

Em grandes escalas operacionais, o endereçamento de IP emperra a inovação em serviços de rede e na web. Para cada mudança na arquitetura, e sem dúvida ao começar a projetar novos sistemas, somos forçados a fazer estas perguntas:
- Qual bloco de endereços de IP iremos ou podemos usar?
- Temos o suficiente em IPv4? Se não, onde e como vamos adquirir mais?
- Como usar endereços IPv6 e isso afeta outros usos do IPv6?
- E, por fim, em que devemos prestar mais atenção em termos de planos, controles, tempo e equipe para a migração?
Quando você para e se preocupa com endereços de IP, gasta tempo, dinheiro e recursos. Isso pode parecer surpreendente, porque o advento do IP, há mais de 40 anos, foi visionário e resiliente. Por design, os endereços de IP devem ser o último elo na cadeia de coisas com as quais uma rede precisa se preocupar. No entanto, se a Internet revelou algo, é que fragilidades pequenas ou supostamente sem importância (muitas vezes invisíveis ou impossíveis de detectar no momento do design) acabam sempre aparecendo em uma escala significativa.
Uma das coisas de que temos certeza, entretanto, é que "mais endereços" nunca deve ser a resposta. No IPv4, esse tipo de raciocínio só pode levar à sua escassez e à disparada dos preços de mercado. O formato IPv6 é absolutamente necessário, mas é apenas parte da solução. Por exemplo, no IPv6, a boa prática estipula que a menor alocação, reservada somente para uso pessoal, é /56, ou seja, 272 ou cerca de 4.722.000.000.000.000.000.000 de endereços. Pessoalmente, não consigo pensar em números tão grandes. E você?
Nesta postagem do blog, vamos explicar porque o endereço de IP é um problema para serviços da web, bem como as causas estruturais desse problema. Além disso, vamos descrever uma solução inovadora que chamamos de "Agilidade de Endereçamento", bem como as lições que aprendemos. A melhor parte dessa abordagem é a variedade de novos sistemas e arquiteturas que a Agilidade de Endereçamento torna possível. Todos os detalhes estão disponíveis em nosso artigo mais recente, da ACM SIGCOMM 2021. Confira um resumo do que aprendemos:

É verdade! Não há limite para o número de nomes que podem aparecer em um determinado endereço. O endereço de qualquer nome pode mudar a cada nova consulta, em qualquer lugar. Da mesma forma, os endereços podem ser alterados por qualquer motivo, seja para a prestação de um serviço, política, avaliação de desempenho ou qualquer outro caso ainda não encontrado…
Veja a seguir uma explicação dos princípios em ação por trás de todas essas realizações, como raciocinamos nesta área e por que essas lições são importantes para serviços HTTP e TLS de qualquer tamanho. O principal insight sobre o qual estamos desenvolvendo todo o nosso pensamento é: assim como no sistema de correios, de acordo com o design do protocolo da Internet (IP, na sigla em inglês), um endereço nunca tem, nunca deve e nunca precisa representar nomes. Mas, às vezes, atribuímos essas responsabilidades aos endereços. Em vez disso, este estudo mostra que todos os nomes devem compartilhar seu conjunto de endereços, um determinado conjunto de endereços ou até mesmo um único endereço.
Essa "camisa de força" é um funil e também um gargalo
Convenções criadas há muitas décadas associam artificialmente os endereços de IP a nomes e recursos. Isso é compreensível, porque a arquitetura e o software que impulsionam a Internet são o resultado de um design em que um computador tinha um nome e (na maioria das vezes) uma placa de interface de rede. Portanto, seria natural que a Internet evoluísse de tal modo que um determinado endereço de IP fosse vinculado a nomes e processos de software.
Essas vinculações de IP têm pouco impacto sobre os clientes finais e operadoras de rede, que não precisam de nomes e menos ainda de processos de escuta. No entanto, as convenções de nomes e processos criam fortes limitações para todos os provedores de serviços de hospedagem, distribuição e conteúdo (CSPs). Uma vez atribuídos a nomes, interfaces e soquetes, os endereços se tornam inerentemente estáticos e qualquer mudança neles requer esforço, planejamento e atenção, se é que uma mudança é possível.
Essa "camisa de força" do IP permitiu o desenvolvimento da Internet, mas como o TCP para protocolos de transporte e o HTTP para protocolos de aplicativo, o protocolo IP se transformou em um freio à inovação. Essa ideia é representada pela figura abaixo, em que podemos ver o estabelecimento de relações transitivas entre vinculações de comunicação (com nomes) e vinculações de conexão (com interfaces e soquetes) que antes ficavam separados.
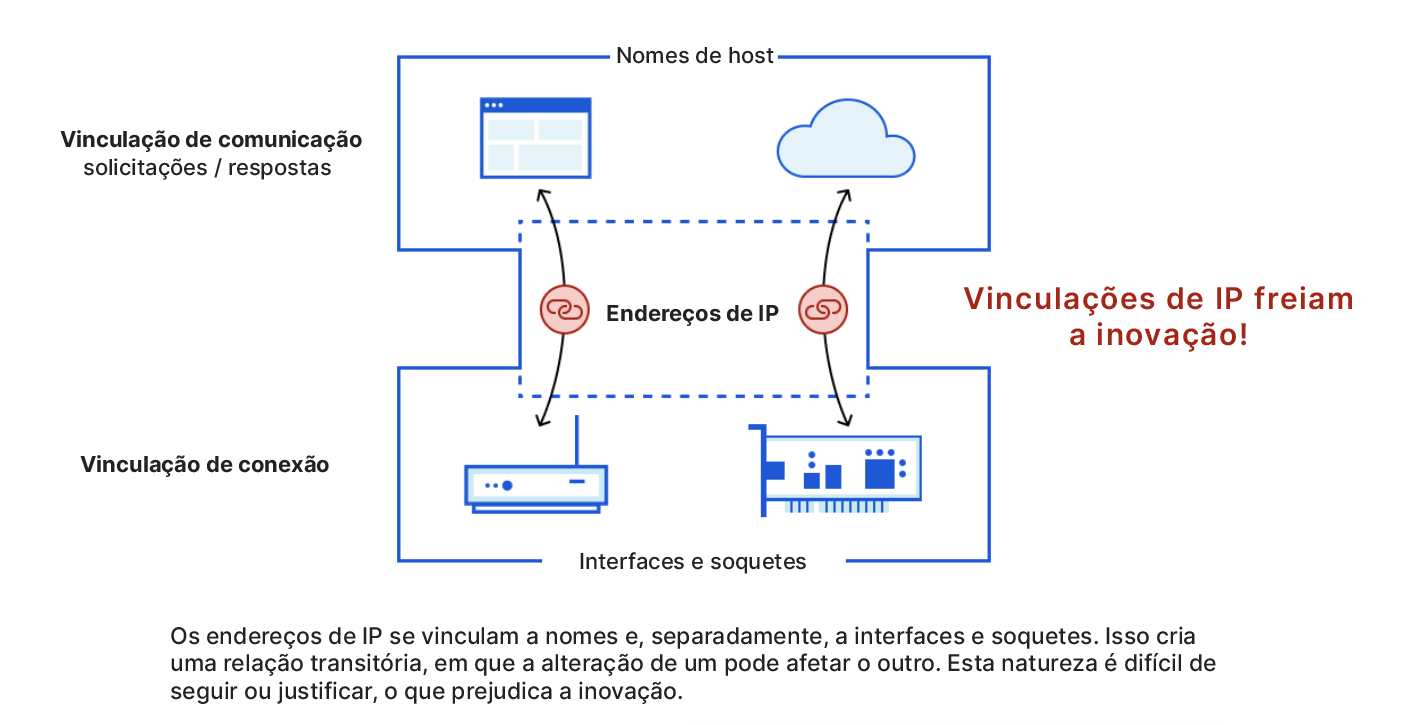
É difícil desfazer esse bloqueio transitivo, porque alterar um dos dois elementos pode afetar o outro. Além disso, os provedores de serviços costumam usar endereços de IP para representar políticas e níveis de serviço que existem por si próprios, independentemente dos nomes. Em última análise, as vinculações de IP são um novo elemento a ser levado em consideração — e por um motivo ruim.
Vamos olhar essa questão de outro ângulo. Ao pensar em novos designs, novas arquiteturas ou simplesmente melhores maneiras de alocar recursos, as primeiras perguntas a serem feitas não devem ser "Quais endereços de IP vamos usar?" ou "Temos os endereços de IP para fazer isso?". Esse tipo de questionamento e as respostas associadas a ele dificultam o desenvolvimento e a inovação.
Percebemos que as vinculações de IP não eram somente artificiais, mas também se mostraram incorretas, do ponto de vista das RFCs e dos padrões originais. Na verdade, a própria noção de um endereço de IP como parte de uma representação de qualquer coisa que não seja acessibilidade vai contra sua concepção original. No RFC original e documentos relacionados, os arquitetos são muito claros: "Uma distinção deve ser feita entre nomes, endereços e rotas. Um nome designa o elemento que observamos. O endereço indica onde este elemento está localizado. A rota mostra como chegar a esse local". Qualquer associação de informações ao IP, como SNI ou host HTTP nos protocolos de camada superior é uma nítida violação do princípio de camadas.
Claro, nosso trabalho não existe de maneira isolada. No entanto, ele encerra um longo processo evolutivo que visa desassociar os endereços de IP de seu uso convencional, uma evolução que, em última instância, consiste em desenvolver nosso próprio conhecimento.
Uma evolução do passado…
Olhando para os últimos 20 anos, podemos ver que essa busca por agilidade no endereçamento acontece há algum tempo, e que a Cloudflare está muito envolvida na questão.
A vinculação um para um entre o IP e as interfaces da placa de rede já é antiga e foi quebrada pela primeira vez há alguns anos, quando o projeto Maglev do Google combinou a estratégia de roteamento de vários caminhos de custo igual (ECMP, na sigla em inglês) com um hash constante para disseminar o tráfego proveniente de um endereço de IP "virtual" entre vários servidores. Como anedota, de acordo com os RFCs originais do protocolo da Internet, esse uso do IP é proibido e nada virtual.
Muitos sistemas semelhantes surgiram desde então no GitHub, no Facebook e em outros lugares, incluindo nossa própria solução, o Unimog. Mais recentemente, a Cloudflare projetou uma nova arquitetura de soquetes programáveis chamada bpf_sk_lookup para desassociar endereços de IP de soquetes e processos.
Mas e os nomes? O conceito de "hospedagem virtual" foi estabelecido em 1997, quando o HTTP 1.1 definiu o campo host como obrigatório. Esse foi o primeiro reconhecimento oficial de que vários nomes poderem coexistir no mesmo endereço de IP, constatação necessariamente reproduzida pelo TLS no campo Indicação de Nome do Servidor. São requisitos absolutos, porque o número de nomes possíveis é maior do que o número de endereços de IP.
…revela um futuro Ágil
Em perspectiva, a pergunta de Shakespeare "O que é que há, pois, num nome?" acaba sendo particularmente astuta. Se a Internet pudesse falar, diria: "Este nome pelo qual caracterizamos um endereço seria tão acessível quanto qualquer outro".
Se Shakespeare tivesse perguntado em vez disso, "O que há em um endereço?", a Internet certamente responderia do mesmo jeito "Este nome pelo qual caracterizamos um endereço seria tão acessível quanto qualquer outro".
Uma forte conclusão surge da verdade dessas respostas: o mapeamento entre nomes e endereços é realizado ponto a ponto (any-to-any). Se isso for verdade, qualquer endereço pode ser usado para acessar um nome, desde que esse nome possa ser acessado em um endereço.
Na verdade, uma versão do formato "vários endereços para um nome" está disponível desde 1995 com a introdução do balanceamento de carga baseado em DNS. Então, por que não "todos os endereços para todos os nomes" ou "qualquer endereço a qualquer momento para todos os nomes"? Ou (como descobriremos em breve) "um endereço para todos os nomes"! Mas vamos primeiro discutir como alcançar Agilidade de Endereçamento.
Para ter Agilidade de Endereçamento: ignore nomes, mapeie políticas
O segredo da Agilidade de Endereçamento está no DNS autoritativo, mas não nos mapeamentos estáticos "nome para IP" armazenados em um registro ou tabela de pesquisa. Considere que, do ponto de vista do cliente, a vinculação só aparece "mediante consulta". Para todos os fins práticos de mapeamento, a resposta à consulta é o último momento em que um nome pode ser vinculado a um endereço durante o ciclo de vida de uma solicitação.
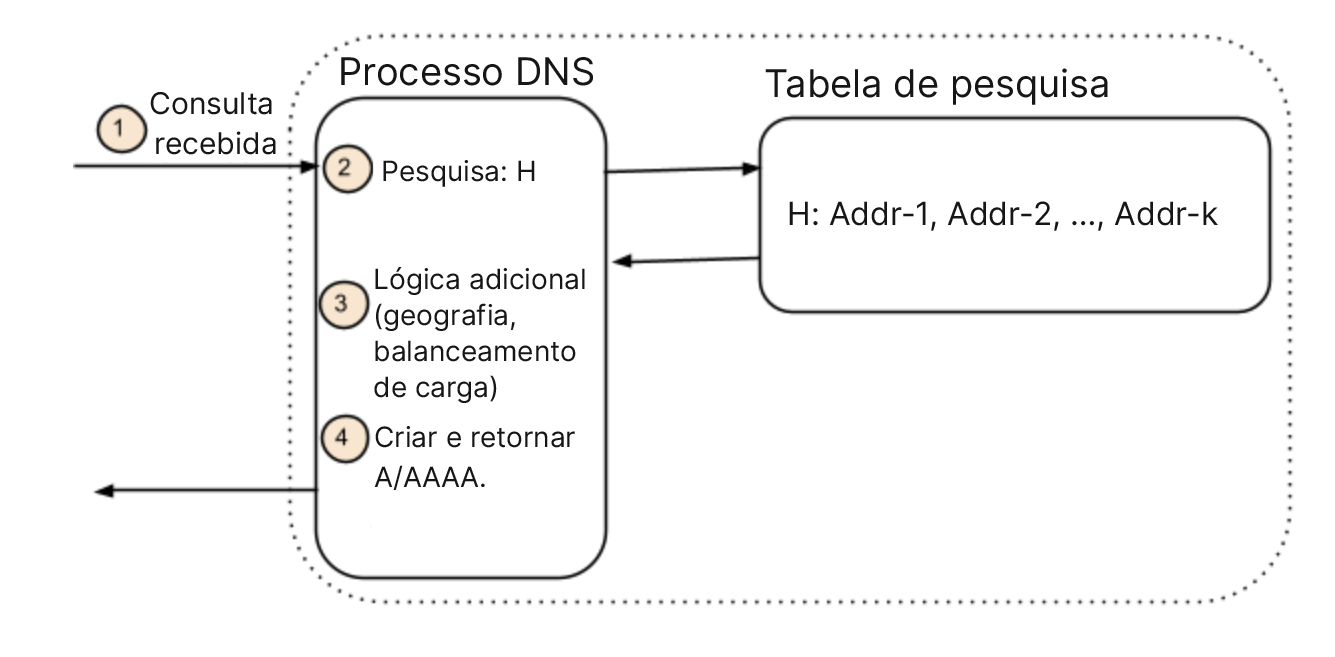
Assim, concluímos que os mapeamentos de nomes são criados no momento em que a resposta é retornada, e não em um arquivo de registro ou zona. É uma diferença sutil, mas importante. Os sistemas DNS de hoje usam um nome para pesquisar um conjunto de endereços e, às vezes, usam políticas para decidir qual endereço retornar. O conceito é mostrado na figura abaixo. Quando uma consulta é recebida, os endereços associados ao nome são revelados e um ou mais desses endereços são retornados. Muitas vezes, outros filtros de política ou lógica são usados para restringir a seleção de endereços, como o nível de serviço ou a cobertura geográfica. É importante que os endereços sejam primeiro identificados com um nome e que as políticas só sejam aplicadas depois.
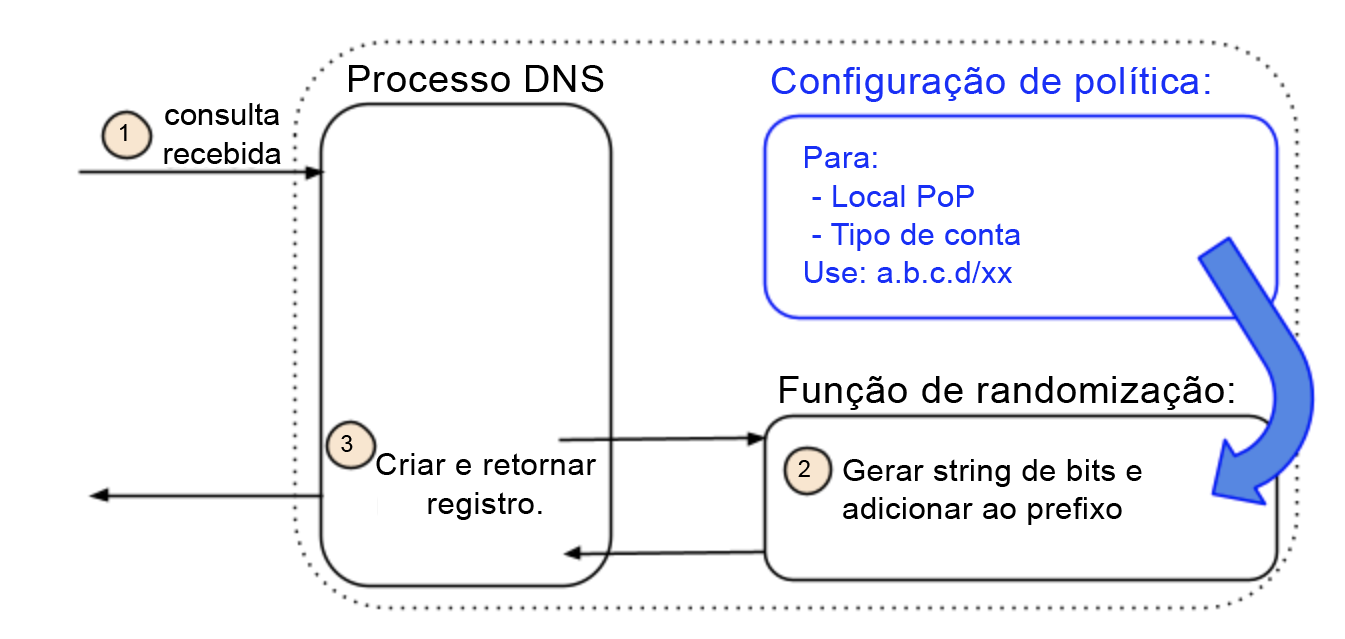
A Agilidade de Endereçamento é conquistada ao inverter essa relação. Em vez de endereços de IP já atribuídos a um nome, nossa arquitetura começa com uma política que pode (ou não, em nosso caso) incluir um nome. Por exemplo, uma política pode ser representada por atributos como local e tipo de conta, enquanto o nome é ignorado (o que fizemos quando o implantamos). Os atributos identificam um pool de endereços associados a esta política. O próprio pool pode ser isolado a esta política ou ter elementos em comum com outros pools e políticas. Além disso, todos os endereços no pool são equivalentes. Isso significa que qualquer endereço pode ser retornado ou mesmo selecionado aleatoriamente sem verificar o nome da consulta DNS.
Agora pare por um momento, pois há duas conclusões muito notáveis que emergem das respostas por consulta:
i. Os endereços de IP podem ser (e são) calculados e atribuídos em tempo de execução ou tempo de consulta.
ii. O ciclo de vida do mapeamento de IP para nome corresponde à duração da conexão subsequente ou ao TTL em caches downstream — o que for maior.
O resultado é impressionante, o que significa que a vinculação em si é efêmera e pode ser alterada independentemente de vinculações, resolvedores, clientes ou objetivos anteriores. A escala também não é um problema, e sabemos disso porque implantamos na borda.
IPv6 — a roupa nova do imperador
Antes de falarmos sobre nossa implementação, vamos primeiro abordar o IPv6. Em primeiro lugar, deve ficar claro que tudo — tudo — que foi discutido aqui em relação ao IPv4 também se aplica ao IPv6. Assim como no sistema mundial de correios, endereços são endereços, seja em Camarões, no Camboja, no Canadá, no Chile ou na China — e isso inclui sua natureza relativamente estática e inflexível.
Apesar da equivalência, a questão óbvia permanece: todas as razões para buscar Agilidade de Endereçamento não foram alcançadas com a mudança para o IPv6? Por mais absurda que seja, a resposta é um não absoluto e retumbante! O IPv6 pode mitigar o esgotamento de endereços, pelo menos durante a vida de todas as pessoas vivas hoje, mas a abundância de prefixos e endereços IPv6 torna difícil pensar em vincular nomes e recursos.
A abundância de endereços IPv6 também acarreta o risco de ineficiência, uma vez que as operadoras podem usar o tamanho do bit e os grandes tamanhos de prefixo para inserir um significado no endereço de IP. Esse é um recurso poderoso do IPv6, mas também significa que muitos, muitos endereços em cada prefixo não são usados.
Para ser claro: a Cloudflare é comprovadamente uma das maiores defensoras do IPv6, e por bons motivos, até porque a abundância de endereços garante longevidade. Ainda assim, o IPv6 muda pouco a maneira como os endereços são vinculados a nomes e recursos, enquanto a Agilidade de Endereçamento garante flexibilidade e capacidade de resposta em todo o seu ciclo de vida.
Uma observação: agilidade é para todos
Uma última observação sobre a arquitetura e sua transferibilidade — Agilidade de Endereçamento é útil, até mesmo desejável, para qualquer serviço que opere DNS autoritativo. Outros provedores de serviços de conteúdo são concorrentes óbvios, mas operadores menores também são. Universidades, empresas e agências governamentais são apenas alguns exemplos de organizações que podem realizar seus próprios serviços autoritativos. Enquanto os operadores puderem aceitar conexões por meio dos endereços de IP retornados, todos serão potenciais beneficiários da Agilidade de Endereçamento.
Endereços aleatórios baseados em políticas — em escala
Desde junho de 2020, trabalhamos com Agilidade de Endereçamento no tráfego de produção ativo na borda, da seguinte maneira:
- Mais de 20 milhões nomes de host e serviços
- Todos os data centers no Canadá (com uma população razoável e vários fusos horários)
- /20 (4.096 endereços) em IPv4 e /44 em IPv6
- /24 (256 endereços) em IPv4 de janeiro a junho de 2021
- Uma seção de host aleatória dentro do prefixo gerada para cada consulta
Afinal, o verdadeiro teste de agilidade atinge seu limite máximo quando um endereço aleatório é gerado para cada consulta que chega aos nossos servidores. Em seguida, decidimos testar a ideia. Em junho de 2021, em nosso data center de Montreal e logo após no de Toronto, todas as mais de 20 milhões de zonas foram atribuídas a um único endereço.
Ao longo de um ano, cada consulta para um domínio coberto pela política recebeu um endereço aleatório — primeiro 4.096, depois 256 e, finalmente, um. Internamente, chamamos o conjunto de endereços de um como Ao1, mas falaremos sobre ele mais adiante.
A medida do sucesso: "Não há nada para ver aqui"
Pode haver uma série de perguntas que nossos leitores se fazem silenciosamente:
- O que isso quebrou na Internet?
- Como isso afetou os sistemas da Cloudflare?
- O que eu faria, se pudesse?
A resposta mais fácil para as perguntas acima é: nada. Mas — e isso é importante — a randomização de endereços revela os pontos fracos no design de sistemas que dependem da Internet. As vulnerabilidades sempre ocorrem (cada uma!) porque os desenvolvedores atribuem um significado diferente aos endereços de IP, que vai além da acessibilidade. E cada uma dessas vulnerabilidades é contornada, mesmo que de forma aleatória, com o uso de um endereço, ou "Ao1").
Para entender melhor a natureza do "nada", devemos responder às perguntas acima da última para a primeira.
O que eu faria, se pudesse?
A resposta é mostrada no exemplo da figura a seguir. Em todos os data centers no "resto do mundo" fora de nossa implementação, uma consulta para uma zona retorna os mesmos endereços (este é o sistema Anycast global da Cloudflare). Em contraste, toda consulta que chega a um data center de implementação recebe um endereço aleatório. Isso pode ser visto abaixo em comandos dig consecutivos para dois data centers diferentes.
Caso você esteja pensando no tráfego de solicitações abaixo: sim, isso significa que os servidores estão configurad
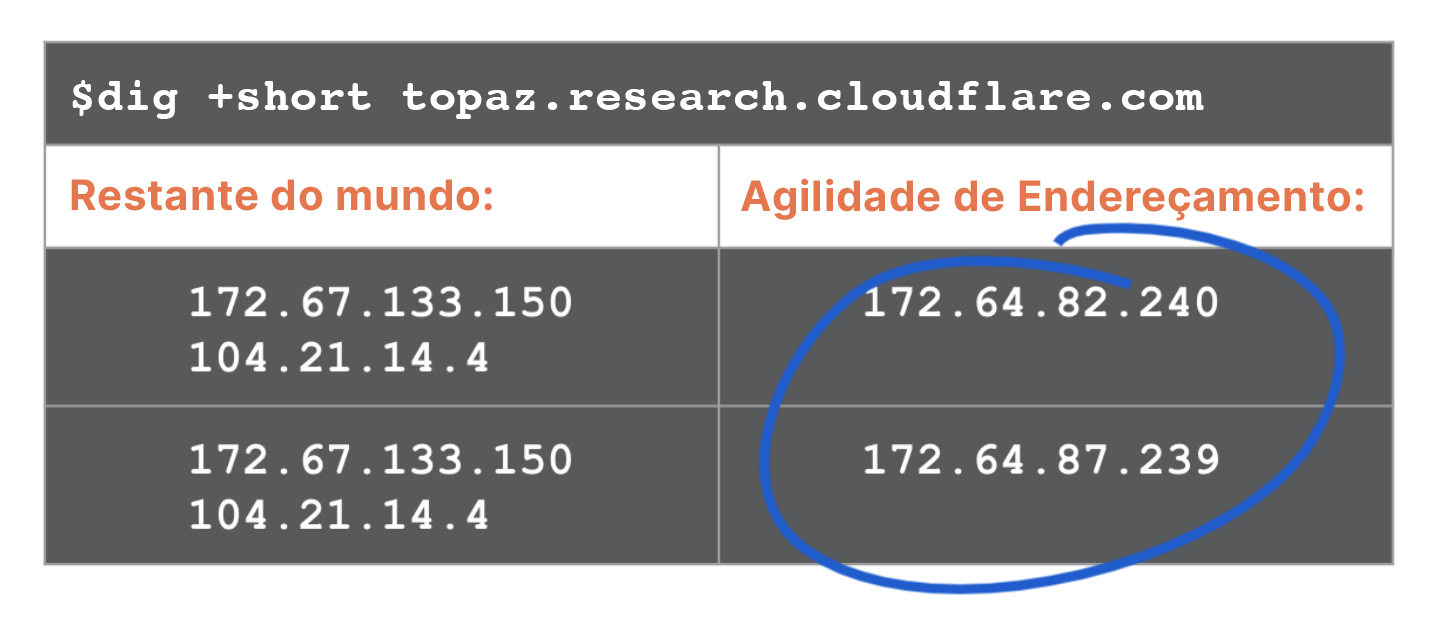
os para aceitar solicitações de conexão de qualquer um dos mais de 20 milhões de domínios em todos os endereços no pool de endereços.
Tudo bem, mas certamente os sistemas circundantes da Cloudflare tiveram que ser alterados?
Não. Esta é uma mudança transparente no pipeline de dados para DNS autoritativo. Todos os anúncios de prefixo de roteamento em BGP, DDoS, balanceadores de carga, cache distribuído etc. não precisaram ser alterados.
No entanto, há um efeito colateral fascinante: a randomização é para endereços de IP o que uma boa função hash é para uma tabela hash — atribui uma entrada de qualquer tamanho uniformemente a um número fixo de saídas. O efeito fica claro ao observar a carga por IP antes e depois da randomização, conforme mostrado nos gráficos abaixo, onde os dados vêm de 1% da amostra de solicitações em um data center em sete dias.
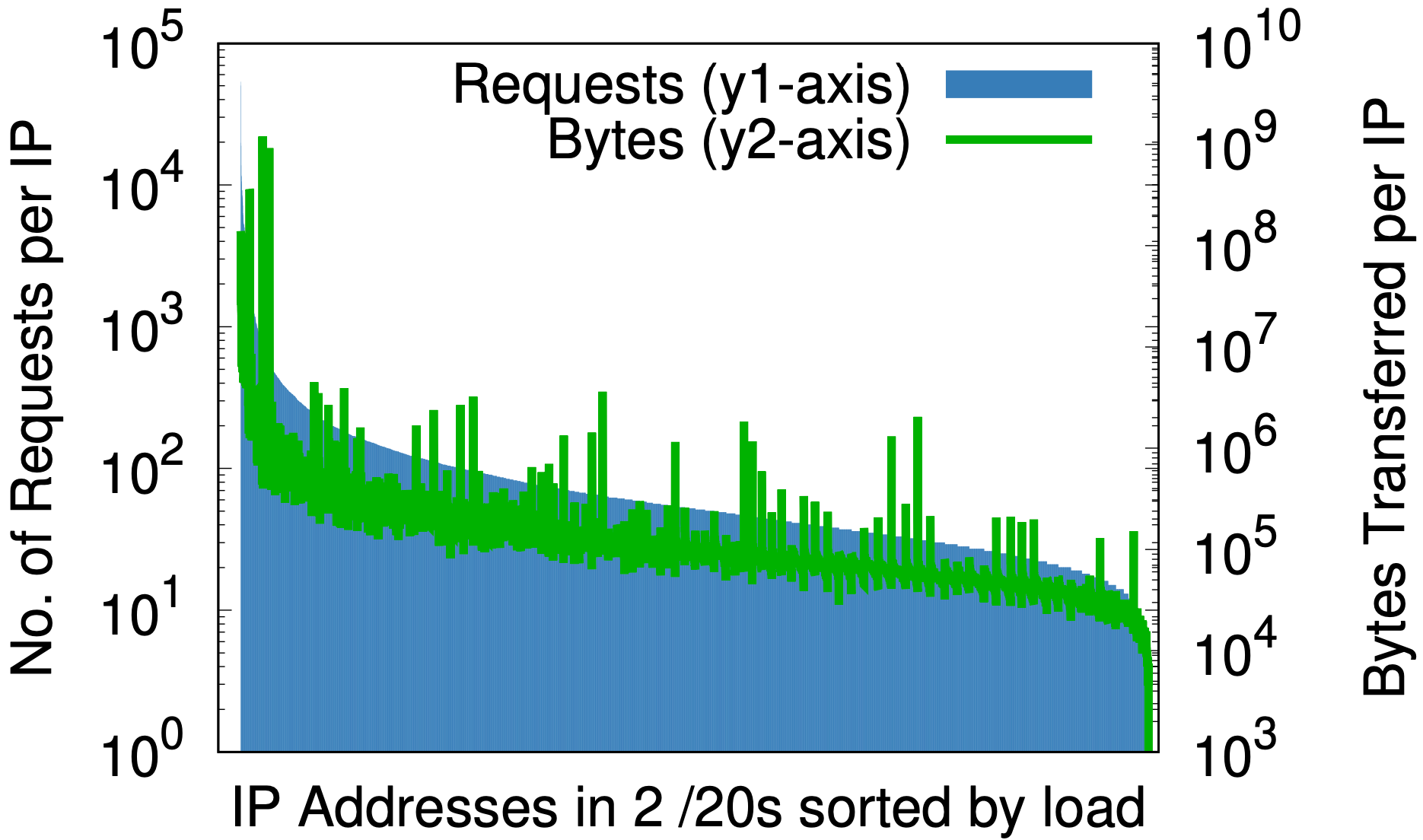
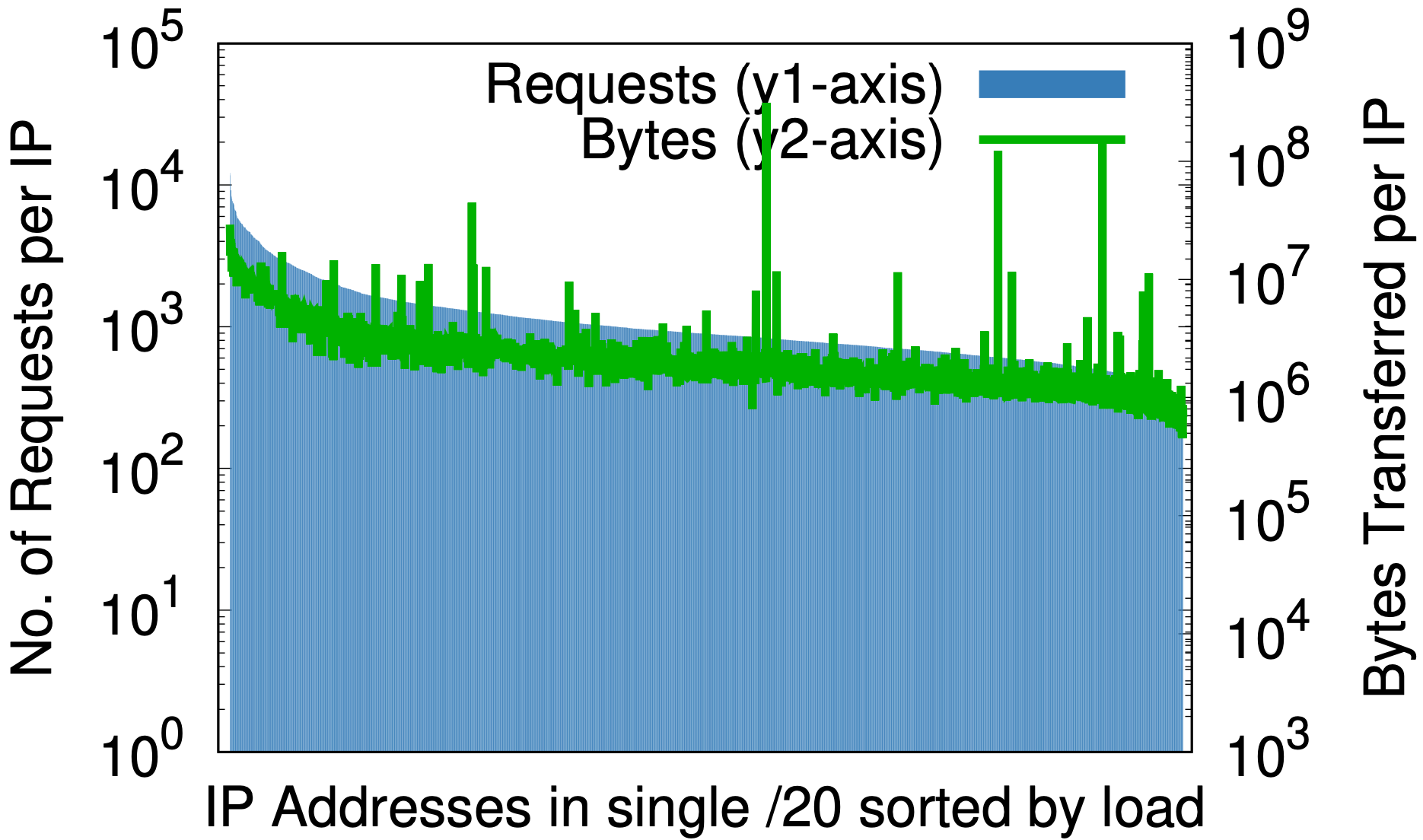
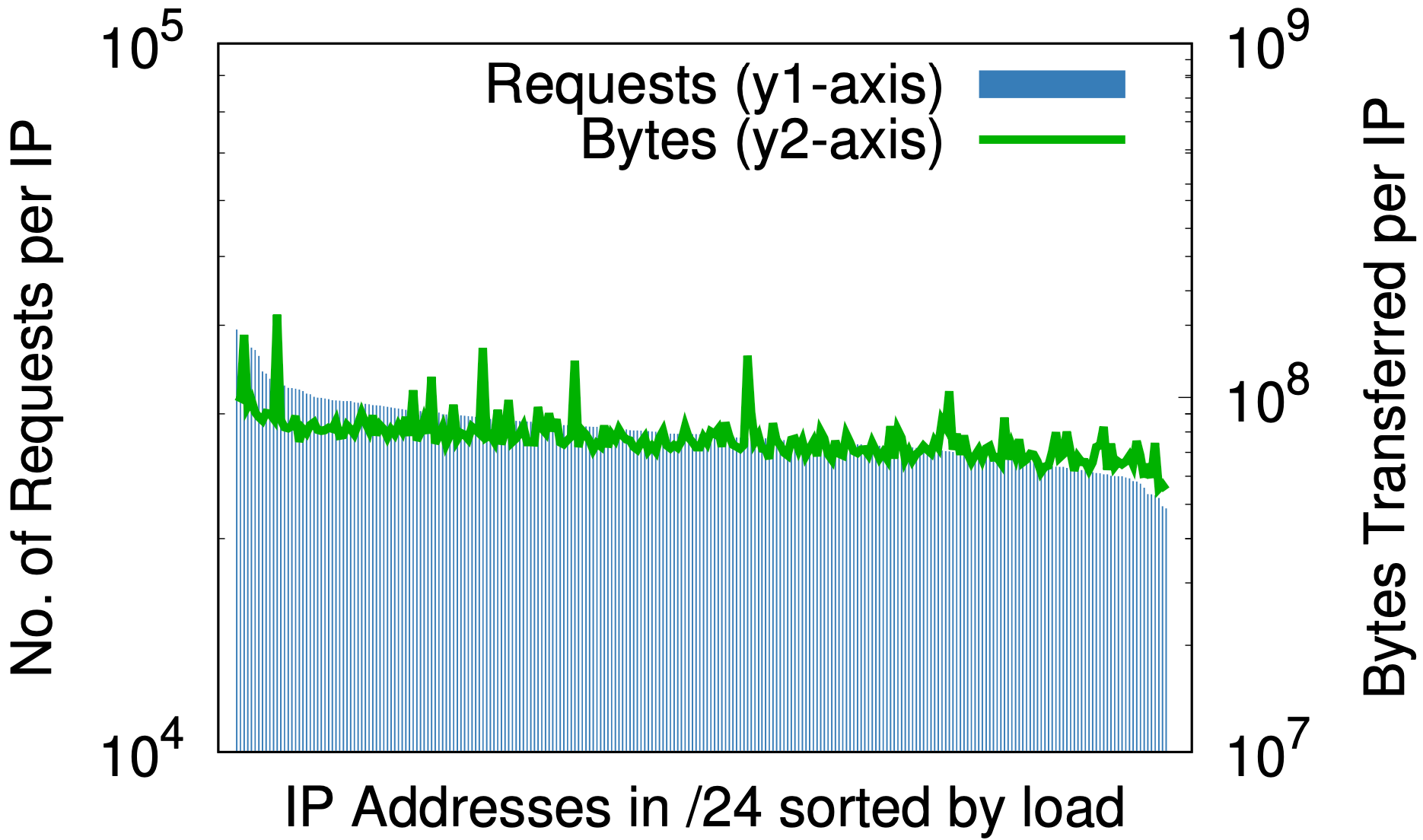
Antes da randomização, em apenas uma pequena parte do espaço de IP da Cloudflare, (a) a diferença entre o maior e o menor número de solicitações por IP (eixo y1 à esquerda) é de três classes de tamanho; da mesma forma, a diferença em bytes por IP (eixo y2 à direita) é de quase seis classes de tamanho. Após a randomização, (b) em todas as áreas em um único /20 que anteriormente ocupavam vários /20, houve uma redução de duas ou três classes de tamanho. Já em /24, (c) a randomização por consulta de mais de 20 milhões de zonas para 256 endereços reduz as diferenças na carga a pequenos fatores constantes.
Isso pode ser importante para qualquer provedor de serviços de conteúdo que considere o provisionamento de recursos por endereço de IP. Pode ser difícil prever a priori a carga gerada por um cliente. Os gráficos acima mostram que a melhor maneira é atribuir todos os endereços a todos os nomes.
Certamente isso leva a interrupções na Internet como um todo, não é?
Também não. Bem, para ser mais preciso: "Não, a randomização não interrompe nada… mas pode revelar os pontos fracos dos sistemas e seus designs".
Todo sistema que pode ser afetado pela randomização de endereço parece ter um pré-requisito: o endereço de IP recebe um significado que vai além da mera acessibilidade. A Agilidade de Endereçamento retém e até recupera a semântica dos endereços de IP e da arquitetura central da Internet, mas impede que os sistemas de software façam suposições sobre seu significado.
Primeiro, vamos ver alguns exemplos e por que eles não importam. Em seguida, faça uma pequena mudança na Agilidade de Endereçamento que contorna as vulnerabilidades (usando um único endereço de IP):
- A união de conexões HTTP permite que um cliente reutilize conexões existentes para solicitar recursos de diferentes origens. Clientes como o Firefox, que permitem uma união quando a autoridade do URI corresponde à conexão, não são afetados. No entanto, os clientes que solicitarem que um host URI resolva para o mesmo endereço de IP da conexão especificada falharão.
- Serviços não baseados em TLS ou HTTP podem ser afetados. Um exemplo é o ssh, que gerencia uma atribuição de nomes de host a endereços de IP em known_hosts. Essa associação é compreensível, mas desatualizada, pois muitos registros de DNS atualmente geram mais de um endereço de IP.
- Os certificados TLS não SNI exigem seu próprio endereço IP. Os provedores são forçados a cobrar uma sobretaxa porque cada endereço só é compatível com um único certificado sem SNI. Independentemente do IP, o maior problema é usar TLS sem um SNI. Iniciamos esforços para entender os que não usam SNI e esperamos que esse infeliz legado chegue ao fim.
- As proteções contra DDoS que dependem de IPs de destino podem ser prejudicadas inicialmente. Acreditamos que a Agilidade de Endereçamento é benéfica por dois motivos. Em primeiro lugar, a randomização de IP distribui a carga de ataque por todos os endereços usados, atuando efetivamente como um balanceador de carga da Camada 3. Em segundo lugar, as mitigações de DoS geralmente funcionam com a alteração dos endereços de IP — uma habilidade que está incluída na Agilidade de Endereçamento.
Um por todos, e todos por um
Começamos com mais de 20 milhões de zonas vinculadas a dezenas de milhares de endereços e os provisionamos com êxito 4.096 endereços em um /20 e 256 endereços em um /24. Esta tendência certamente levanta a seguinte questão:
Se a randomização funciona em n endereços, por que não funciona em 1 endereço?
É mesmo. Por que não? Lembre-se da observação acima sobre a randomização em IPs, que corresponde a uma função de hash perfeita em uma tabela de hash. O legal das estruturas hash bem projetadas é que elas retêm suas propriedades em qualquer tamanho de estrutura, mesmo que o tamanho seja de 1. Essa redução seria um verdadeiro teste das premissas sobre as quais a Agilidade de Endereçamento se desenvolve.
É por isso que conduzimos um teste. De um conjunto de endereços /20, para um /24 e, a partir de junho de 2021, para um conjunto de endereços de 1 a /32, e equivalente a /128 (Ao1). Funcionou. E funcionou muito bem. O Ao1 elimina todas preocupações que possam surgir com a randomização. Por exemplo, serviços não TLS ou não HTTP têm um endereço de IP confiável (ou pelo menos um não aleatório e até que a política de nomenclatura seja alterada). Além disso, a união de conexões HTTP também falha por si só e, sim, vemos um nível maior de união quando Ao1 é usado.
Mas por que no IPv6, onde existem tantos endereços?
Um argumento contra a vinculação a um único endereço IPv6 é que isso não é necessário, porque é improvável que os endereços se esgotem. Este é um posicionamento pré-CIDR que acreditamos ser benigno na melhor das hipóteses e irresponsável na pior. Conforme mencionado anteriormente, o número de endereços IPv6 torna difícil o julgamento. Em vez de perguntar por que um único endereço IPv6 deve ser usado, devemos perguntar: "Por que não?".
Existem efeitos upstream? Sim, e oportunidades!
O Ao1 revela um conjunto totalmente diferente de efeitos de randomização de IP, o que sem dúvida nos dá um vislumbre do futuro do roteamento e acessibilidade da Internet, amplificando os efeitos de atos aparentemente pequenos.
Por quê? O número de nomes de comprimento variável possíveis no universo sempre será maior do que o número de endereços de comprimento fixo. Isso significa que, de acordo com o princípio da casa dos pombos, um único endereço de IP deve ser compartilhado por vários nomes e diferentes conteúdos de partes não relacionadas.
Vale a pena falar sobre os possíveis efeitos upstream amplificados pelo Ao1, descritos abaixo. Até agora, no entanto, não encontramos nenhum desses problemas em nossas avaliações ou na comunicação com as redes upstream.
- Os erros de roteamento upstream são imediatos e totais. Se todo o tráfego chegar a um único endereço (ou prefixo), os erros de roteamento upstream afetarão todo o conteúdo igualmente. (Este é o motivo pelo qual a Cloudflare retorna dois endereços em intervalos de endereços não contíguos.) No entanto, o mesmo se aplica ao bloqueio de ameaças.
- Medidas de proteção contra DoS upstream podem ser acionadas. É concebível que a concentração de solicitações e tráfego em um único endereço upstream seja percebida como um ataque DoS e desencadeie as medidas de proteção que possam estar em vigor.
Em ambos os casos, as medidas são mitigadas pela capacidade da Agilidade de Endereçamento de alterar endereços em massa e rapidamente. A prevenção também é possível, mas requer comunicação e discurso abertos.
Um último efeito upstream permanece:
- O esgotamento de portas no IPv4 NAT pode ser acelerado e é resolvido pelo IPv6! Do lado do cliente, o número de conexões simultâneas permitidas para um endereço é limitado pelo tamanho do campo de porta do protocolo de transporte, por exemplo, cerca de 65 mil para TCP.
Com o TCP no Linux, por exemplo, isso era um problema até recentemente. (Veja este commit e SO_BIND_ADDRESS_NO_PORT na página de manual ip(7) man page.) O problema persiste com UDP. No QUIC, os identificadores de conexão podem evitar o esgotamento de portas, mas devem ser usados. No entanto, até agora não vimos qualquer indicação de que isso seja um problema.
Mesmo assim — e esta é a melhor parte —, até onde sabemos, esse é o único risco de usar um único endereço e a mudança para o IPv6 irá corrigi-lo imediatamente. (Portanto, ISPs e administradores de rede, não se enganem e implementem o IPv6!)
Estamos só começando!
E terminamos da mesma forma que começamos. O que você conseguiria desenvolver se não houvesse um limite máximo para o número de nomes em um único endereço de IP e existisse a capacidade de alterar o endereço por qualquer motivo mediante solicitação?

Na verdade, estamos apenas no começo! A flexibilidade e sustentabilidade possibilitadas pela Agilidade de Endereçamento nos dá a oportunidade de imaginar, projetar e construir novos sistemas e arquiteturas. Planejamos a detecção e mitigação de vazamento na rota BGP para sistemas Anycast, plataformas de medição e muito mais.
Para saber mais detalhes técnicos sobre todos os itens acima, bem como agradecer todos que ajudaram a tornar isso possível, consulte este artigo e uma breve conversa. Mesmo com essas novas possibilidades, os desafios permanecem. Existem muitas questões em aberto, incluindo, entre outros, o seguinte:
- Quais políticas podem ser formuladas ou implementadas com sensatez?
- Existe alguma sintaxe ou gramática abstrata que pode ser usada para expressá-las?
- Podemos usar métodos formais e verificação para prevenir políticas errôneas ou conflitantes?
A Agilidade de Endereçamento é para todos e é necessária para que essas ideias tenham sucesso em uma escala mais ampla. Aguardamos sugestões e ideias em [email protected].
Se você é um aluno matriculado em um programa de doutorado ou de pesquisa equivalente e está procurando um estágio nos EUA ou no Canadá ou na UE ou no Reino Unido.
Se você tem interesse em contribuir com projetos como este ou ajudar a Cloudflare a desenvolver seus sistemas de gerenciamento de tráfego e endereços, nossa equipe de Agilidade de Endereçamento está contratando novos funcionários!