


No final de agosto de 2022, a equipe de suporte ao cliente da Cloudflare começou a receber reclamações sobre sites em nossa rede que estavam fora do ar na Áustria. Nossa equipe imediatamente entrou em ação para tentar identificar a origem do que, de fora, parecia uma interrupção parcial da internet na Áustria. Rapidamente percebemos que era um problema com os provedores de internet austríacos locais.
Mas a interrupção do serviço não foi resultado de um problema técnico. Como soubemos mais tarde pelos relatos da mídia, o que estávamos vendo era o resultado de uma ordem judicial. Sem qualquer notificação à Cloudflare, um tribunal austríaco ordenou que os Provedores de internet austríacos bloqueassem 11 dos endereços de IP da Cloudflare.
Em uma tentativa de bloquear 14 sites que estariam violando os direitos autorais, segundo seus detentores, o bloqueio de IPs ordenado pelo tribunal tornou milhares de sites inacessíveis para os internautas comuns na Áustria durante um período de dois dias. O que os milhares de outros sites fizeram de errado? Nada. Eles foram vítimas temporárias do fracasso em criar soluções legais e sistemas que reflitam a arquitetura real da internet.
Hoje, vamos nos aprofundar em uma discussão sobre bloqueio de IPs: por que o vemos, o que é, o que faz, quem afeta e por que é uma maneira tão problemática de abordar o conteúdo on-line.
Efeitos colaterais, grandes e pequenos
O mais absurdo é que esse tipo de bloqueio acontece regularmente, em todo o mundo. Mas, a menos que esse bloqueio aconteça na escala que aconteceu na Áustria, ou que alguém decida chamar a atenção para ele, normalmente é invisível para o mundo exterior. Mesmo a Cloudflare, com profundo conhecimento técnico e compreensão sobre como funciona o bloqueio, não consegue ver rotineiramente quando um endereço de IP está bloqueado.
Para os internautas, fica ainda menos transparente. Eles geralmente não sabem por que não conseguem se conectar a um determinado site, de onde vem o problema de conexão ou como resolvê-lo. Eles simplesmente sabem que não conseguem acessar o site que estavam tentando visitar. E isso pode ser difícil de documentar quando os sites se tornam inacessíveis devido ao bloqueio de endereços de IP.
Práticas de bloqueio também são amplamente difundidas. Em seu relatório Freedom on the Net, a Freedom House informou recentemente que 40 dos 70 países examinados, que variam de países como Rússia, Irã e Egito a democracias ocidentais como Reino Unido e Alemanha, fizeram algum tipo de bloqueio de sites. Embora o relatório não se aprofunde exatamente como esses países bloqueiam, muitos deles usam formas de bloqueio de IPs, com o mesmo tipo de efeitos potenciais para uma interrupção parcial da internet que vimos na Áustria.
Embora possa ser desafiador avaliar a quantidade de danos colaterais do bloqueio de IPs, temos exemplos em que as organizações tentaram quantificá-lo. Em conjunto com um caso perante o Tribunal Europeu de Direitos Humanos, o European Information Society Institute, uma organização sem fins lucrativos com sede na Eslováquia, analisou o regime da Rússia para bloqueio de sites em 2017. A Rússia usou exclusivamente endereços de IPs para bloquear o conteúdo. O European Information Society Institute concluiu que o bloqueio de IPs levou ao “bloqueio colateral de sites em grande escala” e observou que, em 28 de junho de 2017, “6.522.629 recursos da internet foram bloqueados na Rússia, dos quais 6.335.850, ou 97%, foram bloqueados colateralmente, ou seja, sem justificativa legal.”
No Reino Unido, o bloqueio generalizado levou a organização sem fins lucrativos Open Rights Group a criar o site Blocked.org.uk. O site possui uma ferramenta que permite que usuários e proprietários de sites relatem overblocking e solicitem que os provedores o removam. O grupo também tem centenas de histórias individuais sobre o efeito dos bloqueios naqueles cujos sites foram bloqueados de forma inadequada, de instituições de caridade a pequenos empresários. Embora nem sempre fique claro quais métodos de bloqueio são usados, o fato de o site ser necessário comunica o significado do overblocking. Imagine uma costureira, um relojoeiro ou um revendedor de carros que anuncia seus serviços e possivelmente conquista novos clientes com seu site, se os usuários locais não puderem acessar o site isso não vai acontecer.
Uma reação pode ser: “Bem, apenas certifique-se de que não haja sites restritos compartilhando um endereço com sites irrestritos.” Mas, como discutiremos com mais detalhes, isso ignora a grande diferença entre o número de nomes de domínio possíveis e o número de endereços de IP disponíveis e vai contra as próprias especificações técnicas que capacitam a internet. Além disso, as definições de restrito e irrestrito diferem entre nações, comunidades e organizações. Mesmo que fosse possível conhecer todas as restrições, os designs dos protocolos, da própria internet, significam que é simplesmente inviável, senão impossível, satisfazer as restrições de cada agência.
Preocupações legais e de direitos humanos
O overblocking de sites não é apenas um problema para os usuários; ele tem implicações legais. Devido ao efeito que pode ter sobre os cidadãos comuns que buscam exercer seus direitos on-line, as entidades governamentais (tribunais e órgãos reguladores) têm a obrigação legal de garantir que suas ordens sejam necessárias e proporcionais e não afetem desnecessariamente aqueles que não estão contribuindo para o dano.
Seria difícil imaginar, por exemplo, que um tribunal em resposta a uma alegada transgressão emitiria às cegas um mandado de busca ou uma ordem com base apenas em um endereço sem se importar se esse endereço era de uma casa com uma única família, de um condomínio com um edifício de seis unidades, ou de um arranha-céus com centenas de unidades separadas. Mas esse tipo de prática com endereços de IP parece estar descontrolado.
Em 2020, o Tribunal europeu de direitos humanos (CEDH), o tribunal que supervisiona a implementação da Convenção europeia de direitos humanos do conselho da Europa, analisou um caso envolvendo um site que foi bloqueado na Rússia não porque havia sido alvo do governo russo, mas porque compartilhou um endereço de IP com um site bloqueado. O dono do site entrou com uma ação sobre o bloqueio. O CEDH concluiu que o bloqueio indiscriminado era inadmissível, determinando que o bloqueio do conteúdo legal do site “equivale a uma interferência arbitrária nos direitos dos proprietários de tais sites”. Em outras palavras, a ECHR decidiu que era impróprio um governo emitir ordens que resultassem no bloqueio de sites não visados.
Usar a infraestrutura da internet para enfrentar os desafios de conteúdo
Os internautas comuns não pensam muito sobre como o conteúdo que estão tentando acessar on-line é entregue a eles. Eles deduzem que, quando digitam um nome de domínio no navegador, o conteúdo é exibido automaticamente. E se não é, eles acham que o site tem problemas, a menos que toda a sua conexão com a internet pareça estar com problemas. Mas essas suposições básicas ignoram a realidade de que as conexões a um site são frequentemente usadas para limitar o acesso ao conteúdo on-line.
Por que os países bloqueiam as conexões com sites? Talvez eles queiram impedir que seus próprios cidadãos acessem o que acreditam ser conteúdo ilegal, como jogos de azar on-line ou material explícito, que são permitidos em outras partes do mundo. Talvez eles queiram evitar a visualização de uma fonte de notícias estrangeira que acreditam ser principalmente de desinformação. Ou talvez eles queiram apoiar detentores de direitos autorais que buscam bloquear o acesso a um site para limitar a exibição de conteúdo que eles acreditam que infringe seus direitos de propriedade intelectual.
Para ser claro, bloquear o acesso não é a mesma coisa que remover conteúdo da internet. Há muitas obrigações legais e autoridades específicas para permitir a remoção de fato de conteúdo ilegal. Na verdade, a expectativa legal em muitos países é que o bloqueio seja uma questão de último recurso, após tentativas de remover o conteúdo na origem.
O bloqueio apenas impede que certos visualizadores, aqueles cujo acesso à internet depende do provedor que está bloqueando, possam acessar sites. O site em si continua a existir on-line e pode ser acessado por todos. Mas quando o conteúdo vem de um lugar diferente e não pode ser facilmente removido, um país pode ver o bloqueio como sua melhor ou única abordagem.
Reconhecemos as preocupações que às vezes levam os países a implementar o bloqueio. Mas, fundamentalmente, acreditamos que é importante que os usuários saibam quando os sites que estão tentando acessar foram bloqueados e, na medida do possível, quem os bloqueou e por quê. E é fundamental que quaisquer restrições de conteúdo sejam tão limitadas quanto possível para lidar com o dano, para evitar infringir os direitos de outras pessoas.
O bloqueio de endereços de IP por força bruta não permite essas coisas. É totalmente não transparente para os internautas. A prática tem consequências não intencionais e inevitáveis em outros conteúdos. E a própria estrutura da internet significa que não há uma boa maneira de identificar quais outros sites podem ser afetados antes ou durante um bloqueio de IPs.
Para entender o que aconteceu na Áustria e o que acontece em muitos outros países ao redor do mundo que buscam bloquear conteúdo com a falta de objetividade dos endereços de IP, temos que entender o que está acontecendo nos bastidores. Isso significa aprofundamento em alguns detalhes técnicos.
A identidade está ligada aos nomes, nunca aos endereços
Antes mesmo de começarmos a descrever as realidades técnicas do bloqueio, é importante ressaltar que a primeira e melhor opção para lidar com o conteúdo está na fonte. O proprietário de um site ou provedor de hospedagem tem a opção de remover o conteúdo em um nível granular, sem precisar desativar o site inteiro. No lado mais técnico, um registrador ou registro de nome de domínio tem a possibilidade de retirar um nome de domínio e, portanto, um site da internet.
Mas como bloquear o acesso a um site se, por qualquer motivo, o proprietário ou a fonte do conteúdo não puder ou não quiser removê-lo da internet? Existem apenas três pontos de controle possíveis.
O primeiro é por meio do Domain Name System (DNS), que traduz nomes de domínio em endereços de IP para que o site possa ser encontrado. Em vez de retornar um endereço de IP válido para um nome de domínio, o resolvedor de DNS pode mentir e responder com um código, NXDOMAIN, o que significa que “tal nome não existe”. Uma abordagem melhor seria usar um dos números de erros honestos padronizados em 2020, incluindo o erro 15 para bloqueado, o 16 para censurado, o 17 para filtrado ou o 18 para proibido, embora esses não sejam amplamente usados atualmente.
Curiosamente, a precisão e a eficácia do DNS como ponto de controle dependem de o resolvedor de DNS ser privado ou público. Os resolvedores de DNS privados ou "internos" são operados por provedores e ambientes corporativos pelos seus próprios clientes conhecidos, o que significa que os operadores podem ser precisos na aplicação de restrições de conteúdo. Por outro lado, esse nível de precisão não está disponível para resolvedores abertos ou públicos, até porque o roteamento e o endereçamento são globais e estão em constante mudança no mapa da internet, totalmente diferente dos endereços e rotas em um mapa postal ou de ruas que é fixo. Por exemplo, os resolvedores de DNS privados podem bloquear o acesso a sites em regiões geográficas específicas com pelo menos algum nível de precisão de uma forma que os resolvedores de DNS públicos não conseguem, o que se torna extremamente importante devido aos regimes de bloqueio díspares (e inconsistentes) em todo o mundo.
A segunda abordagem é bloquear solicitações de conexão individuais para um nome de domínio restrito. Quando um usuário ou cliente deseja visitar um site, uma conexão é iniciada do cliente para um nome de servidor, ou seja, o nome de domínio. Se uma rede ou dispositivo no caminho for capaz de observar o nome do servidor, a conexão pode ser encerrada. Ao contrário do DNS, não há nenhum mecanismo para comunicar ao usuário que o acesso ao nome do servidor foi bloqueado ou por quê.
A terceira abordagem é bloquear o acesso a um endereço de IP onde o nome de domínio pode ser encontrado. Seria como bloquear a entrega de todas as correspondências para um endereço físico. Imagine, por exemplo, que esse endereço é um arranha-céu com seus muitos ocupantes não relacionados e independentes. A interrupção da entrega de correspondência no endereço do arranha-céu causa danos colaterais, afetando invariavelmente todas as partes naquele endereço. Os endereços de IP funcionam da mesma maneira.
Notavelmente, o endereço de IP é a única das três opções que não possui anexo ao nome de domínio. O nome de domínio do site não é necessário para roteamento e entrega de pacotes de dados; na verdade, é totalmente ignorado. Um site pode estar disponível em qualquer endereço de IP ou mesmo em vários endereços de IP simultaneamente. E o conjunto de endereços de IP em que um site está pode mudar a qualquer momento. O conjunto de endereços de IP não pode ser conhecido definitivamente consultando o DNS, que pode retornar qualquer endereço válido a qualquer momento por qualquer motivo, desde 1995.
A ideia de que um endereço representa uma identidade é um anátema para o design da internet, porque a dissociação entre endereço e nome está profundamente enraizada nos padrões e protocolos da internet, conforme explicado a seguir.
A internet é um conjunto de protocolos, não uma política ou perspectiva
Muitas pessoas ainda deduzem, incorretamente, que um endereço de IP representa um único site. Afirmamos anteriormente que a associação entre nomes e endereços é compreensível, visto que os primeiros componentes conectados da internet apareciam como um computador, uma interface, um endereço e um nome. Essa associação um-para-um era um artefato do ecossistema no qual o protocolo da internet foi implantado e atendia às necessidades da época.
Apesar da prática de nomenclatura um-para-um do início da internet, sempre foi possível atribuir mais de um nome a um servidor (ou "host"). Por exemplo, um servidor era (e ainda é) frequentemente configurado com nomes para refletir suas ofertas de serviço, como mail.example.com e www.example.com, mas eles compartilhavam um nome de domínio base. Havia poucos motivos para ter nomes de domínio completamente diferentes até a necessidade de colocar sites completamente diferentes em um único servidor. Essa prática foi facilitada em 1997 pelo cabeçalho Host em HTTP/1.1, um recurso preservado pelo campo SNI em uma extensão TLS em 2003.
Ao longo dessas mudanças, o protocolo da internet e, separadamente, o protocolo de DNS, não apenas acompanharam o ritmo, mas permaneceram fundamentalmente inalterados. Eles são a própria razão pela qual a internet foi capaz de escalar e evoluir, porque tratam de endereços, acessibilidade e nomes arbitrários para relacionamentos de endereços de IP.
Os designs de IP e DNS também são totalmente independentes, o que apenas reforça que os nomes são separados dos endereços. Uma inspeção mais detalhada dos elementos de design dos protocolos esclarece as percepções errôneas das políticas que levam à prática comum atual de controlar o acesso ao conteúdo bloqueando endereços de IP.
Por design, o IP é para acessibilidade e nada mais
Assim como grandes projetos públicos de engenharia civil dependem de códigos de construção e melhores práticas, a internet é construída usando um conjunto de padrões e especificações abertos informados pela experiência e acordados por consenso internacional. Os padrões da internet que conectam hardware e aplicativos são publicados pela Internet Engineering Task Force (IETF) na forma de "Requests for Comment" ou RFCs, assim chamados não para sugerir incompletude, mas para refletir que os padrões devem ser capazes de evoluir com conhecimento e experiência. A IETF e seus RFCs são consolidados na própria estrutura das comunicações, por exemplo, com o primeiro RFC 1 publicado em 1969. A especificação do Protocolo da internet (IP) alcançou o status de RFC em 1981.
Juntamente com as organizações de padronização, o sucesso da internet foi auxiliado por uma ideia central conhecida como princípio end-to-end (e2e), codificado também em 1981, com base em anos de experiência de tentativa e erro. O princípio end-to-end é uma abstração poderosa que, apesar de assumir muitas formas, manifesta uma noção central da especificação do protocolo da internet: a única responsabilidade da rede é estabelecer a acessibilidade e todos os outros recursos possíveis têm um custo ou um risco.
A ideia de “acessibilidade” no protocolo da internet também está consagrada no design dos próprios endereços de IP. Observando a especificação do Protocolo da internet, RFC 791, o seguinte trecho da Seção 2.3 é explícito sobre os endereços de IP não terem associação com nomes, interfaces ou qualquer outra coisa.
Addressing
A distinction is made between names, addresses, and routes [4]. A
name indicates what we seek. An address indicates where it is. A
route indicates how to get there. The internet protocol deals
primarily with addresses. It is the task of higher level (i.e.,
host-to-host or application) protocols to make the mapping from
names to addresses. The internet module maps internet addresses to
local net addresses. It is the task of lower level (i.e., local net
or gateways) procedures to make the mapping from local net addresses
to routes.
[ RFC 791, 1981 ]
Assim como os endereços postais dos arranha-céus no mundo físico, os endereços de IP nada mais são do que endereços escritos em um pedaço de papel. E, assim como em um endereço no papel, nunca se pode ter certeza sobre as entidades ou organizações que existem em um endereço de IP. Em uma rede como a da Cloudflare, qualquer endereço de IP único representa milhares de servidores e pode ter ainda mais sites e serviços, em alguns casos chegando a milhões, expressamente porque o protocolo da internet foi projetado para permitir isso.
Aqui está uma pergunta interessante: poderíamos, ou qualquer provedor de serviços de conteúdo poderia, garantir que cada endereço de IP corresponda a um e apenas um nome? A resposta é um inequívoco não, e aqui também, por causa de um projeto de protocolo, neste caso, o DNS.
O número de nomes no DNS sempre excede os endereços disponíveis
Uma relação um-para-um entre nomes e endereços é impossível dadas as especificações da internet pelas mesmas razões pelas quais é inviável no mundo físico. Ignore por um momento que pessoas e organizações podem mudar de endereço. Fundamentalmente, o número de pessoas e organizações no planeta excede o número de endereços postais. Não apenas queremos, mas precisamos que a internet acomode mais nomes do que endereços.
A diferença de magnitude entre nomes e endereços também é codificada nas especificações. Os endereços IPv4 são de 32 bits e os endereços IPv6 são de 128 bits. O tamanho de um nome de domínio que pode ser consultado pelo DNS é de até 253 octetos ou 2.024 bits (da Seção 2.3.4 do RFC 1035, publicado em 1987). A tabela abaixo ajuda a colocar essas diferenças em perspectiva:
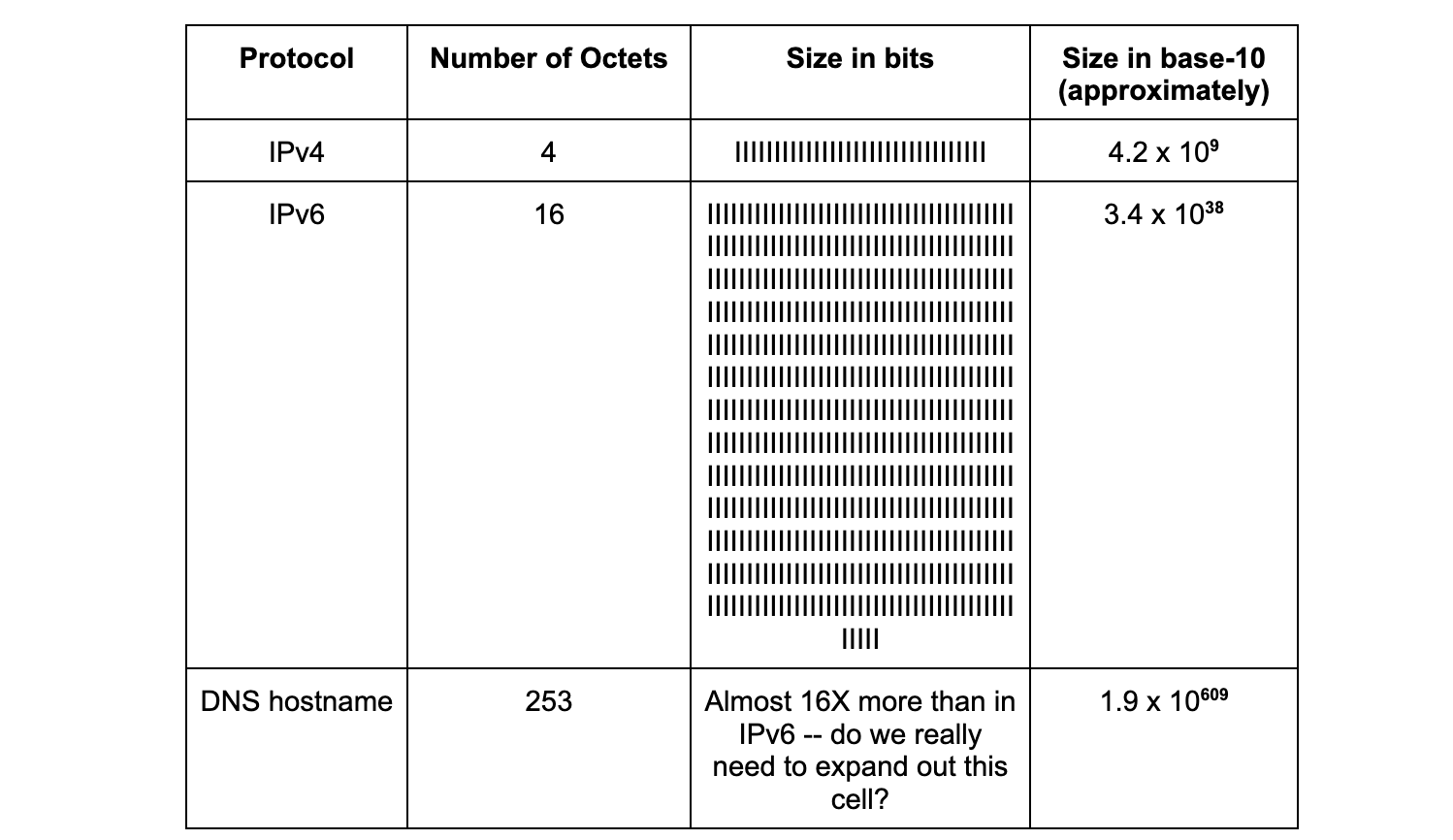
Em 15 de novembro de 2022, as Nações Unidas anunciaram que a população da Terra ultrapassou oito bilhões de pessoas. Intuitivamente, sabemos que não pode haver tantos endereços postais. A diferença entre o número de nomes possíveis no planeta, e da mesma forma na internet, supera e deve ultrapassar o número de endereços disponíveis.
O segredo está nos nomes!
Agora que esses dois princípios relevantes sobre endereços de IP e nomes de DNS nos padrões internacionais estão compreendidos, que endereço de IP e nomes de domínio servem a propósitos distintos e não há relação de um para um entre os dois, um exame de um caso recente de bloqueio de conteúdo usando os endereços de IP podem ajudar a ver os motivos pelos quais isso é problemático. Veja, por exemplo, o incidente de bloqueio de IPs na Áustria no final de agosto de 2022. O objetivo era restringir o acesso a 14 domínios alvo, bloqueando 11 endereços de IP (fonte: RTR.Telekom. Postado pelo Internet Archive), a incompatibilidade entre esses dois números deveria ter sido um sinalizador de aviso de que o bloqueio de IPs podia não ter o efeito desejado.
Analogias e padrões internacionais podem explicar os motivos pelos quais o bloqueio de IPs deve ser evitado, mas podemos ver a escala do problema observando os dados em escala da internet. Para entender e explicar melhor a gravidade do bloqueio de IPs, decidimos gerar uma visão global de nomes de domínio e endereços de IP (agradecemos ao estagiário de pesquisa de PhD, Sudheesh Singanamalla, pelo esforço). Em setembro de 2022, usamos os arquivos de zona autoritativa para os domínios de nível superior (TLDs) .com, .net .info, e .org, juntamente com as listas de um milhão de sites principais, para encontrar um total de 255.315.270 nomes exclusivos. Em seguida, consultamos o DNS de cada uma das cinco regiões e registramos o conjunto de endereços de IP retornados. A tabela abaixo resume nossas conclusões:
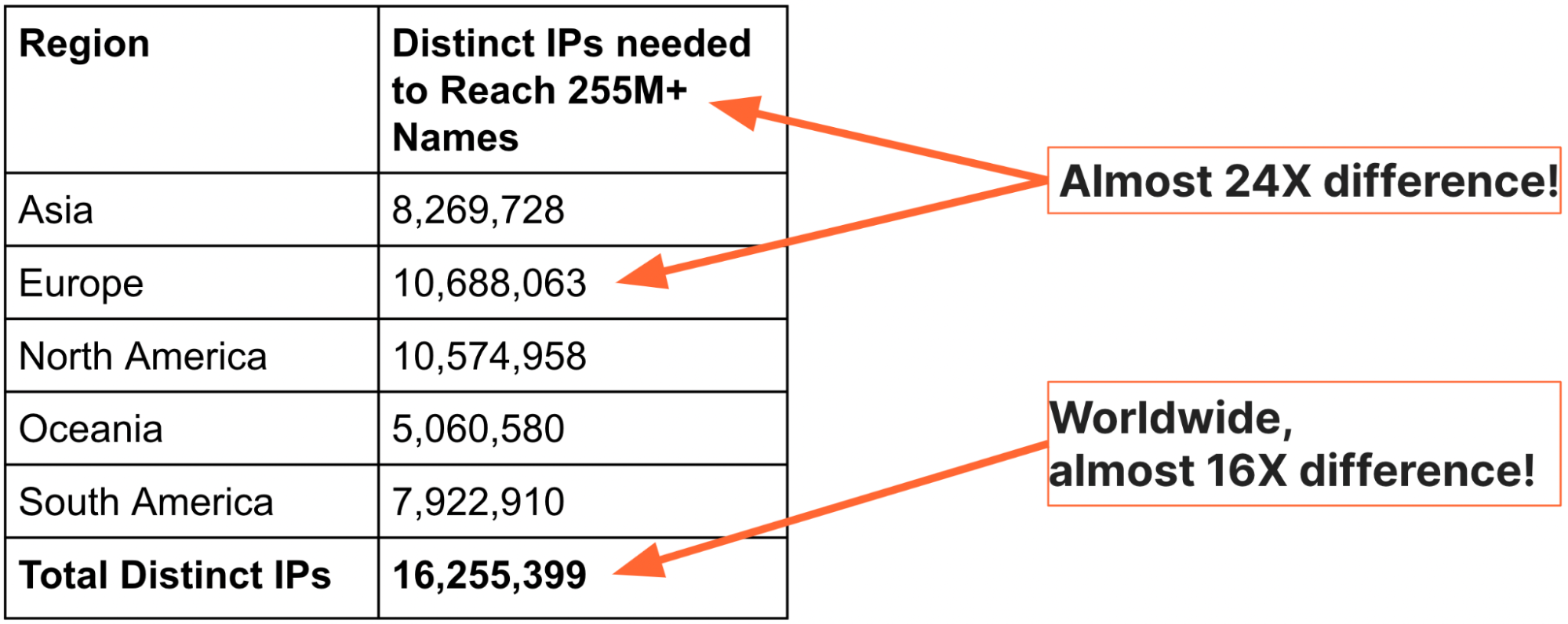
A tabela acima deixa claro que não são necessários mais de 10,7 milhões de endereços para alcançar 255.315.270 de nomes de qualquer região do planeta, e o conjunto total de endereços de IP para esses nomes de todos os lugares é de cerca de 16 milhões. A proporção de nomes para endereços de IP é quase 24x na Europa e 16x no mundo.
Há mais um detalhe interessante sobre os números acima: os endereços de IP são os totais combinados dos endereços IPv4 e IPv6, o que significa que muito menos endereços são necessários para acessar todos os 255 milhões de sites.
Também inspecionamos os dados de algumas maneiras diferentes para encontrar algumas observações interessantes. Por exemplo, a figura abaixo mostra a distribuição cumulativa (CDF) da proporção de sites que podem ser visitados com cada endereço de IP adicional. No eixo y está a proporção de sites que podem ser acessados com um determinado número de endereços de IP. No eixo x, os 16 milhões de endereços de IP são classificados do maior número de domínios à esquerda para o menor domínio à direita. Observe que qualquer endereço de IP neste conjunto é uma resposta do DNS e, portanto, deve ter pelo menos um nome de domínio, mas o maior número de domínios em endereços de IP no conjunto de números está na casa dos milhões de oito dígitos.
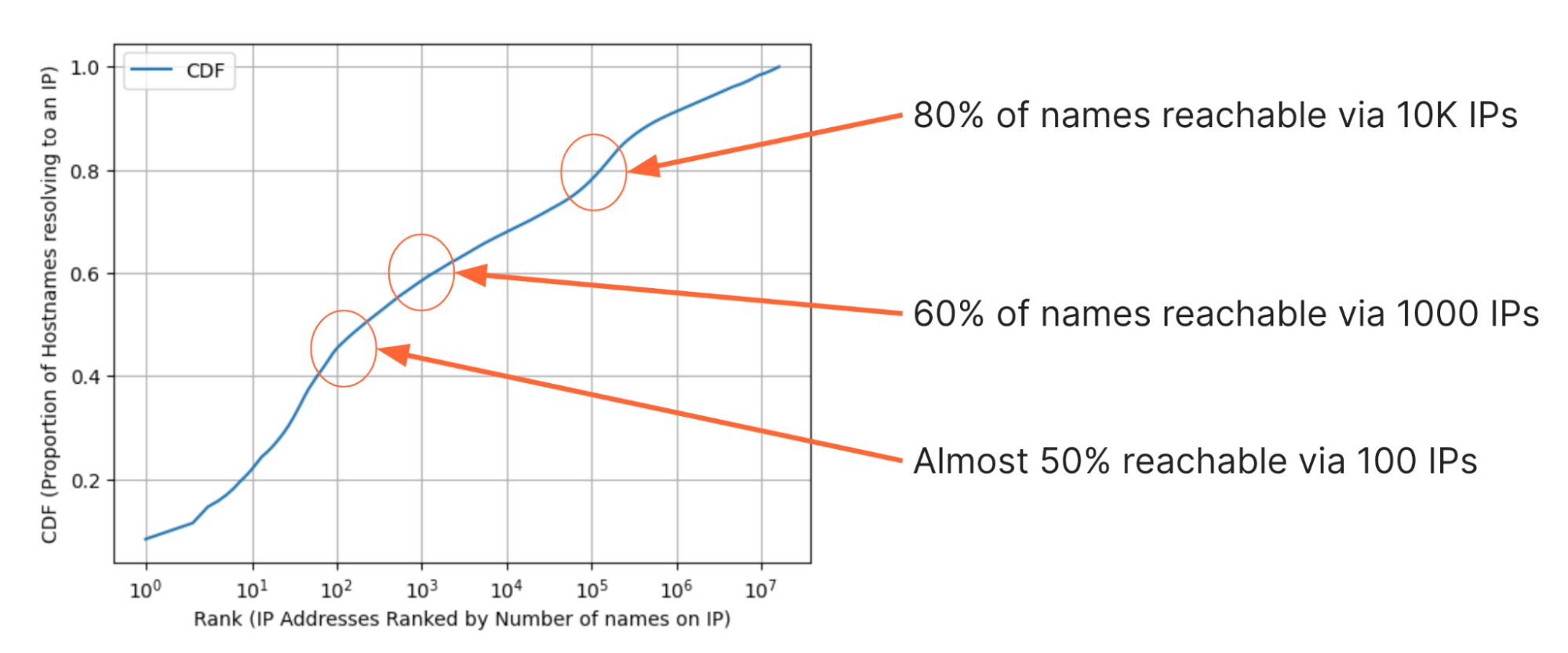
Ao analisar o CDF, há algumas observações interessantes:
- São necessários menos de 10 endereços de IP para atingir 20% ou aproximadamente 51 milhões de domínios do conjunto;
- Cem IPs são suficientes para atingir quase 50% dos domínios;
- Mil IPs são suficientes para atingir 60% dos domínios;
- Dez mil IPs são suficientes para atingir 80%, ou cerca de 204 milhões de domínios.
De fato, do conjunto total de 16 milhões de endereços, menos da metade, 7,1 milhões (43,7%), dos endereços no conjunto de dados tinham um nome. Sobre este "único" ponto, devemos ser claros: não podemos verificar se havia apenas um e nenhum outro nome nesses endereços porque há muito mais nomes de domínio do que aqueles contidos apenas em .com, .org, .info. , e .net. Pode muito bem haver outros nomes nesses endereços.
Além de ter vários domínios em um único endereço de IP, qualquer endereço de IP pode mudar ao longo do tempo para qualquer um desses domínios. A alteração periódica dos endereços de IP pode ser útil com certa segurança, desempenho e para melhorar a confiabilidade dos sites. Um exemplo comum em uso por muitas operações é o balanceamento de carga. Isso significa que as consultas de DNS podem retornar diferentes endereços de IP ao longo do tempo ou em locais diferentes para os mesmos sites. Esse é outro motivo separado pelo qual o bloqueio com base em endereços de IP não servirá ao propósito pretendido ao longo do tempo.
Em última análise, não há maneira confiável de saber o número de domínios em um endereço de IP sem inspecionar todos os nomes no DNS, de todos os locais do planeta, a cada momento. Uma proposição totalmente inviável.
Qualquer ação em um endereço de IP deve, pelas próprias definições dos protocolos que regem e capacitam a internet, ter efeitos colaterais.
Falta de transparência no bloqueio de IPs
Então, se temos que esperar que o bloqueio de um endereço de IP tenha efeitos colaterais, e é geralmente aceito que é inapropriado ou mesmo legalmente inadmissível bloquear endereços de IP com múltiplos domínios, por que isso ainda acontece? Isso é difícil de saber com certeza, então só podemos especular. Às vezes, reflete uma falta de compreensão técnica sobre os possíveis efeitos, principalmente de entidades como juízes que não são tecnólogos. Às vezes, os governos simplesmente ignoram os danos colaterais, como fazem com as interrupções da internet, porque consideram o bloqueio de seu interesse. E quando há dano colateral, geralmente não é óbvio para o mundo exterior, então pode haver muito pouca pressão externa para resolvê-lo.
Vale a pena enfatizar esse ponto. Quando um IP é bloqueado, os usuários notam apenas uma falha na conexão. Eles não sabem por que a conexão falhou ou quem causou a falha. Por outro lado, o servidor que age em nome do site nem sabe que foi bloqueado até começar a receber reclamações sobre o fato de estar indisponível. Praticamente não há transparência ou responsabilidade pelo overblocking. E pode ser desafiador, se não impossível, para o proprietário de um site contestar um bloqueio ou buscar reparação por ter sido bloqueado de forma inadequada.
Alguns governos, incluindo a Áustria, publicam listas de bloqueio ativas, o que é um passo importante para a transparência. Mas, por todos os motivos que discutimos, publicar um endereço de IP não revela todos os sites que podem ter sido bloqueados involuntariamente. E não dá aos afetados um meio de contestar o overblocking. Mais uma vez, no exemplo do mundo físico, é difícil imaginar uma ordem judicial em um arranha-céu que não fosse afixada na porta, mas muitas vezes parecemos pular esse devido processo legal e requisitos de notificação no espaço virtual.
Acreditamos que falar sobre as consequências problemáticas do bloqueio de IPs é mais importante do que nunca, pois um número crescente de países pressiona para bloquear conteúdo on-line. Infelizmente, os provedores costumam usar bloqueios de IP para implementar esses requisitos. Pode ser que o provedor seja mais novo ou menos robusto do que seus equivalentes maiores, mas provedores maiores também adotam a prática, e isso é compreensível porque o bloqueio de IPs exige menos esforço e está prontamente disponível na maioria dos equipamentos.
E à medida que mais e mais domínios são incluídos no mesmo número de endereços de IP, o problema só vai piorar.
Próximas etapas
Então, o que podemos fazer?
Acreditamos que o primeiro passo é melhorar a transparência em torno do uso do bloqueio de IPs. Embora não tenhamos conhecimento de nenhuma maneira abrangente de documentar os danos colaterais causados pelo bloqueio de IPs, acreditamos que há medidas que podemos tomar para expandir a conscientização sobre a prática. Estamos empenhados em trabalhar em novas iniciativas que destacam essas percepções, como fizemos com o Cloudflare Radar Outage Center.
Também reconhecemos que esse é um problema da internet e, portanto, deve fazer parte de um esforço mais amplo. A probabilidade significativa de que o bloqueio por endereço de IP resultará na restrição do acesso a toda uma série de domínios não relacionados (e não direcionados) deve torná-lo algo que não seja adotado por todos. É por isso que estamos nos envolvendo com parceiros da sociedade civil e empresas afins para dar sua opinião e contestar o uso do bloqueio de endereços de IP como forma de enfrentar os desafios de conteúdo e apontar danos colaterais quando eles os notarem.
Para ser claro, para enfrentar os desafios do conteúdo ilegal on-line, os países precisam de mecanismos legais que permitam a remoção ou restrição de conteúdo de uma forma que respeite os direitos. Acreditamos que abordar o conteúdo na fonte é quase sempre o melhor e o primeiro passo necessário. Leis como a nova Lei de Serviços Digitais da UE ou a Lei de Direitos Autorais do Milênio Digital fornecem ferramentas que podem ser usadas para lidar com conteúdo ilegal na fonte, respeitando princípios importantes do devido processo legal. Os governos devem se concentrar na criação e aplicação de mecanismos legais de forma que afetem menos os direitos de outras pessoas, de acordo com as expectativas dos direitos humanos.
De forma simples, essas necessidades não podem ser atendidas bloqueando endereços de IP.
Vamos continuar procurando novas maneiras de falar sobre atividades e interrupções de rede, principalmente quando isso resulta em limitações desnecessárias de acesso. Confira o Cloudflare Radar para obter mais informações sobre o que vemos on-line.