


LoRA 微调 LLM 推理功能开启公测
今天,我们隆重宣布,您现在可在 Workers AI 上使用 LoRA 运行微调推理。该功能现已开启公测,针对预训练的 LoRA 适配器,与 Mistral、Gemma 或 Llama 2 一起使用,但有一些限制。请浏览我们的 产品公告博客文章, 了解 BYO LoRA 功能的概述。
本文将深入探讨什么是微调和 LoRA,向您展示如何在我们的 Workers AI 平台上使用它,以及我们如何在平台上实施这一功能的技术细节。
什么是微调?
微调(fine-tuning)是一个通用术语,指通过使用更多数据继续训练来修改 AI 模型。微调的目的是提高生成的模型与数据集相似的概率。从头开始训练一个模型对于许多用例来说并不现实,因为训练模型既昂贵又耗时。通过对现有的预训练模型进行微调,您可以从其能力中获益,同时还能完成您想要完成的任务。 低秩适应(Low-Rank Adaptation,LoRA)是一种特定的微调方法,可应用于各种模型架构,而不仅仅是 LLM。在传统的微调方法中,通常会直接修改预训练模型的权重或将其与额外的微调权重融合在一起。而 LoRA 允许微调权重和预训练模型保持分离,预训练模型保持不变。最终结果是,您可以训练模型,使其在特定任务上更加准确,例如生成代码、具有特定个性或生成特定风格的图像。 您甚至可以对现有的 LLM进行微调,以了解有关特定主题的更多信息。
保持原始基础模型权重的方法意味着你可以用相对较少的计算量创建新的微调权重。您可以利用现有的基础模型(如 Llama、Mistral 和 Gemma),并根据自己的需要对其进行调整。
微调如何工作?
为了更好地理解微调以及 LoRA 为何如此有效,我们必须退一步,了解 AI 模型的工作原理。 AI 模型(如 LLM)是通过深度学习技术训练出来的神经网络。在神经网络中,有一组参数作为模型领域知识的数学表示,由权重和偏差(简单而言,就是数字)组成。这些参数通常用大型数字矩阵表示。模型的参数越多,模型就越大,所以当您看到 llama-2-7b这样的模型时 ,您可以读出 "7b",并知道该模型有 70 亿个参数。
模型的参数决定了它的行为。 当您从头开始训练一个模型时,这些参数通常一开始都是随机数。 在数据集上训练模型时,这些参数会被一点一点地调整,直到模型反映出数据集并表现出正确的行为。 有些参数会比其他参数更重要,因此我们会应用一个权重,用它来表示重要性的高低。 权重对模型捕捉训练数据中的模式和关系的能力起着至关重要的作用。
传统的微调会用一组新的权重来调整训练模型中的所有参数。因此,微调模型需要我们提供与原始模型相同数量的参数,这意味着训练和运行一个完全微调模型的推理需要大量时间和计算。此外,新的先进模型或现有模型的版本会定期发布,这意味着完全微调模型的训练、维护和存储成本会变得很高。
LoRA 是一种有效的微调方法
最简单地说,LoRA 避免了调整预训练模型中的参数,而是允许我们应用少量附加参数。 这些附加参数临时应用于基础模型,以有效控制模型行为。 与传统的微调方法相比,训练这些附加参数(称为 LoRA 适配器)所需的时间和计算量要少得多。 训练完成后,我们会将 LoRA 适配器打包成一个单独的模型文件,然后将其插入基础模型中进行训练。 一个完全微调的模型可能有几十个千兆字节大小,而这些适配器通常只有几兆字节。 这使其更易于分发,使用 LoRA 提供微调推理只需在总推理时间上增加毫秒的延迟。
如果您想了解 LoRA 为何如此有效,那么请准备好——我们首先得简单学习一下线性代数。如果您从大学开始就没有想过这个术语,别担心,我们会详细解释。
数学原理
在传统微调方法中,我们可以对模型的权重(W0)进行调整,输出一组新的权重——因此,原始模型权重与新权重之间的差异为 ΔW ,代表权重的变化。因此,经过微调的模型将具有一组新的权重,可以表示为原始模型权重加上权重变化,即 W0 + ΔW 。
请记住,所有这些模型权重实际都是表示为大型数字矩阵。在数学中,每个矩阵都有一个称为秩(r)的属性,描述矩阵中线性独立的列或行的数量。当矩阵为低秩时,它们只有几列或几行是 “重要”的,因此我们实际上可以将它们分解或拆分成两个带有最重要参数的较小矩阵(就像代数中的因式分解)。这种技术被称为秩分解,它允许我们在保留最重要内容的同时,大大减少和简化矩阵。在微调的背景下,秩决定了原始模型中有多少多少参数被改变—— 秩越高,微调越强,对输出具备更精细的控制。
根据最初的 LoRA 论文,研究人员发现,当一个模型是低秩时,代表权重变化的矩阵也是低秩的。因此,我们可以对代表权重变化的矩阵 ΔW 进行秩分解 ,创建两个较小的 矩阵A、B,其中 ΔW= BA。现在,模型的变化可以用两个更小的低秩矩阵来表示。 因此,这种微调方法被称为低阶适应。
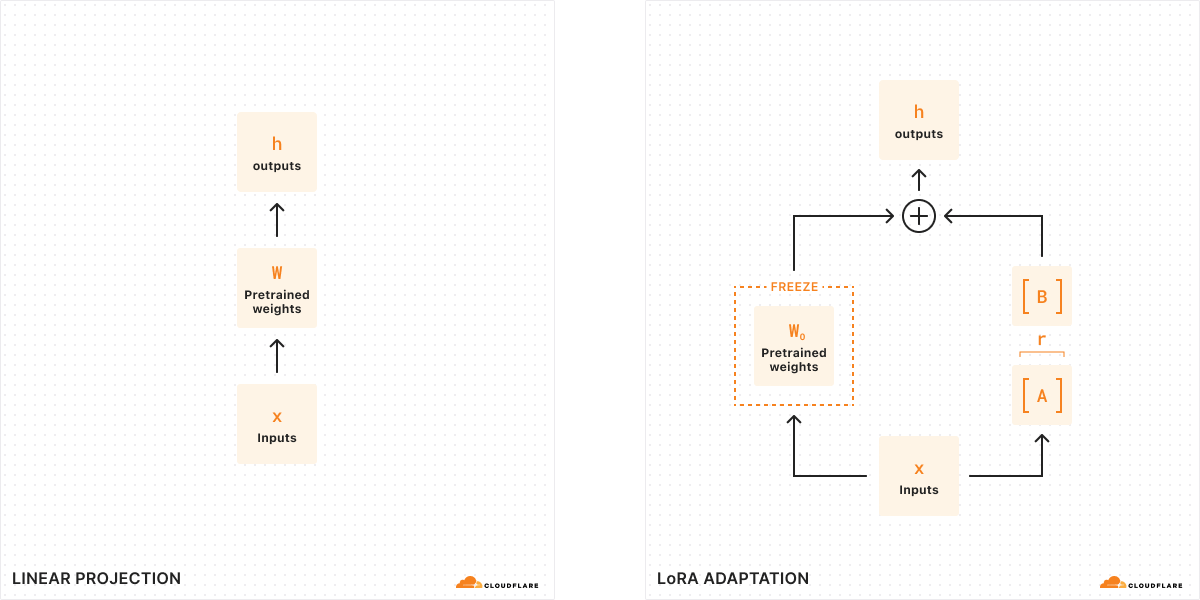
当我们运行推理时,我们只需要较小的矩阵 A、B 来改变模型的行为。A 和 B 中的模型权重构成了我们的 LoRA 适配器(以及配置文件)。运行时,我们将模型权重加在一起,将原始模型( W0 )和 LoRA 适配器(A、B)合并起来 。加法和减法都是简单的数学运算,这意味着我们可以通过从 W0 中加减 A、B来快速更换不同的 LoRA 适配器 。通过临时调整原始模型的权重,我们可以修改模型的行为和输出,从而以最小的延迟增加获得微调推理。
根据最初的 LoRA 论文,“LoRA 可以将可训练参数的数量减少 10000 倍,GPU 内存需求减少 3 倍”。正因为如此,LoRA 是最流行的微调方法之一,原因是它的计算成本远低于完全微调模型,不会大幅增加推理时间,而且体积小得多,便于携带。
如何通过 Workers AI 使用 LoRA?
因为我们运行无服务器推理的方式,Workers AI 非常适合运行 LoRA。我们目录中的模型总是预先加载在我们的 GPU上,这意味着它们保持随时可用状态,让您的请求不会遇到冷启动延迟。这意味着基础模型始终可用,我们可以根据需要动态加载和切换 LoRA 适配器。 我们实际上可以在一个基础模型中插入多个 LoRA 适配器,以便同时服务多个不同的微调推理请求。
使用 LoRA 进行微调时,输出将是两个文件:自定义模型权重(safetensors 格式)和适配器配置文件(json 格式)。如果要自己创建这些权重,可以使用 Hugging Face PEFT (参数高效微调)库结合 Hugging Face AutoTrain LLM 库 在自己的数据上训练 LoRA 。您还可以在 Auto Train 和 Google Colab 等服务上运行训练任务 。此外, Hugging Face 上还有许多开源 LoRA 适配器 ,可满足各种用例。
最终,我们希望在我们的平台上支持 LoRA 训练工作负载,但目前我们需要您就将训练好的 LoRA 适配器带到 Workers AI,这就是我们将此功能称为BYO(自带)LoRA 的原因。
在最初的公开测试版本中,我们允许人们在 Mistral、Llama 和 Gemma 使用 LoRA。我们为这些模型预留了可接受 LoRA 的版本,您可以在模型名称后添加`-lora`来访问这些版本。您的适配器必须是根据我们以下支持的基础模型之一进行微调的:
@cf/meta-llama/llama-2-7b-chat-hf-lora@cf/mistral/mistral-7b-instruct-v0.2-lora@cf/google/gemma-2b-it-lora@cf/google/gemma-7b-it-lora
随着我们推出这个功能的公开测试版,有一些限制需要注意:目前还不支持量化的 LoRA 模型,LoRA 适配器必须小于 100 MB,最大秩为 8,初始公测中每个账户可试用最多 30 个 LoRA。要开始在 Workers AI 上使用 LoRA,请阅读开发人员文档。
一如既往,我们希望用户在使用 Workers AI 和我们全新推出的 BYO LoRA 功能 时,能牢记我们的服务条款,包括模型许可条款中包含的任何模型特定限制。
我们是如何构建多租户 LoRA 服务的?
同时为多个 LoRA 模型提供服务对 GPU 资源利用率提出了挑战。 虽然有可能将推理请求批量发送到一个基础模型,但服务独特的 LoRA 适配器带来的额外复杂性导致批量处理请求要困难得多。为解决这一问题,我们利用 Punica CUDA 内核设计与全局缓存优化相结合,以处理多租户 LoRA 服务的内存密集型工作负载,同时提供较低的推理延迟。
论文《 Punica:多租户 LoRA 服务》一文中介绍了 Punica CUDA 内核,作为在同一个基础模型上服务多个、明显不同的 LoRA 模型的方法。与以前的推理技术相比,这种方法大幅提高了吞吐量和延迟。这种优化部分是通过启用请求批处理来实现的,即使在服务不同 LoRA 适配器时。
Punica 内核系统的核心是一个新的 CUDA 内核,名为“分段收集矩阵-矢量乘法(SGMV)”。 SGMV 允许 GPU 在服务不同 LoRA 模型时,只存储预训练模型的一个副本。 Punica 内核设计系统整合了独特 LoRA 模型的批处理请求,通过并行处理一批中不同请求的特征-权重乘法来提高性能。 然后对同一 LoRA 模型的请求进行分组,以提高操作强度。 最初,GPU 会加载基本模型,同时为 KV 缓存保留大部分 GPU 内存。 当收到请求时,LoRA 组件(A 和 B 矩阵)会按需从远程存储(Cloudflare 缓存或 R2)加载。 这种按需加载只带来几毫秒的延迟,这意味着多个 LoRA 适配器可以无缝获取和提供服务,对推理性能的影响微乎其微。 频繁请求的 LoRA 适配器会被缓存,以实现最快的推理速度。
一旦请求的 LoRA 被缓存在本地,它可用于推理的速度仅受 PCIe 带宽的限制。无论如何,鉴于每个请求都可能需要自己的 LoRA,因此异步执行 LoRA 下载和内存复制操作变得至关重要。 Punica调度器正是解决这一挑战,只对当前在 GPU 内存中有所需 LoRA 权重的请求进行批处理,并将没有所需权重的请求排队,直到所需权重可用且请求可以有效地加入批处理。
通过有效管理 KV 缓存和批处理这些请求,可以处理大量多租户 LoRA 服务工作负载。 另一项重要的优化措施是使用连续批处理。 常见的批处理方法要求对同一适配器的所有请求在达到停止条件后才能释放。 连续批处理允许提前释放批处理中的一个请求,以便不必等待运行时间最长的请求。
鉴于部署到 Cloudflare 网络的 LLM 在全球范围内可用,因此 LoRA 适配器模型也必须在全球范围内可用。 很快,我们将在 Cloudflare 边缘缓存远程模型文件,以进一步减少推理延迟。
在 Workers AI 上运行微调的路线图
推出对 LoRA 适配器的支持是在我们的平台上实现微调的重要一步。 除了目前可用的 LLM 微调功能外,我们还期待支持更多模型和各种任务类型,包括图像生成。
我们对 Workers AI 的愿景是成为开发人员运行 AI 工作负载的最佳场所,这包括对其本身进行微调的过程。 最终,我们希望能够直接在 Workers AI 上运行微调训练任务以及完全微调模型。 这为 AI 解锁了许多用例,通过赋予模型更多的粒度和细节以处理特定的任务,从而使 AI 在组织中发挥更大的作用。
通过 AI Gateway ,我们就可以帮助开发人员记录他们的提示词和响应,然后他们就可以利用这些提示词和响应来使用生产数据对模型进行微调。我们的愿景是提供一键式微调服务,AI Gateway上的日志数据可用于重新训练模型(在 Cloudflare 上),经过微调的模型可重新部署到 Workers AI 上进行推理。这将使开发人员能够个性化他们的 AI 模型,以适应他们的应用,允许低至每个用户级别的粒度。经过微调的模型可以更小、更优化,帮助用户节省 AI 推理的时间和金钱,而且神奇之处在于,所有这一切都可以在我们自己的开发人员平台上实现。
诚邀您体验 BYO LoRAs 的公测版。 请阅读我们的开发人员文档以了解更多细节,并在 Discord 上告诉我们您的想法 。