


Faciliter le full-stack
S'il est vrai que nous sommes le 1er avril, et que nous aimons faire des farces tout autant que n'importe qui, nous souhaitons néanmoins profiter de cette journée pour vous informer d'annonces tout à fait sérieuses. En effet, à la date d'aujourd'hui, ce sont plus de deux millions de développeurs qui travaillent actuellement sur la plateforme Cloudflare, et ce n'est pas une blague !
Afin de donner le coup d'envoi de cette édition de la Developer Week, nous apposons le tampon « prêt pour la production » sur trois de nos produits : D1, notre base de données SQL serverless, Hyperdrive, un service qui vous donne l'impression que vos bases de données existantes sont distribuées (et plus rapides !), et Workers Analytics Engine, notre base de données de séries chronologiques.
Depuis quelque temps déjà, nous nous sommes donné pour mission d'aider les développeurs à faire migrer l'intégralité de leur pile vers Cloudflare, mais à quoi ressemblerait une application développée sur notre plateforme ?
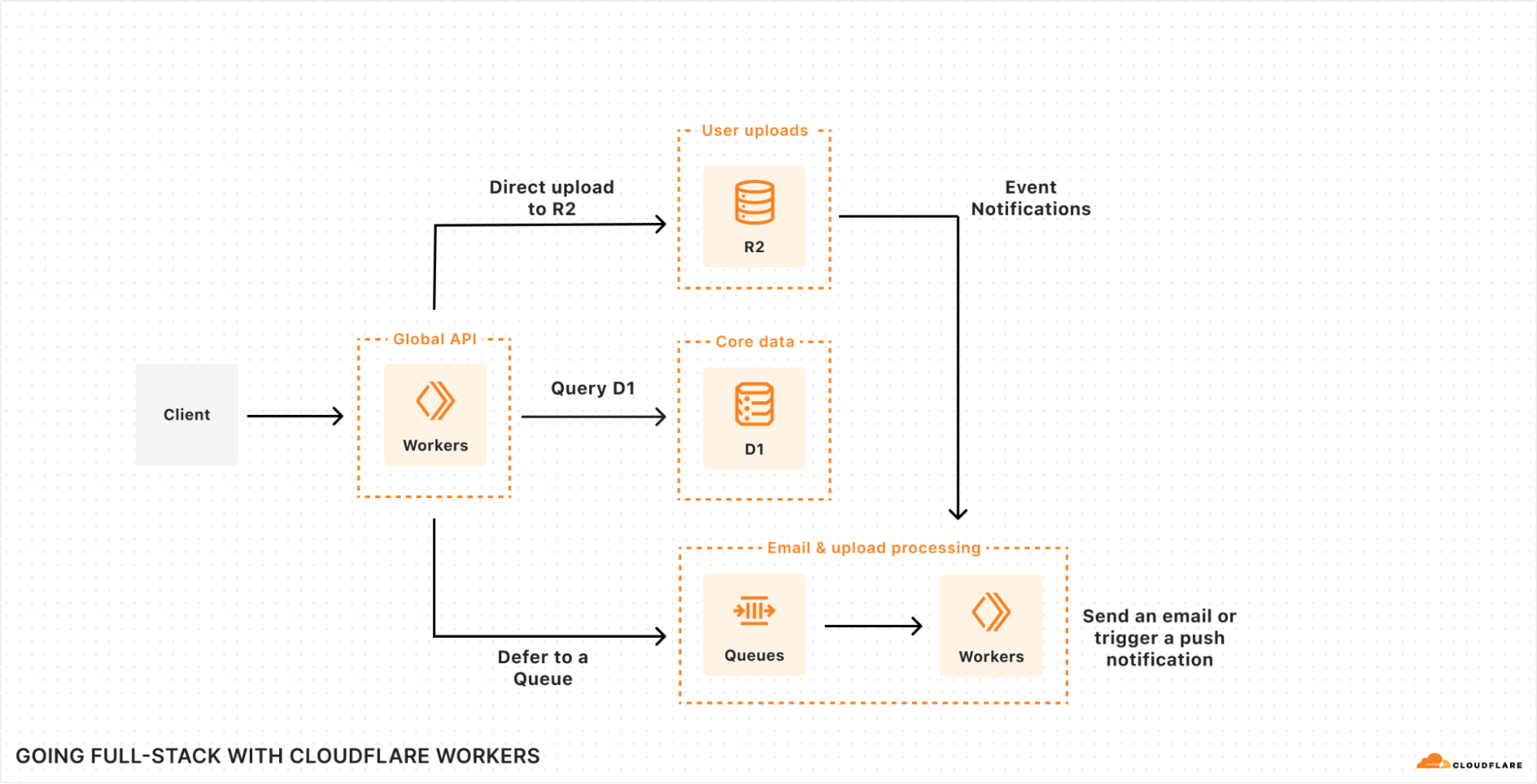
Le schéma en lui-même ne devrait pas être trop différent des outils que vous connaissez déjà : vous avez besoin d'une base de données pour les données de vos utilisateurs essentiels, mais aussi d'une solution de stockage d'objets pour les ressources et le contenu utilisateur. Vous pourriez également avoir besoin d'une file d'attente pour les tâches de fond, comme le traitement des e-mails ou des importations. Un magasin clé-valeur rapide pourrait aussi s'avérer utile pour la configuration des environnements d'exécution, voire une base de données de séries chronologiques afin d'agréger les événements utilisateur et/ou les données de performances. Et nous n'avons même pas encore évoqué l'IA, qui adopte une place de plus en plus fondamentale dans de nombreuses applications, pour effectuer l'ensemble des tâches de recherche, de recommandation et/ou d'analyse d'images (au minimum !).
Et pourtant, sans même y penser, cette architecture doit s'exécuter à l'échelle de la planète. Elle doit donc se montrer évolutive, fiable et rapide, et ce de manière immédiate.
Mise en disponibilité générale de D1 : le service est prêt pour la production

Votre base de données principale est l'un des éléments les plus essentiels de votre infrastructure. Elle doit être ultra-fiable, car elle ne peut pas se permettre de perdre des données. Elle doit également être évolutive, aussi avons-nous travaillé d'arrache-pied cette dernière année à mettre l'intégralité des éléments de D1 en place afin de nous assurer qu'il soit prêt pour la production. Nous sommes donc extrêmement enthousiastes à l'idée d'annoncer que le service D1, notre base de données SQL serverless mondiale, est désormais en disponibilité générale.
La mise en disponibilité générale de D1 s'accompagne de certaines des fonctionnalités que vous nous avez le plus demandées, notamment les suivantes :
- prise en charge des bases de données 10 Go et de 50 000 bases de données par compte ;
- nouvelles capacités d'exportation de données ; et
- débogage renforcé des requêtes (une fonction que nous nommons « D1 Insights »), afin de vous permettre de comprendre quelles requêtes sont les plus chronophages, les plus coûteuses ou simplement les plus inefficaces…
Nous offrons ainsi aux développeurs tous les outils nécessaires pour concevoir des applications prêtes pour la production avec D1, afin de répondre à tous leurs besoins de SQL relationnel. Plus important encore, à une époque où le concept même d'« offre gratuite » ou d'« offre amateur » semble en péril, nous n'avons aucunement l'intention de supprimer le niveau gratuit pour D1 ni de réduire les 25 milliards de lignes lues incluses dans l'offre payante Workers à 5 USD/mois :
Pour ceux qui suivent l'actualité du service D1 depuis le début : la tarification est identique à celle que nous avions annoncée lors de la bêta ouverte.
Mais la mise en disponibilité générale ne signe pas l'arrêt du développement : nous avons de nouvelles fonctionnalités majeures en réserve pour le service D1, notamment la réplication de lecture à l'échelle mondiale, des bases de données d'encore plus grande taille, des capacités Time Travel supplémentaires vous permettant de diviser votre base de données, ainsi que de nouvelles API afin d'interroger et/ou de créer dynamiquement de nouvelles bases de données à la volée au sein d'un Worker.
La fonctionnalité de réplication de lecture de D1 déploiera automatiquement les répliques comme nécessaire pour rapprocher les données de vos utilisateurs, le tout sans avoir à mettre en place/gérer la mise à l'échelle, ou rencontrer de problèmes de cohérence (décalage de réplication). Vous trouverez ci-dessous un aperçu de ce à quoi ressemblera l'API Replication à venir pour D1 :
export default {
async fetch(request: Request, env: Env) {
const {pathname} = new URL(request.url);
let resp = null;
let session = env.DB.withSession(token); // An optional commit token or mode
// Handle requests within the session.
if (pathname === "/api/orders/list") {
// This statement is a read query, so it will work against any
// replica that has a commit equal or later than `token`.
const { results } = await session.prepare("SELECT * FROM Orders");
resp = Response.json(results);
} else if (pathname === "/api/orders/add") {
order = await request.json();
// This statement is a write query, so D1 will send the query to
// the primary, which always has the latest commit token.
await session.prepare("INSERT INTO Orders VALUES (?, ?, ?)")
.bind(order.orderName, order.customer, order.value);
.run();
// In order for the application to be correct, this SELECT
// statement must see the results of the INSERT statement above.
//
// D1's new Session API keeps track of commit tokens for queries
// within the session and will ensure that we won't execute this
// query until whatever replica we're using has seen the results
// of the INSERT.
const { results } = await session.prepare("SELECT COUNT(*) FROM Orders")
.run();
resp = Response.json(results);
}
// Set the token so we can continue the session in another request.
resp.headers.set("x-d1-token", session.latestCommitToken);
return resp;
}
}
Fait important, nous donnerons aux développeurs la capacité de conserver la cohérence en fonction de la session, afin que les utilisateurs puissent continuer à voir leurs propres modifications en effet, tout en continuant à bénéficier des gains de performances et de latence apportés par la réplication.
Vous en apprendrez davantage sur le fonctionnement de la fonctionnalité de réplication de lecture de D1 dans notre article approfondi. De même, si vous souhaitez commencer à développer dès aujourd'hui sur D1, nous vous invitons à consulter nos documents destinés aux développeurs afin de créer votre première base de données.
Hyperdrive : disponibilité générale

Nous avons lancé la bêta ouverte d'Hyperdrive en septembre dernier au cours de la semaine anniversaire, et notre solution est désormais en disponibilité générale (ou, en d'autres termes, testée sur le champ de bataille et prête pour la production).
Si vous n'avez pas suivi ce qu'est Hyperdrive, sachez qu'il s'agit d'une solution conçue pour vous donner l'impression que les bases de données centralisées dont vous disposez déjà sont internationales. Nous mettons à profit notre réseau mondial pour définir des itinéraires plus rapides pour votre base de données, pour conserver les pools de connexions en état de marche et pour mettre en cache vos requêtes les plus courantes, aussi près des utilisateurs que possible.
Qui plus est, Hyperdrive prend en charge les pilotes et les bibliothèques ORM (Object Relational Mapper, mappeur objet-relationnel) les plus populaires dès l'installation, afin de vous éviter d'avoir à réapprendre ou à réécrire vos requêtes :
// Use the popular 'pg' driver? Easy. Hyperdrive just exposes a connection string
// to your Worker.
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
// Prefer using an ORM like Drizzle? Use it with Hyperdrive too.
// https://orm.drizzle.team/docs/get-started-postgresql#node-postgres
const client = new Client({ connectionString: env.HYPERDRIVE.connectionString });
await client.connect();
const db = drizzle(client);
Le travail sur Hyperdrive ne va toutefois pas s'arrêter du simple fait de sa « mise en disponibilité générale ». Au cours des prochains mois, nous lui ajouterons la prise en charge de l'autre moteur de base de données le plus largement déployé : MySQL, mais aussi celle de la connexion des bases de données au sein des réseaux privés (y compris les réseaux cloud VPC) via Cloudflare Tunnel et Magic WAN. Pour couronner le tout, nous prévoyons de lui apporter davantage de configurabilité en matière de stratégies d'invalidation et de mise en cache, afin de vous permettre de prendre des décisions plus granulaires entre les performances et la fraîcheur des données.
Comme nous le pensions lorsque nous souhaitions facturer Hyperdrive, nous avons compris que tarifer ce service ne semblait pas juste. Les avantages en termes de performances dus à Hyperdrive sont non seulement considérables, mais également essentiels à la connexion de moteurs de bases de données traditionnels. Sans Hyperdrive, le fait de payer la latence supplémentaire résultant des six (ou plus !) allers-retours nécessaires pour connecter et interroger votre base de données pour chaque requête ne semble en effet pas des plus justes.
Nous sommes donc ravis d'annonce qu'Hyperdrive est gratuit pour n'importe quel développeur titulaire d'une offre Workers payante. Cette gratuité inclut à la fois la mise en cache des requêtes et la mise en pool des connexions, de même que la capacité à créer plusieurs Hyperdrives, afin de séparer des applications différentes, la production de la préproduction, ou de proposer différentes configurations (avec ou sans cache, par exemple).
Pour faire vos premiers pas dans l'univers Hyperdrive, rendez-vous dans les documents afin d'apprendre à connecter votre base de données existante et commencer à l'interroger depuis vos Workers.
Queues : extraction depuis n'importe quel point
La file d'attente de tâches constitue un élément de plus en plus essentiel du développement d'une application moderne et full-stack. C'est ce que nous avions à l'esprit lorsque nous avons annoncé pour la première fois la bêta ouverte de Queues. Depuis, nous avons travaillé sur plusieurs fonctionnalités majeures du service Queues et lançons deux d'entre elles cette semaine : les consommateurs basés sur l'extraction et les mesures de contrôle de la transmission des nouveaux messages.
N'importe quel client basé sur le protocole HTTP peut désormais extraire (pull) des messages depuis une file d'attente, en appelant le nouveau point de terminaison /pull d'une file d'attente afin de demander un lot de messages, et en appelant le point de terminaison /ack pour accuser réception de chaque message (ou lot de messages) lorsque vous les traitez avec succès :
// Pull and acknowledge messages from a Queue using any HTTP client
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/pull" -X POST --data '{"visibilityTimeout":10000,"batchSize":100}}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
// Ack the messages you processed successfully; mark others to be retried.
$ curl "https://api.cloudflare.com/client/v4/accounts/${CF_ACCOUNT_ID}/queues/${QUEUE_ID}/messages/ack" -X POST --data '{"acks":["lease-id-1", "lease-id-2"],"retries":["lease-id-100"]}' \
-H "Authorization: Bearer ${QUEUES_TOKEN}" \
-H "Content-Type:application/json"
Un consommateur de type pull peut s'exécuter n'importe où, afin de vous permettre de placer ces consommateurs en file d'attente parallèlement à votre infrastructure cloud d'ancienne génération existante. Les équipes de Cloudflare ont adopté ce schéma très tôt, avec un scénario d'utilisation axé sur l'écriture des données télémétriques d'un appareil vers une file d'attente de nos plus de 310 datacenters et consommant les données au sein d'une partie de notre infrastructure back-end exécutée sur Kubernetes. Fait important, la distribution mondiale de notre infrastructure de file d'attente implique que les messages sont conservés au sein de la file jusqu'à ce que le consommateur soit prêt à les traiter.
De même, le service Queues prend désormais en charge le retardement de messages, à la fois lors de l'envoi vers une file d'attente, mais aussi lors du marquage d'un message pour un nouvel essai. Cette caractéristique peut être utile pour mettre en file d'attente des tâches pour l'avenir, ainsi que pour appliquer un mécanisme de retour si une API ou une infrastructure en amont dispose d'un contrôle du volume en place nécessitant de cadencer la vitesse à laquelle vous traitez les messages.
// Apply a delay to a message when sending it
await env.YOUR_QUEUE.send(msg, { delaySeconds: 3600 })
// Delay a message (or a batch of messages) when marking it for retry
for (const msg of batch.messages) {
msg.retry({delaySeconds: 300})
}
Nous proposerons également un rendement par file d'attente augmenté de manière substantielle au cours des mois qui nous séparent de la mise en disponibilité générale du service Queues. Il est important pour nous que Queues soit extrêmement fiable. Les messages abandonnés ou perdus peuvent impliquer, par exemple, qu'un utilisateur ne reçoit pas son e-mail de confirmation de commande, une notification de réinitialisation de mot de passe et/ou les notifications de traitement de ses importations de données. Or, chacun de ces cas de figure peut exercer une influence sur la situation de l'utilisateur, qui pourrait avoir du mal à se remettre de ses effets.

Le service Workers Analytics Engine est en disponibilité générale
Le service Workers Analytics Engine propose des analyses à cardinalité infinie à l'échelle souhaitée, via une API intégrée pour écrire les points de données issues de Workers, et une API SQL pour interroger ces données.
La solution Workers Analytics Engine est soutenue par le même système basé sur ClickHouse que celui sur lequel nous nous reposons depuis des années chez Cloudflare. Nous l'utilisons nous-mêmes pour observer l'intégrité de nos propres services, capturer les données d'utilisation des produits à des fins de facturation et répondre aux questions sur les schémas d'utilisation de clients spécifiques. Au moins un point de données est écrit sur ce système pour presque chaque requête effectuée au réseau Cloudflare. Le service Workers Analytics Engine vous permet de développer vos propres outils d'analyse à l'aide de cette même infrastructure, tandis que nous gérons les aspects les plus difficiles pour vous.
Depuis le lancement de la solution en bêta, les développeurs ont commencé à se reposer sur Workers Analytics Engine pour les mêmes scénarios d'utilisation et bien d'autres, des grandes entreprises aux projets open source, comme Counterscale. Le service Workers Analytics Engine fonctionne à l'échelle de la production avec des charges de travail essentielles à l'activité depuis des années, mais nous n'avions encore rien communiqué sur son prix, jusqu'à aujourd'hui.
Pour Workers Analytics Engine, nous comptons proposer une tarification simple et basée sur deux indicateurs :
- Points de données écrits : chaque appel effectué à writeDataPoint() au sein d'un Worker compte pour un point de données écrit. Chaque point de données coûte le même montant. Contrairement à d'autres plateformes, nous ne comptabilisons aucune pénalité pour l'ajout de dimensions ou la cardinalité. IL n'est donc pas nécessaire de tenter de prédire la taille et le coût d'un point de données compressé.
- Requêtes de lecture : chaque publication transmise à l'API SQL de Workers Analytics Engine compte comme une requête de lecture. Chaque requête coûte le même montant. Contrairement à d'autres plateformes, nous ne comptabilisons aucune pénalité pour la complexité des requêtes. Il n'est donc pas nécessaire de tenir compte du nombre de lignes de données qui seront lues à chaque requête.
Les offres Workers gratuite et payante proposeront toutes deux un quota de points de données écrits et de requêtes de lecture, la tarification en cas d'usage supplémentaire s'effectuant comme suit :
Avec cette tarification, vous pouvez répondre à la question « Combien le service Workers Analytics Engine va-t-il me coûter ? » en comptant le nombre d'appels à une fonction au sein de votre Worker et le nombre de fois que vous effectuez une requête à un point de terminaison d'API HTTP. Des comptes sur nappe en papier, plutôt que sur feuille de calcul.
La tarification sera annoncée à tous au cours des prochains mois. D'ici là, le service Workers Analytics Engine continuera d'être accessible gratuitement. Vous pouvez commencer à écrire des points de données depuis votre Worker dès aujourd'hui. Il ne faut que quelques minutes et moins de 10 lignes de code pour commencer à capturer des données. Nous sommes impatients de savoir ce que vous pensez de notre solution.
La semaine ne fait que commencer
Restez à l'écoute de ce que nous avons en réserve pour vous lors de la deuxième journée de la Developer Week. Si vous avez des questions ou si vous souhaitez nous présenter ce que vous avez déjà développé, n'hésitez pas à rejoindre notre Discord destiné aux développeurs.