


The Fediverse has been a hot topic of discussion lately, with thousands, if not millions, of new users creating accounts on platforms like Mastodon to either move entirely to "the other side" or experiment and learn about this new social network.
Today we're introducing Wildebeest, an open-source, easy-to-deploy ActivityPub and Mastodon-compatible server built entirely on top of Cloudflare's Supercloud. If you want to run your own spot in the Fediverse you can now do it entirely on Cloudflare.
The Fediverse, built on Cloudflare
Today you're left with two options if you want to join the Mastodon federated network: either you join one of the existing servers (servers are also called communities, and each one has its own infrastructure and rules), or you can run your self-hosted server.
There are a few reasons why you'd want to run your own server:
You want to create a new community and attract other users over a common theme and usage rules.
You don't want to have to trust third-party servers or abide by their policies and want your server, under your domain, for your personal account.
You want complete control over your data, personal information, and content and visibility over what happens with your instance.
The Mastodon gGmbH non-profit organization provides a server implementation using Ruby, Node.js, PostgreSQL and Redis. Running the official server can be challenging, though. You need to own or rent a server or VPS somewhere; you have to install and configure the software, set up the database and public-facing web server, and configure and protect your network against attacks or abuse. And then you have to maintain all of that and deal with constant updates. It's a lot of scripting and technical work before you can get it up and running; definitely not something for the less technical enthusiasts.
Wildebeest serves two purposes: you can quickly deploy your Mastodon-compatible server on top of Cloudflare and connect it to the Fediverse in minutes, and you don't need to worry about maintaining or protecting it from abuse or attacks; Cloudflare will do it for you automatically.
Wildebeest is not a managed service. It's your instance, data, and code running in our cloud under your Cloudflare account. Furthermore, it's open-sourced, which means it keeps evolving with more features, and anyone can extend and improve it.
Here's what we support today:
ActivityPub, WebFinger, NodeInfo, WebPush and Mastodon-compatible APIs. Wildebeest can connect to or receive connections from other Fediverse servers.
Compatible with the most popular Mastodon web (like Pinafore), desktop, and mobile clients. We also provide a simple read-only web interface to explore the timelines and user profiles.
You can publish, edit, boost, or delete posts, sorry, toots. We support text, images, and (soon) video.
Anyone can follow you; you can follow anyone.
You can search for content.
You can register one or multiple accounts under your instance. Authentication can be email-based on or using any Cloudflare Access compatible IdP, like GitHub or Google.
You can edit your profile information, avatar, and header image.
How we built it
Our implementation is built entirely on top of our products and APIs. Building Wildebeest was another excellent opportunity to showcase our technology stack's power and versatility and prove how anyone can also use Cloudflare to build larger applications that involve multiple systems and complex requirements.
Here's a birds-eye diagram of Wildebeest's architecture:
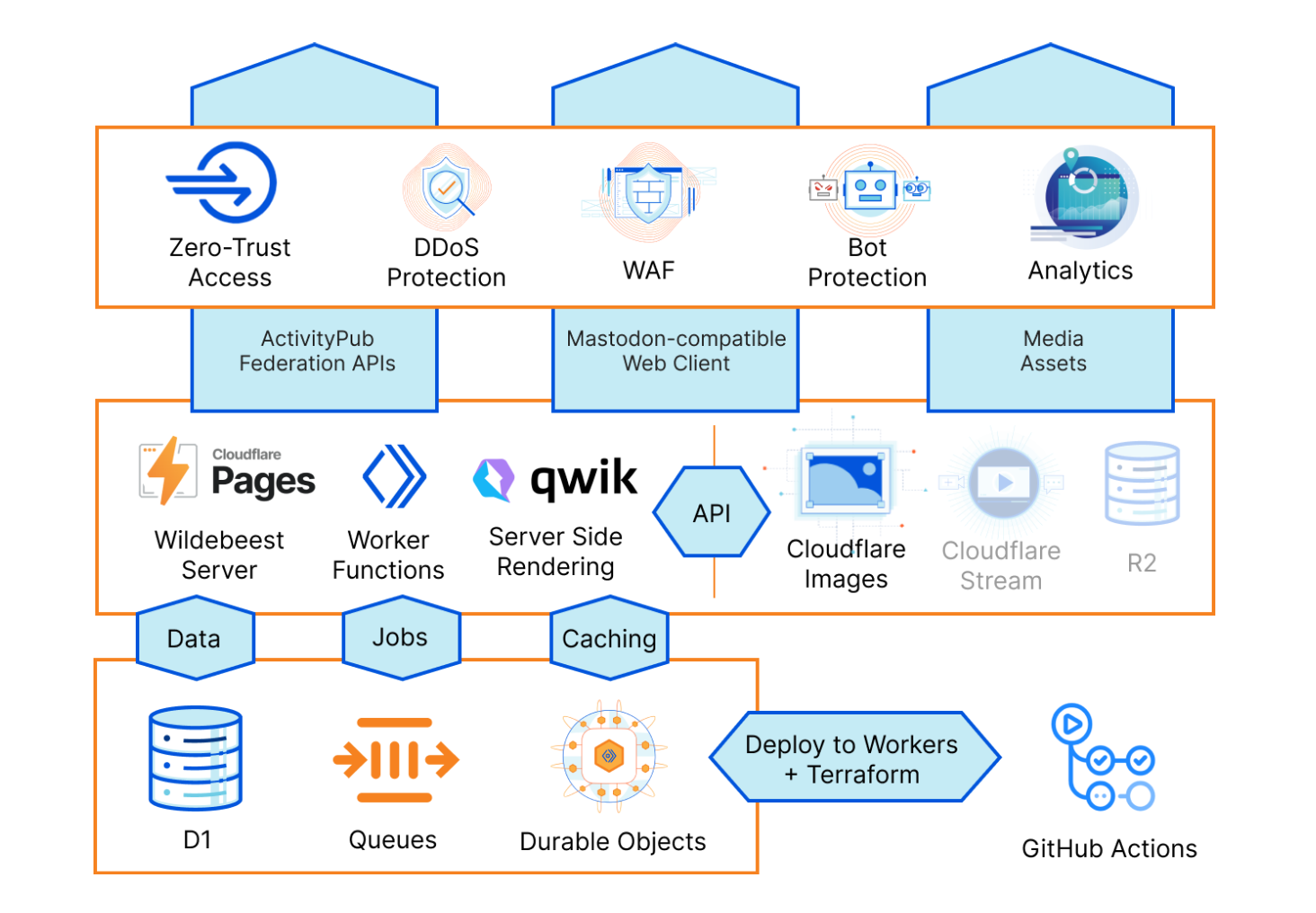
Let's get into the details and get technical now.
Cloudflare Pages
At the core, Wildebeest is a Cloudflare Pages project running its code using Pages Functions. Cloudflare Pages provides an excellent foundation for building and deploying your application and serving your bundled assets, Functions gives you full access to the Workers ecosystem, where you can run any code.
Functions has a built-in file-based router. The /functions directory structure, which is uploaded by Wildebeest’s continuous deployment builds, defines your application routes and what files and code will process each HTTP endpoint request. This routing technique is similar to what other frameworks like Next.js use.
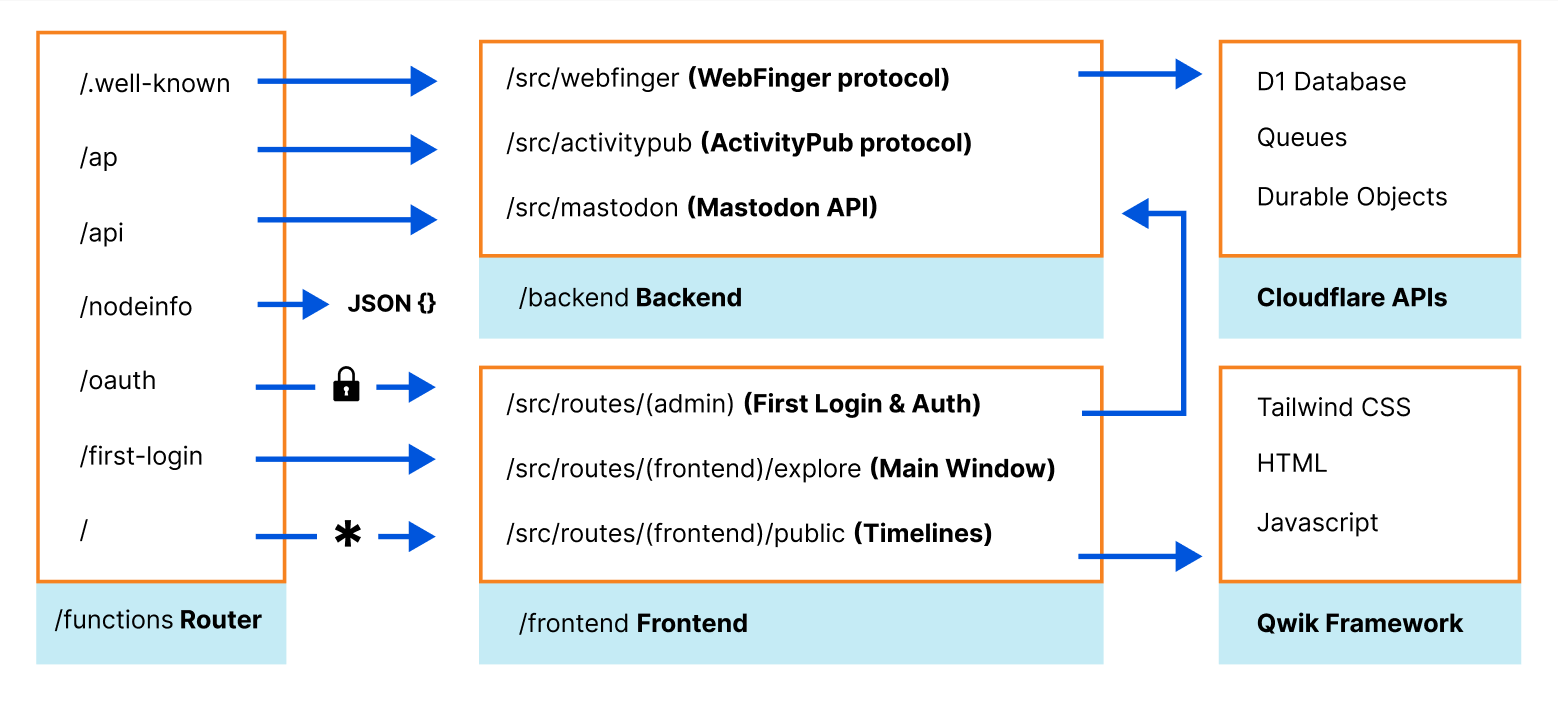
For example, Mastodon’s /api/v1/timelines/public API endpoint is handled by /functions/api/v1/timelines/public.ts with the onRequest method.
export onRequest = async ({ request, env }) => {
const { searchParams } = new URL(request.url)
const domain = new URL(request.url).hostname
...
return handleRequest(domain, env.DATABASE, {})
}
export async function handleRequest(
…
): Promise<Response> {
…
}
Unit testing these endpoints becomes easier too, since we only have to call the handleRequest() function from the testing framework. Check one of our Jest tests, mastodon.spec.ts:
import * as v1_instance from 'wildebeest/functions/api/v1/instance'
describe('Mastodon APIs', () => {
describe('instance', () => {
test('return the instance infos v1', async () => {
const res = await v1_instance.handleRequest(domain, env)
assert.equal(res.status, 200)
assertCORS(res)
const data = await res.json<Data>()
assert.equal(data.rules.length, 0)
assert(data.version.includes('Wildebeest'))
})
})
})
As with any other regular Worker, Functions also lets you set up bindings to interact with other Cloudflare products and features like KV, R2, D1, Durable Objects, and more. The list keeps growing.
We use Functions to implement a large portion of the official Mastodon API specification, making Wildebeest compatible with the existing ecosystem of other servers and client applications, and also to run our own read-only web frontend under the same project codebase.
Wildebeest’s web frontend uses Qwik, a general-purpose web framework that is optimized for speed, uses modern concepts like the JSX JavaScript syntax extension and supports server-side-rendering (SSR) and static site generation (SSG).
Qwik provides a Cloudflare Pages Adaptor out of the box, so we use that (check our framework guide to know more about how to deploy a Qwik site on Cloudflare Pages). For styling we use the Tailwind CSS framework, which Qwik supports natively.
Our frontend website code and static assets can be found under the /frontend directory. The application is handled by the /functions/[[path]].js dynamic route, which basically catches all the non-API requests, and then invokes Qwik’s own internal router, Qwik City, which takes over everything else after that.
The power and versatility of Pages and Functions routes make it possible to run both the backend APIs and a server-side-rendered dynamic client, effectively a full-stack app, under the same project.
Let's dig even deeper now, and understand how the server interacts with the other components in our architecture.
D1
Wildebeest uses D1, Cloudflare’s first SQL database for the Workers platform built on top of SQLite, now open to everyone in alpha, to store and query data. Here’s our schema:
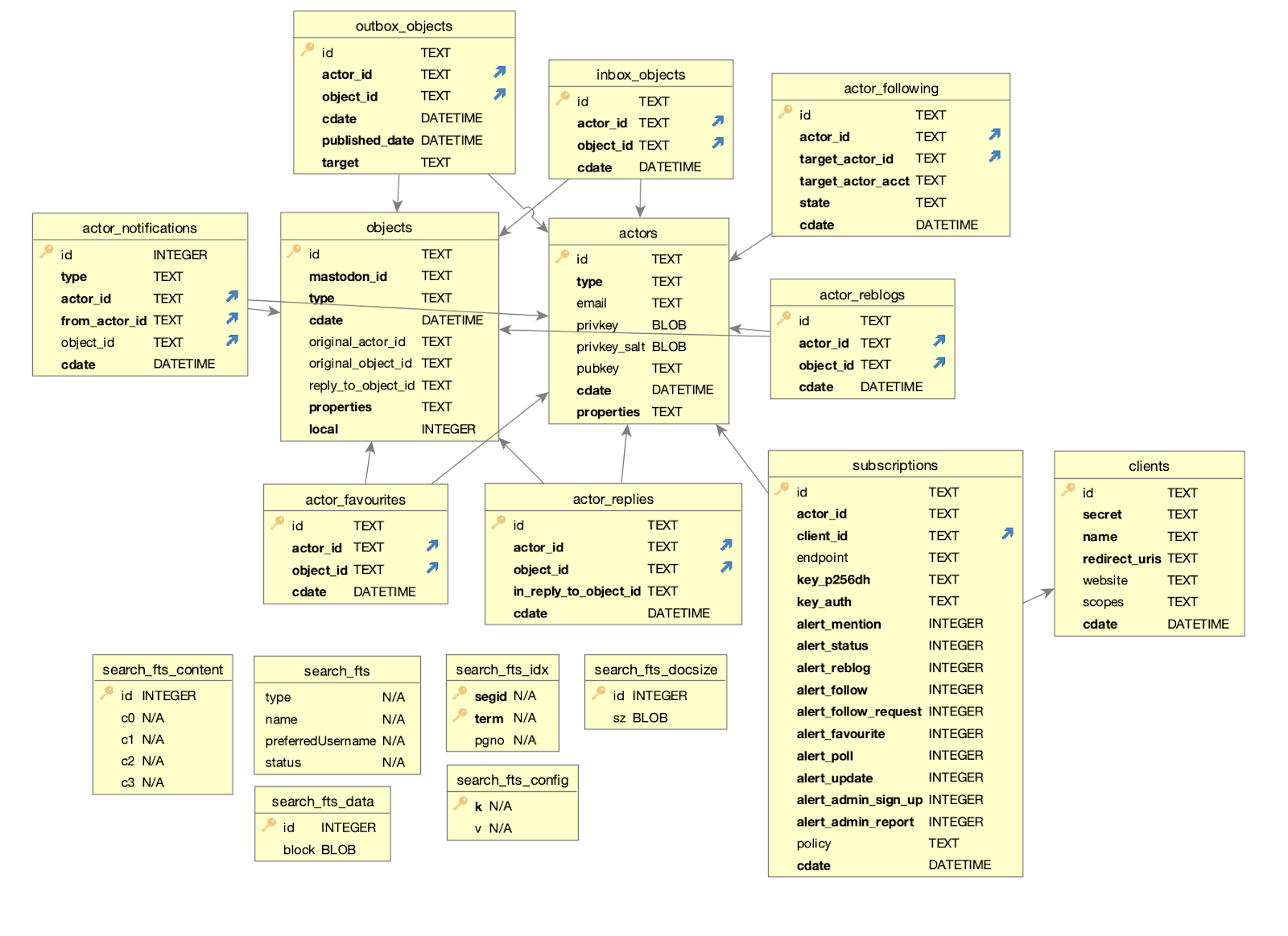
The schema will probably change in the future, as we add more features. That’s fine, D1 supports migrations which are great when you need to update your database schema without losing your data. With each new Wildebeest version, we can create a new migration file if it requires database schema changes.
-- Migration number: 0001 2023-01-16T13:09:04.033Z
CREATE UNIQUE INDEX unique_actor_following ON actor_following (actor_id, target_actor_id);
D1 exposes a powerful client API that developers can use to manipulate and query data from Worker scripts, or in our case, Pages Functions.
Here’s a simplified example of how we interact with D1 when you start following someone on the Fediverse:
export async function addFollowing(db, actor, target, targetAcct): Promise<UUID> {
const query = `INSERT OR IGNORE INTO actor_following (id, actor_id, target_actor_id, state, target_actor_acct) VALUES (?, ?, ?, ?, ?)`
const out = await db
.prepare(query)
.bind(id, actor.id.toString(), target.id.toString(), STATE_PENDING, targetAcct)
.run()
return id
}
Cloudflare’s culture of dogfooding and building on top of our own products means that we sometimes experience their shortcomings before our users. We did face a few challenges using D1, which is built on SQLite, to store our data. Here are two examples.
ActivityPub uses UUIDs to identify objects and reference them in URIs extensively. These objects need to be stored in the database. Other databases like PostgreSQL provide built-in functions to generate unique identifiers. SQLite and D1 don't have that, yet, it’s in our roadmap.
Worry not though, the Workers runtime supports Web Crypto, so we use crypto.randomUUID() to get our unique identifiers. Check the /backend/src/activitypub/actors/inbox.ts:
export async function addObjectInInbox(db, actor, obj) {
const id = crypto.randomUUID()
const out = await db
.prepare('INSERT INTO inbox_objects(id, actor_id, object_id) VALUES(?, ?, ?)')
.bind(id, actor.id.toString(), obj.id.toString())
.run()
}Problem solved.
The other example is that we need to store dates with sub-second resolution. Again, databases like PostgreSQL have that:
psql> select now();
2023-02-01 11:45:17.425563+00However SQLite falls short with:
sqlite> select datetime();
2023-02-01 11:44:02We worked around this problem with a small hack using strftime():
sqlite> select strftime('%Y-%m-%d %H:%M:%f', 'NOW');
2023-02-01 11:49:35.624See our initial SQL schema, look for the cdate defaults.
Images
Mastodon content has a lot of rich media. We don't need to reinvent the wheel and build an image pipeline; Cloudflare Images provides APIs to upload, transform, and serve optimized images from our global CDN, so it's the perfect fit for Wildebeest's requirements.
Things like posting content images, the profile avatar, or headers, all use the Images APIs. See /backend/src/media/image.ts to understand how we interface with Images.
async function upload(file: File, config: Config): Promise<UploadResult> {
const formData = new FormData()
const url = `https://api.cloudflare.com/client/v4/accounts/${config.accountId}/images/v1`
formData.set('file', file)
const res = await fetch(url, {
method: 'POST',
body: formData,
headers: {
authorization: 'Bearer ' + config.apiToken,
},
})
const data = await res.json()
return data.result
}If you're curious about Images for your next project, here's a tutorial on how to integrate Cloudflare Images on your website.
Cloudflare Images is also available from the dashboard. You can use it to browse or manage your catalog quickly.
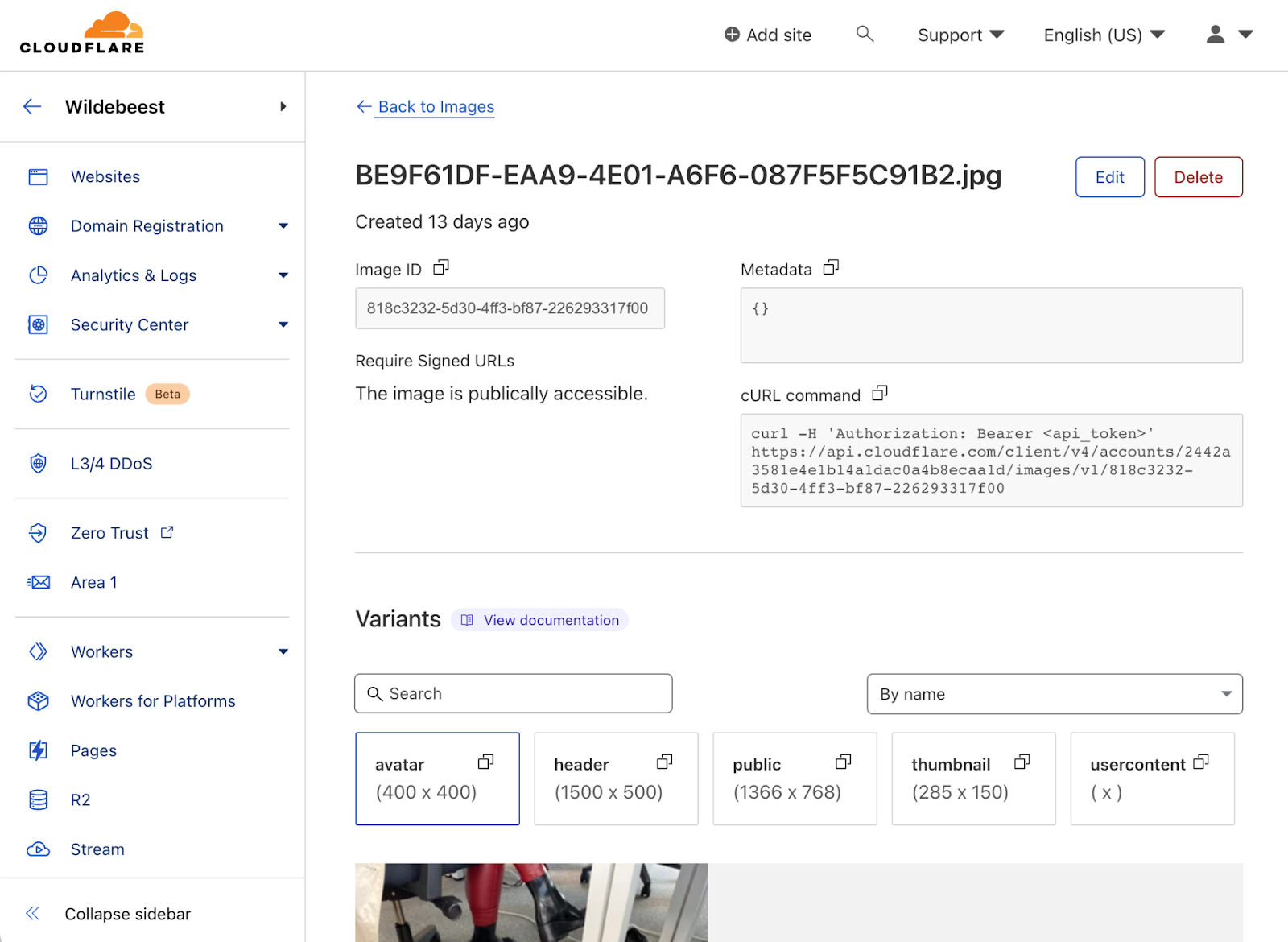
Queues
The ActivityPub protocol is chatty by design. Depending on the size of your social graph, there might be a lot of back-and-forth HTTP traffic. We can’t have the clients blocked waiting for hundreds of Fediverse message deliveries every time someone posts something.
We needed a way to work asynchronously and launch background jobs to offload data processing away from the main app and keep the clients snappy. The official Mastodon server has a similar strategy using Sidekiq to do background processing.
Fortunately, we don't need to worry about any of this complexity either. Cloudflare Queues allows developers to send and receive messages with guaranteed delivery, and offload work from your Workers' requests, effectively providing you with asynchronous batch job capabilities.
To put it simply, you have a queue topic identifier, which is basically a buffered list that scales automatically, then you have one or more producers that, well, produce structured messages, JSON objects in our case, and put them in the queue (you define their schema), and finally you have one or more consumers that subscribes that queue, receive its messages and process them, at their own speed.
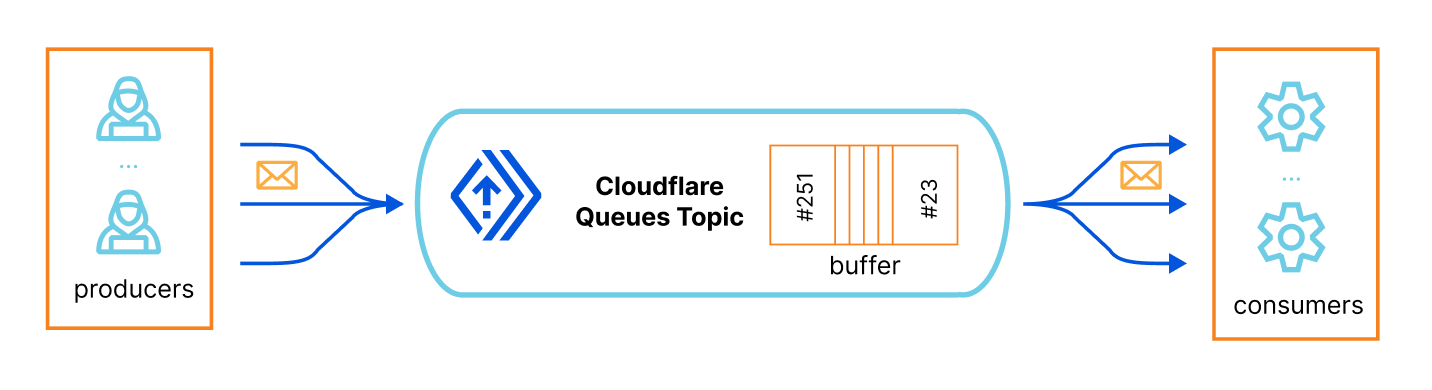
Here’s the How Queues works page for more information.
In our case, the main application produces queue jobs whenever any incoming API call requires long, expensive operations. For example, when someone posts, sorry, toots something, we need to broadcast that to their followers' inboxes, potentially triggering many requests to remote servers. Here we are queueing a job for that, thus freeing the APIs to keep responding:
export async function deliverFollowers(
db: D1Database,
from: Actor,
activity: Activity,
queue: Queue
) {
const followers = await getFollowers(db, from)
const messages = followers.map((id) => {
const body = {
activity: JSON.parse(JSON.stringify(activity)),
actorId: from.id.toString(),
toActorId: id,
}
return { body }
})
await queue.sendBatch(messages)
}Similarly, we don't want to stop the main APIs when remote servers deliver messages to our instance inboxes. Here's Wildebeest creating asynchronous jobs when it receives messages in the inbox:
export async function handleRequest(
domain: string,
db: D1Database,
id: string,
activity: Activity,
queue: Queue,
): Promise<Response> {
const handle = parseHandle(id)
const actorId = actorURL(domain, handle.localPart)
const actor = await actors.getPersonById(db, actorId)
// creates job
await queue.send({
type: MessageType.Inbox,
actorId: actor.id.toString(),
activity,
})
// frees the API
return new Response('', { status: 200 })
}And the final piece of the puzzle, our queue consumer runs in a separate Worker, independently from the Pages project. The consumer listens for new messages and processes them sequentially, at its rhythm, freeing everyone else from blocking. When things get busy, the queue grows its buffer. Still, things keep running, and the jobs will eventually get dispatched, freeing the main APIs for the critical stuff: responding to remote servers and clients as quickly as possible.
export default {
async queue(batch, env, ctx) {
for (const message of batch.messages) {
…
switch (message.body.type) {
case MessageType.Inbox: {
await handleInboxMessage(...)
break
}
case MessageType.Deliver: {
await handleDeliverMessage(...)
break
}
}
}
},
}If you want to get your hands dirty with Queues, here’s a simple example on Using Queues to store data in R2.
Caching and Durable Objects
Caching repetitive operations is yet another strategy for improving performance in complex applications that require data processing. A famous Netscape developer, Phil Karlton, once said: "There are only two hard things in Computer Science: cache invalidation and naming things."
Cloudflare obviously knows a lot about caching since it's a core feature of our global CDN. We also provide Workers KV to our customers, a global, low-latency, key-value data store that anyone can use to cache data objects in our data centers and build fast websites and applications.
However, KV achieves its performance by being eventually consistent. While this is fine for many applications and use cases, it's not ideal for others.
The ActivityPub protocol is highly transactional and can't afford eventual consistency. Here's an example: generating complete timelines is expensive, so we cache that operation. However, when you post something, we need to invalidate that cache before we reply to the client. Otherwise, the new post won't be in the timeline and the client can fail with an error because it doesn’t see it. This actually happened to us with one of the most popular clients.
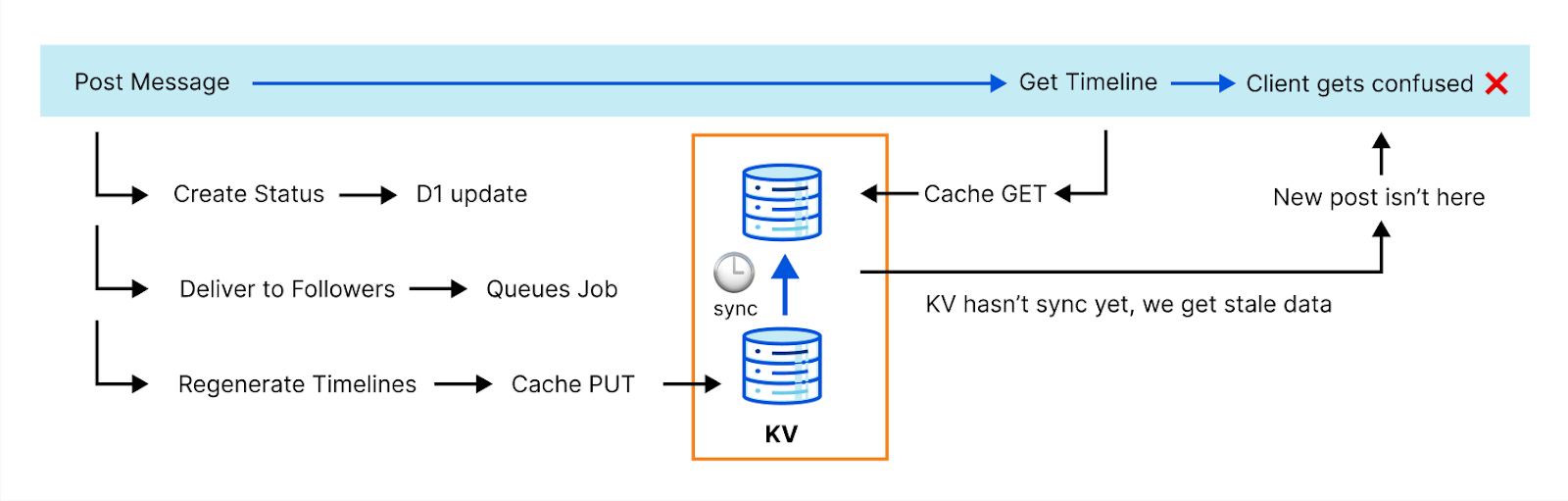
We needed to get clever. The team discussed a few options. Fortunately, our API catalog has plenty of options. Meet Durable Objects.
Durable Objects are single-instance Workers that provide a transactional storage API. They're ideal when you need central coordination, strong consistency, and state persistence. You can use Durable Objects in cases like handling the state of multiple WebSocket connections, coordinating and routing messages in a chatroom, or even running a multiplayer game like Doom.
You know where this is going now. Yes, we implemented our key-value caching subsystem for Wildebeest on top of a Durable Object. By taking advantage of the DO's native transactional storage API, we can have strong guarantees that whenever we create or change a key, the next read will always return the latest version.
The idea is so simple and effective that it took us literally a few lines of code to implement a key-value cache with two primitives: HTTP PUT and GET.
export class WildebeestCache {
async fetch(request: Request) {
if (request.method === 'GET') {
const { pathname } = new URL(request.url)
const key = pathname.slice(1)
const value = await this.storage.get(key)
return new Response(JSON.stringify(value))
}
if (request.method === 'PUT') {
const { key, value } = await request.json()
await this.storage.put(key, value)
return new Response('', { status: 201 })
}
}
}Strong consistency it is. Let's move to user registration and authentication now.
Zero Trust Access
The official Mastodon server handles user registrations, typically using email, before you can choose your local username and start using the service. Handling user registration and authentication can be daunting and time-consuming if we were to build it from scratch though.
Furthermore, people don't want to create new credentials for every new service they want to use and instead want more convenient OAuth-like authorization and authentication methods so that they can reuse their existing Apple, Google, or GitHub accounts.
We wanted to simplify things using Cloudflare’s built-in features. Needless to say, we have a product that handles user onboarding, authentication, and access policies to any application behind Cloudflare; it's called Zero Trust. So we put Wildebeest behind it.
Zero Trust Access can either do one-time PIN (OTP) authentication using email or single-sign-on (SSO) with many identity providers (examples: Google, Facebook, GitHub, LinkedIn), including any generic one supporting SAML 2.0.
When you start using Wildebeest with a client, you don't need to register at all. Instead, you go straight to log in, which will redirect you to the Access page and handle the authentication according to the policy that you, the owner of your instance, configured.
The policy defines who can authenticate, and how.
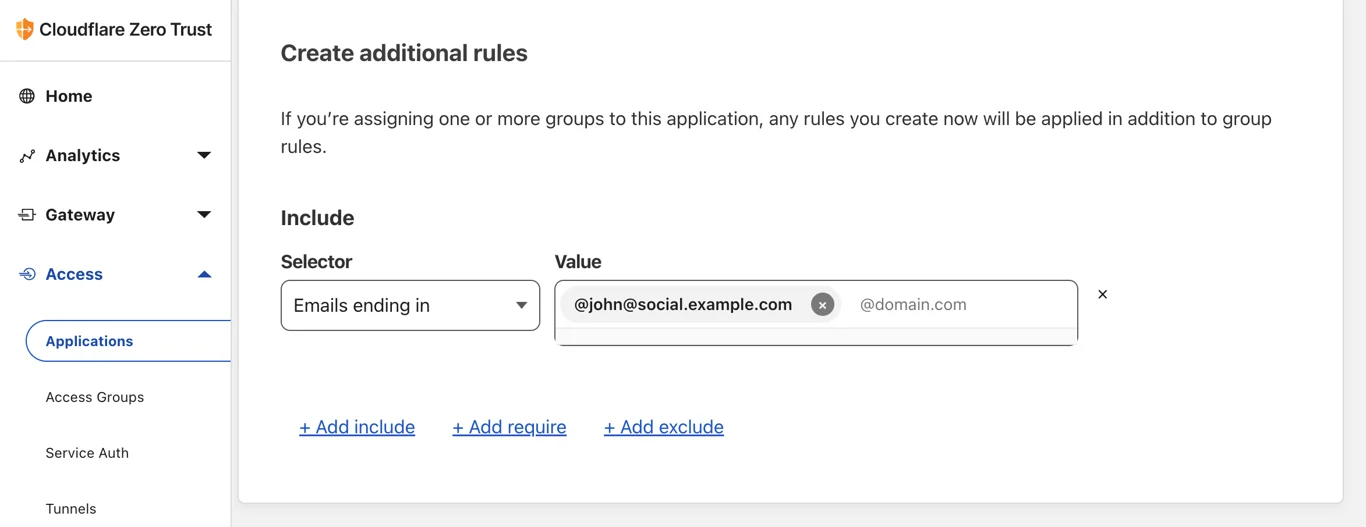
When authenticated, Access will redirect you back to Wildebeest. The first time this happens, we will detect that we don't have information about the user and ask for your Username and Display Name. This will be asked only once and is what will be to create your public Mastodon profile.
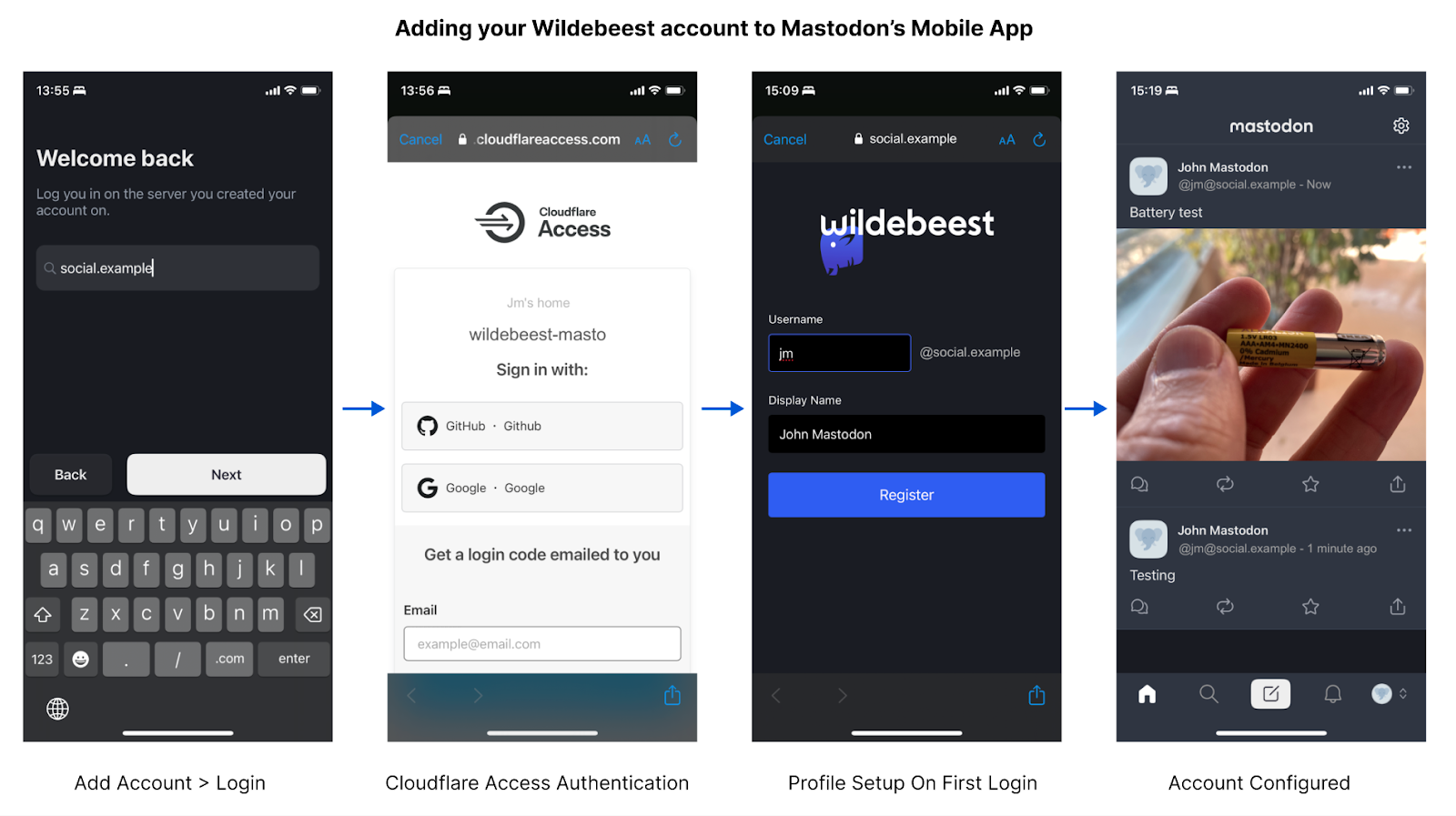
Technically, Wildebeest implements the OAuth 2 specification. Zero Trust protects the /oauth/authorize endpoint and issues a valid JWT token in the request headers when the user is authenticated. Wildebeest then reads and verifies the JWT and returns an authorization code in the URL redirect.
Once the client has an authorization code, it can use the /oauth/token endpoint to obtain an API access token. Subsequent API calls inject a bearer token in the Authorization header:
Authorization: Bearer access_token
Deployment and Continuous Integration
We didn't want to run a managed service for Mastodon as it would somewhat diminish the concepts of federation and data ownership. Also, we recognize that ActivityPub and Mastodon are emerging, fast-paced technologies that will evolve quickly and in ways that are difficult to predict just yet.
For these reasons, we thought the best way to help the ecosystem right now would be to provide an open-source software package that anyone could use, customize, improve, and deploy on top of our cloud. Cloudflare will obviously keep improving Wildebeest and support the community, but we want to give our Fediverse maintainers complete control and ownership of their instances and data.
The remaining question was, how do we distribute the Wildebeest bundle and make it easy to deploy into someone's account when it requires configuring so many Cloudflare features, and how do we facilitate updating the software over time?
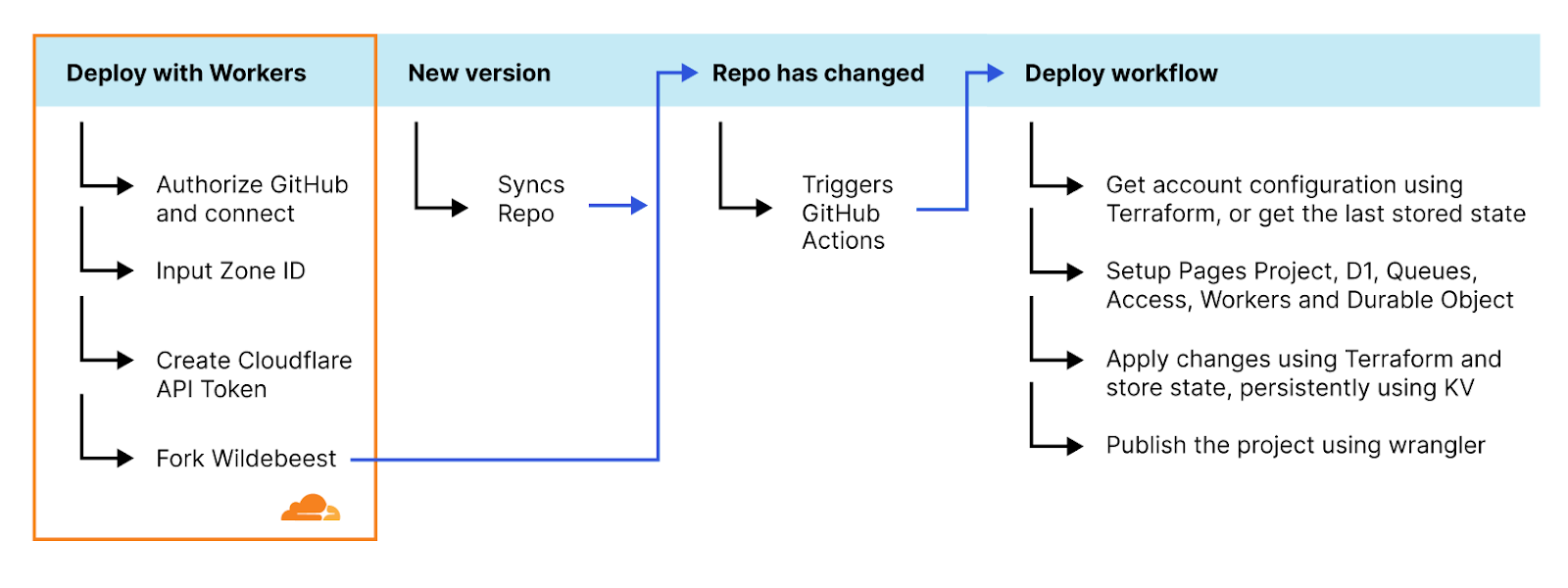
The solution ended up being a clever mix of using GitHub with GitHub Actions, Deploy with Workers, and Terraform.

The Deploy with Workers button is a specially crafted link that auto-generates a workflow page where the user gets asked some questions, and Cloudflare handles authorizing GitHub to deploy to Workers, automatically forks the Wildebeest repository into the user's account, and then configures and deploys the project using a GitHub Actions workflow.
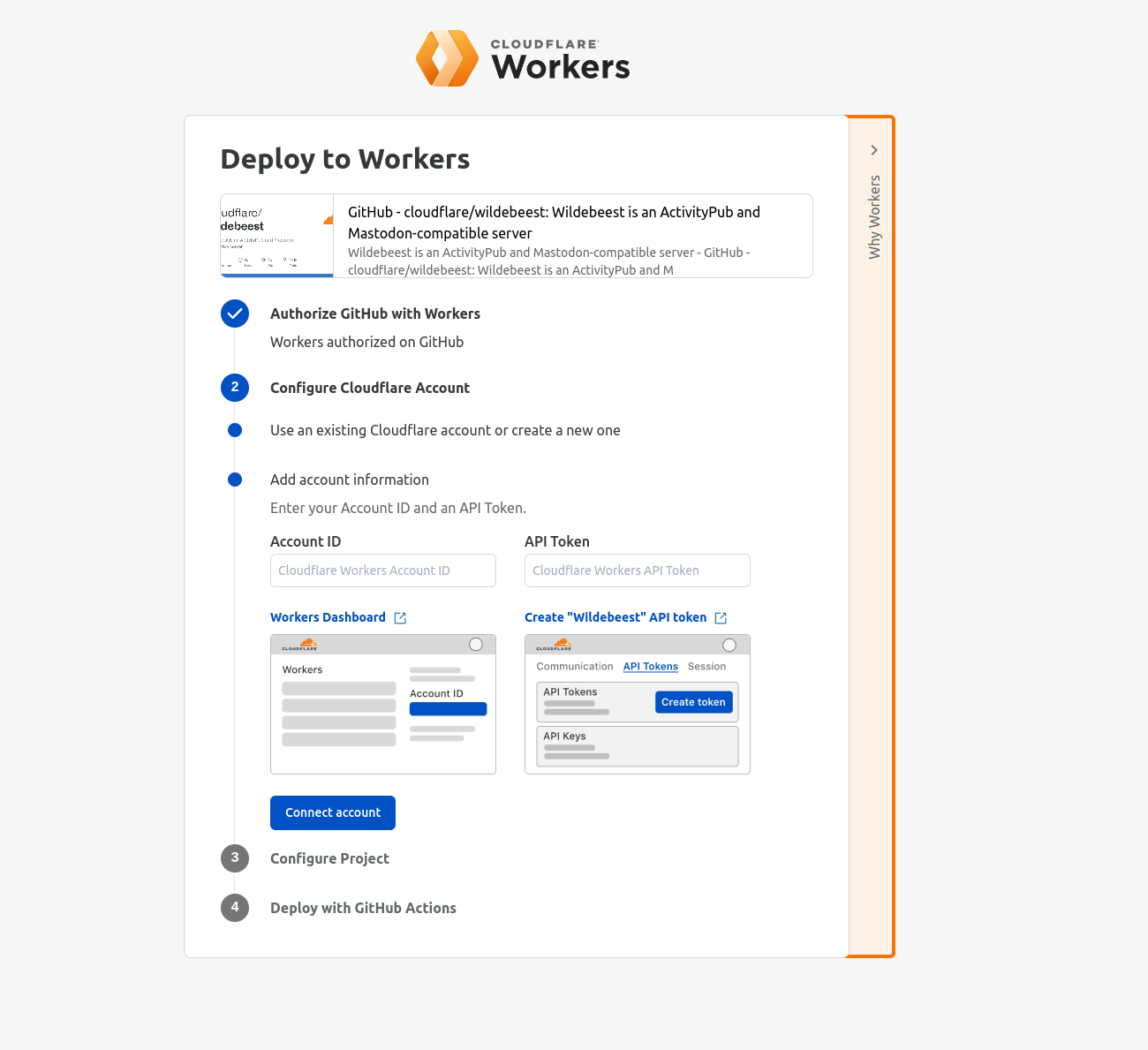
A GitHub Actions workflow is a YAML file that declares what to do in every step. Here’s the Wildebeest workflow (simplified):
name: Deploy
on:
push:
branches:
- main
repository_dispatch:
jobs:
deploy:
runs-on: ubuntu-latest
timeout-minutes: 60
steps:
- name: Ensure CF_DEPLOY_DOMAIN and CF_ZONE_ID are defined
...
- name: Create D1 database
uses: cloudflare/wrangler-action@2.0.0
with:
command: d1 create wildebeest-${{ env.OWNER_LOWER }}
...
- name: retrieve Zero Trust organization
...
- name: retrieve Terraform state KV namespace
...
- name: download VAPID keys
...
- name: Publish DO
- name: Configure
run: terraform plan && terraform apply -auto-approve
- name: Create Queue
...
- name: Publish consumer
...
- name: Publish
uses: cloudflare/wrangler-action@2.0.0
with:
command: pages publish --project-name=wildebeest-${{ env.OWNER_LOWER }} .Updating Wildebeest
This workflow runs automatically every time the main branch changes, so updating the Wildebeest is as easy as synchronizing the upstream official repository with the fork. You don't even need to use git commands for that; GitHub provides a convenient Sync button in the UI that you can simply click.
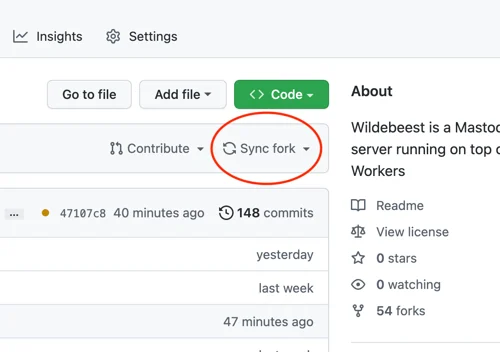
What's more? Updates are incremental and non-destructive. When the GitHub Actions workflow redeploys Wildebeest, we only make the necessary changes to your configuration and nothing else. You don't lose your data; we don't need to delete your existing configurations. Here’s how we achieved this:
We use Terraform, a declarative configuration language and tool that interacts with our APIs and can query and configure your Cloudflare features. Here's the trick, whenever we apply a new configuration, we keep a copy of the Terraform state for Wildebeest in a Cloudflare KV key. When a new deployment is triggered, we get that state from the KV copy, calculate the differences, then change only what's necessary.
Data loss is not a problem either because, as you read above, D1 supports migrations. If we need to add a new column to a table or a new table, we don't need to destroy the database and create it again; we just apply the necessary SQL to that change.
Protection, optimization and observability, naturally
Once Wildebeest is up and running, you can protect it from bad traffic and malicious actors. Cloudflare offers you DDoS, WAF, and Bot Management protection out of the box at a click's distance.
Likewise, you'll get instant network and content delivery optimizations from our products and analytics on how your Wildebeest instance is performing and being used.
ActivityPub, WebFinger, NodeInfo and Mastodon APIs
Mastodon popularized the Fediverse concept, but many of the underlying technologies used have been around for quite a while. This is one of those rare moments when everything finally comes together to create a working platform that answers an actual use case for Internet users. Let's quickly go through the protocols that Wildebeest had to implement:
ActivityPub
ActivityPub is a decentralized social networking protocol and has been around as a W3C recommendation since at least 2018. It defines client APIs for creating and manipulating content and server-to-server APIs for content exchange and notifications, also known as federation. ActivityPub uses ActivityStreams, an even older W3C protocol, for its vocabulary.
The concepts of Actors (profiles), messages or Objects (the toots), inbox (where you receive toots from people you follow), and outbox (where you send your toots to the people you follow), to name a few of many other actions and activities, are all defined on the ActivityPub specification.
Here’s our folder with the ActivityPub implementation.
import type { APObject } from 'wildebeest/backend/src/activitypub/objects'
import type { Actor } from 'wildebeest/backend/src/activitypub/actors'
export async function addObjectInInbox(db, actor, obj) {
const id = crypto.randomUUID()
const out = await db
.prepare('INSERT INTO inbox_objects(id, actor_id, object_id) VALUES(?, ?, ?)')
.bind(id, actor.id.toString(), obj.id.toString())
.run()
}
WebFinger
WebFinger is a simple HTTP protocol used to discover information about any entity, like a profile, a server, or a specific feature. It resolves URIs to resource objects.
Mastodon uses WebFinger lookups to discover information about remote users. For example, say you want to interact with @user@example.com. Your local server would request https://example.com/.well-known/webfinger?resource=acct:user@example.com (using the acct scheme) and get something like this:
{
"subject": "acct:user@example.com",
"aliases": [
"https://example.com/ap/users/user"
],
"links": [
{
"rel": "self",
"type": "application/activity+json",
"href": "https://example.com/ap/users/user"
}
]
}
Now we know how to interact with @user@example.com, using the https://example.com/ap/users/user endpoint.
Here’s our WebFinger response:
export async function handleRequest(request, db): Promise<Response> {
…
const jsonLink = /* … link to actor */
const res: WebFingerResponse = {
subject: `acct:...`,
aliases: [jsonLink],
links: [
{
rel: 'self',
type: 'application/activity+json',
href: jsonLink,
},
],
}
return new Response(JSON.stringify(res), { headers })
}Mastodon API
Finally, things like setting your server information, profile information, generating timelines, notifications, and searches, are all Mastodon-specific APIs. The Mastodon open-source project defines a catalog of REST APIs, and you can find all the documentation for them on their website.
Our Mastodon API implementation can be found here (REST endpoints) and here (backend primitives). Here’s an example of Mastodon’s server information /api/v2/instance implemented by Wildebeest:
export async function handleRequest(domain, db, env) {
const res: InstanceConfigV2 = {
domain,
title: env.INSTANCE_TITLE,
version: getVersion(),
source_url: 'https://github.com/cloudflare/wildebeest',
description: env.INSTANCE_DESCR,
thumbnail: {
url: DEFAULT_THUMBNAIL,
},
languages: ['en'],
registrations: {
enabled: false,
},
contact: {
email: env.ADMIN_EMAIL,
},
rules: [],
}
return new Response(JSON.stringify(res), { headers })
}Wildebeest also implements WebPush for client notifications and NodeInfo for server information.
Other Mastodon-compatible servers had to implement all these protocols too; Wildebeest is one of them. The community is very active in discussing future enhancements; we will keep improving our compatibility and adding support to more features over time, ensuring that Wildebeest plays well with the Fediverse ecosystem of servers and clients emerging.
Get started now
Enough about technology; let's get you into the Fediverse. We tried to detail all the steps to deploy your server. To start using Wildebeest, head to the public GitHub repository and check our Get Started tutorial.
Most of Wildebeest's dependencies offer a generous free plan that allows you to try them for personal or hobby projects that aren't business-critical, however you will need to subscribe an Images plan (the lowest tier should be enough for most needs) and, depending on your server load, Workers Unbound (again, the minimum cost should be plenty for most use cases).
Following our dogfooding mantra, Cloudflare is also officially joining the Fediverse today. You can start following our Mastodon accounts and get the same experience of having regular updates from Cloudflare as you get from us on other social platforms, using your favorite Mastodon apps. These accounts are entirely running on top of a Wildebeest server:
@cloudflare@cloudflare.social - Our main account
@radar@cloudflare.social - Cloudflare Radar

Wildebeest is compatible with most client apps; we are confirmed to work with the official Mastodon Android and iOS apps, Pinafore, Mammoth, and tooot, and looking into others like Ivory. If your favorite isn’t working, please submit an issue here, we’ll do our best to help support it.
Final words
Wildebeest was built entirely on top of our Supercloud stack. It was one of the most complete and complex projects we have created that uses various Cloudflare products and features.
We hope this write-up inspires you to not only try deploying Wildebeest and joining the Fediverse, but also building your next application, however demanding it is, on top of Cloudflare.
Wildebeest is a minimally viable Mastodon-compatible server right now, but we will keep improving it with more features and supporting it over time; after all, we're using it for our official accounts. It is also open-sourced, meaning you are more than welcome to contribute with pull requests or feedback.
In the meantime, we opened a Wildebeest room on our Developers Discord Server and are keeping an eye open on the GitHub repo issues tab. Feel free to engage with us; the team is eager to know how you use Wildebeest and answer your questions.
PS: The code snippets in this blog were simplified to benefit readability and space (the TypeScript types and error handling code were removed, for example). Please refer to the GitHub repo links for the complete versions.