


Workers AI es nuestra plataforma de inferencia por GPU sin servidor que se ejecuta sobre la red global de Cloudflare. Ofrece un catálogo en aumento de modelos listos para usar que se ejecutan fácilmente con Workers y permiten a los desarrolladores crear aplicaciones de IA potentes y escalables en cuestión de minutos. Ya hemos visto a desarrolladores haciendo cosas increíbles con Workers AI, y estamos impacientes por ver lo que hacen a medida que seguimos ampliando la plataforma. Con ese objetivo, hoy nos complace anunciar algunas de nuestras nuevas funciones más solicitadas: respuestas de transmisión para todos los modelos de lenguaje de gran tamaño (LLM) en Workers AI, ventanas de contexto y secuencia más amplias y una variante del modelo Llama-2 de precisión completa.
Si ya has utilizado ChatGPT, estarás familiarizado con las ventajas de la transmisión de respuesta, en la que las respuestas fluyen token a token. Los LLM funcionan internamente generando respuestas de manera secuencial mediante un proceso de inferencia repetida. El resultado completo de un modelo LLM es esencialmente una secuencia de cientos o miles de tareas de predicción individuales. Por esta razón, aunque solo se tardan unos milisegundos en generar un único token, la generación de la respuesta completa lleva más tiempo, en el orden de segundos. La buena noticia es que podemos empezar a mostrar la respuesta en cuanto se generen los primeros tokens, e ir añadiendo cada token adicional hasta completar la respuesta. Esta ventaja mejora la experiencia del usuario final, ya que la visualización progresiva del texto, conforme se va generando, no solo proporciona una capacidad de respuesta instantánea, sino que también da tiempo al usuario final para leerlo e interpretarlo.
A partir de hoy, puedes utilizar la transmisión de respuesta para cualquier modelo LLM de nuestro catálogo, incluido el famoso modelo Llama-2. A continuación, puedes ver cómo funciona.
Eventos enviados por el servidor: una pequeña joya en la API del navegador
Los eventos enviados por el servidor son fáciles de usar, sencillos de implementar en el servidor, están estandarizados y, además, están totalmente disponibles en muchas plataformas de forma nativa o como polyfill. Los eventos enviados por el servidor cubren el nicho de gestionar un flujo de actualizaciones desde el servidor, eliminando la necesidad de código reutilizable que de otro modo sería necesario para gestionar el flujo de eventos.
| Fácil de usar | Streaming | Bidireccional | |
|---|---|---|---|
| fetch | ✅ | ||
| Eventos enviados por el servidor | ✅ | ✅ | |
| Websockets | ✅ | ✅ |
Para empezar a utilizar la transmisión en los modelos de generación de texto de Workers AI con eventos enviados por el servidor, define el parámetro "stream" en "true" en la entrada de la solicitud. De este modo, se cambiará el formato de respuesta y el mime-type a text/event-stream.
A continuación, puedes ver un ejemplo de uso de la transmisión con la API de REST:
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]Fíjate en el siguiente ejemplo donde se utiliza un script Worker:
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}Si quieres consumir la salida event-stream de este Worker en una página del navegador, el JavaScript del lado cliente será algo así:
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}Puedes utilizar este código sencillo con cualquier página HTML simple, aplicaciones web de una sola página (SPA) complejas que utilicen React u otros marcos web.
De esta forma, la experiencia es mucho más interactiva para el usuario, que ahora ve cómo se actualiza la página a medida que se crea la respuesta de forma gradual, en lugar de esperar con un indicador giratorio hasta que se haya generado toda la secuencia de respuesta. Pruébalo en tiempo real en ai.cloudflare.com.
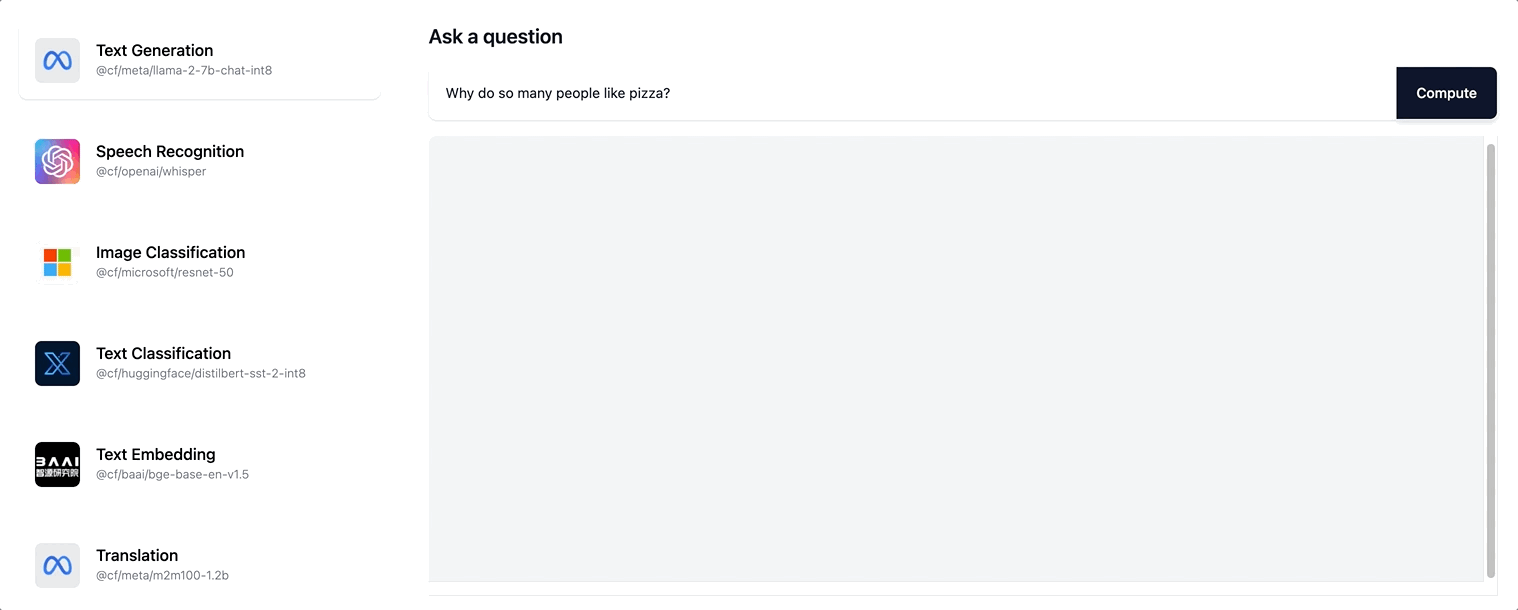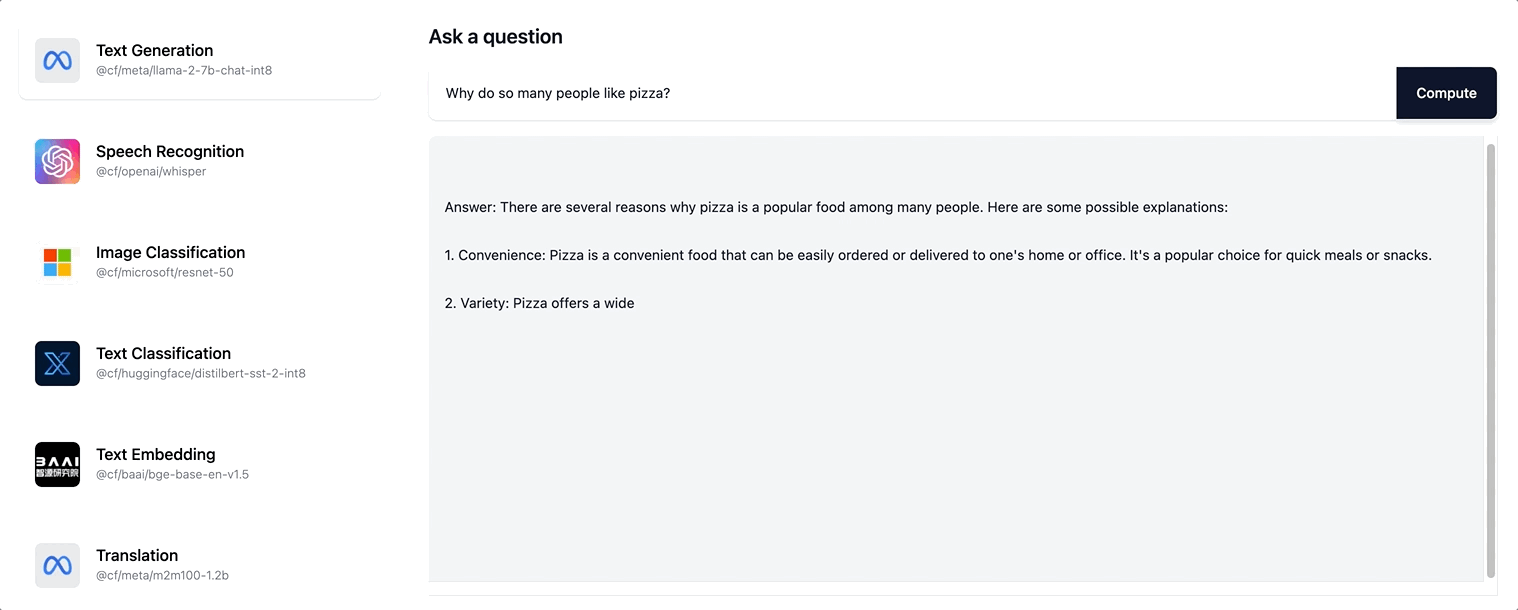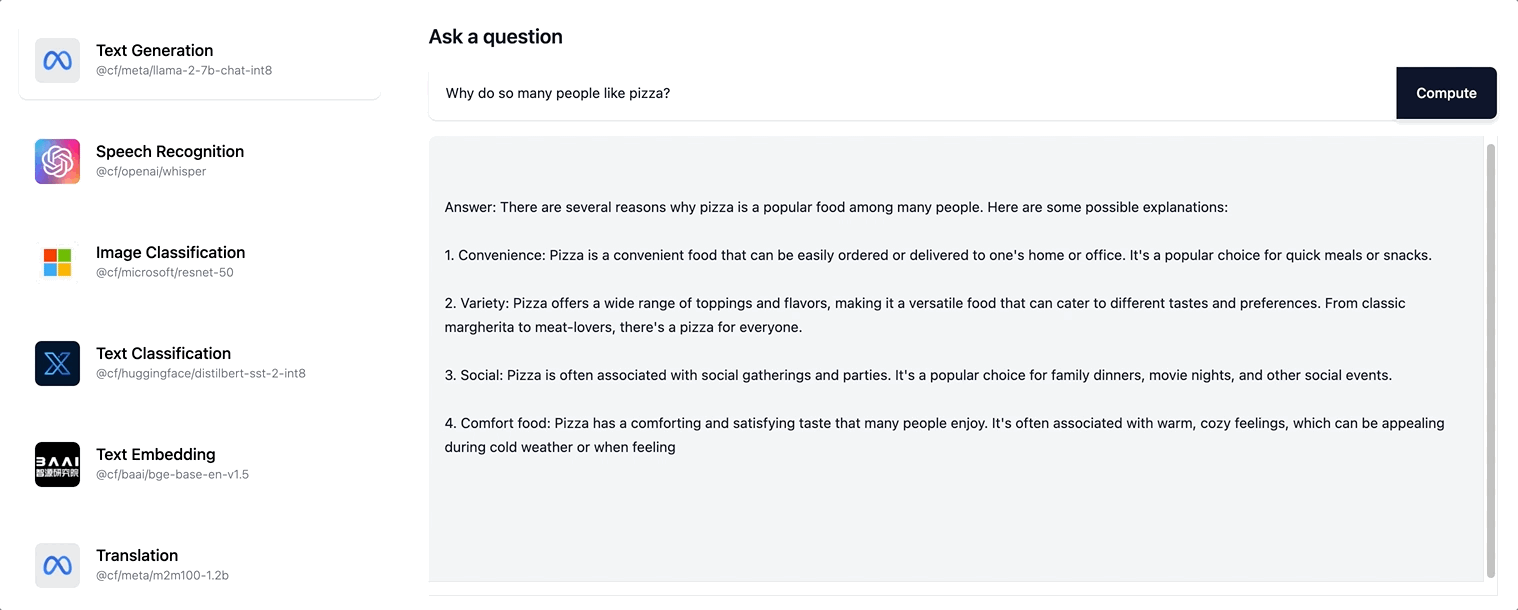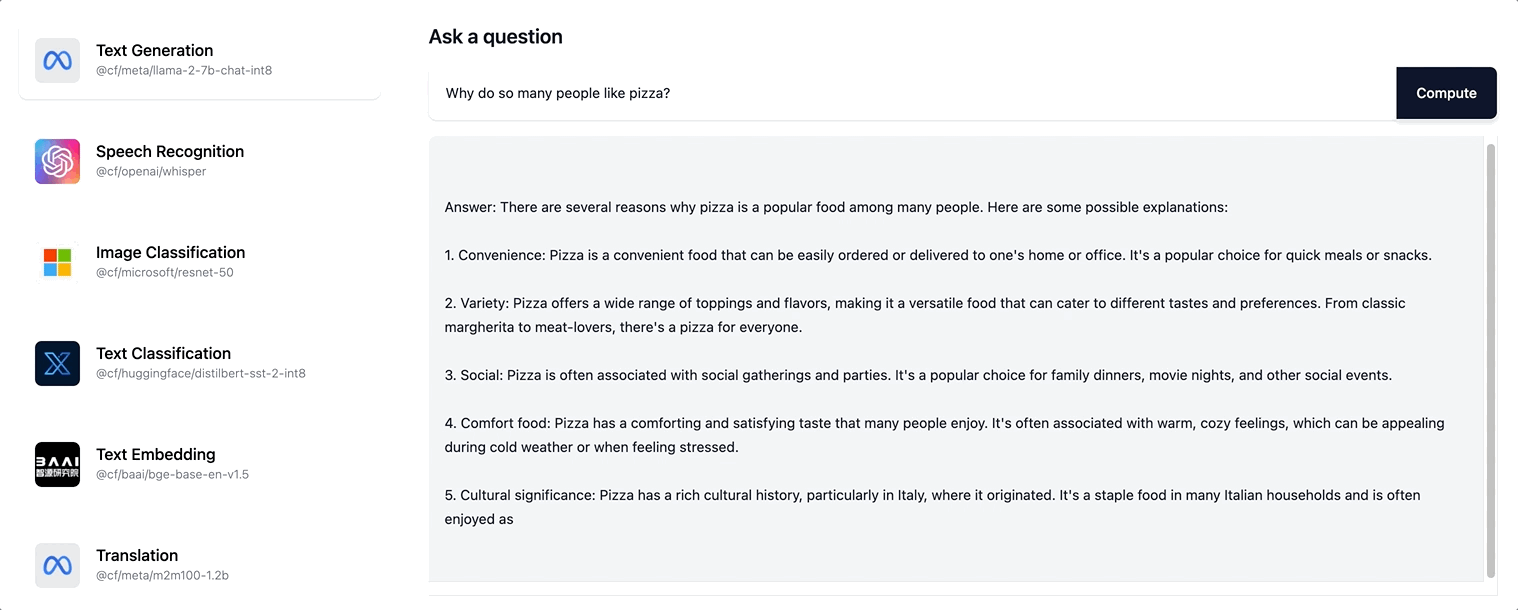
Workers AI es compatible con la transmisión de respuestas de texto para el modelo Llama-2 y cualquier modelo LLM futuro que vayamos añadiendo a nuestro catálogo.
Pero esto no es todo.
Mayor precisión, mayor contexto y longitud de secuencia
Otra de las principales peticiones que nos transmitió nuestra comunidad tras el lanzamiento de Workers AI fue la de preguntas y respuestas más largas en nuestro modelo Llama-2. En terminología LLM, esto se traduce en una mayor longitud de contexto (el número de tokens que el modelo toma como entrada antes de hacer la predicción) y una mayor longitud de secuencia (el número de tokens que el modelo genera en la respuesta).
Lo hemos tenido en cuenta, y junto con la transmisión, hoy añadimos al catálogo una variante de Llama-2 de 16 bits de precisión completa más alta, y aumentamos las longitudes de contexto y secuencia respecto a la versión existente de 8 bits.
| Modelo | Longitud de contexto (entrada) | Longitud de secuencia (salida) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048 (768 antes) | 1800 (256 antes) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
En conjunto, la transmisión, la mayor precisión y las mayores longitudes de contexto y secuencia mejoran la experiencia del usuario y permiten nuevas aplicaciones más enriquecidas con el uso de modelos de lenguaje de gran tamaño en Workers AI.
Consulta la documentación para desarrolladores de Workers AI para obtener más información y conocer las opciones. Si tienes alguna pregunta o comentario sobre Workers AI, consulta la Comunidad de Cloudflare y Discord.
Si te interesan el aprendizaje automático y la IA sin servidor, el equipo de Cloudflare Workers AI está desarrollando una plataforma y herramientas a escala global que permiten a nuestros clientes ejecutar tareas de inferencia rápidas y de baja latencia sobre nuestra red. Consulta nuestra página de empleo para ver las oportunidades.