



File upload is a common feature in many web applications. Applications may allow users to upload files like images of flood damage to file an insurance claim, PDFs like resumes or cover letters to apply for a job, or other documents like receipts or income statements. However, beneath the convenience lies a potential threat, since allowing unrestricted file uploads can expose the web server and your enterprise network to significant risks related to security, privacy, and compliance.
Cloudflare recently introduced WAF Content Scanning, our in-line malware file detection and prevention solution to stop malicious files from reaching the web server, offering our Enterprise WAF customers an additional line of defense against security threats.
Today, we're pleased to announce that the feature is now generally available. It will be automatically rolled out to existing WAF Content Scanning customers before the end of March 2024.
In this blog post we will share more details about the new version of the feature, what we have improved, and reveal some of the technical challenges we faced while building it. This feature is available to Enterprise WAF customers as an add-on license, contact your account team to get it.
What to expect from the new version?
The feedback from the early access version has resulted in additional improvements. The main one is expanding the maximum size of scanned files from 1 MB to 15 MB. This change required a complete redesign of the solution's architecture and implementation. Additionally, we are improving the dashboard visibility and the overall analytics experience.
Let's quickly review how malware scanning operates within our WAF.
Behind the scenes
WAF Content Scanning operates in a few stages: users activate and configure it, then the scanning engine detects which requests contain files, the files are sent to the scanner returning the scan result fields, and finally users can build custom rules with these fields. We will dig deeper into each step in this section.
Activate and configure
Customers can enable the feature via the API, or through the Settings page in the dashboard (Security → Settings) where a new section has been added for incoming traffic detection configuration and enablement. As soon as this action is taken, the enablement action gets distributed to the Cloudflare network and begins scanning incoming traffic.
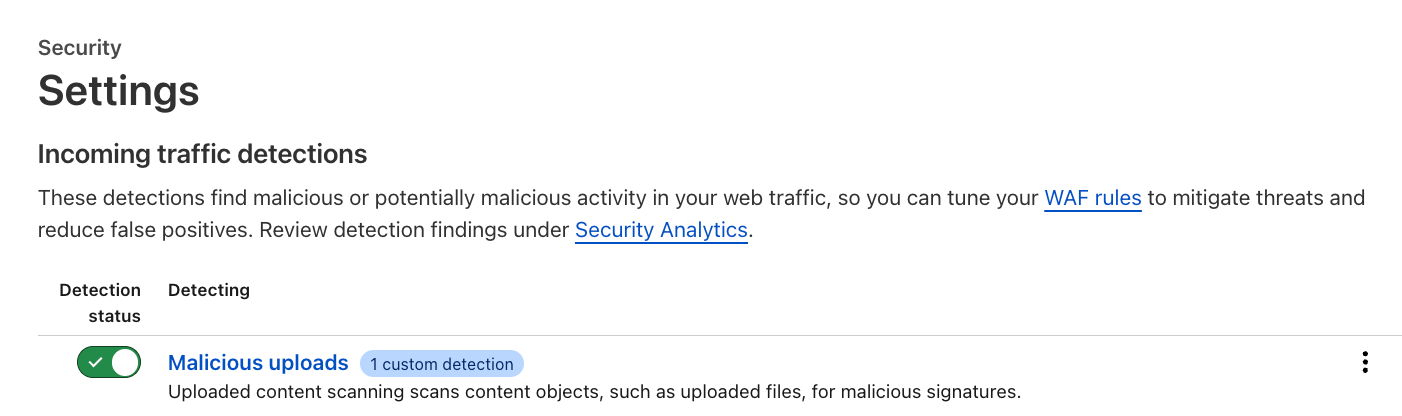
Customers can also add a custom configuration depending on the file upload method, such as a base64 encoded file in a JSON string, which allows the specified file to be parsed and scanned automatically.
In the example below, the customer wants us to look at JSON bodies for the key “file” and scan them.
This rule is written using the wirefilter syntax.
Engine runs on traffic and scans the content
As soon as the feature is activated and configured, the scanning engine runs the pre-scanning logic, and identifies content automatically via heuristics. In this case, the engine logic does not rely on the Content-Type header, as it’s easy for attackers to manipulate. When relevant content or a file has been found, the engine connects to the antivirus (AV) scanner in our Zero Trust solution to perform a thorough analysis and return the results of the scan. The engine uses the scan results to propagate useful fields that customers can use.
Integrate with WAF
For every request where a file is found, the scanning engine returns various fields, including:
cf.waf.content_scan.has_malicious_obj,
cf.waf.content_scan.obj_sizes,
cf.waf.content_scan.obj_types,
cf.waf.content_scan.obj_results
The scanning engine integrates with the WAF where customers can use those fields to create custom WAF rules to address various use cases. The basic use case is primarily blocking malicious files from reaching the web server. However, customers can construct more complex logic, such as enforcing constraints on parameters such as file sizes, file types, endpoints, or specific paths.
In-line scanning limitations and file types
One question that often comes up is about the file types we detect and scan in WAF Content Scanning. Initially, addressing this query posed a challenge since HTTP requests do not have a definition of a “file”, and scanning all incoming HTTP requests does not make sense as it adds extra processing and latency. So, we had to decide on a definition to spot HTTP requests that include files, or as we call it, “uploaded content”.
The WAF Content Scanning engine makes that decision by filtering out certain content types identified by heuristics. Any content types not included in a predefined list, such as text/html, text/x-shellscript, application/json, and text/xml, are considered uploaded content and are sent to the scanner for examination. This allows us to scan a wide range of content types and file types without affecting the performance of all requests by adding extra processing. The wide range of files we scan includes:
- Executable (e.g.,
.exe,.bat,.dll,.wasm) - Documents (e.g.,
.doc,.docx,.pdf,.ppt,.xls) - Compressed (e.g.,
.7z,.gz,.zip,.rar) - Image (e.g.,
.jpg,.png,.gif,.webp,.tif) - Video and audio files within the 15 MB file size range.
The file size scanning limit of 15 Megabytes comes from the fact that the in-line file scanning as a feature is running in real time, which offers safety to the web server and instant access to clean files, but also impacts the whole request delivery process. Therefore, it’s crucial to scan the payload without causing significant delays or interruptions; namely increased CPU time and latency.
Scaling the scanning process to 15 MB
In the early design of the product, we built a system that could handle requests with a maximum body size of 1 MB, and increasing the limit to 15 MB had to happen without adding any extra latency. As mentioned, this latency is not added to all requests, but only to the requests that have uploaded content. However, increasing the size with the same design would have increased the latency by 15x for those requests.
In this section, we discuss how we previously managed scanning files embedded in JSON request bodies within the former architecture as an example, and why it was challenging to expand the file size using the same design, then compare the same example with the changes made in the new release to overcome the extra latency in details.
Old architecture used for the Early Access release
In order for customers to use the content scanning functionality in scanning files embedded in JSON request bodies, they had to configure a rule like:
lookup_json_string(http.request.body.raw, “file”)
This means we should look in the request body but only for the “file” key, which in the image below contains a base64 encoded string for an image.
When the request hits our Front Line (FL) NGINX proxy, we buffer the request body. This will be in an in-memory buffer, or written to a temporary file if the size of the request body exceeds the NGINX configuration of client_body_buffer_size. Then, our WAF engine executes the lookup_json_string function and returns the base64 string which is the content of the file key. The base64 string gets sent via Unix Domain Sockets to our malware scanner, which does MIME type detection and returns a verdict to the file upload scanning module.
This architecture had a bottleneck that made it hard to expand on: the expensive latency fees we had to pay. The request body is first buffered in NGINX and then copied into our WAF engine, where rules are executed. The malware scanner will then receive the execution result — which, in the worst scenario, is the entire request body — over a Unix domain socket. This indicates that once NGINX buffers the request body, we send and buffer it in two other services.
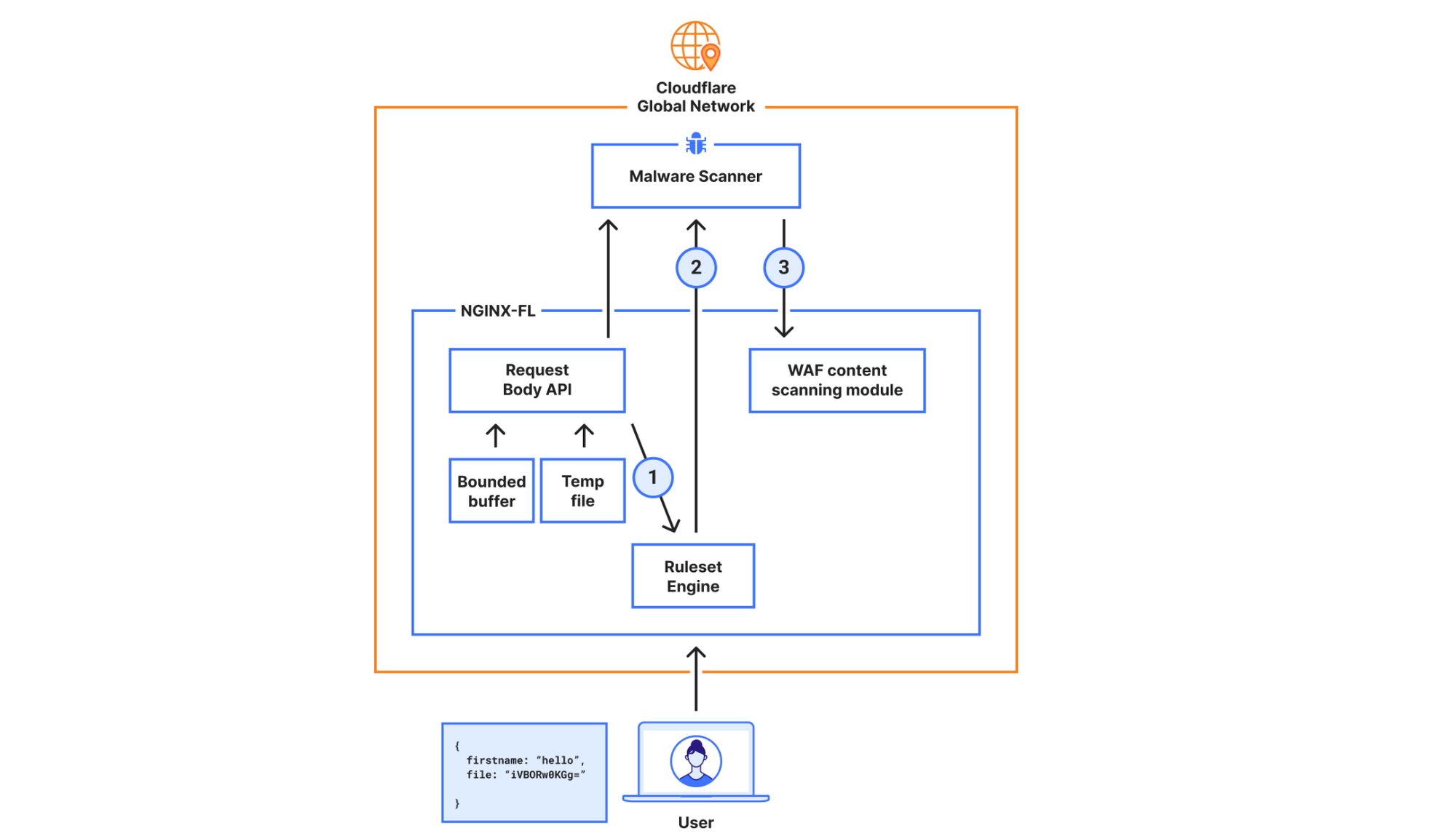
New architecture for the General Availability release
In the new design, the requirements were to scan larger files (15x larger) while not compromising on performance. To achieve this, we decided to bypass our WAF engine, which is where we introduced the most latency.
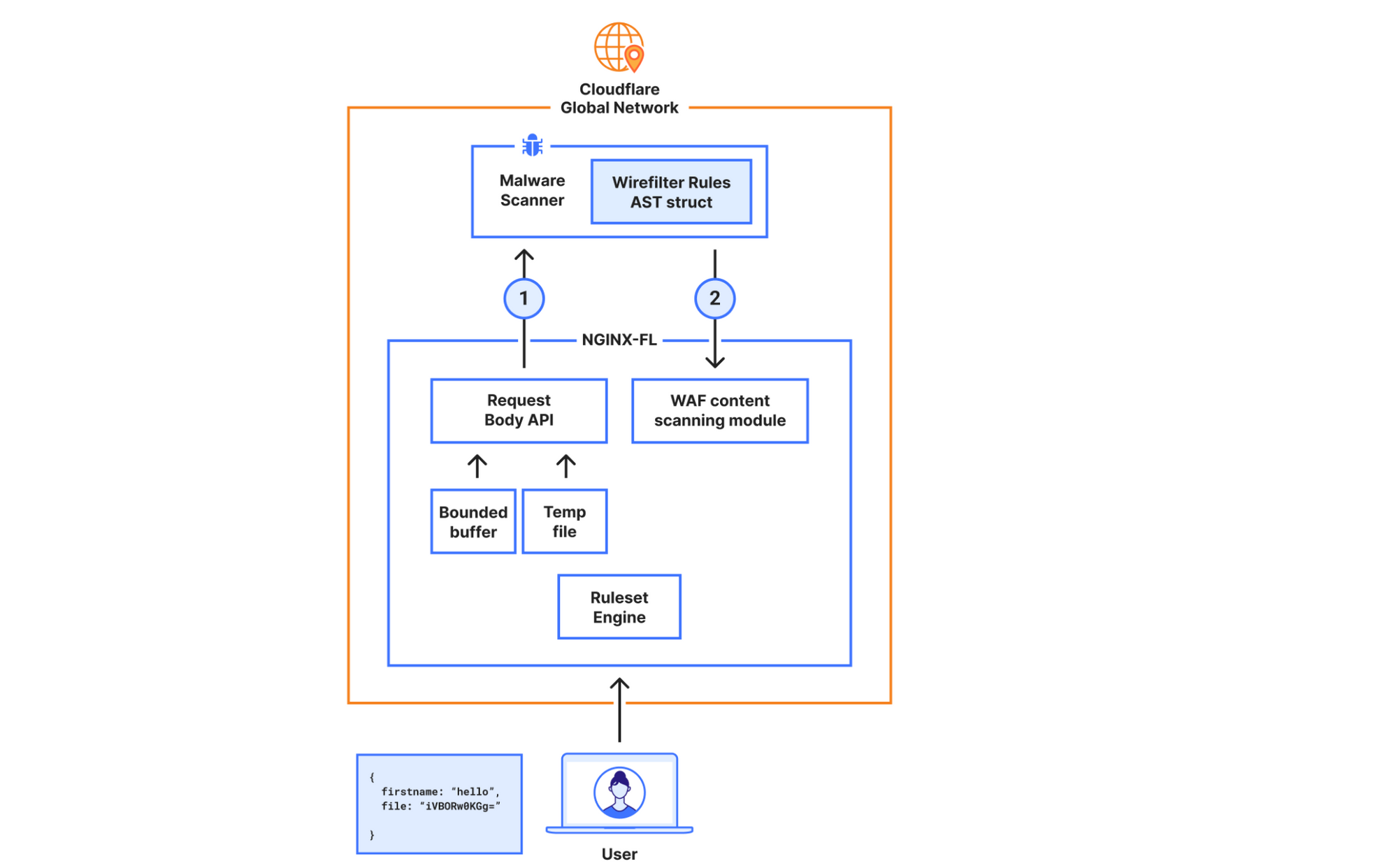
In the new architecture, we made the malware scanner aware of what is needed to execute the rule, hence bypassing the Ruleset Engine (RE). For example, the configuration “lookup_json_string(http.request.body.raw, “file”)”, will be represented roughly as:
{
Function: lookup_json_string
Args: [“file”]
}
This is achieved by walking the Abstract Syntax Tree (AST) when the rule is configured, and deploying the sample struct above to our global network. The struct’s values will be read by the malware scanner, and rule execution and malware detection will happen within the same service. This means we don’t need to read the request body, execute the rule in the Ruleset Engine (RE) module, and then send the results over to the malware scanner.
The malware scanner will now read the request body from the temporary file directly, perform the rule execution, and return the verdict to the file upload scanning module.
The file upload scanning module populates these fields, so they can be used to write custom rules and take actions. For example:
all(cf.waf.content_scan.obj_results[*] == "clean")
This module also enriches our logging pipelines with these fields, which can then be read in Log Push, Edge Log Delivery, Security Analytics, and Firewall Events in the dashboard. For example, this is the security log in the Cloudflare dashboard (Security → Analytics) for a web request that triggered WAF Content Scanning:
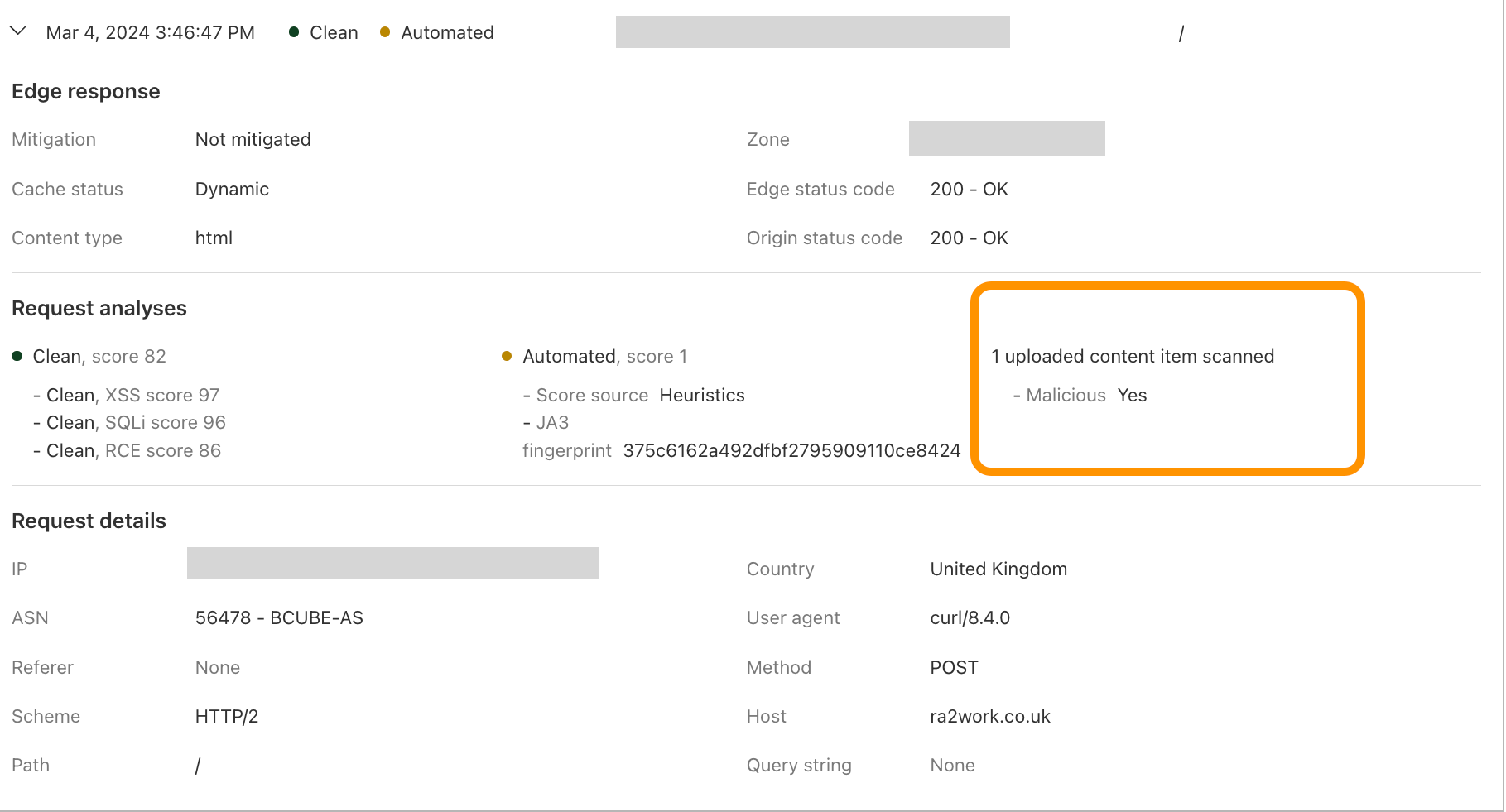
WAF content scanning detection visibility
Using the concept of incoming traffic detection, WAF Content Scanning enables users to identify hidden risks through their traffic signals in the analytics before blocking or mitigating matching requests. This reduces false positives and permits security teams to make decisions based on well-informed data. Actually, this isn't the only instance in which we apply this idea, as we also do it for a number of other products, like WAF Attack Score and Bot Management.
We have integrated helpful information into our security products, like Security Analytics, to provide this data visibility. The Content Scanning tab, located on the right sidebar, displays traffic patterns even if there were no WAF rules in place. The same data is also reflected in the sampled requests, and you can create new rules from the same view.
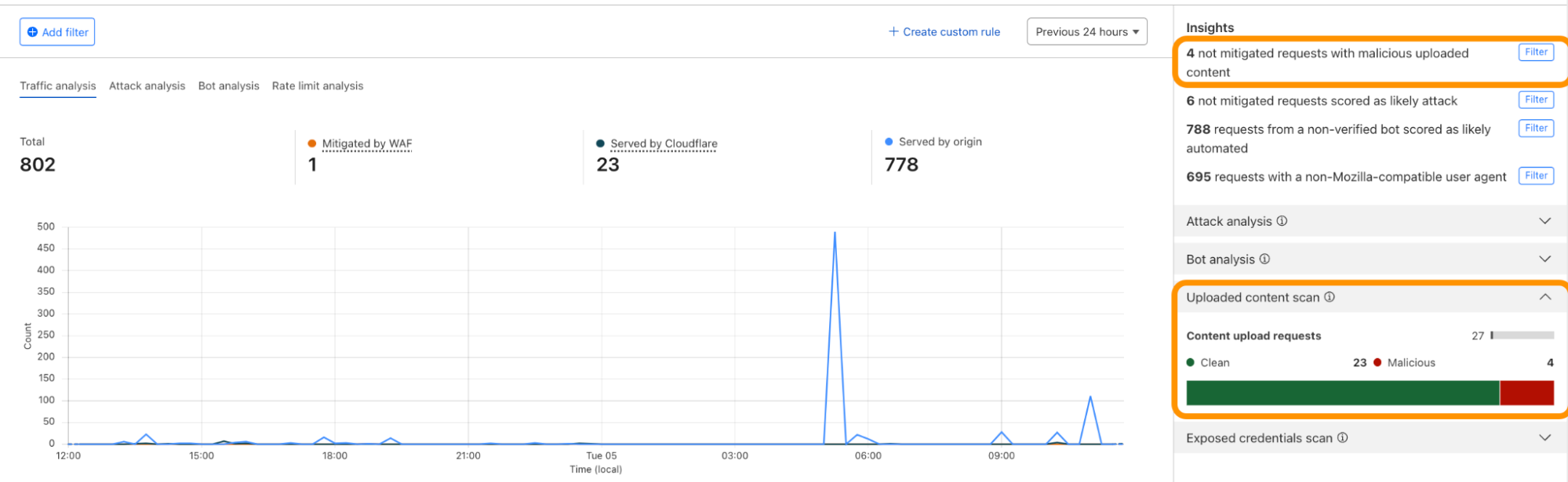
On the other hand, if you want to fine-tune your security settings, you will see better visibility in Security Events, where these are the requests that match specific rules you have created in WAF.
Last but not least, in our Logpush datastream, we have included the scan fields that can be selected to send to any external log handler.
What’s next?
Before the end of March 2024, all current and new customers who have enabled WAF Content Scanning will be able to scan uploaded files up to 15 MB. Next, we'll focus on improving how we handle files in the rules, including adding a dynamic header functionality. Quarantining files is also another important feature we will be adding in the future. If you're an Enterprise customer, reach out to your account team for more information and to get access.