例如,有人发布帖子、sorry 帖或_嘟文_时,我们需要将其传送到粉丝的收件箱,可能会引发许多对远程服务器的请求。这时,我们为此排列作业,将 API 释放出来确保继续响应:
同样,远程服务器向我们的实例收件箱传送消息时,我们也不希望停止主 API。Wildebeest 在收件箱接收消息时,创建异步作业的方法如下:
export async function deliverFollowers(
db: D1Database,
from: Actor,
activity: Activity,
queue: Queue
) {
const followers = await getFollowers(db, from)
const messages = followers.map((id) => {
const body = {
activity: JSON.parse(JSON.stringify(activity)),
actorId: from.id.toString(),
toActorId: id,
}
return { body }
})
await queue.sendBatch(messages)
}最后一环是我们的队列消费者,它们在一个独立的 Worker 中运行,独立于 Pages 项目。消费者监听新的消息,并按自己的节奏依次处理,将其他人从拥堵中解救出来。繁忙时,队列会增加缓冲区。尽管如此,一切仍在运行,作业最终会全部分派,将主要的 API 释放出来处理关键的事情:尽可能快速响应远程服务器和客户端。
export async function handleRequest(
domain: string,
db: D1Database,
id: string,
activity: Activity,
queue: Queue,
): Promise<Response> {
const handle = parseHandle(id)
const actorId = actorURL(domain, handle.localPart)
const actor = await actors.getPersonById(db, actorId)
// creates job
await queue.send({
type: MessageType.Inbox,
actorId: actor.id.toString(),
activity,
})
// frees the API
return new Response('', { status: 200 })
}如果您想亲自体验 Queues,可以试试这个简单的例子:使用 Queues 在 R2 中存储数据。
export default {
async queue(batch, env, ctx) {
for (const message of batch.messages) {
…
switch (message.body.type) {
case MessageType.Inbox: {
await handleInboxMessage(...)
break
}
case MessageType.Deliver: {
await handleDeliverMessage(...)
break
}
}
}
},
}缓存和 Durable Objects
缓存重复性操作也可以提高需要数据处理的复杂应用程序的性能。著名的 Netscape 开发者 Phil Karlton 曾说:“计算机科学只有两件难事:缓存失效和命名。”
Cloudflare 显然非常了解缓存,毕竟缓存是我们全球 CDN 的一个核心功能。我们还向客户提供 Workers KV——一个低延迟的全球键值数据存储,任何人都可以用它在我们的数据中心缓存数据对象,构建快速的网站和应用程序。
但 KV 实现了最终一致的性能。虽然这对许多应用程序和用例来说还不错,但对其他应用程序和用例来说却不太理想。
ActivityPub 协议高度事务性,无法实现最终一致性。例如:生成完整的时间线成本高昂,所以我们会缓存该操作。然而,发布帖子时,我们需要在缓存失效后再回复客户端。否则,新的帖子就不会出现在时间线上,客户端可能会因为没有看到它而出错,导致发帖失败。这其实就是我们最流行的客户端上发生过的情况。
我们需要更加聪明。团队讨论了几个选项。幸运的是,我们的 API 目录有很多选择。例如 Durable Objects。
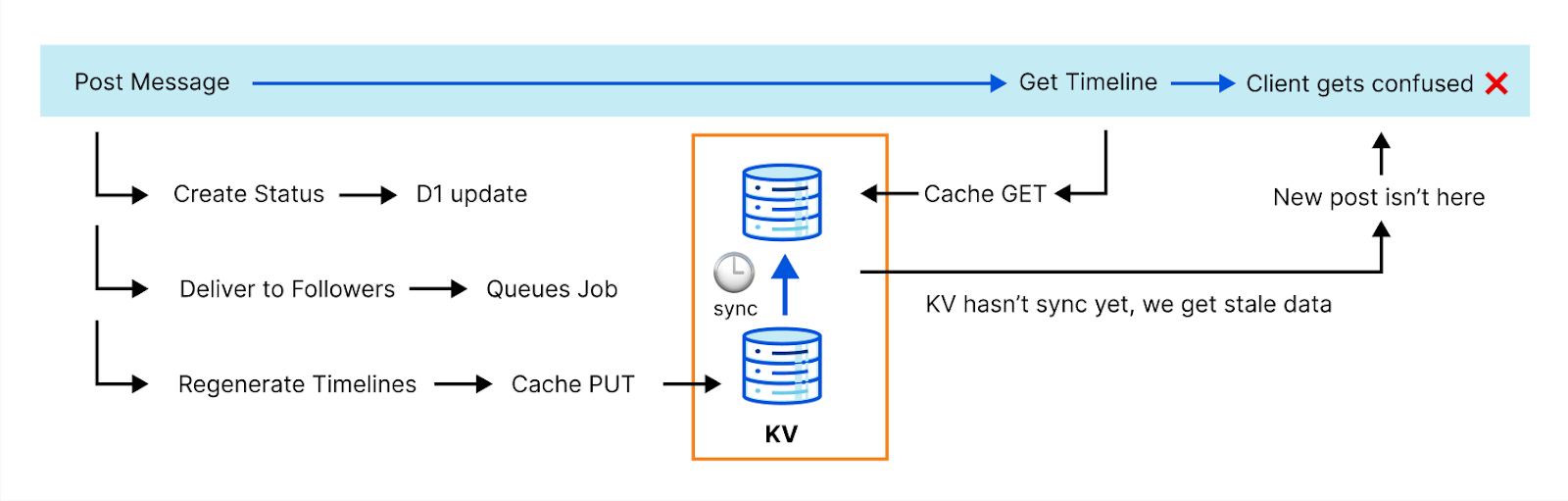
Durable Objects 是提供事务性存储 API 的单实例 Workers。需要中央协调性、强一致性和状态持久性时,Durable Objects 便是理想之选。处理多个 WebSocket 连接的状态、协调和路由聊天室消息,甚至运行多人游戏(例如 Doom)等用例中均可使用 Durable Objects。
现在您已经有所了解。是的,我们在 Durable Objects 的基础上,为 Wildebeest 实现了键值缓存子系统。通过利用 DO 的原生事务性存储 API,我们可以有力地保证,当我们创建或更改一个键后,下次读取时将总是会返回最新的版本。
这个想法非常简单有效,我们只用了几行代码,就使用两种原语(HTTP PUT 和 GET)实现了键值缓存。
强一致性就是这样。现在我们来看看用户注册和身份验证。
export class WildebeestCache {
async fetch(request: Request) {
if (request.method === 'GET') {
const { pathname } = new URL(request.url)
const key = pathname.slice(1)
const value = await this.storage.get(key)
return new Response(JSON.stringify(value))
}
if (request.method === 'PUT') {
const { key, value } = await request.json()
await this.storage.put(key, value)
return new Response('', { status: 201 })
}
}
}Zero Trust Access
官方的 Mastodon 服务器处理用户注册(通常使用电子邮件注册)之后,您才能选择您的本地用户名,开始使用该服务。如果我们从头开始构建,处理用户注册和身份验证可能非常耗时,令人生畏。
此外,人们不希望为想要使用的每一项新服务创建新的凭证,而是希望有更方便的授权和身份验证方法,就像 OAuth 那样,可以使用他们现有的 Apple、Google 或 GitHub 帐户。
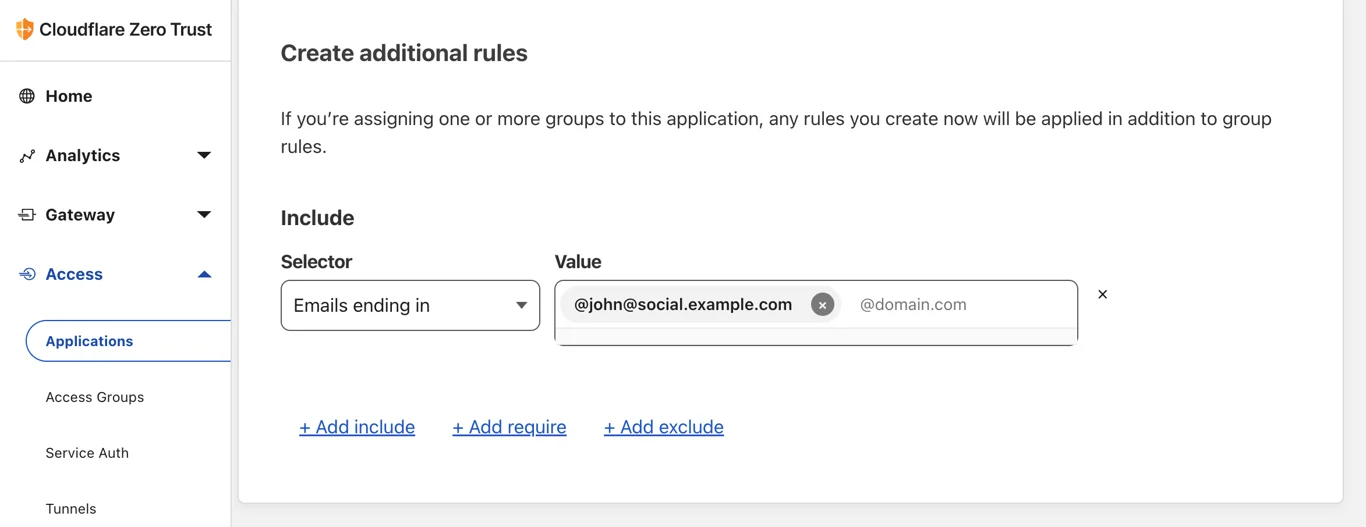
我们希望利用 Cloudflare 的内置功能进行简化。显然,我们有一款产品可以为 Cloudflare 保护的任何应用程序处理用户引导、身份验证和访问策略;它就是 Zero Trust。因此,我们把 Wildebeest 部署在它后面。
Zero Trust Access 可以使用电子邮件进行一次性 PIN (OTP) 身份验证,或使用多种标识提供程序(例如 Google、Facebook、GitHub、LinkedIn)进行单点登录 (SSO),包括任何支持 SAML 2.0 的常规标识提供程序。
开始在客户端上使用 Wildebeest 时,根本不需要注册。您可以直接登录,然后将重定向到 Access 页面,并根据您自己(您的实例的所有者)配置的策略来处理身份验证。
该策略定义了谁可以通过身份验证,以及如何验证。
通过身份验证后,Access 将把您重定向到 Wildebeest。第一次这样登录时,如果我们没有该用户的信息,我们会检测出来,并要求提供用户名和显示名称。这些问题只会问一次,并直接用于创建您的公开 Mastodon 档案。
在技术上,Wildebeest 实现了 OAuth 2 规范。Zero Trust 保护 /oauth/authorize 端点,并在用户通过身份验证后,在请求标头中出具一个有效的 JWT 令牌。然后 Wildebeest 读取并验证 JWT,并在 URL 重定向中返回一个授权码。
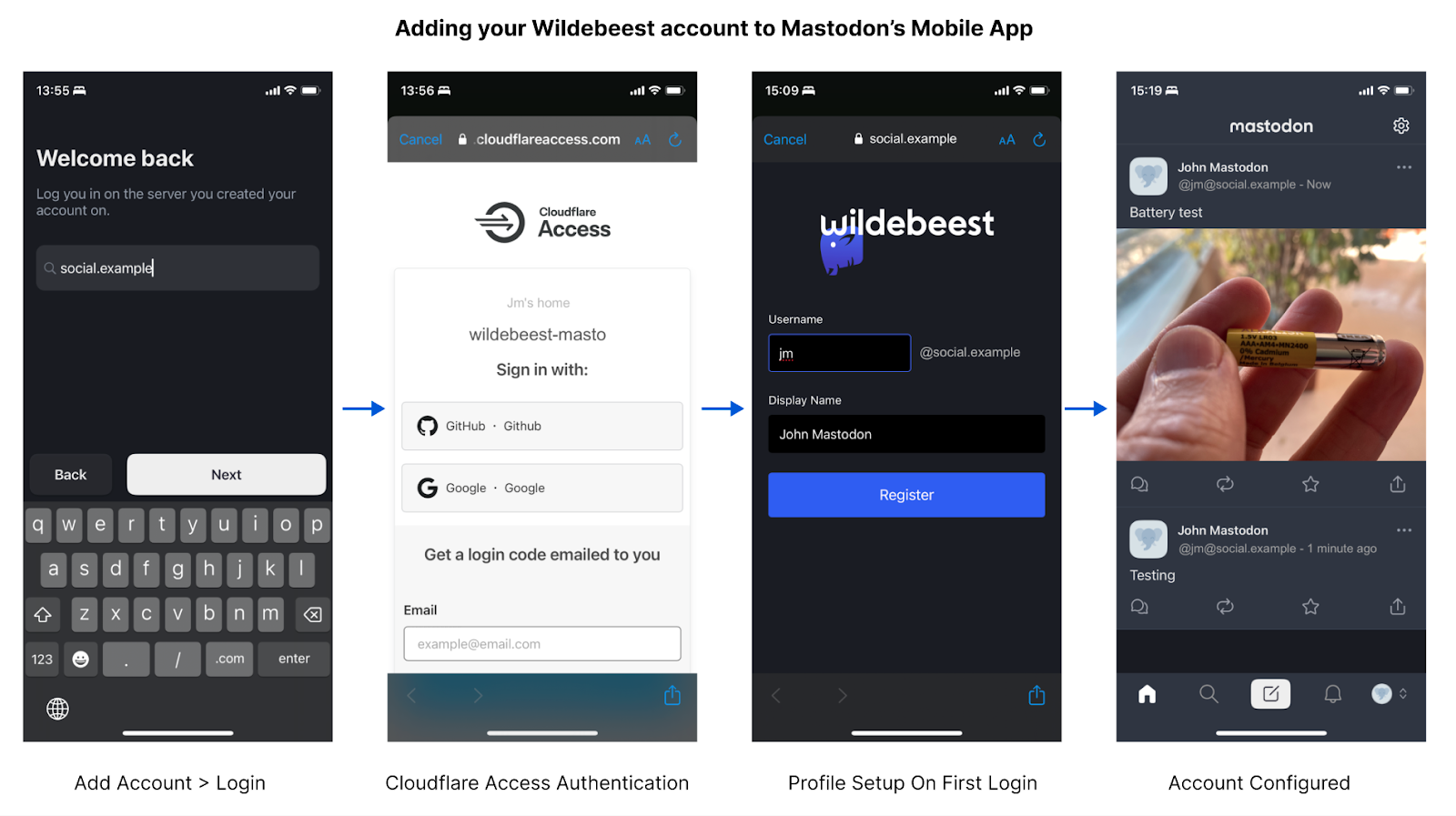
客户端获得授权码后,就可以使用 /oauth/token 端点来获取 API 访问令牌。随后的 API 调用会在授权标头中注入一个持有者令牌。
Authorization: Bearer access_token
部署和持续集成
我们不想为 Mastodon 运行托管服务,因为这会在一定程度上削弱联盟和数据所有权的概念。此外,我们必须承认 ActivityPub 和 Mastodon 是快速发展的新兴技术,将以难以预测的方式迅速演进。
因此,我们认为,现在帮助构建生态系统的最好方式是提供一个开源软件包,任何人都可以在我们的云上使用、定制、改进和部署。Cloudflare 显然会继续改进 Wildebeest,并支持社区,但我们希望 Fediverse 维护者可以完全控制和拥有其实例和数据。
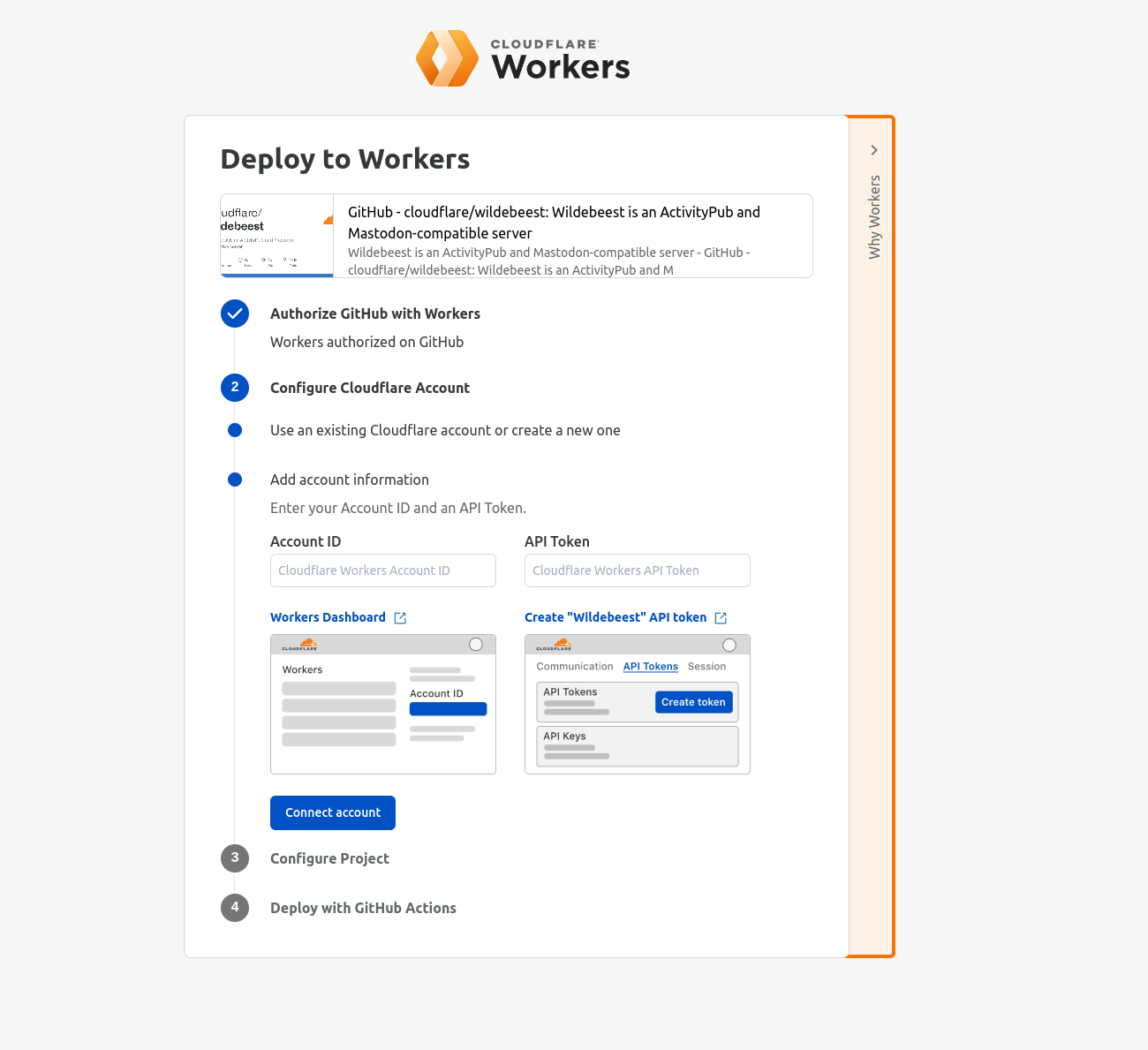
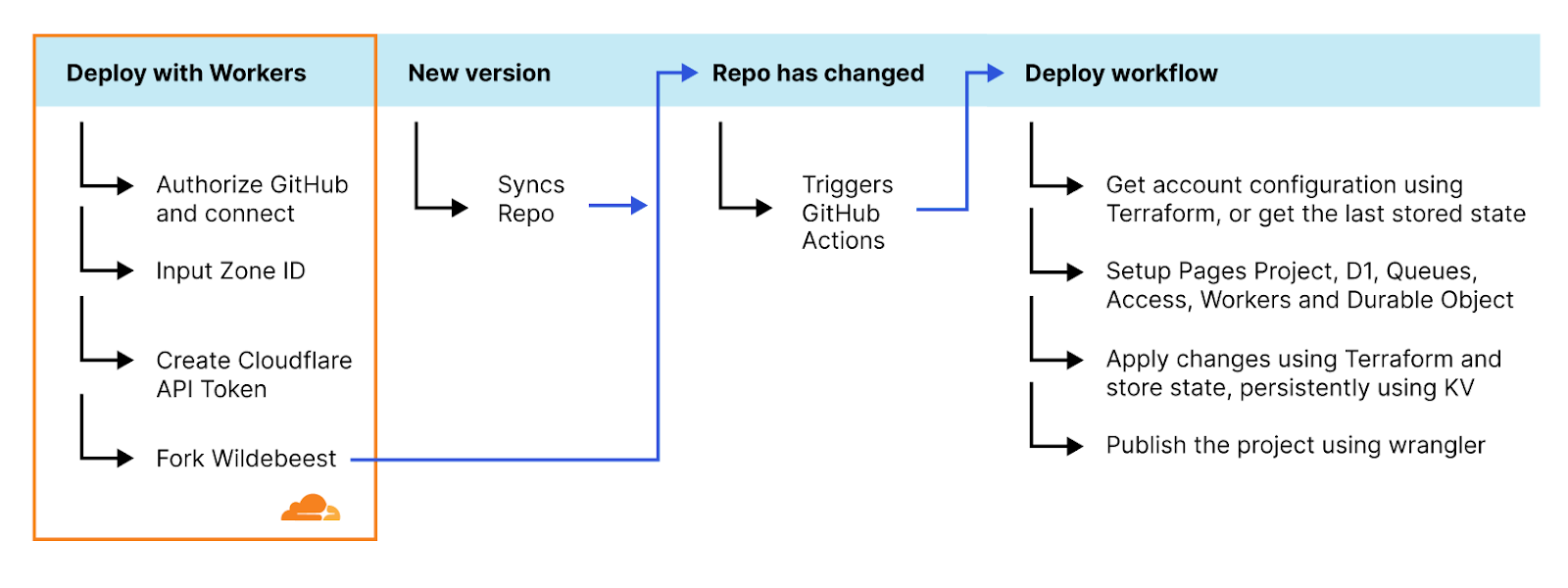
但问题是,当 Wildebeest 需要配置这么多 Cloudflare 功能时,我们如何分发 Wildebeest 软件包并轻松部署到某人的帐户中,以及如何支持长期更新软件?
最终解决方案是将 GitHub 与 GitHub Actions、Deploy with Workers 和 Terraform 巧妙搭配。
用 Deploy with Workers 按钮是一个特制链接,可以自动生成工作流程页面,询问用户一些问题,Cloudflare 负责授权 GitHub 部署到 Workers,自动分叉 Wildebeest 存储库并克隆到用户的帐户中,然后使用 GitHub Actions 工作流程来配置和部署该项目。

GitHub Actions 工作流程 是一个 YAML 文件,其中说明了每一步操作。Wildebeest 工作流程(简化版)如下:
更新 Wildebeest
name: Deploy
on:
push:
branches:
- main
repository_dispatch:
jobs:
deploy:
runs-on: ubuntu-latest
timeout-minutes: 60
steps:
- name: Ensure CF_DEPLOY_DOMAIN and CF_ZONE_ID are defined
...
- name: Create D1 database
uses: cloudflare/wrangler-action@2.0.0
with:
command: d1 create wildebeest-${{ env.OWNER_LOWER }}
...
- name: retrieve Zero Trust organization
...
- name: retrieve Terraform state KV namespace
...
- name: download VAPID keys
...
- name: Publish DO
- name: Configure
run: terraform plan && terraform apply -auto-approve
- name: Create Queue
...
- name: Publish consumer
...
- name: Publish
uses: cloudflare/wrangler-action@2.0.0
with:
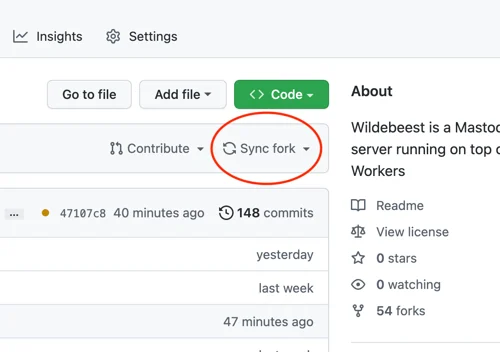
command: pages publish --project-name=wildebeest-${{ env.OWNER_LOWER }} .每当主分支发生变更,都会自动运行该工作流程,因此,更新 Wildebeest 就像将上游官方存储库与分叉同步一样简单。您甚至不需要使用 git 命令;GitHub 在用户界面中提供了同步按钮,点击该按钮即可,非常简单方便。
还有呢?更新是增量式的,不涉及销毁。将 GitHub Actions 工作流程重新部署 Wildebeest 时,我们只对您的配置做必要的修改,没有任何其他操作。您绝不会丢失数据;我们也不需要删除您现有的配置。我们的操作方法如下:
我们使用 Terraform,这是一种声明式配置语言和工具,可与我们的 API 交互,并可查询和配置您的 Cloudflare 功能。关键在于,每当我们应用一个新的配置时,我们会在一个 Cloudflare KV 键中为 Wildebeest 保留一份 Terraform 状态的副本。当触发新的部署时,我们可从 KV 副本中获取该状态,计算差值,只进行必要的修改。
也不会有数据丢失问题。如前文所述,D1 支持迁移。如果我们需要给表格增加一个新的列或需要新增一个表格,我们不需要销毁、重建数据库,我们只需要将必要的 SQL 应用于这一变更。
防护、优化和可观察性,轻而易举
一旦启动并运行 Wildebeest,您必须保护它免受不良流量和恶意行为者的影响。Cloudflare 在开箱后只需点击几下即可为您提供 DDoS、WAF 和 机器人管理保护。
同样,您将通过我们的产品获得即时的网络和内容交付优化,以及有关您的 Wildebeest 实例的性能和使用情况分析。
ActivityPub、WebFinger、NodeInfo 和 Mastodon API
尽管是 Mastodon 普及了 Fediverse 的概念,但其使用的底层技术许多早已有之。这是一个珍贵的时刻,所有技术最终“齐聚一堂”,共同创建一个工作平台,回答互联网用户的实际用例问题。我们来快速浏览一下 Wildebeest 必须实现的协议:
ActivityPub
ActivityPub 是一个去中心化的社交网络协议,至少从 2018 年起就以 W3C 建议书的形式出现了。它定义了用于创建和操作内容的客户端 API,以及用于内容交换和通知的服务器到服务器 API,也称为联盟。ActivityPub 的词汇表使用 ActivityStreams,这是一个更老的 W3C 协议。
许多操作和活动的概念都是在 ActivityPub 规范中定义的。例如:Actors(档案)、消息或 Objects(嘟文)、收件箱(您通过收件箱接收关注对象的嘟文)和发件箱(您通过发件箱向关注对象发送嘟文)。
我们实现了 ActivityPub 的文件夹如下:
WebFinger
import type { APObject } from 'wildebeest/backend/src/activitypub/objects'
import type { Actor } from 'wildebeest/backend/src/activitypub/actors'
export async function addObjectInInbox(db, actor, obj) {
const id = crypto.randomUUID()
const out = await db
.prepare('INSERT INTO inbox_objects(id, actor_id, object_id) VALUES(?, ?, ?)')
.bind(id, actor.id.toString(), obj.id.toString())
.run()
}
WebFinger 是一个简单的 HTTP 协议,用于发现任何实体(例如配置文件、服务器或特定功能)的相关信息。它将 URI 解析为资源对象。
Mastodon 使用 WebFinger 查询来发现远程用户的信息。例如,假设您想与 @user@example.com 互动,您的本地服务器会请求 https://example.com/.well-known/webfinger?resource=acct:user@example.com(使用 acct 方案)并得到类似这样的结果:
现在我们已经知道如何使用 https://example.com/ap/users/user endpoint 端点与 @user@example.com 互动。
{
"subject": "acct:user@example.com",
"aliases": [
"https://example.com/ap/users/user"
],
"links": [
{
"rel": "self",
"type": "application/activity+json",
"href": "https://example.com/ap/users/user"
}
]
}
我们的 WebFinger 响应如下:
Mastodon API
export async function handleRequest(request, db): Promise<Response> {
…
const jsonLink = /* … link to actor */
const res: WebFingerResponse = {
subject: `acct:...`,
aliases: [jsonLink],
links: [
{
rel: 'self',
type: 'application/activity+json',
href: jsonLink,
},
],
}
return new Response(JSON.stringify(res), { headers })
}最后,设置服务器信息、档案信息、生成时间线、通知和搜索等,都是 Mastodon 特定的 API。Mastodon 开源项目定义了一个 REST API 目录,您可以在他们的网站上查找所有文档。
可以在此处(REST 端点)和此处(后端原语)查看我们的 Mastodon API 实现。下面举一个由 Wildebeest 实现的 Mastodon 服务器信息 /api/v2/instance 示例。
Wildebeest 还为客户端通知实现了 WebPush,为服务器令牌实现了 NodeInfo。
export async function handleRequest(domain, db, env) {
const res: InstanceConfigV2 = {
domain,
title: env.INSTANCE_TITLE,
version: getVersion(),
source_url: 'https://github.com/cloudflare/wildebeest',
description: env.INSTANCE_DESCR,
thumbnail: {
url: DEFAULT_THUMBNAIL,
},
languages: ['en'],
registrations: {
enabled: false,
},
contact: {
email: env.ADMIN_EMAIL,
},
rules: [],
}
return new Response(JSON.stringify(res), { headers })
}其他与 Mastodon 兼容的服务器也必须实现所有这些协议;Wildebeest 便是其中之一。社区非常积极地讨论未来的增强功能;我们将不断提高我们的兼容性,并增加对更多功能的支持,确保 Wildebeest 在 Fediverse 服务器和客户端生态系统的形成过程中发挥积极作用。
立即开始使用
技术方面我们已经讨论了很多,下面我们来了解 Fediverse。我们尽可能详细说明部署服务器的所有步骤。要开始使用 Wildebeest,请前往公共 GitHub 存储库,并查阅我们的入门教程。
Wildebeest 的大多数依赖项提供优惠的免费计划,允许您为个人或业余项目(与关键业务无关)试用它们,但您需要订阅一个 Images 计划(最低级的计划应该足以满足大多数需求),并视服务器负载情况订阅 Workers Unbound(同样,最便宜的计划应该足以满足大多数用例)。
我们倡导内部测试,因此,Cloudflare 今天也正式加入了 Fediverse。您可以开始关注我们的 Mastodon 帐户,并使用您最喜爱的 Mastodon 应用程序获取 Cloudflare 的定期更新,与通过其他社交平台获取更新的体验毫无二致。这些帐户完全在 Wildebeest 的服务器上运行。
@cloudflare@cloudflare.social - 我们的主要帐户
@radar@cloudflare.social - Cloudflare Radar
Wildebeest 与大多数客户端应用程序兼容;我们已确认可与官方的 Mastodon Android 和 iOS 应用程序、Pinafore、Mastodon 和 tooot 兼容,并还在研究与 Ivory 等其他应用程序的兼容性。如果您最喜爱的应用程序不能兼容,请在此提交问题,我们将尽力提供支持。

结语
Wildebeest 完全构建在我们的 Supercloud 栈上。这是我们创建的最完整、最复杂的项目之一,使用了 Cloudflare 的各种产品和功能。
希望这篇报道能激励您不仅尝试部署 Wildebeest,加入 Fediverse,并在 Cloudflare 上构建您的下一个应用程序,无论应用程序要求有多高。
Wildebeest 目前还只是一个非常简单可行、与 Mastodon 兼容的服务器,但我们会不断改进,推出更多功能,支持更多应用程序;毕竟,我们的官方帐户也在使用它。Wildebeest 是一种开源服务器,非常欢迎您通过拉动请求或反馈献计献策。
同时,我们在我们的 Developers Discord Server 上开设了Wildebeest 室,并始终关注 GitHub 存储库问题选项卡。欢迎与我们交流,我们渴望了解您是如何使用 Wildebeest 的,也乐意回答您的问题。
PS:为方便阅读并节省空间,本博客中的代码片段经过了简化(例如,删除了 TypeScript 类型和错误处理代码)。请参阅 GitHub 存储库的链接,查看完整版本。