

Aujourd'hui, une modification de notre système de mise en cache par niveau (Tiered Cache) a entraîné l'échec de certaines requêtes pour les utilisateurs avec affichage d'un code d'état 530. Les répercussions de cette panne ont duré près de six heures au total. Nous estimons qu'au pic de l'incident, environ 5 % de l'ensemble des requêtes ont renvoyé une erreur. En raison de la complexité de notre système et d'un angle mort dans nos tests, nous n'avons pas identifié cet incident lorsque la modification a été déployée dans notre environnement de test.
Les erreurs ont été causées par des effets secondaires de notre façon de traiter les requêtes mises en cache sur différents sites. À première vue, les erreurs semblaient être causées par un autre système, dont le déploiement avait commencé quelque temps auparavant. Il a fallu à nos équipes un certain nombre d'essais pour identifier exactement la cause des problèmes. Après l'avoir identifiée, nous avons lancé une restauration rapide, qui a été finalisée en 87 minutes.
Nous nous excusons, et nous prenons des dispositions pour que cela ne se reproduise pas.
Contexte
Parmi les produits de Cloudflare figure son réseau de diffusion de contenu, ou CDN (Content Delivery Network). Il est utilisé pour mettre en cache les ressources de sites web dans le monde entier. Cependant, il n'est pas garanti qu'un datacenter dispose d'une ressource mise en cache. Celle-ci peut être nouvelle, avoir expiré ou avoir été purgée. Lorsque cela se produit et qu'un utilisateur demande cette ressource, notre réseau CDN doit récupérer une nouvelle copie de la ressource sur le serveur d'origine d'un site web. Cependant, le datacenter auquel accède l'utilisateur peut encore être assez éloigné du serveur d'origine. Cela présente un problème supplémentaire pour les clients : chaque fois qu'une ressource n'est pas mise en cache dans le datacenter, nous devons récupérer une nouvelle copie sur le serveur d'origine.
Pour améliorer les taux d'accès au cache, nous avons introduit le service de mise en cache par niveau Tiered Cache. Avec Tiered Cache, nous organisons nos datacenters au sein du réseau CDN selon une hiérarchie de « niveaux inférieurs », plus proches des utilisateurs finaux, et de « niveaux supérieurs », plus proches du serveur d'origine. Lorsqu'un défaut de cache se produit à un niveau inférieur, le niveau supérieur est vérifié. Si le niveau supérieur dispose d'une copie récente de la ressource, nous pouvons la servir en réponse à la requête. Ceci améliore les performances et réduit le nombre d'occurrences dans lesquelles Cloudflare doit contacter un serveur d'origine afin de récupérer des ressources qui ne sont pas mises en cache dans les datacenters de niveau inférieur.
Chronologie et répercussions de l'incident
À 08h40 UTC, le déploiement logiciel d'un composant du réseau CDN contenant un bug a lentement débuté. Le bug se manifestait lorsqu'un utilisateur consultait un site sur lequel étaient configurés les services Tiered Cache, Cloudflare Images ou Bandwidth Alliance. Chez un sous-ensemble de ces clients, ce bug renvoyait une erreur : le code d'état HTTP 530. Le contenu pouvant être servi directement depuis le cache local d'un datacenter n'était pas affecté.
Nous avons lancé une enquête après avoir reçu des signalements de clients rapportant une augmentation intermittente du nombre d'erreurs 530 suite au lancement du composant défectueux dans un sous-ensemble de datacenters.
Lorsque le déploiement de la version a débuté dans les datacenters restants, dans le monde entier, une forte augmentation du nombre d'erreurs 530 a déclenché des alertes ainsi que de nouveaux signalements de clients, et un incident a été déclaré.
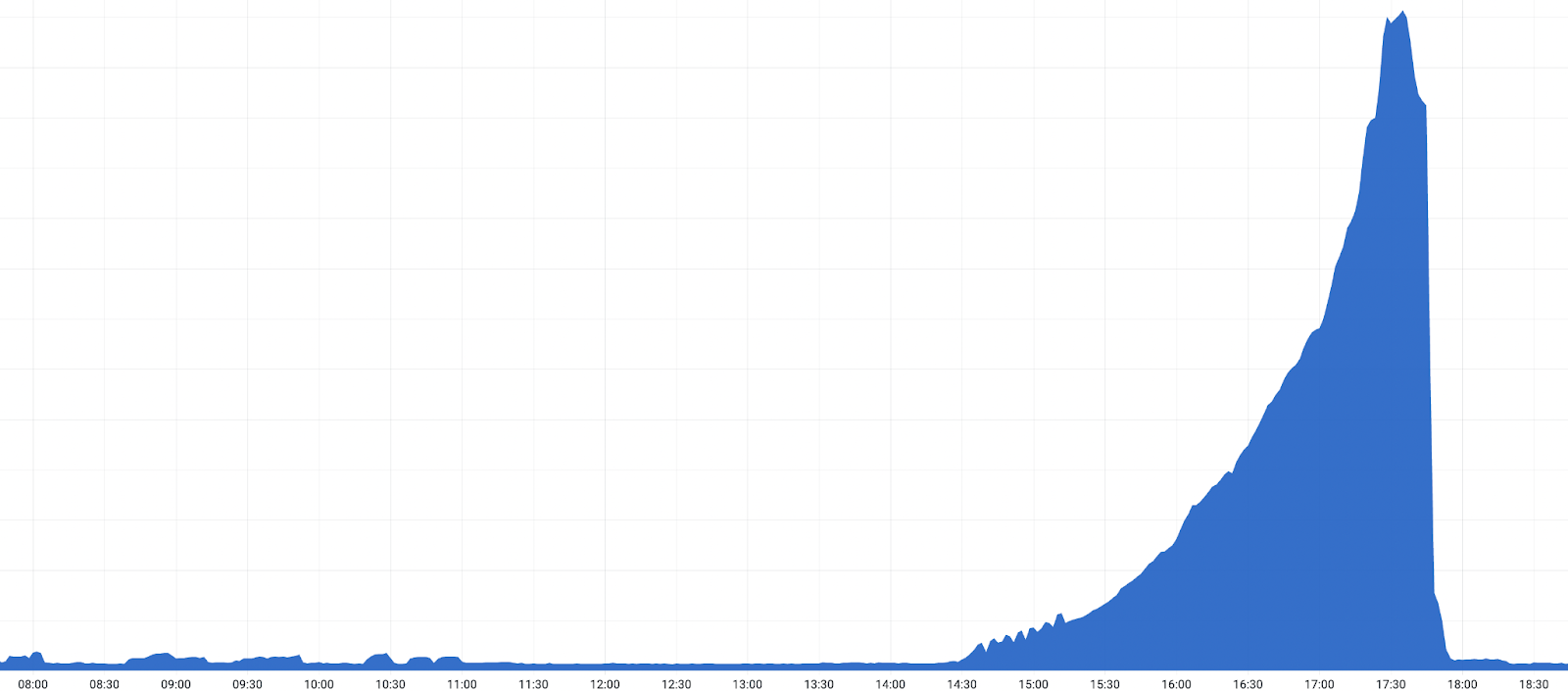
Nous avons confirmé qu'une version défaillante était à l'origine de ce problème en effectuant une restauration de la version dans un datacenter à 17h03 UTC. Après la restauration, nous avons observé une diminution des erreurs 530. Après cette confirmation, une restauration mondiale accélérée a démarré, et les erreurs 530 ont commencé à diminuer. Les répercussions ont pris fin lorsque le déploiement de la version a été annulé dans tous les datacenters configurés en tant que niveaux supérieurs du service Tiered Cache, à 18h04 UTC.
Chronologie :
- 25-10-2022 08h40 : le déploiement débute dans un petit sous-ensemble de datacenters.
- 25-10-2022 10h35 : une alerte client individuelle est déclenchée, indiquant une augmentation du nombre de codes d'erreur 500.
- 25-10-2022 11h20 : après une enquête, un petit datacenter unique est identifié comme étant la source du problème ; il est retiré de la production pendant que les équipes examinent l'incident sur ce site.
- 25-10-2022 12h30 : le problème commence à se propager plus largement, à mesure que des datacenters plus nombreux reçoivent les modifications du code.
- 25-10-2022 14h22 : le nombre d'erreurs 530 augmente, à mesure que le déploiement de la version débute progressivement dans nos plus grands datacenters.
- 25-10-2022 14h39 : plusieurs équipes sont impliquées dans l'enquête, tandis que des clients plus nombreux commencent à signaler une augmentation des erreurs.
- 25-10-2022 17h03 : le déploiement du logiciel du réseau CDN est annulé à Atlanta, et la cause fondamentale est confirmée.
- 25-10-2022 17h28 : niveau maximal des répercussions ; environ 5 % de l'ensemble des requêtes HTTP renvoie une erreur avec le code d'état 530.
- 25-10-2022 17h38 : une restauration accélérée se poursuit ; les grands datacenters servent de niveau supérieur pour de nombreux clients.
- 25-10-2022 18h04 : la restauration est terminée pour tous les niveaux supérieurs.
- 25-10-2022 18h30 : la restauration est terminée.
Durant les premières phases de l'enquête, il est apparu qu'il s'agissait d'un problème lié à notre système DNS interne, dont une version était en cours de déploiement au même moment. Comme l'indique la section suivante, il s'agissait d'un effet secondaire, plutôt que de la cause de la panne.
L'ajout d'une fonction de traçage distribué au service de mise en cache par niveau Tiered Cache était à l'origine du problème
Afin d'améliorer nos performances, nous ajoutons régulièrement du code de surveillance à différentes parties de nos services. La surveillance du code nous aide en nous fournissant une visibilité du fonctionnement des différents composants, ce qui nous permet d'identifier les goulets d'étranglement que nous pouvons améliorer. Notre équipe a récemment ajouté une fonction de traçage distribué supplémentaire à la logique de notre service de mise en cache par niveau (Tiered Cache). Le code du point d'entrée du service de mise en cache par niveau se présente comme ceci :
* Avant :
function _M.go()
-- code to run here
end
* Après :
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
endLe code ci-dessus enveloppe la fonction go() existante avec trace_fn(), qui appelle la fonction go()n, puis déclare sa durée d'exécution.
Cependant, la logique qui injecte une fonction dans le module opentracing efface les en-têtes de contrôle à chaque requête :
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
-- Normalement, nous extrayons les données de ces en-têtes de contrôle avant de les effacer ; cela fait partie de la procédure habituelle de traitement des requêtes.
Toutefois, le trafic interne du service de mise en cache par niveau s'attend à ce que les en-têtes de contrôle provenant du niveau inférieur soient transmis « en l'état ». En raison de l'effacement des en-têtes et de l'utilisation d'un niveau supérieur, des informations qui pouvaient être essentielles pour l'acheminement des requêtes n'étaient pas disponibles. Dans le sous-ensemble de requêtes concernées, le nom d'hôte devant être résolu par notre service interne de résolution DNS pour les adresses IP du serveur d'origine était manquant. Par conséquent, une erreur DNS 530 était renvoyée au client.
Mesures de correction et de suivi
Pour éviter que cela ne se reproduise, en plus de corriger le bug, nous avons identifié un ensemble de modifications qui nous aideront à détecter et à prévenir les problèmes de ce type à l'avenir :
- Inclure un datacenter plus grand, configuré comme un niveau supérieur de Tiered Cache, dans une étape antérieure du plan de déploiement. Ceci nous permettra de détecter plus rapidement les problèmes similaires, en amont d'un déploiement mondial.
- Étendre la couverture de nos tests d'acceptation afin d'inclure un ensemble plus étendu de configurations, notamment différentes topologies du service Tiered Cache.
- Lancer l'alerte de manière plus agressive dans les situations où nous ne disposons pas d'un contexte complet concernant les requêtes et nous avons besoin d'informations supplémentaires sur l'hôte dans les en-têtes de contrôle.
- S'assurer que notre système déclenche correctement une interruption immédiate en cas d'erreur comme celle-ci, ce qui aurait permis d'identifier le problème lors du développement et des tests.
Conclusion
Nous avons connu un incident qui a affecté un nombre important de clients utilisant Tiered Cache. Après avoir identifié le composant défectueux, nous avons pu rapidement effectuer une restauration et remédier au problème. Nous sommes désolés pour les perturbations que cet incident a entraînées pour nos clients et les utilisateurs finaux qui tentaient d'accéder aux services.
Des mesures correctives visant à éviter qu'un tel incident ne se reproduise seront mises en place dès que possible.