



Super Slurperは、クラウドオブジェクトストレージプロバイダーとCloudflare R2間の大規模なデータ転送を簡単に行うために設計された、Cloudflareのデータ移行ツールです。ローンチ以来、何千もの開発者がSuper Slurperを使って、AWS S3、Google Cloud Storage、その他のS3互換サービスからR2へ、数ペタバイトに及ぶデータを移行してきました。
しかし、当社は移行をさらに高速化する機会を見出しました。Cloudflareの開発者プラットフォームを使い、Cloudflare Workers、Durable Objects、Queuesを土台としてSuper Slurperのアーキテクチャを一から再構築し、転送速度を最大5倍に上げました。この記事では、オリジナルのアーキテクチャ、特定されたパフォーマンスのボトルネック、その解決方法、それらの改善が実世界にもたらす影響について掘り下げます。
当初のアーキテクチャとパフォーマンスのボトルネック
Super Slurperは当初、SourcingKitとアーキテクチャを共有していました。SourcingKitは、AWS S3からCloudflare Imagesへ画像を一括インポートするために構築されたツールです。SourcingKitはKubernetes上にデプロイされ、Imagesサービスと共に稼働しました。当社はSuper Slurperの構築を始めた時に、Super Slurperを独自のKubernetesネームスペースに分割し、いくつかの新しいAPIを導入して、オブジェクトストレージのユースケースで使いやすくしました。このセットアップはうまく機能し、何千人もの開発者がR2へデータを移行するのに役に立ちました。
しかし、課題がなかったわけではありません。SourcingKitは、ペタバイト級の大容量転送に必要なスケールを処理するように設計されていませんでした。SourcingKitもSuper Slurperも、当社のコアデータセンターの1つにあるKubernetesクラスタ上で稼働していました。つまり、計算リソースと帯域幅をCloudflareのコントロールプレーン、分析、その他のサービスと共用しなければならなかったのです。こうしたリソースの制約は、移行件数が増えるにつれて明らかなボトルネックになりました。
オブジェクトストレージプロバイダー間でデータを転送するサービスの場合、ジョブはシンプルです。ソースからオブジェクトをリスト化し、宛先にコピーし、それを繰り返すだけです。これがまさに当初のSuper Slurperの仕組みです。ソースバケットからオブジェクトをリスト化し、そのリストをPostgresベースのキュー(pg_queue)へプッシュし、このキューから一定のペースでオブジェクトをコピーしていました。オブジェクトストレージ移行の規模を考えると、必然的に帯域幅の使用量が高くなる傾向にありました。そのため、スケーリングが困難でした。
当社のコアデータセンターだけでは帯域幅の制約があったため、それに対処するためにCloudflare Workersを導入しました。コアデータセンターでデータのコピーを処理するのではなく、Workerを呼び出して実際のコピーを行うようにしたのです:
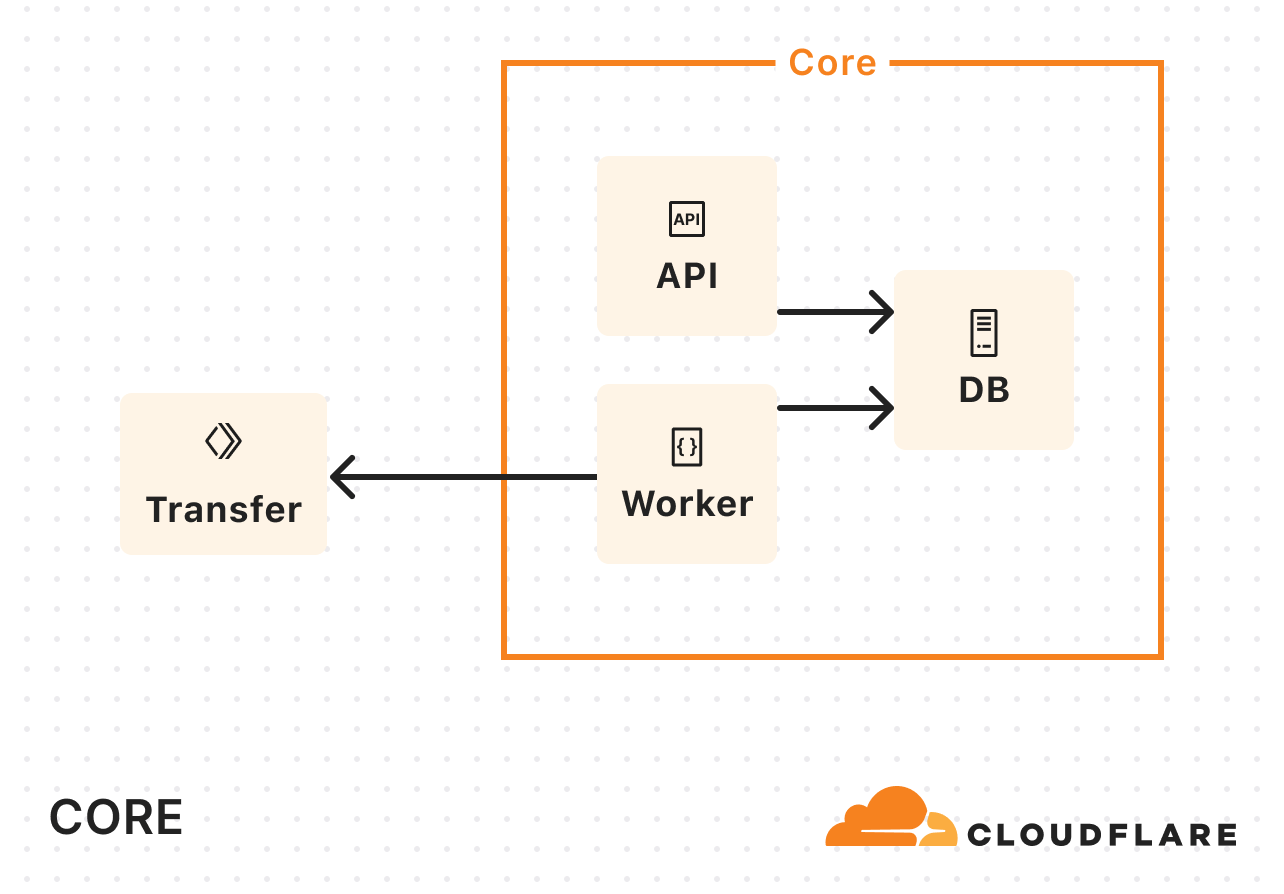
Super Slurperの利用が増えるにつれて、Kubernetesリソースの消費量も増加しました。データ転送中のかなりの時間が、計算集約型のタスクの実行にではなく、ネットワークI/Oやストレージを待つのに費やされていました。そこで必要だったのはメモリやCPUの増設ではなく、コンカレンシーを高めることだったのです。
レプリカの数を増やし続けて需要に対応しましたが、終いには壁に突き当たりました。問題はスケーラビリティでした。数十ポッドで稼働していましたが、それを数桁上回る規模が必要だったのです。
私たちは、継承したアーキテクチャに依拠するのではなく、第一原理からアプローチ全体を再考することにしました。Cloudflare Workers、Durable Objects、Queuesを使った大まかな概念実証を一週間ほどで作成しました。ソースバケットからオブジェクトをリスト化し、キューへプッシュし、キューからメッセージを消費して転送を開始しました。最初の実装の仕組みとよく似ているように聞こえますが、Cloudflareの開発者プラットフォーム上で構築したことにより、以前より数桁大きな規模の自動スケーリングが可能になりました。
Cloudflare Queues:非同期的なオブジェクト転送と、移行するオブジェクトの数に合わせた自動スケーリングが可能です。
Cloudflare Workers:Kubernetesのオーバーヘッドなしで軽量の計算タスクを実行し、プロセスの各部分の実行場所を最適化することで、遅延を短縮し、パフォーマンスを向上させます。
SQLiteベースのDurable Objects(DO):完全に分散されたデータベースとして機能し、単一のPostgreSQLインスタンスの制限を排除します。
Hyperdrive:オリジナルのPostgreSQLデータベースからジョブ履歴に高速アクセスし、アーカイブストアとして保持します。
いくつかのテストを実施した結果、小規模な転送(数百のオブジェクト)では、概念実証のスピードが当初の実装よりも遅いことがわかりました。しかし、転送が数百万オブジェクトにスケールアップすると、当初実装のパフォーマンスに匹敵するレベルに達し、最終的にはそれを上回りました。これこそ、当社が概念実証から本番環境への移行に時間を投資する必要があるというサインでした。
当社は概念実証のハックを取り除き、安定性の確保に取り組み、転送をさらに高いコンカレンシーに拡張する新しい方法を見つけました。数回のイテレーションの後に、満足のいくものにたどり着きました。
新しいアーキテクチャ: Workers、Queues、Durable Objects
処理層:移行フローの管理
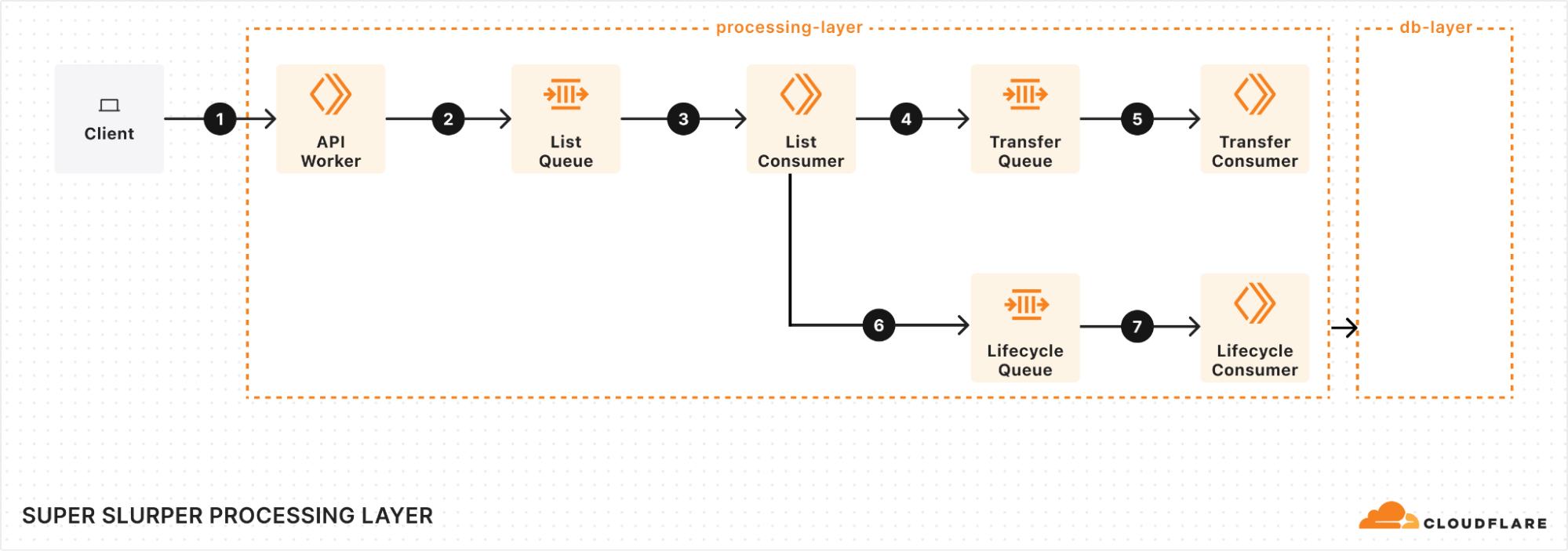
処理層の中心となるのは、キュー、コンシューマー、ワーカーです。プロセスは次のようになります:
移行を開始
クライアントが移行をトリガーする際は、当社のAPI Workerにリクエストが送信されることから始まります。このワーカーは移行の詳細を取得してデータベースに保存し、List Queueにメッセージを追加してプロセスを開始します。
ソースバケットオブジェクトのリスト
事が速く進み始めるのはList Queue Consumerにおいてです。List Queue Consumerはキューからメッセージをプルし、ソースバケットからオブジェクトリストを取得し、必要なフィルタを適用し、重要なメタデータをデータベースに保存します。次に、オブジェクト転送メッセージを Transfer Queueのキューに入れることにより、新しいタスクを作成します。
新しい作業のバッチをすぐにキューに入れ、コンカレンシー(同時実行数)を最大化します。スロットリングメカニズムが組み込まれており、依存関係するシステムがダウンするなどの予期せぬ障害が発生した時にキューにメッセージを追加できなくなっています。これにより、障害中も安定性を維持し過負荷を防ぐことができます。
効率的なオブジェクト転送
Transfer Queue Consumer Workersは、オブジェクト転送メッセージをキューからプルし、データベースのオブジェクトキーをロックすることによって、各オブジェクトが一度だけ処理されるようにします。転送が終了するとオブジェクトのロックは解除されます。大きなオブジェクトの場合は管理可能なチャンクに分割し、マルチパートアップロードとして転送します。
スムーズな障害対応
どの分散システムでも障害は避けられず、確実な対応をする必要がありました。一時的な障害が発生した場合の自動リトライを実装したため、問題によって移行の流れが妨げられることはありません。しかし、リトライで解決できない場合は、メッセージはDead Letter Queue(DLQ)に送られ、そこで後のレビューと解決のために記録されます。
ジョブ完了とライフサイクル管理
すべてのオブジェクトがリストにされ、転送が進行中になると、Lifecycle Queue Consumerはすべてを監視します。進行中の転送を監視し、オブジェクトが取り残されないようにします。すべての転送が完了すると、ジョブが完了とマークされ、移行プロセスが終了します。
データベース層:耐久性の高いストレージとレガシーデータの取得
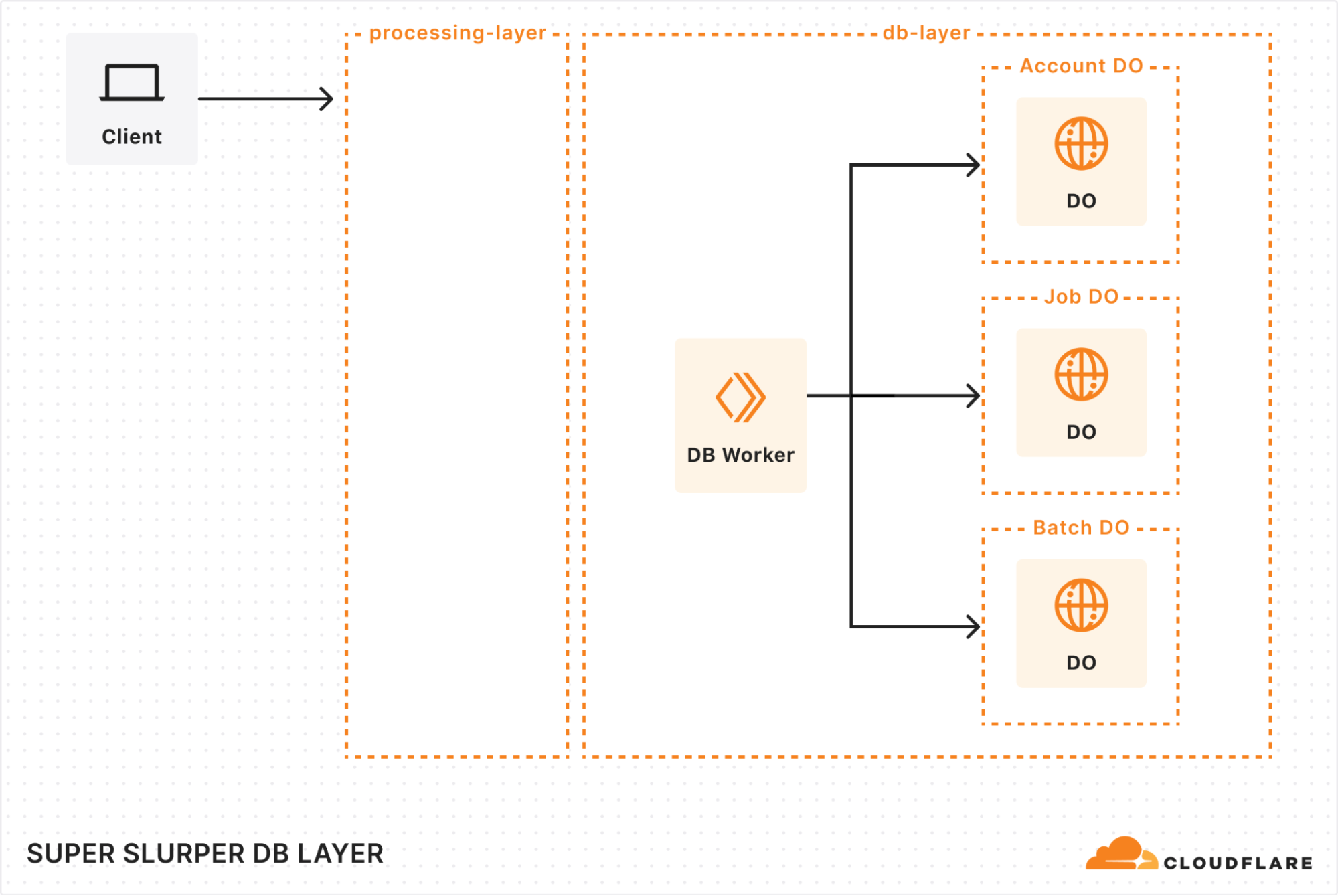
私たちは新しいアーキテクチャを構築するにあたり、膨大なデータセットを処理できてジョブ履歴の取得が可能な堅牢なソリューションが必要であることを認識していました。そこで使ったのがDurable Objects(DO)とHyperdriveの組み合わせです。
Durable Objects
移行ジョブを追跡するため、各アカウントに専用のDurable Objectを与えました。各ジョブのDOには、バケット名、ユーザーオプション、ジョブの状態などの重要な詳細が保存されます。これにより、すべてが整理され、簡単に管理できるようになりました。また、大規模な移行をサポートするために、転送のためにキューに入れられたすべてのオブジェクトを管理し、転送状態、オブジェクトキー、追加のメタデータを保存するBatch DOも追加しました。
移行が数十億ものオブジェクトにスケールアップしたため、ストレージに関してもクリエイティブになる必要がありました。リクエストの負荷を分散するシャーディング戦略を実装してボトルネックを防止し、SQLite DOの10 GBのストレージ制限を回避しました。オブジェクトが転送されると、その詳細をクリーンアップし、その過程でストレージスペースを最適化します。10億のオブジェクトキーの保存に、びっくりするほどのストレージが必要なのです。
Hyperdrive
何年もの移行履歴のあるシステムの再構築でしたので、過去の移行の詳細をすべて保存し、アクセス可能にする方法が必要でした。Hyperdriveは、レガシーシステムへのブリッジとして機能し、当社のコアPostgreSQLデータベースからジョブ履歴をシームレスに取得することを可能にします。これは単なるデータ検索メカニズムではなく、複雑な移行シナリオのためのアーカイブです。
結果:Super Slurperは最大5倍の速さでR2へデータを転送
結局、データ転送を高速化するという目標は実際に達成できたのでしょうか?
AWS S3からR2へ75,000個のオブジェクトを移行するテストを実施しました。前の実装では転送に15分30秒かかりました。パフォーマンス改善の後は、同じ移行がわずか3分25秒で完了しました。
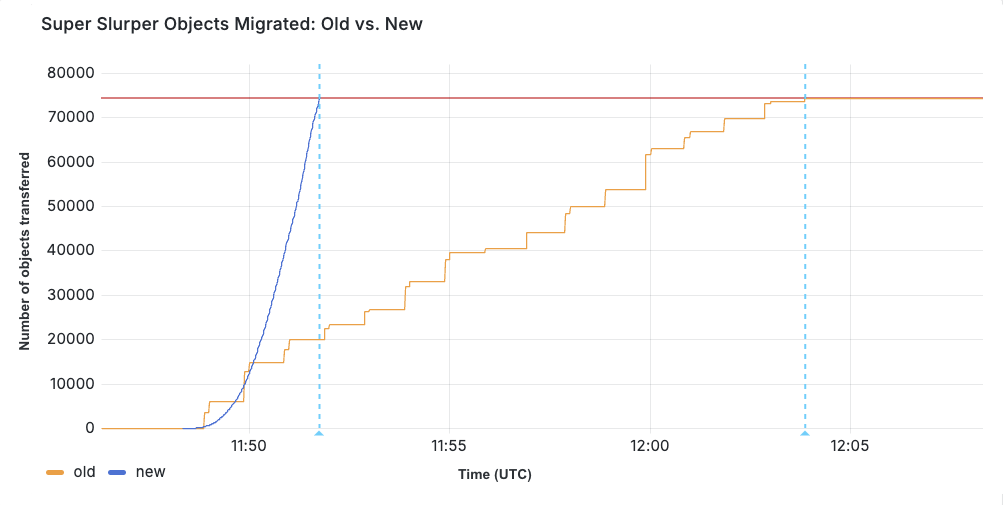
2月に新サービスを利用した本番移行がスタートした時、特にオブジェクトサイズの分布によって、さらに大きな改善が見られたケースもありました。Super Slurperは約2年前からありますが、パフォーマンスが向上し、より多くのデータを移行できるようになりました。Super Slurperがコピーした全オブジェクトの35%が、ここ2か月の移行です。
課題
新しいアーキテクチャの最大の課題の1つは、重複メッセージの処理でした。重複が発生する可能性はいくつかあります:
Queuesは少なくとも1回の配信を行います。つまり、配信を保証するために、コンシューマーは同じメッセージを複数回受信する場合があるということです。
失敗と再試行で、明らかな重複が発生する場合があります。例えば、オブジェクトが既に転送された後にDurable Objectへのリクエストが失敗した場合、リトライで同じオブジェクトが再処理される可能性があります。
正しく処理されないと、同じオブジェクトが複数回転送されることになります。これを解決するために、各オブジェクトが正確に記録され、転送が一度だけ行われるようにするいくつかの戦略を実装しました:
リストは順次処理されるため(例えば、オブジェクト2の取得にはオブジェクト1のリストからの継続トークンが必要)、各リスト化操作にシークエンスIDを割り当てています。これにより、重複するリストを検出し、複数のプロセスが同時に開始されることを防げます。データベースやキューの操作完了を待たずとも次のバッチをリスト化できるため、特に有用です。リスト2が失敗すれば再試行できます。リスト3が既に開始されている場合は、不要な再試行を省くことができます。
転送が開始されると各オブジェクトはロックされ、同じオブジェクトの並列転送を防ぎます。転送が正常に完了すると、データベースからそのオブジェクトのキーを削除することでロックが解除されます。そのオブジェクトのメッセージが後で再び表示されたとしても、キーがもはや存在しなければ、既に転送されたと考えて大丈夫です。
カウントの正確性の維持は、データベースのトランザクションに依存しています。オブジェクトがロック解除されなければ、カウントは変わりません。同様に、データベースへのオブジェクトキー追加が失敗すればカウントは更新されず、操作は後で再試行されます。
最後の安全策として、オブジェクトが既にターゲットバケットに存在し、移行開始後に公開されたことを確認します。確認できれば、当社のプロセス(または別のプロセス)によって転送されたと想定し、スキップします。

Super Slurperの今後の展開は?
私たちは、Super Slurperをより速く、よりスケーラブルにし、さらに使いやすくする方法を常に模索しています。今回の改善はほんの始まりに過ぎません。
当社は最近、どのS3互換ストレージプロバイダーからでも移行できる機能をローンチしました!
データ移行は、現在のところアカウントあたり同時移行3回に制限されていますが、この制限を引き上げたいと考えています。それにより、オブジェクトのプレフィックスを別の移行に分割して並列処理することができ、バケットの移行速度を大幅に向上させることができます。Super Slurperの詳細と既存のオブジェクトストレージからR2へのデータ移行の方法については、当社のドキュメントをご覧ください。
P.S.今回のアップデートの一環として、APIとのやり取りを簡素化したため、移行をプログラムで管理できるようになりました!