


隆重宣布 Cloudflare 数据丢失防护 (DLP) 解决方案的创新功能:一种自我改进的 AI 驱动算法,适应组织独特的流量模式以减少误报。
当敏感数据在组织内部甚至外部移动时,如何对其进行识别和保护是一项动态多变的任务,让很多客户感到困扰。通过诸如正则表达式等确定性方法检测数据经常失败,因为这些方法无法识别归类为个人可识别信息(PII)或知识产权(IP)的详细信息。这会产生高误报率,导致干扰性的警报,继而造成审查疲劳。更关键的是,这种不太理想的体验可能会使用户不再依赖我们的 DLP 产品,从而削弱整体安全态势。
内置在 Cloudflare DLP 引擎中的 AI 使我们能够与客户的历史报告并行智能地评估文档或 HTTP 请求的内容,以确定上下文相似性,从而更准确得出有关数据敏感度的结论。
本篇博客文章中,我们将探讨 DLP AI 上下文分析,使用 Workers AI 和 Vectorize 实现的过程,以及我们正在开发的未来改进。
了解误报及其对用户信心的影响
Cloudflare 的数据丢失防护(DLP)扫描各种渠道(例如 Web、云、电子邮件和 SaaS 应用)中的潜在数据泄露源,检测敏感信息。我们采用了多种检测方法,像正则表达式这样的模式匹配方法在我们的方法中发挥着关键作用。这种方法对多种类型的敏感数据都是有效的。然而,某些信息仅通过模式难以准确分类。例如,美国社会安全号码(SSN)结构为 AAA-GG-SSSS,有时会省略短划线,经常与其他类似格式的数据混淆,如美国纳税人的身份证号码、银行账号或电话号码。
自我们的 DLP 产品推出以来,我们引入了置信度阈值等新功能,以减少用户收到的误报。这种方法涉及检查围绕某个模式匹配的上下文,以评估 Cloudflare 对其准确性的信心。对于置信度阈值时,用户可以指定一个阈值(低、中或高)以表示对检测误报的容忍程度偏好。DLP 将所选阈值作为最低标准,仅显示置信度得分达到或超过指定阈值的检测结果。
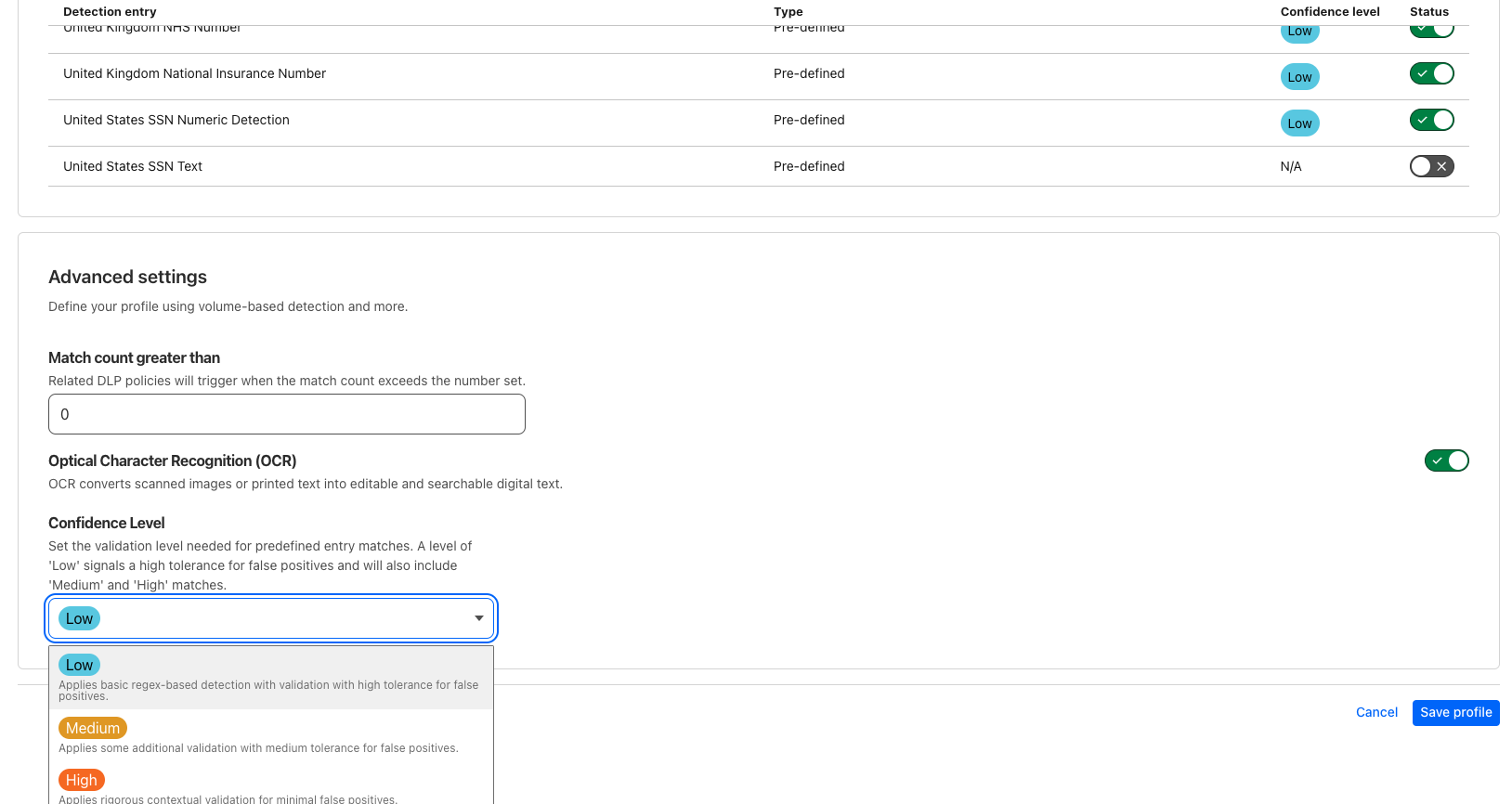
然而,实施上下文分析也并非易事。一种简单直接的方法可能涉及在匹配模式附近查找特定关键词,例如在潜在的 SSN 匹配项附近查找“SSN”,但这种方法存在局限性。关键字列表通常不完整,用户可能会出现拼写错误,而且许多有效匹配并没有靠近识别关键词(例如,银行账号靠近路由编号,或 SSN 靠近姓名)。
利用 AI/ML 提高检测准确性
为了解决针对上下文分析的硬编码策略的局限性,我们开发了一种动态、自我改进的算法,该算法通过学习客户反馈来持续优化未来的体验。每当客户通过解密有效负载日志提交误报时,系统就会降低未来类似上下文中命中的置信度。相反,报告有效匹配增加系统在类似情况下命中的置信度。
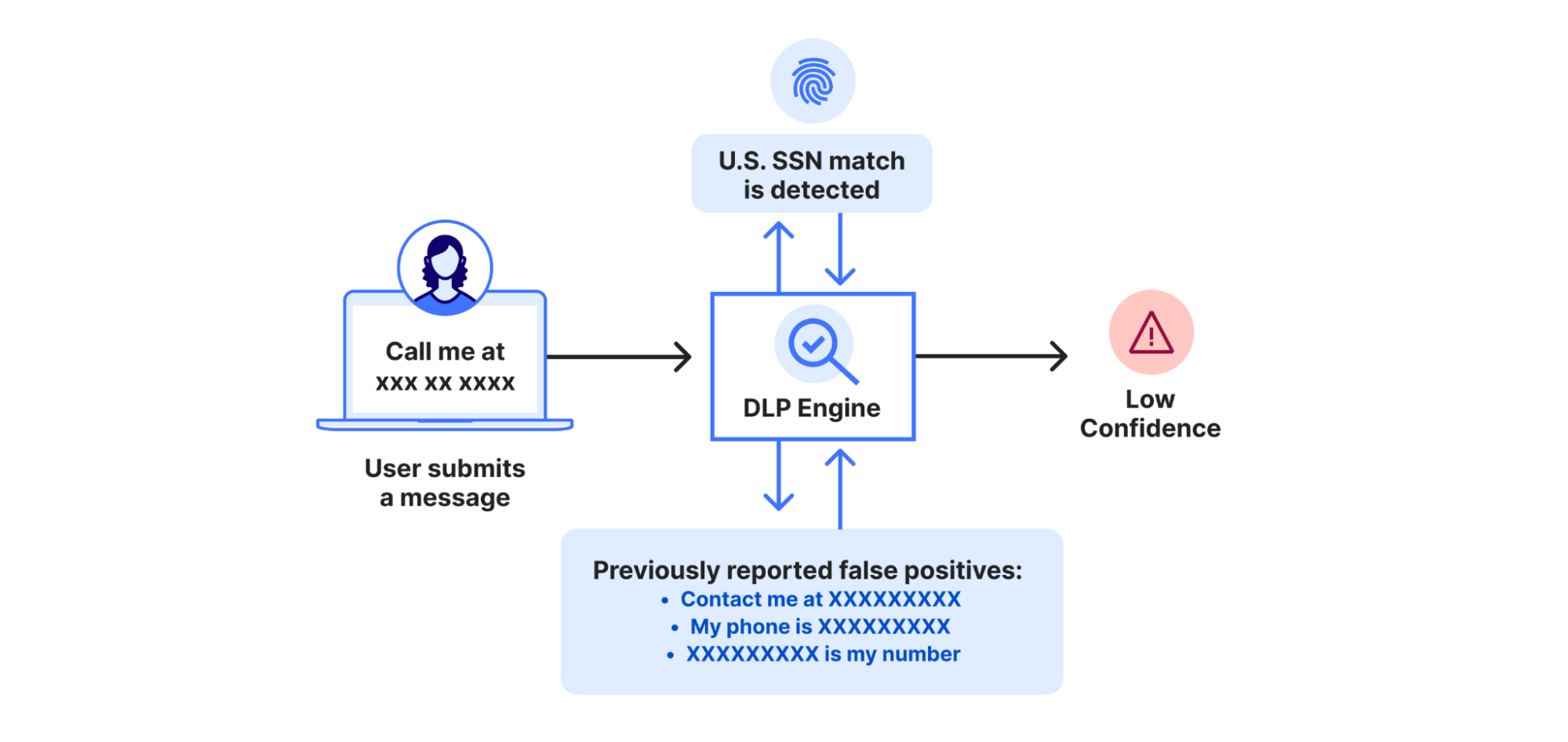
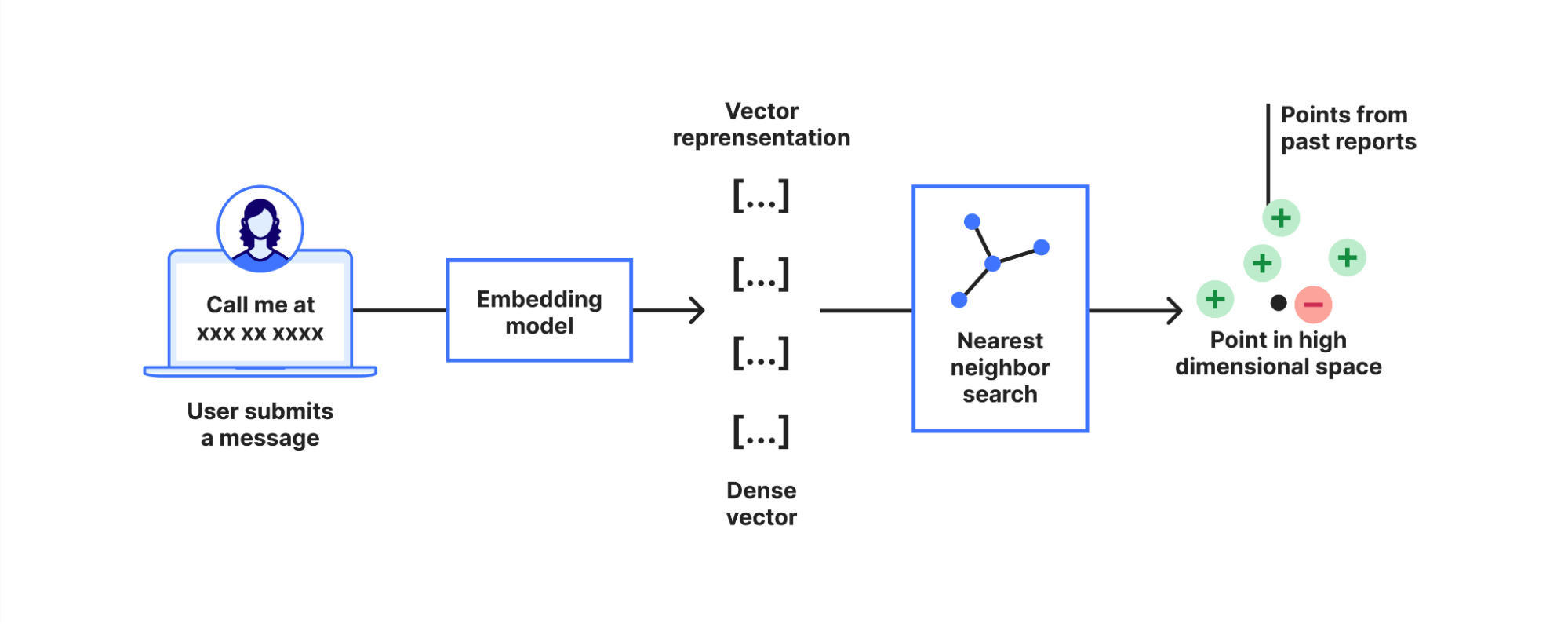
我们利用 Workers AI 来确定上下文相似性。具体而言,就是使用一个预训练语言模型将文本转换为高维向量(即文本嵌入)。这些嵌入向量捕捉文本的语义,确保语义相同但措辞不同的两个句子映射到彼此接近的向量空间。
当检测到模式匹配时,系统利用 AI 模型计算周围上下文的嵌入向量。随后,系统执行最近邻搜索,寻找具有相似语义的误报或真实匹配项历史记录。这样,即使确切措辞不同,只要语义相同,系统就能识别上下文相似性。
在使用 Cloudflare 员工流量进行的实验中,这种方法已证明稳定可靠,能有效处理此前未遇到过的新模式匹配。当 DLP 管理员通过 Cloudflare 仪表板查看某个策略匹配的有效负载日志时,报告误报和有效匹配可帮助 DLP 持续改进,从而随着时间推移显著降低误报率。
与 Workers AI 和 Vectorize 无缝集成
在开发这一新功能时,我们使用了来自 Cloudflare 开发人员平台的 Workers AI 和 Vectorize 组件,这有助于简化我们的设计。我们并非自行管理底层基础设施,而是以 Cloudflare Workers 为基础,使用Workers AI 进行文本嵌入,并使用 Vectorize 作为向量数据库。这种配置使我们能够专注于算法本身,无需处理预置底层资源的开销。
得益于 Workers AI,将文本转换为嵌入向量变得前所未有的简单。只需一行代码,我们就可以将任何文本转换为其相应的向量表示。
const result = await env.AI.run(model, {text: [text]}).data;这一方案处理从分词到 GPU 加速推理的一切工作,使得整个过程既简单又具有可扩展性。
最近邻搜索同样简单直接。从Workers AI 获取向量后,我们使用 Vectorize 从过去的报告中快速找到类似的上下文。同时,我们将当前模式匹配的向量存储在 Vectorize 中,以便我们从未来的反馈中学习。
为了优化资源利用,我们采用了一些更巧妙的技术。例如,我们不是存储每个模式匹配命中的向量,而是使用在线聚类将向量分组,并仅存储聚类中心点,同时附带用于追踪命中次数和报告的计数器。这样做减少了存储需求并加快搜索速度。此外,我们还集成了 Cloudflare Queues,将索引编制过程从 DLP 扫描热路径中分离出来,确保系统稳健、响应迅速。
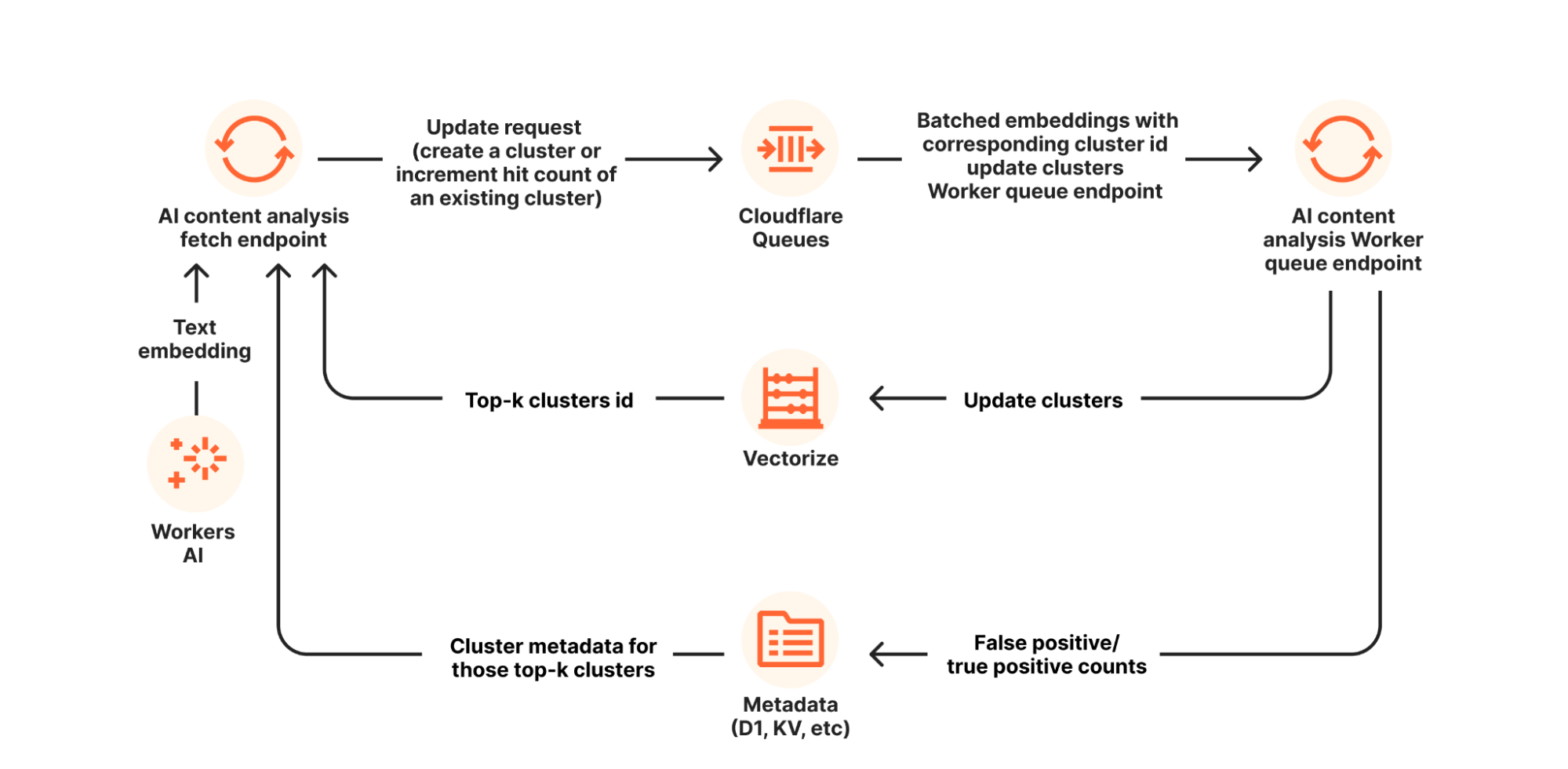
隐私保护是我们的首要任务。在转换为嵌入向量之前,我们会删除任何匹配的文本,并将所有向量和报告存储在 Vectorize、D1 和 Workers KV 特定于客户的专用命名空间中。这意味着每个客户的学习过程都是独立、安全的。此外,我们实施数据保留策略,对于 60 天内未被访问或引用的向量,系统将自动删除。
局限性与持续改进
AI 驱动的上下文分析显著提升了检测的准确性。但是,这样做的代价是给最终用户体验造成一定延迟。如果请求未匹配任何已启用的 DLP 项目,不会增加延迟。然而,如果请求与启用了 AI 上下文分析的配置文件中已启用的条目匹配,则通常会增加 400 毫秒左右的延迟。在罕见的极端情况下,例如请求匹配多个条目,延迟增加可能高达 1.5 秒。我们正在积极降低延迟,理想情况下延迟增加不到过 250 毫秒。
另一个局限性在于,由于我们选择的语言模型,当前实现仅支持英语。不过, Workers AI 正在开发一种多语言模型,将使 DLP 增加对不同地区和语言的支持。
展望未来,我们还致力于提升 AI 上下文分析的透明度。目前,用户不了解根据过去的误报和有效报告做出决定的过程。我们计划开发工具和接口,提供对置信度评分计算的更多洞察,提高系统的可解释度和用户友好度。
对于本次发布,AI 上下文分析仅可用于 Gateway HTTP 流量。到 2025 年底,AI 上下文分析将在 CASB 和 电子邮件安全 中可用,以便客户在整个数据环境中获得相同的 AI 增强功能。
释放潜能:立即启用 AI 驱动的检测功能
DLP 的 AI 上下文分析功能目前处于封测阶段。在此注册,提前体验以体验数据丢失防护 HTTP 流量匹配的即时改进。随着产品迈向正式发布,即将推出进一步更新!
如要通过 Cloudflare One 使用 DLP,请联系您的客户经理。