





Willkommen zum KI-Tag unserer Developer Week 2024! In diesem Blogbeitrag geben wir einen Überblick über unsere neuen KI-Produkte und diesbezüglichen Pläne. Dazu gehören die allgemeine Verfügbarkeit von Workers AI mit optimierter Preisgestaltung, ein Update der GPU-Hardware, eine Erweiterung unserer Partnerschaft mit Hugging Face, eine Feinabstimmung der Inferenz im Bring Your Own LoRA-Modell, Python-Unterstüzung bei Workern, eine Erhöhung der Anbieterzahl in AI Gateway und Metadatenfilterung bei Vectorize.
Allgemeine Verfügbarkeit von Workers AI
Wir geben bekannt, dass unsere Inferenzplattform Workers AI ab sofort allgemein verfügbar ist. Nach einer mehrmonatigen Open Beta-Phase haben wir die Zuverlässigkeit und Performance des Diensts optimiert, die Tarife veröffentlicht und viele weitere Modelle in unseren Katalog aufgenommen.
Höhere Performance und größere Zuverlässigkeit
Wir haben uns das Ziel gesetzt, KI-Inferenz mit Workers AI so zuverlässig und benutzerfreundlich zu gestalten wie das übrige Cloudflare-Netzwerk. Dazu haben wir die in Workers AI integrierte Lastverteilung optimiert. Anfragen können nun an mehr GPU in einer größeren Zahl von Städten weitergeleitet werden und jeder dieser Standorte kennt die gesamte verfügbare KI-Inferenzkapazität. Würde die Anfrage in der aktuellen Stadt in einer Warteschlange landen, kann sie stattdessen an einen anderen Standort weitergeleitet werden, sodass bei hohem Trafficaufkommen schneller Ergebnisse ausgegeben werden können. Außerdem haben wir das Limit der Durchsatzbegrenzung für alle unsere Modelle angehoben – für die meisten LLM liegt die Obergrenze jetzt bei 300 Anfragen pro Minute, gegenüber 50 Anfragen pro Minute in der Beta-Phase. Bei kleineren Modellen beträgt das Limit 1500–3000 Anfragen pro Minute. In der Entwickler-Dokumentation finden Sie die Limits für die Durchsatzbegrenzung der verschiedenen Modelle.
Beliebte Modelle werden günstiger
Abgesehen von der allgemeinen Verfügbarkeit von Workers AI haben wir Anfang des Monats einen Preisrechnerhttps://ai.cloudflare.com/ - pricing-calculator für unsere zehn Nicht-Beta-Modelle veröffentlicht. Wir wollten Workers AI zu einer der erschwinglichsten und am besten zugänglichen Inferenz-Lösungen machen. Deshalb haben wir unsere Modelle auf Erschwinglichkeit hin optimiert. So ist Llama 2 jetzt mehr als siebenmal billiger und Mistral 7B mehr als vierzehnmal günstiger im Betrieb als von uns am 1. März angegeben. Wir wollen auch in Zukunft die beste Plattform für KI-Inferenz sein und werden unseren Kunden weiterhin Optimierungen anbieten, wann immer dies möglich ist.
Zur Erinnerung: Seit dem 1. April sind unsere Nicht-Beta-Modelle von Workers AI kostenpflichtig. Die Beta-Modelle sind aber weiterhin kostenlos und unbegrenzt. Wir bieten allen Kunden 10.000 Neuronen pro Tag gratis an. Workers Free-Kunden, die innerhalb von 24 Stunden 10.000 Neuronen verwenden, haben damit ihr Kontingent erschöpft. Für Kunden, die eine kostenpflichtige Workers-Version verwenden, fällt bei Erreichung dieser Grenze eine Nutzungsgebühr von 0,011 US-Dollar für jeweils 1.000 zusätzliche Neuronen an. Die aktuelle Preisgestaltung können Sie der entsprechenden Entwickler-Dokumentation für Workers AI entnehmen.
Neues Dashboard und neuer Experimentierbereich
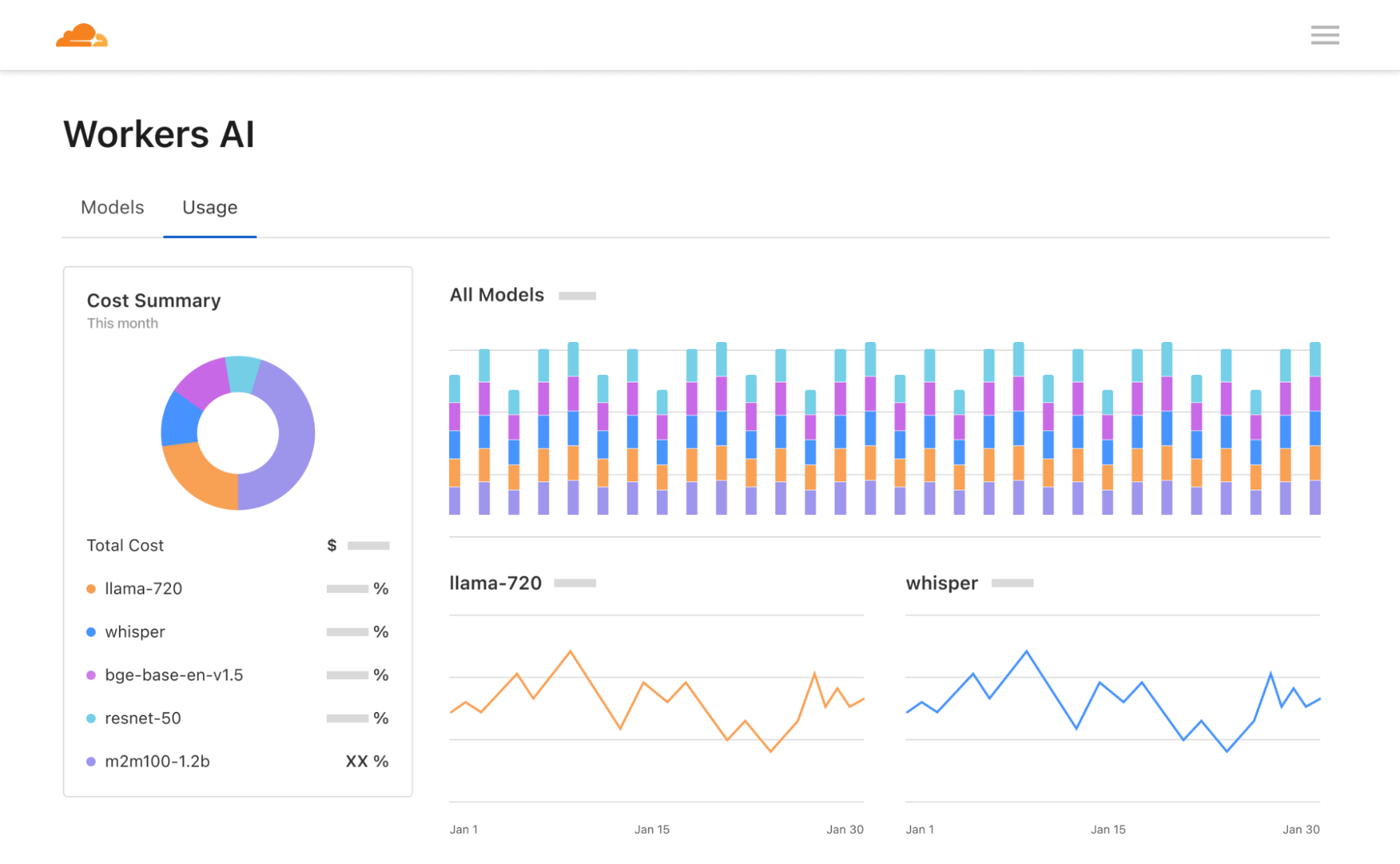
Zu guter Letzt haben wir das Dashboard von Workers AI und unseren AI-Experimentierbereich überarbeitet. Im Workers AI-Bereich des Dashboards von Cloudflare werden jetzt Nutzungsanalysen für alle Modelle angezeigt. Dazu zählen auch Neuronenberechnungen, anhand derer sich die Kosten besser vorhersagen lassen. Mit dem KI-Experimentierbereich können verschiedene Modelle schnell getestet und miteinander verglichen werden. Außerdem lassen sich damit Prompts und Parameter konfigurieren. Wir hoffen, dass diese neuen Tools Entwicklern die Arbeit auf Workers AI erleichtern. Probieren Sie sie doch einfach einmal aus!
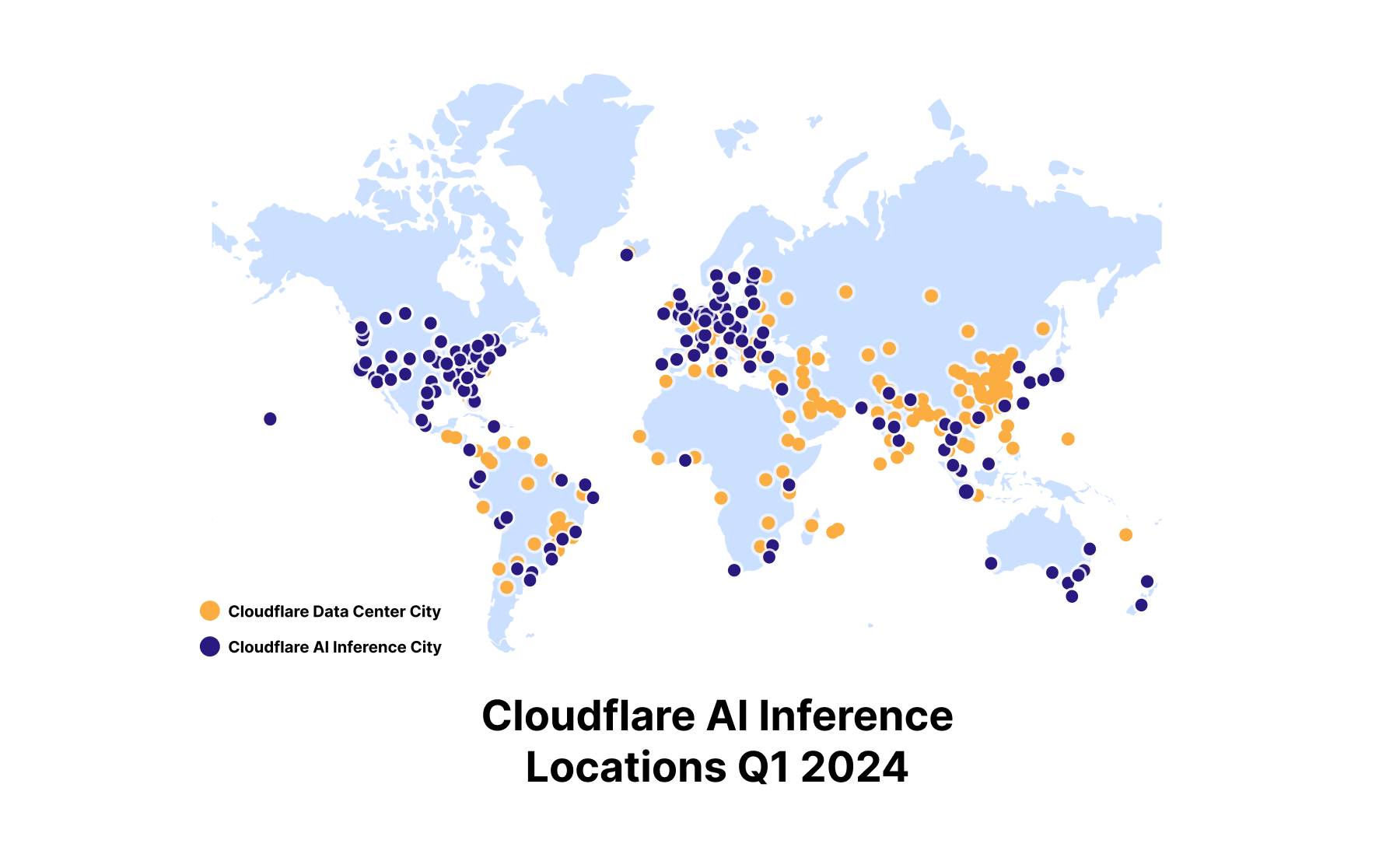
Ausführung von Inferenzaufgaben auf GPU in über 150 Städten weltweit
Als wir im September 2023 Workers AI vorgestellt haben, war unser Folgeziel, in unseren Rechenzentren auf der ganzen Welt GPU einzusetzen. Bis Ende 2024 wollen wir fast überall GPU mit Inferenzfunktion verwenden, was uns zu der cloudbasierten KI-Inferenzplattform mit der größten Verteilung macht. Aktuell verfügen Standorte in mehr als 150 Städten über GPU und im Lauf des Jahres werden noch weitere Städte hinzukommen.
Unsere nächste Generation von Compute-Servern mit GPU kommt im zweiten Quartal 2024 auf den Markt. Sie bietet eine höhere Performance, Energieeffizienz und Zuverlässigkeit als Vorgänger-Generationen. In einem Blogbeitrag vom Dezember 2023 haben wir einen Ausblick auf das Design unserer Compute-Server der 12. Generation gegeben. Weitere Details werden folgen. In Bezug auf die 12. Generation und zukünftige Hardware-Einführungen wollen wir als Nächstes Unterstützung für größere Machine Learning-Modelle und Feinabstimmung (Fine-Tuning) auf unserer Plattform anbieten. Dadurch werden wir einen höheren Durchsatz bei der Inferenz, eine geringe Latenz und eine größere Verfügbarkeit für Produktiv-Workloads erreichen und die Unterstützung auf neue Kategorien von Workloads wie Fine-Tuning ausweiten.
Partnerschaft mit Hugging Face

Wir freuen uns außerdem über die Fortsetzung unserer Partnerschaft mit Hugging Face, weil wir damit unserem Prinzip treu bleiben, unseren Kunden das Beste aus dem Bereich Open-Source anzubieten. Sie können sich jetzt einige der beliebtesten Modelle auf Hugging Face ansehen. Wenn das von Ihnen gewünschte Modell auf unserer Plattform verfügbar ist, brauchen Sie es nur anzuklicken, um es auf Workers AI auszuführen.
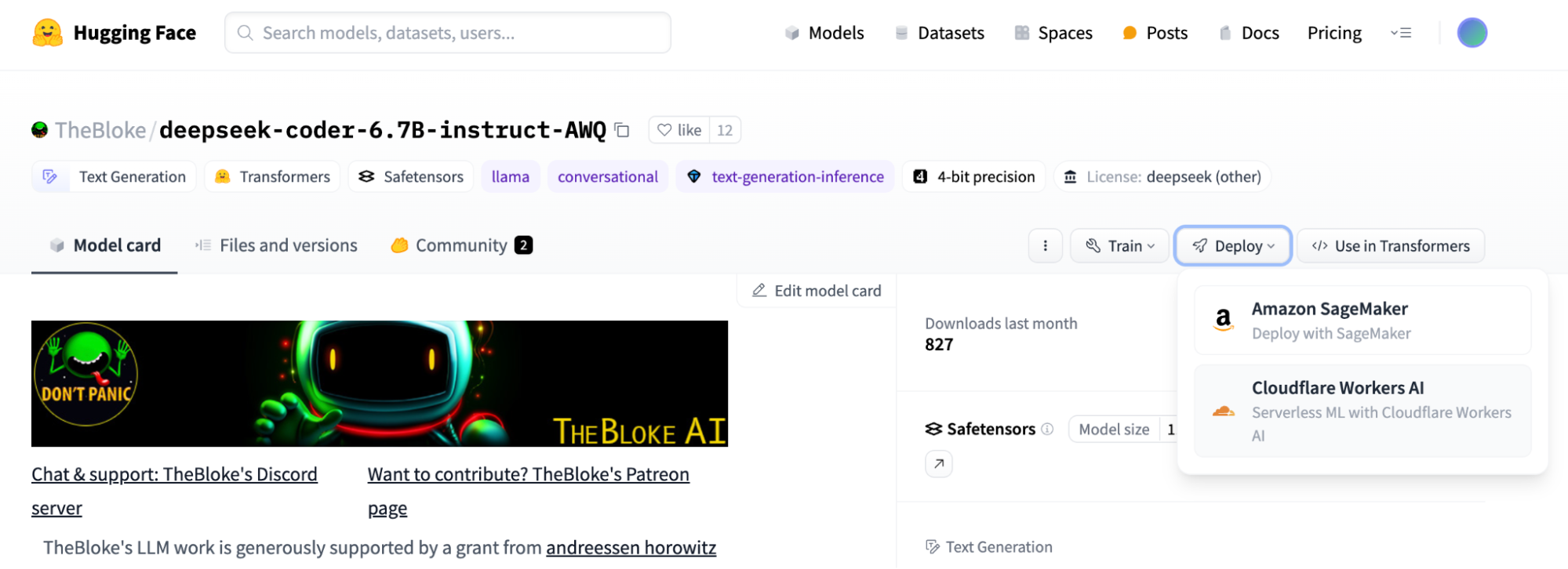
Darüber hinaus haben wir im Rahmen unserer Kooperation mit Hugging Face vier weitere Modelle in unsere Plattform aufgenommen. Damit können Sie nun auf das neue Mistral 7B v0.2-Modell mit verbesserten Kontextfenstern, die feinjustierte Version von Mistral 7B von Hermes 2 Pro der Firma Nous Research, Gemma 7B von Google und die fein abgestimmte Starling-LM-7B-Betaversion von OpenChat zugreifen. Derzeit stehen für Serverless-GPU-Inferenz auf der Workers AI-Plattform von Cloudflare 14 Modelle zur Verfügung, die wir alle gemeinsam mit Hugging Face ausgewählt haben. Weitere werden bald folgen. Diese Modelle werden alle mit der Technologie von Hugging Face und einem TGI-Backend bereitgestellt. Wir arbeiten bei der Kuratierung, Optimierung und Bereitstellung dieser Modelle eng mit dem Team von Hugging Face zusammen.
„Wir freuen uns, gemeinsam mit Cloudflare auf eine bessere Zugänglichkeit von KI für Entwicklerinnen und Entwickler hinzuarbeiten. Die beliebtesten frei zugänglichen Modelle mit einer Serverless-API nutzen zu können, die auf ein globales GPU-Netz zurückgreifen kann, ist ein fantastisches Angebot für die Hugging Face-Community. Ich bin schon gespannt, was diese damit alles erschaffen wird.“‑ Julien Chaumond, Mitgründer und CTO von Hugging Face
Sie finden alle von Workers AI unterstützen, frei verfügbaren Modelle in dieser Hugging Face-Sammlung. Die Schaltfläche „Deploy to Cloudflare Workers AI“ befindet sich oben auf jeder Modellkarte. Mehr erfahren Sie in diesem Blogbeitrag von Hugging Face. Hilfreich für den Einstieg ist auch unsere Entwickler-Dokumentation. Sie vermissen ein bestimmtes Modell auf Workers AI? Dann lassen Sie es uns bei Discord wissen.
Unterstützung feinjustierter Inferenz mit BYO LoRA
Eine der am häufigsten geforderten Funktionen für Workers AI ist eine feinjustierte Inferenz. Mit Bring Your Own (BYO) Low Rank Adaptation (LoRA) sind wir diesem Ziel jetzt einen Schritt nähergekommen. Mithilfe der beliebten Low Rank Adaptation-Methode haben Forscher herausgefunden, wie sich einige Parameter eines Modells an die jeweilige Aufgabe anpassen lassen, anstatt – wie bei einem vollständigen Fine-Tuning eines Modells – alle Modellparameter neu schreiben zu müssen. Somit erhält man feinjustierte Ergebnisse ohne den für eine vollständige Feinjustierung erforderlichen Rechenaufwand.
Ab sofort unterstützt Workers AI trainierte LoRA. Die LoRA-Anpassung wird während der Laufzeit auf ein Basismodell angewandt, wodurch die Ausführung von Inferenzaufgaben fein abgestimmt werden kann – und das mit der Geschwindigkeit eines Modells, das einem vollständigen Fine-Tuning unterzogen wurde, aber zu einem Bruchteil von dessen Kosten und Größe. Zu gegebener Zeit wollen wir Feinabstimmung und vollständig feinjustierte Modelle direkt auf unserer Plattform unterstützen. LoRa bringt uns diesem Ziel einen Schritt näher.
const response = await ai.run(
"@cf/mistralai/mistral-7b-instruct-v0.2-lora", //the model supporting LoRAs
{
messages: [{"role": "user", "content": "Hello world"],
raw: true, //skip applying the default chat template
lora: "00000000-0000-0000-0000-000000000", //the finetune id OR name
}
);
„BYO LoRA“ befindet sich für die Modelle Gemma 2B und 7B, Llama 2 7B und Mistral 7B seit heute in der Open Beta-Phase. Verfügbar sind in diesem Rahmen LoRA-Adapter mit einer Größe von bis zu 100 MB und einem maximalen Rang von 8 sowie insgesamt bis zu 30 LoRA pro Konto. Wie immer sind Workers AI und unsere neue „BYO LoRA“-Funktion unter Einhaltung unserer Nutzungsbedingungen zu verwenden. Dies beinhaltet auch alle in den Lizenzbedingungen der einzelnen Modelle festgelegten modellspezifischen Nutzungsbeschränkungen.
Beim Einstieg hilft Ihnen dieser technisch vertiefende Blogbeitrag und die Entwickler-Dokumentation.
Programmierung von Workern in Python
Python ist die nach JavaScript beliebteste Programmiersprache der Welt und die Sprache der Wahl für das Entwickeln von KI-Anwendungen. Ab heute können Sie in der Open Beta-Version Cloudflare-Worker in Python programmieren. Python-Worker unterstützen alle Ressourcen-Bindungen an Cloudflare, einschließlich Vectorize, D1, KV und R2.
LangChain ist das populärste Framework für die Erstellung LLM-gesteuerter Anwendungen, und so wie Workers AI mit langchain-js funktioniert, so funktioniert die Python LangChain-Bibliothek mit Python-Workern, ebenso wie andere Python-Pakete wie FastAPI.
In Python programmierte Worker sind ebenso unkompliziert wie solche, die in JavaScript geschrieben sind:
from js import Response
async def on_fetch(request, env):
return Response.new("Hello world!")
Zur Konfigurierung wird einfach auf eine .py-Datei in Ihrer wrangler.toml-Datei verwiesen:
name = "hello-world-python-worker"
main = "src/entry.py"
compatibility_date = "2024-03-18"
compatibility_flags = ["python_workers"]Weitere Toolchain- oder Vorkompilierungsschritte sind nicht erforderlich. Die Pyodide-Python-Ausführungsumgebung wird Ihnen direkt von der Workers-Laufzeitumgebung zur Verfügung gestellt, wobei die Funktionsweise die von in JavaScript programmierten Workern widerspiegelt.
Wenn Sie noch tiefer in die Materie einsteigen und erfahren möchten, wie Python-Worker im Hintergrund arbeiten, werfen Sie doch einfach einen Blick in unsere Dokumentation und lesen Sie unseren begleitenden Blogbeitrag.
Unterstützung von Anthropic, Azure, AWS Bedrock, Google Vertex und Perplexity bei AI Gateway

AI Gateway hilft Entwicklern unter anderem mit Analysen, Zwischenspeicherung und Durchsatzbegrenzung dabei, ihre KI-Anwendungen besser zu steuern und zu beobachten. Wir integrieren kontinuierlich neue Anbieter in das Produkt. Die neuesten sind Anthropic, Google Vertex und Perplexity, wie wir heute bekannt geben können. Im Dezember 2023 haben wir in aller Stille die Unterstützung von Azure und Amazon Bedrock eingeführt, sodass die beliebtesten Anbieter nun von AI Gateway unterstützt werden, was auch Workers AI selbst umfasst.
Werfen Sie doch einen Blick in unsere Entwickler-Dokumentation, um mit AI Gateway loszulegen.
Dauerhafte Protokolle demnächst verfügbar
Im zweiten Quartal 2024 werden wir dauerhafte Protokolle einführen, was es Ihnen erlauben wird, Ihre Protokolle (einschließlich Prompts und Antworten) in den Objektspeicher zu verschieben. Hinzu kommen außerdem benutzerdefinierte Metadaten, damit Sie Anfragen mit Nutzer-ID oder anderen Identifikatoren versehen können, und die Verwaltung sensibler Daten (Secrets) für den sicheren Umgang mit den API-Schlüsseln Ihrer Anwendung.
Wir möchten, dass Sie Ihre KI-Anwendung über AI Gateway steuern können und Ihre Entwickler in der Lage sind, damit Anfragen dynamisch zu bewerten und an verschiedene Modelle und Anbieter weiterzuleiten. Mit unseren dauerhaften Protokollen sollen Entwickler die Möglichkeit haben, ihre protokollierten Daten mit einem einzigen Klick zur Feinabstimmung von Modellen einzusetzen. Letzten Endes sollen die Aufgabe des Fine-Tuning und das feinjustierte Modell direkt auf unserer Plattform Workers AI ausgeführt werden können. AI Gateway ist nur eines von zahlreichen Produkten in unserem KI-Toolkit, aber wir sind begeistert von den Arbeitsabläufen und Anwendungsfällen, die mit unserer Plattform arbeitenden Entwicklern damit offenstehen. Wir hoffen, dass es Ihnen genauso geht.
Filterung von Vectorize-Metadaten und künftige allgemeine Verfügbarkeit von Millionen Vektorindizes
Vectorize ist eine weitere Komponente unseres Toolkits für KI-Anwendungen und befindet sich seit September 2023 in der Open Beta-Phase. Die Lösung ermöglicht es Entwicklern, zur Unterstützung von Anwendungsfällen wie der Ähnlichkeitssuche oder Empfehlungen Einbettungen (Vektoren), wie sie etwa von Texteinbettungsmodellen von Workers AI generiert werden, zu speichern und nach dem Treffer mit der größten Übereinstimmung zu suchen. Die von Modellen ausgegebenen Ergebnisse geraten ohne eine Vektordatenbank in Vergessenheit und können nicht ohne zusätzliche Kosten für die erneute Ausführung eines Modells abgerufen werden.
Seit Einführung der Open Beta-Version von Vectorize haben wir diese um eine Metadaten-Filterung erweitert. Dank dieser Funktion können Entwickler die Vektorsuche mit der Filterung nach beliebigen Metadaten kombinieren, was eine höhere Abfragekomplexität bei KI-Anwendungen erlaubt. Aktuell arbeiten wir daran, Vectorize allgemein verfügbar zu machen. Wir streben eine Einführung im Juni 2024 mit Unterstützung mehrerer Millionen von Vektor-Indizes an.
// Insert vectors with metadata
const vectors: Array<VectorizeVector> = [
{
id: "1",
values: [32.4, 74.1, 3.2],
metadata: { url: "/products/sku/13913913", streaming_platform: "netflix" }
},
{
id: "2",
values: [15.1, 19.2, 15.8],
metadata: { url: "/products/sku/10148191", streaming_platform: "hbo" }
},
...
];
let upserted = await env.YOUR_INDEX.upsert(vectors);
// Query with metadata filtering
let metadataMatches = await env.YOUR_INDEX.query(<queryVector>, { filter: { streaming_platform: "netflix" }} )
Die umfassendste Entwicklerplattform zur Erstellung von KI-Anwendungen
Wir sind wir der Meinung, dass alle Entwickler Full-Stack-Anwendungen, einschließlich KI-gestützter Funktionen, schnell erschaffen und bereitstellen können sollten. Durch die allgemeine Verfügbarkeit von Workers AI, die Python-Unterstützung bei Workern, die Verfügbarkeit von AI Gateway und Vectorize sowie unsere Partnerschaft mit Hugging Face haben wir die Möglichkeiten für die Entwicklung von Produkten mithilfe von KI auf unserer Plattform erweitert. Wir hoffen, dass Sie davon genauso angetan sind wie wir! Werfen Sie für Ihre ersten Schritte doch einfach einen Blick in unsere Entwickler-Dokumentation. Sie können uns auch gern wissen lassen, woran Sie arbeiten.