


Workers AI는 Cloudflare의 전역 네트워크상에서 실행되는 서버리스 GPU 기반 추론 플랫폼입니다. 이 플랫폼에서는 Workers와 함께 원활하게 실행되는 기성 모델 카탈로그를 제공하며 개발자가 몇 분이면 강력하고 확장 가능한 AI 앱을 구축할 수 있도록 지원합니다. 우리는 이미 개발자들이 Workers AI를 통해 놀라운 성과를 거두고 있는 것을 목격했으며, 우리가 플랫폼을 계속 확장해 나가는 동안 개발자들이 어떤 성과를 거둘지 기대가 됩니다. 이를 위해 오늘 가장 많은 요청을 받았던 몇 가지 새로운 기능을 발표하게 되어 기쁘게 생각합니다. 그 기능은 바로 Workers AI의 모든 대규모 언어 모델(LLM)에 대한 스트리밍 응답, 더 커진 컨텍스트 및 시퀀스 창, 고정밀Llama-2 모델 변형입니다.
ChatGPT를 사용해 본 적이 있는 분은 토큰 단위로 응답이 전송되는 응답 스트리밍의 이점에 대해 잘 알고 계실 것입니다. LLM은 반복적인 추론 프로세스를 사용하여 순차적으로 응답을 생성하는 방식으로 내부적으로 작동하며, LLM 모델의 전체 출력은 본질적으로 수백 또는 수천 개의 개별 예측 작업의 시퀀스입니다. 이러한 이유로 단일 토큰을 생성하는 데는 몇 밀리초밖에 걸리지 않지만, 전체 응답을 생성하는 데는 몇 초 정도 더 오래 걸립니다. 좋은 소식은 첫 번째 토큰이 생성되는 즉시 응답이 표시되기 시작하고 응답이 완료될 때까지 각 토큰이 추가될 수 있다는 것입니다. 따라서 최종 사용자에게는 훨씬 더 나은 경험이 제공될 수 있습니다. 텍스트가 생성되면서 점진적으로 표시되므로 즉각적인 응답성이 제공될 뿐만 아니라 최종 사용자가 텍스트를 읽고 해석할 시간을 확보할 수 있습니다.
현재, 매우 인기 있는Llama-2 모델을포함하여 당사의 카탈로그에 있는 모든 LLM 모델에 응답 스트리밍을 사용할 수 있습니다. 작동 방식은 다음과 같습니다.
서버 전송 이벤트: 브라우저 API의 보석 같은 기능
서버 전송 이벤트는 사용하기 쉽고, 서버 측에서 간단하게 구현할 수 있으며, 표준화되어 있고, 많은 플랫폼에서 기본적으로 또는 폴리필로 광범위하게 사용할 수있습니다. 서버 전송 이벤트는 서버에서 업데이트 스트림을 처리하는 틈새를 메워주므로 이벤트 스트림을 처리하는 데 필요한 상용구 코드가 필요하지 않습니다.
| 간편한 사용 | 스트리밍 | 양방향 | |
|---|---|---|---|
| 가져오기 | ✅ | ||
| 서버 전송 이벤트 | ✅ | ✅ | |
| Websockets | ✅ | ✅ |
서버에서 보낸 이벤트가 포함된 Workers AI의 텍스트 생성 모델에서 스트리밍을 사용하려면 요청 입력에서 "stream" 매개변수를 true로 설정하세요. 그러면 응답 형식과 mime 유형이 텍스트/이벤트 스트림으로 변경됩니다.
다음은 REST API로 스트리밍을 사용하는 예제입니다.
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]또한 다음은 Worker 스크립트를 사용하는 예제입니다.
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}브라우저 페이지에서 이 Worker의 출력 이벤트 스트림을 사용하려는 경우 클라이언트 측 JavaScript는 다음과 같습니다.
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}이 간단한 코드는 간단한 HTML 페이지, React를 사용하는 복잡한 SPA, 기타 웹 프레임워크에 모두 사용할 수 있습니다.
따라서 사용자에게 훨씬 더 인터랙티브한 경험이 제공됩니다. 이제 사용자는 전체 응답 시퀀스가 생성될 때까지 스피너로 기다리지 않으며, 대신 응답이 점진적으로 생성되면서 페이지가 업데이트되는 것을 볼 수 있습니다. ai.cloudflare.com에서 스트리밍을 사용해 보세요.
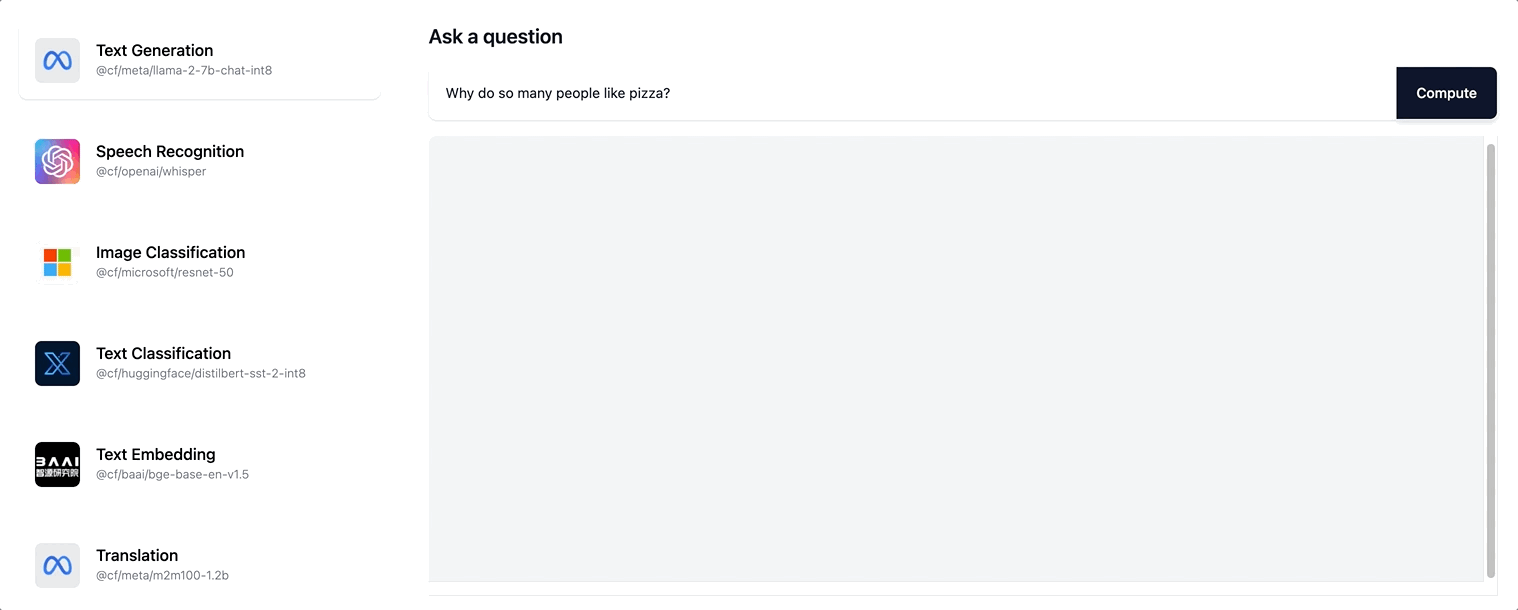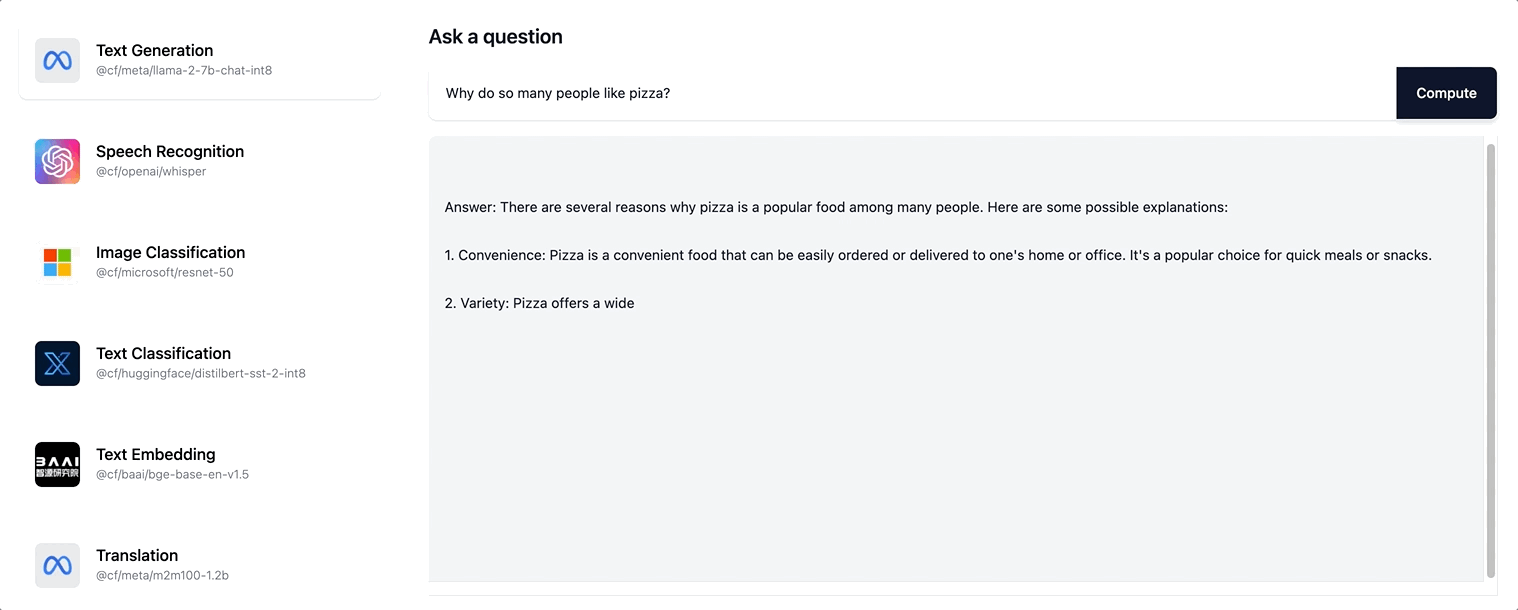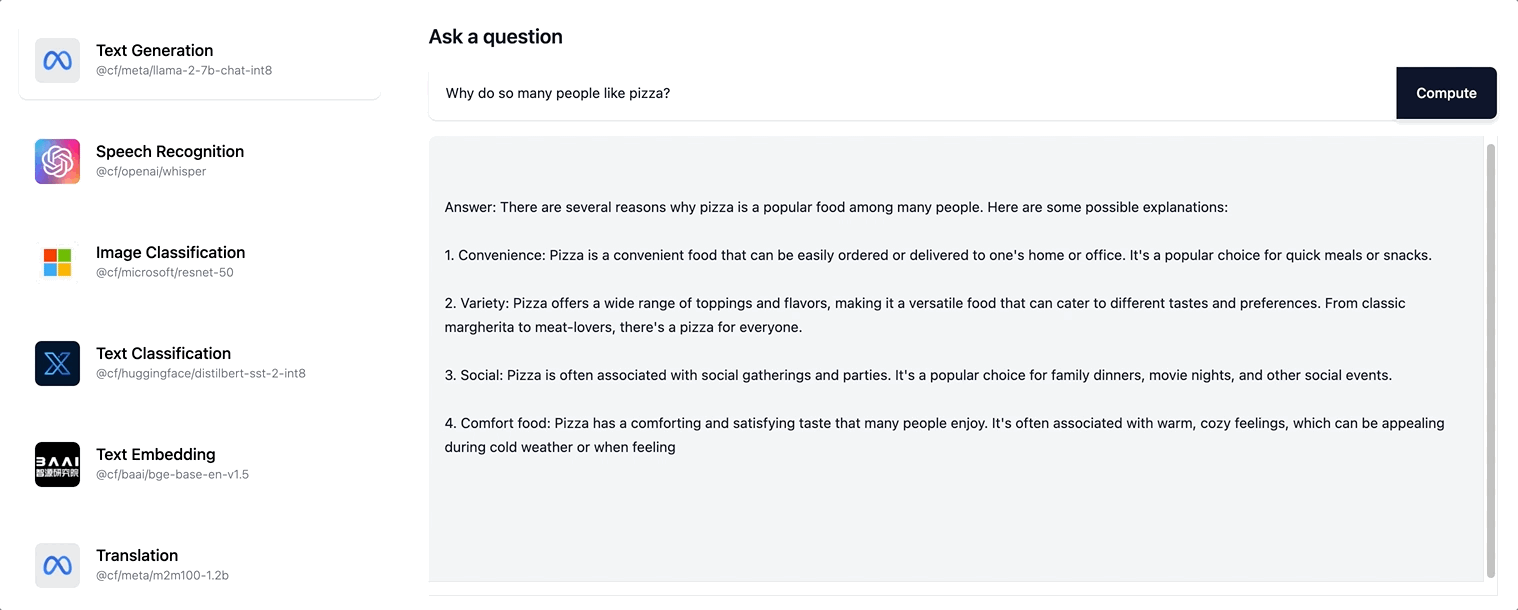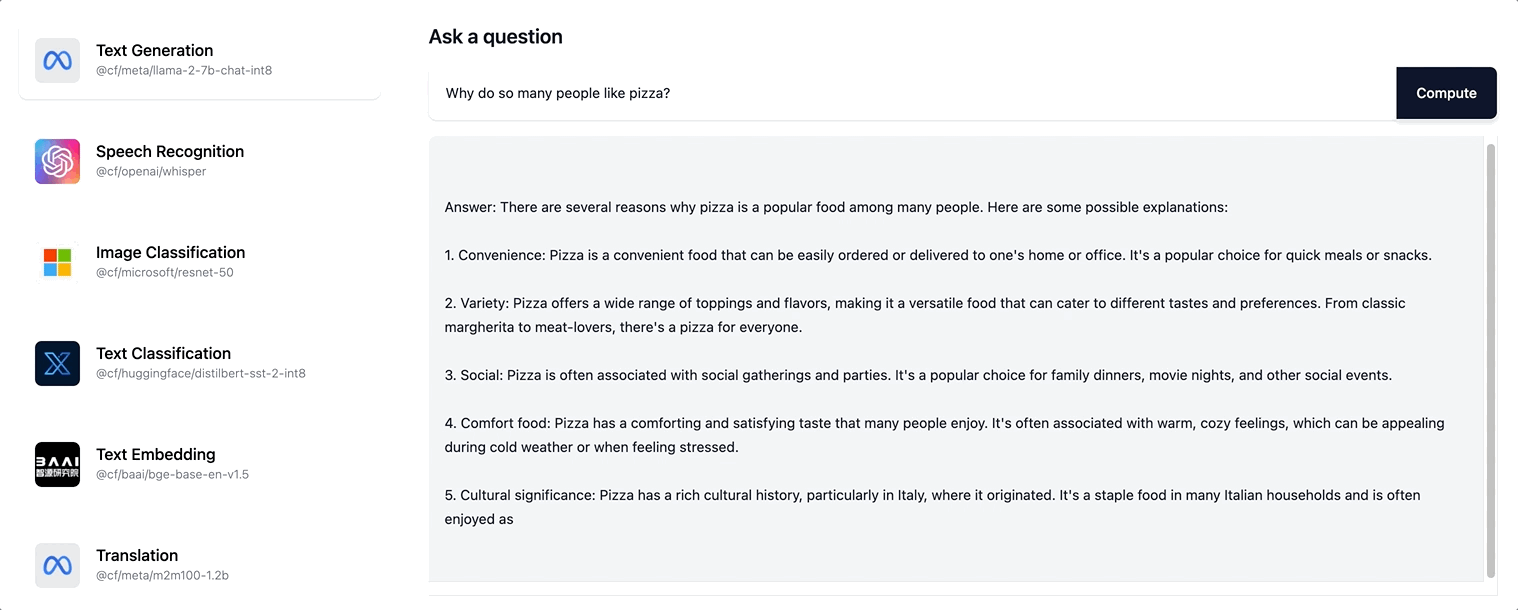
Workers AI는 Llama-2 모델과 향후 카탈로그에 추가될 모든 LLM 모델에대한 스트리밍 텍스트 응답을 지원합니다.
하지만 이것으로 끝이 아닙니다.
더 높은 정밀도, 더 긴 컨텍스트 및 시퀀스 길이
Workers AI 출시 후 커뮤니티에서 가장 많이 받은 또 다른 요청은 Llama-2 모델에서 더 긴 질문과 답변을 제공해 달라는 것이었습니다. LLM 용어로 표현하자면, 이는 컨텍스트 길이(모델에서 예측을 하기 전에 입력으로 사용하는 토큰의 개수)가 길어지고 시퀀스 길이(모델에서 응답에서 생성하는 토큰의 개수)가 길어짐을 의미합니다.
Cloudflare에서는 고객의 의견을 경청하면서, 현재 스트리밍과 함께 카탈로그에 더 높은 16비트 고정밀 Llama-2 변형을 추가하고 기존 8비트 버전의 컨텍스트 및 시퀀스 길이를 늘리고 있습니다.
| 모델 | 컨텍스트 길이(입력) | 시퀀스 길이(출력) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048(이전 768) | 1800(이전 256) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
스트리밍, 더 높은 정확도, 더 긴 컨텍스트 및 시퀀스 길이를 통해 더 나은 사용자 경험이 제공되며, Workers AI의 대규모 언어 모델을 사용하여 새롭고 풍부한 앱이 만들어질 수 있습니다.
자세한 정보와 옵션은 Workers AI 개발자 문서를 확인하세요. Workers AI에 대한 질문이나 피드백이 있는 경우 Cloudflare 커뮤니티와 Cloudflare Discord를 참조하세요.
머신 러닝과 서버리스 AI에 관심이 있으시면, Cloudflare Workers AI 팀에서 고객이 네트워크상에서 빠르고 대기 시간이 짧은 추론 작업을 실행할 수 있는 글로벌 규모의 플랫폼과 도구를 구축하고 있습니다. 채용 페이지에서 기회를 확인해 보세요.