

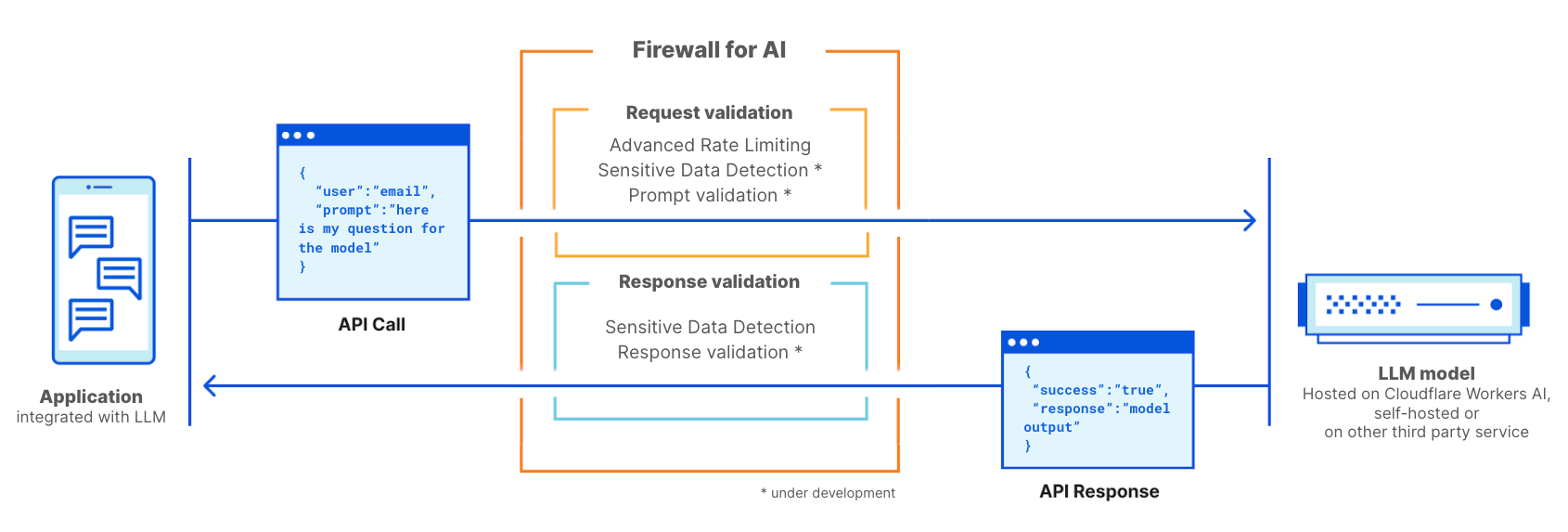
今天,Cloudflare 宣佈正在開發 Firewall for AI,這是一個可以部署在大型語言模型 (LLM) 前方的保護層,用於在濫用行為到達模型之前識別它們。
隨著 AI 模型(尤其是 LLM)的激增,客戶表示他們很關注保護自有 LLM 的最佳策略。在網際網路連線應用程式中使用 LLM 會引入新的漏洞,這些漏洞可能會被不良行為者利用。
影響傳統 Web 和 API 應用程式的一些漏洞也適用於 LLM 領域,包括插入或資料外流。然而,由於 LLM 的運作方式,現在出現了一系列新的威脅。例如,研究人員最近在一個 AI 協作平台中發現了一個漏洞,允許他們劫持模型並執行未經授權的動作。
Firewall for AI 是一種進階 Web 應用程式防火牆 (WAF),專為使用 LLM 的應用程式量身定制。它將包含一組可以部署在應用程式前方的工具,用於偵測漏洞並為模型擁有者提供可見性。該工具組將包括 WAF 中已經包含的產品,例如限速和敏感資料偵測,以及目前正在開發的新保護層。這項新的驗證會分析終端使用者提交的提示詞,以識別利用該模型擷取資料的嘗試和其他濫用嘗試。利用 Cloudflare 網路的規模,Firewall for AI 在盡可能靠近使用者的地方執行,使我們能夠及早識別攻擊並保護終端使用者和模型免受濫用和攻擊。
在我們深入研究 Firewall for AI 的工作原理及其完整功能集之前,我們先研究 LLM 的獨特之處以及它們帶來的攻擊面。我們將使用 OWASP LLM 十大漏洞作為參考。
為什麼 LLM 與傳統應用程式不同?
當將 LLM 視為網際網路連線的應用程式時,其與更傳統的 Web 應用程式有兩個主要區別。
首先,使用者與產品互動的方式。傳統應用程式本質上是確定性的。考慮一個銀行應用程式,它由一組操作定義(查看我的餘額、進行轉帳等)。透過控制這些端點接受的一組具體操作:「GET /balance」或「POST /transfer」,即可確保業務操作(和資料)的安全性。
LLM 操作在設計上就是不確定的。首先,LLM 互動基於自然語言,這使得識別有問題的請求比比對攻擊特徵更困難。此外,除非快取了回應,否則 LLM 通常每次都會提供不同的回應——即使重複輸入相同的提示詞也是如此。這使得更加難以限制使用者與應用程式互動的方式。這也對使用者構成了威脅,因為使用者可能會接觸到錯誤的資訊,從而削弱對模型的信任。
其次,一個很大的區別是應用程式控制平面與資料互動的方式。在傳統應用程式中,控制平面(程式碼)與資料平面(資料庫)明顯分離。定義的操作是與底層資料互動的唯一方式(例如顯示我的付款交易歷程記錄)。這樣,安全從業人員能夠專注於在控制平面上新增檢查和防護措施,從而間接保護資料庫。
LLM 的不同之處在於,訓練資料透過訓練過程成為模型本身的一部分,因而很難以控制應用程式如何將該資料作為使用者提示詞的結果分享出去。人們正在探索一些架構解決方案,例如將 LLM 分為不同層級和隔離資料。然而,目前還沒有找到解決問題的靈丹妙藥。
從安全角度來看,這些差異使得攻擊者能夠設計新的攻擊手段,以 LLM 為目標,並避開為傳統 Web 應用程式設計的現有安全工具的雷達。
OWASP LLM 漏洞
OWASP 基金會發佈了 LLM 十大漏洞清單,為考慮如何保護語言模型提供了一個有用的框架。其中一些威脅類似於 OWASP 的 Web 應用程式十大漏洞,另一些則是語言模型所特有的。
類似于 Web 應用程式,其中一些漏洞在 LLM 應用程式設計、開發和訓練時予以解決效果最佳。例如,可透過在用於訓練新模型的資料集中引入漏洞來執行訓練資料投毒。當模型上線時,有毒的資訊就會呈現給使用者。供應鏈漏洞和不安全的外掛程式設計是新增到模型的元件(如第三方軟體封裝)中引入的漏洞。最後,處理過度代理時,管理授權和權限至關重要,因為不受約束的模型可能在更廣泛的應用程式或基礎架構中執行未經授權的動作。
相反,透過採用 Cloudflare Firewall for AI 之類的代理安全解決方案,可以緩解提示詞插入、模型阻斷服務和敏感資料揭露等漏洞。接下來,我們將提供有關這些漏洞的更多細節,並討論 Cloudflare 如何具備緩解這些漏洞的最佳優勢。
LLM 部署
語言模型風險也取決於部署模型。目前,我們看到三種主要的部署方法:內部 LLM、公用 LLM 和產品 LLM。在全部這三種情況下,您都需要保護模型免遭濫用、保護模型中儲存的任何專有資料,以及保護終端使用者免於接觸錯誤訊息或不當內容。
- 內部 LLM:公司開發 LLM 來支援員工的日常任務。這些被視為公司資產,不得被非員工存取。例如,使用銷售資料和客戶互動進行訓練並用於產生定制化提案的 AI co-pilot,或者使用內部知識庫進行訓練且可供工程師查詢的 LLM。
- 公用 LLM:這些是可以在公司邊界之外存取的 LLM。這些解決方案通常有任何人都可以使用的免費版本,而且它們通常接受過一般或公共知識的訓練。範例包括 OpenAI 的 GPT 或 Anthropic 的 Claude。
- 產品 LLM:從公司的角度來看,LLM 可以成為提供給客戶的產品或服務的一部分。這些通常是定制的自托管解決方案,可以作為與公司資源互動的工具。例如客戶支援聊天機器人或 Cloudflare AI 助理。
從風險的角度來看,產品 LLM 公用 LLM 之間的差異在於誰承擔了成功攻擊的影響。公用 LLM 被認為是對資料的威脅,因為最終進入模型的資料幾乎可以被任何人存取。這也是許多公司建議其員工不要在公開可用服務的提示中使用機密資訊的原因之一。如果模型在訓練期間(有意或無意)存取了專有資訊,那麼產品 LLM 可以被視為對公司及其知識產權的威脅。
Firewall for AI
Cloudflare Firewall for AI 將像傳統 WAF 一樣部署,將會對使用 LLM 提示發起的每個 API 請求進行掃描,以查找潛在攻擊的模式和特徵。
Firewall for AI 可部署在託管於 Cloudflare Workers AI 平台的模型前方,或者託管於任何第三方基礎架構上的模型前方。它可以與 Cloudflare AI Gateway 一起使用,客戶將能使用 WAF 控制平面來控制和設定 Firewall for AI。
防止巨流量攻擊
OWASP 列出的威脅之一是模型阻斷服務攻擊。與傳統應用程式類似,DoS 攻擊是透過消耗異常大量的資源來進行的,這會導致服務品質下降或可能增加執行模型的成本。鑑於 LLM 執行所需的資源量以及使用者輸入的不可預測性,這種類型的攻擊可能會造成破壞。
透過採用限速原則來控制單一工作階段的請求速率,從而限制上下文視窗,可以減輕這種風險。立即透過 Cloudflare 代理您的模型,您將獲得現成可用的 DDoS 防護。您還可以使用限速和進階限速,透過設定工作階段期間單一 IP 位址或 API 金鑰執行的請求的最大速率,管理對模型的請求速率。
透過敏感資料偵測識別敏感資訊
敏感資料有兩種用例,取決於您是否擁有模型和資料,或者您是否想要阻止使用者將資料傳送到公用 LLM。
根據 OWASP 的定義,當 LLM 無意中在回應中洩漏了機密資料時,就會發生敏感資訊揭露,從而導致未經授權的資料存取、隱私侵犯和安全漏洞。防止這種情況的一種方法是新增嚴格的提示驗證。另一種方法是在個人識別資訊 (PII) 離開模型時予以識別。一種相關的情況是使用公司知識庫來訓練模型,其中可能包含敏感資訊,例如 PII(如社會安全號碼)、專有程式碼或演算法。
使用 Cloudflare WAF 保護 LLM 模型的客戶可以採用敏感資料偵測 (SDD) WAF 受管理規則集來識別模型在回應中傳回的某些 PII。客戶可以在 WAF 安全事件上查看 SDD 匹配情況。如今,SDD 作為一組受管理規則提供,旨在掃描財務資訊(例如信用卡號)以及祕密(API 金鑰)。作為路線圖的一部分,我們計劃允許客戶建立自己的自訂指紋。
另一個用例旨在防止使用者與外部 LLM 提供者(例如 OpenAI 或 Anthropic)分享 PII 或其他敏感資訊。為了防止這種情況,我們計劃擴展 SDD 以掃描請求提示並將其輸出與 AI Gateway 整合,其中除了提示的歷程記錄之外,我們還偵測請求中是否包含某些敏感資料。我們將從使用現有的 SDD 規則開始,並計劃允許客戶編寫自己的自訂特徵。與此相關的是,我們聽到很多客戶談論的另一個功能是混淆。一旦可用,擴展的 SDD 將允許客戶在提示資訊到達模型之前,混淆特定敏感資料。請求階段的 SDD 正在開發中。
防止模型濫用
模型濫用是一種更廣泛的濫用類別。這包括「提示詞插入」方法,或者提交請求使模型產生幻覺,或導致不準確、冒犯性、不適當或完全偏離主題的回應。
提示詞插入嘗試透過特製的輸入來操縱語言模型,從而導致 LLM 做出意外的回應。插入的結果可能會有所不同,從擷取敏感資訊到透過模仿與模型的正常互動來影響決策。提示詞插入的一個典型範例是操縱履歷表來影響履歷篩選工具的輸出。
我們從 AI Gateway 客戶那裡聽到的一個常見用例是,他們希望避免其應用程式產生有毒、冒犯性或有問題的語言。不控制模型結果的風險包括聲譽受損以及因提供不可靠的回應而損害終端使用者。
可以透過在模型前面新增額外的保護層來管理這些類型的濫用。可以訓練該保護層,來封鎖插入嘗試或封鎖屬於不適當類別的提示詞。
提示詞和回應驗證
Firewall for AI 將執行一系列偵測,旨在識別提示詞插入嘗試和其他濫用行為,例如確保主題停留在模型擁有者定義的邊界內。與其他現有 WAF 功能一樣,Firewall for AI 將自動尋找 HTTP 請求中嵌入的提示詞,或允許客戶根據在請求的 JSON 正文中可以找到提示詞的位置來建立規則。
啟用後,防火牆將分析每個提示詞,並根據其惡意的可能性提供一個分數。它還會根據預先定義的類別標記提示詞。分數範圍從 1 到 99,表示提示詞插入的可能性,其中 1 表示最有可能。
客戶將能夠建立 WAF 規則,以封鎖或处理在一个或两个维度中具有特定评分的请求。您可以將此分數與其他現有訊號(例如機器人分數或攻擊分數)結合起來,以確定請求是應該到達模型還是應該被封鎖。例如,它可以與機器人分數結合,以識別請求是否為惡意以及是否由自動化來源產生。
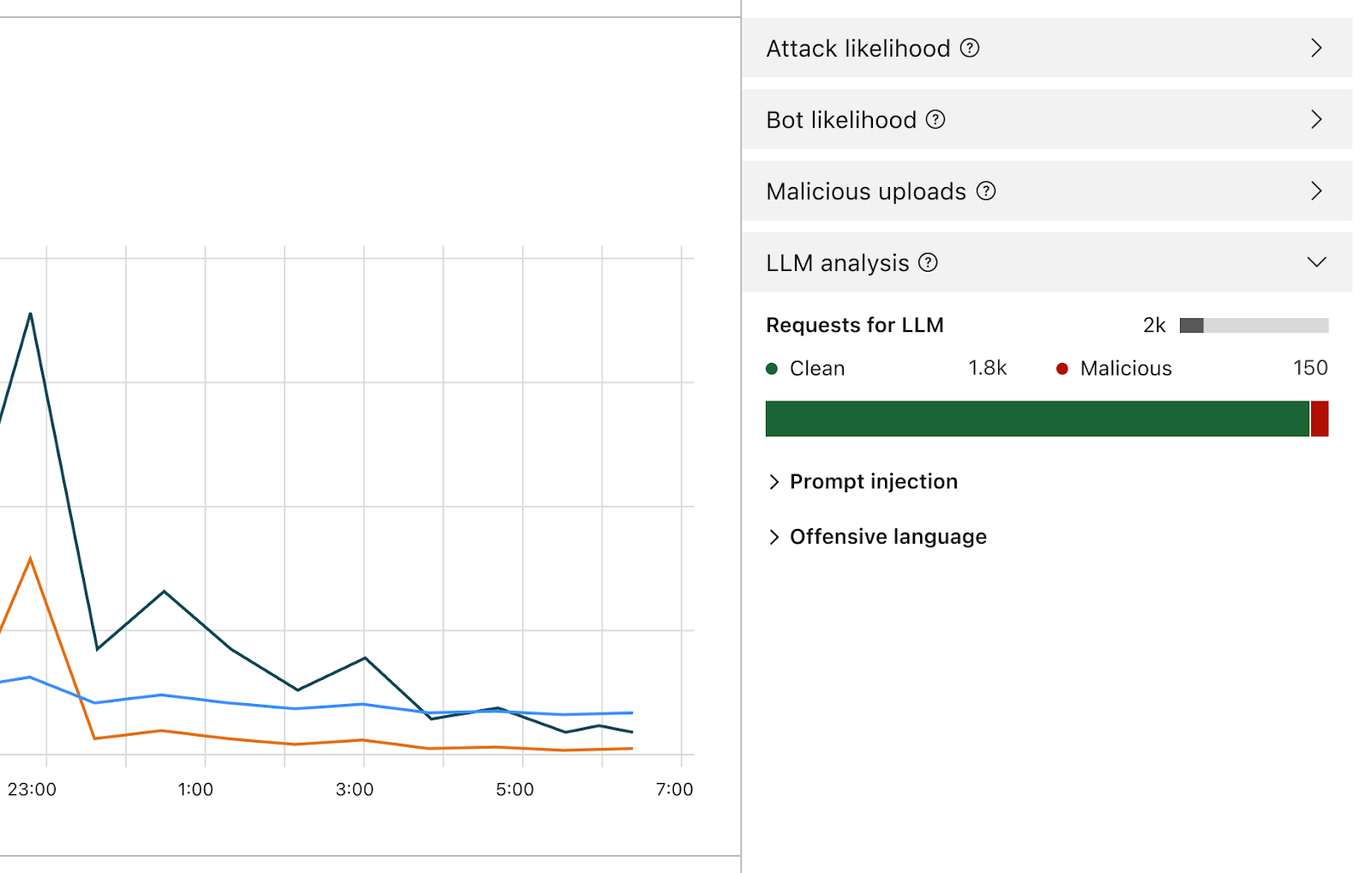
除了分數之外,我們還將為每個提示詞指派標籤,這些標籤可在建立規則時使用,以防止屬於任何這些類別的提示詞到達其模型。例如,客戶將能夠建立規則來封鎖特定主題。例如,使用攻擊性詞彙,或與宗教、性內容或政治相關詞彙的提示詞。
如何使用 Firewall for AI?誰有資格獲得該產品?
使用應用程式安全性進階產品的企業方案客戶可以立即開始使用進階限速和敏感資料偵測(在回應階段)。這兩種產品都可以在 Cloudflare 儀表板的 WAF 部分中找到。Firewall for AI 的提示詞驗證功能目前正在開發中,測試版將在未來幾個月內向所有 Workers AI 使用者發佈。註冊加入等候名單,並在該功能可用時收到通知。
結論
Cloudflare 是首批推出一套工具來保護 AI 應用程式的安全提供者之一。使用 Firewall for AI,客戶可以控制哪些提示詞和請求能夠到達其語言模型,從而降低濫用和資料外流的風險。請繼續關注,以瞭解有關 AI 應用程式安全性如何演變的更多資訊。