
Il y a près de neuf ans, Cloudflare était une toute petite entreprise dont j’étais le client, et non l’employé. Cloudflare était sorti depuis un mois et un jour, une notification m’alerte que mon petit site, jgc.org, semblait ne plus disposer d’un DNS fonctionnel. Cloudflare avait effectué une modification dans l’utilisation de Protocol Buffers qui avait endommagé le DNS.
J’ai contacté directement Matthew Prince avec un e-mail intitulé « Où est mon DNS ? » et il m’a envoyé une longue réponse technique et détaillée (vous pouvez lire tous nos échanges d’e-mails ici) à laquelle j’ai répondu :
De: John Graham-Cumming
Date: Jeudi 7 octobre 2010 à 09:14
Objet: Re: Où est mon DNS?
À: Matthew Prince
Superbe rapport, merci. Je veillerai à vous appeler s’il y a un
problème. Il serait peut-être judicieux, à un certain moment, d’écrire tout cela dans un article de blog, lorsque vous aurez tous les détails techniques, car je pense que les gens apprécient beaucoup la franchise et l’honnêteté sur ce genre de choses. Surtout si vous y ajoutez les tableaux qui montrent l’augmentation du trafic suite à votre lancement.
Je dispose d’un système robuste de surveillance de mes sites qui m’envoie un SMS en cas de problème. La surveillance montre une panne de 13:03:07 à 14:04:12. Des tests sont réalisés toutes les cinq minutes.
Un accident de parcours dont vous vous relèverez certainement. Mais ne pensez-vous pas qu’il vous faudrait quelqu’un en Europe? :-)
Ce à quoi il a répondu :
De: Matthew Prince
Date: Jeudi 7 octobre 2010 à 09:57
Objet: Re: Où est mon DNS?
À: John Graham-Cumming
Merci. Nous avons répondu à tous ceux qui nous ont contacté. Je suis en route vers le bureau et nous allons publier un article sur le blog ou épingler un post officiel en haut de notre panneau d’affichage. Je suis parfaitement d’accord, la transparence est nécessaire.
Aujourd’hui, en tant qu’employé d’un Cloudflare bien plus grand, je vous écris de manière transparente à propos d’une erreur que nous avons commise, de son impact et de ce que nous faisons pour régler le problème.
Les événements du 2 juillet
Le 2 juillet, nous avons déployé une nouvelle règle dans nos règles gérées du pare-feu applicatif Web (WAF) qui ont engendré un surmenage des processeurs sur chaque cœur de processeur traitant le trafic HTTP/HTTPS sur le réseau Cloudflare à travers le monde. Nous améliorons constamment les règles gérées du WAF pour répondre aux nouvelles menaces et vulnérabilités. En mai, par exemple, nous avons utilisé la vitesse avec laquelle nous pouvons mettre à jour le WAF pour appliquer une règle et nous protéger d’une vulnérabilité SharePoint importante. Être capable de déployer rapidement et globalement des règles est une fonctionnalité essentielle de notre WAF.
Malheureusement, la mise à jour de mardi dernier contenait une expression régulière qui nous a fait reculer énormément et qui a épuisé les processeurs utilisés pour la distribution HTTP/HTTPS. Les fonctionnalités essentielles de mise en proxy, du CDN et du WAF de Cloudflare sont tombées en panne. Le graphique suivant présente les processeurs dédiés à la distribution du trafic HTTP/HTTPS atteindre presque 100 % d’utilisation sur les serveurs de notre réseau.
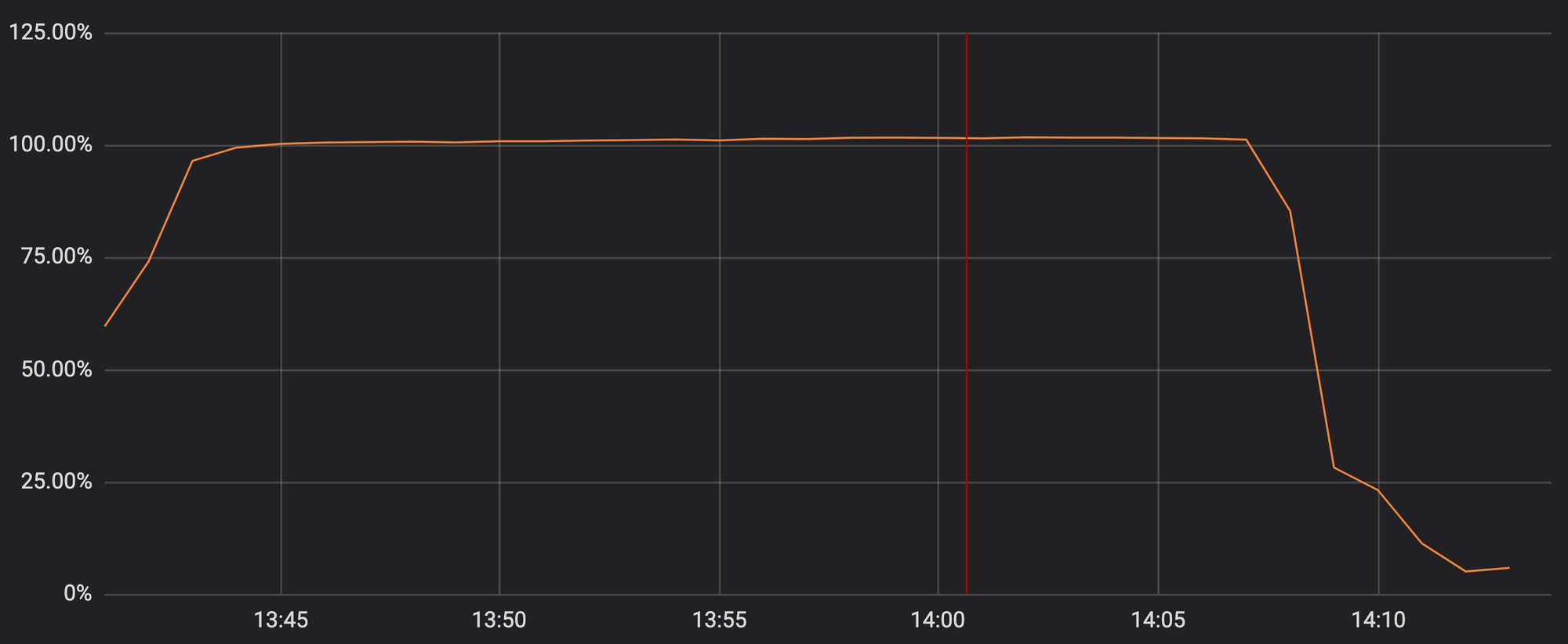
En conséquence, nos clients (et leurs clients) voyaient une page d’erreur 502 lorsqu’ils visitaient n’importe quel domaine Cloudflare. Les erreurs 502 étaient générées par les serveurs Web frontaux Cloudflare dont les cœurs de processeurs étaient encore disponibles mais incapables d’atteindre les processus qui distribuent le trafic HTTP/HTTPS.
Nous réalisons à quel points nos clients ont été affectés. Nous sommes terriblement gênés qu’une telle chose se soit produite. L’impact a été négatif également pour nos propres activités lorsque nous avons traité l’incident.
Cela a du être particulièrement stressant, frustrant et angoissant si vous étiez l’un de nos clients. Le plus regrettable est que nous n’avions pas eu de panne globale depuis six ans.
Le surmenage des processeurs fut causé par une seule règle WAF qui contenait une expression régulière mal écrite et qui a engendré un retour en arrière excessif. L’expression régulière au cœur de la panne est (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Bien que l’expression régulière soit intéressante pour de nombreuses personnes (et évoquée plus en détails ci-dessous), comprendre ce qui a causé la panne du service Cloudflare pendant 27 minutes est bien plus complexe « qu’une expression régulière qui a mal tourné ». Nous avons pris le temps de noter les séries d’événements qui ont engendré la panne et nous ont empêché de réagir rapidement. Et si vous souhaitez en savoir plus sur le retour en arrière d’une expression régulière et que faire dans ce cas, veuillez consulter l’annexe à la fin de cet article.
Ce qui s’est produit
Commençons par l’ordre des événements. Toutes les heures de ce blog sont en UTC.
À 13:42, un ingénieur de l’équipe pare-feu a déployé une légère modification aux règles de détection XSS via un processus automatique. Cela a généré un ticket de requête de modification. Nous utilisons Jira pour gérer ces tickets (capture d’écran ci-dessous).
Trois minutes plus tard, la première page PagerDuty indiquait une erreur avec le pare-feu applicatif Web (WAF). C’était un test synthétique qui vérifie les fonctionnalités du WAF (nous disposons de centaines de tests de ce type) en dehors de Cloudflare pour garantir qu’il fonctionne correctement. Ce test fut rapidement suivi par des pages indiquant de nombreux échecs d’autres tests de bout-en-bout des services Cloudflare, une alerte de perte de trafic globale, des erreurs 502 généralisées, puis par de nombreux rapports de nos points de présence (PoP) dans des villes à travers le monde indiquant un surmenage des processeurs.


Préoccupé par ces alertes, j’ai quitté la réunion à laquelle j’assistais et en me dirigeant vers mon bureau, un responsable de notre groupe Ingénieur Solutions m’a dit que nous avions perdu 80 % de notre trafic. J’ai couru au département SRE où l’équipe était en train de déboguer la situation. Au tout début de la panne, certains pensaient à un type d’attaque que nous n’avions jamais connu auparavant.

L’équipe SRE de Cloudflare est répartie dans le monde entier pour assurer une couverture continue. Les alertes de ce type, dont la majorité identifient des problèmes très spécifiques sur des cadres limités et dans des secteurs précis, sont surveillées dans des tableaux de bord internes et traitées de nombreuses fois chaque jour. Cependant, ce modèle de pages et d’alertes indiquait que quelque chose de grave s’était produit, et le département SRE a immédiatement déclaré un incident P0 et transmis à la direction de l’ingénierie et à l’ingénierie des systèmes.
À ce moment, l’équipe d’ingénieurs de Londres assistait à une conférence technique interne dans notre espace principal d’événements. La discussion fut interrompue et tout le monde s’est rassemblé dans une grande salle de conférence ; les autres se sont connectés à distance. Ce n’était pas un problème normal que le département SRE pouvait régler seul ; nous avions besoin que toutes les équipes appropriées soient en ligne au même moment.
À 14:00, nous avons identifié que le composant à l’origine du problème était le WAF, et nous avons écarté la possibilité d’une attaque. L’équipe Performances a extrait les données en direct du processeur d’une machine qui montrait clairement que le WAF était responsable. Un autre membre de l’équipe a utilisé Strace pour confirmer. Une autre équipe a observé des journaux d’erreur indiquant que le WAF présentait un problème. À 14:02, toute l’équipe m’a regardé : la proposition était d’utiliser un « global kill », un mécanisme intégré à Cloudflare pour désactiver un composant unique partout dans le monde.
Mais utiliser un « global kill » pour le WAF, c’était une toute autre histoire. Nous avons rencontré plusieurs obstacles. Nous utilisons nos propres produits et avec la panne de notre service Access, nous ne pouvions plus authentifier notre panneau de contrôle interne (une fois de retour en ligne, nous avons découvert que certains membres de l’équipe avaient perdu leur accès à cause d’une fonctionnalité de sécurité qui désactive les identifiants s’ils n’utilisent pas régulièrement le panneau de contrôle interne).
Et nous ne pouvions pas atteindre les autres services internes comme Jira ou le moteur de production. Pour les atteindre, nous avons du employer un mécanisme de contournement très rarement utilisé (un autre point à creuser après l’événement). Finalement, un membre de l’équipe a exécuté le « global kill » du WAF à 14:07 ; à 14:09, les niveaux du trafic et des processeurs sont revenus à la normale à travers le monde. Le reste des mécanismes de protection de Cloudflare a continué de fonctionner.
Nous sommes ensuite passés à la restauration de la fonctionnalité WAF. Le côté sensible de la situation nous a poussé à réaliser des tests négatifs (nous demander « est-ce réellement ce changement particulier qui a causé le problème ? ») et des tests positifs (vérifier le fonctionnement du retour) dans une ville unique à l’aide d’un sous-ensemble de trafic après avoir retiré de cet emplacement le trafic de nos clients d’offres payantes.
À 14:52, nous étions certains à 100 % d’avoir compris la cause, résolu le problème et que le WAF était réactivé partout dans le monde.
Fonctionnement de Cloudflare
Cloudflare dispose d’une équipe d’ingénieurs dédiée à notre solution de règles gérées du WAF ; ils travaillent constamment pour améliorer les taux de détection, réduire les faux positifs et répondre rapidement aux nouvelles menaces dès qu’elles apparaissent. Dans les 60 derniers jours, 476 requêtes de modifications ont été traitées pour les règles gérées du WAF (en moyenne une toutes les 3 heures).
Cette modification spécifique fut déployée en mode « simulation » où le trafic client passe au travers de la règle mais rien n’est bloqué. Nous utilisons ce mode pour tester l’efficacité d’une règle et mesurer son taux de faux positifs et de faux négatifs. Cependant, même en mode simulation, les règles doivent être exécutées, et dans cette situation, la règle contenait une expression régulière qui consommait trop de processeur.
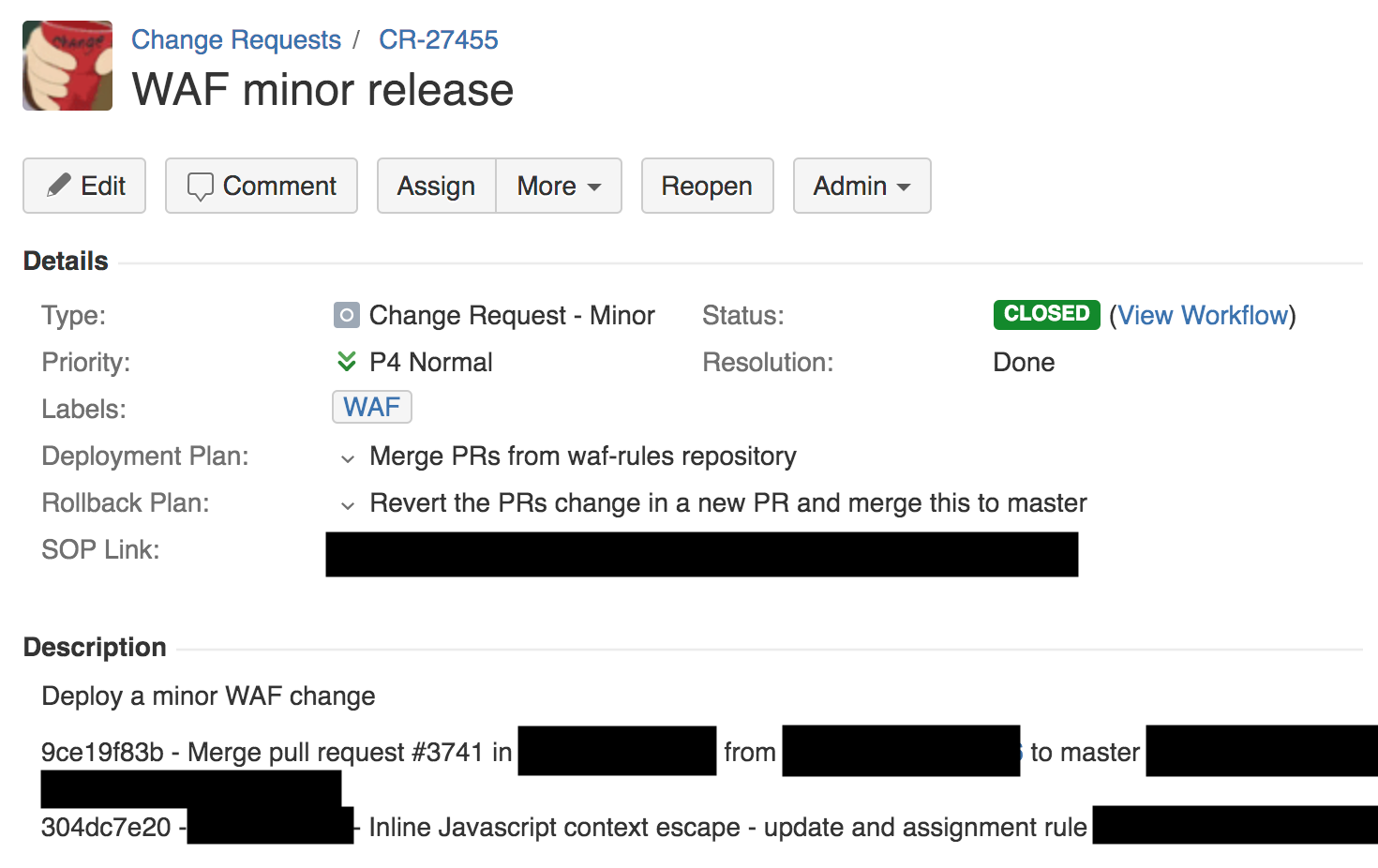
On peut observer dans la requête de modification ci-dessus un plan de déploiement, un plan de retour et un lien vers la procédure opérationnelle standard (POS) interne pour ce type de déploiement. La POS pour une modification de règle lui permet d’être appliquée à l’échelle mondiale. Ce processus est très différent de tous les logiciels que nous publions chez Cloudflare, où la POS applique d’abord le logiciel au réseau interne de dogfooding d’un point de présence (PoP) (au travers duquel passent nos employés), puis à quelques clients sur un emplacement isolé, puis à un plus grand nombre de clients et finalement au monde entier.
Le processus pour le lancement d’un logiciel ressemble à cela : Nous utilisons Git en interne via BitBucket. Les ingénieurs qui travaillent sur les modifications intègrent du code créé par TeamCity ; les examinateurs sont désignés une fois la construction validée. Lorsqu’une requête d’extraction est approuvée, le code est créé et la série de tests exécutée (à nouveau).
Si la construction et les tests sont validés, une requête de modification Jira est générée et la modification doit être approuvée par le responsable approprié ou la direction technique. Une fois approuvée, le déploiement de ce que l’on appelle les « PDP animaux » survient : DOG, PIG et les Canaries
Le PoP DOG est un PoP Cloudflare (au même titre que toutes nos villes à travers le monde) mais qui n’est utilisé que par les employés Cloudflare. Ce PoP de dogfooding nous permet d’identifier les problèmes avant que le trafic client n’atteigne le code. Et il le fait régulièrement.
Si le test DOG réussit, le code est transféré vers PIG (en référence au « cobaye » ou « cochon d’Inde »). C’est un PoP Cloudflare sur lequel un petit sous-ensemble de trafic client provenant de clients de l’offre gratuite passe au travers du nouveau code.
Si le test réussit, le code est transféré vers les Canaries. Nous disposons de trois PoP Canaries répartis dans le monde entier ; nous exécutons du trafic client des offres payantes et gratuite qui traverse ces points sur le nouveau code afin de vérifier une dernière fois qu’il n’y a pas d’erreur.
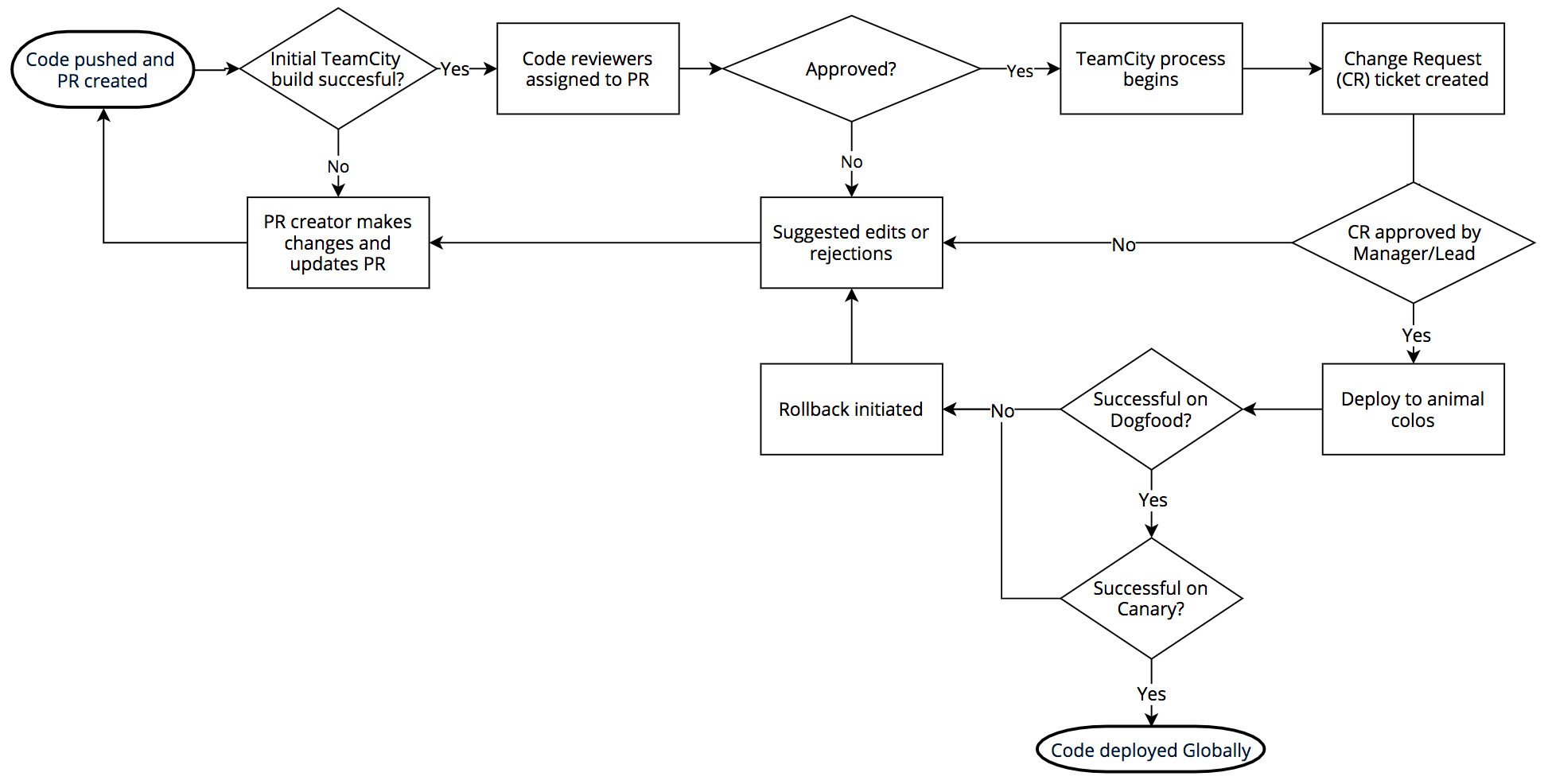
Une fois validé aux Canaries, le code peut être déployé. L’intégralité du processus DOG, PIG, Canari, Global peut prendre plusieurs heures ou plusieurs jours en fonction du type de modification de code. La diversité du réseau et des clients de Cloudflare nous permet de tester rigoureusement le code avant d’appliquer un lancement à tous nos clients partout dans le monde. Cependant, le WAF n’est pas conçu pour utiliser ce processus car il doit répondre rapidement aux menaces.
Menaces WAF
Ces derniers années, nous avons observé une augmentation considérable des vulnérabilités dans les applications communes. C’est une conséquence directe de la disponibilité augmentée des outils de test de logiciels, comme par exemple le fuzzing (nous venons de publier un nouveau blog sur le fuzzing ici).
Le plus souvent, une preuve de concept (PoC, Proof of Concept) est créée et publiée rapidement sur Github, afin que les équipes en charge de l’exécution et de la maintenance des applications puissent effectuer des tests et vérifier qu’ils disposent des protections adéquates. Il est donc essentiel que Cloudflare soit capable de réagir aussi vite que possible aux nouvelles attaques pour offrir à nos clients une chance de corriger leur logiciel.
Le déploiement de nos protections contre la vulnérabilité SharePoint au mois de mai illustre parfaitement la façon dont Cloudflare est capable d’offrir une protection de manière proactive (blog ici). Peu de temps après la médiatisation de nos annonces, nous avons observé un énorme pic de tentatives visant à exploiter les installations Sharepoint de notre client. Notre équipe surveille constamment les nouvelles menaces et rédige des règles pour les atténuer pour le compte de nos clients.
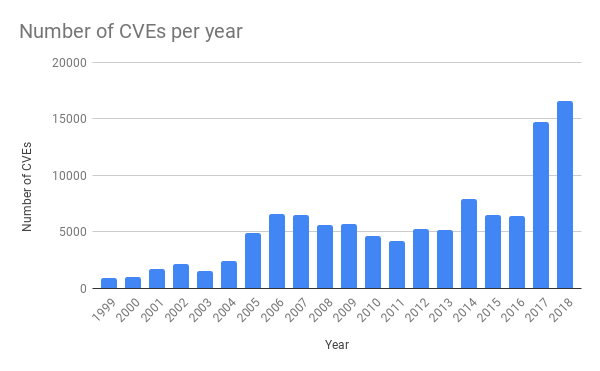
La règle spécifique qui a engendré la panne de mardi dernier ciblait les attaques Cross-Site Scripting (XSS). Ce type d’attaque a aussi considérablement augmenté ces dernières années.
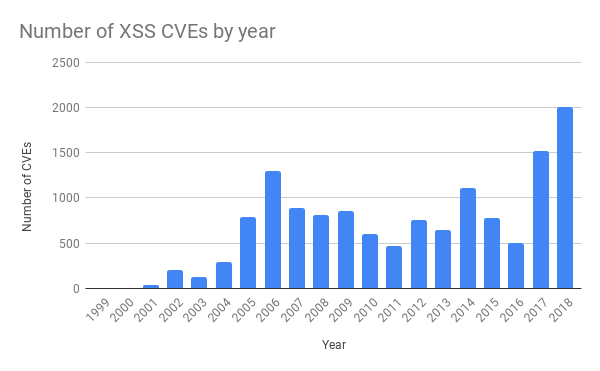
La procédure standard pour une modification des règles gérées du WAF indique que les tests d’intégration continue (CI) doivent être validés avant un déploiement à l’échelle mondiale. Cela s’est passé normalement mardi dernier et les règles ont été déployées. À 13:31, un ingénieur de l’équipe fusionnait une requête d’extraction contenant la modification déjà approuvée.
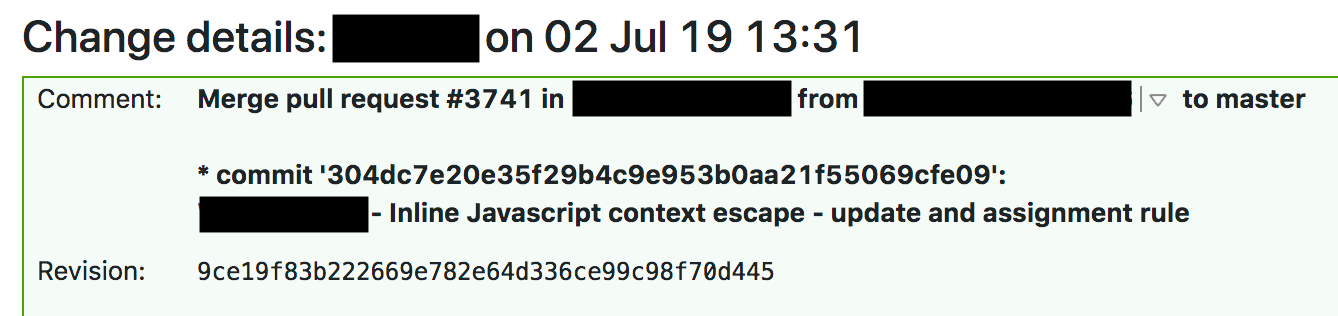
À 13:37, TeamCity a construit les règles et exécuté les tests puis donné son feu vert. La série de tests WAF vérifie que les fonctionnalités principales du WAF fonctionnent ; c’est un vaste ensemble de tests individuels ayant chacun une fonction associée. Une fois les tests individuels réalisés, les règles individuelles du WAF sont testées en exécutant une longue série de requêtes HTTP sur le WAF. Ces requêtes HTTP sont conçues pour tester les requêtes qui doivent être bloquées par le WAF (pour s’assurer qu’il identifie les attaques) et celles qui doivent être transmises (pour s’assurer qu’il ne bloque pas trop et ne crée pas de faux positifs). Il n’a pas vérifié si le WAF utilisait excessivement le processeur, et en examinant les journaux des précédentes constructions du WAF, on peut voir qu’aucune augmentation n’est observée pendant l’exécution de la série de tests avec la règle qui aurait engendré le surmenage du processeur sur notre périphérie.
Après le succès des tests, TeamCity a commencé à déployer automatiquement la modification à 13:42.
Quicksilver
Les règles du WAF doivent répondre à de nouvelles menaces ; elles sont donc déployées à l’aide de notre base de données clé-valeur Quicksilver, capable d’appliquer des modifications à l’échelle mondiale en quelques secondes. Cette technologie est utilisée par tous nos clients pour réaliser des changements de configuration dans notre tableau de bord ou via l’API. C’est la base de notre service : répondre très rapidement aux modifications.
Nous n’avons pas vraiment abordé Quicksilver. Auparavant, nous utilisions Kyoto Tycoon comme base de données clé-valeur distribuées globalement, mais nous avons rencontré des problèmes opérationnels et rédigé notre propre base de données clé-valeur que nous avons reproduite dans plus de 180 villes. Quicksilver nous permet d’appliquer des modifications de configuration client, de mettre à jour les règles du WAF et de distribuer du code JavaScript rédigé par nos clients à l’aide de Cloudflare Workers.
Cliquer sur un bouton dans le tableau de bord, passer un appel d’API pour modifier la configuration et cette modification prendra effet en quelques secondes à l’échelle mondiale. Le clients adorent cette configurabilité haut débit. Avec Workers, ils peuvent profiter d’un déploiement logiciel global quasi instantané. En moyenne, Quicksilver distribue environ 350 modifications par seconde.
Et Quicksilver est très rapide. En moyenne, nous atteignons un p99 de 2,29 s pour distribuer une modification sur toutes nos machines à travers le monde. En général, cette vitesse est un avantage. Lorsque vous activez une fonctionnalité ou purgez votre cache, vous êtes sûr que ce sera fait à l’échelle mondiale presque instantanément. Lorsque vous intégrez du code avec Cloudflare Workers, celui-ci est appliqué à la même vitesse. La promesse de Cloudflare est de vous offrir des mises à jour rapides quand vous en avez besoin.
Cependant, dans cette situation, cette vitesse a donc appliqué la modification des règles à l’échelle mondiale en quelques secondes. Vous avez peut-être remarqué que le code du WAF utilise Lua. Cloudflare utilise beaucoup Lua en production, et des informations sur Lua dans le WAF ont été évoquées auparavant. Le WAF Lua utilise PCRE en interne, le retour en arrière pour la correspondance, et ne dispose pas de mécanisme pour se protéger d’une expression étendue. Ci-dessous, plus d’informations sur nos actions.

Tout ce qui s’est passé jusqu’au déploiement des règles a été fait « correctement » : une requête d’extraction a été lancée, puis approuvée, CI/CD a créé le code et l’a testé, une requête de modification a été envoyée avec une procédure opérationnelle standard précisant le déploiement et le retour en arrière, puis le déploiement a été exécuté.
Les causes du problème
Nous déployons des douzaines de nouvelles règles sur le WAF chaque semaine, et nous avons de nombreux systèmes en place pour empêcher tout impact négatif sur ce déploiement. Quand quelque chose tourne mal, c’est donc généralement la convergence improbable de causes multiples. Trouver une cause racine unique est satisfaisant mais peut obscurcir la réalité. Voici les vulnérabilités multiples qui ont convergé pour engendrer la mise hors ligne du service HTTP/HTTPS de Cloudflare.
- Un ingénieur a rédigé une expression régulière qui pouvait facilement causer un énorme retour en arrière.
- Une protection qui aurait pu empêcher l’utilisation excessive du processeur par une expression régulière a été retirée par erreur lors d’une refonte du WAF quelques semaines plus tôt (refonte dont l’objectif était de limiter l’utilisation du processeur par le WAF).
- Le moteur d’expression régulière utilisé n’avait pas de garanties de complexité.
- La série de tests ne présentait pas de moyen d’identifier une consommation excessive du processeur.
- La procédure opérationnelle standard a permis la mise en production globale d’une modification de règle non-urgente sans déploiement progressif.
- Le plan de retour en arrière nécessitait la double exécution de l’intégralité du WAF, ce qui aurait pris trop de temps.
- La première alerte de chute du trafic global a mis trop de temps à se déclencher.
- Nous n’avons pas mis à jour suffisamment rapidement notre page d’état.
- Nous avons eu des problèmes pour accéder à nos propres systèmes en raison de la panne et la procédure de contournement n’était pas bien préparée.
- Les ingénieurs fiabilité avaient perdu l’accès à certains systèmes car leurs identifiants ont expiré pour des raisons de sécurité.
- Nos clients ne pouvaient pas accéder au tableau de bord ou à l’API Cloudflare car ils passent par la périphérie Cloudflare.
Ce qui s’est passé depuis mardi dernier
Tout d’abord, nous avons interrompu la totalité du travail de publication sur le WAF et réalisons les actions suivantes :
- Réintroduction de la protection en cas d’utilisation excessive du processeur qui avait été retirée. (Terminé)
- Inspection manuelle de toutes les 3 868 règles des règles gérées du WAF pour trouver et corriger tout autre cas d’éventuel retour en arrière excessif. (Inspection terminée)
- Introduction de profil de performances pour toutes les règles sur la série de tests. (ETA : 19 juillet)
- Passage au moteur d’expression régulière re2 ou Rust qui disposent de garanties de temps d’exécution. (ETA : 31 juillet)
- Modifier la procédure opérationnelle standard afin d’effectuer des déploiements progressifs de règles de la même manière que pour les autres logiciels chez Cloudflare tout en conservant la capacité de réaliser des déploiements globaux d’urgence pour les attaques actives.
- Mettre en place une capacité d’urgence pour retirer le tableau de bord et l’API Cloudflare de la périphérie de Cloudflare.
- Mettre à jour automatiquement la page d’état Cloudflare.
À long terme, nous nous éloignons du WAF Lua que j’ai rédigé il y a plusieurs années. Nous déplaçons le WAF pour qu’il utilise le nouveau moteur pare-feu. Cela rendra le WAF plus rapide et offrira une couche de protection supplémentaire.
Conclusion
Ce fut une panne regrettable pour nos clients et pour l’équipe. Nous avons réagi rapidement pour régler la situation et nous réparons les défauts de processus qui ont permis à cette panne de se produire. Afin de nous protéger contre d’éventuels problèmes ultérieurs avec notre utilisation des expressions régulières, nous allons remplacer notre technologie fondamentale.
Nous sommes très gênés par cette panne et désolés de l’impact sur nos clients. Nous sommes convaincus que les changements réalisés nous permettront de ne plus jamais subir une telle panne.
Annexe : À propos du retour en arrière d’expression régulière
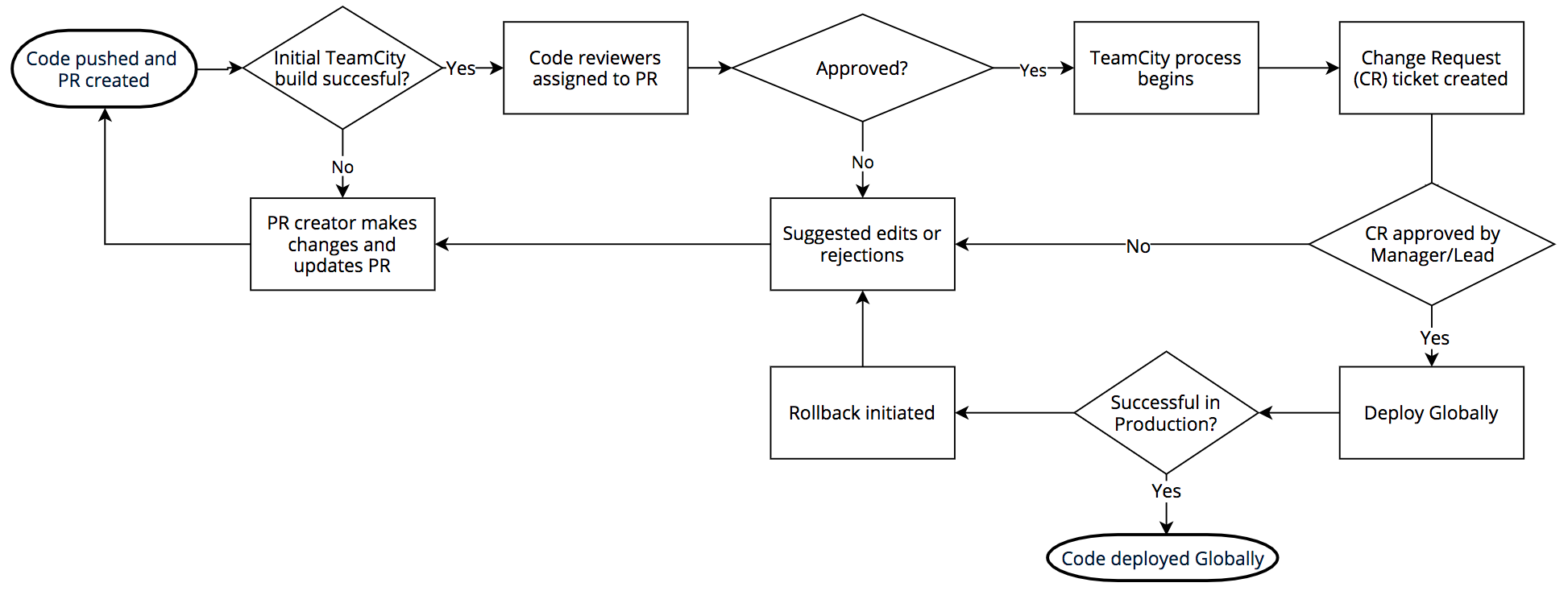
Pour comprendre comment (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) a causé le surmenage du processeur, vous devez vous familiariser avec le fonctionnement d’un moteur d’expression régulière standard. La partie critique est .*(?:.*=.*). Le(?: et les ) correspondantes sont un groupe de non-capture (l’expression entre parenthèses est regroupée dans une seule expression).
Pour identifier la raison pour laquelle ce modèle engendre le surmenage du processeur, nous pouvons l’ignorer et traiter le modèle .*.*=.*. En le réduisant, le modèle paraît excessivement complexe, mais ce qui est important, c’est que toute expression du « monde réel » (comme les expressions complexes au sein de nos règles WAF) qui demande au moteur de « faire correspondre quelque chose suivi de quelque chose » peut engendrer un retour en arrière catastrophique. Explication.
Dans une expression régulière, . signifie correspondre à un caractère unique, .* signifie correspondre à zéro ou plus de caractères abondamment (c’est à dire faire correspondre autant que possible). .*.*=.* signifie donc correspondre à zéro ou plus de caractères, puis à nouveau zéro ou plus de caractères, puis trouver un signe littéral =, puis correspondre à zéro ou plus de caractères.
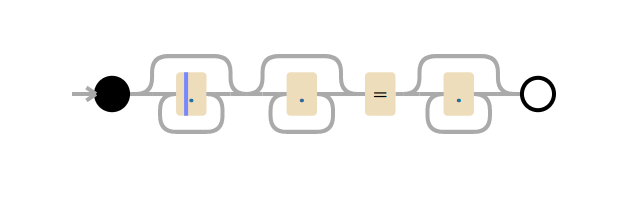
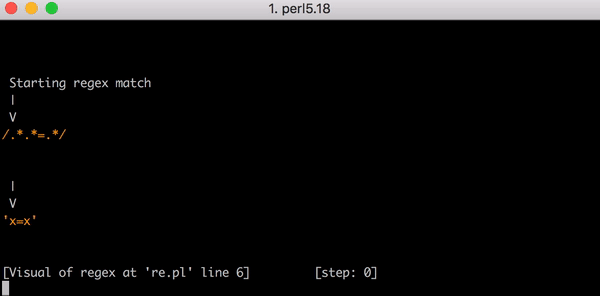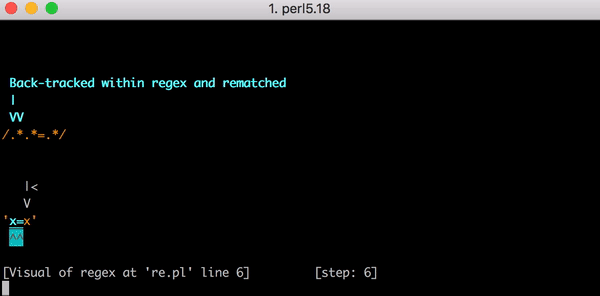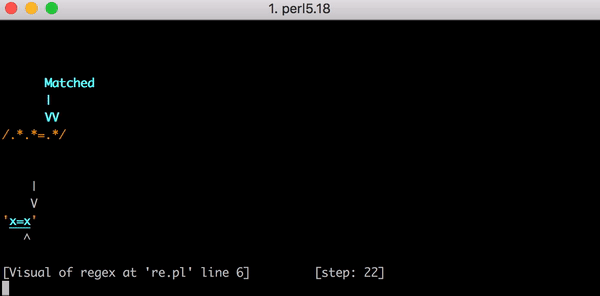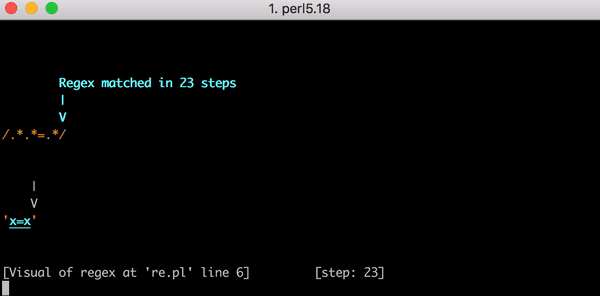
Prenons la chaîne test x=x. Cela correspondra à l’expression .*.*=.*. Les .*.* précédant le signe = peuvent correspondre au premier x (l’un des .* correspond au x, l’autre correspond à zéro caractère). Le .* après le signe = correspond au x final.
Il faut 23 étapes pour atteindre cette correspondance. Le premier .* de .*.*=.* agit abondamment et correspond à la chaîne complète x=x. Le moteur avance pour examiner le .* suivant. Il ne reste aucun caractère à faire correspondre, le deuxième .* correspond donc à zéro caractère (c’est autorisé). Le moteur passe ensuite au =. La correspondance échoue car il n’y a plus de caractère à faire correspondre (le premier .* ayant consommé l’intégralité de x=x).
À ce moment, le moteur d’expression régulière retourne en arrière. Il retourne au premier .* et le fait correspondre à x= (au lieu de x=x) et passe ensuite au deuxième .*. Ce .* correspond au deuxième x et il n’y a maintenant plus aucun caractère à associer. Quand le moteur essaie d’associer le = dans .*.*=.*, la correspondance échoue. Le moteur retourne de nouveau en arrière.
Avec ce retour en arrière, le premier .* correspond toujours à x= mais le deuxième .* ne correspond plus à x ; il correspond à zéro caractère. Le moteur avance ensuite pour essayer de trouver le signe littéral = dans le modèle .*.*=.* mais échoue (car il correspond déjà au premier .*). Le moteur retourne de nouveau en arrière.
Cette fois-ci, le premier .* correspond seulement au premier x. Mais le deuxième .* agit abondamment et correspond à =x. Vous imaginez la suite. Lorsqu’il essaie d’associer le signe littéral =, il échoue et retourne de nouveau en arrière.
Le premier .* correspond toujours seulement au premier x. Désormais, le deuxième .* correspond seulement à =. Comme vous l’avez deviné, le moteur ne peut pas associer le signe littéral = car il correspond déjà au deuxième .*. Le moteur retourne donc de nouveau en arrière. Tout cela pour associer une chaîne de trois caractères.
Enfin, avec le premier .* correspondant uniquement au premier x et le deuxième .* correspondant à zéro caractère, le moteur est capable d’associer le signe littéral = dans l’expression avec le = contenu dans la chaîne. Il avance et le dernier .* correspond au dernier x.
23 étapes pour faire correspondre x=x. Voici une courte vidéo de l’utilisation de Perl Regexp::Debugger présentant les étapes et le retour en arrière.
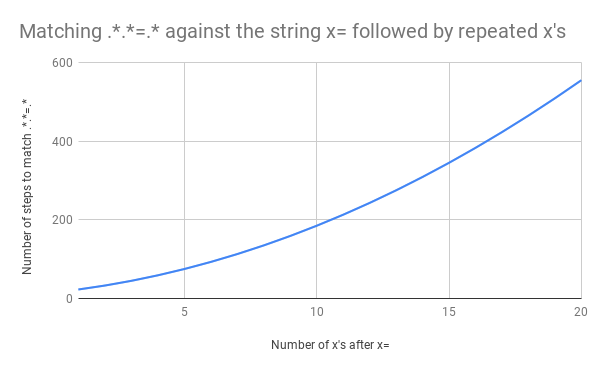
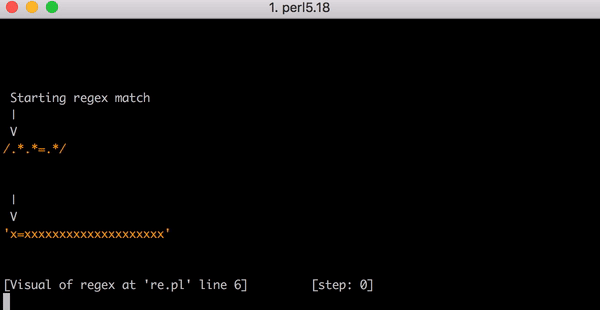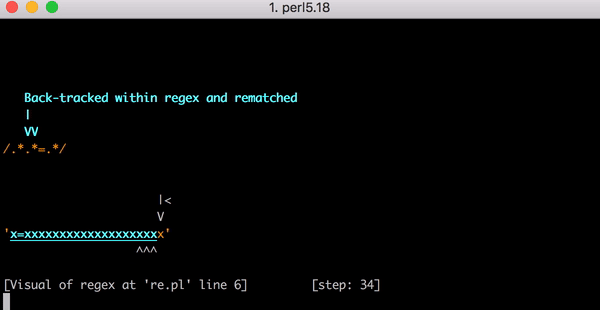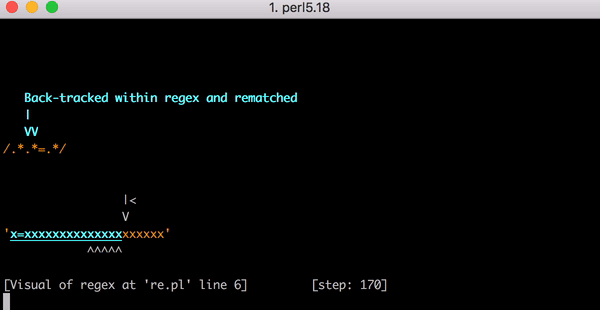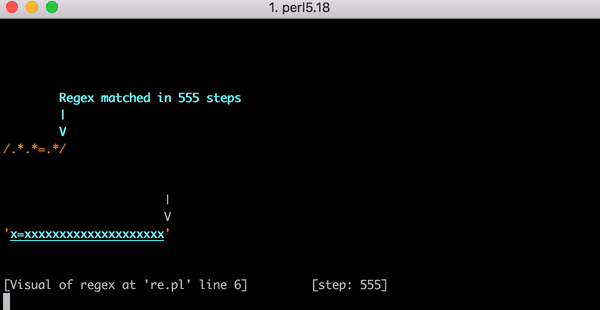
Cela représente beaucoup de travail, mais que se passe-t-il si la chaîne passe de x=x à x=xx ? La correspondance prend cette fois 33 étapes. Et si l’entrée est x=xxx, 45 étapes. Ce n’est pas linéaire. Voici un graphique présentant la correspondance de x=x à x=xxxxxxxxxxxxxxxxxxxx (20 x après le =). Avec 20 x après le =, le moteur requiert 555 étapes pour associer ! (Pire encore, si le x= était manquant et que la chaîne ne contenait que 20 x, le moteur nécessiterait 4 067 étapes pour réaliser que le modèle ne correspond pas).
Cette vidéo montre tout le retour en arrière nécessaire pour correspondre à x=xxxxxxxxxxxxxxxxxxxx:
Ce n’est pas bon signe car à mesure que la taille de l’entrée augmente, le temps de correspondance augmente de manière ultra linéaire. Mais cela aurait pu être encore pire avec une expression régulière légèrement différente. Prenons l’exemple .*.*=.*; (avec un point-virgule littéral à la fin du modèle). Nous aurions facilement pu rédiger cela pour tenter d’associer une expression comme foo=bar;.
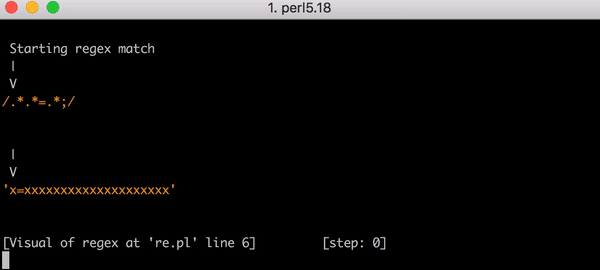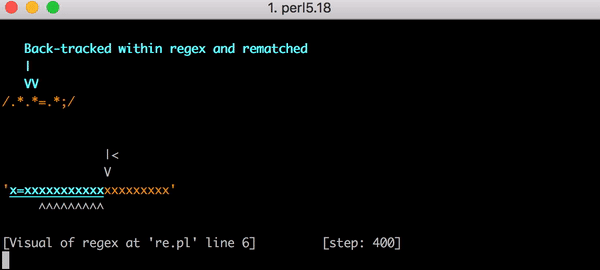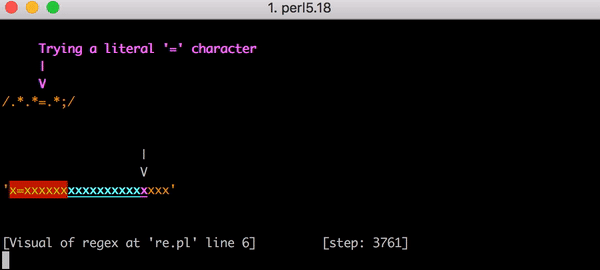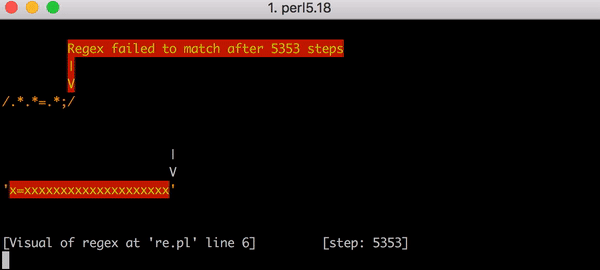
Le retour en arrière aurait été catastrophique. Associer x=x prend 90 étapes au lieu de 23. Et le nombre d’étapes augmente très rapidement. Associer x= suivi de 20 x prend 5 353 étapes. Voici le graphique correspondant : Observez attentivement les valeurs de l’axe Y par rapport au graphique précédent.
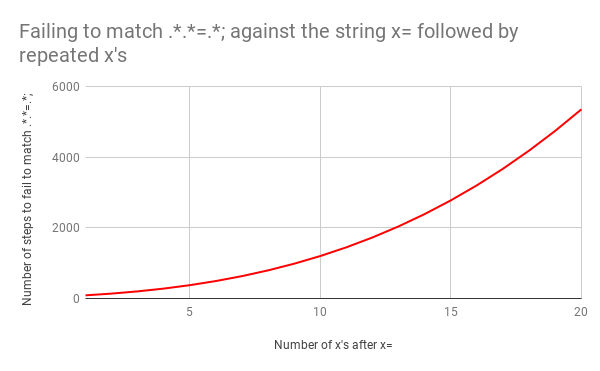
Pour terminer, voici toutes les 5 353 étapes de l’échec de la correspondance de x=xxxxxxxxxxxxxxxxxxxx avec .*.*=.*;
L’utilisation de correspondances fainéantes plutôt que gourmandes (lazy / greedy) permet de contrôler l’étendue du retour en arrière qui survient dans ce cas précis. Si l’expression originale est modifiée en .*?.*?=.*?, la correspondance de x=x prend 11 étapes (au lieu de 23), tout comme la correspondance de x=xxxxxxxxxxxxxxxxxxxx. C’est parce que le ? après le .*ordonne au moteur d’associer le plus petit nombre de caractères avant de commencer à avancer.
Mais la fainéantise n’est pas la solution totale à ce comportement de retour en arrière. Modifier l’exemple catastrophique .*.*=.*; en .*?.*?=.*?; n’affecte pas du tout son temps d’exécution. x=x prend toujours 555 étapes et x= suivi de 20 x prend toujours 5 353 étapes.
La seule vraie solution, mise à part la réécriture complète du modèle pour être plus précis, c’est de s’éloigner du moteur d’expression régulière avec ce mécanisme de retour en arrière. Ce que nous faisons au cours des prochaines semaines.
La solution à ce problème existe depuis 1968, lorsque Ken Thompson écrivait un article intitulé « Techniques de programmation : Algorithme de recherche d’expression régulière ». L’article décrit un mécanisme pour convertir une expression régulière en AFN (automate fini non-déterministe) et suivre les transitions d’état dans l’AFN à l’aide d’un algorithme exécuté en un temps linéaire de la taille de la chaîne que l’on souhaite faire correspondre.

L’article de Thompson n’évoque pas l’AFN mais l’algorithme de temps linéaire est clairement expliqué. Il présente également un programme ALGOL-60 qui génère du code de langage assembleur pour l’IBM 7094. La réalisation paraît ésotérique mais l’idée présentée ne l’est pas.
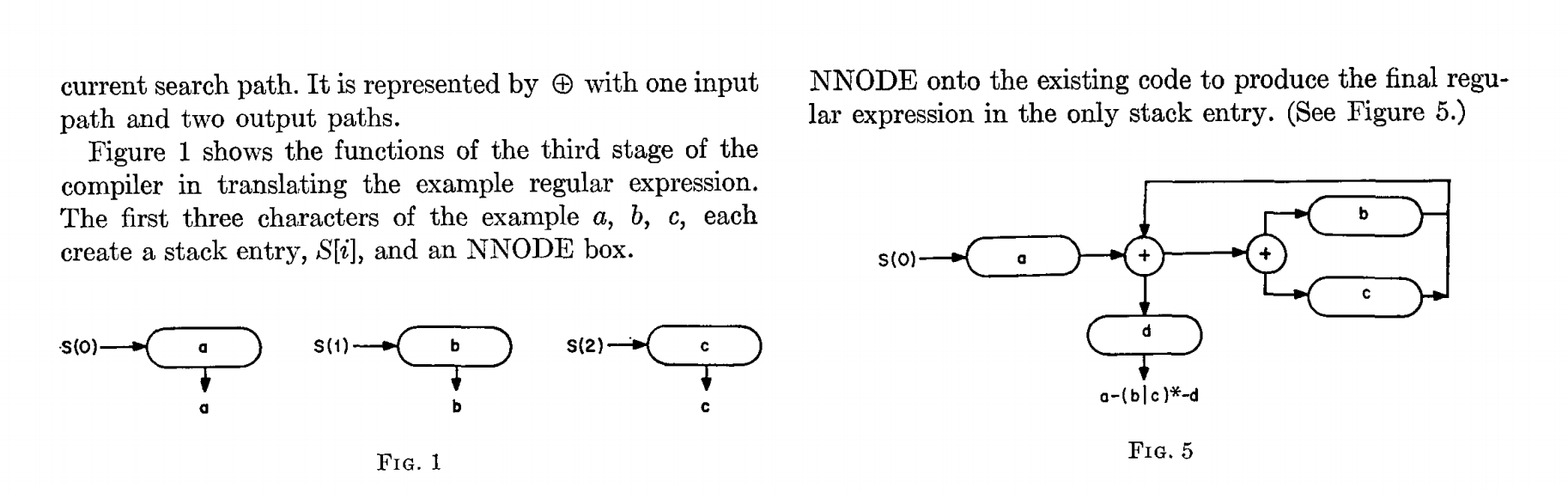
Voici à quoi ressemblerait l’expression régulière .*.*=.* si elle était schématisée d’une manière similaire aux images de l’article de Thompson.
Le schéma 0 contient 5 états commençant à 0. Il y a trois boucles qui commencent avec les états 1, 2 et 3. Ces trois boucles correspondent aux trois .* dans l’expression régulière. Les trois pastilles avec des points à l’intérieur correspondent à un caractère unique. La pastille avec le signe = à l’intérieur correspond au signe littéral =. L’état 4 est l’état final : s’il est atteint, l’expression régulière a trouvé une correspondance.
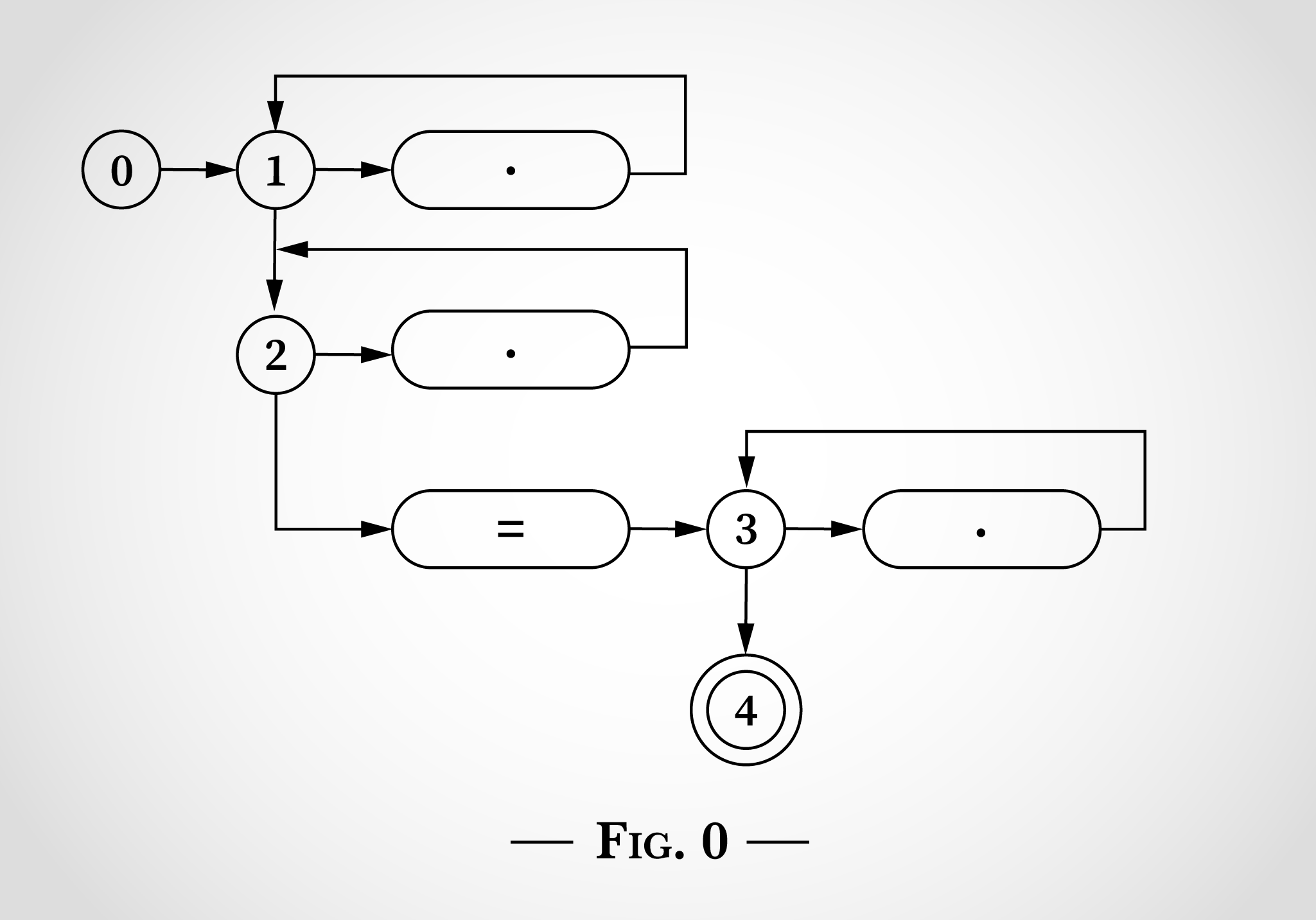
Pour voir comment un tel schéma d’état peut être utilisé pour associer l’expression régulière .*.*=.*, nous allons examiner la correspondance de la chaîne x=x. Le programme commence à l’état 0 comme indiqué dans le schéma 1.
La clé pour faire fonctionner cet algorithme est que la machine d’état soit dans plusieurs états au même moment. L’AFN prendra autant de transitions que possible simultanément.
Avant de lire une entrée, il passe immédiatement aux deux états 1 et 2 comme indiqué dans le schéma 2.
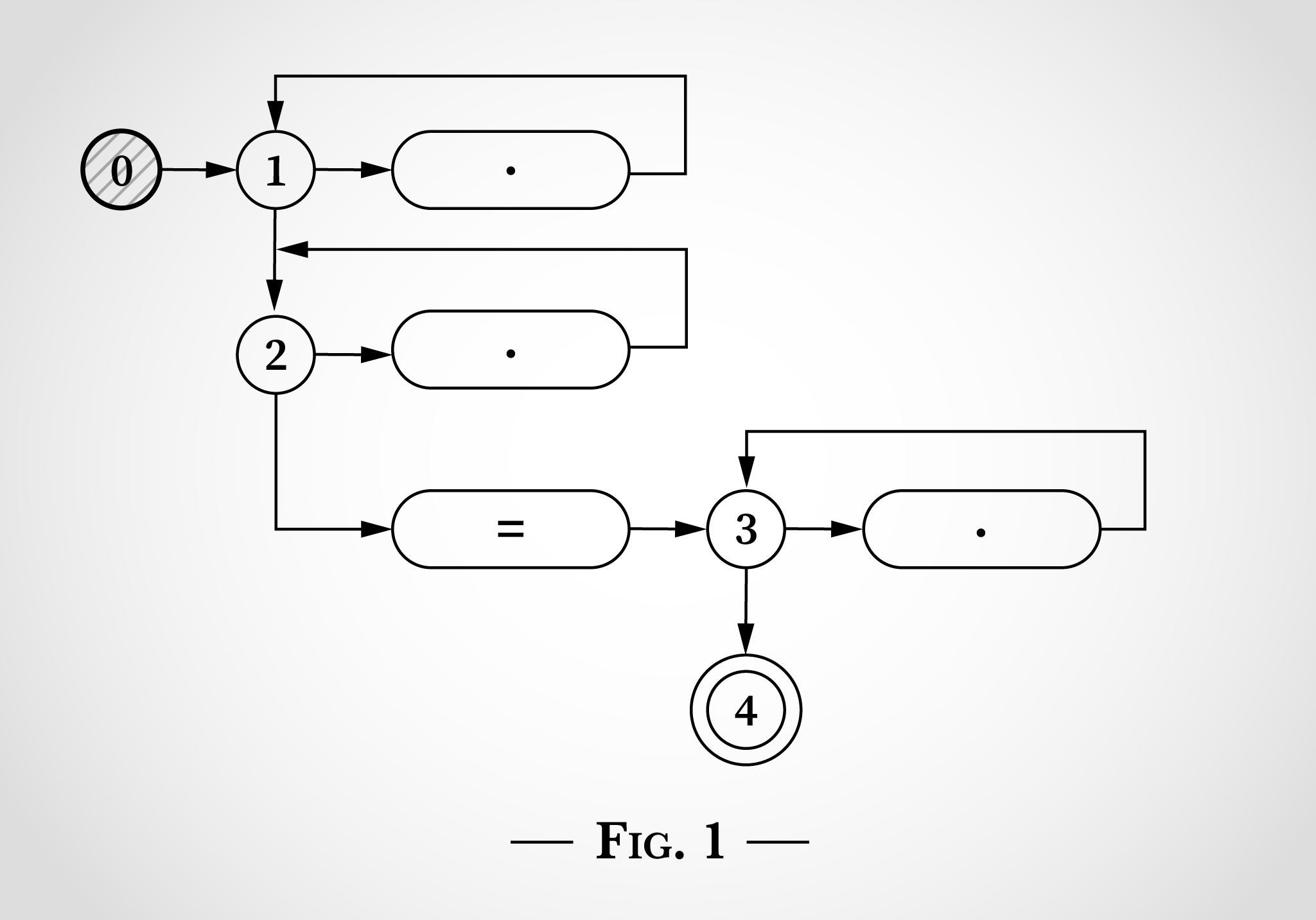
En observant le schéma 2, on peut voir ce qui s’est passé lorsqu’il considère le premier x dans x=x. Le x peut correspondre au point supérieur en faisant une transition de l’état 1 et en retournant à l’état 1. Ou le x peut correspondre au point inférieur en faisant une transition de l’état 2 et en retournant à l’état 2.
Après avoir associé le premier x dans x=x, les états restent 1 et 2. On ne peut pas atteindre l’état 3 ou 4 car il faut un signe littéral =.
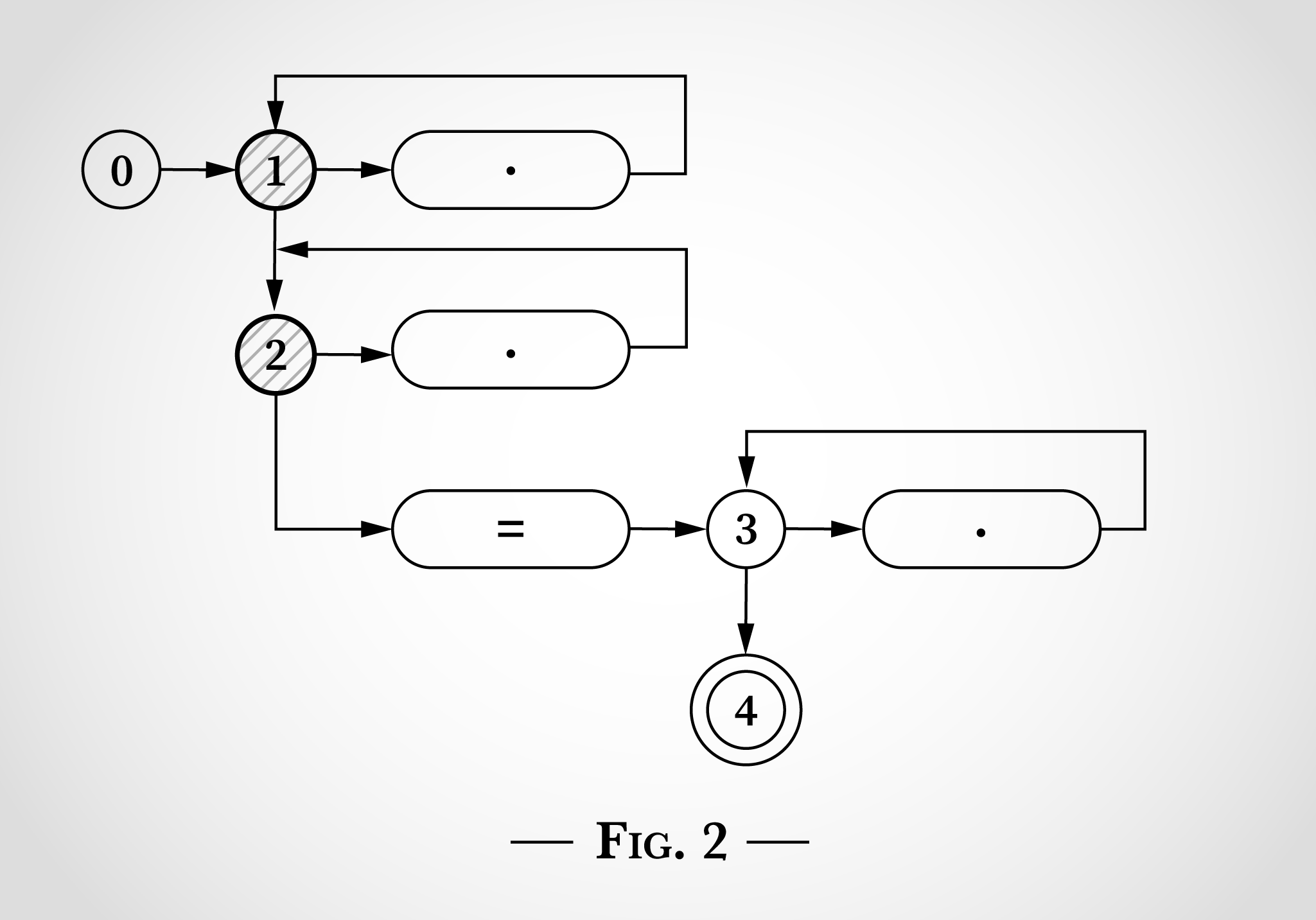
L’algorithme considère ensuite le = dans x=x. Comme le x avant lui, il peut être associé par l’une des deux boucles supérieures faisant une transition de l’état 1 à l’état 1 ou de l’état 2 à l’état 2. En outre, le signe littéral = peut être associé et l’algorithme peut faire une transition de l’état 2 à l’état 3 (et directement à l’état 4). C’est illustré dans le schéma 3.
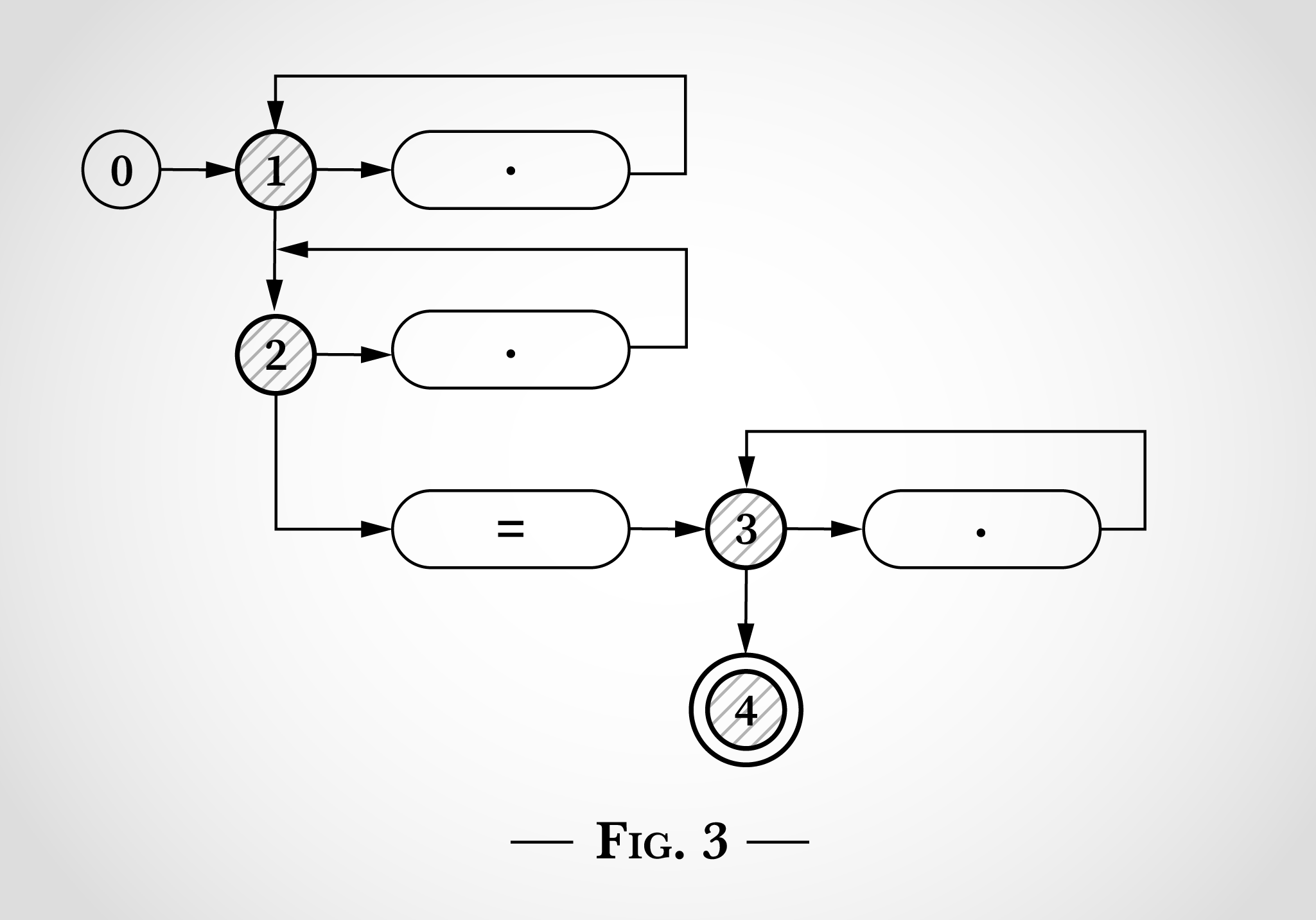
Ensuite, l’algorithme atteint le x final dans x=x. Depuis les états 1 et 2, les mêmes transitions sont possibles vers les états 1 et 2. Depuis l’état 3, le x peut correspondre au point sur la droite et retourner à l’état 3.
À ce niveau, chaque caractère de x=x a été considéré, et puisque l’état 4 a été atteint, l’expression régulière correspond à cette chaîne. Chaque caractère a été traité une fois, l’algorithme était donc linéaire avec la longueur de la chaîne saisie. Aucun retour en arrière nécessaire.
Cela peut paraître évident qu’une fois l’état 4 atteint (après la correspondance de x=), l’expression régulière correspond et l’algorithme peut terminer sans prendre en compte le x final.
Cet algorithme est linéaire avec la taille de son entrée.