
Znam filtry Blooma (nazwane na cześć Burtona Blooma) od czasów uniwersyteckich, ale nie miałem okazji używać ich w praktyce. W zeszłym miesiącu to się zmieniło — zafascynowały mnie możliwości tej struktury danych, ale szybko zdałem sobie sprawę, że ma ona pewne wady. Ten wpis to opowieść o moim przelotnym romansie z filtrami Blooma.
Podczas poszukiwania informacji na temat podszywania się pod adresy IP musiałem sprawdzić, czy źródłowe adresy IP wydobyte z pakietów docierających do naszych serwerów są prawidłowe, biorąc pod uwagę położenie geograficzne naszych centrów danych. Na przykład, źródłowe adresy IP należące do legalnego włoskiego dostawcy usług internetowych nie powinny docierać do centrum danych w Brazylii. Problem ten może wydawać się prosty, ale w nieustannie zmieniającym się krajobrazie Internetu jego rozwiązanie nie jest wcale łatwe. Wystarczy powiedzieć, że skończyłem z wieloma dużymi plikami tekstowymi zawierającymi następujące dane:

Pierwsza linia oznacza, że adres IP 192.0.2.1 został zarejestrowany z chwilą dotarcia prawidłowego żądania do centrum danych Cloudflare o numerze 107. Dane te pochodziły z wielu źródeł, w tym z naszych aktywnych i pasywnych sond, dzienników niektórych posiadanych przez nas domen (takich jak cloudflare.com), źródeł publicznych (takich jak tablica BGP) itp. Identyczna linia powtarzałaby się zazwyczaj w wielu plikach.
Uzyskałem więc gigantyczny zbiór danych tego typu. W pewnym momencie naliczyłem miliard linii we wszystkich przeanalizowanych źródłach. Zwykle piszę skrypty bash do wstępnego przetwarzania danych wejściowych, ale takie podejście nie sprawdzało się przy takiej skali. Na przykład usunięcie duplikatów z tego niewielkiego pliku o skromnym rozmiarze 600 MiB z 40 mln linii trwało... mniej więcej wieczność:

Dość powiedzieć, że usuwanie duplikatów przy użyciu typowych poleceń bash (takich jak 'sort') w różnych konfiguracjach (zobacz '--parallel', '--buffer-size' i '--unique') nie było optymalne w odniesieniu do tak dużego zbioru danych.
Filtry Blooma na ratunek
{kind=link}
Wtedy doznałem olśnienia — nie muszę sortować linii! Wystarczy tylko usunąć zduplikowane linie, przy czym użycie jakiegoś rodzaju struktury danych „zbioru” powinno być znacznie szybsze. Co więcej, znam mniej więcej kardynalność pliku wejściowego (liczbę unikalnych linii), mogę więc pogodzić się z utratą niektórych punktów danych — użycie probabilistycznej struktury danych jest do przyjęcia!
Filtry Blooma są idealnym rozwiązaniem!
Choć zachęcam do zapoznania się z artykułem o filtrach Blooma dostępnym w Wikipedii,, oto jak ja postrzegam tę strukturę danych.
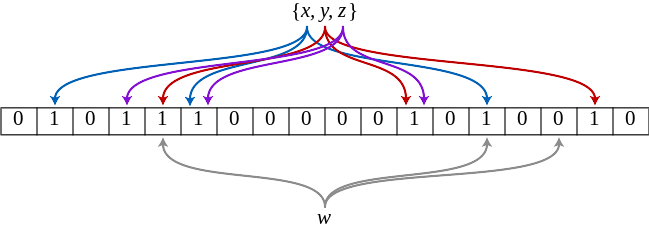
Jak można by zaimplementować "zbió"? Przy założeniu doskonałej funkcji skrótu i nieskończonej pamięci moglibyśmy po prostu utworzyć nieskończoną tablicę bitową i ustawić bit o numerze 'hash(item)' dla każdego napotkanego elementu. To dałoby nam idealną strukturę danych „zbioru”, prawda? Trywialne. Niestety, funkcje skrótu mają kolizje, a nieskończona pamięć nie istnieje, dlatego w naszych realiach trzeba iść na kompromis. Możemy jednak obliczyć prawdopodobieństwo kolizji i nim zarządzać. Wyobraźmy sobie na przykład, że mamy dobrą funkcję skrótu i 128 GiB pamięci. Możemy obliczyć, że prawdopodobieństwo kolizji drugiego elementu dodanego do tablicy bitowej wynosiłoby 1 na 1099511627776. Prawdopodobieństwo kolizji przy dodawaniu kolejnych elementów zwiększa się wraz wypełnianiem tablicy bitowej.
Ponadto, moglibyśmy użyć więcej niż jednej funkcji skrótu, co skutkowałoby gęstszą tablicą bitową. To właśnie optymalizują filtry Blooma. Filtr Blooma to kilka operacji matematycznych opartych na czterech zmiennych:
- n — liczba elementów wejściowych (kardynalność)
- m — pamięć zajęta przez tablicę bitową
- k — liczba funkcji skrótu uwzględnianych dla każdego wejścia
- p — prawdopodobieństwo dopasowania fałszywie pozytywnego
Przy ustalonej kardynalności wejściowej (n) i oczekiwanym prawdopodobieństwie wyniku fałszywie pozytywnego (p) operacje matematyczne filtra Blooma zwracają rozmiar wymaganej pamięci (m) oraz liczbę potrzebnych funkcji skrótu (k).
Świetna wizualizacja autorstwa Thomasa Hursta pokazuje, jak parametry te wzajemnie na siebie wpływają:
mmuniq-bloom
Wiedziony tą intuicją udałem się w podróż, aby dodać nowe narzędzie do mojego zestawu — 'mmuniq-bloom'. Jest to narzędzie probabilistyczne, które po przyjęciu danych do STDIN zwraca do STDOUT jedynie unikalne linie; mam nadzieję, że znacznie szybciej niż kombinacja 'sort' + 'uniq'!
Oto ono:
Dla uproszczenia i szybkości zaprojektowałem 'mmuniq-bloom' z kilkoma założeniami. Po pierwsze, jeśli nie zaznaczono inaczej, program korzysta z 8 funkcji skrótu, czyli k=8. Wydaje się to być liczbą bliską optymalnej dla rozmiarów danych, z którymi pracuję, a funkcja skrótu może szybko wygenerować 8 przyzwoitych skrótów. Następnie dobieramy m, czyli liczbę bitów w tablicy bitowej, w taki sposób, aby była potęgą liczby dwa. Ma to na celu uniknięcie kosztownej operacji modulo %, która kompiluje się do powolnego asemblerowego 'div'. Przy rozmiarach stanowiących potęgę liczby dwa możemy po prostu użyć operatora bitowego AND (z ciekawości można sprawdzić, jak kompilatory optymalizują niektóre dzielenia, wykorzystując mnożenie przez magiczną stałą.)
Teraz możemy uruchomić to narzędzie na tym samym pliku danych, którego używaliśmy wcześniej:

O, jest znacznie lepiej! 12 sekund w porównaniu z 2 minutami wygląda dużo lepiej. Ale chwilę... Program korzysta ze zoptymalizowanej struktury danych, charakteryzuje się stosunkowo niewielkim użyciem pamięci, zoptymalizowanym parsowaniem linii oraz dobrym buforowaniem wyjścia, lecz 12 sekund to nadal wieczność w porównaniu z narzędziem 'wc -l':

Co się dzieje? Rozumiem, że zliczanie linii przez 'wc' jest prostsze niż ustalanie unikalnych linii, ale czy naprawdę jest to warte 26‑krotnej różnicy? Dokąd są przekazywane wszystkie instrukcje procesora w programie 'mmuniq-bloom'?
Musi chodzić o moją funkcję skrótu. 'wc' nie musi angażować całej mocy procesora do wykonania wszystkich tych dziwnych obliczeń dla każdej z 40 milionów linii na wejściu. Korzystam z dość nietrywialnej funkcji skrótu 'siphash24', więc na pewno obciąża ona procesor, prawda? Sprawdźmy to, uruchamiając kod obliczający funkcję skrótu, ale niewykonujący żadnych operacji filtra Blooma:

Dziwne. Zliczenie funkcji skrótu faktycznie trwa około 2 sekund, ale w poprzednim uruchomieniu zajęło to programowi 12 sekund. Operacje samego filtra Blooma trwają 10 sekund? Jak to możliwe? To taka prosta struktura danych...
Tajna broń — profiler
Nadszedł czas, aby użyć narzędzia odpowiedniego do zadania — uruchommy profilera i zobaczmy, gdzie podziewają się zasoby CPU. Uruchomienie 'strace' pozwoli potwierdzić, że nie wykonujemy żadnych nieoczekiwanych wywołań systemowych:
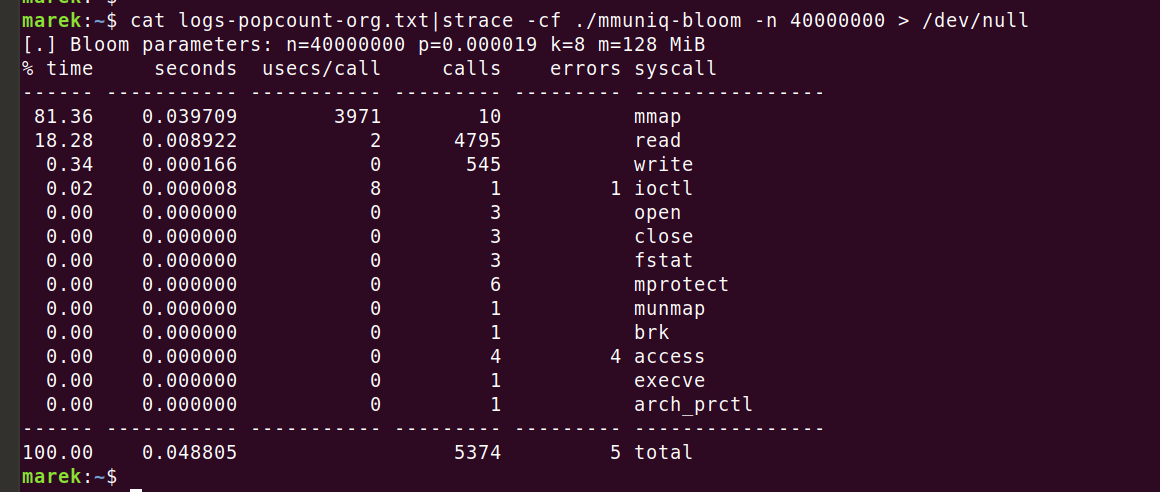
Wszystko wygląda dobrze. Dziesięć wywołań 'mmap', z których każde zajmuje 4 ms (3971 μs), jest intrygujące, ale to w porządku. Wstępnie zapełniamy pamięć za pomocą 'MAP_POPULATE', aby ograniczyć liczbę późniejszych błędów strony.
Jaki jest kolejny krok? Oczywiście linuksowy 'perf'!

Następnie możemy sprawdzić wyniki:
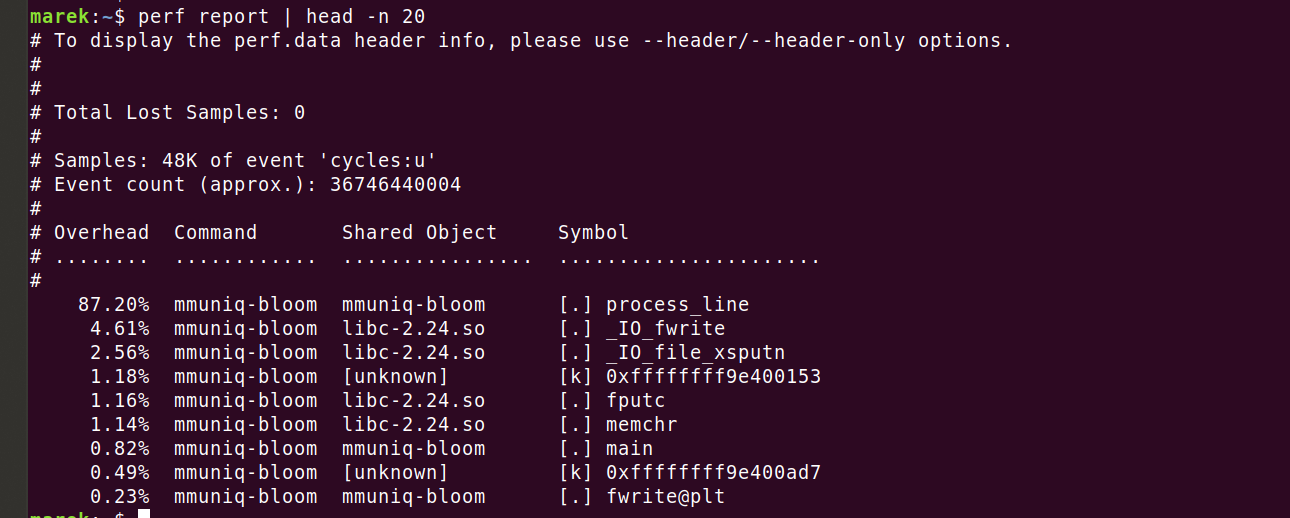
Zgadza się — faktycznie zużywamy 87,2% cykli w naszym krytycznym kodzie. Zobaczmy, gdzie dokładnie. Po wykonaniu instrukcji 'perf annotate process_line --source' szybko dostrzegam coś, czego się nie spodziewałem.
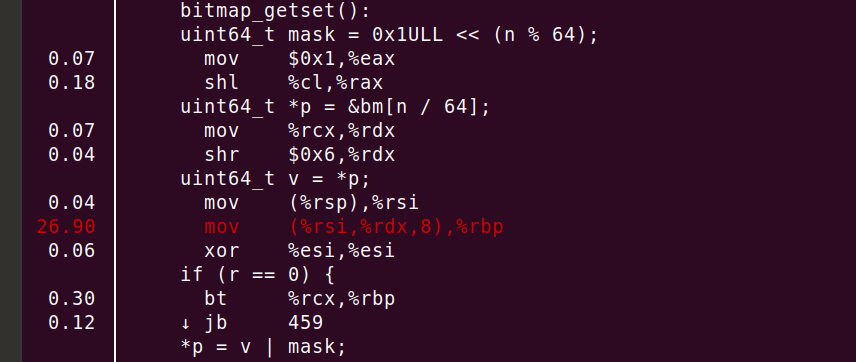
Widać, że 26,90% mocy obliczeniowej CPU jest zużywane przez instrukcję 'mov', ale to nie wszystko! Kompilator poprawnie umieścił funkcję w kodzie i rozwinął pętlę ośmiokrotnie. Podsumowując, linia 'mov' lub 'uint64_t v = *p' generuje większości cykli!
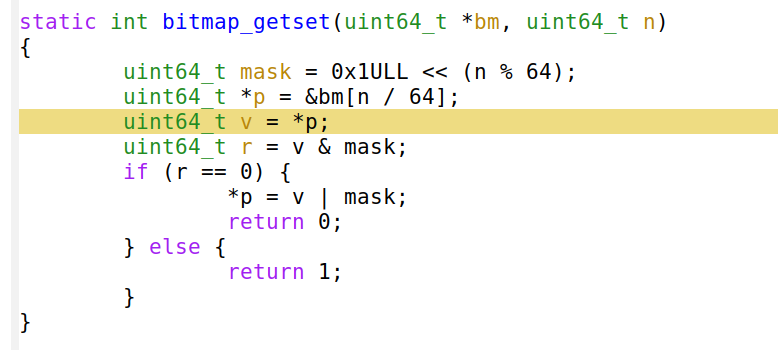
Najwyraźniej instrukcja 'perf' musi być błędna — jak taka prosta linia może skutkować takim obciążeniem? Możemy powtórzyć test wydajności z użyciem innego profilera i uwidoczni on nam ten sam problem. Lubię na przykład używać instrukcji 'google-perftools' z parametrem kcachegrind, ponieważ generuje ona atrakcyjne wizualnie wykresy:
Uzyskany wynik wygląda następująco:
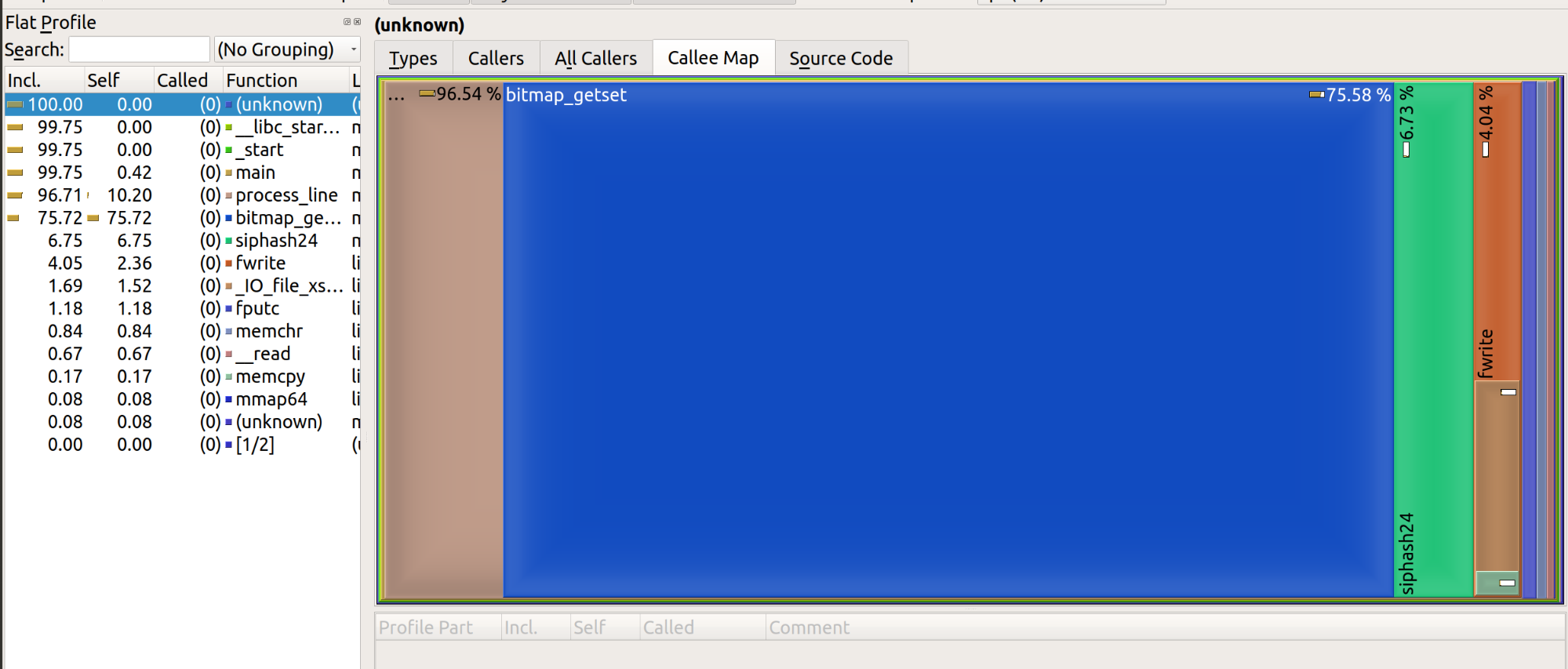
Podsumujmy dotychczasowe ustalenia.
Ogólnodostępne narzędzie 'wc' potrzebuje 0,45 s czasu procesora do przetworzenia pliku o rozmiarze 600 MiB. Nasze zoptymalizowane narzędzie 'mmuniq-bloom' potrzebuje 12 sekund. Procesor jest obciążony przez jedną instrukcję 'mov', wyłuskanie pamięci...

Och, jak mogłem o tym zapomnieć! Pamięć RAM jest powolna! Bardzo, bardzo, bardzo powolna!
Zgodnie z ogólną zasadą dotyczącą "wartości opóźnień, które każdy programista powinien znać" czas jednego pobrania danych z pamięci RAM wynosi około 100 ns. Wykonajmy obliczenia: 40 milionów linii, 8 funkcji skrótu zliczonych dla każdej linii. Nasz filtr Blooma ma rozmiar 128 MiB, dlatego na starszym sprzęcie nie mieści się w pamięci podręcznej L3! Funkcje skrótu są równomiernie rozłożone w dużym zakresie pamięci, a każda z nich generuje brak trafienia w pamięci. Składając to wszystko razem, otrzymujemy...

To sugeruje, że tylko operacje pobierania danych z pamięci trwały łącznie 32 sekundy. Rzeczywisty program jest szybszy, gdyż jego działanie zajmuje tylko 12 sekund. Wynika to z faktu, że chociaż dane filtra Blooma nie mieszczą się w całości w pamięci podręcznej L3, to i tak częściowy ich zapis w tej pamięci przynosi pewne korzyści. Można to łatwo zaobserwować, używając instrukcji 'perf stat -d':
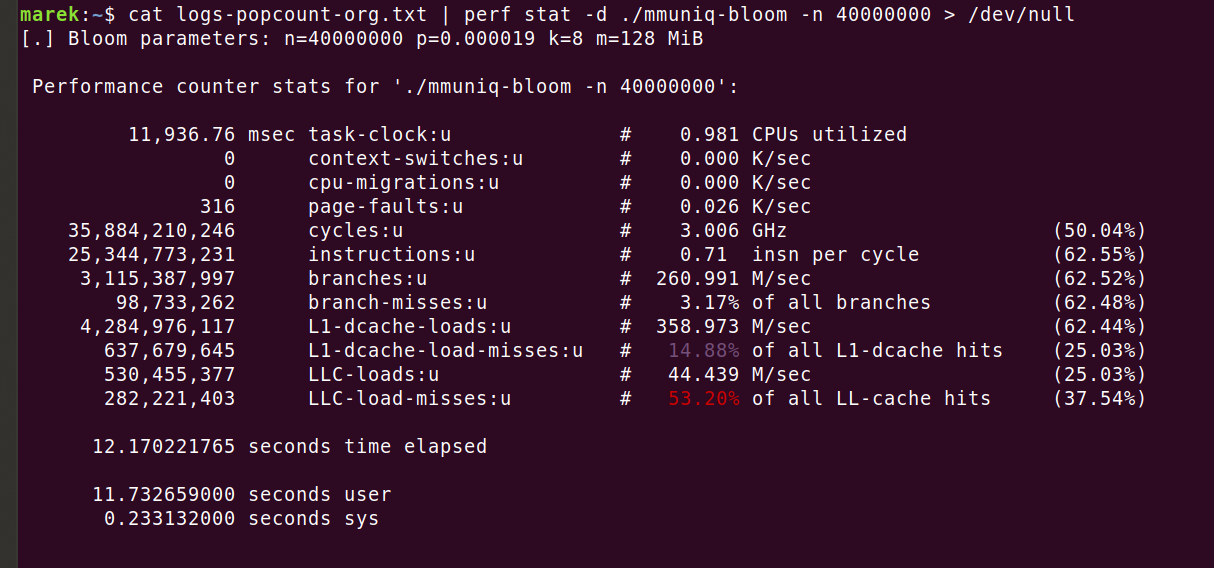
Tak jest — powinniśmy mieć przynajmniej 320 milionów braków trafień w pamięci podręcznej ostatniego poziomu (LLC‑load‑misses), a mieliśmy tylko 280 milionów. To nadal nie wyjaśnia, dlaczego program działał tylko 12 sekund. Nie ma to jednak większego znaczenia. Ważne jest, że liczba braków trafień w pamięci podręcznej jest prawdziwym problemem i można go rozwiązać tylko poprzez zmniejszenie liczby dostępów do pamięci. Spróbujmy dostroić filtr Blooma tak, aby używał tylko jednej funkcji skrótu:

Auć! To naprawdę zabolało! Filtr Blooma wymagał 64 GiB pamięci, aby osiągnąć pożądany stosunek prawdopodobieństwa wyników fałszywie dodatnich wynoszący 1 błąd na 10 tysięcy linii. To straszne!
Ponadto, nie wydaje się, abyśmy wiele poprawili. System operacyjny potrzebował 22 sekund, aby przygotować dla nas pamięć, ale nadal poświęcaliśmy 11 sekund na operacje w przestrzeni użytkownika. Wydaje się, że tym razem wszelkie korzyści z rzadszego dostępu do pamięci zostały zniwelowane przez niższe prawdopodobieństwo trafienia w pamięć podręczną ze względu na drastycznie zwiększony rozmiar pamięci. W poprzednich uruchomieniach potrzebowaliśmy zaledwie 128 MiB dla filtra Blooma!
Całkowita rezygnacja z filtrów Blooma
To staje się absurdalne. Aby uzyskać te same gwarancje wyników fałszywie pozytywnych, albo musimy używać wielu funkcji skrótu w filtrze Blooma (na przykład 8) i tym samym wykonywać wiele operacji w pamięci, albo możemy użyć jednej funkcji skrótu przy ogromnych wymaganiach dotyczących pamięci.
Nie jesteśmy w sumie ograniczeni dostępną pamięcią — zamiast tego chcemy optymalizacji pod kątem zredukowania dostępów do pamięci. Wszystko, czego potrzebujemy, to struktura danych, która wymaga co najwyżej jednego braku trafienia w pamięci na element i wykorzystuje mniej niż 64 GB pamięci RAM...
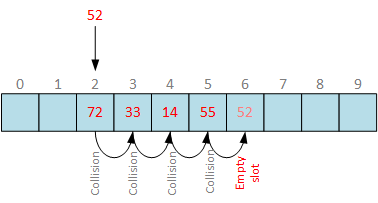
Moglibyśmy rozważyć bardziej zaawansowane struktury danych, takie jak filtr Cuckoo, ale być może znajdzie się prostsze rozwiązanie. Co powiesz na starą, dobrą, prostą tablicę mieszającą z sondowaniem liniowym?
Rysunek autorstwa Vadims Podāns
Powitajmy mmuniq-hash
Tutaj można znaleźć zmodyfikowaną wersję filtra mmuniq-bloom, ale wykorzystującą tablicę mieszającą:
Zamiast przechowywania bitów, jak w przypadku filtra Blooma, teraz przechowujemy 64‑bitowe funkcje skrótu pochodzące z funkcji 'siphash24'. Daje nam to znacznie większe gwarancje prawdopodobieństwa, z prawdopodobieństwem wyników fałszywie pozytywnych znacznie lepszym niż jeden błąd na 10 tysięcy linii.
Przeprowadźmy obliczenia. Dodanie nowego elementu do tablicy mieszającej zawierającej, powiedzmy, 40 milionów wpisów daje 40M/2^64 szans na wystąpienie kolizji funkcji skrótu. Jest to zatem bardzo niskie prawdopodobieństwo wynoszące w przybliżeniu jeden na 461 miliardów. Nie dodajemy jednak jednego elementu do wstępnie wypełnionego zbioru, lecz 40 milionów linii do początkowo pustego zbioru! Zgodnie z paradoksem urodzin zwiększa to znacznie szanse na wystąpienie kolizji w pewnym momencie. Przyzwoite przybliżenie to ~n^2/2m, co w naszym przypadku wynosi ~(40M2)/(2*(264)), czyli szansa jedna na 23000. Innymi słowy, zakładając, że używamy dobrej funkcji skrótu, jeden spośród 23 tysięcy losowych zbiorów zawierających 40 mln elementów będzie miał kolizję funkcji skrótu. Ta praktyczna szansa na wystąpienie kolizji jest nie do pominięcia, ale jest to nadal lepiej niż w przypadku filtra Blooma oraz całkowicie akceptowalne dla mojego przypadku użycia.
Kod tablicy mieszającej działa szybciej, ma lepsze wzorce dostępu do pamięci oraz charakteryzuje się niższym prawdopodobieństwem wyników fałszywie pozytywnych, niż w przypadku podejścia z wykorzystaniem filtra Blooma.

Nie martw się o linię „konfliktów funkcji skrótu” — wskazuje ona jedynie stopień zapełnienia tablicy mieszającej. Korzystamy z sondowania liniowego, zatem gdy wiadro jest już używane, po prostu wybieramy następne puste wiadro. W naszym przypadku musieliśmy przeskoczyć średnio 0,7 wiadra, aby znaleźć puste miejsce w tablicy. To jest w porządku, a ponieważ przeprowadzamy iterację po wiadrach w kolejności liniowej, możemy oczekiwać sprawnego wstępnego pobierania danych z pamięci.
Z poprzedniego ćwiczenia wiemy, że czas przetwarzania naszej funkcji skrótu wynosi około 2 sekundy. Tym samym można uczciwie stwierdzić, że przetworzenie 40 milionów trafień w pamięci zajmie około 4 sekundy.
Czego się dowiedzieliśmy
Nowoczesne procesory są naprawdę dobre w sekwencyjnym dostępie do pamięci, gdy można przewidzieć wzorce pobierania danych z pamięci (zobacz: Wstępne pobieranie danych z pamięci podręcznej). Z drugiej strony, pamięć RAM jest bardzo kosztowna.
Zaawansowane struktury danych są bardzo interesujące, lecz należy zachować ostrożność. Nowoczesne komputery wymagają algorytmów zoptymalizowanych pod kątem pamięci podręcznej. Pracując z dużymi zbiorami danych, które nie mieszczą się w pamięci L3, lepiej jest zoptymalizować algorytmy pod kątem zmniejszenia liczby operacji ładowania danych, niż optymalizować ilość używanej pamięci.
Moim zdaniem można uczciwie powiedzieć, że filtry Blooma są świetne, dopóki mieszczą się w pamięci podręcznej L3. Z chwilą, gdy to założenie przestaje być spełnione, stają się okropne. To nic nowego — filtry Blooma są zoptymalizowane pod kątem wykorzystania pamięci, a nie dostępu do niej (zobacz np. publikację dotyczącą filtrów Cuckoo.
Inną kwestią jest niekończąca się dyskusja na temat funkcji skrótu. Szczerze mówiąc, w większości przypadków nie ma to znaczenia. Koszt zliczania nawet skomplikowanych funkcji skrótu, takich jak 'siphash24', jest mały w porównaniu z kosztem pamięci RAM. W naszym przypadku uproszczenie funkcji skrótu przyniesie tylko niewielkie korzyści. Czas pracy procesora jest po prostu marnowany gdzie indziej — na oczekiwaniu na pamięć!
Jeden z kolegów często powtarza: „Możesz zakładać, że nowoczesne procesory są nieskończenie szybkie. Pracują z nieskończoną szybkością, dopóki nie zderzą się ze ścianą pamięci".
Na koniec: nie popełniaj moich błędów — każdy powinien zacząć profilowanie od użycia instrukcji 'perf stat -d' i przyjrzenia się licznikowi instrukcji na cykl (IPC). Jego wartość mniejsza niż 1 zazwyczaj oznacza, że program utknął i oczekuje na pamięć. Wartości powyżej 2 byłyby świetne, gdyż oznaczałoby to, że obciążenie jest głównie związane z pracą procesora. Niestety, jeszcze nie widziałem wysokich wartości przy obciążeniach, z którymi mam do czynienia...
Ulepszona wersja mmuniq
Z pomocą moich kolegów przygotowałem jeszcze bardziej ulepszoną wersję narzędzia opartego na tablicy mieszającej 'mmuniq'. Oto odpowiedni kod:
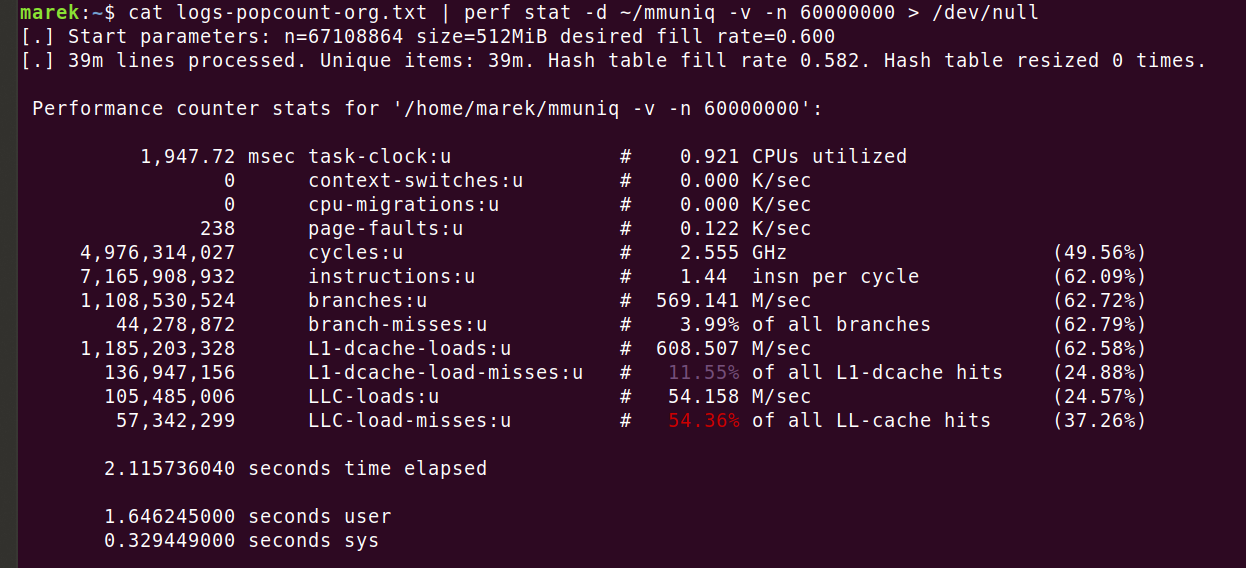
Jest on w stanie dynamicznie zmieniać rozmiar tablicy mieszającej, aby obsługiwać dane wejściowe o nieznanej mocy zbioru (kardynalności). Następnie, dzięki tworzeniu plików wsadowych może efektywnie wykorzystać podpowiedź 'prefetch' dotyczącą procesora, przyspieszając program o 35–40%. Należy uważać, gdyż dodanie do kodu instrukcji 'prefetch' rzadko przynosi efekty. Zamiast tego, celowo zmieniłem przepływ algorytmów, aby wykorzystać tę instrukcję. Z wszystkimi ulepszeniami udało mi się skrócić czas działania do 2,1 sekundy:
Zakończenie
W trakcie pisania tego podstawowego narzędzia, które stara się być szybsze niż kombinacja 'sort | uniq', ujawniły się pewne ukryte klejnoty nowoczesnego przetwarzania danych. Przy odrobinie pracy udało nam się je przyspieszyć z ponad dwóch minut do 2 sekund. Podczas tej podróży dowiedzieliśmy się o opóźnieniach pamięci RAM oraz o potędze struktur danych przyjaznych dla pamięci podręcznej. Wymyślne struktury danych są ekscytujące, ale w praktyce zmniejszenie obciążenia pamięci RAM często przynosi lepsze rezultaty.