


Introduction
Aujourd'hui, le 21 juin 2022, Cloudflare a subi une panne qui a affecté le trafic dans 19 de nos datacenters. Malheureusement, ces 19 sites figurent également parmi les plus importants et traitent à ce titre une part considérable de notre trafic mondial. La panne résulte d'une modification effectuée dans le cadre d'un projet de longue haleine visant à accroître la résilience dans nos points d'implantation les plus fréquentés. En tant que maillon essentiel de notre infrastructure, ces derniers voient en effet passer une proportion significative du trafic de Cloudflare. Une modification de la configuration réseau de ces datacenters a ainsi entraîné une panne, qui a commencé à 6 h 27 UTC. Le premier datacenter a été remis en ligne à 6 h 58 UTC et tous nos datacenters avaient récupéré leur connexion et fonctionnaient correctement à 7 h 42 UTC.
En fonction de votre position dans le monde, il est possible que vous vous soyez retrouvé dans l'impossibilité d'accéder aux sites web et aux services qui dépendent de Cloudflare. Cloudflare a continué de fonctionner comme à l'accoutumée dans les autres points d'implantation du réseau.
Nous sommes sincèrement désolés pour cette panne. L'erreur provenait de nos services et n'était absolument pas imputable à une quelconque attaque ou activité malveillante.
Contexte
Ces derniers 18 mois, nous nous sommes efforcés de convertir l'ensemble des points d'implantation les plus fréquentés du réseau Cloudflare au profit d'une architecture plus redondante. Sur cette période, nous avons procédé à la migration de 19 de nos datacenters vers cette architecture, que nous nommons en interne Multi-Colo PoP (MCP). Les datacenters concernés sont les suivants : Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, Londres, Los Angeles, Madrid, Manchester, Miami, Milan, Mumbai, Newark, Osaka, São Paulo, San Jose, Singapour, Sydney et Tokyo.
Une partie essentielle de la nouvelle architecture, conçue comme un réseau Clos, forme une couche supplémentaire de routage et crée ainsi un maillage de connexions. Ce maillage nous permet d'activer et de désactiver facilement certaines parties du réseau interne d'un datacenter à des fins d'entretien ou pour régler un problème. Cette couche est représentée par les « troncs » (spines) sur le schéma suivant.
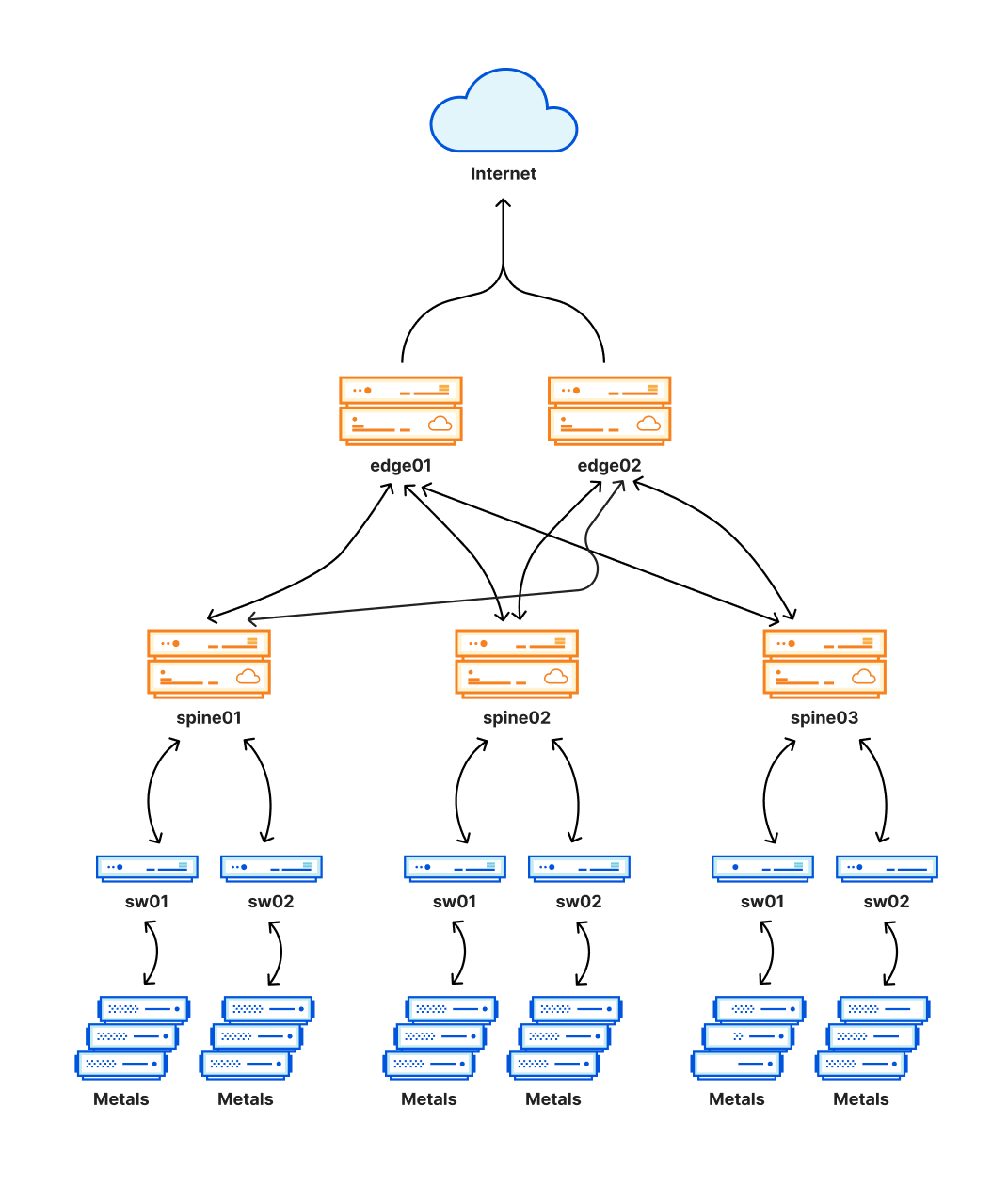
Cette nouvelle architecture nous a offert des améliorations significatives en matière de fiabilité, tout en nous permettant de procéder à la maintenance de ces points d'implantation sans perturber le trafic des clients. Comme ces points soutiennent également une vaste proportion du trafic Cloudflare, tout problème survenant dans l'un d'eux peut avoir une incidence particulièrement étendue et c'est ce qui s'est produit aujourd'hui.
Chronologie de l'incident (UTC) et répercussions
Afin d'être joignables sur Internet, les réseaux tels que celui de Cloudflare font appel à un protocole nommé BGP. Dans le cadre de ce protocole, les opérateurs définissent des politiques qui permettent de décider quels préfixes (un ensemble d'adresses IP adjacentes) sont annoncés aux pairs (les autres réseaux auxquels le réseau de l'opérateur se connecte) ou acceptés de la part de ces derniers.
Ces politiques présentent des composants individuels, évalués de manière séquentielle. Le résultat final aboutira soit à l'annonce d'un préfixe donné soit à l'absence d'annonce de ce dernier. Une modification de la politique peut entraîner l'absence d'annonce d'un préfixe précédemment annoncé, auquel cas ce dernier est retiré de la table de routage et les adresses IP qui en dépendent ne seront plus joignables sur Internet.
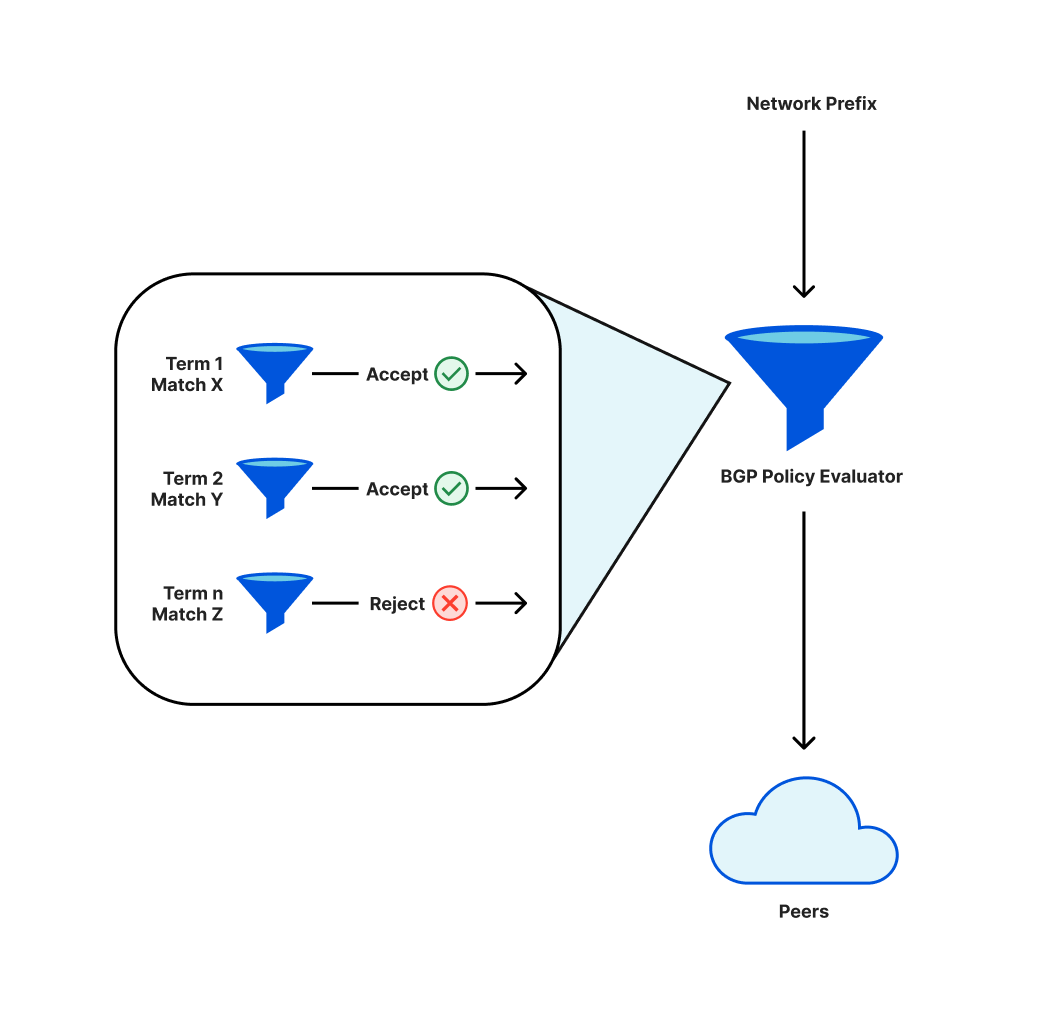
En déployant une modification de nos politiques d'annonce des préfixes, une réorganisation des termes nous a conduits à retirer un sous-ensemble de préfixes essentiel.
Du fait de ce retrait, les techniciens de Cloudflare ont rencontré des difficultés supplémentaires pour joindre les emplacements concernés afin d'annuler la modification problématique. Nous disposons de procédures de secours conçues pour traiter de tels événements et y avons eu recours pour prendre le contrôle des points d'implantation affectés.
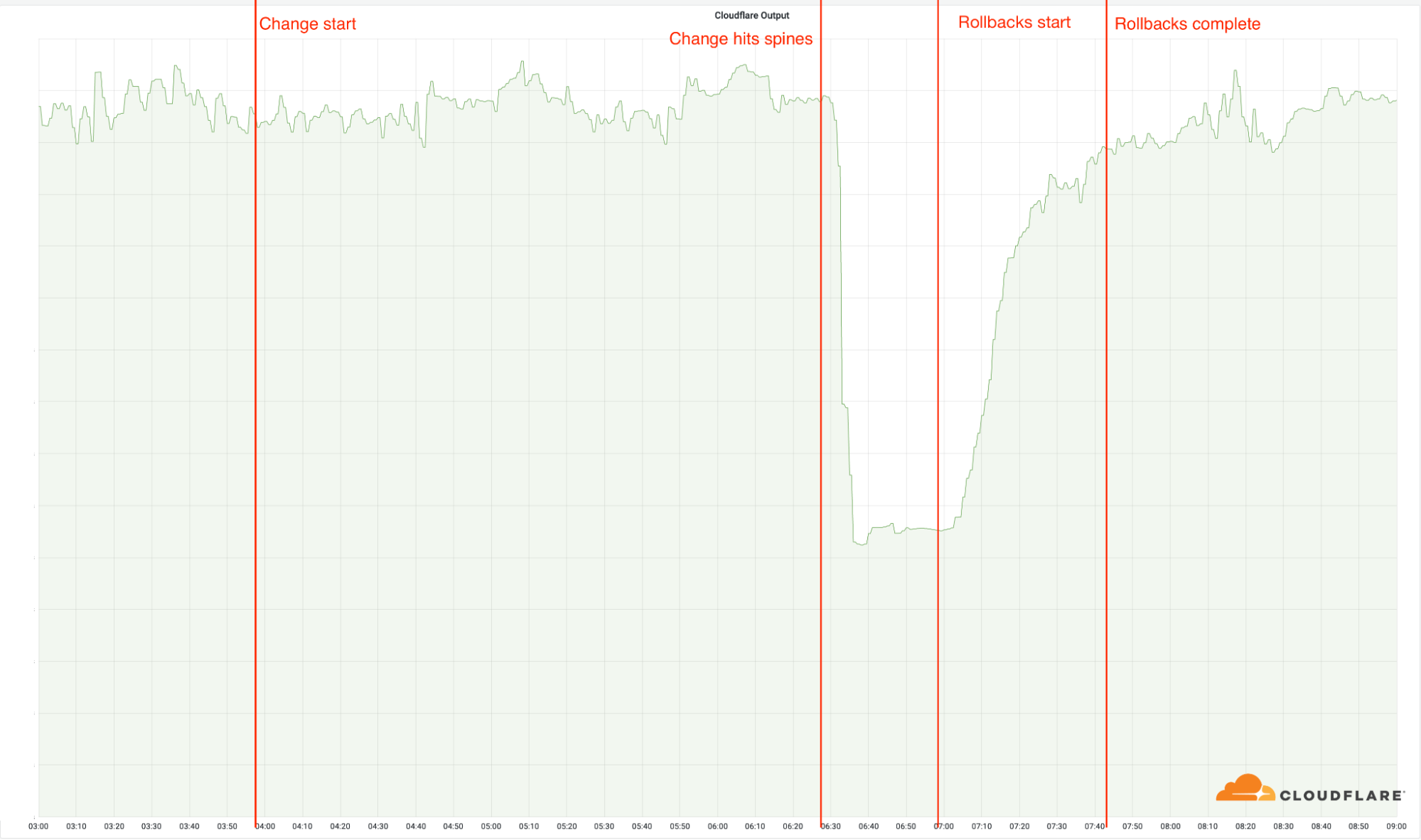
3 h 56 : déploiement de la modification dans le premier point d'implantation. Aucun de nos points d'implantation n'est affecté par la modification, car ces derniers utilisent notre ancienne architecture.
6 h 17 : la modification est déployée dans nos points d'implantation les plus fréquentés, mais pas ceux qui disposent de la nouvelle architecture.
6 h 27 : le déploiement a atteint nos points d'implantation les plus fréquentés et disposant de la nouvelle architecture. La modification est déployée vers les troncs. C'est à ce moment que l'incident a débuté, car la modification a rapidement mis hors ligne ces 19 points d'implantation.
6 h 32 : déclaration de l'incident Cloudflare en interne.
6 h 51 : première modification effectuée sur un routeur pour vérifier la possibilité d'une cause fondamentale.
6 h 58 : cause fondamentale trouvée et comprise. Les travaux d'annulation de la modification problématique commencent.
7 h 42 : finalisation de la dernière annulation. Celle-ci a pris du retard, car les modifications apportées par les techniciens réseau se sont chevauchées les unes les autres. Ces derniers annulaient ainsi les annulations effectuées précédemment et le problème initial réapparaissait de manière sporadique.
9 h : fin de l'incident.
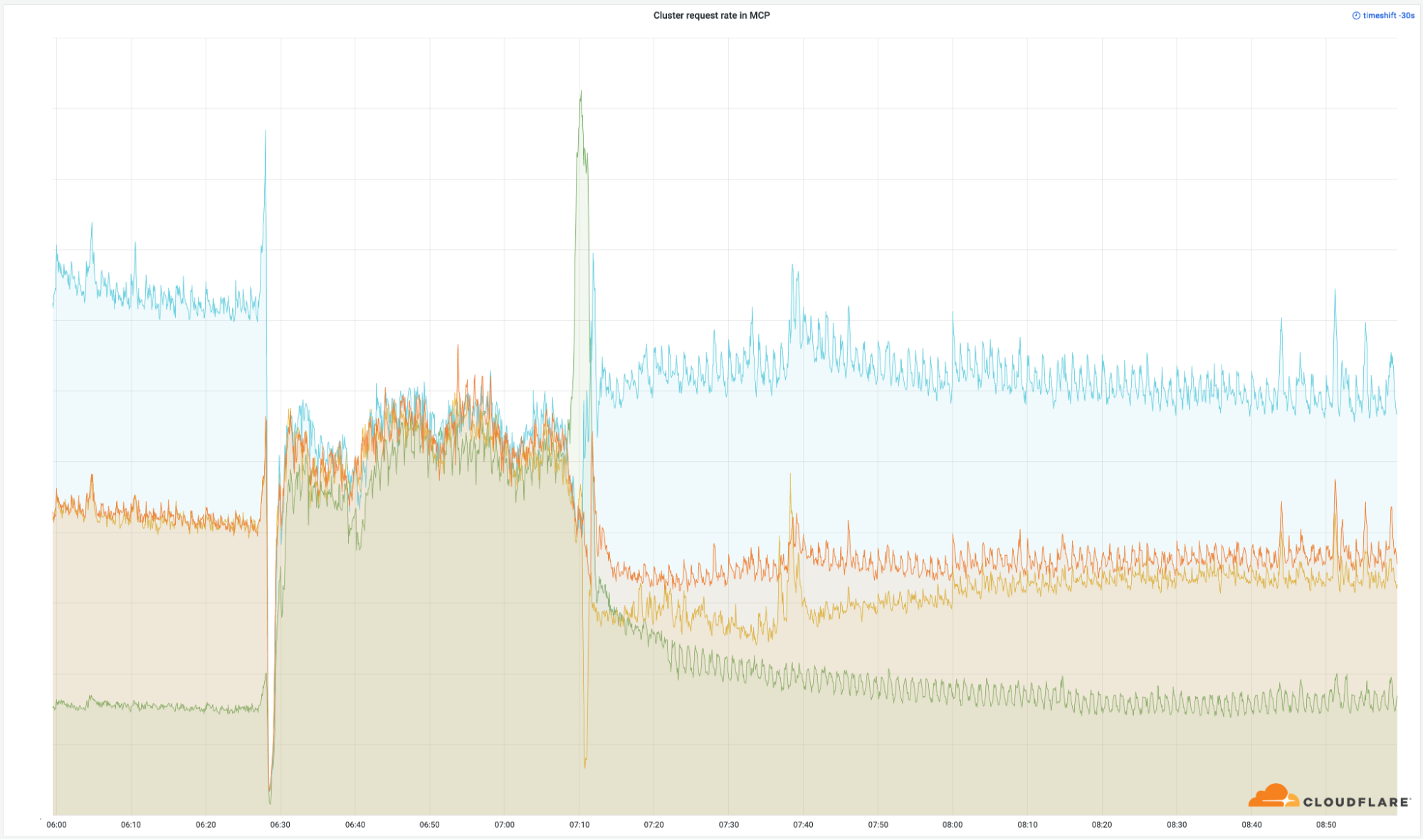
Le caractère critique de ces datacenters apparaît clairement dans le nombre de requêtes fructueuses que nous avons renvoyées à l'échelle du monde entier :
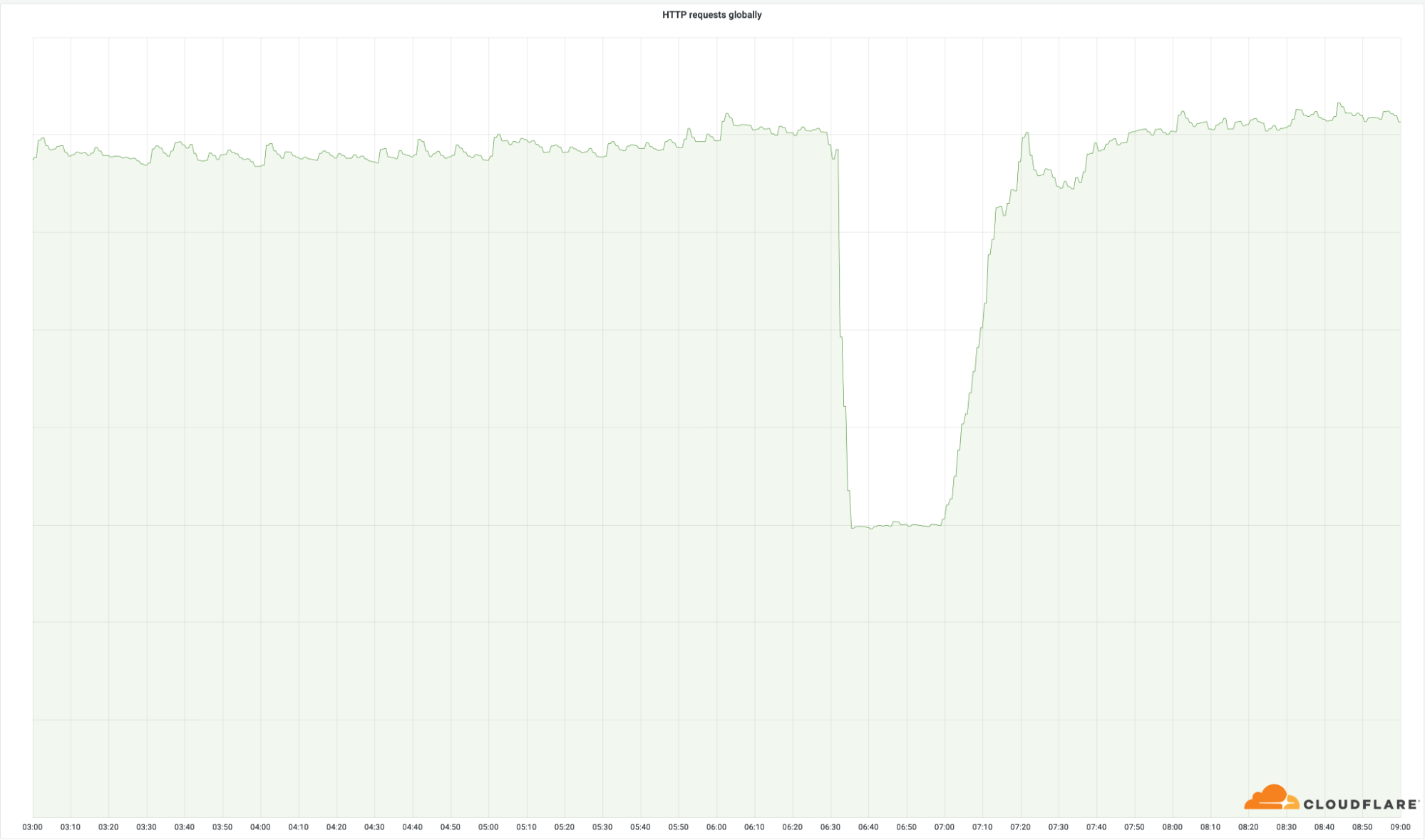
Ces points d'implantation ne constituent qu'un petit pourcentage de l'ensemble de notre réseau (4 %), mais ils ont affecté 50 % de notre nombre total de requêtes. Nous pouvons faire les mêmes observations à l'égard de la bande passante de notre trafic sortant :
Description technique de l'erreur et de son déroulement
Dans le cadre de nos efforts continus d'homogénéisation de la configuration de notre infrastructure, nous avons déployé une modification permettant de normaliser les communautés BGP que nous attachons à un sous-ensemble des préfixes que nous annonçons. Plus spécifiquement, nous avons ajouté des communautés informelles à nos préfixes « site-local ». Ces préfixes permettent à nos nœuds de communiquer les uns avec les autres, ainsi que de se connecter aux serveurs d'origine des clients. Dans le cadre de la procédure de modification en vigueur chez Cloudflare, un ticket de demande de modification (Change Request, CR) a été créé. Ce dernier comprend une version en « marche à blanc » de la modification, ainsi qu'une procédure de déploiement par étapes de cette dernière. Avant l'autorisation de la modification, la demande fait également l'objet d'un examen collégial conduit par plusieurs techniciens. Malheureusement, dans ce cas précis, les étapes ne se sont pas révélées suffisamment petites pour que l'erreur puisse être détectée avant d'atteindre nos troncs.
La modification se présentait sous la forme suivante sur l'un des routeurs :
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
Cette dernière se montrait inoffensive et se contentait d'ajouter des informations supplémentaires aux annonces de ces préfixes. La modification déployée sur les troncs était la suivante :
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
Un premier coup d'œil à ce diff pourrait donner l'impression que la modification se révèle identique, mais malheureusement, ce n'était pas le cas. Si nous nous concentrons sur la première partie du diff, la raison apparaît comme évidente :
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
Sous ce format de diff, les points d'exclamation situés devant les termes indiquent une réorganisation de ces derniers. Dans ce cas précis, plusieurs termes sont montés dans la liste et deux termes ont été ajoutés en bas. De manière plus spécifique, le terme 4-ADV-SITE-LOCALS s'est retrouvé plus bas. Ce terme se situait alors derrière le terme REJECT-THE-REST qui, comme son nom l'indique, constitue un rejet explicite :
term REJECT-THE-REST {
then reject;
}
Comme ce terme se situe désormais avant les termes site-local, nous avons immédiatement cessé d'annoncer nos préfixes site-local, une opération qui a supprimé notre accès direct à l'ensemble des points d'implantation affectés en l'espace d'une seconde, tout en retirant à nos serveurs la capacité de joindre des serveurs d'origine.
En plus de cette incapacité de contacter les serveurs d'origine, le retrait de ces préfixes site-local a également entraîné l'arrêt de notre système d'équilibrage de charge interne Multimog (une variante de notre équilibreur de charge Unimog), car ce dernier ne pouvait plus transférer les requêtes entre les serveurs au sein de nos MCP. Les plus petites grappes de calcul d'un MCP recevaient ainsi la même quantité de trafic que les grappes les plus vastes et les petites grappes se retrouvaient donc en surcharge.
Mesures de correction et de suivi
Cet incident a eu des répercussions très étendues. En outre, nous prenons la disponibilité très au sérieux. Nous avons identifié plusieurs domaines d'amélioration et continuerons à nous efforcer de dénicher d'éventuelles autres lacunes susceptibles d'entraîner une récidive.
Dans l'immédiat, nous travaillons sur ce qui suit :
Processus : le programme MCP a été conçu pour améliorer la disponibilité, mais une faille procédurale dans la manière dont nous avons mis à jour ces datacenters a finalement eu des répercussions plus larges, notamment dans ces points d'implantation MCP. Nous avons suivi une procédure échelonnée pour le déploiement de la modification, mais le processus n'incluait pas de datacenter MCP avant la dernière étape. Les politiques de modification et d'automatisation de ces dernières doivent inclure des procédures de test et déploiement spécifiques à l'architecture MCP afin de garantir l'absence de conséquences inattendues.
Architecture : la configuration incorrecte du routeur a bloqué l'annonce des routes appropriées à notre périphérie. Cette erreur empêchait donc le trafic de circuler correctement vers notre infrastructure. En définitive, la déclaration de politique (policy-statement) à l'origine de l'annonce de routage incorrecte sera remaniée afin d'empêcher une réorganisation incorrecte et non intentionnelle.
Automatisation : au niveau de notre suite d'automatisation, nous avons identifié plusieurs opportunités susceptibles d'atténuer tout ou partie des répercussions observées des suites de cet événement. Nous nous concentrerons en premier lieu sur deux types d'améliorations du processus d'automatisation, l'une conçue pour appliquer une politique d'échelonnement améliorée aux déploiements concernant la configuration réseau et l'autre pour assurer un plan de retour en arrière automatisé de type « commit-confirm » (soumission-confirmation). La première de ces améliorations (la politique d'échelonnement améliorée) aurait réduit de manière considérable les répercussions générales et la seconde (le plan de retour en arrière, ou rollback) aurait permis de réduire fortement le Time-to-Resolve (temps de résolution) pendant l'incident.
Conclusion
Si Cloudflare a considérablement investi dans la conception de notre architecture MCP afin d'améliorer la disponibilité de nos services, nous nous sommes clairement révélés en dessous des attentes de nos clients avec cet incident particulièrement douloureux. Nous en sommes profondément désolés pour les perturbations subies par nos clients et l'ensemble de nos utilisateurs qui n'ont pas pu accéder à leurs propriétés Internet pendant la panne. Nous avons d'ores et déjà commencé à travailler sur les modifications décrites ci-dessus et poursuivrons nos efforts avec diligence afin de nous assurer qu'une telle situation ne puisse plus se reproduire.