


Unsere mittels Grafikprozessor betriebene Serverless-Inferenzplattform Workers AI setzt auf dem weltumspannenden Netzwerk von Cloudflare auf. Sie bietet eine wachsende Auswahl an direkt einsetzbaren Modellen, die sich nahtlos in Workers einfügen und es Entwicklern erlauben, binnen weniger Minuten wirkmächtige und skalierbare KI-Anwendungen zu schaffen. Mithilfe von Workers AI wurden schon großartige Dinge entwickelt und wir können es nicht erwarten, zu sehen, was mit der schrittweisen Erweiterung der Plattform in Zukunft noch alles entstehen wird. Insofern freuen wir uns besonders, heute die Einführung einiger der am häufigsten nachgefragten Funktionen in diesem Zusammenhang bekannt geben zu können: das Streamen von Antworten für alle Large Language Models (LLM) bei Workers AI, größere Kontext- und Sequenzfenster sowie eine Variante des Llama-2-Modells mit voller Präzision.
Wenn Sie ChatGPT schon einmal verwendet haben, sind Sie sich der Vorteile bewusst, die eine tokenweise Ausgabe der Antworten bietet. Intern arbeiten LLM, indem sie Antworten mittels wiederholter Inferenz nacheinander generieren: Beim dem vollständigen Output eines LLM handelt es sich im Grunde um eine Sequenz aus Hunderten oder Tausenden einzelner Vorhersagen. Obwohl es nur ein paar Millisekunden dauert, einen einzelnen Token (Bestandteil der Antwort) zu generieren, nimmt deshalb die Erstellung der gesamten Antwort mehr Zeit (und zwar ein paar Sekunden) in Anspruch. Die gute Nachricht ist, dass die Ausgabe der Antwort in dem Moment beginnen kann, in dem die ersten Token generiert werden. Anschließend werden weitere Token ergänzt, bis die Antwort vollständig ist. Für den Endnutzer ist das deutlich angenehmer: Wenn der Text nach und nach ausgegeben wird, sobald er verfügbar ist, signalisiert das sofortige Reaktionsfähigkeit. Zugleich hat der Endnutzer so Zeit, den Text zu lesen und zu interpretieren.
Künftig kann das Streamen von Antworten bei jedem von uns angebotenem LLM genutzt werden, darunter auch dem ausgesprochen beliebten Llama-2-Modell. So funktioniert’s:
„Server-Sent Events“: ein kleiner Schatz in der Browser-API
„Server-Sent Events“ sind leicht zu benutzen und serverseitig zu implementieren, standardisiert und bei vielen Plattformen nativ oder als Polyfill verfügbar. Sie decken eine Nische ab, indem sie einen Update-Stream vom Server verarbeiten und den Standard-Programmcode überflüssig machen, der sonst für die Verarbeitung des Ereignis-Streams erforderlich wäre.
| Einfache Handhabung | Streaming | Bidirektional | |
|---|---|---|---|
| fetch | ✅ | ||
| „Server-Sent Events“ | ✅ | ✅ | |
| WebSockets | ✅ | ✅ |
Um mit bei den Textgenerierungsmodellen von Workers AI mit dem Streamen mittels „Server-Sent Events“ zu beginnen, setzen Sie den Parameter „stream“ in der Eingabe der Anfrage auf „true“. Dadurch werden das Antwortformat und der MIME-Type auf text/event-stream umgestellt.
Es folgt ein Beispiel für das Streamen mit der REST-API:
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]Und hier sehen Sie ein Beispiel für die Verwendung eines Worker-Skripts:
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}Wenn der von diesem Worker ausgegebene Ereignis-Stream in einer Browserseite angezeigt werden soll, sieht der clientseitige JavaScript-Code ungefähr so aus:
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}Sie können dieses simple Programm mit jeder einfachen HTML-Seite, komplizierten SPA unter Verwendung von React oder anderen Web-Frameworks zusammen benutzen.
Auf diese Weise wird dem Nutzer eine viel größere Interaktionsfähigkeit vermittelt. Er muss nun nicht mehr warten, bis die gesamte Antwortsequenz generiert wurde. Vielmehr wird ihm eine sich stetig aktualisierende Version der Seite angezeigt, während die Antwort schrittweise erstellt wird. Unter ai.cloudflare.com können Sie das Streamen ausprobieren.
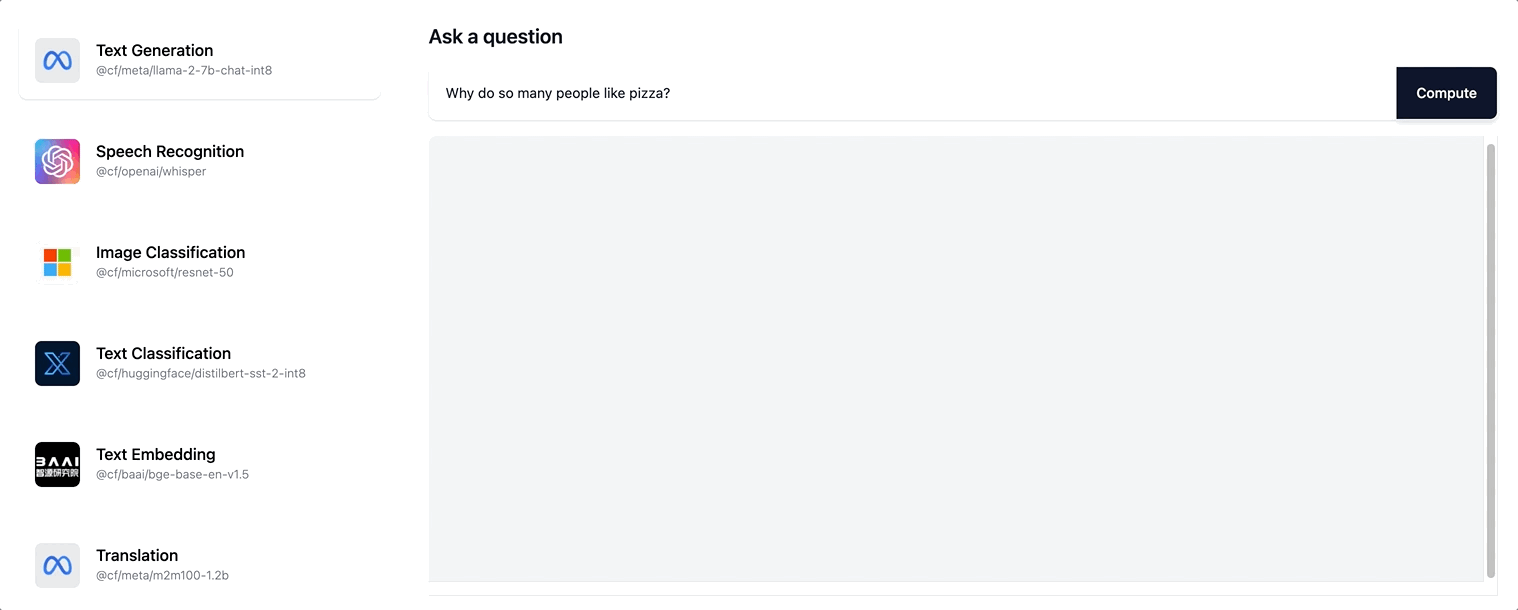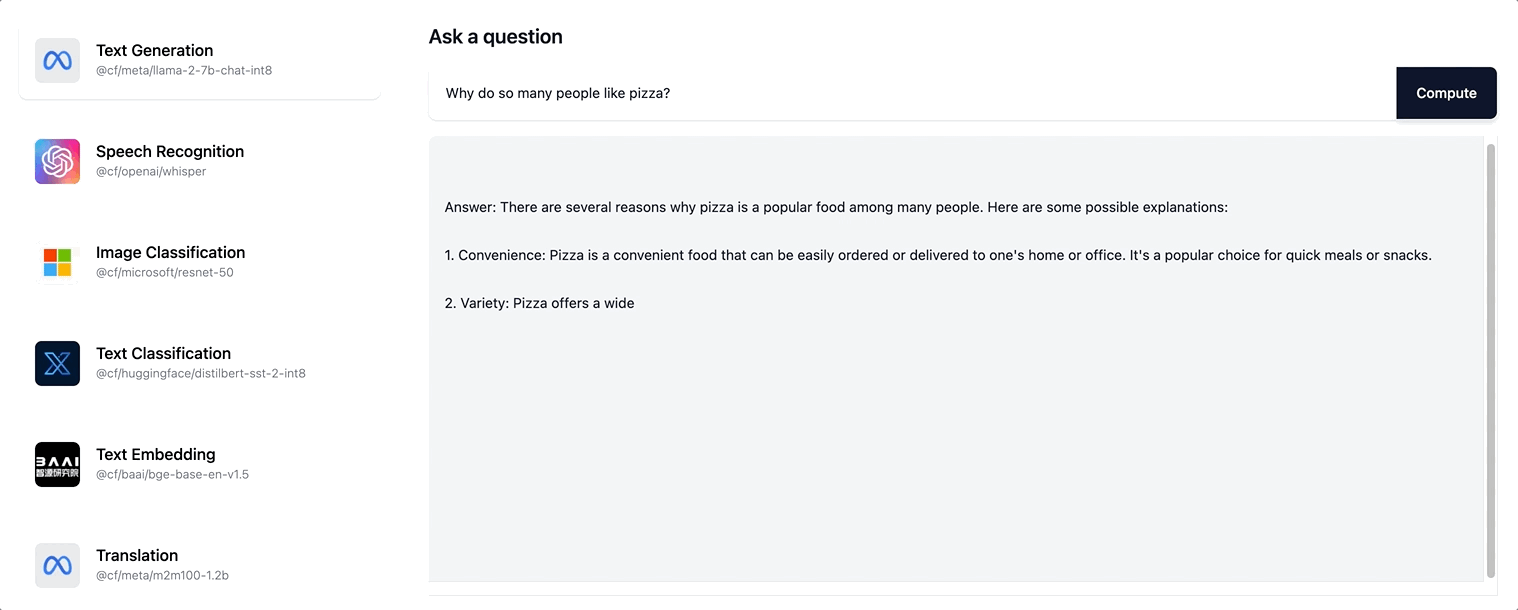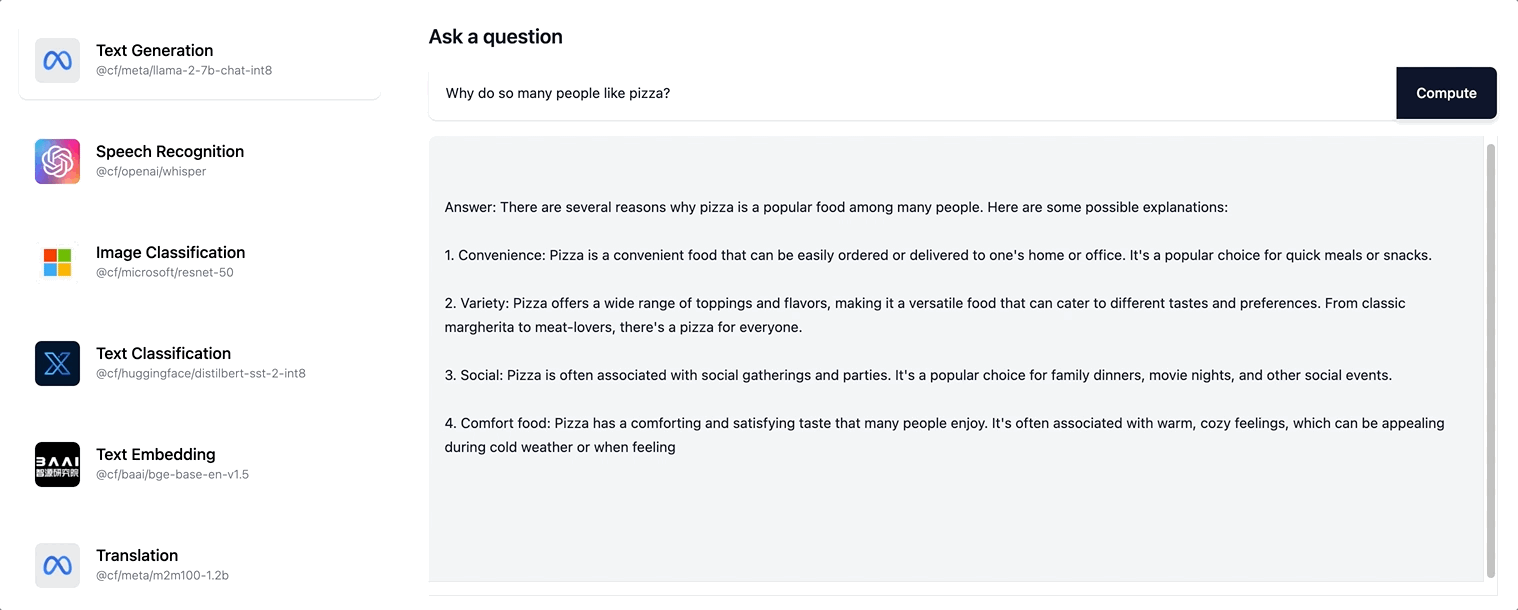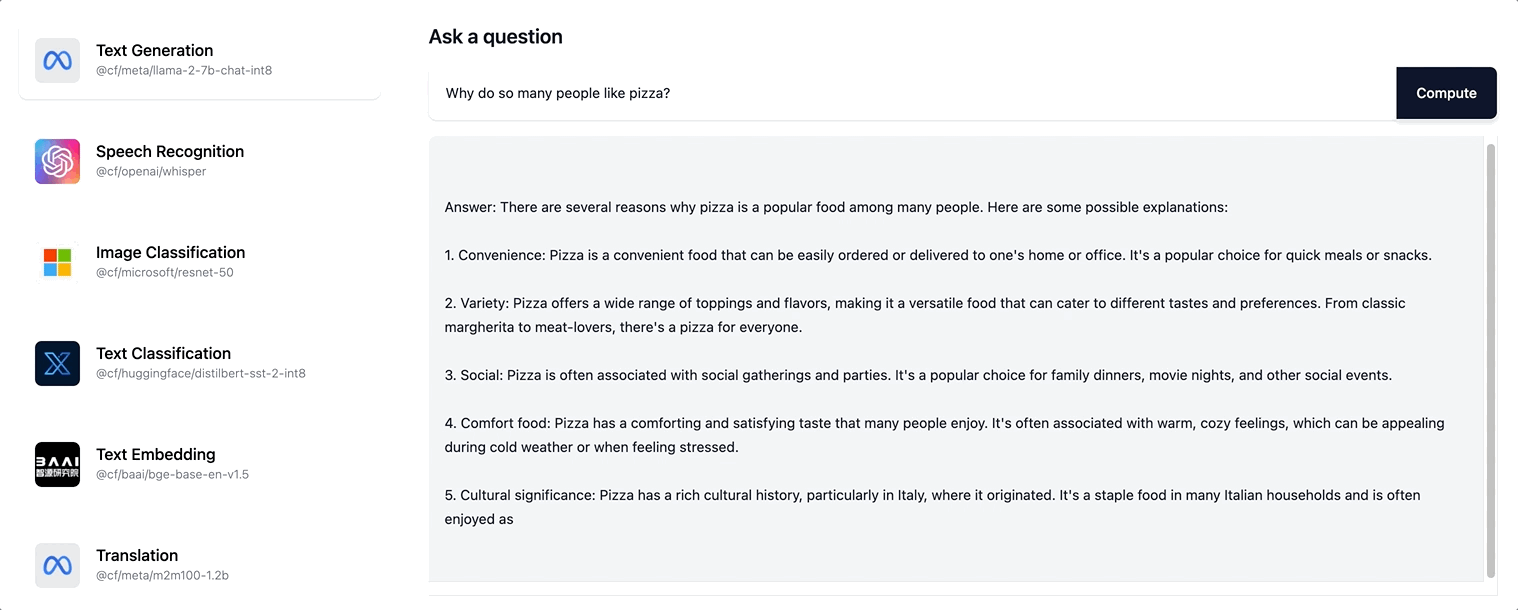
Workers AI unterstützt das Streamen von textbasierten Anworten für das Llama-2-Modell und alle LLM, die wir künftig noch in unserer Sortiment aufnehmen werden.
Das ist aber noch nicht alles.
Höhere Genauigkeit, größere Kontext- und Sequenzlänge
Nach der Einführung von Workers AI wünschte sich unsere Community außerdem besonders oft die Möglichkeit, in unserem Llama-2-Modell längere Fragen stellen und längere Antworten erhalten zu können. Bei LLM bedeutet das eine höhere Kontextlänge (die Zahl der Token, die das Modell bei der Eingabe annimmt, bevor es eine Vorhersage trifft) und eine höhere Sequenzlänge (die Zahl der Token, die das Modell als Antwort generiert).
Wir haben uns das zu Herzen genommen und führen deshalb heute nicht nur das Streamen ein, sondern ergänzen unser Angebot auch um eine 16-Bit-Variante von Llama-2 mit voller Präzision. Außerdem haben wie die Kontext- und Sequenzlänge der bestehenden 8-Bit-Version erhöht.
| Modell | Kontextlänge (Eingabe) | Sequenzlänge (Ausgabe) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048 (bisher: 768) | 1800 (bisher: 256) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
Streaming, höhere Genauigkeit sowie größere Kontext- und Sequenzlängen stellen für den Nutzer eine Verbesserung dar und erlauben neue, vielfältigere Anwendungen, die Large Language Models in Workers AI nutzen.
Weitere Informationen und Optionen finden Sie in der Entwicklerdokumentation zu Workers AI. Sie haben Fragen oder Anmerkungen zu Workers AI? Dann schauen Sie doch einfach in der Cloudflare Community und dem Cloudflare Discord-Kanal vorbei.
Wenn Sie Interesse an maschinellem Lernen und Serverless-KI haben: Das Team von Cloudflare Workers AI entwickelt eine Plattform mit globalem Maßstab und Werkzeuge, die es unseren Kunden erlauben, schnell funktionierende, latenzarme Inferenzaufgaben über unser Netzwerk auszuführen. Und vielleicht findet sich ja auf unserer Stellenseite der richtige Job für Sie.