



Super Slurper 是 Cloudflare 打造的数据迁移工具,旨在简化云对象存储提供商和 Cloudflare R2 之间的大规模数据传输。自推出以来,已有数千名开发人员使用 Super Slurper 将 PB 级数据从 AWS S3、Google Cloud Storage 和 其他 S3 兼容服务 迁移至 R2。
但我们看到了进一步提升性能的机会。基于我们的开发人员平台,我们从零开始重新设计了 Super Slurper 的架构,使用 Cloudflare Workers、Durable Objects 和 Queues,将传输速度提升高达 5 倍。在本文中,我们将深入探讨原始架构、识别的性能瓶颈、解决方案,以及这些改进的实际影响。
原有架构与性能瓶颈
Super Slurper 最初与 SourcingKit 共享架构,后者是一个用于将图像从 AWS S3 批量导入到 Cloudflare Images 的工具。SourcingKit 部署在 Kubernetes 上,与 Images 服务一起运行。在开始构建 Super Slurper 时,我们将其拆分到独立的 Kubernetes 命名空间,并引入了几个新的 API,使其更容易在对象存储应用场景中使用。这一架构配置运行良好,帮助数千名开发人员成功将数据迁移至 R2。
然而,其中并非没有挑战。SourcingKit 并不是为处理大规模 PB 级传输所需的规模而设计的。SourcingKit 乃至 Super Slurper 运行在位于核心数据中心的 Kubernetes 集群上,这意味着它必须与 Cloudflare 的控制平面、分析服务和其他服务共享计算资源和带宽。随着迁移数量的增长,这些资源约束逐渐成为明显的性能瓶颈。
对于在对象存储提供商之间传输数据的服务而言,其工作流程非常简单:列出源存储中的对象,将其复制到目标存储,并重复此过程。这正是原版 Super Slurper 的工作方式。我们列出来自源存储桶的对象,将该列表推送到一个基于 Postgres 的队列(pg_queue),然后以稳定的速度从此队列中拉出对象以复制过来。鉴于对象存储迁移的规模,带宽使用量势必居高不下。这使得系统扩展存在挑战性。
为了解决仅在我们的核心数据中心运行的带宽限制,我们引入了 Cloudflare Workers。我们不再在核心数据中心处理数据复制,而是开始调用 Worker 执行实际的复制操作:
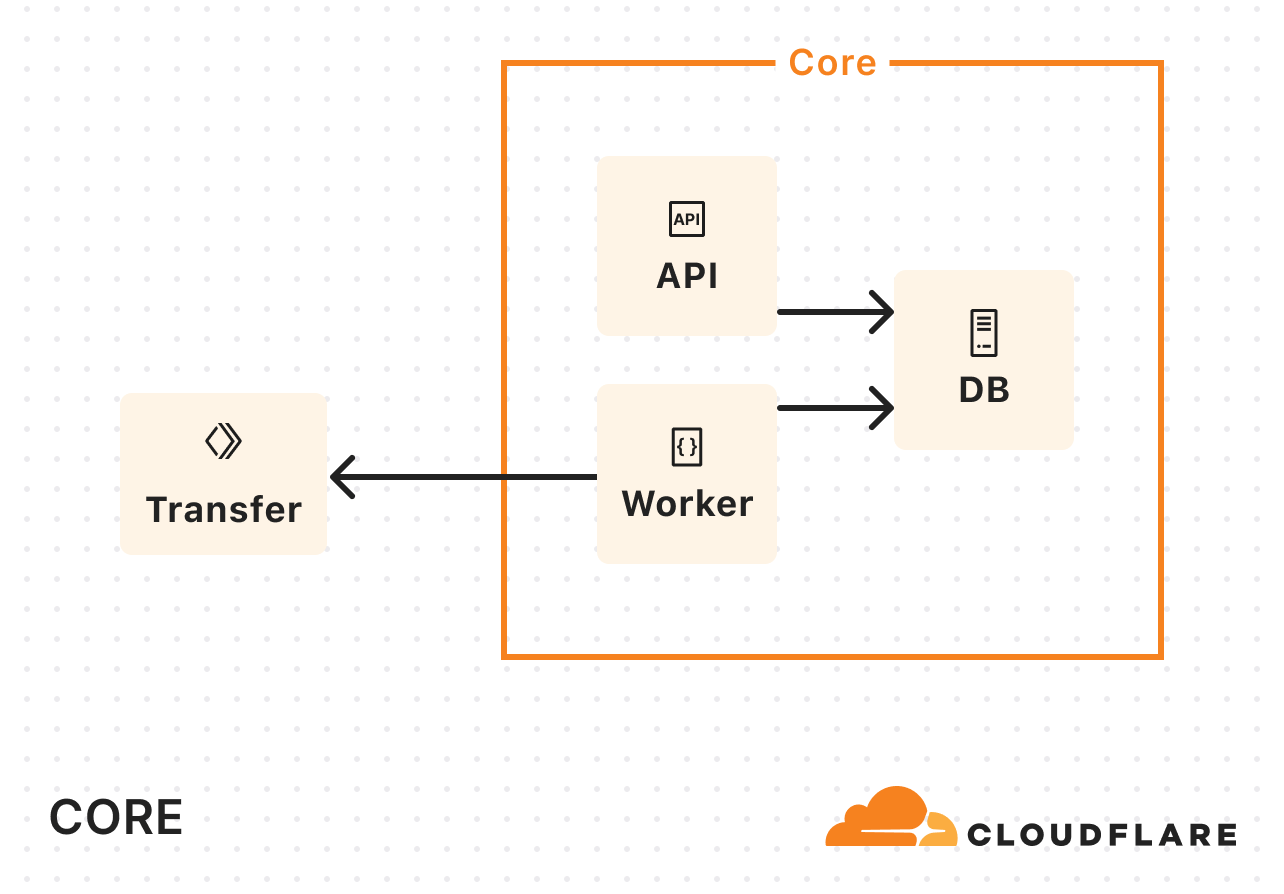
随着 Super Slurper 使用量增加,我们的 Kubernetes 资源消耗也在增加。在数据传输过程中,大量时间都耗费在等待网络 I/O 或存储操作上,而非实际执行计算密集型任务。所以我们不需要更多的内存或更多的 CPU,我们需要更多的并发。
为了跟上需求,我们不断增加副本数量。但最终,我们遇到了瓶颈。我们面临着可扩展性方面的挑战,当运行大约数十个 Pod 时,我们希望将其进一步增加几个数量级。
我们决定从最基本原理重新思考整个方案,而不是依赖已继承的架构。在大约一周的时间里,我们使用 Cloudflare Workers、Durable Objects 和 Queues构建了一个粗略的概念验证原型。我们列出源存储桶中的对象,将它们推送到队列中,然后使用队列中的消息来启动传输。尽管这听起来与我们最初的实现方案非常相似,但基于 Cloudflare 开发人员平台构建使我们能够自动扩展到比之前高一个数量级的规模。
Cloudflare Queues:支持异步对象传输,并可自动扩展以满足迁移对象的数量需求。
Cloudflare Workers:运行轻量级计算任务,没有 Kubernetes 的开销,并优化进程每个部分的运行位置,以降低延迟和提高性能。
基于 SQLite 的 Durable Objects (DO):充当一个完全分布式的数据库,消除了单个 PostgreSQL 实例的局限性。
Hyperdrive:提供对原始 PostgreSQL 数据库中历史作业数据的快速访问,并保留其作为存档存储。
我们进行了几轮测试,发现对于小规模传输(数百个对象)时,我们的概念验证方案性能低于原始实现,但随着传输规模扩展到数百万个对象时,性能逐渐匹配并最终超越了原始实现。那是我们需要投入时间将概念验证投入生产的信号。
我们移除了概念验证临时方案,专注于稳定性优化,并探索了使传输能够实现更高并发的新方法。经过几次迭代后,我们获得了满意的效果。
全新架构: Workers、 Queues 和 Durable Objects
处理层:管理迁移流程
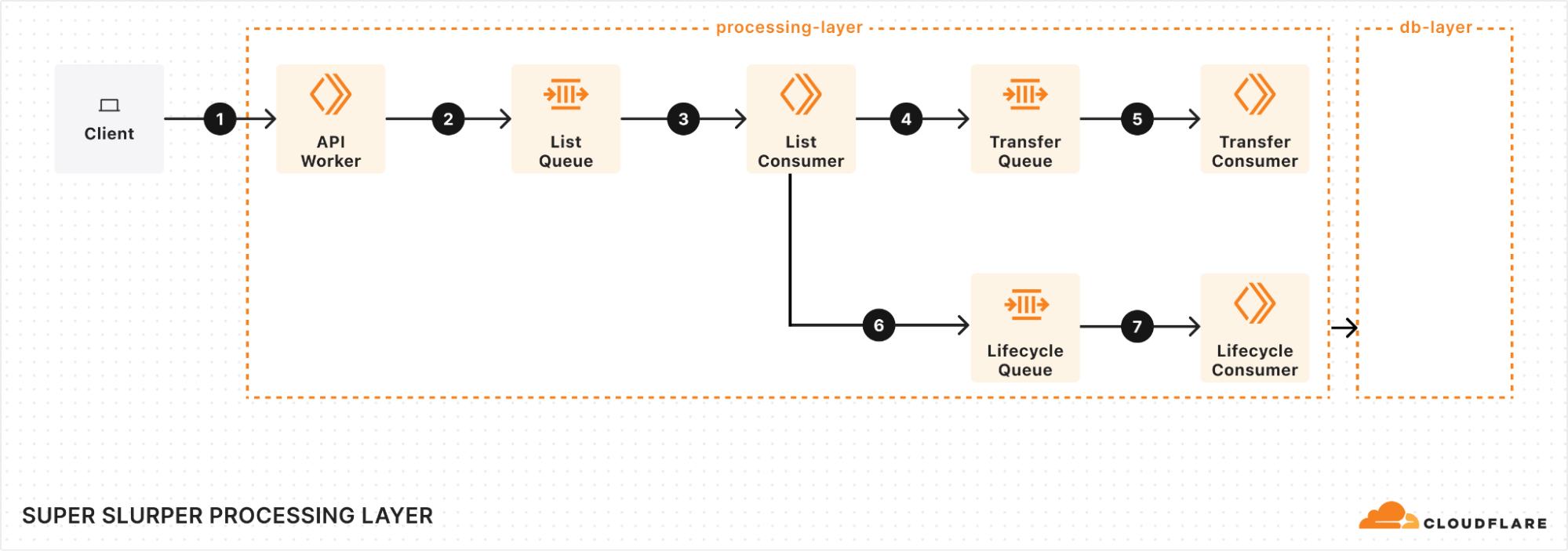
我们处理层的核心是 队列、消费者和 workers 。其过程如下所示:
启动迁移
当客户端触发迁移时,它首先向我们的 API Worker 发送请求。这个 worker 获取迁移的详细信息,存储在数据库中,并向 List Queue 添加消息以启动迁移过程。
列出源存储对象
List Queue 是事务开始处理的关键环节。它从队列中拉取消息,从源存储桶中检索对象列表,应用任何必要的过滤器,并将重要的元数据存储在数据库中。然后,它通过将对象传输消息排队到 Transfer Queue 中来创建新任务。
我们立即将新批次的工作排队,最大程度增加并发。内置的限流机制可以防止我们在发生意外故障时向队列添加更多的消息,例如从属系统宕机。这有助于保持稳定性并防止中断期间过载。
高效的对象传输
Transfer Queue Consumer Workers 从队列中提取对象传输消息,通过锁定数据库中的对象键来确保每个对象仅被处理一次。传输完成后,该对象将被解锁。对于大型对象,我们将其拆分为可管理的块,并以分段上传的方式传输。
优雅地处理故障
在任何分布式系统中,故障都是不可避免的,我们必须确保对此做好充分的容错处理。我们实现了暂时性故障的自动重试,确保问题不会打断迁移过程。但是,如果重试无法解决问题,则消息会进入 Dead Letter Queue (DLQ) ,并记录下来供以后查看和解决。
作业完成与生命周期管理
一旦所有对象列出且开始传输, Lifecycle Queue Consumer 将持续监控整个过程。它会监控传输过程,确保没有对象被遗漏。当所有传输完成后,作业将被标记为已完成,迁移过程随即结束。
数据库层:持久化存储和传统数据检索
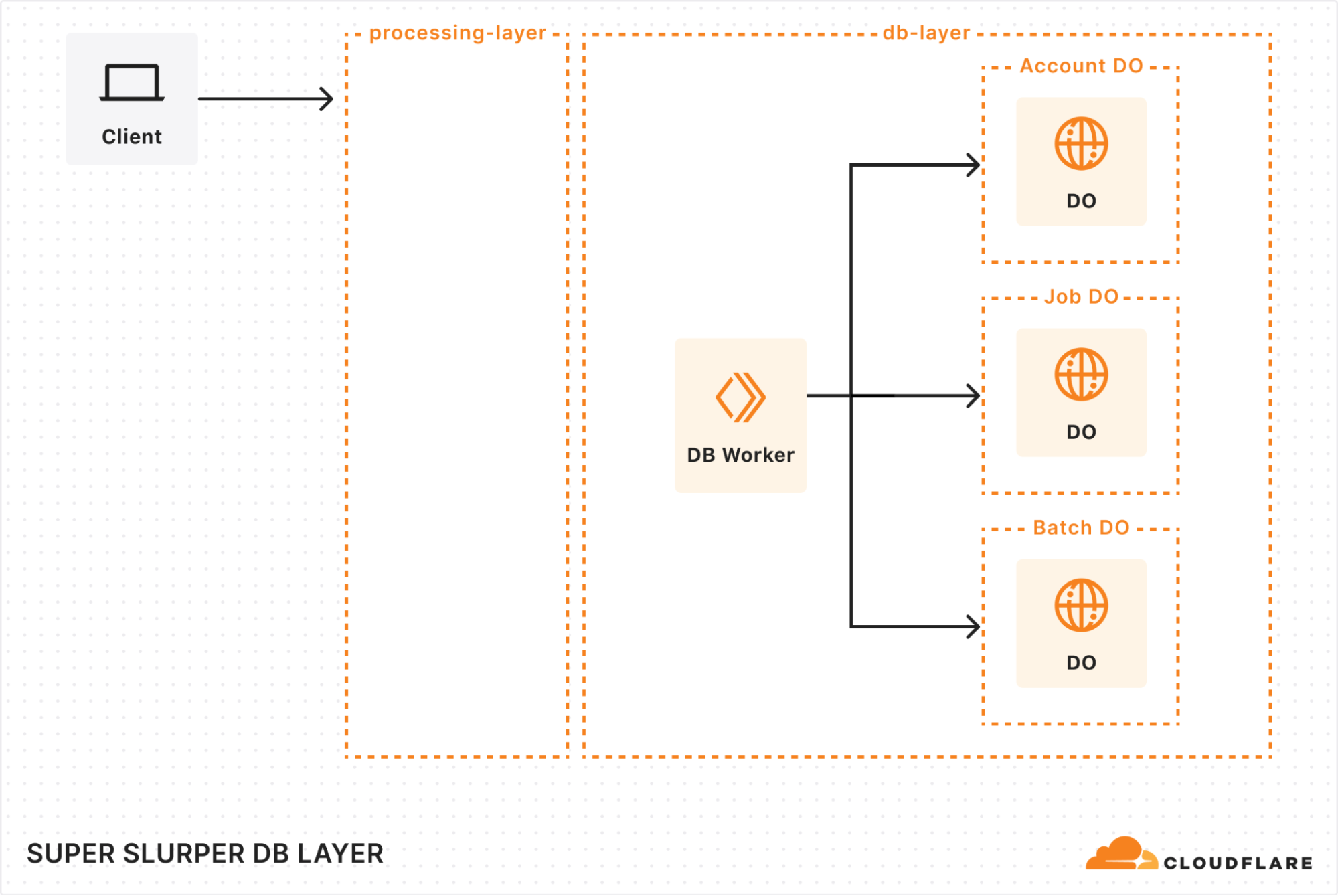
在构建新架构时,我们深知需要一个强大的解决方案,既能处理海量数据集,又能确保历史作业数据的检索。这就是我们的 Durable Objects (DO) 和 Hyperdrive 组合发挥作用的地方。
Durable Objects
我们为每个帐户分配一个专用的 Durable Object,专门跟踪迁移作业。每项作业的 DO 存储关键的详细信息,例如存储桶名称、用户选项和作业状态。这确保一切都有条不紊且易于管理。为了支持大型迁移,我们还添加了一个 Batch DO,用于管理所有排队等待传输的对象,并存储其传输状态、对象键以及任何额外的元数据。
随着迁移规模扩大到数十亿个对象,我们必须在存储方面发挥创造力。我们实施了分片策略来分散请求负载,既避免了性能瓶颈,又绕过了 SQLite DO 10 GB 的存储限制。在对象传输后,我们会清理其详细信息,从而优化存储空间。10 亿个对象键所需的存储空间非常惊人!
Hyperdrive
由于我们正在重建一个拥有多年迁移历史的系统,我们需要一种方法来保存和访问每一个历史迁移的详细信息。Hyperdrive 作为连接我们传统系统的桥梁,能够从核心 PostgreSQL 数据库无缝检索历史作业数据。这不仅仅是一种数据检索机制,更是复杂迁移场景的归档存储。
成果:Super Slurper 现将数据迁移到 R2 的速度提高多达 5 倍
那么,在完成以上所有工作之后,我们是否真正实现了加快传输速度的目标呢?
我们进行了测试,将 75000 个对象从 AWS S3 迁移到 R2。使用原始实现方案时,数据传输耗时 15 分钟 30 秒。经过性能优化后,同样的迁移过程仅耗时 3 分钟 25 秒。
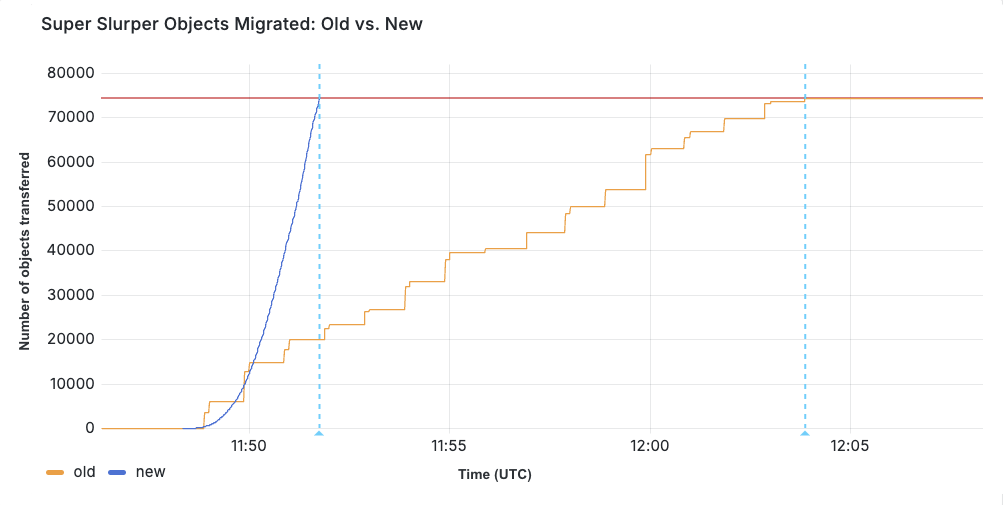
2 月份生产环境迁移正式使用新服务后,我们在某些场景下观察到更显著的性能提升,尤其是在对象大小分布不同的情况下。Super Slurper 已经投入使用 大约两年了 。然而,性能改进使其能够迁移到数据量大幅提升 —— Super Slurper 复制的所有对象中,有 35% 实在最近两个月内发生的。
挑战
使用新架构时,我们面临的最大挑战之一是处理重复消息。重复消息可能会以几种方式产生:
Queues 提供至少一次交付(At-least-once delivery)机制,这意味着为了确保传输成功,消费者可能会多次接收同一条消息。
失败和重试也可能造成明显的重复。例如,如果对 Durable Object 的请求在对象已完成传输后失败,重试可能会重复处理同一个对象。
如果处理不当,可能会导致同一对象被传输多次。为解决这一问题,我们实施了多项策略,以确保每个对象准确计数并仅传输一次:
由于列出对象是按顺序进行的(例如,要获取对象 2,您需要从列出对象 1 时获得的继续令牌),我们为每个列出操作分配了一个序列 ID。这使我们能够检测重复的列出操作,并防止多个进程同时启动。这特别有用,因为我们无需等待数据库和队列操作完成,就能列出下一批次。如果列出操作 2 失败,我们可以重试;如果列出操作 3 已经启动,我们可以跳过不必要的重试。
当每个对象传输开始时都会被锁定,从而防止同一对象的并行传输。对象成功传输后,通过从数据库中删除其键来解锁。如果针对该对象的消息后续重新出现,如果其键不再存在,则我们可以安全地假定该对象已完成传输。
我们依赖数据库事务来保持计数的准确性。如果一个对象释放失败,其计数保持不变。同样,如果对象键添加到数据库失败,则不会更新计数,并会在稍后重试该操作。
作为最后的故障保护机制,我们会检查目标存储桶中是否已存在该对象,并验证其发布时间是否晚于我们迁移的起始时间。如果是,则假定该对象是由我们(或另一个)进程传输的,并安全地跳过它。

Super Slurper 的下一步计划是什么?
我们始终在探索优化 Super Slurper 的方法,致力于提升其性能、可扩展性和易用性 ——这仅仅是个开始。
我们最近推出了从任何 S3 兼容存储提供商迁移的功能!
目前数据迁移仍被限制为每个账户最多 3 个并发迁移,但我们计划提高这一限制。这将使对象前缀能够拆分为独立的迁移任务以并行执行,显著提高存储桶的迁移速度。欲进一步了解 Super Slurper 和如何从现有对象存储迁移数据到 R2,请参阅我们的文档。
P.S.作为本次更新的一部分,我们使 API 的交互更加简单,因此现在管理迁移能够 以编程方式管理了!