





Bienvenue dans notre mardi consacré à l'IA de la Developer Week 2024 ! Dans cet article, nous serons heureux de partager avec vous une vue d'ensemble de nos nouvelles annonces et de notre vision en matière d'IA. Vous y retrouverez notamment l'actualité de Workers AI (qui passe officiellement en disponibilité générale, avec une tarification améliorée), mais aussi des informations sur notre dynamique de déploiement de GPU physiques, l'extension de notre partenariat avec Hugging Face, le lancement de l'inférence fine via le « Bring Your Own LoRA » (Utilisez vos propres LoRA), la prise en charge du langage Python dans Workers, l'accroissement du nombre de fournisseurs dans AI Gateway et le filtrage des métadonnées dans Vectorize.
Disponibilité générale de Workers AI
Nous nous réjouissons d'annoncer aujourd'hui la mise en disponibilité de notre plateforme d'inférence Workers AI. Après des mois de bêta ouverte, nous avons amélioré notre service en le rendant plus fiable et plus performant. Nous inaugurons également notre modèle tarifaire et avons ajouté de nombreux modèles à notre catalogue.
Performances et fiabilité améliorées
L'objectif que nous poursuivons avec Workers AI consiste à rendre l'inférence de l'IA aussi fiable et facile à utiliser que le reste du réseau de Cloudflare. Sous le capot, nous avons amélioré l'équilibrage de charge intégré à Workers AI. Les requêtes peuvent désormais être acheminées vers davantage de GPU, implantés dans davantage de villes, et chaque ville est consciente de la capacité totale disponible pour les tâches d'inférence en IA. Si la requête doit être placée en file d'attente dans la ville actuelle, elle peut être acheminée vers un autre emplacement, afin d'obtenir des résultats plus rapidement lorsque le trafic est élevé. Dans cette optique, nous avons augmenté les limites de volume pour l'ensemble de nos modèles. La plupart des LLM (Large Linguistic Models, modèles linguistiques de grande taille) disposent désormais d'une limite de 300 requêtes par minute, contre 50 requêtes par minute lors de la phase bêta. Les modèles plus petits présentent une limite de 1 500-3 000 requêtes par minute. Consultez nos documents destinés aux développeurs pour connaître les limites de volume de chaque modèle.
Réduction des coûts sur les modèles les plus populaires
Parallèlement à la mise en disponibilité générale de Workers AI, nous avons publié un outil de calcul de la tarification pour nos 10 modèles hors bêta au début du mois. Nous souhaitons que Workers AI s'impose comme l'une des solutions les plus abordables et les plus accessibles pour exécuter des tâches d'inférence. Nous avons donc ajouté quelques optimisations à nos modèles pour les rendre plus économiques. Le modèle Llama 2 est aujourd'hui plus de 7 fois (et Mistral 7B plus de 14 fois) moins cher à exécuter que ce que nous avions initialement publié le 1er mars. Nous souhaitons continuer à être la meilleure plateforme pour l'inférence de l'IA et continuerons ainsi à proposer des optimisations à nos clients lorsque nous le pourrons.
Pour rappel, la facturation du service Workers AI a commencé le 1er avril pour nos modèles hors bêta, tandis que les modèles en bêta demeurent gratuits et illimités. Nous offrons gratuitement 10 000 neurones par jour à tous nos clients. Les clients de l'offre gratuite Workers se heurteront à une limite de volume stricte après avoir utilisé 10 000 neurones en 24 heures, tandis que les clients de l'offre payante Workers se verront facturer 0,011 USD par tranche de 1 000 neurones supplémentaires. Consultez nos documents pour développeurs consacrés à la tarification de Workers AI pour les informations les plus récentes sur notre modèle tarifaire.
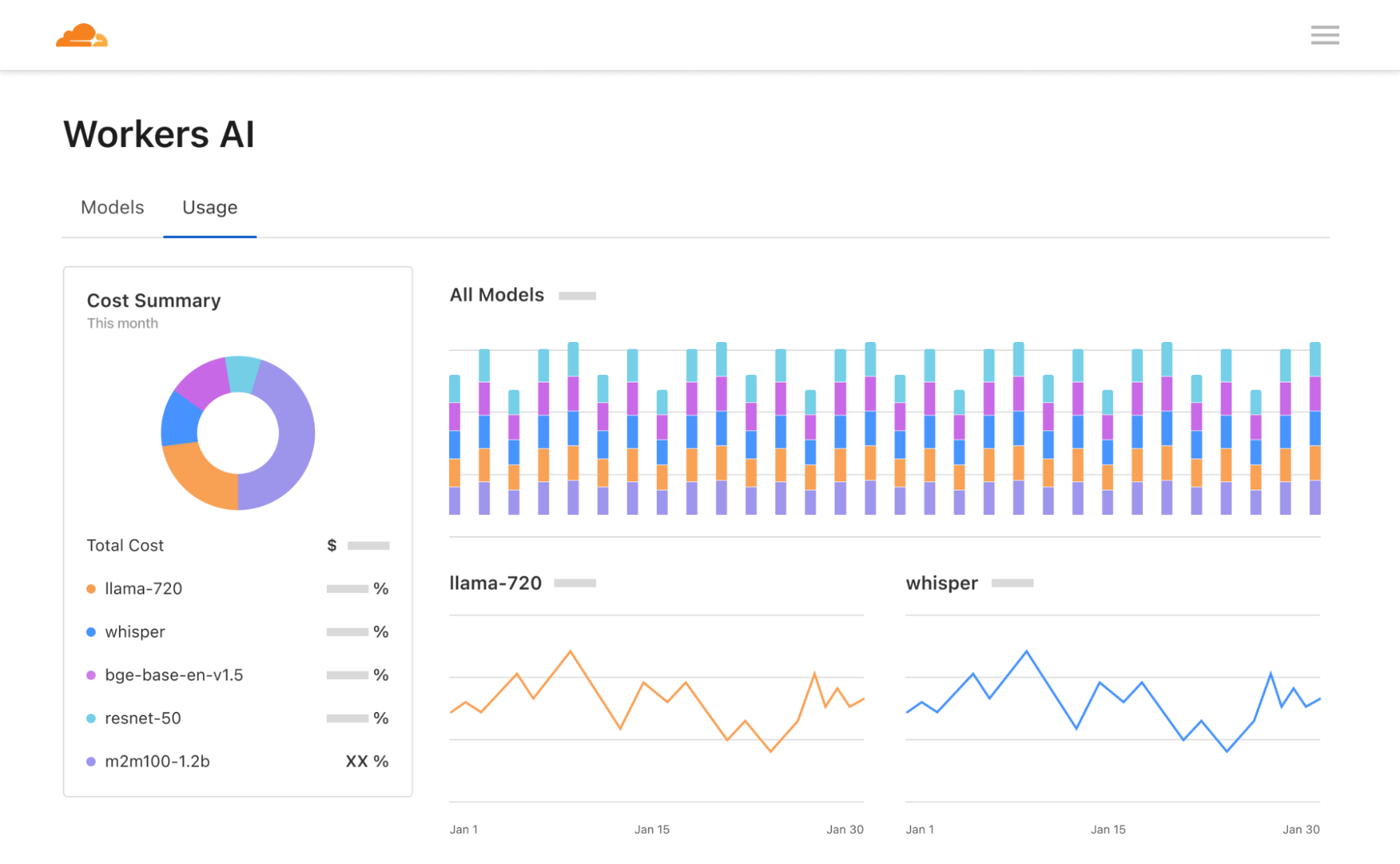
Nouveau tableau de bord et nouveau bac à sable
Enfin, nous avons repensé le tableau de bord de Workers AI et notre bac à sable pour IA. La page Workers AI du tableau de bord Cloudflare affiche désormais des analyses sur l'utilisation des modèles, notamment des calculs d'utilisation de neurones pour vous aider à mieux prévoir le prix du service. Le bac à sable pour IA vous permet de tester et de comparer rapidement différents modèles, mais aussi de configurer les invites et les paramètres. Nous espérons que ces nouveaux outils aideront les développeurs à concevoir sur Workers AI en toute fluidité. N'hésitez pas à les essayer !
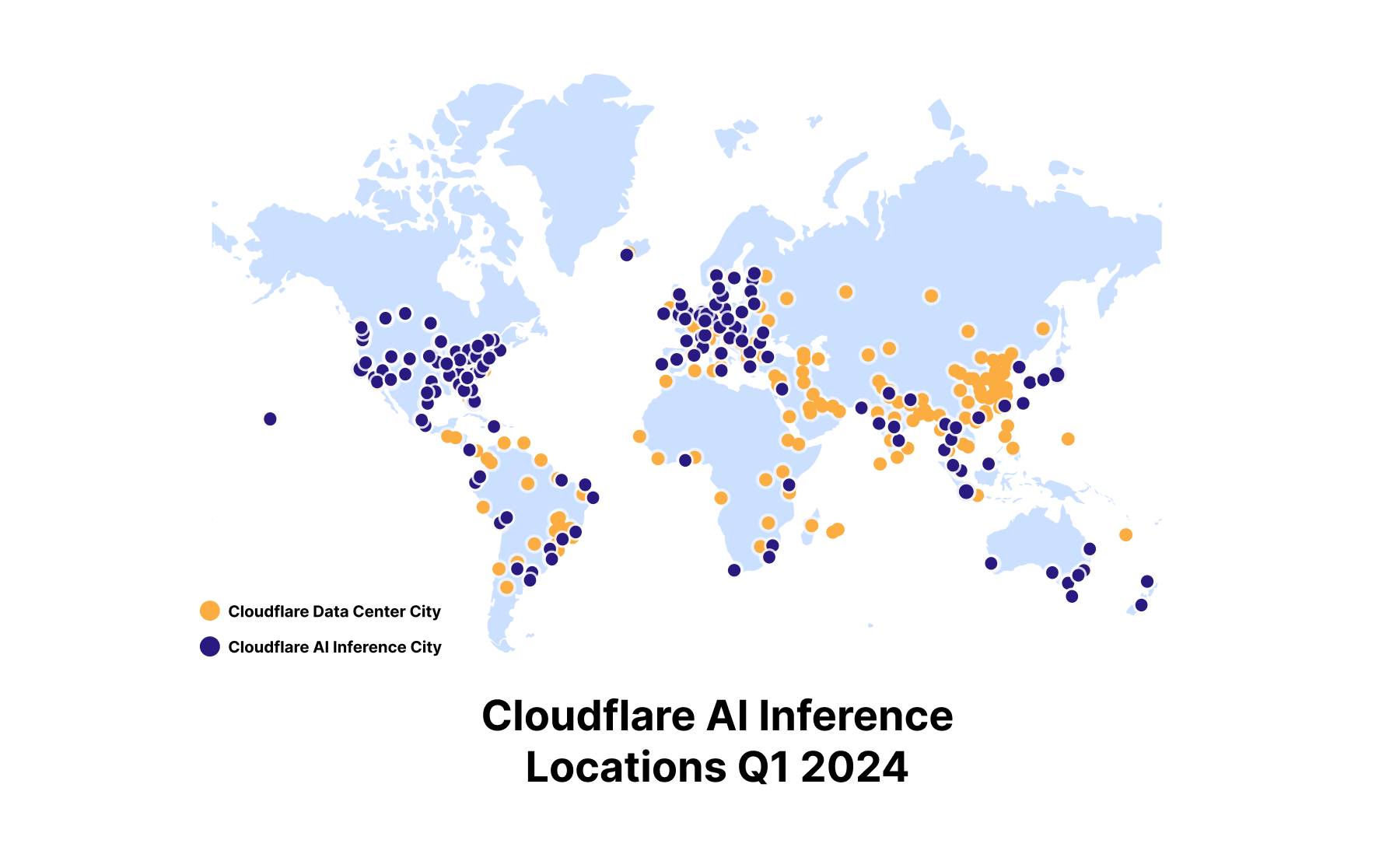
Exécutez vos tâches d'inférence sur des GPU implantés dans plus de 150 villes à travers le monde
Lorsque nous avons annoncé Workers AI en septembre 2023, nous avons entrepris de déployer des GPU dans nos datacenters à travers le monde. Nous avons l'intention de tenir cette promesse et de déployer des GPU adaptés à l'inférence pratiquement partout d'ici la fin 2024. Cette opération fera de nous la plateforme cloud dédiée à l'inférence IA la plus largement distribuée. Plus de 150 villes sont aujourd'hui équipées de GPU et nous continuerons à en déployer tout au long de l'année.
Notre prochaine génération de serveurs de calcul avec GPU sera également lancée au deuxième trimestre 2024. Cette génération assurera de meilleures performances, une meilleure efficacité énergétique et une fiabilité améliorée par rapport aux précédentes. Nous avons publié un aperçu de la conception de nos serveurs de calcul de 12e génération dans un article de blog daté de décembre 2023, avec plus de détails à venir. Pour la 12e génération et les futurs lancements d'équipements physiques prévus, la prochaine étape consistera à prendre en charge des modèles d'apprentissage automatique (Machine Learning) de plus grande taille et à proposer un réglage fin sur notre plateforme. Nous pourrons ainsi atteindre un débit d'inférence plus élevé, une latence plus faible et une plus grande disponibilité pour les charges de travail de production, tout en étendant la prise en charge à de nouvelles catégories de charges de travail, comme l'affinage.
Partenariat avec Huggingface

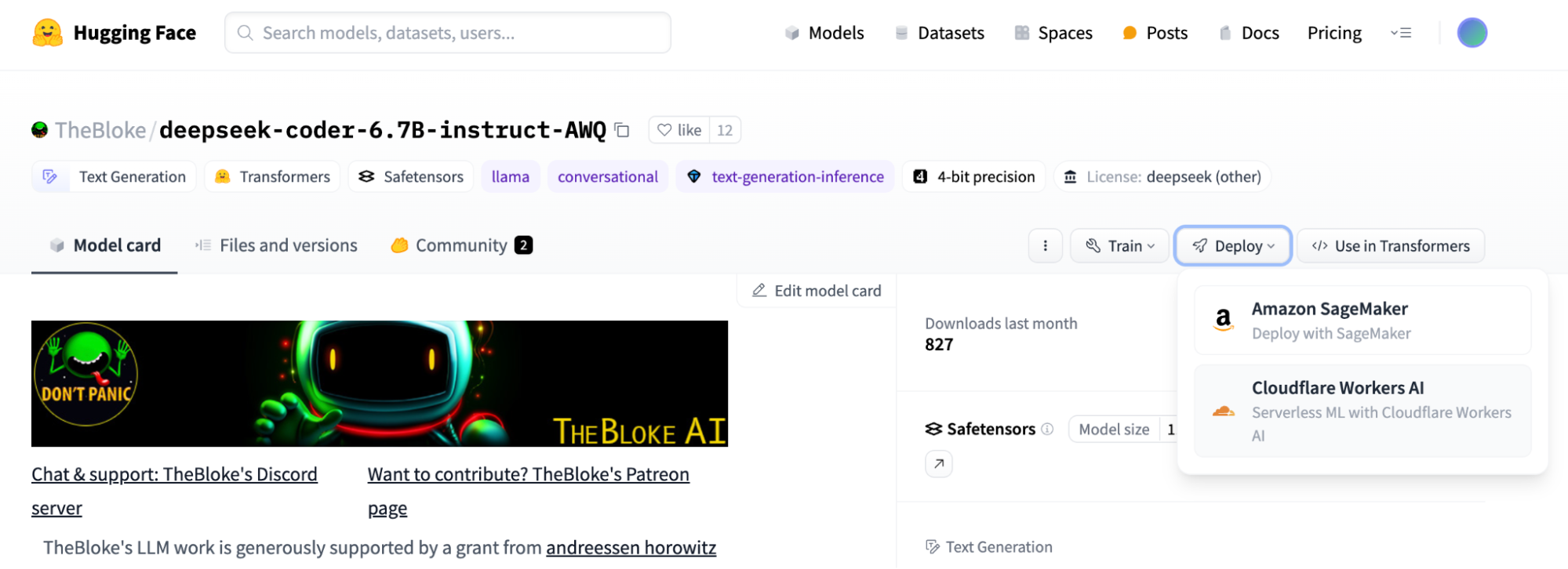
Nous nous réjouissons également de poursuivre notre partenariat avec Hugging Face, conclu dans l'esprit d'apporter le meilleur de l'open source à nos clients. Vous pouvez désormais parcourir certains des modèles les plus populaires sur Hugging Face et les exécuter facilement en un clic sur Workers AI s'ils sont disponibles sur notre plateforme.
Nous sommes heureux d'annoncer l'ajout de quatre nouveaux modèles à notre plateforme en collaboration avec Hugging Face. Vous pouvez désormais accéder au nouveau modèle Mistral 7B v0.2 doté de fenêtres contextuelles améliorées, au modèle Hermes 2 Pro de Nous Research, la version fine de Mistral 7B, au modèle Gemma 7B de Google et à Starling-LM-7B-beta, le modèle affiné d'OpenChat. Nous avons sélectionné 14 modèles avec Hugging Face à l'heure actuelle, que nous proposons pour effectuer des tâches d'inférence GPU serverless soutenues par la plateforme de Cloudflare Workers AI. D'autres seront bientôt disponibles. Ces modèles sont tous déployés à l'aide d'un back-end TGI reposant sur la technologie d'Hugging Face et nous travaillons en étroite collaboration avec l'équipe d'Hugging Face pour les sélectionner, les optimiser et les déployer.
« Nous nous réjouissons de travailler avec Cloudflare pour rendre l'IA plus accessible aux développeurs. Cette proposition alliant les modèles ouverts les plus populaires à une API serverless, soutenue par une flotte mondiale de GPU, constitue une opportunité incroyable pour les membres de la communauté Hugging Face. J'ai hâte de voir ce que ces derniers vont développer avec. »
- Julien Chaumond, cofondateur et CTO, Hugging Face
Vous retrouvez tous les modèles ouverts pris en charge par Workers AI dans la Hugging Face Collection. Le bouton « Deploy to Cloudflare Workers AI » (Déployer sur Cloudflare Workers AI) se trouve en haut de chaque carte de modèle. Pour en savoir plus, consultez l'article de blog de Hugging Face et jetez un coup d'œil à nos documents destinés aux développeurs pour commencer. Vous souhaitez voir un modèle sur Workers AI ? Envoyez-nous votre demande sur Discord.
Soutenir l'inférence fine — BYO LoRA
L'inférence fine est l'une des fonctionnalités les plus demandées sur Workers AI et nous nous en sommes rapprochés avec l'approche Bring Your Own LoRA (BYO, Utilisez vos propres LoRA). En utilisant la méthode populaire de l'adaptation de faible rang (Low-Rank Adaptation), les chercheurs ont trouvé le moyen de prendre un modèle et d'adapter certains de ses paramètres à la tâche à accomplir, plutôt que de réécrire tous les paramètres du modèle comme vous le feriez pour un modèle entièrement affiné. Il est ainsi possible d'obtenir des sorties de modèle affinées, sans les dépenses de calcul liées à l'affinage complet d'un modèle.
Nous prenons désormais en charge l'utilisation de LoRA entraînés pour la plateforme Workers AI, sur laquelle nous appliquons l'adaptateur LoRA vers un modèle de base au moment de l'exécution afin de vous permettre d'obtenir une inférence fine, pour une fraction du coût, de la taille et de la vitesse d'un modèle entièrement affiné. À l'avenir, nous souhaitons pouvoir prendre en charge les tâches d'affinage et les modèles entièrement affinés directement sur notre plateforme, mais nous sommes ravis de faire un pas de plus aujourd'hui grâce aux LoRA.
const response = await ai.run(
"@cf/mistralai/mistral-7b-instruct-v0.2-lora", //the model supporting LoRAs
{
messages: [{"role": "user", "content": "Hello world"],
raw: true, //skip applying the default chat template
lora: "00000000-0000-0000-0000-000000000", //the finetune id OR name
}
);
L'approche BYO LoRA est en bêta ouverte à partir d'aujourd'hui pour les modèles Gemma 2B et 7B, Llama 2 7B et Mistral 7B disposant d'adaptateurs LoRA d'une taille maximale de 100 Mo et d'un rang maximal de 8, jusqu'à un total de 30 LoRA par compte. Comme toujours, nous espérons que vous utiliserez Workers AI et notre nouvelle fonction BYO LoRA en gardant nos conditions d'utilisation à l'esprit, y compris les restrictions spécifiques aux modèles contenues dans les conditions de licence de ces derniers.
Pour commencer, consultez l'article technique approfondi et les documents destinés aux développeurs.
Rédiger des Workers en Python
Le langage de programmation Python est le deuxième le plus populaire au monde (après JavaScript) et le langage de prédilection pour la création d'applications d'intelligence artificielle. À partir d'aujourd'hui, dans le cadre de notre bêta ouverte, vous pouvez désormais rédiger des Cloudflare Workers en Python. Les Workers Python prennent en charge toutes les liaisons aux ressources disponibles sur Cloudflare, parmi lesquelles Vectorize, D1, KV, R2 et bien d'autres.
LangChain est le cadre de travail le plus populaire pour développer des applications soutenues par LLM, et comme Workers AI fonctionne avec langchain-js, la bibliothèque Python LangChain fonctionne également sur Python Workers, tout comme d'autres paquets Python du type FastAPI.
Les Workers rédigés en Python sont tout aussi simples à utiliser que les Workers rédigés en JavaScript :
from js import Response
async def on_fetch(request, env):
return Response.new("Hello world!")
… et sont configurés en les faisant simplement pointer vers un fichier .py dans votre wrangler.toml :
name = "hello-world-python-worker"
main = "src/entry.py"
compatibility_date = "2024-03-18"
compatibility_flags = ["python_workers"]Aucune chaîne d'outils supplémentaire ni étape de précompilation n'est nécessaire. L'environnement d'exécution Pyodide Python vous est fourni, directement par le moteur d'exécution Workers, de manière similaire à celle dont les Workers rédigés en JavaScript fonctionnent déjà.
Il reste encore beaucoup d'autres éléments dont parler. Jetez un coup d'œil à nos documents et consultez notre article de blog pour plus de détails sur le fonctionnement des Workers Python dans les coulisses.
AI Gateway prend désormais en charge Anthropic, Azure, AWS Bedrock, Google Vertex et Perplexity

Notre produit AI Gateway aide les développeurs à mieux contrôler et observer leur application IA, grâce à l'analyse, à la mise en cache, au contrôle du volume de requêtes et à bien d'autres outils. Nous continuons à ajouter de nouveaux fournisseurs au produit, dont Anthropic, Google Vertex et Perplexity, que nous sommes heureux d'annoncer aujourd'hui. Après le déploiement discret de la prise en charge d'Azure et d'Amazon Bedrock en décembre 2023, les fournisseurs les plus populaires sont désormais pris en charge par la solution AI Gateway, y compris par le service Workers AI lui-même.
Consultez nos documents destinés aux développeurs pour commencer à utiliser la solution AI Gateway.
Bientôt disponible : les journaux persistants
Au deuxième trimestre 2024, nous ajouterons les journaux persistants afin de vous permettre de transmettre vos journaux (notamment les invites et les réponses) vers des solutions de stockage d'objets. Nous ajouterons également les métadonnées personnalisées, afin que vous puissiez étiqueter les requêtes à l'aide d'identifiants utilisateur ou d'autres identifiants, ainsi que la gestion des secrets pour vous permettre de gérer en toute sécurité les clés API de votre application.
Nous souhaitons que la solution AI Gateway devienne le plan de contrôle de votre application IA, afin de permettre aux développeurs d'évaluer et d'acheminer dynamiquement les requêtes vers différents modèles et fournisseurs. Avec notre fonction de journaux persistants, nous souhaitons permettre aux développeurs d'utiliser les données qu'ils ont enregistrées pour affiner les modèles en un seul clic, en exécutant directement la tâche d'affinage et le modèle affiné lui-même sur notre plateforme Workers AI. La solution AI Gateway n'est qu'un produit de notre boîte à outils en matière d'IA, mais nous sommes ravis de constater les flux de travail et les scénarios d'utilisation qu'il peut débloquer pour les développeurs qui travaillent sur notre plateforme. Nous espérons que vous le serez également.
Filtrage des métadonnées dans Vectorize et future mise en disponibilité générale de millions d'index vectoriels
La solution Vectorize est un autre composant de notre boîte à outils pour applications IA. En bêta ouverte depuis septembre 2023, Vectorize permet aux développeurs de faire persister les incorporations (vecteurs), telles que celles générées par les modèles d'incorporation de texte de Workers AI, et de rechercher la correspondance la plus proche afin de prendre en charge divers scénarios d'utilisation, comme la recherche de similarité ou les recommandations. Sans base de données vectorielle, les résultats des modèles sont oubliés et ne peuvent être rappelés sans coûts supplémentaires de nouvelle exécution d'un modèle.
Depuis la bêta ouverte de Vectorize, nous lui avons ajouté la fonction de filtrage des métadonnées. Le filtrage des métadonnées permet aux développeurs de combiner la recherche vectorielle avec le filtrage de métadonnées arbitraires, afin de prendre en charge la complexité des requêtes au sein des applications IA. Nous comptons nous concentrer sur la préparation de Vectorize à sa mise en disponibilité générale, avec une date de lancement prévue pour juin 2024. Cette disponibilité inclura la prise en charge de plusieurs millions d'index vectoriels.
// Insert vectors with metadata
const vectors: Array<VectorizeVector> = [
{
id: "1",
values: [32.4, 74.1, 3.2],
metadata: { url: "/products/sku/13913913", streaming_platform: "netflix" }
},
{
id: "2",
values: [15.1, 19.2, 15.8],
metadata: { url: "/products/sku/10148191", streaming_platform: "hbo" }
},
...
];
let upserted = await env.YOUR_INDEX.upsert(vectors);
// Query with metadata filtering
let metadataMatches = await env.YOUR_INDEX.query(<queryVector>, { filter: { streaming_platform: "netflix" }} )
La plateforme de développement la plus complète pour concevoir des applications IA
Nous pensons que tous les développeurs devraient pouvoir utiliser la plateforme de développement de Cloudflare pour concevoir et commercialiser rapidement des applications full-stack, y compris des expériences d'intelligence artificielle. Avec la mise en disponibilité générale de Workers AI, les annonces de la prise en charge du Python dans Workers, AI Gateway et Vectorize, ainsi que notre partenariat avec Hugging Face, nous avons élargi le monde des possibles afin de vous permettre de développer des applications intégrant l'IA sur notre plateforme. Nous espérons que vous serez aussi enthousiastes que nous et vous invitons à consulter l'ensemble de nos documents destinés aux développeurs pour bien démarrer, ainsi qu'à nous informer de ce que vous développez.