

Introduction
Il existe de nombreuses méthodes pour stocker des données dans vos applications. Par exemple, dans les applications Cloudflare Workers, les Workers KV sont consacrés au stockage clé-valeur et les Durable Objects au stockage coordonné, en temps réel, sans compromis sur la cohérence. En dehors de l'écosystème Cloudflare, vous pouvez également connecter d'autres outils tels que NoSQL et des bases de données graphiques.
Mais il arrive que vous préfériez SQL. Les index nous permettent de récupérer rapidement les données. Grâce aux jointures, il est possible de décrire des relations complexes entre différentes tables. SQL décrit dans des déclarations la façon dont les données de notre application sont validées, créées et interrogées.
D1 a été lancé aujourd'hui en version alpha ouverte, et pour marquer l'événement, je souhaite faire part de mon expérience en matière de création d'applications avec D1 ; j'aimerais notamment expliquer comment démarrer et raconter ce qui me réjouit dans le fait que D1 vienne s'ajouter à la longue liste d'outils que vous pouvez utiliser pour créer des applications dans Cloudflare.
D1 est remarquable car il ajoute immédiatement de la valeur aux applications, sans qu'il soit nécessaire d'avoir recours à de nouveaux outils ni de sortir de l'écosystème Cloudflare. Avec l'aide de Wrangler, nous pouvons développer localement sur nos applications Workers et en ajoutant D1 dans Wrangler, nous pouvons également le faire pour des applications à états. Ensuite, quand vient le moment de déployer l'application, Wrangler nous donne accès à des commandes que nous pouvons exécuter sur votre base de données D1, et sur votre API elle-même.
Notre projet
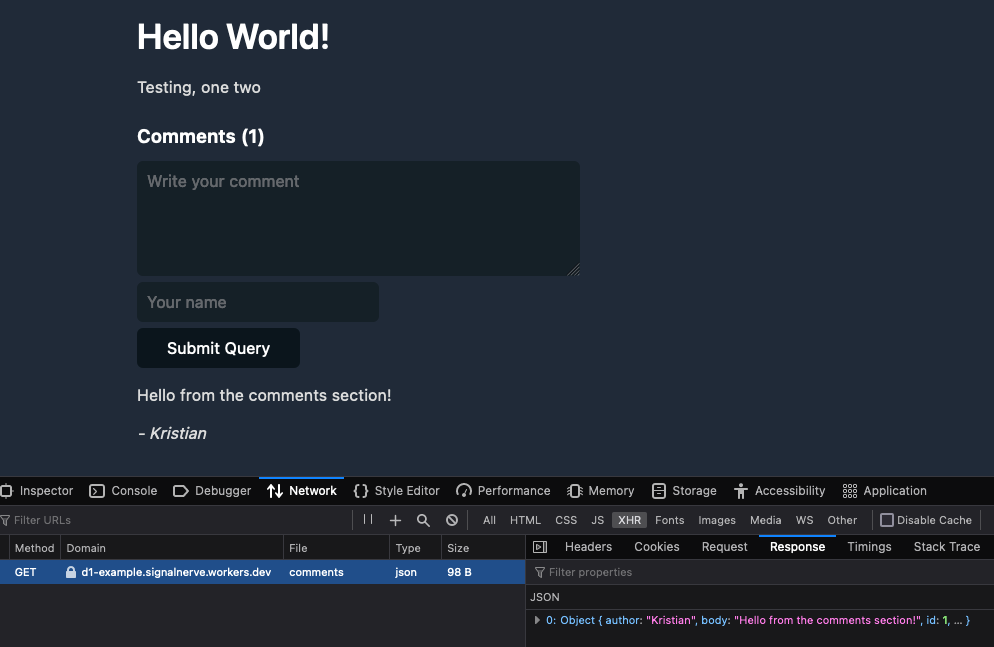
Cet article vous présentera la marche à suivre pour utiliser D1 afin d'ajouter des commentaires sur un blog statique. Pour ce faire, vous devrez définir une nouvelle base de données D1, avant de lui intégrer une simple API JSON permettant la création et la récupération des commentaires.
Comme je l'ai mentionné, en séparant D1 de l'application elle-même (Une API et une base de données qui restent séparées du site statique), nous sommes en mesure d'extraire les éléments statiques et dynamiques de notre site Web et de les séparer les uns des autres. C'est ce qui facilite également le déploiement de notre application : nous déploierons le front-end sur Cloudflare Pages et l'API optimisée par D1 sur Cloudflare Workers.
Création d'une nouvelle application
Pour commencer, ajoutons une API de base dans Workers. Créez un nouveau répertoire avec un nouveau projet Wrangler :
$ mkdir d1-example && d1-example
$ wrangler init
Dans cet exemple, nous allons utiliser Hono, un cadre Express.js-style pour créer rapidement notre API. Pour utiliser Hono avec ce projet, installez-le à l'aide de NPM :
$ npm install hono
Ensuite, dans src/index.ts, nous allons initialiser une nouvelle application Hono et définir quelques points de terminaison - GET /API/posts/:slug/comments, et POST /get/api/:slug/comments.
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
Nous allons ensuite créer une base de données D1. Wrangler 2 prend en charge une sous-commande wrangler d1, qui permet de créer et interroger vos bases de données D1 directement depuis une ligne de commande. Nous pouvons par exemple créer une nouvelle base de données avec une commande unique :
$ wrangler d1 create d1-example
Avec la base de données que nous avons créée, nous pouvons partir de l'ID de nom de base de données et l'associer à une liaison dans wrangler.toml, le fichier de configuration de wrangler. Grâce aux liaisons nous pouvons accéder aux ressources Cloudflare, telles que les bases de données D1, les espaces de noms KV et les compartiments R2, à l'aide d'un simple nom de variable inséré dans notre code. Ci-dessous, nous créons la liaison DB qui nous sert à représenter notre nouvelle base de données :
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
Notez que cette directive, à savoir le champ [[d1_databases]], n'est pour l'instant possible qu'avec une version Bêta de Wrangler. Vous pouvez l'installer pour votre projet à l'aide de la commande npm install -D wrangler/beta.
Avec cette base de données configurée dans notre wrangler.toml, nous pouvons commencer à interagir avec, à l'aide de la ligne de commande et au sein de notre fonction Workers.
Vous pouvez d'abord émettre des commandes SQL directes avec wrangler d1 execute :
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
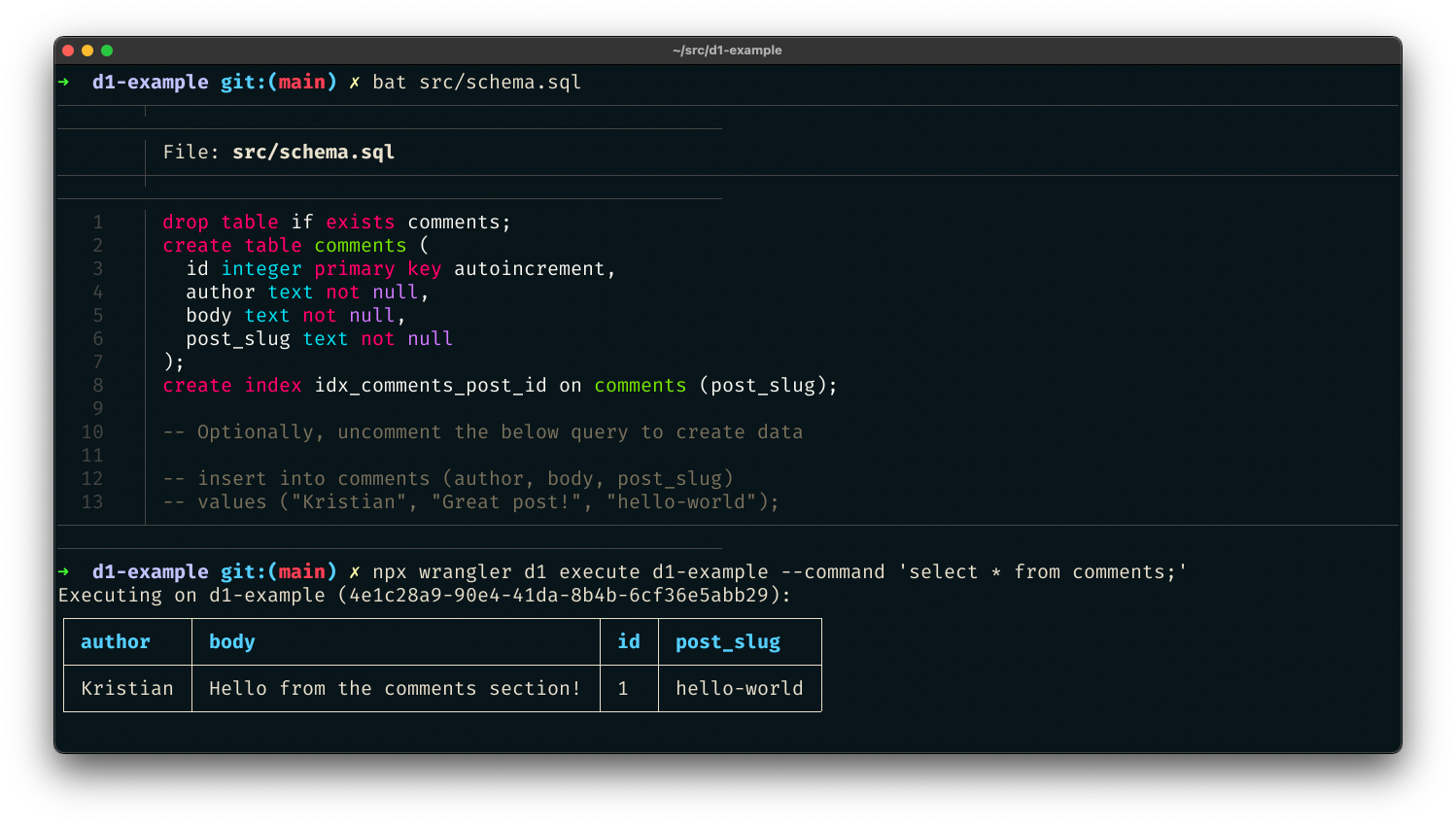
Vous pouvez également transmettre un fichier SQL ; parfait pour semer des données initiales dans une commande unique. Créez src/schema.sql, qui donnera lieu à une nouvelle table de comments pour notre projet :
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
Une fois le fichier créé, exécutez le fichier de schéma pour la base de données D1 en le transmettant avec l'indicateur --file :
$ wrangler d1 execute d1-example --file src/schema.sql
Nous avons créé une base de données SQL en quelques commandes simplement, et y avons ajouté des données initiales. Nous pouvons maintenant ajouter un itinéraire vers notre fonction Workers pour récupérer des données de la base de données. Conformément à notre fichier de configuration wrangler.toml, la base de données D1 est désormais accessible via la liaison DB. Dans notre code, nous pouvons utiliser la liaison pour préparer les instructions SQL et les exécuter pour récupérer des commentaires par exemple :
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
Dans cette fonction, nous acceptons un paramètre de requête URL slug et définissons une nouvelle instruction SQL avec laquelle nous sélectionnons comme paramètre de requête l'ensemble des commentaires associés à une valeur post_slug correspondante. Nous pouvons ensuite la renvoyer comme une simple réponse JSON.
Jusqu'à présent nous n'avons créé que des accès en lecture seule à nos données. Mais il est bien sûr également possible « d'insérer » des valeurs au code SQL. Définissons donc une autre fonction qui permette d'utiliser la commande POST sur un autre point de terminaison pour créer un nouveau commentaire :
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
Dans cet exemple, nous créons une API de commentaires pour alimenter un blog. Pour consulter la source de cette API de commentaires optimisée par D1, accédez à l'adresse cloudflare/templates/worker-d1-api.
Conclusion
Un des aspects les plus intéressants de D1 réside dans la possibilité qu'il offre d'enrichir des applications ou sites Web existants avec des données relationnelles et dynamiques. En tant qu'ancien développeur de Ruby on Rails, un des éléments que je regrette le plus de cette infrastructure dans le monde du JavaScript et des outils de développement sans serveur est la capacité à mettre rapidement en service des applications sans être un expert en gestion des infrastructures de base de données. Avec D1 et la simplicité de ses accès directs aux données SQL, nous pouvons créer de véritables applications axées sur les données sans compromettre les performances ni l'expérience des développeurs.
Cette évolution correspond exactement à l'avènement des sites statiques constaté au cours de ces dernières années, accompagné par des outils tels qu'Hugo ou Gatsby. Un blog assemblé avec un générateur de site statique tel qu'Hugo affiche des performances incroyables ; l'assemblage ne prend que quelques secondes pour des ressources de taille modeste.
Toutefois, en remplaçant un outil tel que WordPress par un générateur de site statique, vous perdez la possibilité d'ajouter des informations dynamiques à votre site. De nombreux développeurs ont imaginé un correctif à ce problème en ajoutant de la complexité aux processus d'assemblage : ils récupèrent des données et génèrent les pages avec ces données pendant l'assemblage.
Cet ajout de complexité dans le processus d'assemblage a pour but de compenser l'absence de dynamisme dans les applications mais cela ne les rend pas réellement dynamiques pour autant. À défaut de pouvoir récupérer et afficher les nouvelles données au fur et à mesure de leur création, l'application se reconstruit et se redéploie à chaque modification des données, ce qui lui donne l'aspect d'une représentation dynamique et vivante des données. Votre application peut rester statique et les données dynamiques se trouveront à proximité des utilisateurs de votre site, accessible via une API interrogeable et expressive.