

Background
We run many backend services that power our customer dashboard, APIs, and features available at our edge. We own and operate physical infrastructure for our backend services. We need an effective way to route arbitrary TCP and UDP traffic between services and also from outside these data centers.
Previously, all traffic for these backend services would pass through several layers of stateful TCP proxies and NATs before reaching an available instance. This solution worked for several years, but as we grew it caused our service and operations teams many issues. Our service teams needed to deal with drops of availability, and our operations teams had much toil when needing to do maintenance on load balancer servers.
Goals
With the experience with our stateful TCP proxy and NAT solutions in mind, we had several goals for a replacement load balancing service, while remaining on our own infrastructure:
- Preserve source IPs through routing decisions to destination servers. This allows us to support servers that require client IP addresses as part of their operation, without workarounds such as X-Forwarded-For headers or the PROXY TCP extension.
- Support an architecture where backends are located across many racks and subnets. This prevents solutions that cannot be routed by existing network equipment.
- Allow operation teams to perform maintenance with zero downtime. We should be able to remove load balancers at any time without causing any connection resets or downtime for services.
- Use Linux tools and features that are commonplace and well-tested. There are a lot of very cool networking features in Linux we could experiment with, but we wanted to optimize for least surprising behavior for operators who do not primarily work with these load balancers.
- No explicit connection synchronization between load balancers. We found that communication between load balancers significantly increased the system complexity, allowing for more opportunities for things to go wrong.
- Allow for staged rollout from the previous load balancer implementation. We should be able to migrate the traffic of specific services between the two implementations to find issues and gain confidence in the system.
Reaching Zero Downtime
Problems
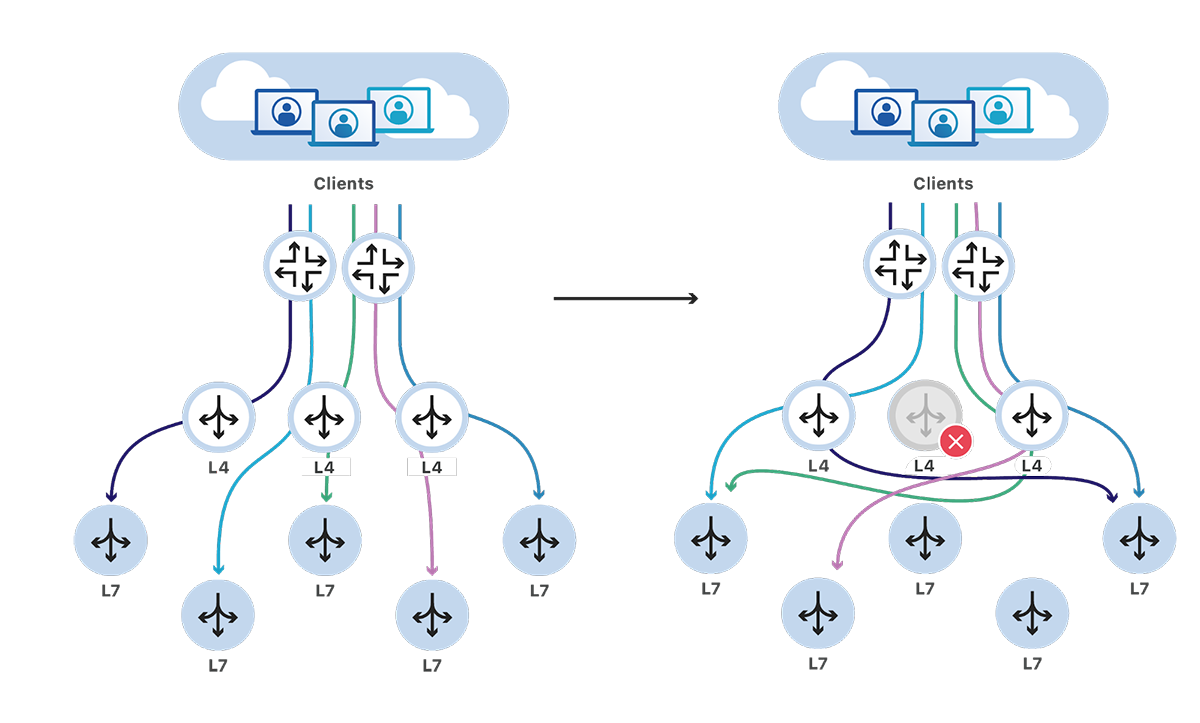
Previously, when traffic arrived at our backend data centers, our routers would pick and forward packets to one of the L4 load balancers servers it knew about. These L4 load balancers would determine what service the traffic was for, then forward the traffic to one of the service's L7 servers.
This architecture worked fine during normal operations. However, issues would quickly surface whenever the set of load balancers changed. Our routers would forward traffic to the new set and it was very likely traffic would arrive to a different load balancer than before. As each load balancer maintained its own connection state, it would be unable to forward traffic for these new in-progress connections. These connections would then be reset, potentially causing errors for our customers.
Consistent Hashing
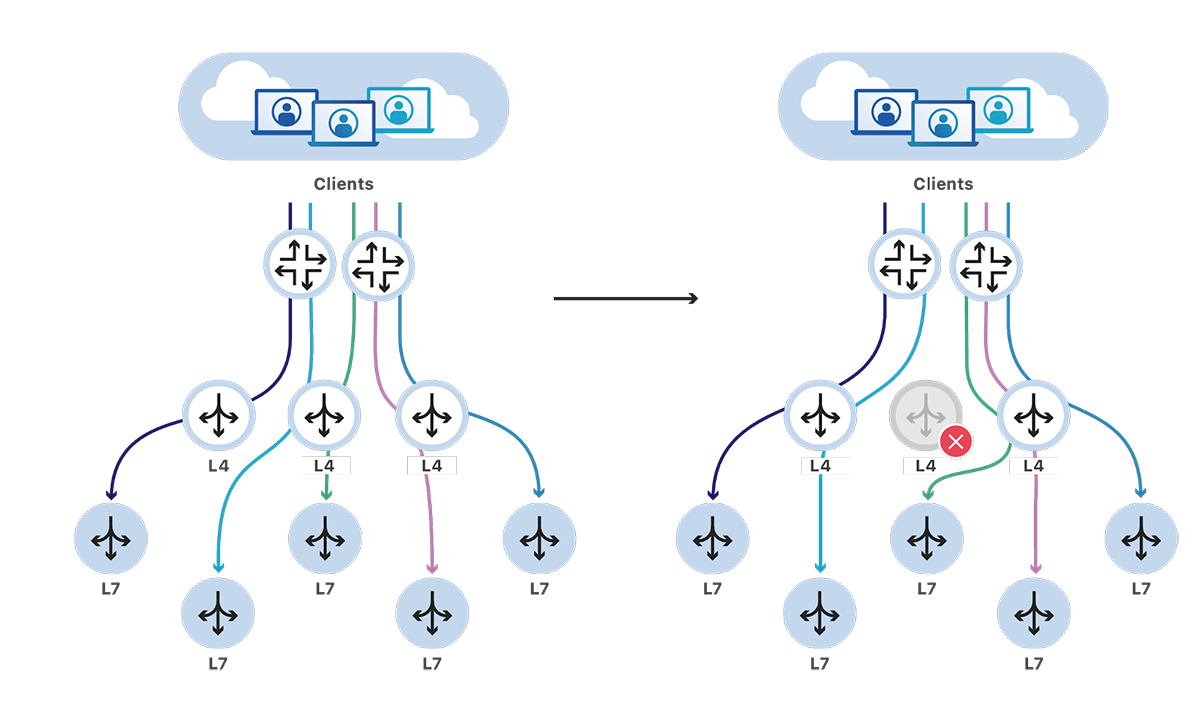
During normal operations, our new architecture has similar behavior to the previous design. A L4 load balancer would be selected by our routers, which would then forward traffic to a service's L7 server.
There's a significant change when the set of load balancers changes. As our load balancers are now stateless, it doesn't matter which load balancer our router selects to forward traffic to, they'll end up reaching the same backend server.
Implementation
BGP
Our load balancer servers announce service IP addresses to our data centers’ routers using BGP, unchanged from the previous solution. Our routers choose which load balancers will receive packets based on a routing strategy called equal-cost multi-path routing (ECMP).
ECMP hashes information from packets to pick a path for that packet. The hash function used by routers is often fixed in firmware. Routers that chose a poor hashing function, or chose bad inputs, can create unbalanced network and server load, or break assumptions made by the protocol layer.
We worked with our networking team to ensure ECMP is configured on our routers to hash only based on the packet's 5-tuple—the protocol, source address and port, and destination address and port.
For maintenance, our operators can withdraw the BGP session and traffic will transparently shift to other load balancers. However, if a load balancer suddenly becomes unavailable, such as with a kernel panic or power failure, there is a short delay before the BGP keepalive mechanism fails and routers terminate the session.
It's possible for routers to terminate BGP sessions after a much shorter delay using the Bidirectional Forwarding Detection (BFD) protocol between the router and load balancers. Different routers have different limitations and restrictions on BFD that makes it difficult to use in an environment heavily using L2 link aggregation and VXLANs.
We're continuing to work with our networking team to find solutions to reduce the time to terminate BGP sessions, using tools and configurations they're most comfortable with.
Selecting Backends with Maglev
To ensure all load balancers are sending traffic to the same backends, we decided to use the Maglev connection scheduler. Maglev is a consistent hash scheduler hashing a 5-tuple of information from each packet—the protocol, source address and port, and destination address and port—to determine a backend server.
By being a consistent hash, the same backend server is chosen by every load balancer for a packet without needing to persist any connection state. This allows us to transparently move traffic between load balancers without requiring explicit connection synchronization between them.
IPVS and Foo-Over-UDP
Where possible, we wanted to use commonplace and reliable Linux features. Linux has implemented a powerful layer 4 load balancer, the IP Virtual Server (IPVS), since the early 2000s. IPVS has supported the Maglev scheduler since Linux 4.18.
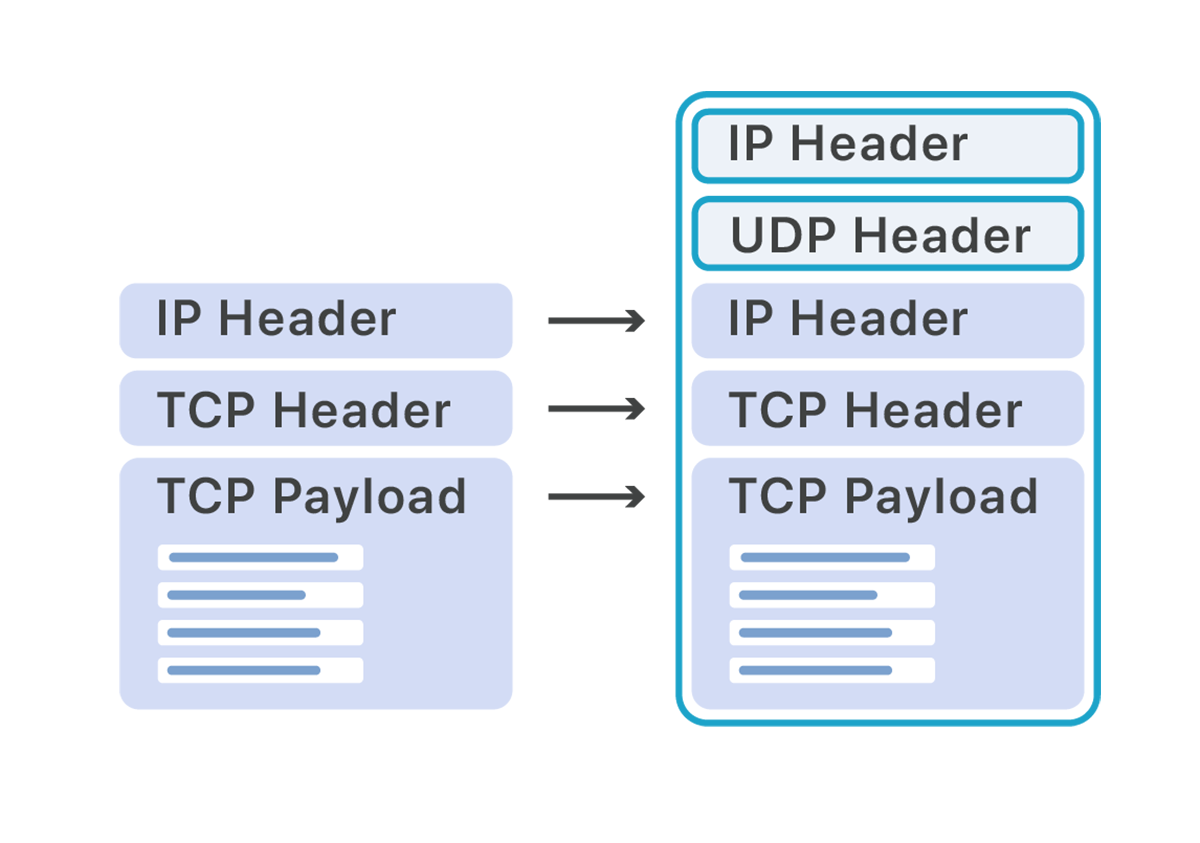
Our load balancer and application servers are spread across multiple racks and subnets. To route traffic from the load balancer we opted to use Foo-Over-UDP encapsulation.
In Foo-Over-UDP encapsulation a new IP and UDP header are added around the original packet. When these packets arrive on the destination server, the Linux kernel removes the outer IP and UDP headers and inserts the inner payload back into the networking stack for processing as if the packet had originally been received on that server.
Compared to other encapsulation methods—such as IPIP, GUE, and GENEVE—we felt Foo-Over-UDP struck a nice balance between features and flexibility. Direct Server Return, where application servers reply directly to clients and bypass the load balancers, was implemented as a byproduct of the encapsulation. There was no state associated with the encapsulation, each server only required one encapsulation interface to receive traffic from all load balancers.
Example Load Balancer Configuration
# Load in the kernel modules required for IPVS and FOU.
$ modprobe ip_vs && modprobe ip_vs_mh && modprobe fou
# Create one tunnel between the load balancer and
# an application server. The IPs are the machines'
# real IPs on the network.
$ ip link add name lbtun1 type ipip \
remote 192.0.2.1 local 192.0.2.2 ttl 2 \
encap fou encap-sport auto encap-dport 5555
# Inform the kernel about the VIPs that might be announced here.
$ ip route add table local local 198.51.100.0/24 \
dev lo proto kernel
# Give the tunnel an IP address local to this machine.
# Traffic on this machine destined for this IP address will
# be sent down the tunnel.
$ ip route add 203.0.113.1 dev lbtun1 scope link
# Tell IPVS about the service, and that it should use the
# Maglev scheduler.
$ ipvsadm -A -t 198.51.100.1:80 -s mh
# Tell IPVS about a backend for this service.
$ ipvsadm -a -t 198.51.100.1:80 -r 203.0.113.1:80
Example Application Server Configuration
# The kernel module may need to be loaded.
$ modprobe fou
# Setup an IPIP receiver.
# ipproto 4 = IPIP (not IPv4)
$ ip fou add port 5555 ipproto 4
# Bring up the tunnel.
$ ip link set dev tunl0 up
# Disable reverse path filtering on tunnel interface.
$ sysctl -w net.ipv4.conf.tunl0.rp_filter=0
$ sysctl -w net.ipv4.conf.all.rp_filter=0
IPVS does not support Foo-Over-UDP as a packet forwarding method. To work around this limitation, we've created virtual interfaces that implement Foo-Over-UDP encapsulation. We can then use IPVS's direct packet forwarding method along with the kernel routing table to choose a specific interface.
Linux is often configured to ignore packets that arrive on an interface that is different from the interface used for replies. As packets will now be arriving on the virtual "tunl0" interface, we need to disable reverse path filtering on this interface. The kernel uses the higher value of the named and "all" interfaces, so you may need to decrease "all" and adjust other interfaces.
MTUs and Encapsulation
The maximum IPv4 packet size, or maximum transmission unit (MTU), we accept from the internet is 1500 bytes. To ensure we did not fragment these packets during encapsulation we increased our internal MTUs from the default to accommodate the IP and UDP headers.
The team had underestimated the complexity of changing the MTU across all our racks of equipment. We had to adjust the MTU across all our routers and switches, of our bonded and VXLAN interfaces, and finally our Foo-Over-UDP encapsulation. Even with a carefully orchestrated rollout, and we still uncovered MTU-related bugs with our switches and server stack, many of which manifested first as issues on other parts of the network.
Node Agent
We've written a Go agent running on each load balancer that synchronizes with a control plane layer that's tracking the location of services. The agent then configures the system based on active services and available backend servers.
To configure IPVS and the routing table we're using packages built upon the netlink Go package. We're open sourcing the IPVS netlink package we built today, which supports querying, creating and updating IPVS virtual servers, destinations, and statistics.
Unfortunately, there is no official programming interface for iptables, so we must instead execute the iptables binary. The agent computes an ideal set of iptables chains and rules, which is then reconciled with the live rules.
Subset of iptables for a service
*filter
-A INPUT -d 198.51.100.0/24 -m comment --comment \
"leif:nhAi5v93jwQYcJuK" -j LEIFUR-LB
-A LEIFUR-LB -d 198.51.100.1/32 -p tcp -m comment --comment \
"leif:G4qtNUVFCkLCu4yt" -m multiport --dports 80 -j LEIFUR-GQ4OKHRLCJYOWIN9
-A LEIFUR-GQ4OKHRLCJYOWIN9 -s 10.0.0.0/8 -m comment --comment \
"leif:G4qtNUVFCkLCu4yt" -j ACCEPT
-A LEIFUR-GQ4OKHRLCJYOWIN9 -s 172.16.0.0/12 -m comment --comment \
"leif:0XxZ2OwlQWzIYFTD" -j ACCEPT
The iptables output of a rule may differ significantly from the input given by our ideal rule. To avoid needing to parse the entire iptables rule in our comparisons, we store a hash of the rule, including the position in the chain, as an iptables comment. We then can compare the comment to our ideal rule to determine if we need to take any actions. On chains that are shared (such as INPUT) the agent ignores unmanaged rules.
Kubernetes Integration
We use the network load balancer described here as a cloud load balancer for Kubernetes. A controller assigns virtual IP addresses to Kubernetes services requesting a load balancer IP. These IPs get configured by the agent in IPVS. Traffic is directed to a subset of cluster nodes for handling by kube-proxy, unless the External Traffic Policy is set to "Local" in which case the traffic is sent to the specific backends the workloads are running on.
This allows us to have internal Kubernetes clusters that better replicate the load balancer behavior of managed clusters on cloud providers. Services running Kubernetes, such as ingress controllers, API gateways, and databases, have access to correct client IP addresses of load balanced traffic.
Future Work
- Continuing a close eye on future developments of IPVS and alternatives, including nftlb and Express Data Path (XDP) and eBPF.
- Migrate to nftables. The "flat priorities" and lack of programmable interface for iptables makes it ill-suited for including automated rules alongside rules added by operators. We hope as more projects and operations move to nftables we'll be able to switch without creating a "blind-spot" to operations.
- Failures of a load balancer can result in temporary outages due to BGP hold timers. We'd like to improve how we're handling the failures with BGP sessions.
- Investigate using Lightweight Tunnels to reduce the number of Foo-Over-UDP interfaces are needed on the load balancer nodes.
Additional Reading
- Multi-tier load-balancing with Linux. Vincent Bernat (2018). Describes a network load balancer using IPVS and IPIP.
- Introducing the GitHub Load Balancer. Joe Williams, Theo Julienne (2017). Describes a similar split layer 4 and layer 7 architecture, using consistent hashing and Foo-Over-UDP. They seemed to have limitations with IPVS that looked to have been resolved.
- Foo over UDP. Jonathan Corbet (2014). Describes the basics of IPIP and Foo-Over-UDP, which was just introduced at the time.
- UDP encapsulation, FOU, GUE, & RCO. Tom Herbert (2015). Describes the different UDP encapsulation options.
- Hashing on broken assumptions. Lorenzo Saino (2017). Farther discussion on hashing difficulties with ECMP.
- BFD (Bidirectional Forwarding Detection): Does it work and is it worth it?. Tom School (2009). Discussion on BFD with common protocols and where it can become a problem.