


Vandaag kunnen we met trots aankondigen dat we de Mistral-7B-v0.1-instructie hebben toegevoegd aan Workers AI. Mistral 7B is een taalmodel met 7,3 miljard parameters en een aantal unieke voordelen. Met wat hulp van de oprichters van Mistral AI bekijken we enkele van de hoogtepunten van het Mistral 7B-model en maken we van de gelegenheid gebruik om dieper in te gaan op "attention" en variaties daarop, zoals multi-query attention en grouped-query attention.
Mistral 7B tl;dr:
Mistral 7B is een model met 7,3 miljard parameters dat indrukwekkende scores behaalt op benchmarks. Het model:
- Presteert beter dan Llama 2 13B op alle benchmarks
- Presteert beter dan Llama 1 34B op veel benchmarks,
- Benadert de prestaties van CodeLlama 7B op code, zonder afbreuk aan het Engelse taalvermogen, en
- De versie met gespecialiseerde chat die we hebben ingezet presteert beter dan Llama 2 13B chat op de benchmarks die Mistral heeft geleverd.
Hier is een voorbeeld van het gebruik van streaming met de REST API:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
En hier is een voorbeeld met een Worker-script:
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral maakt gebruik van grouped-query attention voor snellere inferentie. Deze recent ontwikkelde techniek verbetert de snelheid van inferentie zonder afbreuk te doen aan de uitvoerkwaliteit. Voor modellen met 7 miljard parameters kunnen we met Mistral bijna 4x zoveel tokens per seconde genereren als met Llama, dankzij Grouped-Query attention.
U heeft verder geen informatie nodig om Mistral-7B te gaan gebruiken, u kunt het vandaag nog uitproberen op ai.cloudflare.com. Lees verder voor meer informatie over attention en grouped-query attention!
Wat is “attention” eigenlijk?
Het basismechanisme van attention, specifiek “Scaled Dot-Product Attention” zoals geïntroduceerd in het baanbrekende artikel Attention Is All You Need, is vrij eenvoudig:
We noemen onze bijzondere attention “Scale Dot-Product Attention”. De invoer bestaat uit een query en sleutels van dimensie d_k, en waarden van dimensie d_v. We berekenen de puntproducten van de query met alle sleutels, delen elk door sqrt(d_k) en passen een softmax-functie toe om de gewichten op de waarden te verkrijgen.
Concreet ziet dit er als volgt uit:
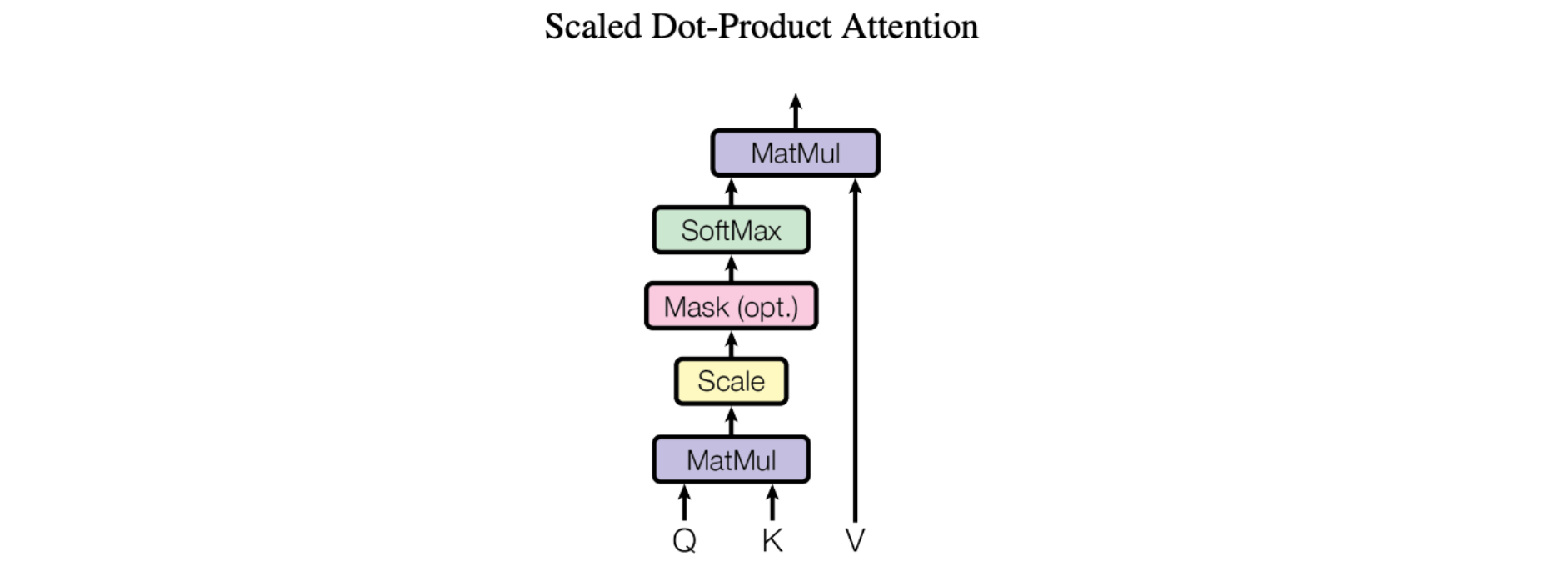
Eenvoudiger gezegd: hierdoor kunnen modellen zich richten op belangrijke delen van de invoer. Stel je voor dat je een zin leest en probeert te begrijpen. Met Scaled dot product attention kun je meer aandacht besteden aan bepaalde woorden op basis van hun relevantie. Het werkt door de gelijkenis tussen elk woord (K) in de zin en een query (Q) te berekenen. Vervolgens worden de similariteitsscores geschaald door ze te delen door de vierkantswortel van de dimensie van de query. Deze schaling helpt om erg kleine of erg grote waarden te vermijden. Tot slot kunnen we met behulp van deze geschaalde similariteitsscores bepalen hoeveel aandacht of belang elk woord zou moeten krijgen. Dit attention-mechanisme helpt modellen cruciale informatie (V) te identificeren en hun begrip en vertaalvermogen te verbeteren.
Simpel, toch? Om van dit eenvoudige mechanisme naar een AI te komen die een “Seinfeld-aflevering” kan schrijven waarin Jerry het bubble sort-algoritme leert, moeten we het complexer maken. In feite heeft alles wat we net hebben behandeld niet eens geleerde parameters - constante waarden die tijdens de modeltraining worden geleerd en die de uitvoer van het attention-blok aanpassen!
Attention blocks in the style of Attention is All You Need add mainly three types of complexity:
Aangeleerde parameters
Aangeleerde parameters verwijzen naar waarden of gewichten die worden aangepast tijdens het trainingsproces van een model om de prestaties ervan te verbeteren. Deze parameters worden gebruikt om de informatiestroom of aandacht binnen het model te regelen, zodat het model zich kan richten op de meest relevante delen van de invoergegevens. Eenvoudiger gezegd, zijn geleerde parameters als instelbare knoppen op een machine waaraan gedraaid kan worden om de werking te optimaliseren.
Verticaal stapelen - gelaagde attention-blokken
Verticaal stapelen in lagen is een manier om meerdere attention-mechanismen op elkaar te stapelen, waarbij elke laag voortbouwt op de uitvoer van de vorige laag. Hierdoor kan het model zich richten op verschillende delen van de invoergegevens op verschillende abstractieniveaus, wat kan leiden tot betere prestaties bij bepaalde taken.
Horizontaal stapelen - ook wel bekend als Multi-Head Attention
De figuur uit de paper toont de volledige multi-head attention-module. Meerdere attention-operaties worden parallel uitgevoerd, waarbij de Q-K-V invoer voor elke operatie wordt gegenereerd door een unieke lineaire projectie van dezelfde invoergegevens (gedefinieerd door een unieke set aangeleerde parameters). Deze parallelle attention-blokken worden “attention heads” genoemd. De gewogen-som outputs van alle attention heads worden samengevoegd tot een enkele vector en door een andere geparametriseerde lineaire transformatie gehaald om de uiteindelijke output te krijgen.
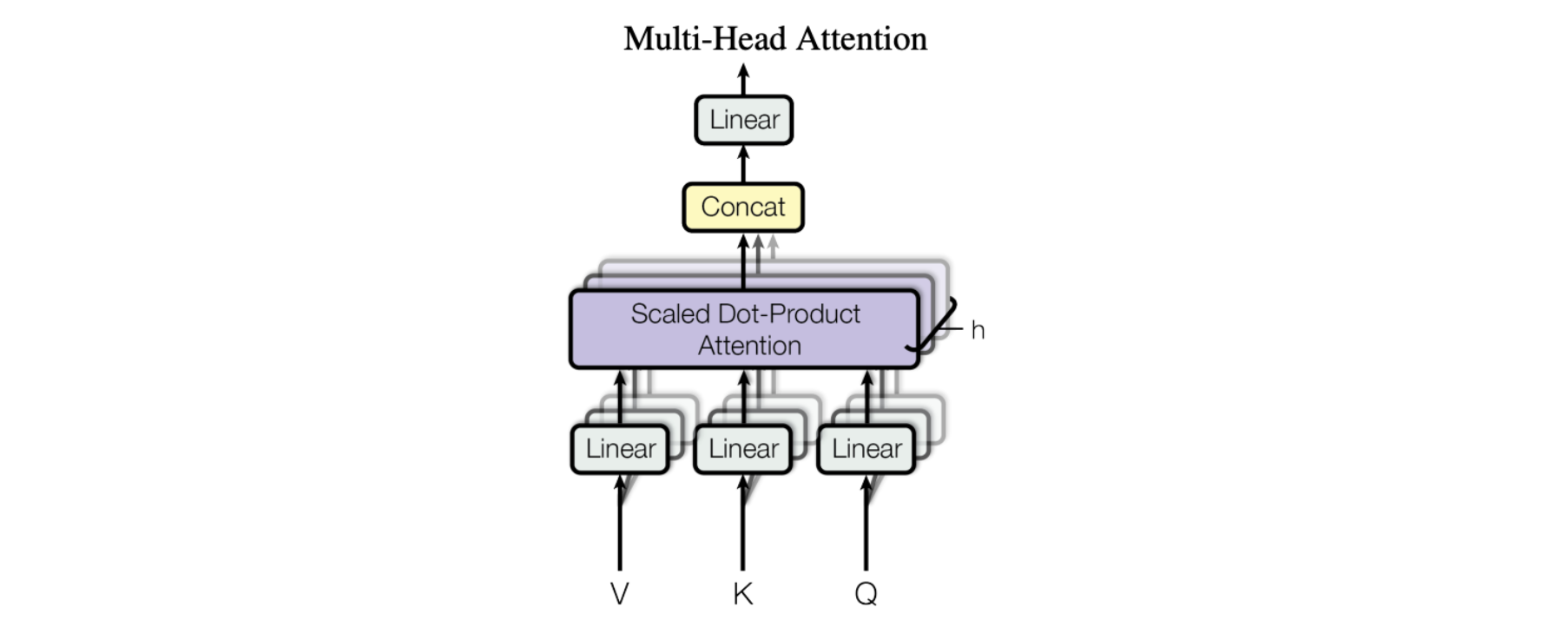
Dankzij dit mechanisme kan een model zich tegelijkertijd op verschillende delen van de invoergegevens richten. Stel je voor dat je een complex stuk informatie probeert te begrijpen, zoals een zin of een alinea. Om het te begrijpen, moet je aandacht besteden aan verschillende delen tegelijk. Je moet bijvoorbeeld aandacht besteden aan het onderwerp van de zin, het werkwoord en het lijdend voorwerp, allemaal tegelijk, om de betekenis van de zin te begrijpen. Multi-headed attention werkt op dezelfde manier. Het stelt een model in staat om aandacht te besteden aan verschillende delen van de invoergegevens op hetzelfde moment, door gebruik te maken van meerdere “attention heads”. Elk attention-head richt zich op een ander aspect van de invoergegevens en de uitvoer van alle heads wordt gecombineerd tot de uiteindelijke uitvoer van het model.
Soorten attention
Er zijn drie veelvoorkomende opstellingen van attention-blocks die worden gebruikt door grote taalmodellen die de afgelopen jaren zijn ontwikkeld: multi-head attention, grouped-query attention en multi-query attention. Ze verschillen in het aantal K- en V-vectoren ten opzichte van het aantal queryvectoren. Multi-head attention gebruikt hetzelfde aantal K- en V-vetoren als Q-vectoren, aangegeven als “N” in de onderstaande tabel. Multi-query attention gebruikt slechts een enkele K- en V-vector. Grouped-query attention, het type dat gebruikt wordt in het Mistral 7B model, verdeelt de Q-vectoren gelijkmatig in groepen die elk “G” vectoren bevatten en gebruikt dan een enkele K- en V-vector voor elke groep voor een totaal van N gedeeld door G sets van K- en V-vectoren. Dit is een samenvatting van de verschillen en we gaan hieronder in de implicaties hiervan.
|
Aantal key/value-blokken |
Kwaliteit |
Geheugengebruik |
|
|
Multi-head attention (MHA) |
N |
Beste |
Meeste |
|
Grouped-query attention (GQA) |
N / G |
Beter |
Minder |
|
Multi-query attention (MQA) |
1 |
Goed |
Minste |
Samenvatting van soorten attention
En dit diagram helpt het verschil tussen de drie soorten te illustreren:
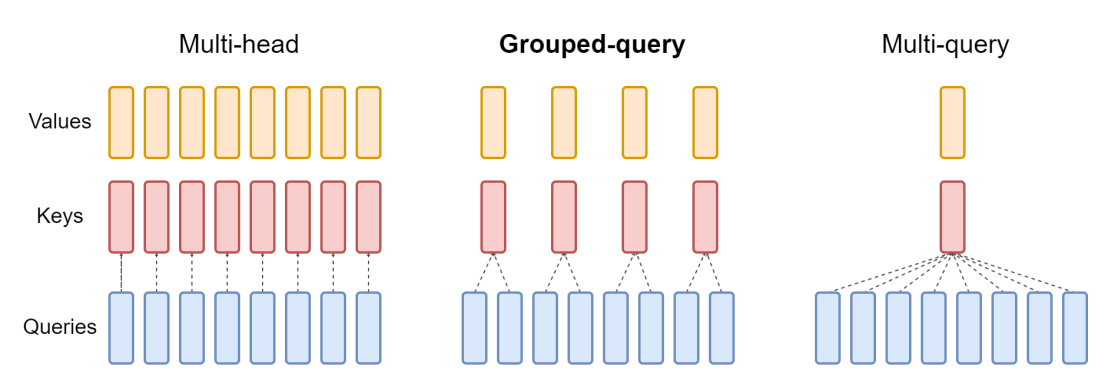
Multi-Query Attention
Multi-query attention werd in 2019 beschreven in het paper van Google: Fast Transformer Decoding: One Write-Head is All You Need. Het idee is dat in plaats van aparte K- en V-items te maken voor elke Q-vector in het attention-mechanisme, zoals in de bovengenoemde multi-head attention, er slechts één enkele K- en V-vector wordt gebruikt voor de hele reeks Q-vectoren. Vandaar de naam, meerdere query's gecombineerd in een enkel aandachtsmechanisme. In de paper werd dit gebenchmarkt op een vertaaltaak en toonde het prestaties gelijk aan multi-head aandacht op de benchmarktaak.
Oorspronkelijk was het idee om de totale grootte van het geheugen dat wordt gebruikt bij het uitvoeren van inferentie voor het model te verkleinen. Sindsdien, met de opkomst van gegeneraliseerde modellen en het toenemen van het aantal parameters, is het benodigde GPU-geheugen vaak de bottleneck. Dit is de kracht van multi-query aandacht, omdat het van de drie soorten aandacht het minste versnellergeheugen vereist. Naarmate de modellen echter groter en algemener werden, daalde de prestatie van multi-query aandacht ten opzichte van multi-head aandacht.
Grouped-Query Attention
De jongste van het stel, en de attention die gebruikt wordt door Mistral, is grouped-query attention, zoals beschreven in de paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints dat in mei 2023 werd gepubliceerd op arxiv.org. Gegroepeerde-query aandacht combineert het beste van twee werelden: de kwaliteit van meervoudige aandacht met de snelheid en het lage geheugengebruik van multi-query attention. In plaats van een enkele set van K- en V-vectoren of een set voor elke Q-vector, wordt een vaste verhouding van 1 set van K- en V-vectoren voor elke Q-vector gebruikt, waardoor minder geheugen wordt gebruikt maar de hoge prestaties op veel taken behouden blijven.
Vaak gaat het bij het kiezen van een model voor een productietaak niet alleen om het kiezen van het beste model dat beschikbaar is, omdat we afwegingen moeten maken tussen prestaties, geheugengebruik, batchgrootte en beschikbare hardware (of cloudkosten). Inzicht in deze drie stijlen van aandacht kan helpen bij het nemen van deze beslissingen en begrijpen wanneer we, gegeven onze omstandigheden, voor een bepaald model zouden kunnen kiezen.
Werk met Mistral — probeer het vandaag nog
Als een van de eerste grote taalmodellen die gebruik maakt van grouped-query attention en deze combineert met 'sliding window'-attention, lijkt Mistral het optimale compromis gevonden te hebben: het heeft een lage latentie, een hoge doorvoer en het presteert echt goed op benchmarks, zelfs in vergelijking met grotere modellen (13B). Dit alles wil zeggen dat het een kracht heeft voor zijn grootte. Met veel trots maken we het vandaag beschikbaar voor alle ontwikkelaars, via Workers AI.
Ga nu naar onze developer docs om te beginnen, en als u hulp nodig heeft, feedback wilt geven, of wilt delen wat u aan het bouwen bent, kom gewoon langs op onze Developer Discord!
Het Workers AI-team is ook op zoek naar nieuwe medewerkers, zie onze jobs-pagina voor openstaande functies als je gepassioneerd bent over AI-engineering en ons wilt helpen bij het bouwen en ontwikkelen van ons wereldwijde, serverloze GPU-aangedreven inferentieplatform.