


บทนำ
เมื่อวันที่ 21 มิถุนายน 2022 ที่ผ่านมา Cloudflare ประสบปัญหาระบบขัดข้องซึ่งส่งผลต่อการรับส่งข้อมูลในศูนย์ข้อมูล 19 แห่งของเรา ซึ่งศูนย์ข้อมูลทั้ง 19 แห่งเหล่านี้เป็นศูนย์ที่ใหญ่ที่สุดของเราและจัดการการรับส่งข้อมูลทั่วโลกในสัดส่วนที่สูงมาก เหตุระบบขัดข้องเป็นผลมาจากการเปลี่ยนแปลงที่เป็นส่วนหนึ่งของโครงการระยะยาวเพื่อเพิ่มความยืดหยุ่นภายในศูนย์ข้อมูลที่ใหญ่ที่สุดของเรา เนื่องจากศูนย์เหล่านี้เป็นส่วนสำคัญของโครงสร้างพื้นฐานของเรา และรองรับปริมาณการรับส่งข้อมูลของ Cloudflare ในสัดส่วนที่สูง การเปลี่ยนแปลงการกำหนดค่าเครือข่ายภายในตำแหน่งที่ตั้งเหล่านั้นเป็นเหตุให้ระบบขัดข้อง โดยระบบเริ่มขัดข้องเมื่อเวลา 06:27 ตามเวลา UTC แต่เมื่อเวลา 06:58 ตามเวลา UTC ศูนย์ข้อมูลแห่งแรกกลับมาออนไลน์ได้อีกครั้ง และศูนย์ข้อมูลทั้งหมดกลับมาออนไลน์และทำงานได้ตามปกติอีกครั้งเมื่อเวลา 07:42 ตามเวลา UTC
คุณอาจไม่สามารถเข้าถึงเว็บไซต์และบริการที่ขึ้นตรงกับ Cloudflare ได้โดยพิจารณาจากตำแหน่งที่ตั้งของคุณเป็นสำคัญ แต่ในสถานที่อื่นๆ Cloudflare ยังคงทำงานได้ตามปกติ
เราขออภัยสำหรับเหตุการณ์ระบบขัดข้องครั้งนี้ ซึ่งถือเป็นข้อผิดพลาดของเรา ไม่ใช่เป็นผลจากการโจมตีหรือกิจกรรมที่เป็นอันตราย
ภูมิหลัง
ตลอดช่วง 18 เดือนที่ผ่านมา Cloudflare ทำงานมาโดยตลอดเพื่อปรับเปลี่ยนศูนย์ข้อมูลที่ใหญ่ที่สุดทั้งหมดของเราให้กลายเป็นสถาปัตยกรรมที่ซับซ้อนมากขึ้น โดยปัจจุบัน เราได้พลิกโฉมศูนย์ข้อมูล 19 แห่งของเราให้ก้าวสู่การเป็นสถาปัตยกรรมลักษณะนี้ ซึ่งเรียกขานเป็นการภายในว่า Multi-Colo PoP (MCP): อัมสเตอร์ดัม, แอตแลนต้า, แอชเบิร์น, ชิคาโก, แฟรงก์เฟิร์ต, ลอนดอน, ลอสแองเจลิส, มาดริด, แมนเชสเตอร์, ไมอามี, มิลาน, มุมไบ, นวร์ก, โอซาก้า, เซาเปาโล, ซานโฮเซ, สิงคโปร์, ซิดนีย์, โตเกียว
ส่วนสำคัญของสถาปัตยกรรมใหม่นี้ ซึ่งได้รับการออกแบบมาให้เป็น เครือข่าย Clos คือการเพิ่มเลเยอร์ของการกำหนดเส้นทางที่สร้างโครงข่ายการเชื่อมต่อ โครงข่ายนี้ช่วยให้เราสามารถปิดการใช้งานและเปิดการใช้งานเครือข่ายภายในบางส่วนจากภายในศูนย์ข้อมูลได้อย่างง่ายดายเมื่อต้องการทำการบำรุงรักษาหรือจัดการกับปัญหา เลเยอร์นี้แสดงแทนด้วยโครงสร้างตามที่ปรากฏในแผนภาพต่อไปนี้
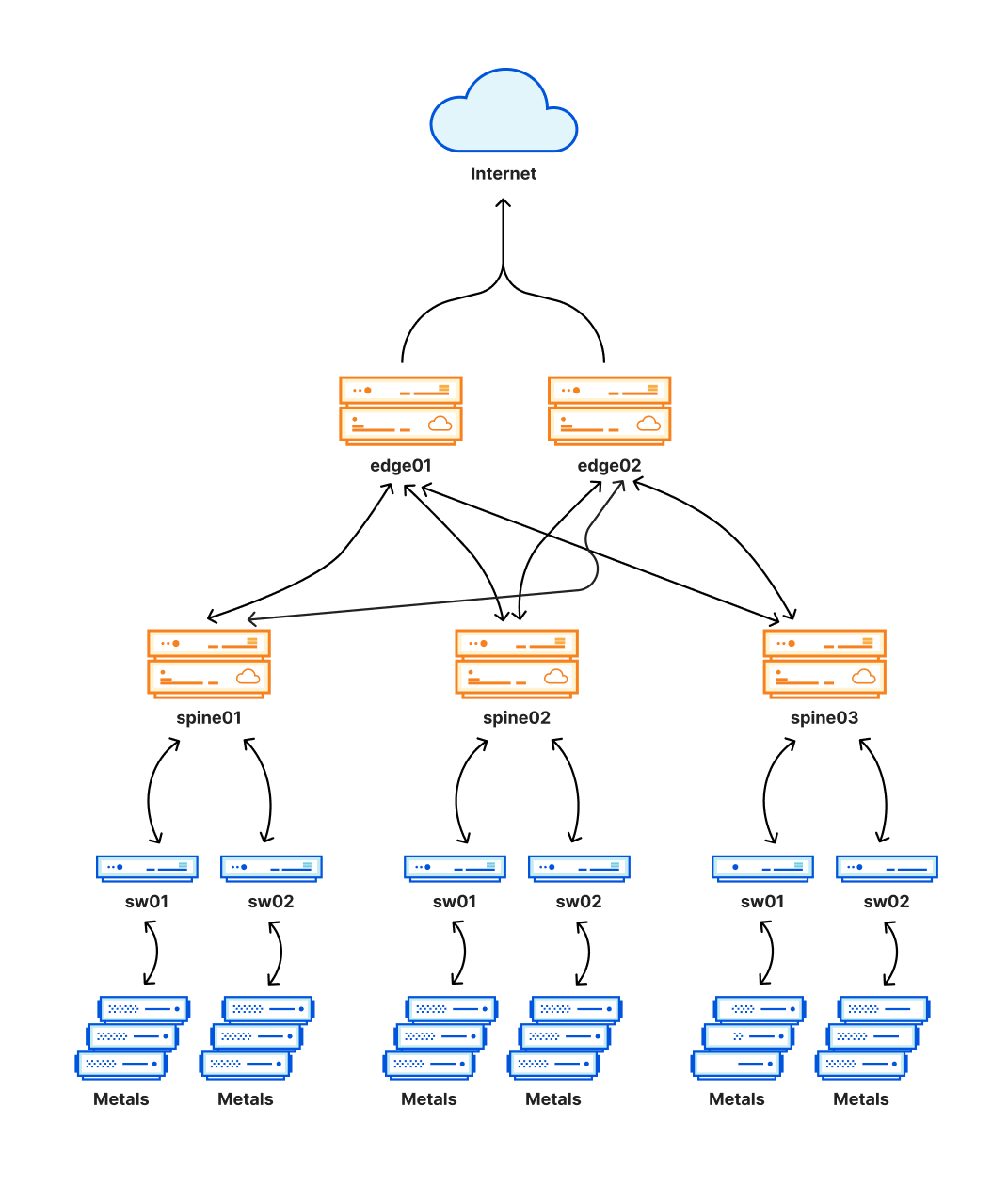
สถาปัตยกรรมใหม่นี้ช่วยให้เราปรับปรุงความน่าเชื่อถือได้อย่างมีนัยสำคัญ เรายังสามารถทำการบำรุงรักษาในสถานที่เหล่านี้ได้โดยไม่ส่งผลต่อการรับส่งข้อมูลของลูกค้า เนื่องจากสถานที่เหล่านี้มีสัดส่วนการรับส่งข้อมูล Cloudflare ที่มีนัยสำคัญ ปัญหาอะไรก็ตามที่เกิดจากที่นี่อาจส่งผลกระทบในวงกว้าง และเป็นเรื่องน่าเศร้าที่เรื่องนี้เกิดขึ้นแล้วที่นี่วันนี้
เส้นเวลาของเหตุการณ์ (UTC) และผลกระทบ
การเข้าถึงบนอินเทอร์เน็ตจะเกิดขึ้นได้ เครือข่ายอย่าง Cloudflare จะใช้โปรโตคอลที่เรียกว่า BGP ในฐานะที่เป็นส่วนหนึ่งของโปรโตคอลนี้ ผู้ให้บริการจะกำหนดนโยบายที่เป็นตัวเลือกว่าให้มี prefix (กลุ่มที่อยู่ IP ที่อยู่ใกล้เคียงกัน) ใดบ้าง ที่จะประกาศไปยังเพียร์ต่างๆ (เครือข่ายอื่น ๆ ที่พวกเขาเชื่อมต่อ) หรือยอมรับการประกาศจากเพียร์เหล่านั้น
นโยบายเหล่านี้จะมีองค์ประกอบย่อยๆ ซึ่งได้รับการประเมินตามลำดับ ผลลัพธ์ขั้นสุดท้ายคือ prefix ที่ระบุ จะมีการประกาศหรือไม่ประกาศ การเปลี่ยนแปลงนโยบายอาจหมายความว่าจะไม่มีการประกาศ prefix ที่ประกาศก่อนหน้านี้อีกต่อไป ซึ่งในกรณีนี้ prefix จะถูกลบออกและที่อยู่ IP เหล่านั้นก็จะไม่สามารถเข้าถึงได้ทางอินเทอร์เน็ตได้อีกต่อไป
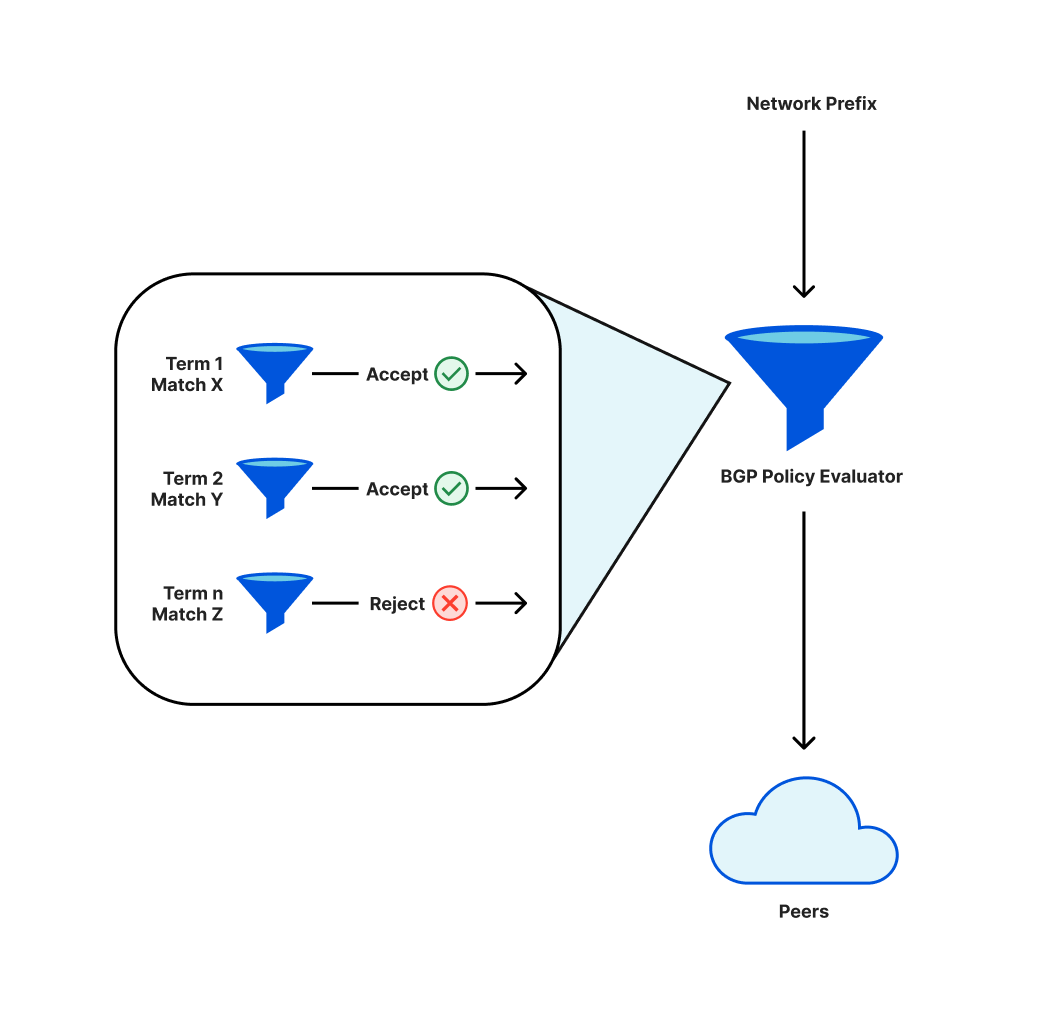
ขณะที่เรานำการเปลี่ยนแปลงดังกล่าวมาใช้กับนโยบายการประกาศ prefix การเรียงลำดับคำต่าง ๆ ใหม่ ทำให้เราต้องถอนซับเซ็ตที่สำคัญของ prefix ออกด้วย
และเพราะการถอนซับเซ็ตนี้ ทีมวิศวกรของ Cloudflare จึงประสบความยุ่งยากมากขึ้นกว่าเดิมเมื่อต้องเข้าถึงตำแหน่งที่ตั้งที่ได้รับผลกระทบเพื่อแปลงกลับการเปลี่ยนแปลงที่เป็นปัญหา เรามีขั้นตอนสำรองเพื่อจัดการกับเหตุการณ์ดังกล่าว และใช้ขั้นตอนเหล่านั้นเพื่อควบคุมตำแหน่งที่ตั้งที่ได้รับผลกระทบ
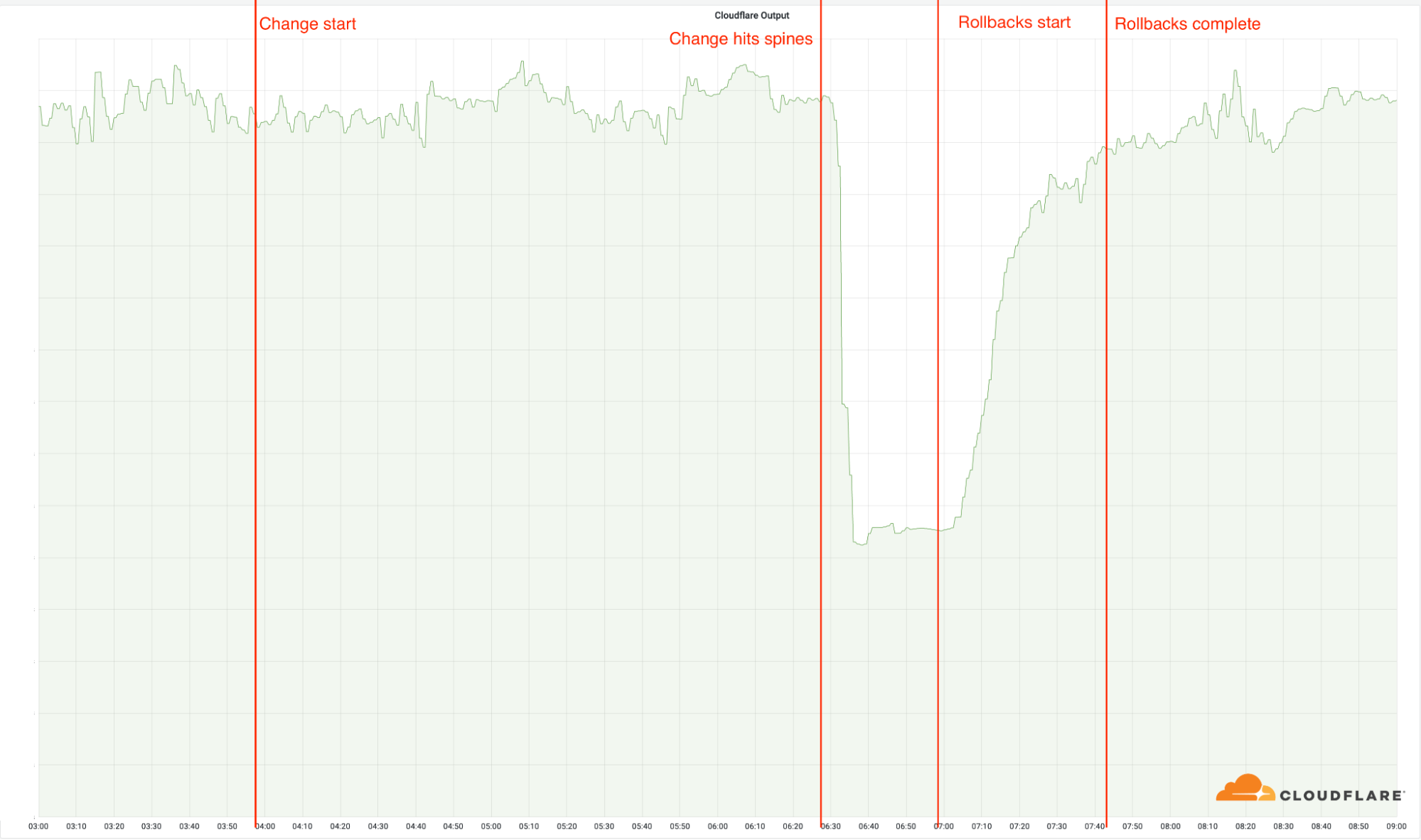
03:56: เรานำการเปลี่ยนแปลงมาใช้กับตำแหน่งที่ตั้งแรกของเรา สถานที่ตั้งของเราทุกแห่งไม่ได้รับผลกระทบจากการเปลี่ยนแปลง เนื่องจากสถานที่เหล่านี้ใช้สถาปัตยกรรมแบบเก่า
06:17: การเปลี่ยนแปลงนี้นำไปใช้กับสถานที่ตั้งที่ใหญ่ที่สุดของเรา แต่ไม่ใช่สถานที่ที่มีสถาปัตยกรรมใหม่
06:27: มีการนำการเปลี่ยนแปลงออกใช้กับสถานที่ที่ใหญ่ที่สุดของเราที่มาพร้อมสถาปัตยกรรมใหม่ และการเปลี่ยนแปลงนี้นำไปใช้กับส่วนแกนหลักของเราด้วย นี่คือตอนที่เกิดเหตุการณ์ดังกล่าวขึ้น ทำให้ศูนย์ข้อมูลทั้ง 19 แห่งออฟไลน์ลงอย่างฉับพลันทันที
06:32: Cloudflare ประกาศแจ้งเหตุการณ์เป็นการภายใน
06:51: ทำการเปลี่ยนแปลงครั้งแรกบนเราเตอร์เพื่อตรวจสอบถึงต้นตอที่แท้จริงที่อาจเป็นไปได้
06:58: พบต้นเหตุของปัญหาและทำความเข้าใจ เริ่มดำเนินการเพื่อแก้ไขการเปลี่ยนแปลงที่เป็นปัญหา
07:42: การคืนค่ากลับในลำดับสุดท้ายเสร็จเรียบร้อย การดำเนินการนี้ล่าช้าออกไปเนื่องจากทีมวิศวกรเครือข่ายต้องตรวจสอบการเปลี่ยนแปลงที่แต่ละส่วนทำขึ้นมา คืนค่าจากการคืนค่าก่อนหน้านั้น เป็นเหตุให้ปัญหากลับมาเกิดขึ้นอีกเป็นระยะๆ
08:00: ปิดเหตุการณ์
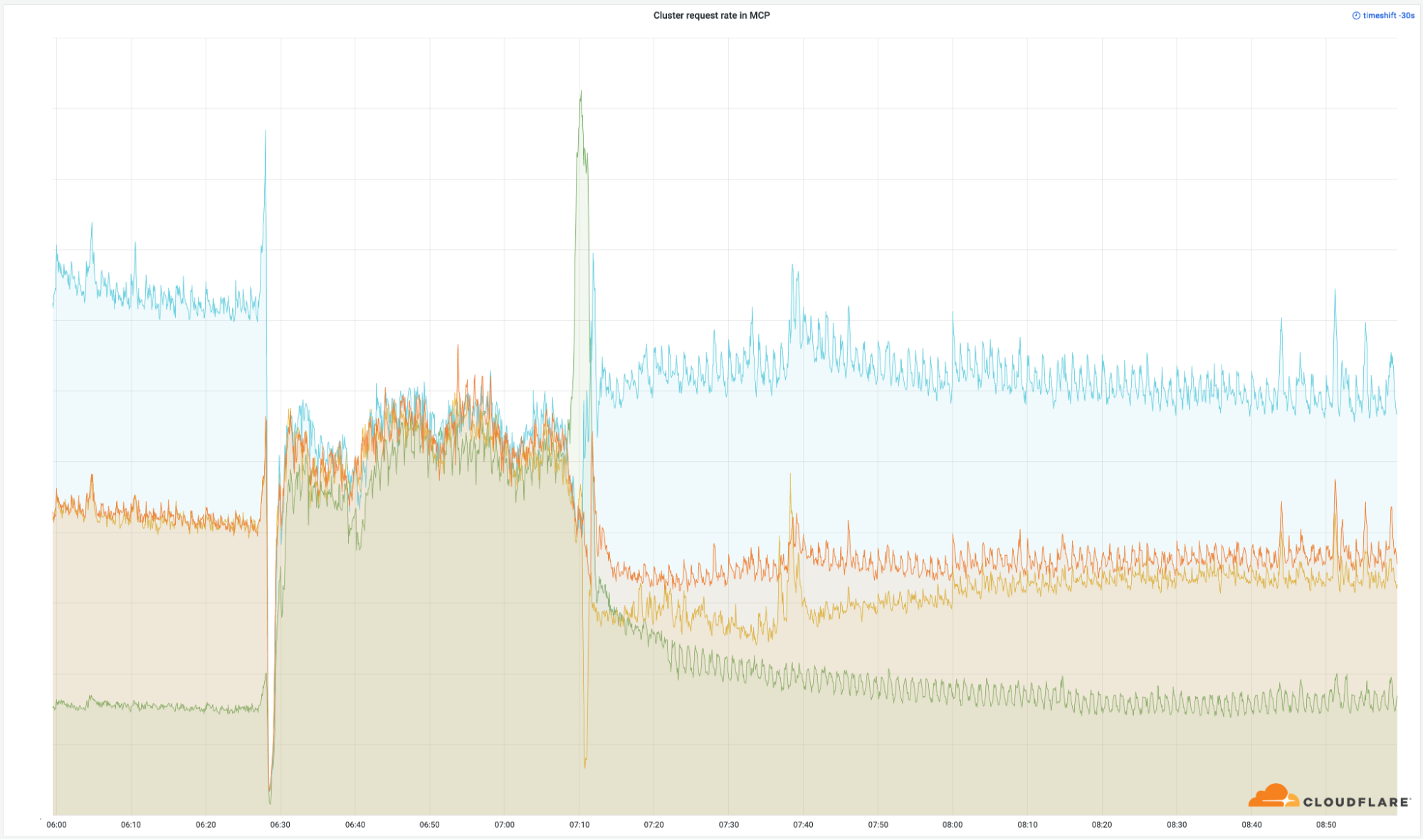
ความสำคัญของศูนย์ข้อมูลเหล่านี้เห็นได้อย่างชัดเจนจากจำนวนคำขอสำเร็จที่เราส่งค่ากลับทั่วโลก:
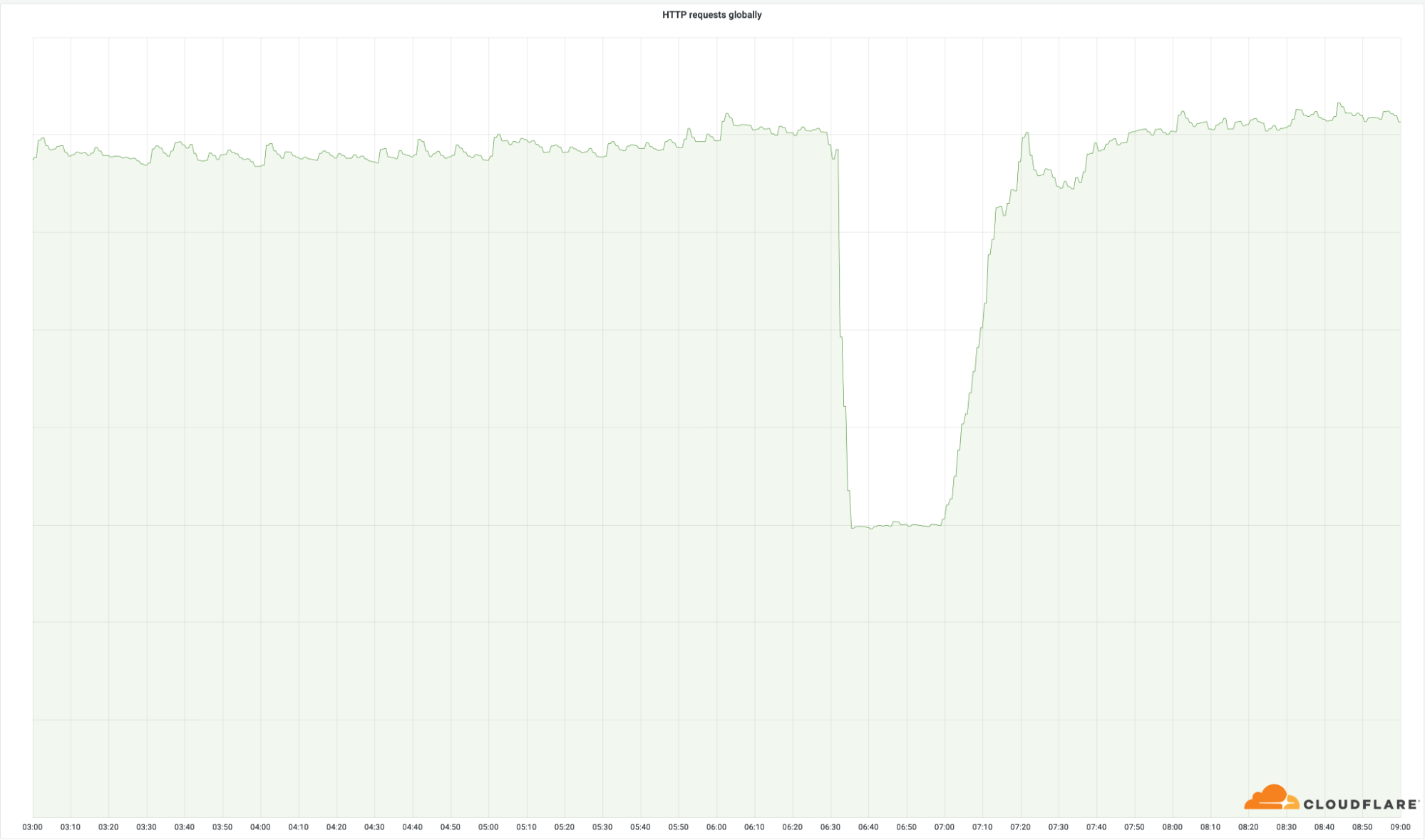
แม้ว่าศูนย์ข้อมูลเหล่านี้จะเป็นเพียงส่วนเล็ก ๆ ของเครือข่ายทั้งหมดของเรา (4%) แต่ 50% ของคำขอทั้งหมดของเราได้รับผลกระทบ เหตุการณ์ทำนองนี้ปรากฏในแบนด์วิดธ์ขาออกของเราด้วย:
คำอธิบายทางเทคนิคของข้อผิดพลาดและวิธีที่เกิดข้อผิดพลาด
เราพยายามอย่างต่อเนื่องเพื่อกำหนดค่าโครงสร้างพื้นฐานให้เป็นมาตรฐาน ส่วนหนึ่งของความพยายามดังกล่าวคือการเปลี่ยนแปลงเพื่อสร้างมาตรฐานให้กับชุมชน BGP ที่เรารวมเข้ากับซับเซ็ตของ prefix ที่เราประกาศ กล่าวให้เฉพาะเจาะจงคือ เรากำลังเพิ่มชุมชนข้อมูลไว้รวมกับ prefix ในไซต์ของเรา prefix เหล่านี้ช่วยให้โหนดการประมวลผลของเราสามารถสื่อสารระหว่างกัน หรือเชื่อมต่อกับข้อมูลต้นทางของลูกค้าได้ นอกจากนี้ ส่วนหนึ่งของขั้นตอนการเปลี่ยนแปลงที่ Cloudflare คือการสร้างตั๋วคำขอเปลี่ยนแปลง (CR) ซึ่งรวมถึงการดำเนินการเปลี่ยนแปลงแบบ dry-run และขั้นตอนการเปลี่ยนแปลงแบบเป็นลำดับขั้น แต่ก่อนจะเปิดตัวขั้นตอนดังกล่าวนี้ ทีมวิศวกรจะต้องเข้ามาตรวจสอบก่อน ซึ่งน่าเสียดายที่ในกรณีนี้ ขั้นตอนนั้นไม่เล็กพอที่จะตรวจจับข้อผิดพลาดได้ก่อนส่งกระทบโครงสร้างทั้งหมดของเรา
การเปลี่ยนแปลงเกิดขึ้นในลักษณะนี้บนเราเตอร์ตัวใดตัวหนึ่ง:
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
การเปลี่ยนแปลงดังกล่าวไม่เป็นอันตราย และเพิ่งเพิ่มเติมข้อมูลใหม่ ๆ รวมเข้ากับการประกาศ prefix เหล่านี้ การเปลี่ยนแปลงบนโครงสร้างมีดังต่อไปนี้:
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
หากดู Diff นี้คร่าว ๆ ในเบื้องต้นจะให้ความรู้สึกว่าการเปลี่ยนแปลงนี้เหมือนกัน แต่จริง ๆ แล้ว มันไม่เกี่ยวกับเรื่องนี้ หากเราเน้นที่ส่วนที่ 1 ของ Diff เราอาจหาสาเหตุได้ชัดเจนยิ่งขึ้น:
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
ในรูปแบบ Diff นี้ เครื่องหมายอัศเจรีย์ด้านหน้าคำต่าง ๆ หมายถึงการเรียงลำดับคำใหม่ ในกรณีนี้ คำหลาย ๆ คำจะถูกเลื่อนขึ้น และมีการเพิ่มคำสองคำที่ด้านล่าง กล่าวให้เฉพาะเจาะจงคือ คำว่า 4-ADV-SITE-LOCALS ถูกย้ายจากด้านบนลงมาด้านล่าง ตอนนี้ คำนี้จะมาอยู่หลังคำว่า REJECT-THE-REST และชื่อนี้บอกถึงการปฏิเสธได้อย่างชัดแจ้ง
term REJECT-THE-REST {
then reject;
}
ณ ตอนนี้ คำนี้อยู่ก่อนคำที่อยู่ภายในไซต์ เราจึงต้องหยุดประกาศ prefix สำหรับไซต์ในพื้นที่ของเราทันที พร้อมลบการเข้าถึงโดยตรงของเราไปยังตำแหน่งที่ตั้งที่ได้รับผลกระทบทั้งหมดในชั่วขณะเดียว และปิดใช้ความสามารถของเซิร์ฟเวอร์ของเราในการเข้าถึงข้อมูลต้นทาง
นอกเหนือจากการที่ไม่สามารถติดต่อกับต้นทางได้แล้ว การนำ prefix ภายในของไซต์เหล่านี้ออก ยังทำให้ระบบ Multimog ของโหลดบาลานซ์ภายในของเรา (อีกรูปแบบของ Unimog load-balancer ของเรา) หยุดการทำงานด้วย เนื่องจากไม่สามารถส่งต่อคำขอระหว่างเซิร์ฟเวอร์ใน MCP ได้ ซึ่งหมายความว่าคลัสเตอร์ประมวลผลที่เล็กกว่าของเราใน MCP ได้รับปริมาณการรับส่งข้อมูลเท่ากับคลัสเตอร์ที่ใหญ่ที่สุดของเรา ทำให้คลัสเตอร์ที่มีขนาดเล็กกว่าอยู่ในสภาวะโอเวอร์โหลด
ขั้นตอนการแก้ไขและติดตามผล
เหตุการณ์นี้ส่งผลกระทบในวงกว้าง และเราให้ความสำคัญกับเรื่องความพร้อมใช้งานมากเป็นพิเศษ เราได้แจกแจงถึงสิ่งที่ต้องปรับปรุงและจะดำเนินความพยายามต่อไปเพื่อค้นหาช่องโหว่อื่นๆ ที่อาจทำให้เกิดเหตุการณ์เช่นนี้ขึ้นอีก
สิ่งที่เราดำเนินการในทันทีคือ:
ขั้นตอน: แม้ว่าโปรแกรม MCP ได้รับการออกแบบมาเพื่อปรับปรุงความพร้อมใช้งาน ช่องว่างระหว่างขั้นตอนวิธีการอัปเดตศูนย์ข้อมูลเหล่านี้ทำให้เกิดผลกระทบในวงกว้างขึ้นโดยเฉพาะภายในตำแหน่งที่ตั้งของ MCP แม้ว่าเราจะใช้กระบวนการ stagger รองรับการเปลี่ยนแปลงนี้ แต่นโยบาย stagger ไม่ได้รวมศูนย์ข้อมูล MCP ไว้จนกว่าจะถึงขั้นตอนสุดท้าย ขั้นตอนการเปลี่ยนแปลงและระบบอัตโนมัติจำเป็นต้องรวมขั้นตอนการทดสอบและปรับใช้เฉพาะ MCP เพื่อยืนยันว่าจะไม่เกิดผลลัพธ์ที่ไม่คาดคิด
สถาปัตยกรรม: การกำหนดค่าเราเตอร์ที่ไม่ถูกต้องทำให้ไม่สามารถประกาศเส้นทางที่เหมาะสมไปยัง Edge ของเราได้ จนเป็นสาเหตุให้การรับส่งข้อมูลไม่เคลื่อนไหวไปยังโครงสร้างพื้นฐานของเรา นอกจากนี้ประกาศนโยบายที่ทำให้เกิดการประกาศเส้นทางที่ไม่ถูกต้องจะได้รับการออกแบบใหม่ทั้งหมดเพื่อป้องกันการออกคำสั่งผิดโดยไม่ตั้งใจ
การทำงานอัตโนมัติ: ชุดการทำงานอัตโนมัติของเรามาพร้อมโอกาสมากมายที่จะช่วยบรรเทาผลกระทบบางส่วนหรือทั้งหมดที่มองเห็นได้จากเหตุการณ์นี้ โดยในขั้นต้น เราจะเน้นที่การปรับปรุงระบบอัตโนมัติที่บังคับใช้นโยบาย stagger ที่ปรับปรุงให้ดีขึ้นเพื่อรองรับการเปิดตัวการกำหนดค่าเครือข่ายและให้การย้อนกลับแบบ “commit-confirm” โดยอัตโนมัติ การปรับปรุงแบบเดิมจะช่วยลดผลกระทบโดยรวมได้อย่างมาก และการปรับปรุงครั้งหลังจะลดเวลาในการแก้ไขในช่วงที่เกิดเหตุการณ์ลงอย่างเห็นได้ชัด
บทสรุป
แม้ว่า Cloudflare ได้ทุ่มเงินจำนวนมหาศาลในงานออกแบบ MCP ของเราเพื่อปรับปรุงความพร้อมของการบริการ แต่สิ่งที่เราเห็นได้อย่างชัดเจนคือ ความคาดหวังของลูกค้าที่หายไปอันเนื่องมาจากเหตุการณ์ที่เจ็บปวดแสนสาหัสนี้ เราขออภัยที่ลูกค้าและผู้ใช้ทั้งหมดของเราต้องประสบกับเหตุขัดข้องจนไม่สามารถเข้าถึงคุณสมบัติอินเทอร์เน็ตได้ในช่วงที่ระบบขัดข้องได้ เราได้เริ่มดำเนินการกับการเปลี่ยนแปลงที่ระบุไว้ข้างต้นแล้ว และจะดำเนินการอย่างแข็งขันเพื่อป้องกันไม่ให้เกิดเหตุการณ์เช่นนี้ขึ้นอีก