


Full-Stack wird einfacher
Heute mag ja der 1. April sein – und wir lachen natürlich auch sehr gerne, dennoch geben wir heute eine Reihe wichtiger und ernsthafter Ankündigungen bekannt. Tatsächlich gibt es mittlerweile über 2 Millionen Entwickler, die auf der Plattform von Cloudflare entwickeln – kein Scherz!
Zum Auftakt der Developer Week legen wir bei drei Produkten den Schalter auf „einsatzbereit“ um: D1, unsere serverlose SQL-Datenbank; Hyperdrive, mit der sich ihre bestehenden Datenbanken wie verteilte Datenbanken anfühlen (und schneller sind!); und die Workers Analytics Engine, unsere Datenbank für Zeitreihen.
Wir sind seit einiger Zeit bestrebt, Entwicklern die Möglichkeit zu geben, ihr gesamtes Stack zu Cloudflare zu bringen. Doch wie könnte eine auf Cloudflare entwickelte Anwendung aussehen?
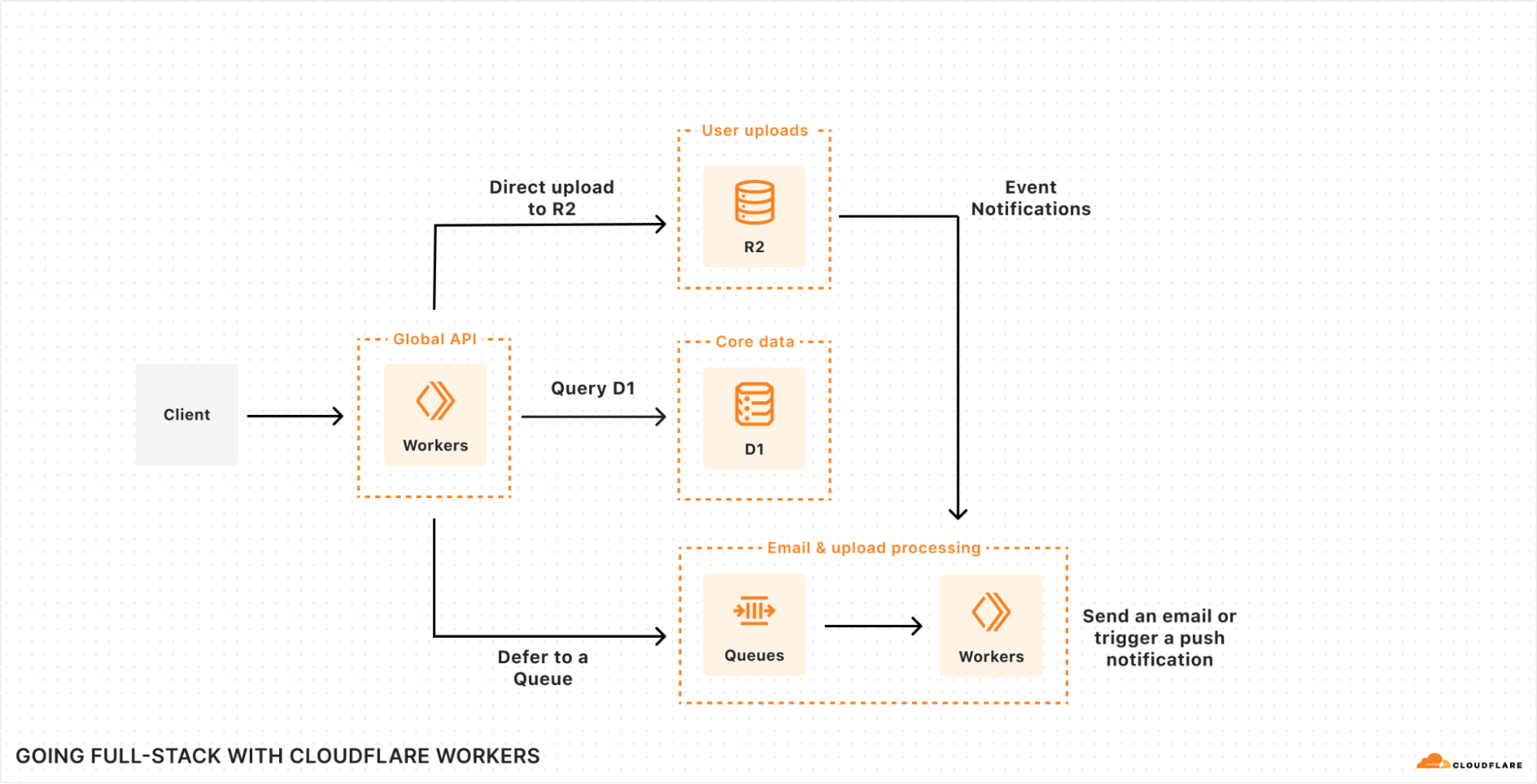
Das Diagramm selbst sollte sich nicht allzu sehr von den Tools unterscheiden, mit denen Sie bereits vertraut sind: Sie benötigen eine Datenbank für ihre zentralen Nutzerdaten. Objektspeicher für Assets und Nutzerinhalte. Vielleicht eine Warteschlange für Hintergrundaufgaben, wie E-Mail oder Upload-Verarbeitung. Ein schneller Schlüssel-Werte-Speicher für die Laufzeitkonfiguration. Vielleicht sogar eine Zeitreihendatenbank für die Aggregation von Nutzerereignissen und/oder Performance-Daten. Und das, bevor wir zu KI kommen, die zunehmend zu einem Kernbestandteil vieler Anwendungen in den Bereichen Suche, Empfehlung und/oder Bildanalyse wird (oder gar ganze Aufgaben übernimmt!).
Doch ohne darüber nachdenken zu müssen, läuft diese Architektur in der Region:Erde, was bedeutet, dass sie skalierbar, zuverlässig und schnell ist – und das von Haus aus.
D1 ist allgemein verfügbar und einsatzbereit

Ihre Core-Datenbank ist einer der wichtigsten Bestandteile Ihrer Infrastruktur. Sie muss extrem zuverlässig sein. Sie darf keine Daten verlieren. Sie muss skalierbar sein. Deshalb haben wir im letzten Jahr alles getan, um D1 einsatzbereit („production-ready“) zu machen, und wir freuen uns sehr, dass D1 — unsere globale, serverlose SQL-Datenbank — jetzt allgemein verfügbar ist.
Die allgemeine Verfügbarkeit für D1 bringt einige der am häufigsten nachgefragten Funktionen mit sich, darunter:
- Unterstützung für 10 GB Datenbanken – und 50.000 Datenbanken pro Konto;
- Neue Datenexportfunktionen; und
- Verbessertes Debugging von Abfragen (wir nennen es „D1 Insights“) – damit können Sie nachvollziehen, welche Abfragen am meisten Zeit und Kosten verbrauchen oder einfach nur ineffizient sind...
…damit Entwickler mit D1 einsatzbereite Anwendungen erstellen können, die alle ihre relationalen SQL-Anforderungen erfüllen. Und wichtig: In einer Zeit, in der das Konzept eines „kostenlosen Tarifs“ oder „Einsteigertarifs“ scheinbar in Gefahr ist, haben wir nicht vor, die kostenlose Tarifstufe für D1 abzuschaffen oder die 25 Mrd. Lesevorgänge für Zeilen zu reduzieren, die im Workers Paid-Tarif (5 $/Monat) enthalten sind:
Für diejenigen, die D1 von Anfang an verfolgt haben: dies ist der gleiche Preis, den wir bei der Open Beta angekündigt haben
Aber es bleibt nicht bei der allgemeinen Verfügbarkeit: Wir haben einige wichtige neue Funktionen für D1 geplant, darunter globale Lesereplikation, noch größere Datenbanken, mehr Time Travel-Funktionen mit denen Sie Ihre Datenbank verzweigen können, und neue APIs für die dynamische Abfrage und/oder Erstellung neuer Datenbanken spontan aus einem Worker heraus.
Die Lesereplikation von D1 stellt bei Bedarf automatisch Lesereplikate bereit, um die Daten näher an Ihre Nutzer zu bringen: und zwar ohne, dass Sie eine Instanz hochfahren, die Skalierung verwalten müssen oder Konsistenzprobleme (Replikationsverzögerung) erleben. Hier sehen Sie eine kleine Vorschau auf die kommende Replikations-API von D1:
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Wichtig ist, dass wir den Entwicklern die Möglichkeit geben, die sitzungsbasierte Konsistenz aufrechtzuerhalten. Dadurch sehen die Nutzer immer noch ihre eigenen Änderungen, während sie gleichzeitig von den Performance- und Latenzvorteilen profitieren, die die Replikation mit sich bringen kann.
Mehr darüber, wie die Lesereplikation von D1 aus technischer Perspektive funktioniert, erfahren Sie in unserem vertiefenden Blog-Beitrag. Wenn Sie noch heute erste Schritte in der Entwicklung mit D1 setzen möchten, besuchen Sie unsere Entwicklerdokumentation, um Ihre erste Datenbank zu erstellen.
Hyperdrive: allgemein verfügbar

Wir haben Hyperdrive im September des letzten Jahres während der Birthday Week in die offene Beta-Phase überführt, und jetzt ist es allgemein verfügbar – oder mit anderen Worten, umfangreich getestet und einsatzbereit.
Falls Sie noch nicht wissen, was Hyperdrive ist: Es wurde entwickelt, damit Ihre zentralisierten Datenbanken global wirken. Wir nutzen unser globales Netzwerk, um schnellere Verbindungen zu Ihrer Datenbank herzustellen, Verbindungspools aufrechtzuerhalten und Ihre am häufigsten ausgeführten Abfragen so nah wie möglich am Nutzer zwischenzuspeichern.
Wichtig ist, dass Hyperdrive die gängigsten Treiber und ORM-Bibliotheken (Object Relational Mapper) von Haus aus unterstützt, sodass Sie Ihre Abfragen nicht neu erlernen oder schreiben müssen:
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
Doch die Arbeit an Hyperdrive hört nicht auf, nur weil es jetzt allgemein verfügbar ist. In den nächsten Monaten werden wir die Unterstützung für die andere meistverbreitete Datenbank-Engine einführen: MySQL. Wir werden auch Unterstützung für die Verbindung zu Datenbanken in privaten Netzwerken (einschließlich Cloud VPC-Netzwerken) über Cloudflare Tunnel und Magic WAN anbieten. Darüber hinaus planen wir, die Konfigurierbarkeit von Invalidierungs- und Caching-Strategien zu verbessern, sodass Sie präzisere Entscheidungen in Bezug auf Performance und Datenaktualität treffen können.
Als wir über die Preisgestaltung für Hyperdrive nachdachten, wurde uns klar, dass wir dafür keine Gebühren verlangen sollten. Denn die Performance-Vorteile von Hyperdrive sind nicht nur beträchtlich, sondern für die Verbindung mit herkömmlichen Datenbank-Engines unerlässlich. Ohne Hyperdrive ist der Latenzaufwand von mehr als 6 Roundtrips zur Verbindung und Abfrage Ihrer Datenbank pro Anfrage einfach nicht angemessen.
Deshalb freuen wir uns, Ihnen mitteilen zu können, dass Hyperdrive für alle Entwickler mit einem Workers Paid-Tarif kostenlos ist. Das beinhaltet sowohl Abfrage-Caching und das Pooling von Verbindungen als auch die Möglichkeit, mehrere Hyperdrives zu erstellen – um verschiedene Anwendungen zu trennen, z. B. prod vs. staging, oder um verschiedene Konfigurationen bereitzustellen (z. B. zwischengespeichert vs. nicht-zwischengespeichert).
Um die ersten Schritte mit Hyperdrive zu unternehmen, schauen Sie sich die Dokumentation an, um zu erfahren, wie Sie Ihre bestehende Datenbank verbinden und von Ihren Workern aus abfragen können.
Warteschlangen: Von überall her abrufen
Die Aufgaben-Warteschlange ist ein zunehmend wichtiger Bestandteil beim Aufbau einer modernen, umfassenden Anwendung. Das hatten wir im Sinn, als wir ursprünglich die offene Beta von Queues ankündigten. Seitdem haben wir an mehreren wichtigen Queues-Funktionen gearbeitet. Zwei davon stellen wir diese Woche vor: Pull-basierte Verbraucher und neue Steuerelemente für die Nachrichtenübermittlung.
Jeder HTTP-sprechende Client kann jetzt Nachrichten aus einer Warteschlange abrufen: Rufen Sie den neuen /pull-Endpunkt einer Warteschlange auf, um einen Stapel von Nachrichten anzufordern, und rufen Sie den /ack-Endpunkt auf, um jede Nachricht (oder jeden Stapel von Nachrichten) zu bestätigen, wenn Sie sie erfolgreich verarbeitet haben:
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
Ein Pull-basierter Verbraucher kann überall laufen, so dass Sie Warteschlangen-Verbraucher neben Ihrer bestehenden älteren Cloud-Infrastruktur betreiben können. Die Teams bei Cloudflare haben dies schon früh übernommen. Ein Anwendungsfall konzentrierte sich auf das Schreiben von Gerätetelemetrie in eine Warteschlange aus unseren über 310 Rechenzentren und die Nutzung innerhalb einiger unserer hausinternen Infrastrukturen, die auf Kubernetes laufen. Wichtig ist, dass unsere global verteilte Warteschlangen-Infrastruktur bewirkt, dass die Nachrichten in der Warteschlange verbleiben, bis der Verbraucher bereit ist, sie zu verarbeiten.
Queues unterstützen jetzt auch die Verzögerung von Nachrichten, sowohl beim Senden an eine Warteschlange als auch beim Markieren einer Nachricht zur Wiederholung. Dies kann nützlich sein, um Aufgaben für die Zukunft in eine Warteschlange zu stellen und einen Backoff-Mechanismus anzuwenden, wenn eine vorgelagerte API oder Infrastruktur Durchsatzbeschränkungen hat, die es erforderlich machen, die Geschwindigkeit der Verarbeitung von Nachrichten zu begrenzen.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
In den kommenden Monaten werden wir außerdem den Durchsatz pro Warteschlange erheblich steigern, um Queues zur GA zu bringen. Es ist uns wichtig, dass Queues extrem zuverlässig ist: Wenn Nachrichten verloren gehen oder gelöscht werden, bedeutet dies, dass ein Nutzer seine Anforderungsbestätigung, die Benachrichtigung zum Zurücksetzen des Passworts und/oder die Verarbeitung seiner Uploads nicht erhält – all dies hat Auswirkungen auf den Nutzer und ist schwer zu beheben.

Workers Analytics Engine ist allgemein verfügbar
Die Workers Analytics Engine bietet Analysen mit unbegrenzter Kardinalität im großen Stil, über eine integrierte API zum Schreiben von Datenpunkten aus Workers und eine SQL-API zur Abfrage dieser Daten.
Die Workers Analytics Engine wird von demselben ClickHouse-basierten System unterstützt, auf das wir uns bei Cloudflare seit Jahren verlassen. Wir verwenden sie selbst, um den Zustand unserer eigenen Dienste zu beobachten, um Produktnutzungsdaten für die Rechnungsstellung zu erfassen und um Fragen zum Nutzungsverhalten bestimmter Kunden zu beantworten. Bei fast jeder Anfrage an das Netzwerk von Cloudflare wird mindestens ein Datenpunkt in dieses System geschrieben. Mit der Workers Analytics Engine können Sie Ihre eigenen benutzerdefinierten Analysen erstellen, indem Sie dieselbe Infrastruktur nutzen, während wir die schwierigen Aufgaben für Sie übernehmen.
Seit dem Start der Beta-Version verlassen sich Entwickler auf Workers Analytics Engine für dieselben Anwendungsfälle und mehr, von großen Unternehmen bis hin zu Open-Source-Projekten wie Counterscale. Die Workers Analytics Engine wird schon seit Jahren im großen Stil mit geschäftskritischen Workloads betrieben – aber wir haben bis heute nichts über die Preisgestaltung verraten.
Wir halten die Preise für Workers Analytics Engine einfach und orientieren uns an zwei Metriken:
- Geschriebene Datenpunkte — jedes Mal, wenn Sie writeDataPoint() in einem Worker aufrufen, zählt dies als ein geschriebener Datenpunkt. Jeder Datenpunkt kostet den gleichen Betrag – im Gegensatz zu anderen Plattformen gibt es keine Strafe für das Hinzufügen von Dimensionen oder Kardinalität und keine Notwendigkeit, die Größe und Kosten eines komprimierten Datenpunkts vorherzusagen.
- Leseabfragen — jedes Mal, wenn Sie an die Workers Analytics Engine SQL API senden, zählt dies als eine Leseabfrage. Jede Abfrage kostet den gleichen Betrag – im Gegensatz zu anderen Plattformen gibt es keine Strafe für die Komplexität der Abfrage und Sie müssen sich keine Gedanken über die Anzahl der Datenzeilen machen, die von jeder Abfrage gelesen werden.
Sowohl die Workers Free- als auch die Workers Paid-Tarife beinhalten eine Zuteilung von Datenpunkten für geschriebene und gelesene Abfragen, wobei die Preise für zusätzliche Nutzung wie folgt sind:
Mit dieser Preisgestaltung können Sie die Frage „Wie viel wird mich die Workers Analytics Engine kosten?“ beantworten, indem Sie zählen, wie oft Sie eine Funktion in Ihrem Worker aufrufen und wie oft Sie eine Anfrage an einen HTTP-API-Endpunkt stellen. Überschlagsmäßige Rechnung anstatt Tabellenkalkulation.
Diese Preise werden in den kommenden Monaten für alle verfügbar sein. Bis dahin ist Workers Analytics Engine weiterhin kostenlos verfügbar. Sie können noch heute damit beginnen, Datenpunkte von Ihrem Worker zu schreiben — es dauert nur ein paar Minuten und benötigt weniger als 10 Zeilen Code, um mit der Datenerfassung zu beginnen. Wir möchten gerne Ihre Meinung hören.
Die Woche fängt gerade erst an
Wenn Sie Fragen haben oder etwas Cooles zeigen möchten, das Sie bereits entwickelt haben, treten Sie bitte unserem Discord-Kanal für Entwickler bei.